django学习-数据表操作
一、数据表操作
1. 数据新增
由模型实例化对象调用内置方法实现数据新增,比如单数据新增调用create,查询与新增调用get_or_create,修改与新增调用update_or_create,批量新增调用bulk_create。
1.1 create()
# 方法一
# 使用create方法实现数据插入
Vocation.objects.create(job='测试工程师',title='系统测试',
payment=0,name_id=3)# 方法二
# 同样使用create方法,但数据以字典格式表示
d=dict(job='测试工程师',title='系统测试',payment=0,name_id=3)
Vocation.objects.create(**d)# 方法三
# 在实例化时直接设置属性值
v=Vocation(job='测试工程师',title='系统测试',payment=0,name_id=3)
v.save()
注意:
执行数据插入时,为了保证数据的有效性,我们需要对数据进行去重判断,确保数据不会重复插入。以往的方案都是对数据表进行查询操作,如果查询的数据不存在,就执行数据插入操作。
1.2 get_or_create()
get_or_create根据每个模型字段的值与数据表的数据进行判断,判断方式如下:
- 只要有一个模型字段的值与数据表的数据不相同(除主键之外),就会执行数据插入操作。
- 如果每个模型字段的值与数据表的某行数据完全相同,就不执行数据插入,而是返回这行数据的数据对象。
d=dict(job='测试工程师',title='系统测试',payment=10,name_id=3)
Vocation.objects.get_or_create(**d)
1.3 update_or_create()
update_or_create方法判断当前数据在数据表里是否存在,若存在,则进行更新操作,否则在数据表里新增数据。
# 第一次是新增数据
d=dict(job='软件工程师',title='Java开发',name_id=2,payment=8000)
v=Vocation.objects.update_or_create(**d)
# 第二次是修改数据
v=Vocation.objects.update_or_create(**d,defaults={'title': 'Java'})
1.4 bulk_create()
如果要对某个模型执行数据批量插入操作,那么可以使用bulk_create方法实现,只需将数据对象以列表或元组的形式传入bulk_create方法即可。
v1=Vocation(job='财务',title='会计',payment=0,name_id=1)
v2=Vocation(job='财务',title='出纳',payment=0,name_id=1)
ojb_list = [v1, v2]
Vocation.objects.bulk_create(ojb_list)
2. 数据修改
数据修改必须执行一次数据查询,再对查询结果进行修改操作,常用方法有:模型实例化、update方法和批量更新bulk_update。
2.1 模型实例化
v = Vocation.objects.get(id=1)
v.payment = 20000
v.save()
2.2 update()
# 批量更新一条或多条数据,查询方法使用filter
# filter以列表格式返回,查询结果可能是一条或多条数据
Vocation.objects.filter(job='测试工程师').update(job='测试员')
# 更新数据以字典格式表示
d= dict(job='测试员')
Vocation.objects.filter(job='测试工程师').update(**d)
# 不使用查询方法,默认对全表的数据进行更新
Vocation.objects.update(payment=6666)
# 使用内置F方法实现数据的自增或自减
# F方法还可以在annotate或filter方法里使用
from django.db.models import F
v=Vocation.objects.filter(job='测试工程师')
# 将payment字段原有的数据自增加一
v.update(payment=F('payment')+1)
2.3 bulk_create()
# 新增两行数据
v1=Vocation.objects.create(job='财务',title='会计',name_id=1)
v2=Vocation.objects.create(job='财务',title='出纳',name_id=1)
# 修改字段payment和title的数据
v1.payment=1000
v2.title='行政'
# 批量修改字段payment和title的数据
Vocation.objects.bulk_update([v1,v2],fields=['payment','title'])
3. 数据删除
数据删除必须执行一次数据查询,再对查询结果进行删除操作,若删除的数据设有外键字段,则删除结果由外键的删除模式决定。
数据删除有3种方式:删除数据表的全部数据、删除一行数据和删除多行数据,实现方式如下:
# 删除数据表中的全部数据
Vocation.objects.all().delete()
# 删除一条id为1的数据
Vocation.objects.get(id=1).delete()
# 删除多条数据
Vocation.objects.filter(job='测试员').delete()
外键删除模式说明:
- PROTECT模式:如果删除的数据设有外键字段并且关联其他数据表的数据,就提示数据删除失败。
- SET_NULL模式:执行数据删除并把其他数据表的外键字段设为Null,外键字段必须将属性Null设为True,否则提示异常。
- SET_DEFAULT模式:执行数据删除并把其他数据表的外键字段设为默认值。
- SET模式:执行数据删除并把其他数据表的外键字段关联其他数据。
- DO_NOTHING模式:不做任何处理,删除结果由数据库的删除模式决定。
- CASCADE模式:执行数据删除时会删除所有依赖于这条记录的从表中的相关记录,更新时也会更新所有从表中的记录。
4. 数据查询
数据查询分为单表查询和多表查询,Django提供多种不同查询的API方法,以满足开发需求。
4.1 单表查询
# SQL:Select * from index_vocation,数据以列表返回
v = Vocation.objects.all()
# 查询第一条数据,序列从0开始
v[0].job
# 查询前3条数据
# SQL:Select * from index_vocation LIMIT 3
# SQL语句的LIMIT方法,在Django中使用列表截取即可
v = Vocation.objects.all()[:3]
# 查询某个字段
# SQL:Select job from index_vocation
# values方法,数据以列表返回,列表元素以字典表示
v = Vocation.objects.values('job')
