pandas——groupby操作
Pandas——groupby操作
文章目录
- Pandas——groupby操作
- 一、实验目的
- 二、实验原理
- 三、实验环境
- 四、实验内容
- 五、实验步骤
一、实验目的
熟练掌握pandas中的groupby操作
二、实验原理
groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False)
参数说明:
by是指分组依据(列表、字典、函数,元组,Series)
axis:是作用维度(0为行,1为列)
level:根据索引级别分组
sort:对groupby分组后新的dataframe中索引进行排序,sort=True为升序,
as_index:在groupby中使用的键是否成为新的dataframe中的索引,默认as_index=True
group_keys:在调用apply时,将group键添加到索引中以识别片段
squeeze :如果可能的话,减少返回类型的维数,否则返回一个一致的类型
grouping操作(split-apply-combine)
数据的分组&聚合 – 什么是groupby 技术?
在数据分析中,我们往往需要在将数据拆分,在每一个特定的组里进行运算。比如根据教育水平和年龄段计算某个城市的工作人口的平均收入。
pandas中的groupby提供了一个高效的数据的分组运算。
我们通过一个或者多个分类变量将数据拆分,然后分别在拆分以后的数据上进行需要的计算
我们可以把上述过程理解为三部:
1.拆分数据(split)
2.应用某个函数(apply)
3.汇总计算结果(aggregate)
下面这个演示图展示了“分拆-应用-汇总”的groupby思想
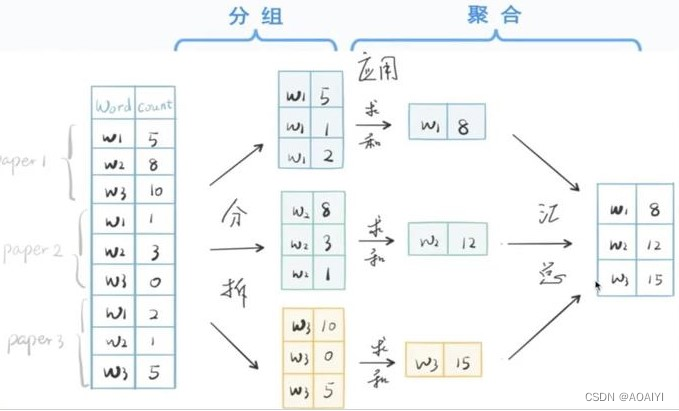
上图所示,分解步骤:
Step1 :数据分组—— groupby 方法
Step2 :数据聚合:
使用内置函数——sum / mean / max / min / count等
使用自定义函数—— agg ( aggregate ) 方法
自定义更丰富的分组运算—— apply 方法
三、实验环境
Python 3.6.1
Jupyter
四、实验内容
练习pandas中的groupby的操作案例
五、实验步骤
1.创建一个数据帧df。
import numpy as np
import pandas as pd
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C' : np.random.randn(8),'D' : np.random.randn(8)})
print(df)

2.通过A列对df进行分布操作。
df.groupby('A')

3.通过A、B列对df进行分组操作。
df.groupby(['A','B'])

4…使用自定义函数进行分组操作,自定义一个函数,使用groupby方法并使用自定义函数给定的条件,按列对df进行分组。
def get_letter_type(letter): if letter.lower() in 'aeiou': return 'vowel' else: return 'consonant' grouped = df.groupby(get_letter_type, axis=1)
for group in grouped: print(group)

5.创建一个Series名为s,使用groupby根据s的索引对s进行分组,返回分组后的新Series,对新Series进行first、last、sum操作。
lst = [1, 2, 3, 1, 2, 3]
s = pd.Series([1, 2, 3, 10, 20, 30], lst)
grouped = s.groupby(level=0)
#查看分组后的第一行数据
grouped.first()
#查看分组后的最后一行数据
grouped.last()
#对分组的各组进行求和
grouped.sum()

6.分组排序,使用groupby进行分组时,默认是按分组后索引进行升序排列,在groupby方法中加入sort=False参数,可以进行降序排列。
df2=pd.DataFrame({'X':['B','B','A','A'],'Y':[1,2,3,4]})
#按X列对df2进行分组,并求每组的和
df2.groupby(['X']).sum()
#按X列对df2进行分组,分组时不对键进行排序,并求每组的和
df2.groupby(['X'],sort=False).sum()

