【python】Pandas处理Excel表格用法分析与最佳实践

✨✨ 欢迎大家来到景天科技苑✨✨
🎈🎈 养成好习惯,先赞后看哦~🎈🎈
🏆 作者简介:景天科技苑
🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。
🏆《博客》:Python全栈,PyQt5和Tkinter桌面开发,小程序开发,人工智能,js逆向,App逆向,网络系统安全,数据分析,Django,fastapi,flask等框架,云原生K8S,linux,shell脚本等实操经验,网站搭建,数据库等分享。所属的专栏:数据分析系统化教学,零基础到进阶实战
景天的主页:景天科技苑

文章目录
- Pandas处理Excel数据的详细用法教程
- 安装Pandas库
- 读取Excel文件
- 读取整个Excel文件
- 读取多个工作表
- 查看数据
- 基本查看
- 详细信息
- 选择数据
- 单列或多列选择
- 基于标签或位置选择
- 数据清洗
- 处理缺失值
- 替换值
- 更改数据类型
- 重复值处理
- 数据排序
- 数据筛选
- 使用条件表达式
- 使用`query()`方法
- 布尔索引
- 数据分组与聚合
- 数据合并与连接
- 使用merge()
- 使用join()
- 使用concat()
- 保存数据到Excel
- 数据转换
- 时间序列数据
- 数据可视化
- 性能优化
- 注意事项和最佳实践
Pandas处理Excel数据的详细用法教程
Pandas是Python中一个非常强大的数据处理库,它提供了快速、灵活和表达式丰富的数据结构,旨在使“关系”或“标签”数据的处理工作变得既简单又直观。在处理Excel数据时,Pandas的read_excel函数及其后续的数据处理功能尤为关键。本教程将结合实际案例,详细介绍Pandas如何读取、处理、分析并保存Excel数据。
安装Pandas库
首先,确保你已经安装了Pandas库。如果还没有安装,可以通过pip命令进行安装:
pip install pandas
此外,由于Pandas使用openpyxl或xlrd等库来读取Excel文件,因此可能还需要安装这些依赖库。对于.xlsx文件,推荐使用openpyxl:
pip install openpyxl
读取Excel文件
读取整个Excel文件
假设我们有一个名为data.xlsx的Excel文件,我们可以使用read_excel函数读取该文件:
import pandas as pd# 读取Excel文件
df = pd.read_excel('data.xlsx')# 显示前几行数据
print(df.head())
默认情况下,read_excel会读取Excel文件的第一个工作表。如果你需要读取特定的工作表,可以通过sheet_name参数指定:
df = pd.read_excel('data.xlsx', sheet_name='Sheet2')
读取多个工作表
如果你需要同时读取多个工作表,可以指定sheet_name为工作表名的列表,或者None来读取所有工作表。如果指定为None,函数将返回一个有序字典(OrderedDict),其中键为工作表名,值为对应的DataFrame:
xls = pd.ExcelFile('data.xlsx')
dict_dfs = pd.read_excel(xls, sheet_name=None)# 访问特定工作表的DataFrame
df_sheet1 = dict_dfs['Sheet1']
print(df_sheet1.head())
查看数据
基本查看
一旦数据被读取到DataFrame中,我们可以使用多种方法来查看数据。head()和tail()函数分别用于查看数据的前几行和后几行:
# 查看前5行数据
print(df.head())# 查看后5行数据
print(df.tail())
详细信息
info()函数提供了DataFrame的详细信息,包括每列的名称、数据类型以及非空值的数量:
print(df.info())
describe()函数则提供了数值列的统计信息,如计数、均值、标准差、最小值、四分位数和最大值:
print(df.describe())
选择数据
单列或多列选择
通过列名,我们可以选择DataFrame中的单列或多列数据:
# 选择单列
column_data = df['列名']# 选择多列
columns_data = df[['列名1', '列名2']]
基于标签或位置选择
Pandas提供了.loc[]和.iloc[]方法来基于标签(即行索引或列名)或整数位置来选择数据:
# 基于标签选择
row_data = df.loc[row_index, '列名']# 基于位置选择
row_data_position = df.iloc[row_position]
.at[]和.iat[]方法则用于选择单个值,分别基于标签和位置:
# 基于标签选择单个值
value = df.at[row_label, '列名']# 基于位置选择单个值
value_position = df.iat[row_position, column_position]
数据清洗
处理缺失值
缺失值是数据清洗中常见的问题。Pandas提供了多种方法来处理这些值:
- 使用
dropna()删除包含缺失值的行或列。 - 使用
fillna(value)用指定的值填充缺失值。