v[1]['job']
# values_list方法,数据以列表返回,列表元素以元组表示
v = Vocation.objects.values_list('job')[:3]
# 使用get方法查询数据
# SQL:Select*from index_vocation where id=2
v = Vocation.objects.get(id=2)
# 使用filter方法查询数据,注意区分get和filter的差异
v = Vocation.objects.filter(id=2)
v[0].job
# SQL的and查询主要在filter里面添加多个查询条件
v = Vocation.objects.filter(job='网站设计', id=3)
#filter的查询条件可设为字典格式
d=dict(job='网站设计', id=3)
v = Vocation.objects.filter(**d)
# SQL的or查询,需要引入Q,编写格式:Q(field=value)|Q(field=value)
#多个Q之间使用“|”隔开即可
# SQL:Select * from index_vocation where job='网站设计' or id=9
from django.db.models import Q
v = Vocation.objects.filter(Q(job='网站设计')|Q(id=4))
# SQL的不等于查询,在Q查询前面使用“~”即可
# SQL语句:SELECT * FROM index_vocation WHERE NOT (job='网站设计')
v = Vocation.objects.filter(~Q(job='网站设计'))
#还可以使用exclude实现不等于查询
v = Vocation.objects.exclude(job='网站设计')
# 使用count方法统计查询数据的数据量
v = Vocation.objects.filter(job='网站设计').count()
# 去重查询,distinct方法无须设置参数,去重方式根据values设置的字段执行
# SQL:Select DISTINCT job from index_vocation where job = '网站设计'
v = Vocation.objects.values('job').filter(job='网站设计').distinct()
# 根据字段id降序排列,降序只要在order_by里面的字段前面加"-"即可
# order_by可设置多字段排列,如Vocation.objects.order_by('-id', 'job')
v = Vocation.objects.order_by('-id')
# 聚合查询,实现对数据值求和、求平均值等。由annotate和aggregate方法实现
# annotate类似于SQL里面的GROUP BY方法
#如果不设置values,默认对主键进行GROUP BY分组
# SQL:Select job,SUM(id) AS 'id__sum' from index_vocation GROUP BY job
from django.db.models import Sum, Count
v = Vocation.objects.values('job').annotate(Sum('id'))
# aggregate是计算某个字段的值并只返回计算结果
# SQL:Select COUNT(id) AS 'id_count' from index_vocation
from django.db.models import Count
v = Vocation.objects.aggregate(id_count=Count('id'))
# union、intersection和difference语法
# 每次查询结果的字段必须相同
# 第一次查询结果v1
v1 = Vocation.objects.filter(payment__gt=9000)
# 第二次查询结果v2
v2 = Vocation.objects.filter(payment__gt=5000)
# 使用SQL的UNION来组合两个或多个查询结果的并集
# 获取两次查询结果的并集
v1.union(v2)
# 使用SQL的INTERSECT来获取两个或多个查询结果的交集
# 获取两次查询结果的交集
v1.intersection(v2)
# 使用SQL的EXCEPT来获取两个或多个查询结果的差
# 以v2为目标数据,去除v1和v2的共同数据
v2.difference(v1)
上述的查询条件filter和get是使用等值的方法来匹配结果。若想使用大于、不等于或模糊查询的匹配方法,则可在查询条件filter和get里使用下面所示的匹配符实现。
- 精确匹配:
Author.objects.filter(name__exact='John Doe') - 模糊匹配:
Author.objects.filter(name__iexact='john doe') - 不等于:
Author.objects.filter(name__ne='John Doe') - 包含:
Author.objects.filter(name__contains='John') - 不区分大小写的包含:
Author.objects.filter(name__icontains='john') - 正则表达式匹配:
Author.objects.filter(name__regex=r'^[A-Za-z]')
注意:
- 查询条件get:查询字段必须是主键或者唯一约束的字段,并且查询的数据必须存在,如果查询的字段有重复值或者查询的数据不存在,程序就会抛出异常信息。
- 查询条件filter:查询字段没有限制,只要该字段是数据表的某一字段即可。查询结果以列表形式返回,如果查询结果为空(查询的数据在数据表中找不到),就返回空列表。
4.2 多表查询
在日常的开发中,常常需要对多张数据表同时进行数据查询。多表查询需要在数据表之间建立表关系才能够实现。一对多或一对一的表关系是通过外键实现关联的,而多表查询分为正向查询和反向查询。
# 正向查询
# 查询模型Vocation某行数据对象v
v = Vocation.objects.filter(id=1).first()
# v.name代表外键name
# 通过外键name去查询模型PersonInfo所对应的数据
v.name.hireDate
# 反向查询
# 查询模型PersonInfo某行数据对象p
p = PersonInfo.objects.filter(id=2).first()
# 方法一
# vocation_set的返回值为queryset对象,即查询结果
# vocation_set的vocation为模型Vocation的名称小写
# 模型Vocation的外键字段name不能设置参数related_name
# 若设置参数related_name,则无法使用vocation_set
v = p.vocation_set.first()
v.job