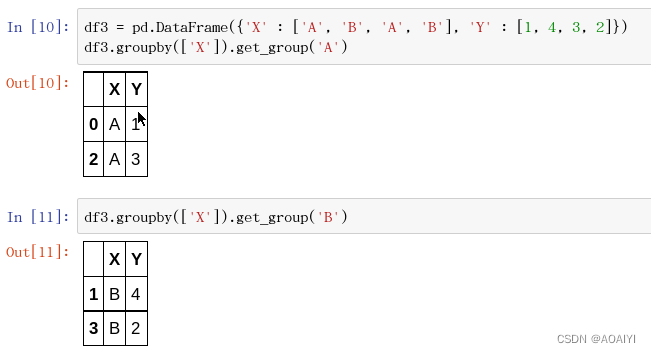
7.使用get_group方法得到分组后某组的值。
df3 = pd.DataFrame({'X' : ['A', 'B', 'A', 'B'], 'Y' : [1, 4, 3, 2]})
#按X列df3进行分组,并得到A组的df3值
df3.groupby(['X']).get_group('A')
#按X列df3进行分组,并得到B组的df3值
df3.groupby(['X']).get_group('B')
8.使用groups方法得到分组后所有组的值。
df.groupby('A').groups
df.groupby(['A','B']).groups

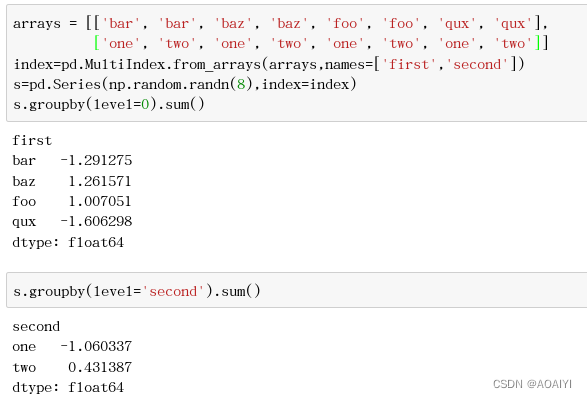
9.多级索引分组,创建一个有两级索引的Series,并使用两个方法对Series进行分组并求和。
arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'],['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']]
index=pd.MultiIndex.from_arrays(arrays,names=['first','second'])
s=pd.Series(np.random.randn(8),index=index)
s.groupby(level=0).sum()
s.groupby(level='second').sum()
10.复合分组,对s按first、second进行分组并求和。
s.groupby(level=['first', 'second']).sum()

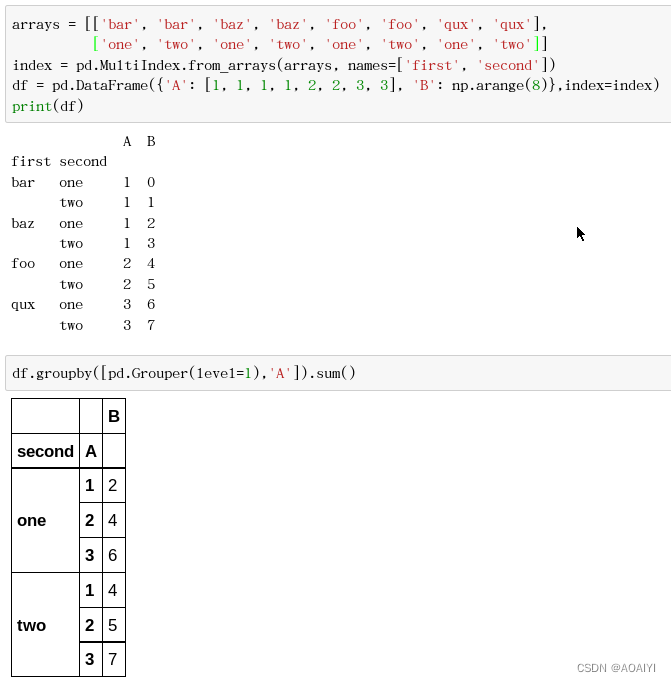
11.复合分组(按索引和列),创建数据帧df,使用索引级别和列对df进行分组。
arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'],['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']]
index = pd.MultiIndex.from_arrays(arrays, names=['first', 'second'])
df = pd.DataFrame({'A': [1, 1, 1, 1, 2, 2, 3, 3], 'B': np.arange(8)},index=index)
print(df)
df.groupby([pd.Grouper(level=1),'A']).sum()
12.对df进行分组,将分组后C列的值赋值给grouped,统计grouped中每类的个数。
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C' : np.random.randn(8),'D' : np.random.randn(8)})
grouped=df.groupby(['A'])
grouped_C=grouped['C']
print(grouped_C.count())

