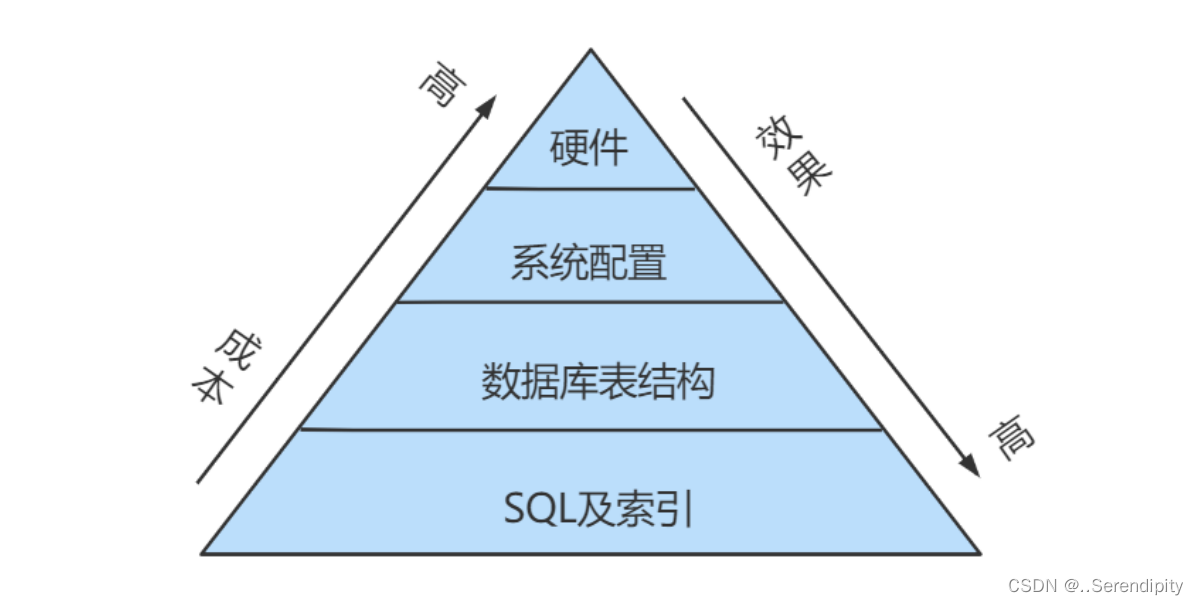
SQL语句性能分析
1. 数据库服务器的优化步骤
当我们遇到数据库调优问题的时候,该如何思考呢?这里把思考的流程整理成下面这张图。
整个流程划分成了 观察(Show status) 和 行动(Action) 两个部分。字母 S 的部分代表观察(会使用相应的分析工具),字母 A 代表的部分是行动(对应分析可以采取的行动)。
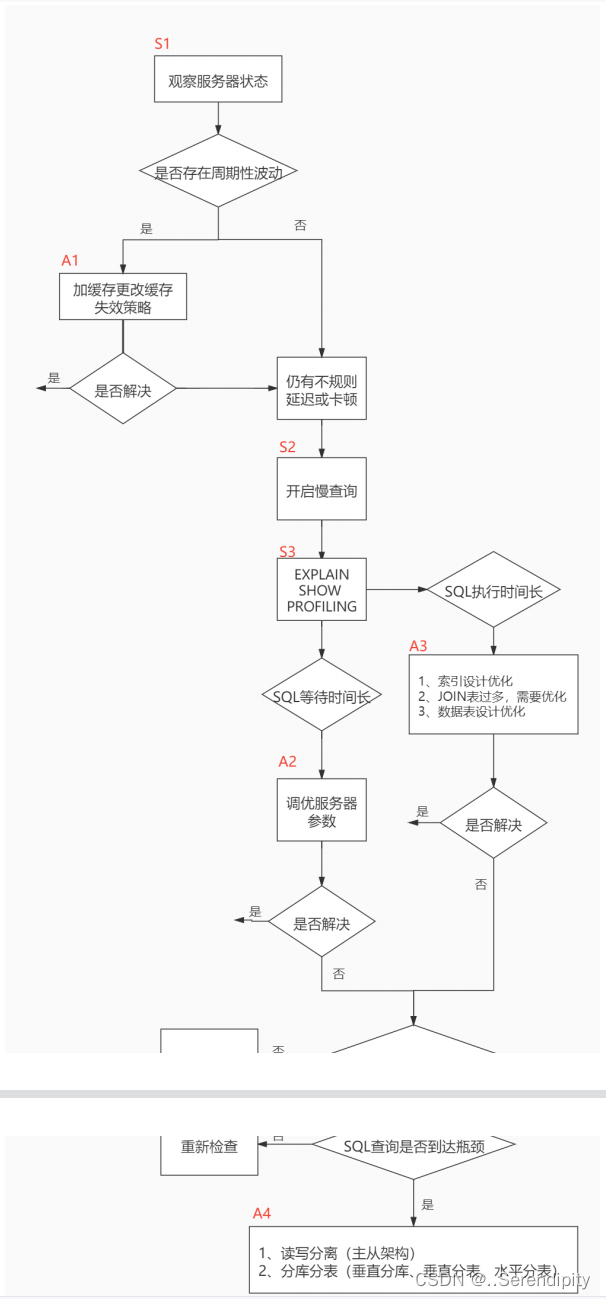
主要的优化手段:
- 加缓存,例如redis
- 调整服务器参数
- 索引的设计优化,SQL语句是否使用到索引?
- 读写,主从分离,分库分表(垂直分库,垂直分表,水平分表)
2. 系统参数
在MySQL中,可以使用 SHOW STATUS 语句查询一些MySQL数据库服务器的 性能参数 、 执行频率 。SHOW STATUS语句语法如下:
SHOW [GLOBAL|SESSION] STATUS LIKE '参数';
global:全局
session:当前会话
一些常用的性能参数如下:
- Connections:连接MySQL服务器的次数。
- Uptime:MySQL服务器的上线时间。
- Slow_queries:慢查询的次数。
- Innodb_rows_read:Select查询返回的行数
- Innodb_rows_inserted:执行INSERT操作插入的行数
- Innodb_rows_updated:执行UPDATE操作更新的行数
- Innodb_rows_deleted:执行DELETE操作删除的行数
- Com_select:查询操作的次数。
- Com_insert:插入操作的次数。对于批量插入的 INSERT 操作,只累加一次。
- Com_update:更新操作的次数。
- Com_delete:删除操作的次数。
show status like 'last_query_cost'查询最近一次查询涉及到的页数
3. 慢查询日志
具体允许时长超过long_query_time值的sql会被记录到慢查询日志中,默认为10,注意不包含10秒,需要超过10秒才会被记录到慢查询日志中
默认情况下是不开启慢查询日志的,需要手动打开
show variables like '%slow_query_log'

开启慢查询日志:
set global slow_query_log='ON';
查看慢日志文件位置
show variables like '%slow_query_log%'

查询慢查询的时间阈值
show variables like '%long_query_time%';

