WeNet 2.0:更高效的端到端语音识别工具包
WeNet 2.0:更高效的端到端语音识别工具包
原文链接:[2203.15455] WeNet 2.0: More Productive End-to-End Speech Recognition Toolkit (arxiv.org)
1.摘要
WeNet是一个开源的端到端语音识别工具包,WeNet 2.0在此基础上进行了四项主要更新,以提升其在生产环境中的适应性和性能。
主要更新内容:
- U2++ 框架:
- 改进点:在原有U2框架的基础上增加了双向注意力解码器,通过右到左的注意力解码器引入未来上下文信息,提升了共享编码器的代表能力和重评分阶段的性能。
- 性能提升:实验结果表明,U2++相较于原U2框架在多种语料库上的识别性能提升了10%。
- 生产语言模型解决方案:
- 改进点:引入了基于n-gram的语言模型和基于加权有限状态转移(WFST)的解码器,促进了丰富文本数据在生产场景中的使用。
- 性能提升:实验结果显示,n-gram语言模型在流式CTC解码阶段可提供高达8%的相对性能提升。
- 上下文偏置框架:
- 改进点:设计了统一的上下文偏置框架,利用用户特定的上下文信息(例如联系人列表)提供快速适应能力,提高了有LM和无LM场景下的ASR准确率。
- 统一IO(UIO)系统:
- 改进点:设计了统一的IO系统,支持大规模数据集的高效模型训练。UIO系统提供了针对不同存储介质(例如本地磁盘或云)的统一接口,以及对不同规模数据集(例如小数据集或大数据集)的统一支持。
2.Wenet2.0
2.1 U2++
U2++ 框架
U2++ 框架是对原始 U2 框架的增强,加入了双向注意力解码器。该方法结合了从左到右(L2R)和从右到左(R2L)的注意力解码器,在训练和解码期间利用了过去和未来的上下文信息。主要组成部分如下:
- 共享编码器:这个编码器捕捉声学特征信息,由多个 Transformer 或 Conformer 层组成。通过考虑有限的右上下文来平衡延迟。
- CTC 解码器:该解码器建模声学特征与标记单元之间的帧级对齐信息。CTC 解码器由一个线性层组成,该层将共享编码器的输出转换为 CTC 激活。
- 从左到右的注意力解码器 (L2R):该解码器从左到右建模有序标记序列,以表示过去的上下文信息。
- 从右到左的注意力解码器 (R2L):该解码器从右到左建模反向标记序列,以表示未来的上下文信息。L2R 和 R2L 注意力解码器都由多个 Transformer 解码器层组成。
在解码阶段,CTC 解码器在第一遍中以流模式运行,L2R 和 R2L 注意力解码器在第二遍中以非流模式重新评分,以提高性能。