# 删除包含缺失值的行
df_cleaned = df.dropna()# 用0填充缺失值
df_filled = df.fillna(0)
替换值
replace()方法允许我们替换DataFrame中的值:
# 替换特定值
df_replaced = df.replace(to_replace=某个值, value=新值)
更改数据类型
在处理Excel数据时,经常需要更改列的数据类型以符合分析或计算的需求。Pandas提供了astype()方法来实现这一点。
# 假设'date_column'列原本为字符串类型,我们需要将其转换为日期类型
df['date_column'] = pd.to_datetime(df['date_column'])# 或者,如果整列都需要转换为另一种数据类型
df['numeric_column'] = df['numeric_column'].astype(float)
注意,pd.to_datetime()是Pandas提供的一个非常有用的函数,用于将字符串转换为日期时间对象。
重复值处理
数据中可能存在重复的行,这可能会影响分析的结果。Pandas提供了drop_duplicates()方法来删除重复的行。
# 删除所有重复的行,保留第一次出现的行
df_unique = df.drop_duplicates()# 也可以指定一个或多个列来识别重复项
df_unique_by_column = df.drop_duplicates(subset=['column1', 'column2'])
数据排序
Pandas提供了sort_values()和sort_index()方法来对数据进行排序。
sort_values()根据列的值进行排序。sort_index()根据行索引进行排序。
# 根据某一列的值进行排序
df_sorted = df.sort_values(by='column_name', ascending=False)# 根据索引进行排序
df_sorted_by_index = df.sort_index()
数据筛选
Pandas提供了多种方式来筛选数据,包括使用条件表达式、query()方法或布尔索引。
使用条件表达式
# 筛选满足条件的行
filtered_df = df[(df['column1'] > 10) & (df['column2'] == 'value')]
使用query()方法
query()方法允许你以字符串的形式编写筛选条件,这可以使代码更加清晰易读。
# 使用query方法筛选数据
filtered_df = df.query('column1 > 10 and column2 == "value"')
布尔索引
布尔索引是Pandas中最强大的数据筛选方法之一,它基于条件表达式的结果(布尔值)来选择数据。
# 创建一个布尔序列
mask = (df['column1'] > 10) & (df['column2'] == 'value')# 使用布尔序列筛选数据
filtered_df = df[mask]
数据分组与聚合
Pandas的groupby()方法允许你根据一个或多个键将数据分组,然后对每个组应用聚合函数。
# 根据某一列的值进行分组,并对另一列应用聚合函数
grouped = df.groupby('group_column')['value_column'].mean()# 或者,使用agg()方法应用多个聚合函数
grouped_multiple = df.groupby('group_column').agg({'value_column1': 'mean', 'value_column2': 'sum'})
数据合并与连接
Pandas提供了多种方法来合并和连接DataFrame,包括merge()、join()和concat()。
使用merge()
merge()方法类似于SQL中的JOIN操作,用于根据一个或多个键合并两个DataFrame。
# 假设df1和df2是两个DataFrame,它们有一个共同的列'key'
merged_df = pd.merge(df1, df2, on='key', how='inner')
使用join()
join()方法主要用于在索引上合并DataFrame。
# 假设df1和df2有相同的索引
joined_df = df1.join(df2, lsuffix='_left', rsuffix='_right')
使用concat()
concat()方法用于沿着一条轴将多个对象堆叠到一起。
# 沿着行方向堆叠两个DataFrame
concatenated_df = pd.concat([df1, df2], ignore_index=True)
保存数据到Excel
处理完数据后,你可能需要将结果保存回Excel文件。Pandas的to_excel()方法允许你这样做。
# 将DataFrame保存到新的Excel文件
df.to_excel('output.xlsx', index=False)# 如果要保存到特定的工作表,并保留原有的工作表,可以使用ExcelWriter