设置慢查询阈值
set global long_query_time = 1;
设置global的方式对当前session的long_query_time失效。对新连接的客户端有效。所以可以一并执行下述语句
set global long_query_time = 1;
set long_query_time = 1;
mysql服务器重启后,设置的慢查询时间阈值就会失效,可以通过配置文件的方式进行永久设置
slow_query_log=ON
slow_query_log_file=/var/lib/mysql/xxxx-slow.log
long_query_time=1
log_output=FILE
如果不指定存储路径,则默认将慢查询日志存储到mysql数据库的数据文件夹下,不指定文件名的话,默认文件名为hostname-slow.log
查看慢查询数目
SHOW GLOBAL STATUS LIKE '%Slow_queries%';
4. 定位慢sql
4.1 开启慢查询日子
set global slow_query_log='ON';
4.2 设置慢查询阈值
set global long_query_time = 1;
4.3 查看慢查询数目
查询当前系统中有多少条慢查询记录
SHOW GLOBAL STATUS LIKE '%Slow_queries%';
4.4 min_examined_row_limit
除了 long_query_time外,控制慢查询日志的还有一个系统变量:min_examined_row_limit。这个变量的意思是,查询扫描过的最少记录数。这个变量和查询执行时间共同组成了判别一个查询是否是慢查询的条件,如果查询扫描过的记录数大于等于这个变量的值,并且查询执行时间超过了 long_query_time的值,那么这个查询就被记录到慢查询日志中,反之,则不会被记录到慢查询日志中
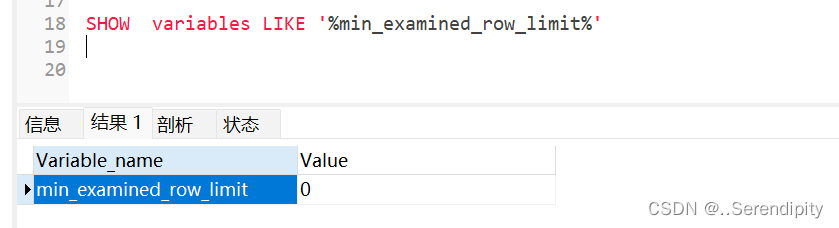
这个值默认是0,可以通过set命令来修改或者修改my.ini文件来进行修改
4.5 具体分析
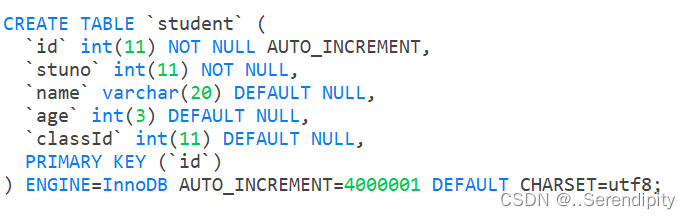
以上表所示,数据量4000000。

执行两条sql,查询时长在1s以上

现在我们的慢sql有5条了(之前有过别的操作增加了慢sql数量)
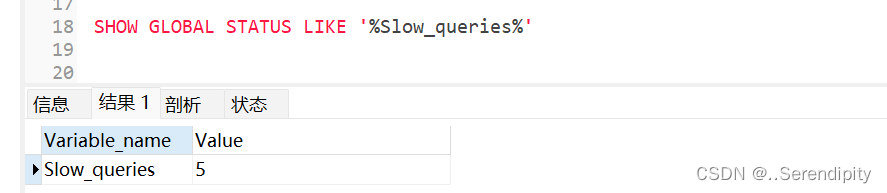
4.6 慢查询日志分析工具:mysqldumpslow
在生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活,MySQL提供了日志分析工具 mysqldumpslow 。
查看mysqldumpslow的帮助信息 mysqldumpslow --help
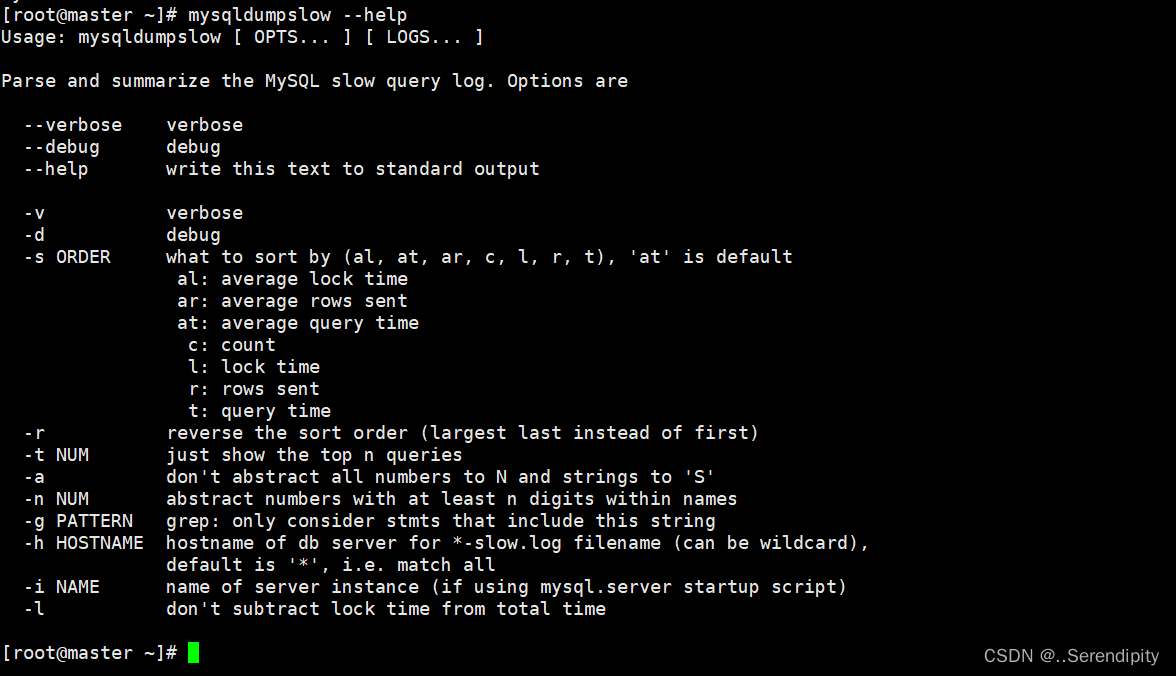
mysqldumpslow 命令的具体参数如下:
-a: 不将数字抽象成N,字符串抽象成S (不加-a,参数就会以N和S替代)
-s: 是表示按照何种方式排序:
c: 访问次数
l: 锁定时间
r: 返回记录
t: 查询时间
al:平均锁定时间
ar:平均返回记录数
at:平均查询时间 (默认方式)
ac:平均查询次数
-t: 即为返回前面多少条的数据;
6 rows in set (2.39 sec)
show status like ‘slow_queries’;
mysqldumpslow --help
-g: 后边搭配一个正则匹配模式,大小写不敏感的;
常用举例:
#得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log
#得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log
#得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/atguigu-slow.log
#另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现爆屏情况
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more
分析慢日志
mysqldumpslow -s -t -t 10 /var/lib/mysql/master-slow.log
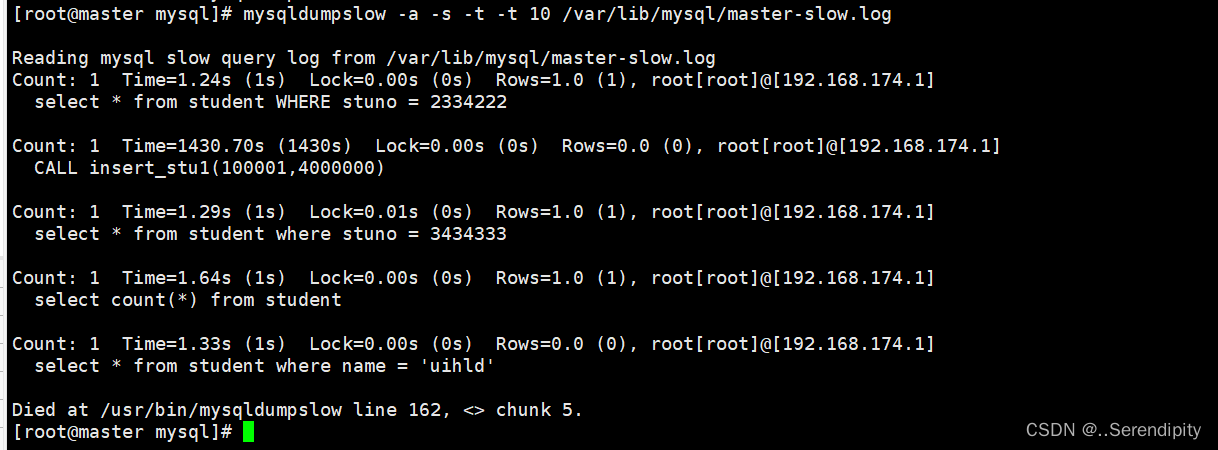
可以观察到我们的慢sql语句,整个顺序是按照耗时降序的
开发中,尽量不打开慢查询日志,会耗费一些性能
如何删除慢查询日志文件 rm命令进行删除
如何重置慢查询日志文件?mysqladmin -uroot -p flush-logs slow
注意:mysqladmin -uroot -p flush-logs 如果不加slow,是重置所有日志文件,包括redo,undo等等。
5 explain
定位了慢查询日志后,我们可以通过explain或describe工具对SQL语句进行分析。
describe的使用方法与explain一样,并且分析结果也是一样。
mysql中会为查询语句提供它认为最优的执行计划,但是并不一定是最优的
版本情况
MySQL 5.6.3以前只能 EXPLAIN SELECT ;MYSQL 5.6.3以后就可以 EXPLAIN SELECT,UPDATE,DELETE
在5.7以前的版本中,想要显示 partitions 需要使用 explain partitions 命令;想要显示filtered 需要使用 explain extended 命令。在5.7版本后,默认explain直接显示partitions和filtered中的信息。