# 方法二
# 由模型Vocation的外键字段name的参数related_name实现
# 外键字段name必须设置参数related_name才有效,否则无法查询
# 将外键字段name的参数related_name设为personinfo
v = p.personinfo.first()
v.job
为了减少查询次数,提高查询效率,我们可以使用select_related或prefetch_related方法实现,该方法只需执行一次SQL查询就能实现多表查询。
select_related主要针对一对一和一对多关系进行优化,它是使用SQL的JOIN语句进行优化的,通过减少SQL查询的次数来进行优化和提高性能,其使用方法如下:
# select_related方法,参数为字符串格式
# 以模型PersonInfo为查询对象
# select_related使用LEFT OUTER JOIN方式查询两个数据表
# 查询模型PersonInfo的字段name和模型Vocation的字段payment
# select_related参数为personinfo,代表外键字段name的参数related_name
# 若要得到其他数据表的关联数据,则可用双下画线“__”连接字段名
# 双下画线“__”连接字段名必须是外键字段名或外键字段参数related_name
p=PersonInfo.objects.select_related('personinfo').
values('name','personinfo__payment')
# 查看SQL查询语句
print(p.query)
# 以模型Vocation为查询对象
# select_related使用INNER JOIN方式查询两个数据表
# select_related的参数为name,代表外键字段name
v=Vocation.objects.select_related('name').values('name','name__age')
# 查看SQL查询语句
print(v.query)
# 获取两个模型的数据,以模型Vocation的payment大于8000为查询条件
v=Vocation.objects.select_related('name').
filter(payment__gt=8000)
# 查看SQL查询语句
print(v.query)
# 获取查询结果集的首个元素的字段age的数据
# 通过外键字段name定位模型PersonInfo的字段age
v[0].name.age
6. 执行SQL语句
执行SQL语句有3种方法实现:extra、raw和execute,其中extra和raw只能实现数据查询,具有一定的局限性;而execute无须经过ORM框架处理,能够执行所有SQL语句,但很容易受到SQL注入攻击。
extra:结果集修改器,一种提供额外查询参数的机制。
extra适合用于ORM难以实现的查询条件,将查询条件使用原生SQL语法实现,此方法需要依靠模型对象,在某程度上可防止SQL注入
# 查询字段job等于‘网站设计’的数据
# params为where的%s提供数值
Vocation.objects.extra(where=["job=%s"],params=['网站设计'])
<QuerySet [<Vocation: 3>]>
# 新增查询字段seat,select_params为select的%s提供数值
=Vocation.objects.extra(select={"seat":"%s"},
select_params=['seatInfo'])
print(v.query)
# 连接数据表index_personinfo
v=Vocation.objects.extra(tables=['index_personinfo'])
print(v.query)
raw:执行原始SQL并返回模型实例对象。
raw的语法和extra所实现的功能是相同的,只能实现数据查询操作,并且也要依靠模型对象,但从使用角度来说,raw更为直观易懂。
v = Vocation.objects.raw('select * from index_vocation')
v[0]
<Vocation: 1>
execute:直接执行自定义SQL。
execute的语法,它执行SQL语句无须经过Django的ORM框架。我们知道Django连接数据库需要借助第三方模块实现连接过程,如MySQL的mysqlclient模块和SQLite的sqlite3模块等,这些模块连接数据库之后,可通过游标的方式来执行SQL语句,而execute就是使用这种方式执行SQL语句
from django.db import connection
cursor=connection.cursor()
# 执行SQL语句
cursor.execute('select * from index_vocation')
# 读取第一行数据
cursor.fetchone()
# 读取所有数据
cursor.fetchall()
execute能够执行所有的SQL语句,但很容易受到SQL注入攻击,一般情况下不建议使用这种方式实现数据操作。尽管如此,它能补全ORM框架所缺失的功能,如执行数据库的存储过程。
7. 数据库事务
数据库事务是指作为单个逻辑执行的一系列操作,这些操作具有原子性,即这些操作要么完全执行,要么完全不执行,常用于银行转账和火车票抢购等。
事务是指作为单个逻辑执行的一系列操作,这些操作具有原子性,即这些操作要么完全执行,要么完全不执行。事务处理可以确保事务性单元内的所有操作都成功完成,否则不会执行数据操作。
事务应该具有4个属性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),这4个属性通常称为ACID特性。
Django中通过使用 atomic() 装饰器或 transaction.atomic() 上下文管理器来包装需要事务处理的代码块。
- 使用 atomic() 装饰器:
from django.db import transaction@transaction.atomic
def view_func(request):# 在此函数内的数据库操作会被自动包装在事务中obj1 = MyModel.objects.create(field1='value1', field2='value2')obj2 = AnotherModel.objects.create(field='value')# 如果任何数据库操作失败,事务会回滚;否则会提交- 使用 transaction.atomic() 上下文管理器:
from django.db import transactiondef view_func(request):with transaction.atomic():# 在此块内的数据库操作会被包装在事务中obj1 = MyModel.objects.create(field1='value1', field2='value2')obj2 = AnotherModel.objects.create(field='value')# 如果任何数据库操作失败,事务会回滚;否则会提交相关文章:

django学习-数据表操作
一、数据表操作 1. 数据新增 由模型实例化对象调用内置方法实现数据新增,比如单数据新增调用create,查询与新增调用get_or_create,修改与新增调用update_or_create,批量新增调用bulk_create。 1.1 create() # 方法一 # 使用cr…...

机器学习-决策树
决策树 决策树1. 简介2. ID3 决策树3. C4.5决策树4. CART决策树5. 决策树对比6. 正则化 剪枝 决策树 1. 简介 """ 简介一种树形结构树中每个内部节点表示一个特征的判断每个分支代表一个判断结果的输出每个叶节点代表一种分类结果建立过程1. 特征选择选取有较…...

opencascade TopoDS_Shape源码学习【重中之重】
opencascade TopoDS_Shape 前言 描述了一个形状,它 引用了一个基础形状,该基础形状有可能被赋予一个位置和方向 为基础形状提供了一个位置,定义了它在本地坐标系中的位置为基础形状提供了一个方向,这是从几何学的角度ÿ…...

Self-study Python Fish-C Note15 P52to53
函数 (part 5) 本节主要讲函数文档、类型注释、内省、高阶函数 函数文档、类型注释、内省 (P52) 函数文档 函数是一种代码封装的方法,对于一个程序来说,函数就是一个结构组件。在函数的外部是不需要关心函数内部的执行细节的,更需要关注的…...

Java小白入门到实战应用教程-异常处理
Java小白入门到实战应用教程-异常处理 前言 我们这一章节进入到异常处理知识点的学习。异常是指程序在运行时遇到的一种特殊情况,它能打断了正常的程序执行流程。 而异常处理是一项至关重要的技术,它使得程序能够优雅地处理运行时错误,避免…...