相较于 U2 框架的改进
与 U2 框架相比,U2++ 额外加入了一个从右到左的注意力解码器,以增强模型的上下文建模能力,从而使上下文信息不仅来自过去(左到右解码器),还来自未来(右到左解码器)。这提高了共享编码器的表征能力、整个系统的泛化能力以及重新评分阶段的性能。
训练和解码过程
结合 CTC 和 AED 损失来训练 U2++ 模型:
L combined ( x , y ) = λ L CTC ( x , y ) + ( 1 − λ ) L AED ( x , y ) L_{\text{combined}}(x,y) = \lambda L_{\text{CTC}}(x,y) + (1-\lambda)L_{\text{AED}}(x,y) Lcombined(x,y)=λLCTC(x,y)+(1−λ)LAED(x,y)
其中, x x x 表示声学特征, y y y 表示相应的标签, λ λ λ 是一个平衡 CTC 损失和 AED 损失的重要性超参数。
为了在模型中加入一个额外的 R2L 注意力解码器,我们在 AED 损失中引入一个超参数 α\alphaα 以调整两个单向解码器的贡献:
L AED ( x , y ) = ( 1 − α ) L L2R ( x , y ) + α L R2L ( x , y ) L_{\text{AED}}(x,y) = (1-\alpha)L_{\text{L2R}}(x,y) + \alpha L_{\text{R2L}}(x,y) LAED(x,y)=(1−α)LL2R(x,y)+αLR2L(x,y)
动态块掩码策略用于统一流模式和非流模式。在训练阶段,我们首先从均匀分布中随机抽取一个块大小 CCC,然后将输入拆分为几个具有选择块大小的块。最后,当前块在 L2R/R2L 注意力解码器中分别对自身和前/后的块执行双向块级注意力。在解码阶段,第一遍 CTC 解码器获得的 n-best 结果由 L2R 和 R2L 注意力解码器利用共享编码器生成的相应声学信息重新评分。最终结果通过融合两个注意力解码器和 CTC 解码器的分数获得。
经验上,更大的块大小会带来更好的结果,但延迟也更高。感谢动态策略,U2++ 学会了以任意块大小进行预测,从而在解码中通过调整块大小简化了准确性和延迟的平衡。
2.2 语言模型
为了在生产环境中使用丰富的文本数据,我们在 WeNet 2.0 中提供了一个统一的语言模型 (LM) 集成框架。
作为一个统一的 LM 和无 LM 系统,CTC 被用于生成第一遍的 n-best 结果。当没有提供 LM 时,CTC 前缀波束搜索用于获取 n-best 候选。当提供了 LM 时,WeNet 2.0 将 n-gram LM (G)、词典 (L) 和端到端建模 CTC 拓扑 (T) 编译成基于 WFST 的解码图 (TLG):
T L G = T ∘ min ( det ( L ∘ G ) ) TLG = T \circ \min(\text{det}(L \circ G)) TLG=T∘min(det(L∘G))
然后应用 CTC WFST 波束搜索来获得 n-best 候选。最终,通过注意力重新评分模块重新评分 n-best 候选以找到最佳候选。

2.3 上下文偏置
利用用户特定的上下文信息(例如联系人列表、导航信息)在语音生产中起着重要作用,它不仅显著提高了准确性,还提供了快速适应能力。WeNet 2.0 中设计了一个统一的上下文偏置框架,在流解码阶段利用了用户特定的上下文信息,无论是否使用 LM。
构建过程
- 偏置单元的分割:
- 在无语言模型(LM-free)的情况下,根据 E2E 建模单元将偏置短语分割成偏置单元。
- 在有语言模型(with-LM)的情况下,根据词汇表将偏置短语分割成词汇单元。
- 构建上下文 WFST 图:
- 每个带有增强评分的偏置单元按顺序放置在相应的弧上以生成可接受的链。
- 对于可接受链的每个中间状态,添加一个特殊的失败弧,其带有负的累计增强评分。失败弧用于在仅匹配部分偏置单元而非整个短语时移除增强评分 。
在图 3 中,分别展示了在无语言模型(LM-free)情况下的字符级上下文图和有语言模型(with-LM)情况下的词级上下文图。最终,在流式解码阶段,当光束搜索结果通过上下文 WFST 图与偏置单元匹配时,立即添加一个增强评分 。
公式如下:
y ∗ = arg max y log P ( y ∣ x ) + λ log P C ( y ) y^* = \arg\max_y \log P(y|x) + \lambda \log P_C(y) y∗=argymaxlogP(y∣x)+λlogPC(y)
其中 P C ( y ) P_C(y) PC(y)是偏置分数, λ λ λ是一个可调的超参数,用于控制上下文LM对整体模型分数的影响程度。特别是,当一些偏置短语共享相同的前缀时,我们会进行贪婪匹配以简化实现。

2.4 统一 IO (UIO)
为了处理大规模生产数据集并同时保持对小数据集的高效性,我们设计了一个统一的 IO 系统,提供了针对不同存储(例如本地磁盘或云存储)和不同规模数据集(例如小数据集或大数据集)的统一接口。对于大数据集,我们将每组样本(例如1000个样本)及其相关的元数据信息打包到一个更大的 shard 中。在训练阶段,内存中进行动态解压缩,同一压缩 shard 中的数据按顺序读取,从而解决了时间消耗的问题并加速训练过程。对于小数据集,我们也可以直接加载训练样本。