13.对上面创建的df的C列,按A列值进行分组并求和。
df['C'].groupby(df['A']).sum()

14.遍历分组结果,通过A,B两列对df进行分组,分组结果的组名为元组。
for name, group in df.groupby(['A', 'B']): print(name) print(group)

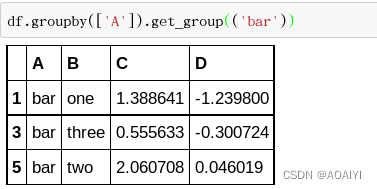
15.通过A列对df进行分组,并查看分组对象的bar列。
df.groupby(['A']).get_group(('bar'))
16.按A,B两列对df进行分组,并查看分组对象中bar、one都存在的部分。
df.groupby(['A','B']).get_group(('bar','one'))

注意:当分组按两列来分时,查看分组对象也应该包含每列的一部分。
17.聚合操作,按A列对df进行分组,使用聚合函数aggregate求每组的和。
grouped=df.groupby(['A'])
grouped.aggregate(np.sum)

按A、B两列对df进行分组,并使用聚合函数aggregate对每组求和。
grouped=df.groupby(['A','B'])
grouped.aggregate(np.sum)
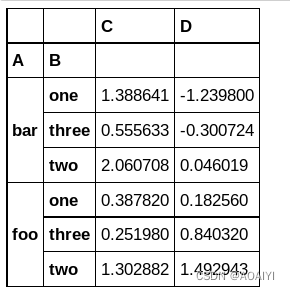
注意:通过上面的结果可以看到。聚合完成后每组都有一个组名作为新的索引,使用as_index=False可以忽略组名。
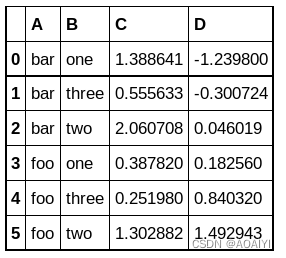
18.当as_index=True时,在groupby中使用的键将成为新的dataframe中的索引。按A、B两列对df进行分组,这是使参数as_index=False,再使用聚合函数aggregate求每组的和.
grouped=df.groupby(['A','B'],as_index=False)
grouped.aggregate(np.sum)
19.聚合操作,按A、B列对df进行分组,使用size方法,求每组的大小。返回一个Series,索引是组名,值是每组的大小。
grouped=df.groupby(['A','B'])
grouped.size()

