机器学习-决策树
决策树
- 决策树
- 1. 简介
- 2. ID3 决策树
- 3. C4.5决策树
- 4. CART决策树
- 5. 决策树对比
- 6. 正则化 剪枝
决策树
1. 简介
"""
简介一种树形结构树中每个内部节点表示一个特征的判断每个分支代表一个判断结果的输出每个叶节点代表一种分类结果建立过程1. 特征选择选取有较强分类能力的特征2. 决策树生成根据选择的特征生成决策树3. 决策树 易过拟合采用剪枝的方法缓解过拟合
"""
2. ID3 决策树
"""
ID3 决策树熵 Entropy信息论中代表随机变量不确定度的度量熵越大 数据的不确定性越高 信息越多熵越小 数据的不确定性越低信息熵公式其中 P(xi) 表示数据中类别出现的概率,H(x) 表示信息的信息熵值信息增益概念特征a对训练数据集D的信息增益 定义为集合D的熵H(D)与特征a给定条件下D的熵(H|a)之差公式条件熵构建流程1. 计算每个特征的信息增益2. 使用信息增益最大特征将数据集 拆分为子集3. 使用该特征作为决策树的一个节点4. 使用剩余特征对子集重复上述 1 2 3 过程不足偏向于选择种类多的特征作为分裂依据
"""
信息熵 公式

信息增益 公式

3. C4.5决策树
"""
信息增益率信息增益率 = 信息增益 /特征熵特征熵本质特征的信息增益 除以 特征的内在信息相当于对信息增益进行修正, 增加一个惩罚系数特征取值个数较多时 惩罚系数较小, 特征取值个数较少时, 惩罚系数较大惩罚系数: 数据集D以特征a作为随机变量的熵的倒数
"""
信息增益率 公式

特征熵 公式

4. CART决策树
"""
CART决策树一种决策树模型, 可以用于分类 可以用于回归回归树: 使用平方误差最小化策略预测输出的是一个连续值采用叶子节点里均值作为预测输出分类生成树: 采用基尼指数最小化策略预测输出的是一个离散值采用叶子节点多数类别作为预测类别基尼值从数据集D中随机抽取两个样本,其类别标记不一致的概率Gini(D)值越小,数据集D的纯度越高基尼指数选择使划分后基尼系数最小的属性作为最优化分属性特殊说明信息增益(ID3)、信息增益率值越大(C4.5),则说明优先选择该特征基尼指数值越小(CART),则说明优先选择该特征"""
# 1.导入依赖包
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
from sklearn.tree import plot_treedef titanicCase():# 2.读数据到内存并预处理# 2.1 读取数据taitan_df = pd.read_csv("./data/titanic/train.csv")print(taitan_df.head()) # 查看前5条数据print(taitan_df.info) # 查看特性信息# 2.2 数据处理,确定x yx = taitan_df[['Pclass', 'Age', 'Sex']]y = taitan_df['Survived']# 2.3 缺失值处理x['Age'].fillna(x['Age'].mean(), inplace = True)print('x -->1', x.head(10))# 2.4 pclass类别型数据,需要转数值one-hot编码x = pd.get_dummies(x)print('x -->2', x.head(10))# 2.5 数据集划分x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.20, random_state=33)# 3.训练模型,实例化决策树模型estimator = DecisionTreeClassifier()estimator.fit(x_train, y_train)# 4.模型预测y_pred = estimator.predict(x_test)# 5.模型评估# 5.1 输出预测准确率myret = estimator.score(x_test, y_test)print('myret-->\n', myret)# 5.2 更加详细的分类性能myreport = classification_report(y_pred, y_test, target_names=['died', 'survived'])print('myreport-->\n', myreport)# 5.3 决策树可视化plot_tree(estimator,max_depth=10,filled=True,feature_names=['Pclass', 'Age', 'Sex_female', 'Sex_male'],class_names=['died', 'survived'])plt.show()
基尼值 公式