5.1 语法
EXPLAIN 或 DESCRIBE语句的语法形式如下:
EXPLAIN SELECT select_options
DESCRIBE SELECT select_options
例如


explain的具体各个结果的意义
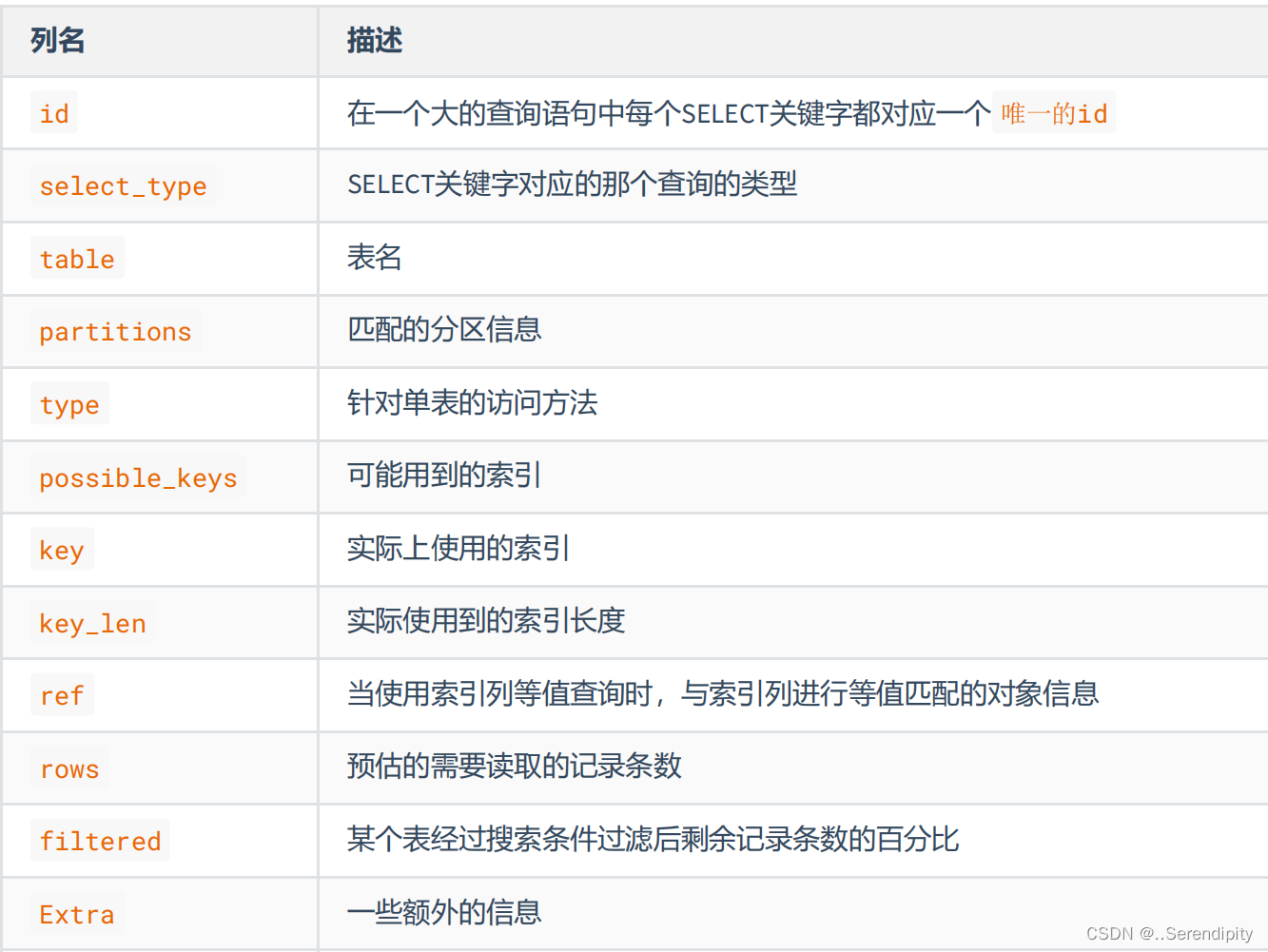
5.2 explain各列作用
准备表结构与数据:每张表含10000条数据
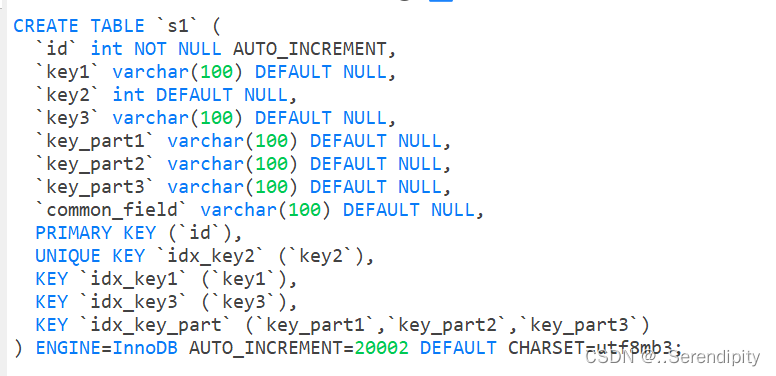
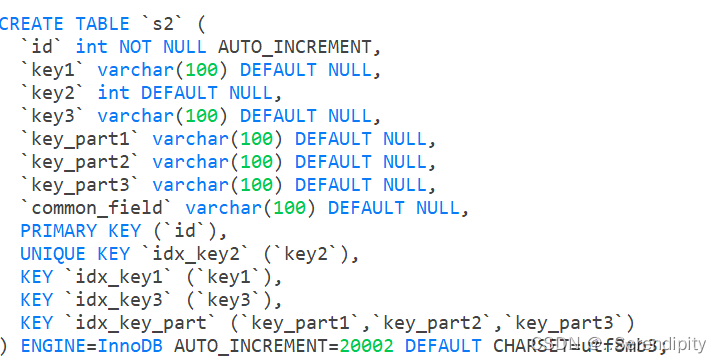
5.2.1 table
table:表名