3.实验
这一章描述了我们的实验设置、测试集,并分析了实验结果。大多数实验设置在WeNet的recipes中可用。实验涉及以下所有或部分语料库:AISHELL-1【28】、AISHELL-2【29】、LibriSpeech【30】、GigaSpeech【31】和最近发布的WenetSpeech【32】。这五个语料库包括不同的语言(英语和普通话)、录音环境(干净和嘈杂)和规模(100到10000小时)。
3.1. U2++
为了评估U2++模型的有效性,我们在上述所有5个ASR语料库上进行了实验。对于大多数实验,使用80维的对数梅尔滤波器组(FBANK),窗口长度为25ms,移位为10ms作为声学特征。在数据增强中应用了SpecAugment【33】。在编码器的前端使用两个卷积子采样层,卷积核大小为3x3,步幅为2。我们在编码器中使用12层Conformer层。为了保持U2和U2++的参数可比性,我们在U2/U2++中分别使用了6层Transformer解码器。最终模型通过模型平均化获得。在AISHELL-1和AISHELL-2中,注意力层的维度为256,前馈神经网络的维度为2048,注意力头数为4。在LibriSpeech、GigaSpeech和WenetSpeech中,注意力层的维度为512,前馈神经网络的维度为2048,注意力头数为8。卷积模块的卷积核大小分别为8/8/31/31/15。使用累积梯度来稳定训练。
在表1中,我们报告了每个语料库的字符错误率(CER)、单词错误率(WER)或混合错误率(MER)。结果显示,U2++在大多数语料库上优于U2,在某些语料库上相对于U2实现了高达10%的相对改进。从结果中,我们可以看出,U2++在各种类型和规模的ASR语料库中表现出优越的性能。

3.2. N-gram语言模型
N-gram语言模型能够捕获单词间的上下文信息,从而减少识别错误。我们使用KenLM工具【34】训练了N-gram模型,并将其与U2++模型结合。实验结果表明,结合N-gram语言模型后,识别性能得到了显著提高。

3.3 上下文偏置
在这一部分,研究了在不同情境下对语音识别的效果进行了测试和分析。特别地,研究了在联系人场景中的情境偏置。
测试集设计
研究设计了两个测试集来评估情境偏置的效果:
- test p(positive test set):正向测试集,包含相关的上下文。选取了107个包含人名的语音,并在解码时将所有人名作为情境偏置短语加入。
- test n(negative test set):负向测试集,不包含任何情境偏置短语(如人名)。随机选择了107个适合的语音作为负向测试集。
实验设置
实验使用了AISHELL-1的U2++模型,并分别在有无语言模型(LM)的情况下进行了测试。情境偏置的强度可以通过调整boosted score来控制,boosted score的取值范围为0到10,其中0表示不应用情境偏置。
实验结果
实验结果如表3所示:
- 无LM时:随着boosted score的增加,正向测试集(test p)的错误率显著降低。在boosted score为7时,错误率从14.94%降到6.17%。负向测试集(test n)的错误率则在7.45%到8.06%之间波动。
- 有LM时:正向测试集(test p)的错误率同样随着boosted score的增加而降低,在boosted score为10时,错误率从13.95%降到9.14%。负向测试集(test n)的错误率则保持稳定,在7.20%到7.33%之间。
总体来看,适当的boosted score可以显著提高正向测试集的性能,同时避免对负向测试集性能的影响。这表明情境偏置技术在特定上下文中能够有效提高语音识别的准确性。

3.4. UIO
在AISHELL-1上,原始模式和分片模式下的UIO准确率接近,而分片模式的训练速度提高了约9.27%。对于Wenet-Speech,因为它太慢了,不能只使用原始模式进行训练,所以训练速度没有显示。我们采用ESPnet的结果(用†标记)作为我们的基线,它与我们的模型具有相同的配置。基于分片模式的Wenet-Speech模型训练结果与ESPnet相当,进一步证明了UIO算法的有效性。