20.聚合操作,对分组grouped进行统计描述。
grouped.describe()
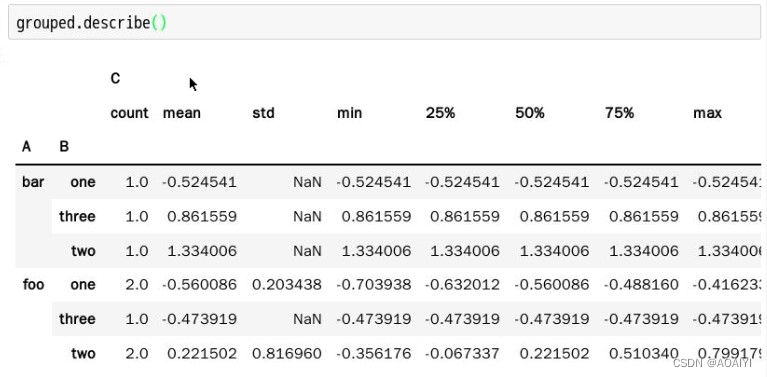
注意:聚合函数可以减少数据帧的维度,常用的聚合函数有:mean、sum、size、count、std、var、sem 、describe、first、last、nth、min、max。
执行多个函数在一个分组结果上:在分组返回的Series中我们可以通过一个聚合函数的列表或一个字典去操作series,返回一个DataFrame。
相关文章:
pandas——groupby操作
Pandas——groupby操作 文章目录Pandas——groupby操作一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤一、实验目的 熟练掌握pandas中的groupby操作 二、实验原理 groupby(byNone, axis0, levelNone, as_indexTrue, sortTrue, group_keysTrue, squeezeFalse&…...
webpack.config.js哪里找?react项目关闭eslint监测
目录 webpack.config.js哪里找? react项目关闭eslint监测 webpack.config.js哪里找? 在React项目中,当我们需要修改一些配置时,发现找不到webpack.config.js,是我们创建的项目有问题吗,还需新创建项目的项…...
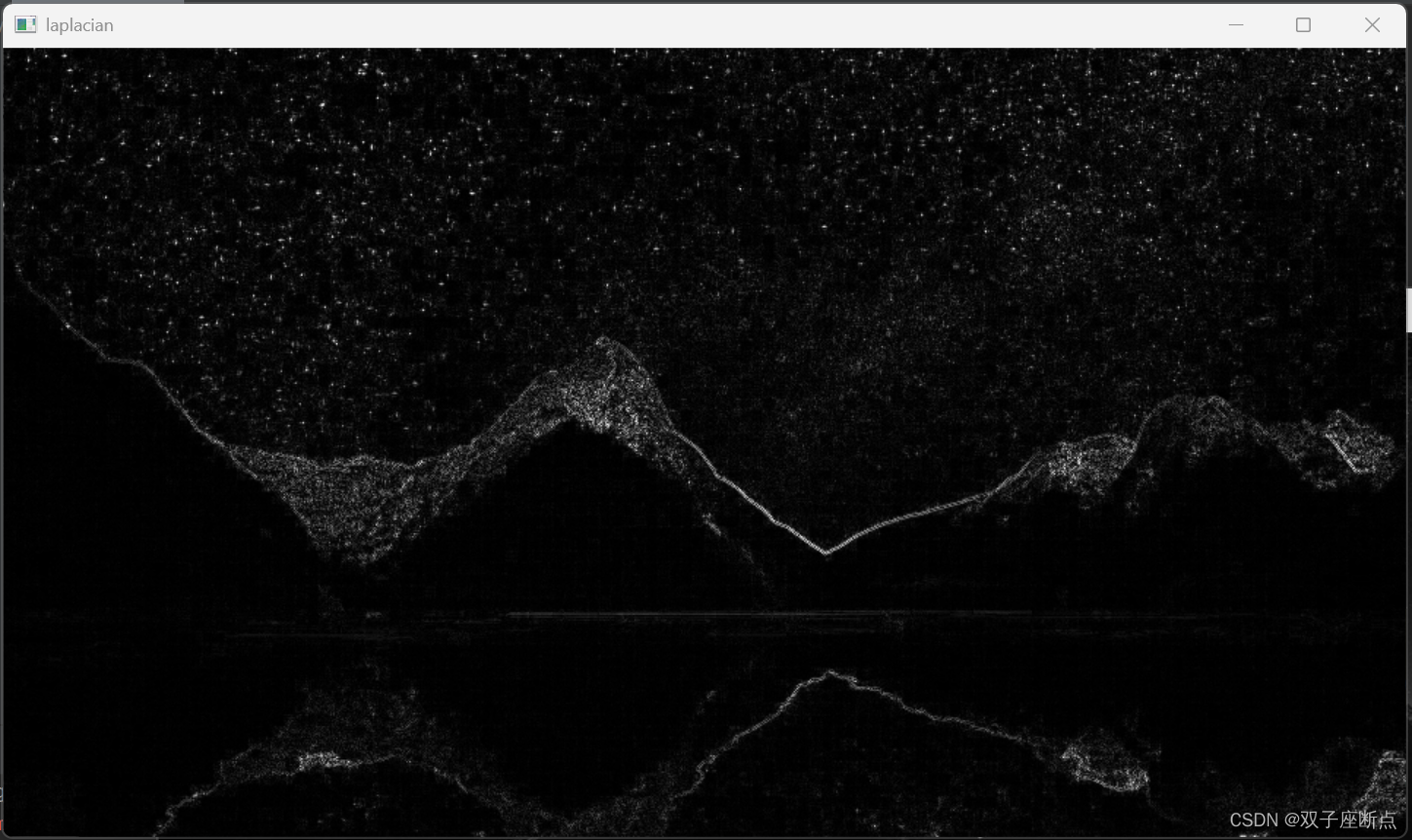
OpenCV 图像梯度算子
本文是OpenCV图像视觉入门之路的第12篇文章,本文详细的介绍了图像梯度算子的各种操作,例如:Sobel算子Scharr算子laplacian算子等操作。 OpenCV 图像梯度算子目录 1 Sobel算子 2 Scharr算子 3 laplacian算子 1 Sobel算子 Sobel算子是一种图…...
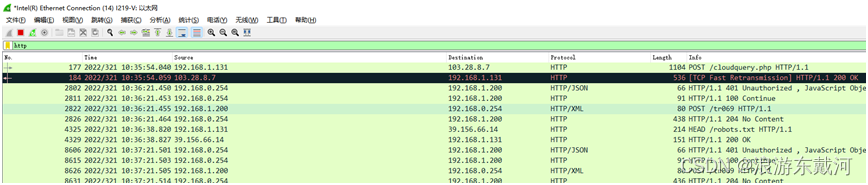
Linux c编程之Wireshark
Wireshark是一个网络报文分析软件,是网络应用问题分析必不可少的工具软件。网络管理员可以使用wireshark排查网络问题。程序开发人员可以用来分析应用协议、定位分析应用问题。无论是网络应用程序开发人员、测试人员、部署人员、技术支持人员,掌握wireshark的使用对于分析网络…...