注意:这里的table的个数不一定是我们sql语句里的个数,还有可能包含临时表等。查询的每一行记录都对应着一个单表,临时表也会对应一个记录。
5.2.2 id
- 在一个大的查询中,每个select关键字都对应一个id
- 该语句的唯一标识。如果explain的结果包括多个id值,则数字越大越先执行
- 而对于相同id的行,则表示从上往下依次执行。
- id号的每个号码代表一趟独立的查询,一个sql语句查询趟数越少越好
举例:一个select
SELECT * FROM s1 INNER JOIN s2 ON s1.key1 = s2.key1 WHERE s1.common_field = 'a';

两个select
EXPLAIN SELECT * FROM s1 UNION ALL SELECT * FROM s2

虚表的情况
EXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2;

特殊情况:
EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key2 FROM s2 WHERE common_field = 'a');

为什么上述sql有两个select,但是id就只有1呢?因为mysql优化器对sql语句进行了重写,原sql复杂度是n*n,优化器给优化为外连接的sql,即2n复杂度。
5.2.3 select_type

5.2.4 partitions
代表分区的命中情况,非分区表,该值为null,一般情况下,查询语句的partitions列都为null
5.2.5 type
- 性能由好到最坏依次是: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
- SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,最好是 consts级别。(阿里巴巴开发手册要求)
5.2.5.1 system
当表中只有一条记录,并且该表使用的存储引擎的统计数据是精确的,比如 MyISAM,Memory,那么对该表访问方法就是system
CREATE TABLE t(i int) Engine=MyISAM;INSERT INTO t VALUES(1);EXPLAIN SELECT * FROM t;

5.2.5.2 const
当我们根据主键或者唯一二级索引列与常数进行等值匹配时,对单表的访问方法就是 const
EXPLAIN SELECT * FROM s1 WHERE id = 10005;

5.2.5.3 eq_ref
在连接查询时,如果被驱动表时通过主键或者唯一二级索引列等值匹配的方式进行访问的(如果该主键或者唯一二级索引是联合索引的话,所有的索引列都必须进行等值比较),则对该被驱动表的访问方法就是eq_ref
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id = s2.id;

5.2.5.4 ref_or_null
当通过普通的二级索引进行等值匹配查询,该索引列的值也可以是null值时,那么对该表的访问方法就可能是ref_or_null
explain select * from s1 where key1 = 'a' or key1 is null

5.2.5.5 index_merge
在某些场景下,可以使用索引合并的方法来执行查询
explain select * from s1 where key1 = 'a' or key3 = 'a'

但是如果把or换成and
explain select * from s1 where key1 = 'a' and key3 = 'a'

5.2.5.6 unique_subquery
它是针对在一些包含in子查询的查询语句中,如果查询优化器决定将in子查询转为exists子查询,并且子查询可以使用到主键进行等值匹配的话,那么该子查询的type就是unique_subquery
EXPLAIN SELECT * FROM s1 WHERE key2 IN (SELECT id FROM s2 where s1.key1 =
s2.key1) OR key3 = 'a';

5.2.5.7 range
如果使用索引获取某些范围的记录,那么有可能使用到range
EXPLAIN SELECT * FROM s1 WHERE key1 IN ('a', 'b', 'c');

5.2.5.8 index
当我们可以使用索引覆盖,但是需要扫描全部索引记录时,访问方法就是index
EXPLAIN SELECT key_part2 FROM s1 WHERE key_part3 = 'a';

按照最左匹配原则来看,应该是用不上索引的,但是由于我们查询的列和筛选条件都在联合索引中,所以就用上了索引
例如我们在查询字段中多加一列
EXPLAIN SELECT key1,key_part2 FROM s1 WHERE key_part3 = 'a';

5.2.5.9 all
EXPLAIN SELECT * FROM s1;

5.2.6 key和possible_keys
possible_keys:代表可能用到的索引
key:实际使用的索引
5.2.7 key_len
实际使用到的索引长度(即字节数),值越大越好(主要针对于联合索引)
5.2.8 ref
当使用索引列进行等值查询时,与索引进行等值匹配的对象的信息
select * from s1 where key1 = 'a'

select * from s1 inner join s2 on s1.id = s2.id

select * from s1 inner join s2 on s2.key1 = upper(s1.key1)

5.2.9 rows
预估需要读取的记录的条目数,该值越小越好
SELECT * FROM s1 WHERE key1 > 'z';

5.2.10 filtered
某个表经过搜索条件过滤后剩余记录数的百分比
对于单表查询来说,这个filtered没什么意义,例如
SELECT * FROM s1 WHERE key1 > 'z';

rows是359,filtered是100,那么查询的数据也是359

在连接查询中,驱动表对应的执行计划记录的filtered值,它决定了被驱动表要执行的次数(即 rows*filtered)
SELECT * FROM s1 WHERE key1 > 'z' AND common_field = 'a';

即key1>'z’的rows有359条数据,然后执行and common_field=‘a’时满足的数据量在 359*10%,
5.2.11 Extra
用来说明一些额外信息,包含不适合在其他列中显示,但十分重要的额外信息,我们可以通过这些额外信息来更准确的理解Mysql到底如何执行给定的查询语句。
例如:
5.2.11.1. No Tables used
select 1

5.2.11.2. Impossible WHERE
SELECT * FROM s1 WHERE 1 != 1;

5.2.11.3. Using where
当我们使用全表扫描来执行对某个表的查询,并且该语句的where子句中有针对该表的搜索条件时,在Extra中会提示Using where
SELECT * FROM s1 WHERE common_field = 'a';

5.2.11.4. No matching min/max row
当查询列表处有min或者max聚合函数,但是并没有符合where自居中的搜索条件记录时,就会提示该信息
SELECT MIN(key1) FROM s1 WHERE key1 = 'abcdefg';

那如果不使用函数呢?
SELECT key1 FROM s1 WHERE key1 = 'abcdefg';

5.2.11.5. Using index
当我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是在可以使用覆盖索引的情况下,在Extra列将会提示Using index
SELECT key1 FROM s1 WHERE key1 = 'a';

5.2.11.6. Using index condition
有些搜索条件虽然使用到了索引列,但是却不能使用到索引
SELECT * FROM s1 WHERE key1 > 'z' AND key1 LIKE '%a';

如果查询语句中的执行过程将要使用索引下推的特性,则extra会显示Using index condition
5.2.11.7. join buffer
当被驱动表不能有效的利用索引来加快访问速度,mysql会为其分配一块 join buffer的内存块来加快查询速度,也就是基于块的嵌套循环算法
SELECT * FROM s1 INNER JOIN s2 ON s1.common_field = s2.common_field;

5.2.11.8. Using where; Not exists
当我们使用左外连接时,如果where子句中包含要求被驱动表的某个列等于null的搜索条件,但是那个列又是不允许为null的,那么在该表的执行计划的extra列就会提示 not exists
SELECT * FROM s1 LEFT JOIN s2 ON s1.key1 = s2.key1 WHERE s2.id IS NULL;
5.2.11.9. Using intersect(…) 、 Using union(…) 和 Using sort_union(…)
就是索引合并的意思,
SELECT * FROM s1 WHERE key1 = 'a' OR key3 = 'a';