我们采用ESPnet的结果(用†标记)作为我们的基线,它与我们的模型具有相同的配置。基于分片模式的Wenet-Speech模型训练结果与ESPnet相当,进一步证明了UIO算法的有效性。
4总结
在本文中,我们提出了更具生产力的 E2E 语音识别工具包 WeNet 2.0,它引入了几个重要的面向生产的特性并实现了显著的 ASR 性能改进。我们正在开发 WeNet 3.0,主要专注于无监督自学习、设备端模型探索和优化以及其他生产工作。
相关文章:
WeNet 2.0:更高效的端到端语音识别工具包
WeNet 2.0:更高效的端到端语音识别工具包 原文链接:[2203.15455] WeNet 2.0: More Productive End-to-End Speech Recognition Toolkit (arxiv.org) 1.摘要 WeNet是一个开源的端到端语音识别工具包,WeNet 2.0在此基础上进行了四项主要更新,…...

阿里大模型调用 = 》通义千问大语言模型
背景:简单的通过API或者SDK在线调用阿里云大模型(基于百炼平台),基于在线知识库 参考地址:安装阿里云百炼SDK_大模型服务平台百炼(Model Studio)-阿里云帮助中心 (aliyun.com) 1、获取API-KEY 当您通过API/SDK调用大模…...

idea使用free流程,2024idea免费使用
1.先到官网下载,这里选择win系统的,点击下图的.exe https://www.jetbrains.com/idea/download/?sectionwindows 2.下载好后基本上就是一直点击“下一步”到直到安装好,安装好后先打开软件后关闭退出 3.下载配配套资料 链接: https://pan.ba…...

算法_链表专题---持续更新
文章目录 前言两数相加题目要求题目解析代码如下 两两交换链表中的结点题目要求题目解析代码如下 重排链表题目要求题目解析代码如下 合并K个升序链表题目要求题目解析 K个一组翻转链表题目要求题目解析代码如下 前言 本文将记录leetcode链表算法题解,包含题目有&a…...

在Windows MFC\C++编程中,如何使用OnCopyData函数
在C中,OnCopyData 函数通常不是标准C库的一部分,而是与特定的图形用户界面(GUI)框架相关联,如Microsoft Foundation Classes (MFC) 或 Windows API 编程。在MFC应用程序中,OnCopyData 是用于处理来自其他应…...