基尼指数公式

5. 决策树对比
"""
对比ID3信息增益1. ID3 只能对离散属性的数据集构成决策树2. 倾向于选择取值较多的属性C4.5信息增益率1. 缓解了ID3 分支过程中总喜欢偏向于选择值较多的属性2. 可处理连续数值型属性, 增加了对缺失值的处理方法3. 只适合于能够驻留于内存的数据集, 大数据集无能为力CART基尼指数1. 可以进行分类和回归 可处理离散属性, 也可以处理连续属性2. 采用基尼指数 计算 量减小3. 一定是二叉树构建过程1. 选择一个特征,将该特征的值进行排序, 取相邻点计算均值作为待划分点2. 根据所有划分点, 将数据集分成两部分, R1 R23. R1 和 R2 两部分的平方损失相加作为该切分点平方损失4. 取最小的平方损失的划分点, 作为当前特征的划分点5. 以此计算其他特征的最优划分点 以及该划分点对应的损失值6. 在所有的特征的划分点中, 选择出最小平方损失的划分点 作为当前树的分裂点"""
# 1.导入依赖包
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeRegressor # 回归决策树
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as pltdef contrastRegressor():"""线性回归与回归决策树对比:return:"""# 2.准备数据x = np.array(list(range(1, 11))).reshape(-1, 1)y = np.array([5.56, 5.70, 5.91, 6.40, 6.80, 7.05, 8.90, 8.70, 9.00, 9.05])print('x -->', x)print('y -->', y)# 3.模型训练,实例化模型model1 = DecisionTreeRegressor(max_depth=1)model2 = DecisionTreeRegressor(max_depth=3)model3 = LinearRegression()model1.fit(x, y)model2.fit(x, y)model3.fit(x, y)# 4.模型预测 # 等差数组-按照间隔x_test = np.arange(0.0, 10.0, 0.01).reshape(-1, 1)y_pre1 = model1.predict(x_test)y_pre2 = model2.predict(x_test)y_pre3 = model3.predict(x_test)print(y_pre1.shape, y_pre2.shape, y_pre3.shape)# 5.结果可视化plt.figure(figsize=(10, 6), dpi=100)plt.scatter(x, y, label='data')plt.plot(x_test, y_pre1, label='max_depth=1') # 深度1层plt.plot(x_test, y_pre2, label='max_depth=3') # 深度3层plt.plot(x_test, y_pre3, label='linear')plt.xlabel('data')plt.ylabel('target')plt.title('DecisionTreeRegressor')plt.legend()plt.show()
6. 正则化 剪枝
"""
正则化-剪枝预剪枝指在决策树生成过程中, 对每个节点在划分前先进行估计, 若当前节点的划分不能带来决策树泛化性能提升, 则停止划分并将当前节点标记为叶节点优点预剪枝使决策树很多分支没有展开, 降低了过拟合风险, 显著的减少了决策树的训练和测试时间的开销缺点有些分支的当前划分虽不能提升泛化性能, 单后续划分却有可能导致性能的显著提高, 预剪枝决策时有欠拟合的风险后剪枝是先从训练集生成一颗完整的决策树, 然后自底向上地对非叶节点进行考察, 若将该节点对应的子树替换为叶节点能带来决策树泛化性能提升, 则将该子树替换为叶节点优点比预剪枝保留了更多的分支, 一般情况下, 后剪枝决策树的欠拟合风险很小, 泛化性能往往优于预剪枝缺点训练时间开销比未剪枝的决策树和预剪枝的决策树都长的多"""
相关文章:
机器学习-决策树
决策树 决策树1. 简介2. ID3 决策树3. C4.5决策树4. CART决策树5. 决策树对比6. 正则化 剪枝 决策树 1. 简介 """ 简介一种树形结构树中每个内部节点表示一个特征的判断每个分支代表一个判断结果的输出每个叶节点代表一种分类结果建立过程1. 特征选择选取有较…...

opencascade TopoDS_Shape源码学习【重中之重】
opencascade TopoDS_Shape 前言 描述了一个形状,它 引用了一个基础形状,该基础形状有可能被赋予一个位置和方向 为基础形状提供了一个位置,定义了它在本地坐标系中的位置为基础形状提供了一个方向,这是从几何学的角度ÿ…...

Self-study Python Fish-C Note15 P52to53
函数 (part 5) 本节主要讲函数文档、类型注释、内省、高阶函数 函数文档、类型注释、内省 (P52) 函数文档 函数是一种代码封装的方法,对于一个程序来说,函数就是一个结构组件。在函数的外部是不需要关心函数内部的执行细节的,更需要关注的…...

Java小白入门到实战应用教程-异常处理
Java小白入门到实战应用教程-异常处理 前言 我们这一章节进入到异常处理知识点的学习。异常是指程序在运行时遇到的一种特殊情况,它能打断了正常的程序执行流程。 而异常处理是一项至关重要的技术,它使得程序能够优雅地处理运行时错误,避免…...

