计算机毕业设计hadoop+spark+hive漫画推荐系统 动漫视频推荐系统 漫画分析可视化大屏 漫画爬虫 漫画推荐系统 漫画爬虫 知识图谱 大数据
Hadoop+Spark+Hive漫画推荐系统详细开题报告
一、引言
随着互联网技术的飞速发展,动漫和漫画产业的数据量急剧增长。用户面临着海量漫画作品的选择难题,如何从这些数据中高效地提取有价值的信息,为用户推荐符合其喜好的漫画作品,成为了当前漫画产业亟需解决的问题。基于Hadoop、Spark和Hive的大数据处理技术,本文旨在设计一个高效的漫画推荐系统,以提升用户体验,推动漫画产业的可持续发展。
二、研究背景与意义
2.1 研究背景
近年来,随着大数据技术的普及和应用,其在各个领域均展现出强大的数据处理和分析能力。在漫画产业中,传统的数据分析方法已难以满足大规模数据的处理需求。Hadoop、Spark和Hive作为大数据处理领域的代表性技术,具有高效、可扩展、容错性强等特点,能够有效地处理海量数据,为漫画推荐系统提供坚实的技术支撑。
2.2 研究意义
- 提升推荐准确性:利用大数据处理技术,对海量漫画数据进行深入分析,建立更加精准的推荐模型,提高推荐系统的准确性。
- 优化用户体验:通过推荐系统,帮助用户快速找到符合其喜好的漫画作品,提升用户满意度和粘性。
- 推动产业发展:为漫画产业提供全面的数据支持,助力产业创新和发展。
三、研究内容与方法
3.1 研究内容
- 数据采集:利用Python爬虫技术(如Selenium、Scrapy等)从各大漫画平台采集漫画数据,包括漫画标题、作者、类型、标签、评论、评分等信息。
- 数据预处理:对采集到的数据进行清洗、去重、格式化等预处理操作,为后续分析提供高质量的数据基础。
- 数据存储:利用Hadoop HDFS进行数据存储,确保数据的可靠性和可扩展性。
- 数据分析:使用Hive进行数据仓库建设,通过SQL查询和Spark进行数据分析,提取用户行为特征和漫画属性特征。
- 推荐模型构建:基于用户行为数据和漫画属性数据,构建推荐模型,实现个性化推荐。
- 可视化展示:利用Flask+ECharts搭建可视化大屏,展示推荐结果和用户行为分析数据。
3.2 研究方法
- 文献综述法:通过查阅国内外相关文献,了解大数据处理技术和推荐系统的研究现状和发展趋势。
- 实验法:设计并实施一系列实验,验证Hadoop、Spark和Hive在漫画推荐系统中的应用效果。
- 案例分析法:选取典型漫画平台作为案例,分析其用户行为数据和漫画属性数据,验证推荐模型的准确性和有效性。
四、预期目标与创新点
4.1 预期目标
- 采集并存储海量漫画数据,构建全面的漫画数据仓库。
- 实现基于Hadoop、Spark和Hive的漫画推荐系统,提高推荐准确性。
- 搭建可视化大屏,展示推荐结果和用户行为分析数据。
4.2 创新点
- 离线与实时结合:利用Hive进行离线分析,Spark进行实时分析,实现数据的快速响应和动态更新。
- 多源数据融合:融合用户行为数据和漫画属性数据,构建更加全面的推荐模型。
- 可视化大屏展示:通过可视化大屏,直观展示推荐结果和用户行为分析数据,提升用户体验。
五、研究计划与进度安排
5.1 研究计划
- 第一阶段(1-3周):完成开题报告、文献综述和需求分析,确定研究方案和技术路线。
- 第二阶段(4-6周):实现数据采集和预处理模块,完成数据存储和仓库建设。
- 第三阶段(7-10周):进行数据分析,构建推荐模型,并进行初步测试。
- 第四阶段(11-13周):搭建可视化大屏,实现推荐结果的展示和用户行为分析数据的可视化。
- 第五阶段(14-16周):完成系统测试和优化,撰写毕业论文。
5.2 进度安排
- 第1周:完成开题报告撰写和提交。
- 第2-3周:进行文献综述和需求分析,确定技术路线。
- 第4-6周:实现数据采集和预处理模块,完成数据存储。
- 第7-9周:进行数据分析,构建推荐模型。
- 第10-12周:搭建可视化大屏,实现推荐结果展示。
- 第13-16周:系统测试和优化,撰写毕业论文。
六、参考文献
(此处省略具体参考文献,实际撰写时应详细列出所有引用的文献)
七、总结
本文旨在设计并实现一个基于Hadoop、Spark和Hive的漫画推荐系统






