极客时间_FlinkSQL 实战
一、批处理以及流处理技术发展 1.Lambda架构三层划分Batch Layer、Speed Layer和Serving Layer。 ①、Batch Layer:主要用于实现对历史数据计算结果的保存,每天计算的结果都保存成为一个Batch View,然后通过对Batch View的计算,实现历史数据的计算。 ②、Speed Layer正是用…...
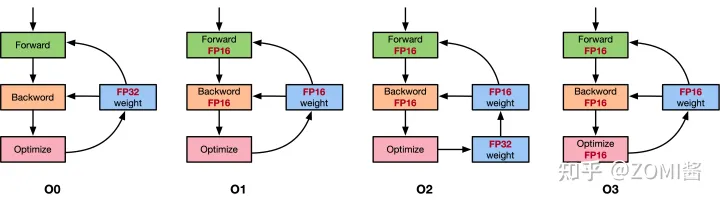
Pytorch 混合精度训练 (Automatically Mixed Precision, AMP)
Contents混合精度训练 (Mixed Precision Training)单精度浮点数 (FP32) 和半精度浮点数 (FP16)为什么要用 FP16为什么只用 FP16 会有问题解决方案损失缩放 (Loss Scaling)FP32 权重备份黑名单Tensor CoreNVIDIA apex 库代码解读opt-level (o1, o2, o3, o4)apex 的 o1 实现apex …...

使用太极taichi写一个只有一个三角形的有限元
公式来源 https://blog.csdn.net/weixin_43940314/article/details/128935230 GAME103 https://games-cn.org/games103-slides/ 初始化我们的三角形 全局的坐标范围为0-1 我们的三角形如图所示 ti.kernel def init():X[0] [0.5, 0.5]X[1] [0.5, 0.6]X[2] [0.6, 0.5]x[0…...
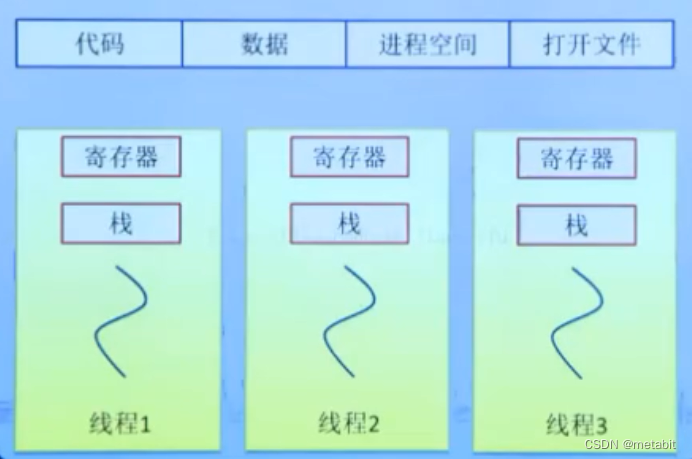
进程,线程
进程是操作系统分配资源的基本单位,线程是CPU调度的基本单位。 PCB:进程控制块,操作系统描述程序的运行状态,通过结构体task,struct{…},统称为PCB(process control block)。是进程管理和控制的…...