使用Anaconda安装多个版本的Python并与Pycharm进行对接
1、参考链接 Anaconda安装使用教程解决多Python版本问题_anaconda安装多个python版本-CSDN博客 基于上面的一篇博客的提示,我做了尝试。并在Pycharm的对接上做了拓展。 2、首先安装Anaconda 这个比较简单,直接安装即可: 3、设置conda.exe的…...

android系统中data下的xml乱码无法查看问题剖析及解决方法
背景: Android12高版本以后系统生成的很多data路径下的xml都变成了二进制类型,根本没办法看xml的内容具体如下: 比如想要看当前系统的widget的相关数据 ./system/users/0/appwidgets.xml 以前老版本都是可以直接看的,这些syste…...
创建索引(2)使用 CREATE INDEX 语句在已经存在的表上创建索引)
MySQL——索引(三)创建索引(2)使用 CREATE INDEX 语句在已经存在的表上创建索引
若想在一个已经存在的表上创建索引,可以使用 CREATE INDEX.语句,CREATEINDEX语句创建索引的具体语法格式如下所示: CREATE [UNIQUEIFULLTEXTISPATIAL]INDEX 索引名 ON 表名(字段名[(长度)J[ASCIDESC]); 在上述语法格式中,UNIQUE、FULLTEXT 和…...

html+css 实现hover选择按钮
前言:哈喽,大家好,今天给大家分享htmlcss 绚丽效果!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目…...

Python数据可视化利器:Matplotlib详解
目录 Matplotlib简介安装MatplotlibMatplotlib基本用法 简单绘图子图和布局图形定制 常见图表类型 折线图柱状图散点图直方图饼图 高级图表和功能 3D绘图热图极坐标图 交互和动画与其他库的集成 与Pandas集成与Seaborn集成 常见问题与解决方案总结 Matplotlib简介 Matplotli…...

2024 NVIDIA开发者社区夏令营环境配置指南(Win Mac)
2024 NVIDIA开发者社区夏令营环境配置指南(Win & Mac) 1 创建Python环境 首先需要安装Miniconda: 大家可以根据自己的网络情况从下面的地址下载: miniconda官网地址:https://docs.conda.io/en/latest/miniconda.html 清华大学镜像地…...

介绍rabbitMQ
RabbitMQ是一个开源的消息代理软件,实现了高级消息队列协议(AMQP),主要用于在不同的应用程序之间进行异步通信。以下是关于RabbitMQ的详细介绍: 一、基本概念 消息中间件:RabbitMQ是一个消息中间件&#x…...

AI在医学领域:使用眼底图像和基线屈光数据来定量预测近视
关键词:深度学习、近视预测、早期干预、屈光数据 儿童近视已经成为一个全球性的重大健康议题。其发病率持续攀升,且有可能演变成严重且不可逆转的状况,这不仅对家庭幸福构成威胁,还带来巨大的经济负担。当前的研究着重指出&#x…...
进行图形界面开发)
VB.NET中如何利用WPF(Windows Presentation Foundation)进行图形界面开发
在VB.NET中,利用Windows Presentation Foundation (WPF) 进行图形界面开发是一个强大的选择,因为它提供了丰富的UI元素、动画、数据绑定以及样式和模板等高级功能。以下是在VB.NET项目中使用WPF进行图形界面开发的基本步骤: 1. 创建一个新的…...

Go语言标准库中的双向链表的基本用法
什么是二分查找区间? 什么是链表? 链表节点的代码实现: 链表的遍历: 链表如何插入元素? go语言标准库的链表: 练习代码: package mainimport ("container/list""fm…...
手机游戏录屏软件哪个好,3款软件搞定游戏录屏
在智能手机普及的今天,越来越多的人喜欢在手机上玩游戏,并希望能够录制游戏过程或者分享游戏技巧。然而,面对市面上众多的手机游戏录屏软件,很多人可能会陷入选择困难。究竟手机游戏录屏软件哪个好?在这篇文章中&#…...

【力扣】4.寻找两个正序数组的中位数
题目描述 给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。 算法的时间复杂度应该为 O(log (mn)) 。 示例 1: 输入:nums1 [1,3], nums2 [2] 输出:2.0…...