with pd.ExcelWriter('output_with_sheets.xlsx', mode='a', if_sheet_exists='replace') as writer:df.to_excel(writer, sheet_name='Sheet1', index=False)# 如果需要添加更多DataFrame到同一个Excel文件的不同工作表df2.to_excel(writer, sheet_name='Sheet2', index=False)注意:在上面的ExcelWriter示例中,mode='a'表示以追加模式打开文件(如果文件已存在)。然而,当指定if_sheet_exists='replace'时,如果工作表已存在,它会被替换,这意呀着实际上在追加模式下这个参数的行为更像是在每次写入时都替换同名的工作表。如果你确实需要保留工作表而不替换它们,并且文件已经存在,你可能需要先检查哪些工作表存在,然后只添加新的工作表或更新现有的工作表。
另外,如果你使用的是openpyxl作为引擎(Pandas在写入.xlsx文件时的默认引擎),请注意openpyxl不支持在同一ExcelWriter实例中多次打开相同的文件(即使是在不同的with语句块中),除非你关闭了ExcelWriter并重新打开它。但是,在上面的示例中,由于我们使用了with语句,ExcelWriter会在块结束时自动关闭,所以通常不需要手动关闭它。
当然,我们可以继续探讨Pandas在数据处理中的一些高级应用和技巧。
数据转换
Pandas提供了强大的数据转换功能,包括应用自定义函数、使用applymap()在DataFrame的每个元素上应用函数等。
# 使用apply函数在DataFrame的列上应用自定义函数
def custom_function(x):# 对x执行一些操作return x * 2df['transformed_column'] = df['original_column'].apply(custom_function)# 使用applymap在DataFrame的每个元素上应用函数(注意:这通常用于DataFrame的所有元素都是相同类型的情况)
df_transformed = df.applymap(lambda x: x.upper() if isinstance(x, str) else x) # 仅作为示例,实际应用中可能不适用
时间序列数据
Pandas的Timeseries功能非常强大,特别是处理时间序列数据时。datetime类型列可以被转换为时间序列索引,以便进行时间序列分析。
# 假设'date_column'已经是datetime类型
df.set_index('date_column', inplace=True)# 现在df是一个时间序列DataFrame
# 你可以使用resample方法进行时间频率的转换或聚合
resampled_df = df.resample('M').mean() # 按月重新采样并计算均值
数据可视化
虽然Pandas本身并不直接提供高级的数据可视化功能,但它与Matplotlib、Seaborn等库无缝集成,可以轻松地进行数据可视化。
import matplotlib.pyplot as plt# 绘制DataFrame的某一列的直方图
df['column_name'].hist(bins=30)
plt.show()# 使用Seaborn进行更复杂的可视化
import seaborn as snssns.heatmap(df.corr(), annot=True) # 绘制相关性热力图
plt.show()
性能优化
当处理大型数据集时,性能成为一个关键问题。以下是一些优化Pandas操作性能的建议:
- 避免在循环中迭代DataFrame的行:Pandas是为向量化操作而设计的,因此在循环中迭代行通常会比使用Pandas内置的向量化方法慢得多。
- 使用适当的数据类型:选择适当的数据类型可以显著减少内存占用和提高性能。
- 使用
chunksize进行大型文件的分批读取。 - 使用
query()方法进行复杂的筛选:虽然query()方法在代码可读性方面优于布尔索引,但在某些情况下,它也可能比布尔索引更快。 - 利用多核CPU:对于高度并行的任务,可以考虑使用
Dask或Modin等库,它们为Pandas提供了分布式或并行计算的支持。
通过结合使用这些高级功能和最佳实践,你可以更高效地利用Pandas来处理和分析Excel数据。
注意事项和最佳实践
-
内存管理:处理大型Excel文件时,注意内存使用情况。如果可能,尝试在读取文件时只加载必要的数据列和行。
-
数据类型:在读取数据时,注意列的数据类型是否正确。Pandas会根据数据内容自动推断数据类型,但有时候这种推断并不准确。
-
错误处理:在读取或写入文件时,添加错误处理逻辑来捕获并处理可能发生的异常,比如文件不存在、权限问题等。
-
性能优化:对于大型数据集,考虑使用
chunksize参数在read_excel中逐块读取数据,或者使用Dask等并行处理库来加速数据处理过程。 -
版本兼容性:确保你安装的Pandas和依赖库(如
openpyxl)是最新版本,或者至少是彼此兼容的版本。 -
备份原始数据:在处理数据之前,始终备份原始数据,以防不小心丢失或损坏。
-
文档和注释:对于复杂的数据处理流程,编写详细的文档和代码注释,以便将来能够轻松理解和维护代码。
通过遵循这些最佳实践,你可以更有效地使用Pandas处理Excel数据,并确保数据处理的准确性和可靠性。
相关文章:
【python】Pandas处理Excel表格用法分析与最佳实践
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

