YOLOv5改进 | 主干网络 | 将backbone替换为MobileNetV2【小白必备教程+附完整代码】
秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
专栏目录: 《YOLOv5入门 + 改进涨点》专栏介绍 & 专栏目录 |目前已有60+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进
MobileNetV2是一种高效的卷积神经网络架构,专为移动和嵌入式设备上的计算需求设计。它通过引入逆残差结构(Inverted Residuals)和线性瓶颈层,有效地减少了计算量和参数数量,同时保持了良好的精度。该网络在保持较低复杂度的同时,能够在图像分类、目标检测和语义分割等任务中提供强大的性能。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址: YOLOv5改进+入门——持续更新各种有效涨点方法 点击即可跳转
目录
1.原理
2. 将MobileNet v2添加到YOLOv5中
2.1 MobileNet v2的代码实现
2.2 新增yaml文件
2.3 注册模块
2.4 执行程序
3. 完整代码分享
4. GFLOPs
5. 进阶
6. 总结
1.原理

论文地址 :MobileNetV2: Inverted Residuals and Linear Bottlenecks——点击即可跳转
官方代码:官方代码仓库——点击即可跳转
以下原理内容来自@太阳花的小绿豆
在MobileNet v1的网络结构表中能够发现,网络的结构就像VGG一样是个直筒型的,不像ResNet网络有shorcut之类的连接方式。而且有人反映说MobileNet v1网络中的DW卷积很容易训练废掉,效果并没有那么理想。所以我们接着看下MobileNet v2网络。
MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网络,准确率更高,模型更小。刚刚说了MobileNet v1网络中的亮点是DW卷积,那么在MobileNet v2中的亮点就是Inverted residual block(倒残差结构),如下下图所示,左侧是ResNet网络中的残差结构,右侧就是MobileNet v2中的到残差结构。在残差结构中是1x1卷积降维->3x3卷积->1x1卷积升维,在倒残差结构中正好相反,是1x1卷积升维->3x3DW卷积->1x1卷积降维。为什么要这样做,原文的解释是高维信息通过ReLU激活函数后丢失的信息更少(注意倒残差结构中基本使用的都是ReLU6激活函数,但是最后一个1x1的卷积层使用的是线性激活函数)。

在使用倒残差结构时需要注意下,并不是所有的倒残差结构都有shortcut连接,只有当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接(只有当shape相同时,两个矩阵才能做加法运算,当stride=1时并不能保证输入特征矩阵的channel与输出特征矩阵的channel相同)。

下图是MobileNet v2网络的结构表,其中t代表的是扩展因子(倒残差结构中第一个1x1卷积的扩展因子),c代表输出特征矩阵的channel,n代表倒残差结构重复的次数,s代表步距(注意:这里的步距只是针对重复n次的第一层倒残差结构,后面的都默认为1)。