第03章_基本的SELECT语句
第03章_基本的SELECT语句 讲师:尚硅谷-宋红康(江湖人称:康师傅) 官网:http://www.atguigu.com 1. SQL概述 1.1 SQL背景知识 1946 年,世界上第一台电脑诞生,如今,借由这台电脑发展…...

干货 | 简单了解运算放大器...
运算放大器发明至今已有数十年的历史,从最早的真空管演变为如今的集成电路,它在不同的电子产品中一直发挥着举足轻重的作用。而现如今信息家电、手机、PDA、网络等新兴应用的兴起更是将运算放大器推向了一个新的高度。01 运算放大器简述运算放大器&#…...
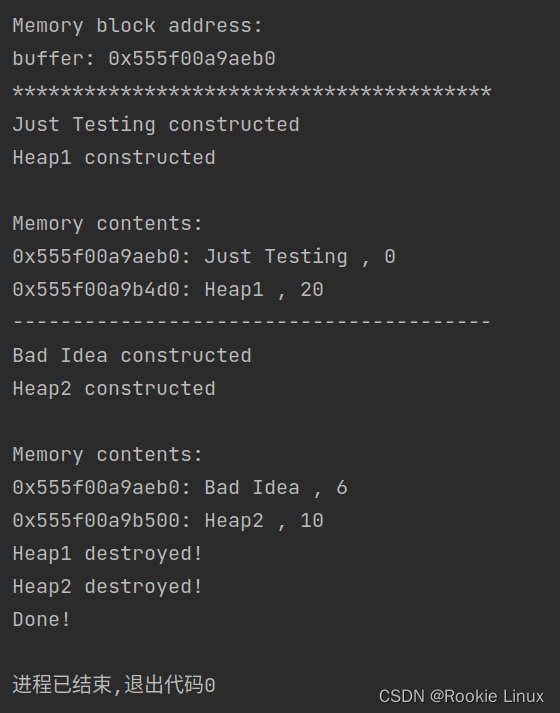
C++定位new用法及注意事项
使用定位new创建对象,显式调用析构函数是必须的,这是析构函数必须被显式调用的少数情形之一!, 另有一点!!!析构函数的调用必须与对象的构造顺序相反!切记!!&a…...

【Android笔记75】Android之翻页标签栏PagerTabStrip组件介绍及其使用
这篇文章,主要介绍Android之翻页标签栏PagerTabStrip组件及其使用。 目录 一、PagerTabStrip翻页标签栏 1.1、PagerTabStrip介绍 1.2、PagerTabStrip的使用 (1)创建布局文件...

【Kafka】【二】消息队列的流派
消息队列的流派 ⽬前消息队列的中间件选型有很多种: rabbitMQ:内部的可玩性(功能性)是⾮常强的rocketMQ: 阿⾥内部⼀个⼤神,根据kafka的内部执⾏原理,⼿写的⼀个消息队列中间 件。性能是与Kaf…...