使用Anaconda安装多个版本的Python并与Pycharm进行对接
1、参考链接 Anaconda安装使用教程解决多Python版本问题_anaconda安装多个python版本-CSDN博客 基于上面的一篇博客的提示,我做了尝试。并在Pycharm的对接上做了拓展。 2、首先安装Anaconda 这个比较简单,直接安装即可: 3、设置conda.exe的…...

android系统中data下的xml乱码无法查看问题剖析及解决方法
背景: Android12高版本以后系统生成的很多data路径下的xml都变成了二进制类型,根本没办法看xml的内容具体如下: 比如想要看当前系统的widget的相关数据 ./system/users/0/appwidgets.xml 以前老版本都是可以直接看的,这些syste…...
创建索引(2)使用 CREATE INDEX 语句在已经存在的表上创建索引)
MySQL——索引(三)创建索引(2)使用 CREATE INDEX 语句在已经存在的表上创建索引
若想在一个已经存在的表上创建索引,可以使用 CREATE INDEX.语句,CREATEINDEX语句创建索引的具体语法格式如下所示: CREATE [UNIQUEIFULLTEXTISPATIAL]INDEX 索引名 ON 表名(字段名[(长度)J[ASCIDESC]); 在上述语法格式中,UNIQUE、FULLTEXT 和…...

html+css 实现hover选择按钮
前言:哈喽,大家好,今天给大家分享htmlcss 绚丽效果!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目…...

Python数据可视化利器:Matplotlib详解
目录 Matplotlib简介安装MatplotlibMatplotlib基本用法 简单绘图子图和布局图形定制 常见图表类型 折线图柱状图散点图直方图饼图 高级图表和功能 3D绘图热图极坐标图 交互和动画与其他库的集成 与Pandas集成与Seaborn集成 常见问题与解决方案总结 Matplotlib简介 Matplotli…...

2024 NVIDIA开发者社区夏令营环境配置指南(Win Mac)
2024 NVIDIA开发者社区夏令营环境配置指南(Win & Mac) 1 创建Python环境 首先需要安装Miniconda: 大家可以根据自己的网络情况从下面的地址下载: miniconda官网地址:https://docs.conda.io/en/latest/miniconda.html 清华大学镜像地…...

介绍rabbitMQ
RabbitMQ是一个开源的消息代理软件,实现了高级消息队列协议(AMQP),主要用于在不同的应用程序之间进行异步通信。以下是关于RabbitMQ的详细介绍: 一、基本概念 消息中间件:RabbitMQ是一个消息中间件&#x…...

AI在医学领域:使用眼底图像和基线屈光数据来定量预测近视
关键词:深度学习、近视预测、早期干预、屈光数据 儿童近视已经成为一个全球性的重大健康议题。其发病率持续攀升,且有可能演变成严重且不可逆转的状况,这不仅对家庭幸福构成威胁,还带来巨大的经济负担。当前的研究着重指出&#x…...
进行图形界面开发)
VB.NET中如何利用WPF(Windows Presentation Foundation)进行图形界面开发
在VB.NET中,利用Windows Presentation Foundation (WPF) 进行图形界面开发是一个强大的选择,因为它提供了丰富的UI元素、动画、数据绑定以及样式和模板等高级功能。以下是在VB.NET项目中使用WPF进行图形界面开发的基本步骤: 1. 创建一个新的…...

Go语言标准库中的双向链表的基本用法
什么是二分查找区间? 什么是链表? 链表节点的代码实现: 链表的遍历: 链表如何插入元素? go语言标准库的链表: 练习代码: package mainimport ("container/list""fm…...
手机游戏录屏软件哪个好,3款软件搞定游戏录屏
在智能手机普及的今天,越来越多的人喜欢在手机上玩游戏,并希望能够录制游戏过程或者分享游戏技巧。然而,面对市面上众多的手机游戏录屏软件,很多人可能会陷入选择困难。究竟手机游戏录屏软件哪个好?在这篇文章中&#…...

【力扣】4.寻找两个正序数组的中位数
题目描述 给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。 算法的时间复杂度应该为 O(log (mn)) 。 示例 1: 输入:nums1 [1,3], nums2 [2] 输出:2.0…...