2. 将MobileNet v2添加到YOLOv5中
2.1 MobileNet v2的代码实现
关键步骤一: 将下面代码添加到 yolov5/models/common.py中
class conv_bn_relu_maxpool(nn.Module):def __init__(self, c1, c2): # ch_in, ch_outsuper(conv_bn_relu_maxpool, self).__init__()self.conv = Conv(c1, c2, k=3, s=2, p=1, g=1, act='ReLU')self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)def forward(self, x):return self.maxpool(self.conv(x))def fuse(self):self.conv.fuse()class RepVGGBlock(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, use_se=False, use_cbam=False,padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False):super(RepVGGBlock, self).__init__()self.deploy = deployself.groups = groupsself.in_channels = in_channelsself.out_channels = out_channelsself.kernel_size = kernel_sizeself.stride = strideself.padding = paddingself.dilation = dilationself.groups = groupsself.padding_mode = padding_modepadding_11 = padding - kernel_size // 2# self.nonlinearity = nn.SiLU()self.nonlinearity = nn.ReLU()if use_se or use_cbam:if use_se:self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)if use_cbam:self.se = CBAM(out_channels, internal_neurons=out_channels // 16)else:self.se = nn.Identity()if deploy:self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride,padding=padding, dilation=dilation, groups=groups, bias=True,padding_mode=padding_mode)else:self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else Noneself.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, groups=groups)self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,padding=padding_11, groups=groups)# print('RepVGG Block, identity = ', self.rbr_identity)def get_equivalent_kernel_bias(self):kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasiddef _pad_1x1_to_3x3_tensor(self, kernel1x1):if kernel1x1 is None:return 0else:return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])def _fuse_bn_tensor(self, branch):if branch is None:return 0, 0if isinstance(branch, nn.Sequential):kernel = branch.conv.weightrunning_mean = branch.bn.running_meanrunning_var = branch.bn.running_vargamma = branch.bn.weightbeta = branch.bn.biaseps = branch.bn.epselse:assert isinstance(branch, (nn.BatchNorm2d, nn.SyncBatchNorm))if not hasattr(self, 'id_tensor'):input_dim = self.in_channels // self.groupskernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)for i in range(self.in_channels):kernel_value[i, i % input_dim, 1, 1] = 1self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)kernel = self.id_tensorrunning_mean = branch.running_meanrunning_var = branch.running_vargamma = branch.weightbeta = branch.biaseps = branch.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)return kernel * t, beta - running_mean * gamma / stddef forward(self, inputs):if hasattr(self, 'rbr_reparam'):return self.nonlinearity(self.se(self.rbr_reparam(inputs)))if self.rbr_identity is None:id_out = 0else:id_out = self.rbr_identity(inputs)return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))# RepVGGBlock(in_channels=self.in_planes, out_channels=planes, kernel_size=3,# stride=stride, padding=1, groups=1, deploy=self.deploy, use_se=self.use_se))def fuse(self):if self.deploy == False:self.rbr_reparam = nn.Conv2d(in_channels=self.in_channels, out_channels=self.out_channels,kernel_size=self.kernel_size,stride=self.stride,padding=self.padding, dilation=self.dilation, groups=self.groups, bias=True,padding_mode=self.padding_mode).requires_grad_(False).to(self.rbr_dense.conv.weight.device)self.deploy = Truekernel, bias = self.get_equivalent_kernel_bias()self.rbr_reparam.weight.data = kernelself.rbr_reparam.bias.data = biasself.forward = self.fusevggforwardself.__delattr__('rbr_identity')self.rbr_dense.__delattr__('conv')self.rbr_dense.__delattr__('bn')self.rbr_1x1.__delattr__('conv')self.rbr_1x1.__delattr__('bn')del self._modules['rbr_dense']del self._modules['rbr_1x1']def fusevggforward(self, inputs):return self.nonlinearity(self.se(self.rbr_reparam(inputs)))class MobileNetV2_Block(nn.Module):def __init__(self, inp, oup, stride=1, expand_ratio=1):super(MobileNetV2_Block, self).