相关文章:
计算机毕业设计hadoop+spark+hive漫画推荐系统 动漫视频推荐系统 漫画分析可视化大屏 漫画爬虫 漫画推荐系统 漫画爬虫 知识图谱 大数据
HadoopSparkHive漫画推荐系统详细开题报告 一、引言 随着互联网技术的飞速发展,动漫和漫画产业的数据量急剧增长。用户面临着海量漫画作品的选择难题,如何从这些数据中高效地提取有价值的信息,为用户推荐符合其喜好的漫画作品,成…...

解决pycharm日志总是弹出“无法运行Git,未安装Git”的问题
需求分析 我电脑中安装了git,但是打开pycharm,右下角总是弹出 无法运行Git,未安装Git的日志。 解决方法 首先打开pycharm,按照以下路径,依次点击。 file -----settings-----version control -----Git----Git path(选择自己下载…...

threejs 节点材质系统 绑定attribute
新的 节点材质系统 绑定属性及使用 非常方便 不必重复声明 以instances为例 import {instancedBufferAttribute,instancedDynamicBufferAttribute,} from "three/tsl";声明一个 InstancedBufferAttribute 使用 instancedBufferAttribute包装后就可以在shader中直接使…...

Rabbitmq的几种工作模式
工具类 public class RabbitMQConnection {public static Connection getConnection() throws Exception{//1.创建connectionFactoryConnectionFactory connectionFactory new ConnectionFactory();//2.配置HostconnectionFactory.setHost("127.0.0.1");//3.设置Po…...

如何在 Debian 上安装运行极狐GitLab Runner?【二】
极狐GitLab 是 GitLab 在中国的发行版,专门面向中国程序员和企业提供企业级一体化 DevOps 平台,用来帮助用户实现需求管理、源代码托管、CI/CD、安全合规,而且所有的操作都是在一个平台上进行,省事省心省钱。可以一键安装极狐GitL…...

简单的docker学习 第13章 CI/CD与Jenkins(下)
第13章 CI/CD 与 Jenkins 13.13 自由风格的 CI 操作(最终架构) 前面的架构存在的问题是,若有多个目标服务器都需要使用该镜像,那么每个目标服务器都需要在本地构建镜像,形成系统资源浪费。若能够在 Jenkins 中将镜像相撞构建好并推送到 Har…...
(202))
基于STM32设计的智能鱼缸_带鱼儿数量视觉识别(华为云IOT)(202)
文章目录 一、前言1.1 项目介绍【1】项目功能介绍【2】设计实现的功能【3】项目硬件模块组成1.2 设计思路【1】整体设计思路【2】ESP8266工作模式配置【3】自动换水原理1.3 项目开发背景【1】选题的意义【2】可行性分析【3】参考文献1.4 开发工具的选择【1】设备端开发【2】上位…...

立体连接模式下的传播与沟通:AI智能名片小程序的创新应用与深度剖析
摘要:在数字化浪潮的推动下,信息传播与沟通方式正经历着前所未有的变革。立体连接模式,作为这一变革的重要产物,通过整合物理空间、虚拟网络空间与社群心理空间的三维联动,实现了信息的深度传播与高效互动。AI智能名片…...