现代 cmake (cmake 3.x) 操作大全
cmake 是一个跨平台编译工具,它面向各种平台提供适配的编译系统配置文件,进而调用这些编译系统完成编译工作。cmake 进入3.x 版本,指令大量更新,一些老的指令开始被新的指令集替代,并加入了一些更加高效的指令/参数。本…...
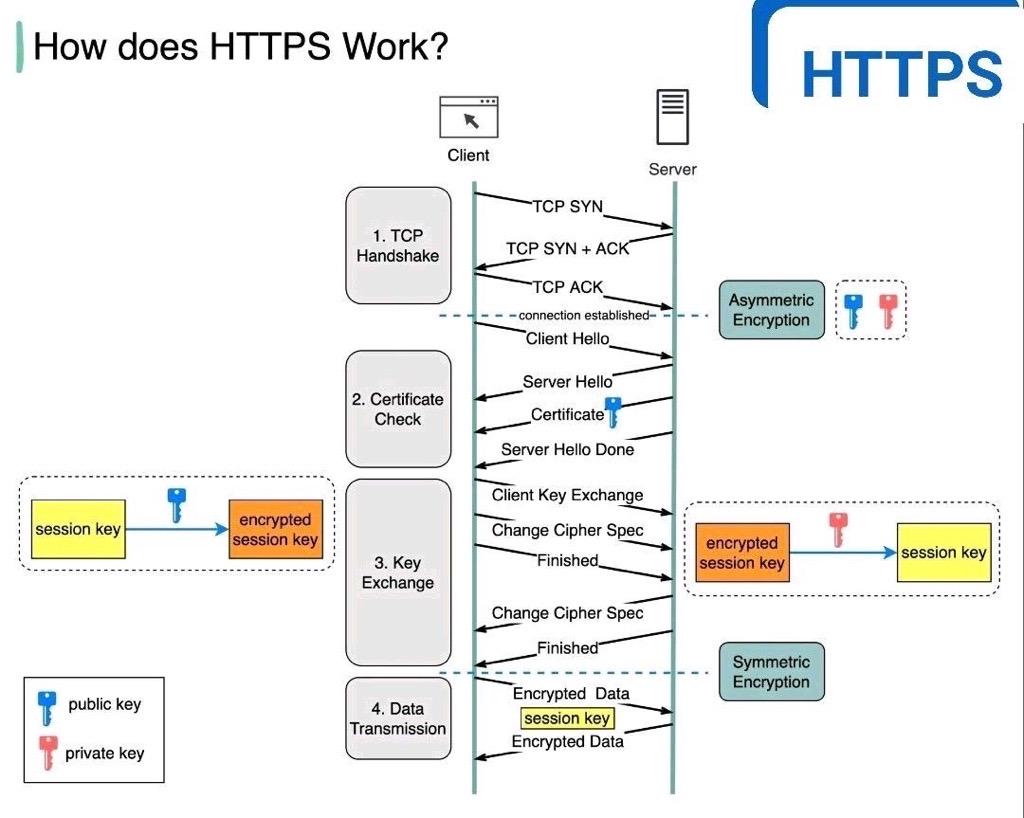
how https works?https工作原理
简单一句话: https http TLShttps 工作原理:HTTPS (Hypertext Transfer Protocol Secure)是一种带有安全性的通信协议,用于在互联网上传输信息。它通过使用加密来保护数据的隐私和完整性。下面是 HTTPS 的工作原理:初始化安全会…...

Docker的资源控制管理
目录 一、CPU控制 1、设置CPU使用率上限 2、设置CPU资源占用比(设置多个容器时才有效) 3、设置容器绑定指定的CPU 二、对内存使用进行限制 1、创建指定物理内存的容器 2、创建指定物理内存和swap的容器 3、 对磁盘IO配额控制(blkio&a…...

MMSeg无法使用单类自定义数据集训练
文章首发及后续更新:https://mwhls.top/4423.html,无图/无目录/格式错误/更多相关请至首发页查看。 新的更新内容请到mwhls.top查看。 欢迎提出任何疑问及批评,非常感谢! 摘要:将三通道图像转为一通道图像,…...

Redis使用方式
一、Redis基础部分: 1、redis介绍与安装比mysql快10倍以上 *****************redis适用场合**************** 1.取最新N个数据的操作 2.排行榜应用,取TOP N 操作 3.需要精确设定过期时间的应用 4.计数器应用 5.Uniq操作,获取某段时间所有数据排重值 6.实时系统,反垃圾系统7.P…...
 枪械名 红字效果 元素属性 清图评分 Boss战评分 泛用性评分 特殊性评分 最终评级 掉落点 掉率 图片 瘟疫传播)
无主之地3重型武器节奏评分榜(9.25) 枪械名 红字效果 元素属性 清图评分 Boss战评分 泛用性评分 特殊性评分 最终评级 掉落点 掉率 图片 瘟疫传播
无主之地3重型武器节奏评分榜(9.25) 枪械名 红字效果 元素属性 清图评分 Boss战评分 泛用性评分 特殊性评分 最终评级 掉落点 掉率 图片 瘟疫传播者 发射巨大能量球,能量球会额外生成追踪附近敌人的伴生弹 全属性 SSS SSS SSS - T0 伊甸6号-…...