KL 散度(python+nlp)
python demo KL 散度(Kullback-Leibler divergence),也称为相对熵,是衡量两个概率分布之间差异的一种方式。KL 散度是非对称的,也就是说,P 相对于 Q 的 KL 散度通常不等于 Q 相对于 P 的 KL 散度。 一个简…...

四种推荐算法——Embedding+MLP、WideDeep、DeepFM、NeuralCF
一、EmbeddingMLP模型 EmbeddingMLP 主要是由 Embedding 部分和 MLP 部分这两部分组成,使用 Embedding 层是为了将类别型特征转换成 Embedding 向量,MLP 部分是通过多层神经网络拟合优化目标。——用于广告推荐。 Feature层即输入特征层,是模…...
鹏鼎控股:最新面试求职SHL逻辑测评笔试题库讲解及真题分享
鹏鼎控股(深圳)股份有限公司,成立于1999年4月29日,是一家专业从事印制电路板(PCB)设计、研发、制造与销售的企业。公司产品广泛应用于通讯、消费电子、汽车、服务器等多个领域,服务全球市场。鹏…...

【Git】git 不跟踪和gitignore区别
文章目录 不跟踪(Untracked):.gitignore 文件:总结 在 Git 中,不跟踪(untracked)和 .gitignore 文件有不同的作用和用途: 不跟踪(Untracked): 不…...
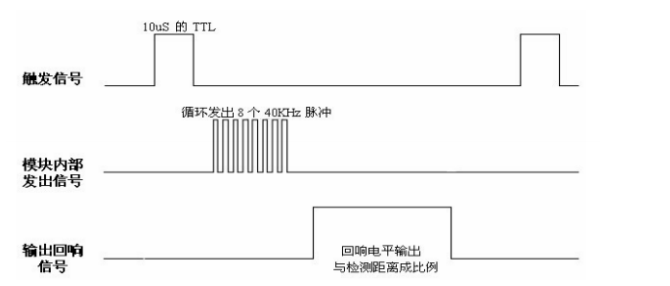
51单片机—智能垃圾桶(定时器)
一. 定时器 1. 简介 C51中的定时器和计数器是同一个硬件电路支持的,通过寄存器配置不同,就可以将他当做定时器或者计数器使用。 确切的说,定时器和计数器区别是致使他们背后的计数存储器加1的信号不同。当配置为定时器使用时,每…...
熵权法模型(评价类问题)
一. 概念 利用信息熵计算各个指标的权重,从而为多指标的评价类问题提供依据。 指标的变异程度越小,所反映的信息量也越少,所以其对应的权值也应该越低。 指标的变异程度(或称为变异性、波动性):描述了一…...

用uniapp 及socket.io做一个简单聊天app 踢人拉黑 7
在聊天群里,以及私聊时,可以点对方头象弹出踢跟拉黑,踢只是让对方退出聊天室。拉黑是记对方退出且不能再进入。 socket.io 中的踢人流程: 将用户从groupUsers 删除,表现在uniapp的界面,就是通知friends页&…...

springboot项目迁移到阿里云函数
注意:长耗时,高内存 的应用,定时任务 不适合迁移。spring-cloud的微服务项目暂不适合迁移。 一、根据模板创建项目 1.内网数据库连接配置 如果用到了rds或者阿里云上自建的mysql数据库 则配置 internetAccess: true vpcConfig:securityGrou…...

Java设计模式(桥接模式)
定义 将抽象部分与它的实现部分解耦,使得两者都能够独立变化。 角色 抽象类(Abstraction):定义抽象类,并包含一个对实现化对象的引用。 扩充抽象类(RefinedAbstraction):是抽象化角…...

【独家原创】基于APO-Transformer-LSTM多特征分类预测(多输入单输出)Matlab代码
【独家原创】基于APO-Transformer-LSTM多特征分类预测(多输入单输出)Matlab代码 目录 【独家原创】基于APO-Transformer-LSTM多特征分类预测(多输入单输出)Matlab代码分类效果基本描述程序设计参考资料 分类效果 基本描述 [24年最…...

【大模型】大模型指令微调的“Prompt”模板
文章目录 一、微调数据集格式二、常用的指令监督微调模板2.1 指令跟随格式(Alpaca)2.2 多轮对话格式(ShareGPT)2.3 其他形式2.4 常见模板 参考资料 一、微调数据集格式 在进行大模型微调的过程中,我们会发现“Prompt”…...