__init__()assert stride in [1, 2]self.stride = strideself.identity = stride == 1 and inp == ouphidden_dim = int(round(inp * expand_ratio))act = 'ReLU'if expand_ratio != 1:self.conv = nn.Sequential(Conv(inp, hidden_dim, k=1, s=1, p=0, act=act),DWConv(hidden_dim, hidden_dim, k=3, s=stride, act=act),Conv(hidden_dim, oup, k=1, s=1, p=0, act=False),)else:self.conv = nn.Sequential(DWConv(hidden_dim, hidden_dim, k=3, s=stride, act=act),Conv(hidden_dim, oup, k=1, s=1, p=0, act=False),)def forward(self, x):y = self.conv(x)if self.identity:return x + yelse:return ydef fuse(self):for m in self.conv:if isinstance(m, (Conv, DWConv, RepVGGBlock)):m.fuse()
2.2 新增yaml文件
关键步骤二:在下/yolov5/models下新建文件 yolov5_MobileNetv2.yaml并将下面代码复制进去
- 目标检测yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# Mobilenetv3Small backbone
# MobileNetV3_Block in_ch, [out_ch, hid_ch, k_s, stride, SE, HardSwish]
backbone:# [from, number, module, args][[-1, 1, Conv, [32, 3, 2]], # 0-p1/2[-1, 1, MobileNetV2_Block, [16, 1, 1]], # 1[-1, 1, MobileNetV2_Block, [24, 2, 6]], # 2-p2/4[-1, 1, MobileNetV2_Block, [24, 1, 6]], # 3[-1, 1, MobileNetV2_Block, [32, 2, 6]], # 4-p3/8[-1, 2, MobileNetV2_Block, [32, 1, 6]], # 5[-1, 1, MobileNetV2_Block, [64, 2, 6]], # 6-p4/16[-1, 3, MobileNetV2_Block, [64, 1, 6]], # 7[-1, 1, MobileNetV2_Block, [96, 1, 6]], # 8[-1, 2, MobileNetV2_Block, [96, 1, 6]], # 9[-1, 1, MobileNetV2_Block, [160, 2, 6]], # 10-p5/32[-1, 2, MobileNetV2_Block, [160, 1, 6]], # 11[-1, 1, MobileNetV2_Block, [320, 1, 6]], # 12[-1, 1, SPPF, [1024, 5]], # 13]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [256, 1, 1]], # 14[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 9], 1, Concat, [1]], # cat backbone P4[-1, 1, C3, [256, False]], # 17[-1, 1, Conv, [128, 1, 1]], # 18[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3[-1, 1, C3, [128, False]], # 20 (P3/8-small)[-1, 1, Conv, [128, 3, 2]],[[-1, 18], 1, Concat, [1]], # cat head P4[-1, 1, C3, [256, False]], # 24 (P4/16-medium)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P5[-1, 1, C3, [512, False]], # 27 (P5/32-large)[[21, 24, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]- 语义分割yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# Mobilenetv3Small backbone
# MobileNetV3_Block in_ch, [out_ch, hid_ch, k_s, stride, SE, HardSwish]
backbone:# [from, number, module, args][[-1, 1, Conv, [32, 3, 2]], # 0-p1/2[-1, 1, MobileNetV2_Block, [16, 1, 1]], # 1[-1, 1, MobileNetV2_Block, [24, 2, 6]], # 2-p2/4[-1, 1, MobileNetV2_Block, [24, 1, 6]], # 3[-1, 1, MobileNetV2_Block, [32, 2, 6]], # 4-p3/8[-1, 2, MobileNetV2_Block, [32, 1, 6]], # 5[-1, 1, MobileNetV2_Block, [64, 2, 6]], # 6-p4/16[-1, 3, MobileNetV2_Block, [64, 1, 6]], # 7[-1, 1, MobileNetV2_Block, [96, 1, 6]], # 8[-1, 2, MobileNetV2_Block, [96, 1, 6]], # 9[-1, 1, MobileNetV2_Block, [160, 2, 6]], # 10-p5/32[-1, 2, MobileNetV2_Block, [160, 1, 6]], # 11[-1, 1, MobileNetV2_Block, [320, 1, 6]], # 12[-1, 1, SPPF, [1024, 5]], # 13]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [256, 1, 1]], # 14[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 9], 1, Concat, [1]], # cat backbone P4[-1, 1, C3, [256, False]], # 17[-1, 1, Conv, [128, 1, 1]], # 18[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3[-1, 1, C3, [128, False]], # 20 (P3/8-small)[-1, 1, Conv, [128, 3, 2]],[[-1, 18], 1, Concat, [1]], # cat head P4[-1, 1, C3, [256, False]], # 24 (P4/16-medium)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P5[-1, 1, C3, [512, False]], # 27 (P5/32-large)[[21, 24, 27], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)]温馨提示:本文只是对yolov5基础上添加模块,如果要对yolov5n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv5n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple# YOLOv5s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple# YOLOv5l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# YOLOv5m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple# YOLOv5x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.3 注册模块
关键步骤三:在yolo.py的parse_model函数中注册 添加“MobileNetv2",