【Qt】项目代码
main.cpp文件 argc:命令行参数个数。*argv[ ]:每一个命令行参数的内容。main的形参就是命令行参数。QApplication a(argc, argv) 编写一个Qt的图形化界面程序,一定需要QApplication对象。 widget w; 在创建项目的时候,勾选widg…...
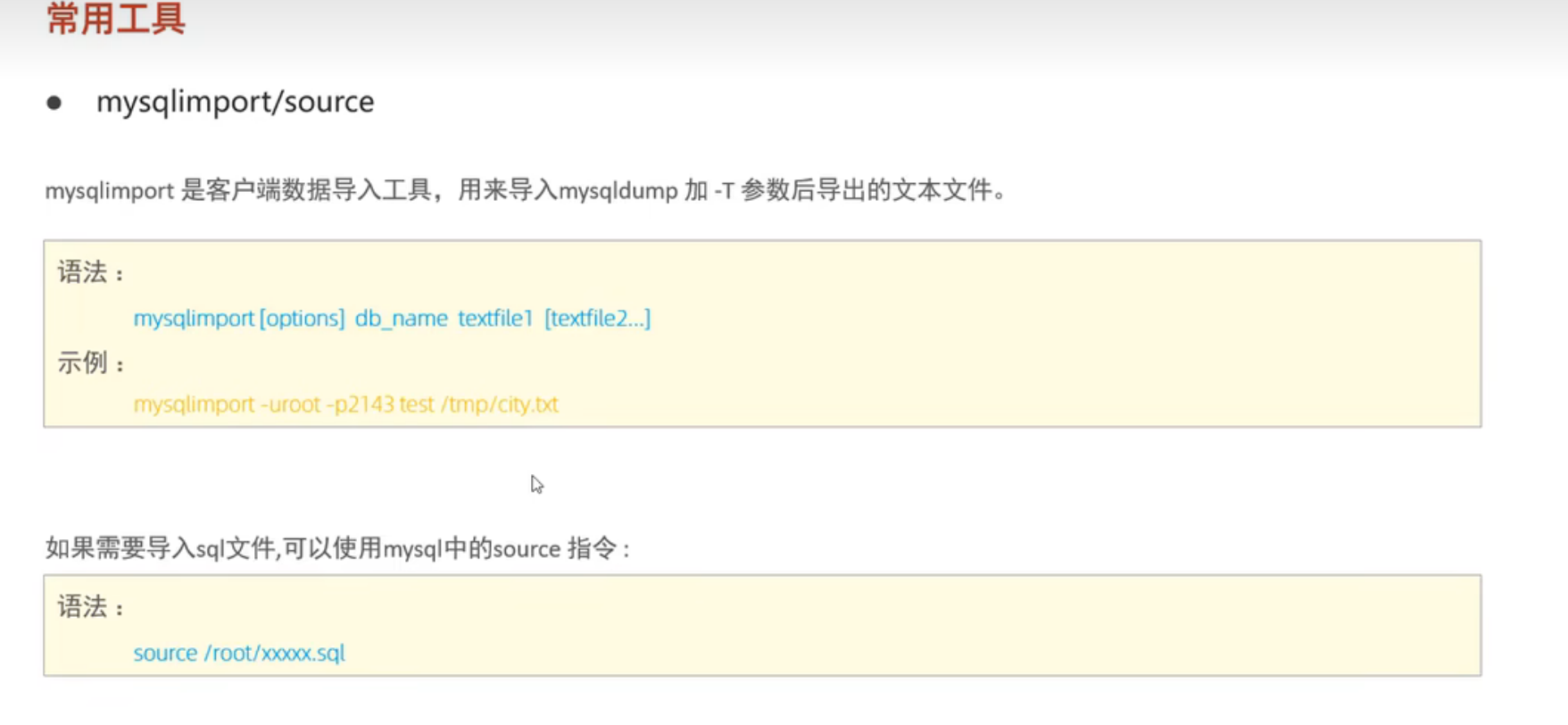
MySQL中常用工具
MySQL自带的系统数据库 常用工具 MySQL mysqladmin mysqlbinlog mysqldump mysqlimport/source mysqlimport只能导入文本文件,不能导入sql文件...
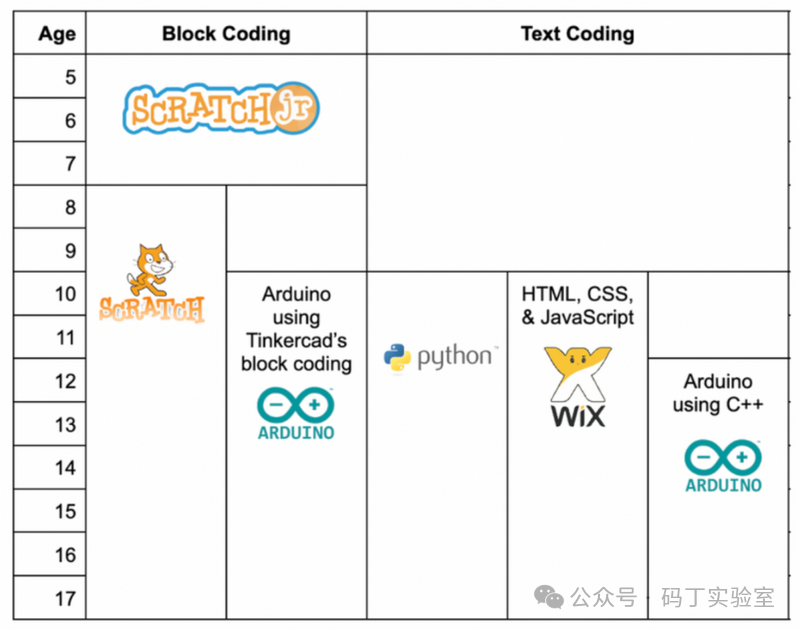
关于儿童编程语言
青少年通常会通过Scratch或Python开始学习编程。在这两种语言中,代码的编写(或者在Scratch中是构建)方式类似于英语,这使得初学者更容易学习。Scratch的一个重要卖点是对视觉和运动感知学习者非常友好。这些代码块按颜色编码&…...