Spring的设计模式----工厂模式及对象代理
一、工厂模式 工厂模式提供了一种将对象的实例化过程封装在工厂类中的方式。通过使用工厂模式,可以将对象的创建与使用代码分离,提供一种统一的接口来创建不同类型的对象。定义一个创建对象的接口让其子类自己决定实例化哪一个工厂类,…...

【算法】浅析广度优先搜索算法
广度优先搜索算法:层层推进,全面探索 1. 引言 在计算机科学和算法设计中,广度优先搜索(Breadth-First Search,简称BFS)是一种用于遍历或搜索树或图的算法。这种算法从起点开始,优先访问所有距…...
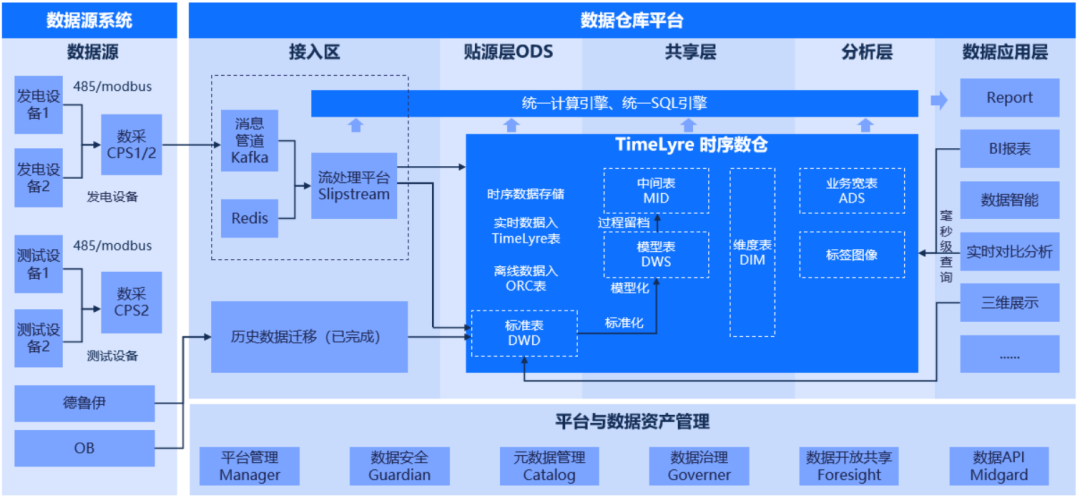
分布式时序数据库TimeLyre 9.2发布:原生多模态、高性能计算、极速时序回放分析
在当今数据驱动的世界中,多模态数据已经成为企业的重要资产。随着数据规模和多样性的不断增加,企业不仅需要高效存储和处理这些数据,更需要从中提取有价值的洞察。工业领域在处理海量设备时序数据的同时,还需要联动分析警报信息、…...

PMP考试题库每日五题+答案解析
第1题(单选题)某技术开发项目正在开展,目前项目所用成本还在预算范围内,但是已经落后项目进度计划三周。项目集经理在最近的项目状态报告中了解到这一项目信息,他要求项目经理必须在计划的交付日期之前完成可交付成果。…...

机器学习用python还是R,哪个更好?
目录 1. 语言特点 1.1 Python的语言特点 1.2 R的语言特点 2. 库支持 2.1 Python的库支持 2.2 R的库支持 3. 性能 3.1 Python的性能 3.2 R的性能 4. 社区支持 4.1 Python的社区支持 4.2 R的社区支持 5. 学习曲线 5.1 Python的学习曲线 5.2 R的学习曲线 6. 实际应…...

【数据结构】mapset详解
🍁1. Set系列集合 Set接口是一种不包含重复元素的集合。它继承自Collection接口,所以可以使用Collection所拥有的方法,Set接口的实现类主要有HashSet、LinkedHashSet、TreeSet等,它们各自以不同的方式存储元素,但都遵…...

数据结构(邓俊辉)学习笔记】词典 02—— 散列函数
文章目录 1. 冲突难免2. 何为优劣3. 整除留余4. 以禅为师5. M A D6. 平方取中7. 折叠汇总8. 伪随机数9. 多项式10. Vorldmort 1. 冲突难免 好,接下来的这一节我们就来介绍散列策略中的第一项,也是最重要的技术,散列函数的设计与定制。 在上…...