【C++】初识面向对象:类与对象详解
C语法相关知识点可以通过点击以下链接进行学习一起加油!命名空间缺省参数与函数重载C相关特性 本章将介绍C中一个重要的概念——类。通过类,我们可以类中定义成员变量和成员函数,实现模块化封装,从而构建更加抽象和复杂的工程。 &…...
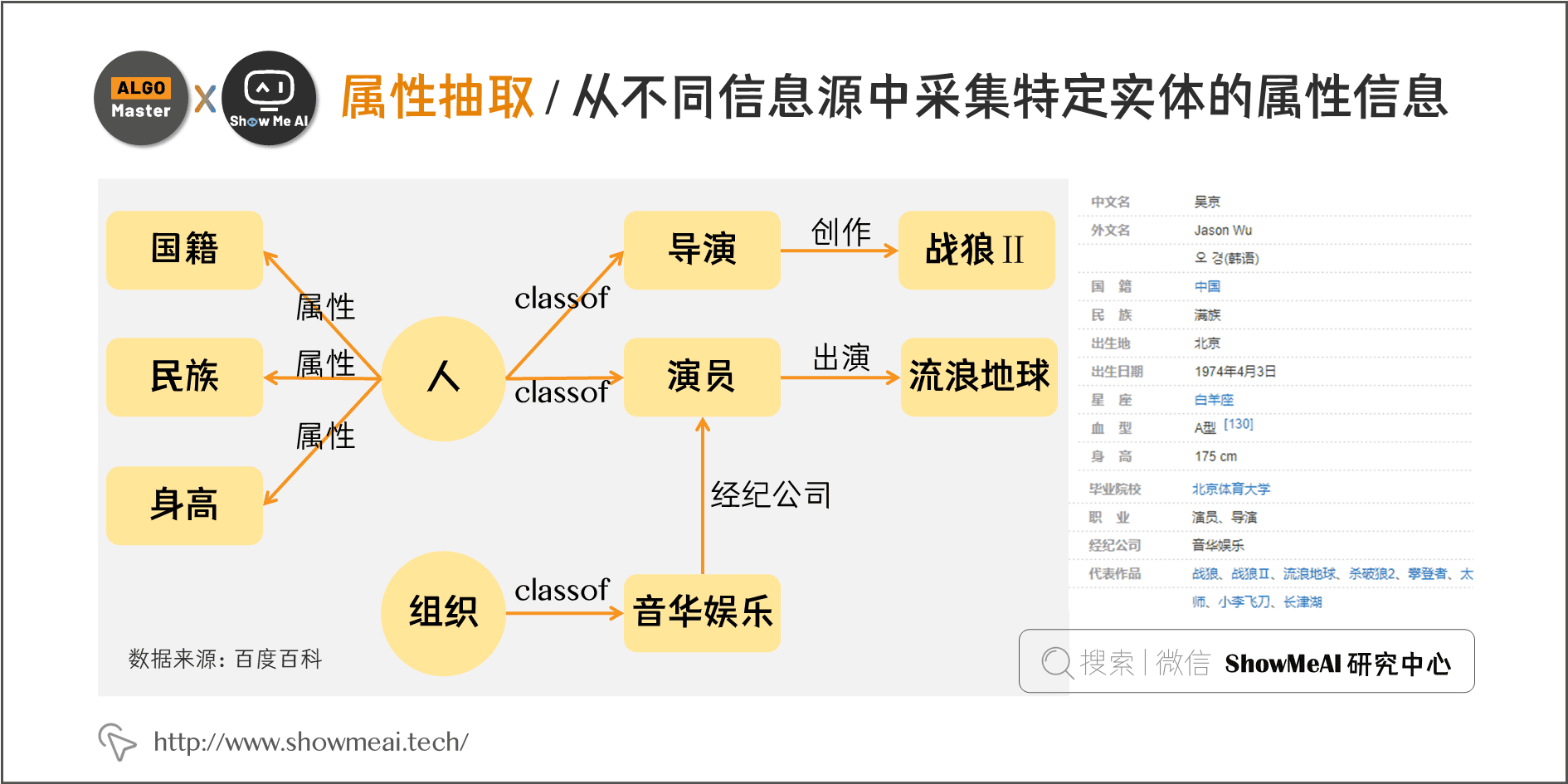
知识图谱学习总结
1 知识图谱的介绍 知识图谱,是结构化的语义知识库,用于迅速描述物理世界中的概念及其相互关系,通过知识图谱能够将Web上的信息、数据以及链接关系聚集为知识,使信息资源更易于计算、理解以及评价,并能实现知识的快速响…...

2021-10-23 51单片机LED1-8按秒递增闪烁
缘由51单片机,八个LED灯按LED1亮1s灭1s,LED1亮2s 灭2s以此类推的方式亮灭-编程语言-CSDN问答 #include "REG52.h" sbit K1 P1^0; sbit K2 P1^1; sbit K3 P1^2; sbit K4 P1^3; sbit P1_0P2^0; sbit P1_1P2^1; sbit P1_2P2^2; sbit P1_3P2^3; sbit P1_…...