2.4 执行程序
在train.py中,将cfg的参数路径设置为yolov5_MobileNetv2.yaml的路径
建议大家写绝对路径,确保一定能找到

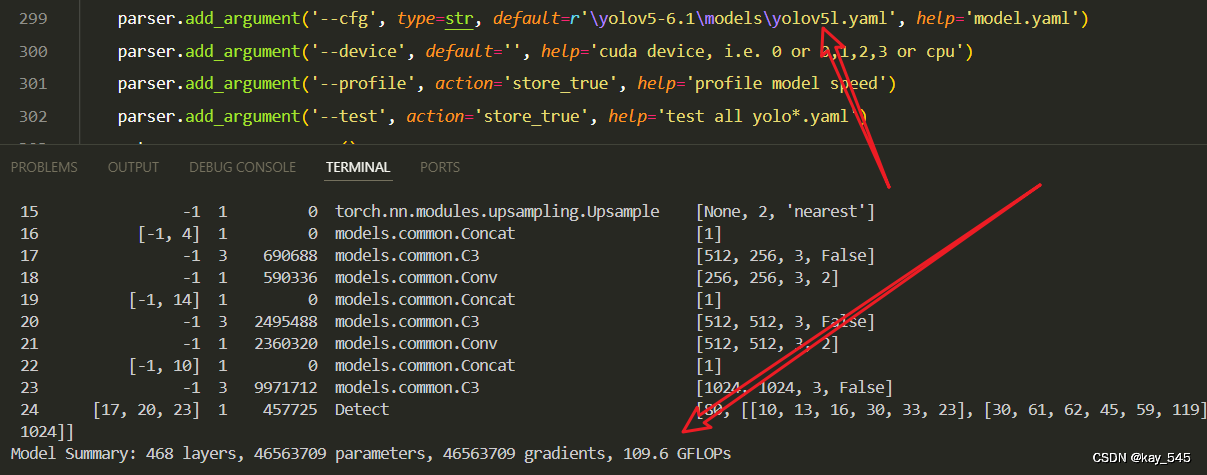
🚀运行程序,如果出现下面的内容则说明添加成功🚀
from n params module arguments0 -1 1 928 models.common.Conv [3, 32, 3, 2]1 -1 1 896 models.common.MobileNetV2_Block [32, 16, 1, 1]2 -1 1 5136 models.common.MobileNetV2_Block [16, 24, 2, 6]3 -1 1 8832 models.common.MobileNetV2_Block [24, 24, 1, 6]4 -1 1 10000 models.common.MobileNetV2_Block [24, 32, 2, 6]5 -1 2 29696 models.common.MobileNetV2_Block [32, 32, 1, 6]6 -1 1 21056 models.common.MobileNetV2_Block [32, 64, 2, 6]7 -1 3 162816 models.common.MobileNetV2_Block [64, 64, 1, 6]8 -1 1 66624 models.common.MobileNetV2_Block [64, 96, 1, 6]9 -1 2 236544 models.common.MobileNetV2_Block [96, 96, 1, 6]10 -1 1 155264 models.common.MobileNetV2_Block [96, 160, 2, 6]11 -1 2 640000 models.common.MobileNetV2_Block [160, 160, 1, 6]12 -1 1 473920 models.common.MobileNetV2_Block [160, 320, 1, 6]13 -1 1 708928 models.common.SPPF [320, 1024, 5]14 -1 1 262656 models.common.Conv [1024, 256, 1, 1]15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']16 [-1, 9] 1 0 models.common.Concat [1]17 -1 1 321024 models.common.C3 [352, 256, 1, False]18 -1 1 33024 models.common.Conv [256, 128, 1, 1]19 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']20 [-1, 5] 1 0 models.common.Concat [1]21 -1 1 78592 models.common.C3 [160, 128, 1, False]22 -1 1 147712 models.common.Conv [128, 128, 3, 2]23 [-1, 18] 1 0 models.common.Concat [1]24 -1 1 296448 models.common.C3 [256, 256, 1, False]25 -1 1 590336 models.common.Conv [256, 256, 3, 2]26 [-1, 14] 1 0 models.common.Concat [1]27 -1 1 1182720 models.common.C3 [512, 512, 1, False]28 [21, 24, 27] 1 229245 Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
YOLOv5 summary: 347 layers, 5662397 parameters, 5662397 gradients, 11.5 GFLOPs3. 完整代码分享
https://pan.baidu.com/s/1uxmTHtaXpeL-hWyP1-me1w?pwd=r6hg提取码: r6hg
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的GFLOPs
改进后的GFLOPs
现在手上没有卡了,等过段时候有卡了把这补上,需要的同学自己测一下