5.2.11.10. Zero limit
SELECT * FROM s1 LIMIT 0;
5.2.11.11. Using filesort
SELECT * FROM s1 ORDER BY common_field LIMIT 10;

因为我们的common_field没有索引,但是如果要做排序,则只能读取到内存中进行排序 using filesort。mysql把这种在内存中或者磁盘上进行排序的方式统称为文件排序filesort。
如果列有索引,例如key1
SELECT * FROM s1 ORDER BY key1 LIMIT 10;

5.2.11.12. Using temporary
使用临时表。在许多查询的执行过程中,mysql可能会借助临时表来完成一些功能,比如去重,排序等,比如许多查询中包含distinct,groupby,union等子句的查询过程中,如果不能有效利用索引来完成查询,mysql很有可能寻求建立内部临时表来执行查询,如果使用到了临时表,则extra会显示using temporary
SELECT DISTINCT common_field FROM s1;
SELECT common_field, COUNT(*) AS amount FROM s1 GROUP BY common_field;

例如有索引的情况下
SELECT key1, COUNT(*) AS amount FROM s1 GROUP BY key1;

5.2.11.14 总结
- EXPLAIN不考虑各种Cache
- EXPLAIN不能显示MySQL在执行查询时所作的优化工作
- EXPLAIN不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况
- 部分统计信息是估算的,并非精确值,例如rows
5.3 explain的进一步使用
5.3.1. 传统格式
传统格式简单明了,输出是一个表格形式,概要说明查询计划。

5.3.2 json格式
json提示的信息量会更全面一些。例如查询成本 query_cost
EXPLAIN FORMAT=JSON SELECT ....
EXPLAIN FORMAT=JSON SELECT key1, COUNT(*) AS amount FROM s1 GROUP BY key1;
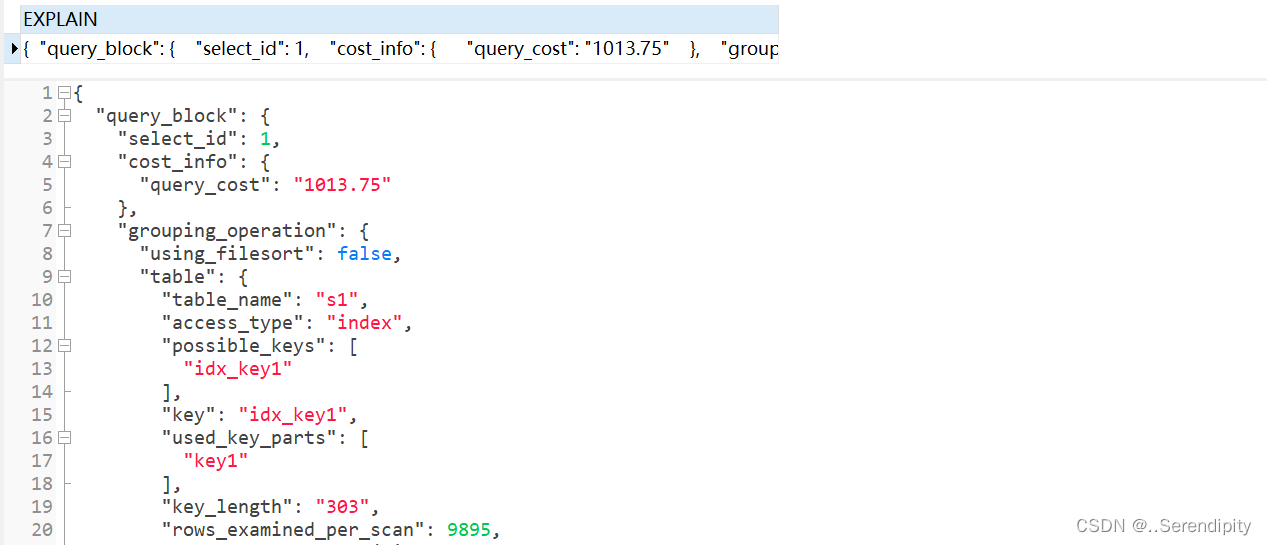
{"query_block": {"select_id": 1,"cost_info": {"query_cost": "1013.75"},"grouping_operation": {"using_filesort": false,"table": {"table_name": "s1","access_type": "index","possible_keys": ["idx_key1"],"key": "idx_key1","used_key_parts": ["key1"],"key_length": "303","rows_examined_per_scan": 9895,"rows_produced_per_join": 9895,"filtered": "100.00","using_index": true,"cost_info": {"read_cost": "24.25","eval_cost": "989.50","prefix_cost": "1013.75","data_read_per_join": "17M"},"used_columns": ["id","key1"]}}}
}
eval_cost 是这样计算的:
检测 rows × filter 条记录的成本。
prefix_cost 就是单独查询 s1 表的成本,也就是:read_cost + eval_cost
data_read_per_join 表示在此次查询中需要读取的数据量。
如果是针对多表连接查询
被驱动表,可能被读取多次,这里的 read_cost 和 eval_cost 是访问多次被驱动表后累加起来的值,大家主要关注里边儿的 prefix_cost 的值代表的是整个连接查询预计的成本,也就是单次查询驱动表和被驱动表后的成本的和
5.3.3 TREE格式
EXPLAIN FORMAT=tree SELECT ....
TREE格式是8.0.16版本之后引入的新格式,主要根据查询的 各个部分之间的关系和各部分的执行顺序来描述如何查询。
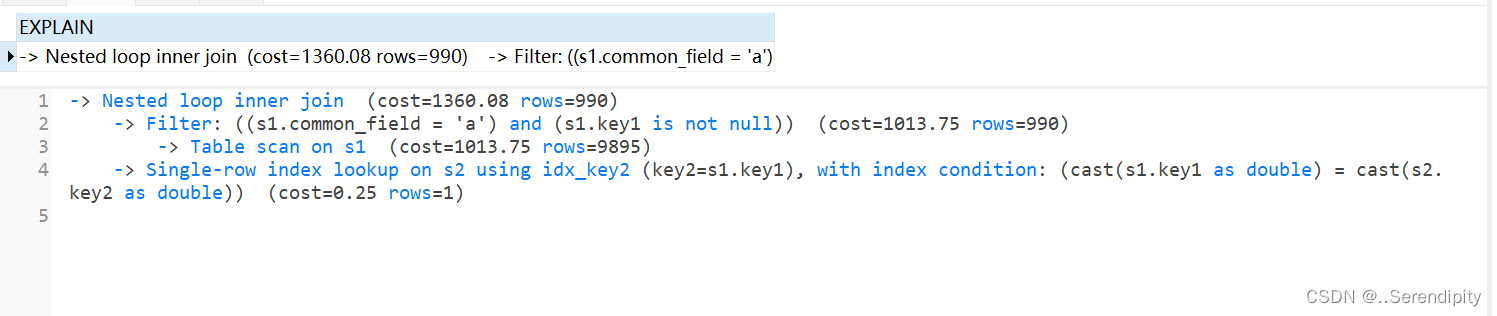
5.4 索引下推
Using index condition
有些搜索条件虽然使用到了索引列,但是却不能使用到索引
SELECT * FROM s1 WHERE key1 > 'z' AND key1 LIKE '%a';
key1>'z’可以使用到索引,但是key1 like '%a’却无法使用到索引,在以前的mysql版本中,是按照如下步骤进行查询
- 根据key1>'z’来获取满足条件的二级索引记录
- 根据步骤1的结果得到主键值进行回表
- 回表中进行like操作
但是like操作也只涉及到了key1列,所以mysql对上述进行了优化
- 根据key1>'z’获取二级索引
- 从获取的二级索引来进行like比对过滤(如果有值则回表,如果没有就结束)
- 回表
mysql将这个改进成为索引下推
如果查询语句中的执行过程将要使用索引下推的特性,则extra会显示Using index condition
相关文章:
SQL语句性能分析
1. 数据库服务器的优化步骤 当我们遇到数据库调优问题的时候,该如何思考呢?这里把思考的流程整理成下面这张图。 整个流程划分成了 观察(Show status) 和 行动(Action) 两个部分。字母 S 的部分代表观察&…...