基于Python的Scrapy爬虫的个性化书籍推荐系统【Django框架、超详细系统设计原型】
文章目录 有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主项目介绍系统分析系统设计展示总结 有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主 项目介绍 近年来,随着互联网的蓬勃发展,企事业单…...

二叉树bst
二叉搜索树的中序遍历结果有序 ,二叉搜索树性质,左小右大,二叉搜索树中序遍历的结果应该是从小到大的。 题目描述二叉树是从上到下,从左到右描述,并非前中后序中的一种。 99. 恢复二叉搜索树 class Solution:first …...

elasticsearch的使用(二)
DSL查询 Elasticsearch的查询可以分为两大类: 叶子查询(Leaf query clauses):一般是在特定的字段里查询特定值,属于简单查询,很少单独使用。 复合查询(Compound query clauses)&am…...

YOLOv8由pt文件中读取模型信息
Pytorch的pt模型文件中保存了许多模型信息,如模型结构、模型参数、任务类型、批次、数据集等 在先前的YOLOv8实验中,博主发现YOLOv8在预测时并不需要指定任务类型,因为这些信息便保存在pt模型中,那么,今天我们便来看看…...

js遍历效率
1w条数据,遍历效率 1、for 15s let t(new Date()).getTime()let a[]for(var i 0; i < 100000; i){a.push({id:i,val:i})}let ts[]for(var i 0; i < a.length; i){if(a[i].val!2 && a[i].val!4 && a[i].val!8){ts.push(a[i])}}let c(new D…...
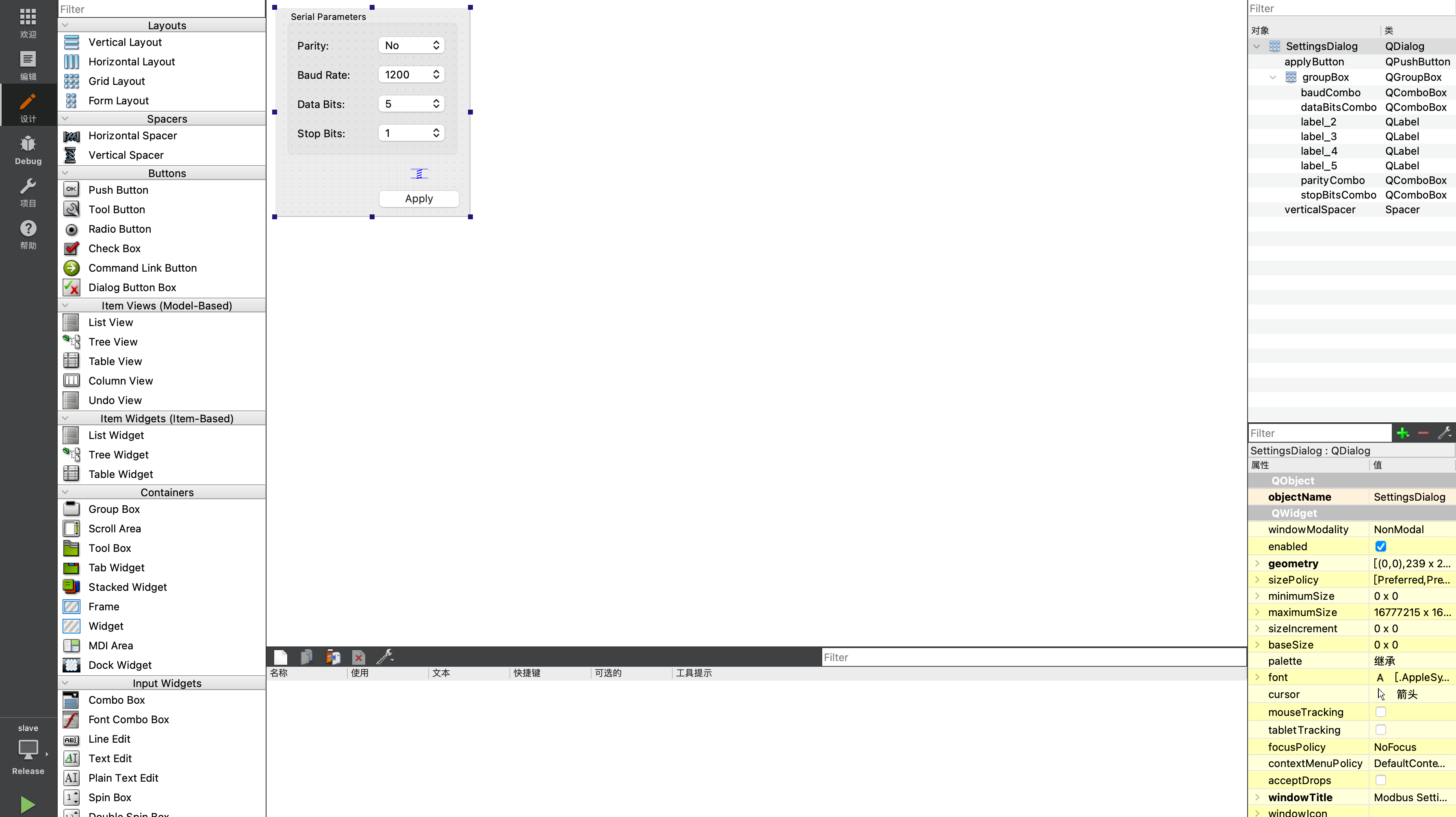
QModbus例程分析
由于有一个Modebus上位机的需要,分析一下QModbus Slave的源代码,方便后面的开发。 什么是Modbus Modbus是一种常用的串行通信协议,被广泛应用于工业自动化领域。它最初由Modicon(目前属于施耐德电气公司)于1979年开发…...