5. 进阶
可以结合损失函数或者卷积模块进行多重改进
YOLOv5改进 | 损失函数 | EIoU、SIoU、WIoU、DIoU、FocuSIoU等多种损失函数——点击即可跳转
6. 总结
MobileNetV2是谷歌于2018年提出的一种高效卷积神经网络架构,专为移动和嵌入式设备设计。它通过引入逆残差结构和线性瓶颈层,优化了计算效率和模型性能,显著减少了计算量和参数数量。MobileNetV2在图像分类、目标检测和语义分割等任务中表现出色,能够在资源受限的设备上提供与更大模型相近的精度。
相关文章:
YOLOv5改进 | 主干网络 | 将backbone替换为MobileNetV2【小白必备教程+附完整代码】
秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转 💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 专栏目录: 《YOLOv5入门 改…...

ARMxy边缘计算网关用于过程控制子系统
在现代工业生产中,过程控制系统的优化对于提高生产效率、保证产品质量、降低能源消耗等方面都具有重要意义。而 ARMxy 工控机作为一种高性能、高可靠性的工业控制设备,正逐渐成为过程控制系统优化的新选择。 ARMxy 工控机采用了先进的 ARM 架构处理器&am…...

Python | TypeError: unsupported operand type(s) for +=: ‘int’ and ‘str’
Python | TypeError: unsupported operand type(s) for : ‘int’ and ‘str’:深度解析 在Python编程中,遇到“TypeError: unsupported operand type(s) for : ‘int’ and ‘str’”这类错误通常意味着你尝试将一个整数(int)和…...

什么是开源什么是闭源?以及它们之间的关系
开源软件(Open Source Software) 定义:开源软件是指其源代码可以被公众访问和使用的软件。用户可以查看、修改和增强软件的源代码。 许可:通常遵循特定的开源许可证,如GNU通用公共许可证(GPL)、…...

SpringBoot+Mybatis Plus实际开发中的注解
SpringBoot+Mybatis Plus实际开发中的注解 实体类Service层Mapper层Controller层启动类配置类SpringBoot+Mybatis Plus实际开发中的注解 实体类 @Data : 底层实现了getter、setter、toString、hashCode、equals 和无参构造@AllArgsConstructor: 底层实现了有参构造@NoArgsCon…...

【香橙派系列教程】(八)一小时速通Python
【八】一小时速通Python 本章内容服务于香橙派下的开发,用C语言的视角来学习即可,会改就行。 详细说明,请看链接:python全篇教学 Python是一种动态解释型的编程语言,Python可以在Windows、UNIX、MAC等多种操作系统上 使用&…...

了解JavaScript 作用、历史和转变
JavaScript 是一种即时执行的脚本语言,其代码在浏览器环境中通过内置的 JavaScript 引擎被动态地一行接一行地解释执行。这一特性赋予了开发者极高的灵活性和效率,因为代码修改后能立即生效,无需经历编译过程,从而加速了开发周期和…...