【K3s】第28篇 详解 k3s-killall.sh 脚本
目录 k3s-killall.sh 脚本 k3s-killall.sh 脚本 为了在升级期间实现高可用性,当 K3s 服务停止时,K3s 容器会继续运行。 要停止所有的 K3s 容器并重置容器的状态,可以使用k3s-killall.sh脚本。 killall 脚本清理容器、K3s 目录和网络组件&a…...

生成时序异常样本-学习记录-未完待续
1.GAN&VAE|时间序列生成及异常注入那些事儿:主要讲了数据增广,用GAN、WGAN、DCGAN、VAE,有给几个代码的github的链接,非常有用 2.时序异常检测综述,写的非常好 3.自编码器原理讲解,后面还附…...
自定义类型的超详细讲解ᵎᵎ了解结构体和位段这一篇文章就够了ᵎ
目录 1.结构体的声明 1.1基础知识 1.2结构体的声明 1.3结构体的特殊声明 1.4结构体的自引用 1.5结构体变量的定义和初始化 1.6结构体内存对齐 那对齐这么浪费空间,为什么要对齐 1.7修改默认对齐数 1.8结构体传参 2.位段 2.1什么是位段 2.2位段的内存分配…...
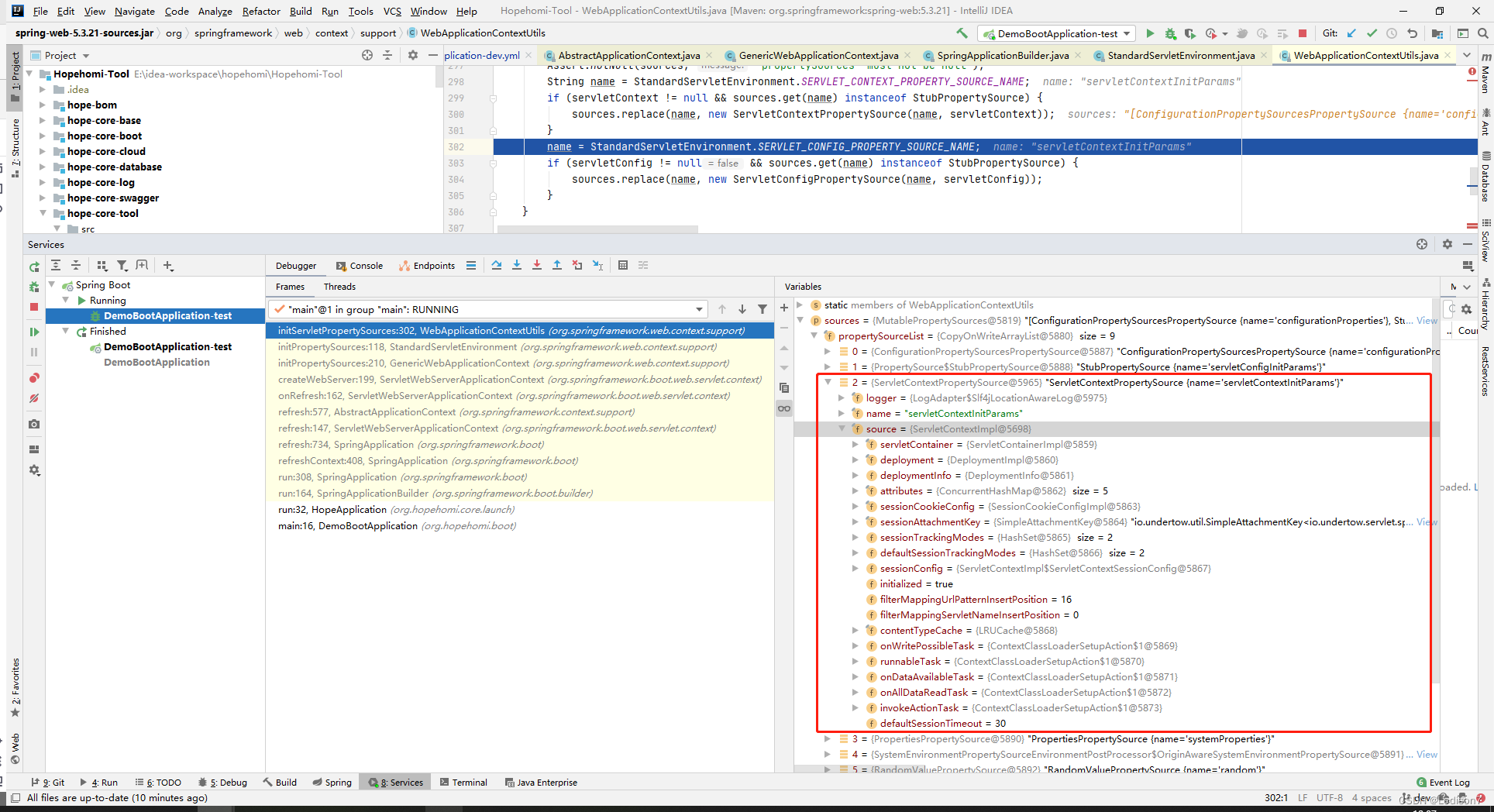
【五】springboot启动源码 - onRefresh
onRefresh 源码解析 Initialize other special beans in specific context subclasses. 核心是创建一个web服务容器(并未在这个方法启动) createWebServer第182行,获取ServletWebServerFactory的具体实现 getWebServerFactory方法ÿ…...
)
带你一文透彻学习【PyTorch深度学习实践】分篇——线性回归(训练周期:前馈、反馈、权重更新)
“梦想使你迷醉,距离就成了快乐;追求使你充实,失败和成功都是伴奏;当生命以美的形式证明其价值的时候,幸福是享受,痛苦也是享受。” --------史铁生《好运设计》 🎯作者主页:追光者♂🔥 🌸个人简介:计算机专业硕士研究生💖、2022年CSDN博客之星人工…...
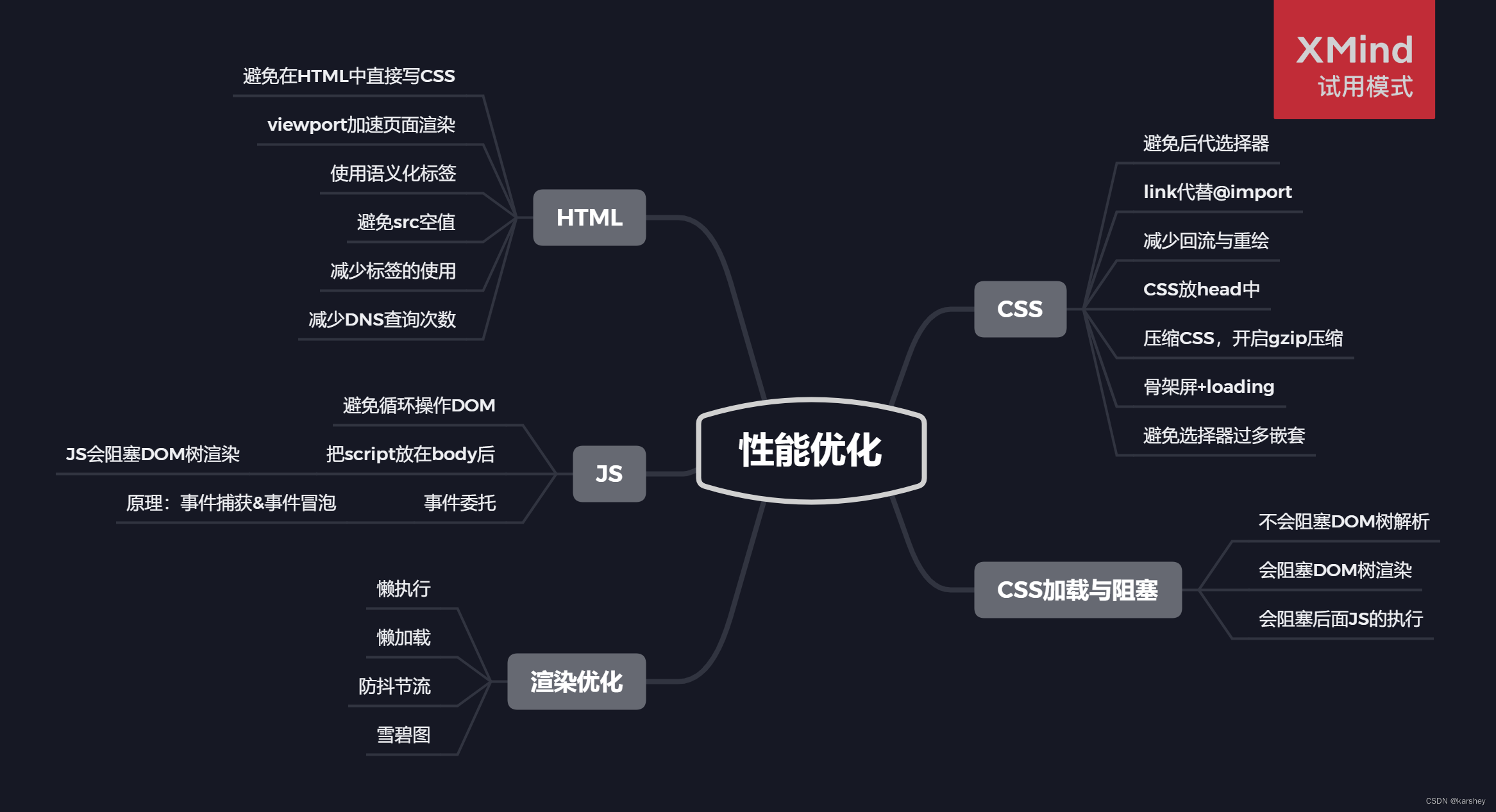
【前端八股文】浏览器系列:性能优化——HTML、CSS、JS、渲染优化
文章目录HTMLCSSCSS加载会造成阻塞吗JavaScript渲染优化参考本系列目录:【前端八股文】目录总结 是以《代码随想录》八股文为主的笔记。详情参考在文末。 代码随想录的博客_CSDN博客-leecode题解,ACM题目讲解,代码随想录领域博主 性能优化,从以下几个方…...