[io]进程间通信 -信号函数 —信号处理过程
sighandler_t signal(int signum, sighandler_t handler); 功能: 信号处理函数 参数: signum:要处理的信号 handler:信号处理方式 SIG_IGN:忽略信号 SIG_DFL:执行默认操作 handler:捕捉信 …...

RoboDK的插件
目录 collision-free-planner: opc-ua: collision-free-planner: RoboDK 的无碰撞规划器插件使用概率路线图 (PRM) 自动在机器人工作空间内创建无碰撞路径。 有关无碰撞规划器的更多信息,请访问我们的 文档。 生成参数无碰撞…...

List<HashMap<String, Object>>排序
如果列表中的元素类型是List<HashMap<String, Object>>,排序时需要考虑到value可能是任意类型的对象。在这种情况下,你可以针对具体的类型进行比较,或者使用Comparable接口来确保对象可以被正确比较。 示例代码 假设我们想要根据…...

【大数据】探索大数据基础知识:定义、特征与生态系统
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: 工💗重💗hao💗:野老杂谈 ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题.…...

营销材料翻译质量对销售渠道的影响
在当今的全球市场中,与不同受众进行有效沟通的能力对于企业的成功至关重要。营销材料的高质量翻译在通过销售渠道塑造客户旅程方面发挥着重要作用,影响着知名度、参与度、转化率和保留率。方法如下: 提高品牌知名度 在销售渠道的顶端&#x…...

centos7.9安装k8s 1.3
centos7.9安装k8s 1.3 k8s环境规划:初始化修改网卡配置两台服务器都执行 配置阿里yum源 安装containerd服务安装初始化k8s需要的软件包kubeadm初始化k8s集群 扩容k8s集群-添加第一个工作节点安装kubernetes网络组件-Calico测试在k8s创建pod是否可以正常访问网络和co…...

【第七节】python多线程及网络编程
目录 一、python多线程 1.1 多线程的作用 1.2 python中的 threading 模块 1.3 线程锁 二、python网络编程 2.1 通过socket访问网络 2.2 python2.x中的编码问题 2.3 python3的编码问题 一、python多线程 1.1 多线程的作用 多线程技术在计算机编程中扮演着重要的角色&a…...

Linux Shell编程--变量
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 变量: bash作为程序设计语言和其它高级语言一样也提供使用和定义变量的功能 预定义变量、环境变量、自定义变量、位置变量 一、自定义变…...

软文写作必须掌握的技巧有哪些?
现代互联网飞速发展的时代,硬广逐渐变的效果越来越差,而软文推广已经成为网络营销的重要组成部分了,一篇好的软文往往能为你的产品、网站带来意想不到的效果。 用于做营销的软文,我们不能像写普通文章那样随意。一篇优质的软文会让…...

探索灵办AI:智能办公的好帮手
引言 随着AI工具的增多,选择合适的AI助手变得尤为重要。ChatGPT的订阅费用高且功能单一,很多小伙伴开始寻找更具性价比和多功能的替代品。灵办AI以其便捷、高效、多功能的特点,成为许多朋友的新宠。 灵办AI助手是一款多功能的全能AI助手&am…...

gin-vue-admin框架遇到AxiosError:Network Error怎么解决?
flipped-aurora/gin-vue-admin: 🚀ViteVue3Gin的开发基础平台,支持TS和JS混用。它集成了JWT鉴权、权限管理、动态路由、显隐可控组件、分页封装、多点登录拦截、资源权限、上传下载、代码生成器【可AI辅助】、表单生成器和可配置的导入导出等开发必备功能…...