遗传算法与深度学习实战——生命模拟与进化论
遗传算法与深度学习实战——生命模拟与进化论 0. 前言1. 模拟进化1.1 代码实现1.2 代码改进 2. 达尔文进化论3. 自然选择和适者生存3.1 适者生存3.2 进化计算中的生物学 小结系列链接 0. 前言 生命模拟通过计算机模拟生物体的基本特征、遗传机制、环境互动等,试图模…...

rt-thread H7 使用fdcan没有外接设备时或发送错误时线程被挂起的解决方案
一、问题查找 使用的开发版是硬石的H7芯片型号STM32H743IIT6,测试时发现如果外面没有连接CAN设备,程序调用CAN发送时会一直等待发送反馈,导致相关线程挂起。 在线仿真时发现是卡在can.c文件的168行_can_int_tx函数:rt_co…...

exptern “C“的作用,在 C 和 CPP 中分别调用 openblas 中的 gemm 为例
openblas提供的sgemm有两种方式,一种是通过cblas,另一种是直接声明并调用 sgemm_ 其中,cblas方式是更正规调用方法; 1,调用openblas的 sgemm 的两种方式 1.1 c语言程序中使用 sgemm hello_sgemm.c #include <st…...

如何提前预防网络威胁
一、引言 随着信息技术的迅猛进步,网络安全议题愈发凸显,成为社会各界不可忽视的重大挑战。近年来,一系列网络安全事件的爆发,如同惊雷般震撼着个人、企业及国家的安全防线,揭示了信息安全保护的紧迫性与复杂性。每一…...

ProviderRpc发送服务二将远程调用来的信息反序列化后调用服务方的方法,并将服务方的结果返回给发送方
在Provider的实现中,OnMessage函数中,处理接收到的连接RPC请求。将接收到的RPC请求(包含请求的对象,请求方法和 请求参数),接收到这些信息之后进行反序列化。得到这些参数之后我们即将要做的事情是去调用相…...

Io 35
FIleinputStream字节输入 package File.io;import java.io.*;public class io1 {public static void main(String[] args) throws IOException {// InputStream is new FileInputStream(new File("C:\\Users\\SUI\\Desktop\\Java1\\one\\src\\kaishi"));//简化Input…...

java基础概念11-方法
一、什么是方法 方法(method)是程序中最小的执行单元。 方法中的程序,要不然就是一起执行,要不然就是一起不执行!!! 二、方法的定义 在Java中,方法定义的一般格式如下:…...

大模型应用中的思维树(Tree of Thought)是什么?
大模型应用中的思维树(Tree of Thought)是什么? 大模型,特别是基于GPT(Generative Pre-trained Transformer)架构的模型,在处理复杂任务时,通常需要依赖某种形式的推理和决策机制。…...
:训练图片分类的算法)
学习记录(11):训练图片分类的算法
文章目录 一、卷积神经网络(CNN)架构1. ResNet(Residual Networks)2. DenseNet(Densely Connected Convolutional Networks)3. EfficientNet4. MobileNet 二、变换器(Transformer)架…...

上网防泄密,这些雷区不要碰!九招教你如何防泄密
李明:“最近看到不少关于信息泄露的新闻,真是让人担忧。咱们在工作中,稍有不慎就可能触碰到泄密的雷区啊。” 王芳:“确实,网络安全无小事。尤其是我们这种经常需要处理敏感信息的岗位,更得小心谨慎。那你…...