Linux分文件编程:静态库与动态库的生成和使用
目录 一,Linux库引入之分文件编程 ① 简单说明 ② 分文件编程优点 ③ 操作逻辑 ④ 代码实现说明 二,Linux库的基本说明 三,Linux库之静态库的生成与使用 ① 静态库命名规则 ② 静态库制作步骤 ③ 静态库的使用 四,Linu…...

技术人的管理学-业务管理
主要内容前言制定计划遇到的问题?过程监控遇到的问题?复盘改进遇到的问题?通过PDCA循环解决业务管理问题总结前言 没有人天生就会管理,优秀的管理者都是在知行合一的过程中成长起来的,他们既需要系统的管理知识&#…...
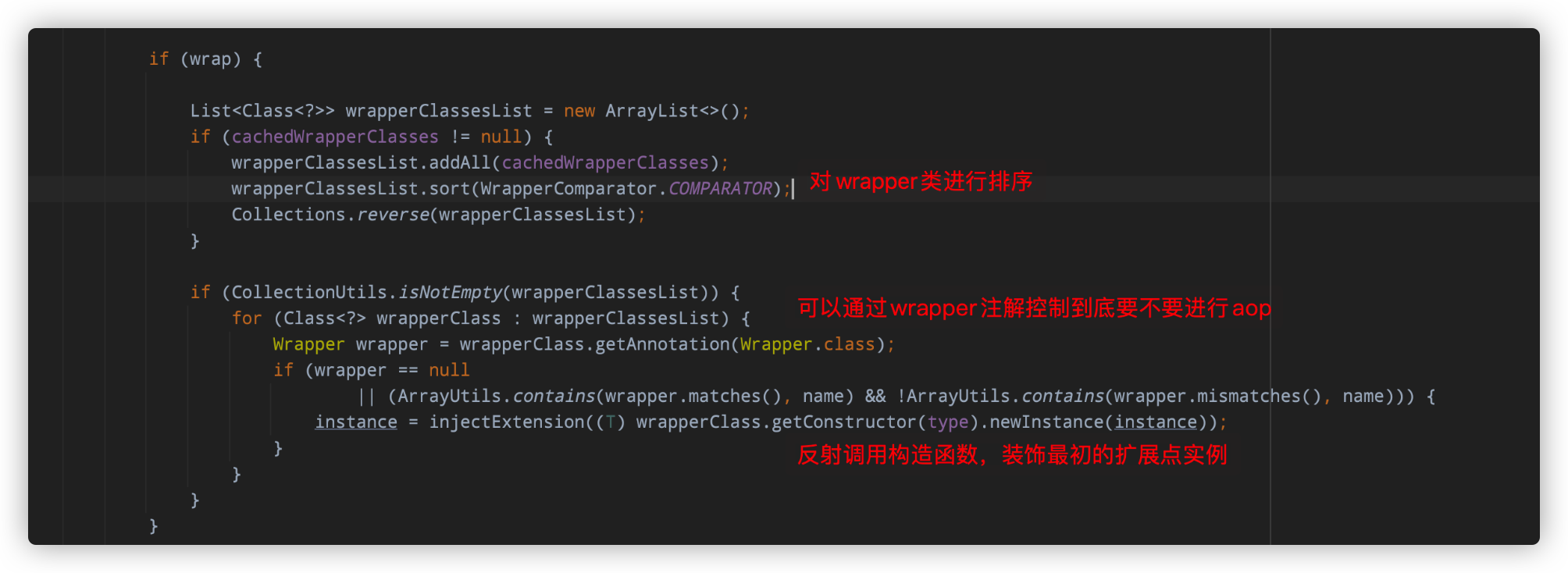
Dubbo的独门绝技,SPI实现原理分析
文章目录前言普通SPI实现原理实例化扩展点源码分析扩展点加载流程分析LoadingStrategy分析接口定义接口实现加载原理loadClass方法分析自适应SPI实现原理自适应扩展代码生成分析自激活SPI简单使用原理分析Activate注解源码分析IOC实现原理objectFactory介绍总结AOP实现原理总结…...
单例模式,饿汉与懒汉
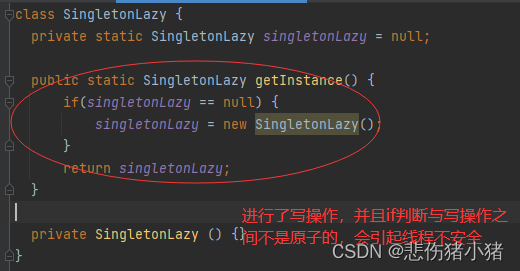
文章目录什么是单例模式单例模式的两种形式饿汉模式懒汉模式懒汉模式与饿汉模式是否线程安全懒汉模式的优化什么是单例模式 单例模式其实就是一种设计模式,跟象棋的棋谱一样,给出一些固定的套路帮助你更好的完成代码。设计模式有很多种,单例…...
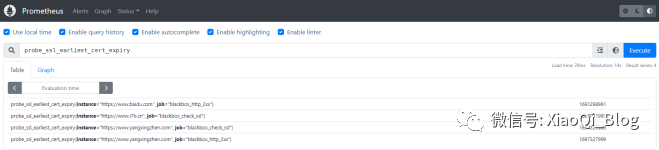
Prometheus监控实战之Blackbox_exporter黑盒监测
1 Blackbox_exporter应用场景 blackbox_exporter是Prometheus官方提供的exporter之一,可以提供HTTP、HTTPS、DNS、TCP以及ICMP的方式对网络进行探测。 1.1 HTTP 测试 定义 Request Header信息 判断 Http status / Http Respones Header / Http Body内容 1.2 TC…...
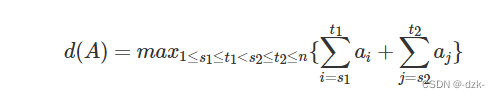
【蓝桥杯集训·每日一题】AcWing 1051. 最大的和
文章目录一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解三、知识风暴线性DP一、题目 1、原题链接 1051. 最大的和 2、题目描述 对于给定的整数序列 A{a1,a2,…,an},找出两个不重合连续子段,使得两子段中所有数字的和最…...