Vue万字学习笔记(入门1)
目录 简介 Vue是什么 渐进式框架 单文件组件 API 风格 选项式 API (Options API) 组合式 API (Composition API) 创建一个 Vue 应用 挂载应用 DOM 中的根组件模板 应用配置 多个应用实例 模板语法 文本插值 原始 HTML Attribute 绑定 简写…...

Cesium手动建模模型用Cesiumlab转3D Tiles模型位置不对,调整模型位置至指定经纬度
Cesium加载3Dtiles模型的平移和旋转_3dtiles先旋转再平移示例-CSDN博客 Cesium 平移cesiumlab生产的3Dtiles切片模型到目标经纬度-CSDN博客 【ArcGISCityEngine】自行制作Lod1城市大尺度白膜数据_cityengine 生成指定坐标集指定区域的白模-CSDN博客 以上次ArcGISCityEngine制…...

学习C语言第23天(程序环境和预处理)
1. 程序的翻译环境和执行环境 在ANSIC的任何一种实现中,存在两个不同的环境 第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令。 第2种是执行环境,它用于实际执行代码。 2. 详解编译链接 2.1 翻译环境 每个源文件单独经过编…...

Ubuntu22.04安装
使用Vmware安装好后 首先执行下面命令,不然每次打开终端会出现To run a command as administrator (user root)… touch ~/.sudo_as_admin_successful换源 参考 sudo cp /etc/apt/sources.list /etc/apt/sources.list.baksudo gedit /etc/apt/sources.list清空…...

从入门到自动化:一篇文章掌握Python的80%
Python作为一种高级编程语言,以其简洁明了的语法和强大的功能性,在全球编程社区内享有极高的声誉。本文将带领你从Python的基础语法入手,介绍其常用库的应用,以及如何将Python用于数据分析、网络爬虫和简单的自动化任务࿰…...