数据库篇--八股文学习第十五天| 一条SQL查询语句是如何执行的?,事务的四大特性有哪些?,数据库的事务隔离级别有哪些?
1、一条SQL查询语句是如何执行的? 答: 连接器:连接器负责跟客户端建立连接、获取权限、维持和管理连接。查询缓存: MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以…...

elk + filebeat + kafka实验和RSync同步
elk filebeat kafka实验和RSync同步 elk filebeat kafka实验 filebeatkafkaELK实验的操作步骤: #在装有nginx的主机上解压filebeat压缩包 [roottest4 opt]# tar -xf filebeat-6.7.2-linux-x86_64.tar.gz #将解压后的压缩包更改名字 [roottest4 opt]# mv file…...
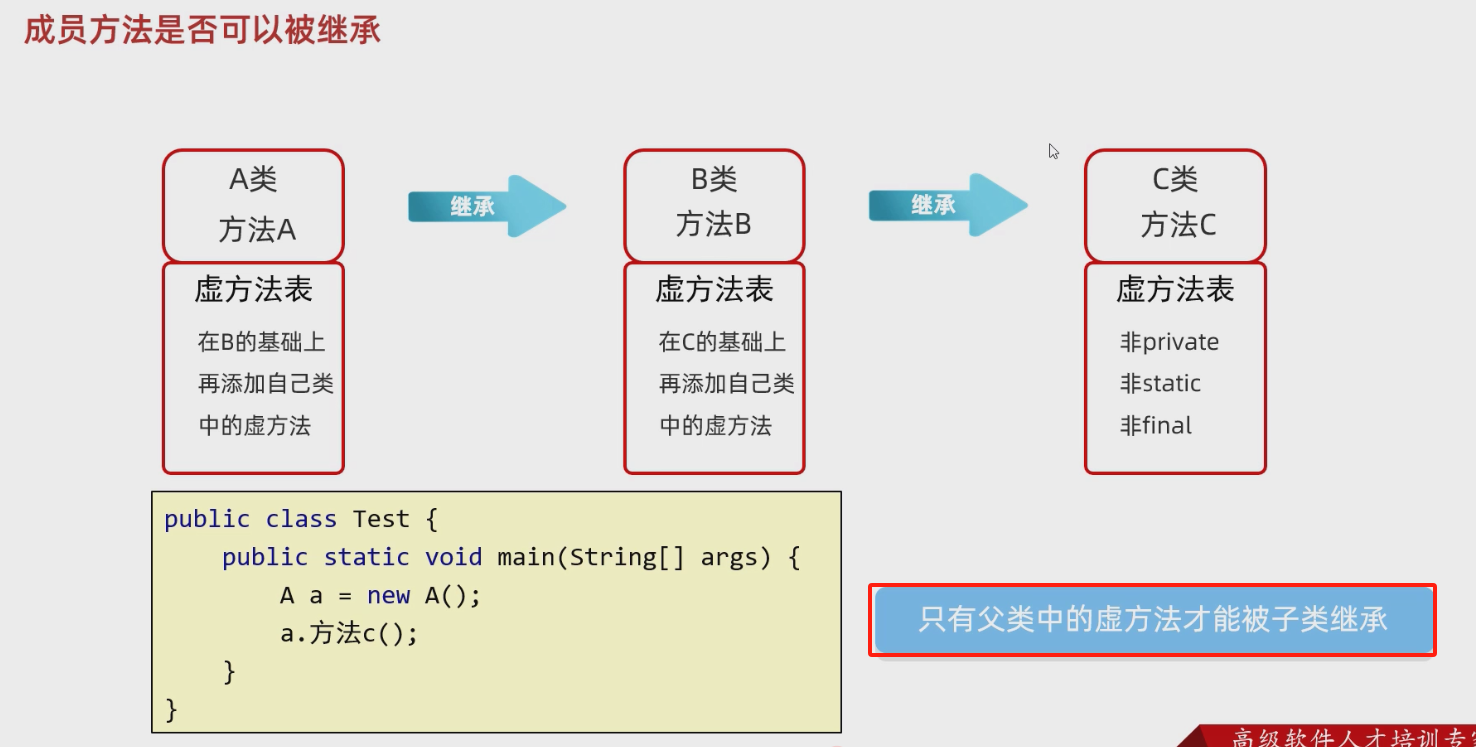
子类到底能继承父类中的哪些内容?
...