什么是编程什么是算法
1.绪论 编程应在一个开发环境中完成源程序的编译和运行。首先,发现高级语言开发环境,TC,Windows系统的C++,R语言更适合数学专业的学生。然后学习掌握编程的方法,在学校学习,有时间的人可以在网上学习,或者购买教材自学。最后,编写源程序,并且在开发环境中实践。 例如…...

在株洲如何根据个人需求选择合适的床垫?
如何根据个人需求选择合适的床垫?在快节奏的现代生活中,一张舒适的床垫对于保证良好的睡眠质量至关重要。然而,面对市场上琳琅满目的床垫产品,如何根据个人需求选择一款合适的床垫呢?本文将从多个维度出发,…...

流处理优化:提高实时数据处理性能
流处理优化:提高实时数据处理性能 一、流处理优化概述 1.1 流处理优化的定义 流处理优化是指通过优化流处理系统的性能、吞吐量和延迟,提高实时数据处理能力的过程。它涉及优化数据处理管道、资源配置和算法实现。 1.2 流处理优化的价值 低延迟ÿ…...

Windows安卓子系统终极指南:从基础配置到专业开发全流程
Windows安卓子系统终极指南:从基础配置到专业开发全流程 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA 想要在Windows 11上无缝运行安卓应用吗&…...

新媒体编辑提效:OpenClaw批量剪辑短视频、生成文案字幕,适配多平台发布规则
新媒体编辑效率革命:OpenClaw赋能短视频批量剪辑、智能文案生成与多平台适配在信息爆炸、注意力稀缺的移动互联网时代,短视频已成为内容传播的绝对主力军。对于新媒体运营团队而言,高效地产出高质量、符合各平台调性且能快速发布的短视频内容…...

Windows平台即时通讯消息保留技术深度解析:RevokeMsgPatcher企业级解决方案完全手册
Windows平台即时通讯消息保留技术深度解析:RevokeMsgPatcher企业级解决方案完全手册 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) …...

英特尔转型芯片代工:从IDM巨头到服务商的六大挑战与机遇
1. 英特尔代工之路:从IDM巨头到服务提供商的六大挑战在半导体行业,英特尔这个名字几乎就是高性能微处理器的代名词。这家公司凭借其垂直整合制造模式,在过去几十年里构筑了难以撼动的技术护城河。然而,当行业的目光从单纯的制程竞…...

计算机视觉入门:从OpenCV到PyTorch的实践指南
1. 项目概述:从“萌芽”到“入行”的视觉之旅 “对计算机视觉的萌芽迷恋”——这个标题精准地捕捉了无数技术爱好者,包括我自己,最初踏入这个领域时的心路历程。它描述的是一种状态:你或许被一张AI生成的艺术图片所震撼ÿ…...

深入Windows内核的“心脏”:通过WRK源码理解ntoskrnl.exe与HAL的协作机制
深入Windows内核的“心脏”:通过WRK源码理解ntoskrnl.exe与HAL的协作机制 在计算机科学领域,操作系统内核堪称最复杂的软件工程之一。作为Windows操作系统的核心,ntoskrnl.exe与硬件抽象层(HAL)的协作机制长期以来都是开发者们津津乐道的话题…...

基于图特征选择与XGBoost的电动公交预测性维护模型构建
1. 项目概述:从数据洪流到精准预警的挑战在电动公交的日常运营中,车辆控制器局域网(CAN)总线每秒都在产生海量的传感器数据,从电池电压、电机温度到刹车片厚度,这些数据流如同车辆的“生命体征”。预测性维…...

2026年6分钟腾讯云部署OpenClaw/Hermes Agent及使用喂饭级步骤流程
2026年6分钟腾讯云部署OpenClaw/Hermes Agent及使用喂饭级步骤流程。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工…...