开源的主流机器学习框架
主流的开源机器学习框架包括: 1. TensorFlow:由Google开发和维护的深度学习框架,广泛用于生产环境和研究。支持多种平台,并具有丰富的工具和库支持。 2. PyTorch:由Facebook开发的深度学习框架,以其动态计…...

Linux内核中的cgroups技术详解
Linux内核中的cgroups技术详解 引言 cgroups(Control Groups)是Linux内核中用于限制、记录和隔离进程组资源使用的机制。它为容器技术、资源管理和服务质量保证提供了基础。cgroups允许管理员精细地控制系统资源的分配,确保关键任务获得足够的…...

Harness 中的事务边界定义:微事务与补偿
Harness 中的事务边界定义:微事务与补偿 引言 核心概念铺垫 在开始本文的核心内容——Harness 中的事务边界定义与微事务/补偿实践体系——之前,我们需要先锚定一组贯穿全文的、与 CI/CD 交付流水线强绑定的专属术语与业务通用术语的融合定义: 交付事务(Delivery Transac…...

如何永久保存微信聊天记录并挖掘数据价值?WeChatMsg全攻略
如何永久保存微信聊天记录并挖掘数据价值?WeChatMsg全攻略 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/W…...

C#基于S7.Net组件实现西门子PLC通信上位机功能说明
C#与西门子plc通讯上位机 c#软件 工控软件 1.该程可以实现CSharp与西门子全系列plc(200,200smart,300,1200,1500)的以太网s7通讯,通讯传输快稳定。 2.该程序采用s7以太网通讯方式,本人经过几个星期的测试&…...

OpenClaw配置优化指南:提升Phi-3-vision-128k长文本处理效率
OpenClaw配置优化指南:提升Phi-3-vision-128k长文本处理效率 1. 问题背景与挑战 上周我尝试用OpenClaw处理一份300页的图文混合技术文档时,遇到了典型的"长文本困境"——系统频繁卡顿,内存占用飙升到16GB,最终因响应超…...
)
别再只做静态分析了!用DPABI解锁小鼠脑功能动态连接(Temporal Dynamic Analysis详解)
从静态到动态:DPABI在小鼠脑功能时间动态分析中的进阶实践 在神经影像研究领域,静息态功能磁共振成像(rs-fMRI)已成为探索大脑功能组织的强大工具。传统分析方法多聚焦于静态功能连接,将整个扫描时段视为一个整体计算相关性。然而࿰…...

解锁专业显示控制:ColorControl让NVIDIA显卡和LG电视完美协作
解锁专业显示控制:ColorControl让NVIDIA显卡和LG电视完美协作 【免费下载链接】ColorControl Easily change NVIDIA display settings and/or control LG TVs 项目地址: https://gitcode.com/gh_mirrors/co/ColorControl 你是否曾为Windows系统显示设置的局限…...

DS4Windows终极指南:让PlayStation手柄在PC上释放全部潜能
DS4Windows终极指南:让PlayStation手柄在PC上释放全部潜能 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 当你兴奋地将PlayStation手柄连接到PC,却发现游戏无法识…...
)
Docker下XTDrone仿真平台搭建全攻略(ROS-Noetic版,含常见错误解决方案)
Docker下XTDrone仿真平台搭建全攻略(ROS-Noetic版) 在无人机开发领域,仿真测试是验证算法、降低硬件损耗的关键环节。XTDrone作为国内开发者广泛使用的开源仿真平台,结合ROS和Gazebo提供了完整的无人机仿真解决方案。本文将带你从…...

从JDBC到MyBatis:手把手调试源码,看一个`String`类型的`id`参数如何走完数据库查询与映射的全流程
从JDBC到MyBatis:手把手调试源码,看一个String类型的id参数如何走完数据库查询与映射的全流程 在Java持久层框架的演进历程中,MyBatis凭借其灵活的SQL控制能力和优雅的ORM映射机制,成为众多开发者处理复杂数据库操作的首选工具。…...