3个步骤实现Zotero笔记与Obsidian双向同步:告别手动复制粘贴
3个步骤实现Zotero笔记与Obsidian双向同步:告别手动复制粘贴 【免费下载链接】zotero-better-notes Everything about note management. All in Zotero. 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-better-notes Zotero-Better-Notes的Markdown双向…...
)
STM32开发者必看:Openocd烧录全流程详解(附Keil生成bin文件技巧)
STM32开发者必看:Openocd烧录全流程详解(附Keil生成bin文件技巧) 在嵌入式开发领域,STM32系列微控制器因其出色的性能和丰富的生态而广受欢迎。对于开发者而言,掌握高效可靠的烧录工具是提升开发效率的关键一环。Openo…...
管理与安全配置的那些事儿)
泛微Ecology异构集成避坑指南:许可证(AppID)管理与安全配置的那些事儿
泛微Ecology异构系统集成安全实践:从许可证管理到防御体系构建 当企业数字化转型进入深水区,异构系统间的数据流通成为刚需。作为国内主流OA平台的泛微Ecology,其开放能力常被用于构建企业级应用生态。但我们在多个大型客户实施案例中发现&am…...

深入解读:SOEM配置汇川SV660N时,PDO映射与EtherCAT状态机的那些关键细节
深入解读:SOEM配置汇川SV660N时,PDO映射与EtherCAT状态机的那些关键细节 在工业自动化领域,EtherCAT协议因其高效性和实时性已成为运动控制系统的首选。然而,当工程师们在实际项目中配置汇川SV660N伺服驱动器时,常常会…...

Bebas Neue 字体终极指南:开源无衬线字体的设计哲学与实战应用
Bebas Neue 字体终极指南:开源无衬线字体的设计哲学与实战应用 【免费下载链接】Bebas-Neue Bebas Neue font 项目地址: https://gitcode.com/gh_mirrors/be/Bebas-Neue 在数字设计的世界中,寻找一款既具有视觉冲击力又具备专业品质的标题字体往往…...

极域电子教室破解终极指南:如何用JiYuTrainer重获电脑控制权
极域电子教室破解终极指南:如何用JiYuTrainer重获电脑控制权 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 还在为课堂上的全屏广播而苦恼吗?当老师开启极…...

如何快速完成重庆大学毕业论文格式排版?终极LaTeX模板使用指南
如何快速完成重庆大学毕业论文格式排版?终极LaTeX模板使用指南 【免费下载链接】CQUThesis :pencil: 重庆大学毕业论文LaTeX模板---LaTeX Thesis Template for Chongqing University 项目地址: https://gitcode.com/gh_mirrors/cq/CQUThesis 还在为毕业论文格…...

SAP财务数据一致性检查:手把手教你用ABAP程序自动修复ACDOCA表异常
SAP财务数据一致性检查:手把手教你用ABAP程序自动修复ACDOCA表异常 在SAP财务模块的日常运维中,ACDOCA表作为新总账(New GL)的核心表,承载着所有财务凭证的明细数据。然而在实际操作中,我们经常会遇到ACDOCA表与BSEG表数据不一致的…...

Windows用户必看:3分钟免费获取macOS同款鼠标指针的终极指南
Windows用户必看:3分钟免费获取macOS同款鼠标指针的终极指南 【免费下载链接】macOS-cursors-for-Windows Tested in Windows 10 & 11, 4K (125%, 150%, 200%). With 2 versions, 2 types and 3 different sizes! 项目地址: https://gitcode.com/gh_mirrors/m…...

Wan2.2-I2V-A14B镜像免配置方案:单卡24G显存+120GB内存开箱即用部署指南
Wan2.2-I2V-A14B镜像免配置方案:单卡24G显存120GB内存开箱即用部署指南 1. 镜像概述与核心优势 Wan2.2-I2V-A14B是一款专为文生视频任务优化的私有部署镜像,针对RTX 4090D 24GB显存显卡进行了深度优化。这个镜像最大的特点就是"开箱即用"——…...