作业zzz
【考查点】 考查SpringBoot相关的知识点,包括:依赖注入(DI)、面向切面编程(AOP),以及常用的SpringBoot组件。 【作业要求】 利用spring-boot-starter-web来搭建一个web服务。完成简单的用户管…...

公众号流量分成大涨!后公众号时代如何运营?流量商店旗下的互粉平台成增粉利器!
“上个月流量主收入终于突破5000元了!”深夜,运营“职场进化论”公众号的小林在朋友圈晒出后台截图。一年前,这个只有几百粉丝的账号月收入还不到100元。而如今,像小林这样依靠公众号流量分成实现可观收入的创作者正越来越多。 20…...
)
保姆级教程:用Python复现DMP动态运动基元,手把手验证收敛性(附完整代码)
从零实现DMP动态运动基元:Python代码实战与收敛性可视化分析 在机器人运动控制领域,动态运动基元(Dynamic Movement Primitives, DMP)因其出色的轨迹生成能力和稳定的收敛特性,已成为模仿学习的核心算法之一。本文将带您用Python完整实现DMP…...

微信群自动回复机器人
在微信生态中,企业每天都在重复做同一件事:加好友、发消息、维护社群。 看似简单,却持续消耗团队精力,一旦规模扩大,效率下降、操作失误、管理混乱等问题也随之放大,成为增长的隐形瓶颈。 真正的问题不在于…...

YOLOE开源镜像生产环境部署:YOLOE-v8m-seg在Docker Swarm集群实践
YOLOE开源镜像生产环境部署:YOLOE-v8m-seg在Docker Swarm集群实践 1. 引言:从单机到集群的跨越 如果你已经体验过YOLOE官版镜像在单台服务器上的强大能力,比如用文本描述就能识别图片里的任何物体,或者用一张示例图就能完成精准…...

大模型训练实战:分布式训练、显存优化与知识蒸馏全解析!
全景路线图: 我们将按模块逐步展开,每个模块都是最终搭建完整平台的一块拼图:之前的章节参考我之前写的文章;G. 分布式训练篇:大模型训练的工程实践 – 学习在多卡多机环境下训练大模型的方法,包括数据并行…...

evo实战:A-LOAM在KITTI数据集上的多维度性能剖析
1. 从KITTI到ROS:数据格式转换实战 第一次接触KITTI数据集时,我被它那庞大的.bin点云文件搞得一头雾水。作为一个常年和ROS打交道的工程师,我深知bag格式才是SLAM算法的"通用语言"。这里分享一个我验证过的高效转换方案——使用lid…...

PyTorch 3.0静态图分布式训练落地实录:从模型编译失败到千卡吞吐提升3.8倍,我踩过的11个致命坑
第一章:PyTorch 3.0静态图分布式训练落地实录:从模型编译失败到千卡吞吐提升3.8倍在 PyTorch 3.0 正式引入 torch.compile() 与 torch.distributed._composable 协同优化的静态图分布式训练范式后,我们于千卡规模集群(A100-80GB …...

万象熔炉 | Anything XL参数详解:EulerAncestralDiscreteScheduler原理浅析
万象熔炉 | Anything XL参数详解:EulerAncestralDiscreteScheduler原理浅析 如果你用过Stable Diffusion这类AI绘画工具,可能对“调度器”这个词有点陌生,但一定感受过它的影响。比如,为什么有的模型生成图片又快又好,…...

云凝结合计数器CNN粒子数浓度分析/python数据可视化
CCN-100是美国DMT公司(Drop Measurement Technologies)生产的一款经典仪器,专用于连续、实时测量大气中不同过饱和度下的CCN数浓度。它采用热梯度云室(Thermal Gradient Cloud Chamber)技术,模拟自然界中云…...
Matlab程序)
改进无人机三维路径规划(蜣螂优化算法)Matlab程序
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。👇 关注我领取海量matlab电子书和数学建模资料🍊个人信条:格物致知,完整Matl…...