在Linux中宏观的看待线程
线程一旦被创建,几乎所有的资源都是被所有的线程共享的。线程也一定要有自己私有的资源,什么样的资源应该是线程私有的? 1.PCB属性私有 2.要有一定的私有上下文结构 3.每个线程都要有独立的栈结构 ps -aL ##1. Linux线程概念 ###什么是线程…...

用pnpm安装一个软件显示包找不到的问题解决
问题总览 您遇到的是**pnpm环境缺失与目标包mmem0ai无法从npm registry获取**的双重问题,具体表现为两条错误链: sudo pnpm add mmem0ai → sudo: pnpm: command not found(sudo环境下未识别pnpm命令);直接运行pnpm ad…...

从服务器被黑到主动防御:fail2ban实战部署与多服务防护策略
1. 从一次真实的服务器入侵说起 去年夏天的一个凌晨,我被手机警报声惊醒——自建服务器的CPU占用率飙升至100%。登录管理界面后,发现有个名为kworker的进程持续消耗资源。经过排查,在/tmp目录下发现了伪装成系统文件的挖矿程序,攻…...
)
Mamba实战:如何用选择性状态空间模型提升你的长序列处理效率(附代码)
Mamba实战:如何用选择性状态空间模型提升你的长序列处理效率(附代码) 在自然语言处理、基因组学和金融时间序列分析等领域,处理长序列数据一直是个棘手的问题。传统Transformer架构虽然强大,但随着序列长度增加&#x…...

【从0开始学设计模式-6| 原型模式】
一个月没更新了,在找实习。。 其实还是懒了,其实每天花个半小时左右就能写一篇博客的。。。概念 原型模式(Prototype Pattern) 设计出来的目标就是:通过本体复制出与本体一样的分身(分身具有本体一样特性)定义…...

Phi-4-reasoning-vision-15B实操手册:强约束提示词设计与错误行为规避
Phi-4-reasoning-vision-15B实操手册:强约束提示词设计与错误行为规避 1. 引言:当视觉模型“自作主张”时,我们该怎么办? 你上传了一张软件界面的截图,想问问某个按钮是干什么用的。结果模型没回答你的问题ÿ…...

OpenClaw配置备份指南:gemma-3-12b-it模型迁移与快速恢复
OpenClaw配置备份指南:gemma-3-12b-it模型迁移与快速恢复 1. 为什么需要备份OpenClaw配置? 上周我的主力开发机突然硬盘故障,导致精心调校的OpenClaw配置全部丢失。整整两天时间,我都在重新配置模型参数、飞书通道和自定义技能—…...

在 AMD Ryzen AI 7 H350 Radeon 860M 上使用 Ollama 运行 GPU 加速
本文介绍了如何在搭载 AMD Ryzen AI 7 H350 及 Radeon 860M 显卡的系统上,配置 Ollama 以利用 GPU 运行 AI 模型。 一、安装 AMD 驱动程序 首先,请安装最新的 AMD 驱动程序,以确保系统能够正确识别并调用显卡硬件。 驱动程序下载地址&…...

EZModbus:面向ESP32的异步无锁Modbus C++库
1. EZModbus项目概述EZModbus是一个专为ESP32平台设计的C Modbus通信库,深度集成FreeRTOS实时操作系统,支持Arduino IDE与原生ESP-IDF两种开发框架。该库并非对现有Modbus协议栈的简单封装,而是从零构建的异步事件驱动型实现,其核…...

OpenClaw本地知识库构建:Qwen2.5-VL-7B处理扫描版PDF与图片资料
OpenClaw本地知识库构建:Qwen2.5-VL-7B处理扫描版PDF与图片资料 1. 为什么选择OpenClaw搭建个人知识管理系统 去年搬家时,我翻出了三大箱纸质资料——从学生时代的课堂笔记到工作后的技术手册,全都堆在角落积灰。这些资料里藏着不少珍贵内容…...

新手入门指南:基于快马生成代码学习注册表单开发与验证
新手入门指南:基于快马生成代码学习注册表单开发与验证 作为一个前端新手,我最近在学习如何开发一个完整的注册表单页面。正好用InsCode(快马)平台尝试实现了一个谷歌风格的账号注册页面,整个过程收获很大,下面分享我的学习心得。…...