Python学习(1):使用Python的Dask库实现并行计算
目录 一、Dask介绍 二、使用说明 安装 三、测试 1、单个文件中实现功能 2、运行多个可执行文件 最近在写并行计算相关部分,用到了python的Dask库。 Dask官网:Dask | Scale the Python tools you love 一、Dask介绍 Dask是一个灵活的并行和分布式…...

AI 时代,计算机专业学生该怎么学?恫
整体排查思路 我们的目标是验证以下三个环节是否正常: 登录成功时:服务器是否正确生成了Session并返回了包含正确 JSESSIONID的Cookie给浏览器。 浏览器端:浏览器是否成功接收并存储了该Cookie。 后续请求:浏览器在执行查询等操作…...

SUPER COLORIZER模型训练进阶:使用自定义数据集微调以适配特定画风
SUPER COLORIZER模型训练进阶:使用自定义数据集微调以适配特定画风 你是不是觉得直接用现成的上色模型,出来的效果总是差那么点意思?要么颜色太普通,要么风格不是你想要的。比如你想给线稿上色成那种飘逸的水墨风,或者…...
)
SolidWorks 2019 + Fusion 360:手把手教你搞定复杂机械臂模型的URDF导出(附开源模型)
SolidWorks与Fusion 360协同工作流:机械臂模型URDF导出实战指南 当你在GitHub上发现一个设计精良的六轴机械臂模型,却因为格式兼容性问题无法直接使用时,这种挫败感每个机器人开发者都深有体会。上周我就遇到了这样的情况——一个基于Gluon架…...

GLM-4V-9B惊艳效果展示:电路板图元器件识别+故障点定位+维修指引生成
GLM-4V-9B惊艳效果展示:电路板图元器件识别故障点定位维修指引生成 安全声明:本文仅展示AI技术能力,所有电路板图像均为演示用途,不涉及任何实际设备或敏感信息 1. 项目概述与核心能力 GLM-4V-9B多模态大模型在工业视觉检测领域展…...

OpenClaw故障排查大全:Qwen3-14B接口调用失败解决方案
OpenClaw故障排查大全:Qwen3-14B接口调用失败解决方案 1. 前言:为什么需要这份指南 上周我在本地部署OpenClaw对接Qwen3-14B模型时,连续遭遇了三次不同原因的接口调用失败。从网关超时到模型响应异常,每次错误都让我花费数小时查…...

坐标系工艺参数的设定
在一台专机机床上模拟圆弧程序时,发现G2和G3的方向是反的,G2轴按逆时针方向运行,G3轴按顺时针方向运行。测试程序如下:G19G0 G90 Y0 Z0G2 Y100 Z100 CR100 F500M30G2指令时,圆弧为逆时针方向G3指令时,圆弧为…...

Python主流框架全解析
以下是 Python 常用框架的分类解析:一、Web 开发框架1. Django定位:全能型框架,内置 ORM、模板引擎、路由系统等特点:开箱即用(如自带后台管理、用户认证)遵循 MVC 设计模式(MTV 变体࿰…...

STM32总线架构解析与性能优化实战
1. STM32单片机内部总线架构概述作为嵌入式开发者,理解STM32单片机的内部总线结构是优化代码性能的关键。在Cortex-M3架构的STM32F1系列中,总线系统就像一座精心设计的立交桥网络,各司其职又相互配合。我第一次调试DMA传输卡顿时,…...

MMC储能、分布式储能Simulink仿真及DCDC升降压储能模块的SOC均衡控制采用模型预测控制
mmc储能 分布式储能simulink仿真 soc均衡控制 采用模型预测控制 dcdc升降压储能模块最近在搞MMC储能的仿真项目,发现这玩意儿真是电网调频的宝藏工具。特别是当分布式储能单元遇上模块化多电平换流器,SOC均衡控制就成了最烧脑的环节。今天咱们就撸起袖…...
 5 .终端连接与环境配置(SSH连接、命令行提示符含义))
Shell应用手册(一) 5 .终端连接与环境配置(SSH连接、命令行提示符含义)
对于后端开发者、运维工程师而言,终端是日常工作中最常用的工具之一。无论是远程管理服务器,还是本地调试程序,终端连接的稳定性、环境配置的合理性,直接影响工作效率。而SSH连接作为远程终端访问的核心方式,命令行提示…...