【C++】初识面向对象:类与对象详解
C语法相关知识点可以通过点击以下链接进行学习一起加油!命名空间缺省参数与函数重载C相关特性 本章将介绍C中一个重要的概念——类。通过类,我们可以类中定义成员变量和成员函数,实现模块化封装,从而构建更加抽象和复杂的工程。 &…...
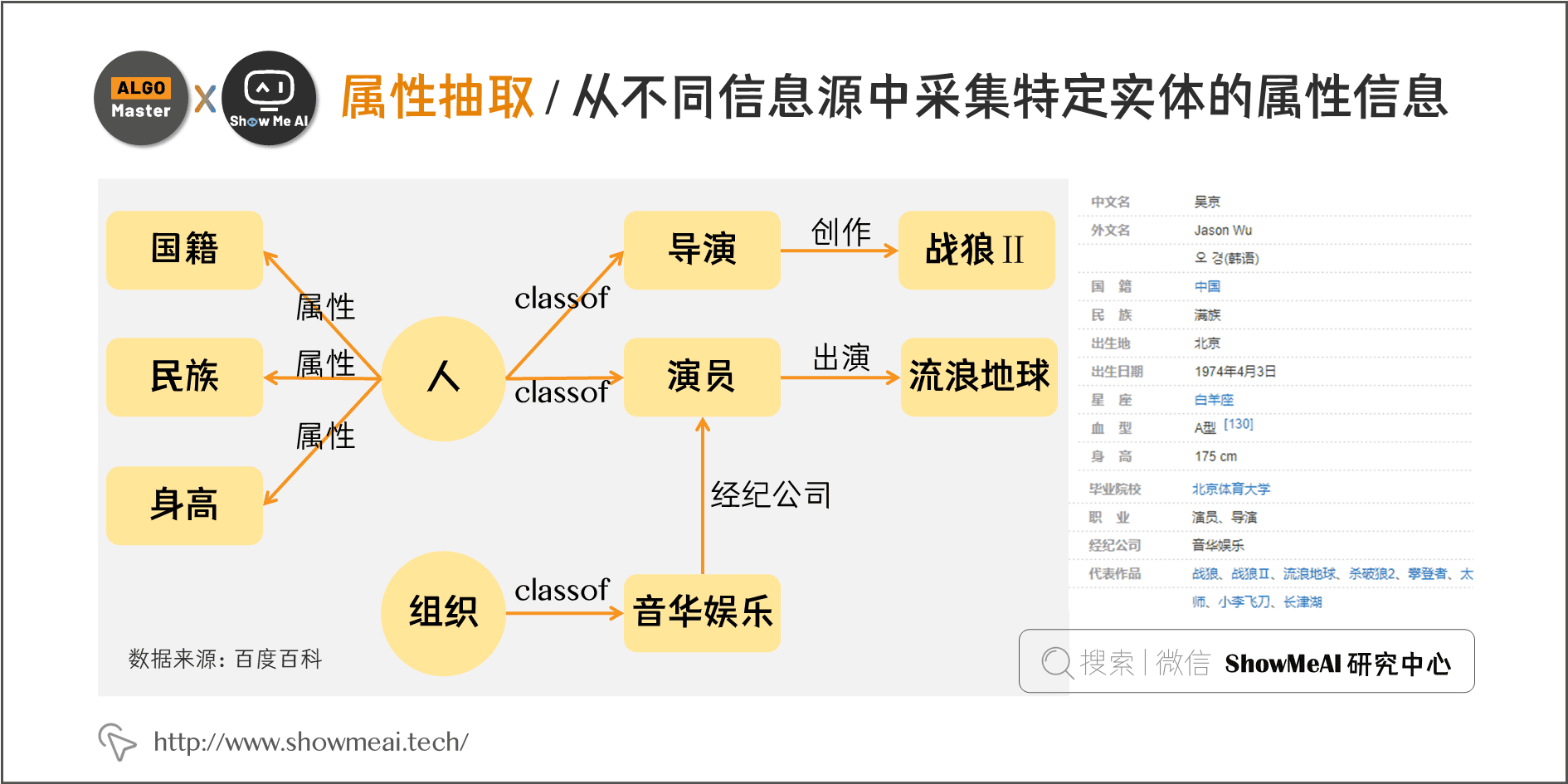
知识图谱学习总结
1 知识图谱的介绍 知识图谱,是结构化的语义知识库,用于迅速描述物理世界中的概念及其相互关系,通过知识图谱能够将Web上的信息、数据以及链接关系聚集为知识,使信息资源更易于计算、理解以及评价,并能实现知识的快速响…...

2021-10-23 51单片机LED1-8按秒递增闪烁
缘由51单片机,八个LED灯按LED1亮1s灭1s,LED1亮2s 灭2s以此类推的方式亮灭-编程语言-CSDN问答 #include "REG52.h" sbit K1 P1^0; sbit K2 P1^1; sbit K3 P1^2; sbit K4 P1^3; sbit P1_0P2^0; sbit P1_1P2^1; sbit P1_2P2^2; sbit P1_3P2^3; sbit P1_…...

网络安全中的图片旋转攻击检测:隐写分析新维度
网络安全中的图片旋转攻击检测:隐写分析新维度 1. 引言 在数字时代,图片已成为我们日常交流和业务处理中不可或缺的一部分。然而,你可能不知道的是,黑客们正在利用一个看似无害的技术——图片旋转,来传递隐蔽信息&am…...

3个颠覆性技巧:NVIDIA Profile Inspector如何释放显卡隐藏性能
3个颠覆性技巧:NVIDIA Profile Inspector如何释放显卡隐藏性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专业的显卡参数配置工具,能够深度…...
)
手把手教你用NVIDIA TX2串口控制大疆C620电机(USB转CAN模块保姆级教程)
从零实现NVIDIA TX2通过USB-CAN模块精准控制大疆C620电机 硬件连接与基础原理 当我们需要在机器人项目中实现高精度电机控制时,CAN总线通信往往是首选方案。但对于使用NVIDIA Jetson TX2这类开发板的新手来说,可能会遇到两个现实问题:TX2原生…...

保姆级教程:用LangFlow可视化工具3步搭建智能问答机器人,无需代码
保姆级教程:用LangFlow可视化工具3步搭建智能问答机器人,无需代码 1. 为什么选择LangFlow? 想象一下,你有一个绝妙的AI应用创意,但面对复杂的代码和API文档却无从下手。LangFlow就是为解决这个问题而生的可视化工具&…...

Qwen3.5-2B生成Typora风格技术文档:Markdown与图表自动编排
Qwen3.5-2B生成Typora风格技术文档:Markdown与图表自动编排 1. 技术写作的新助手 技术文档写作一直是开发者头疼的问题。从项目README到API文档,再到技术报告,我们经常需要花费大量时间在格式调整和排版上。传统写作工具要么功能单一…...

nli-distilroberta-baseAI应用:作为LLM输出后处理模块过滤逻辑矛盾回答
NLI DistilRoBERTa Base AI应用:作为LLM输出后处理模块过滤逻辑矛盾回答 1. 项目概述 nli-distilroberta-base是一个基于DistilRoBERTa模型的自然语言推理(NLI)Web服务,专门用于判断两个句子之间的逻辑关系。这个轻量级但强大的工具可以帮助开发者解决…...

OpenClaw技能市场盘点:10个适配Phi-3-mini-128k-instruct的实用工具
OpenClaw技能市场盘点:10个适配Phi-3-mini-128k-instruct的实用工具 1. 为什么需要关注技能市场? 当我第一次在本地部署OpenClaw时,最让我惊喜的不是框架本身,而是它背后那个充满可能性的技能市场。作为一个长期与命令行打交道的…...

5分钟本地部署Asian Beauty Z-Image Turbo:零基础生成东方美学人像写真
5分钟本地部署Asian Beauty Z-Image Turbo:零基础生成东方美学人像写真 在数字内容创作蓬勃发展的今天,高质量人像图像的需求与日俱增。特别是对于东方审美风格的人像写真,传统拍摄方式成本高昂且效率低下。今天,我将带你快速部署…...

面向 LLM 的程序设计 4:API 版本化与演进——在「模型会记忆旧文档」前提下的兼容策略
用三句话先说明白 人会照旧说明书办事,模型也一样。 它见过的文档、缓存里的接口描述、网页上没刷新的说明、向量库里还没更新的片段,都可能比真实系统更旧。于是系统已经升级了,它还在用老地址、老字段名、老例子去调用。 给人改流程&#…...

CentOS7下CDP7.1.1集群部署全攻略:从系统调优到MySQL配置避坑指南
CentOS7企业级CDP7.1.1集群深度部署指南:系统调优与MySQL高可用实战 开篇:企业级大数据平台的基石构建 当数据量突破TB级门槛时,一个经过深度优化的集群环境直接决定了数据分析的效率和稳定性。我曾亲历过某金融客户由于透明大页未关闭导致集…...