【Unity工具,简单应用】Photon + PUN 2,做一个简单多人在线聊天室
【Unity工具,简单应用】Photon PUN 2,做一个简单多人聊天室前置知识,安装,及简单UI大厅聊天室简单同步较复杂同步自定义同步最终效果前置知识,安装,及简单UI 【Unity工具,简单学习】PUN 2&…...

程序员增加收入实战 让小伙伴们都加个鸡腿
文章目录前言1️⃣一、发外包平台💁🏻♂️二、朋友介绍✍️三、打造自己的个人IP👋🏿四、混群拉单🤳🏿五、面试拉单💻六、技术顾问🦴七、开发个人项目总结:前言 程序员…...
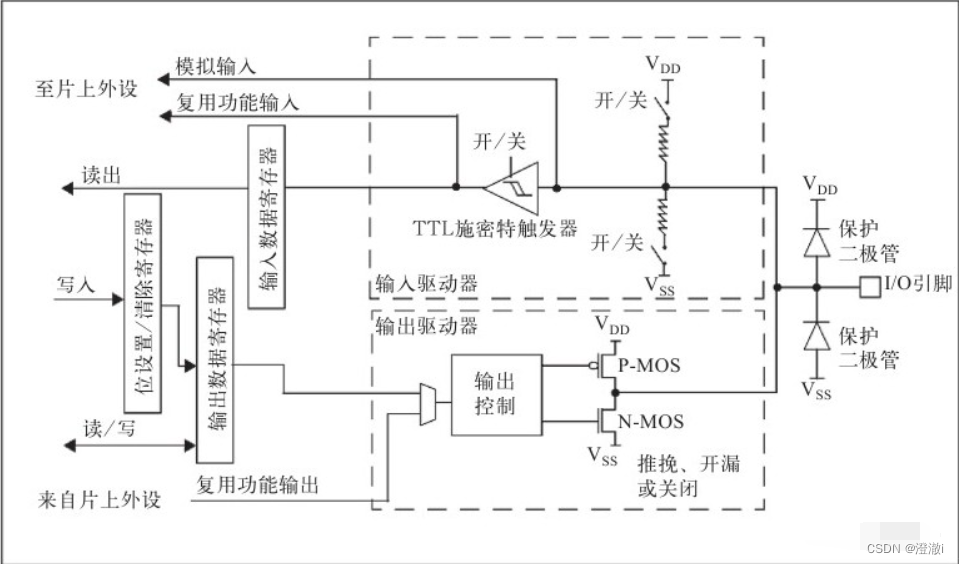
GPIO四种输入和四种输出模式
GPIO的结构图如下所示: 最右端为I/O引脚,左端的器件位于芯片内部。I/O引脚并联了两个用于保护的二极管。 输入模式 从I/O引脚进来就遇到了两个开关和电阻,与VDD相连的为上拉电阻,与VSS相连的为下拉电阻。再连接到TTL施密特触发…...
ChatGPT能够改变时代吗?一点点思考
都知道ChatGPT的出现对整个世界产生了剧烈的影响,前不久出的ChatGPT4更是在ChatGPT3.5的基础上展现了更强的功能。比如说同一个问题,ChatGPT3.5还是乱答的,ChatGPT4已经能给出正确解了。当然这只能说明技术是进步的。 虽然如此,很…...

Markdown如何使用详细教程
目录 一、Markdown 标题 二、Markdown 段落 三、Markdown 字体 四、Markdown 分隔线 五、Markdown 列表 六、Markdown 引用 七、Markdown 代码 八、Markdown 链接 九、Markdown 图片 十、Markdown 表格 前言 当前许多网站都广泛使用 Markdown 来撰写博客,…...

HTML5庆祝生日蛋糕烟花特效
HTML5庆祝生日蛋糕烟花特效 <!DOCTYPE html> <html> <head><meta charset"UTF-8"><title>HTML5 Birthday Cake Fireworks</title><style>canvas {position: absolute;top: 0;left: 0;z-index: -1;}</style> </h…...
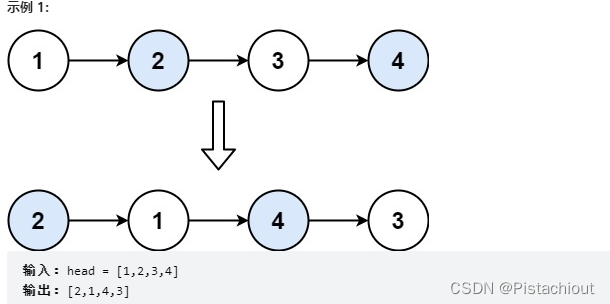
算法套路四——反转链表
算法套路四——反转链表 算法示例一:LeetCode206. 反转链表 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 初始化pre为空,cur为头指针 pre指针:记录当前结点的前一个结点 cur指针:记录当…...

dmview.ocx文件丢失找不到 打不开程序 免费下载方法分享
在使用电脑系统时经常会出现丢失找不到某些文件的情况,由于很多常用软件都是采用 Microsoft Visual Studio 编写的,所以这类软件的运行需要依赖微软Visual C运行库,比如像 QQ、迅雷、Adobe 软件等等,如果没有安装VC运行库或者安装…...

Windows平台APK安装架构革命:从模拟器到原生集成的技术演进
Windows平台APK安装架构革命:从模拟器到原生集成的技术演进 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 当移动生态与桌面系统相遇,技术融合…...
)
图像处理中的NCC算法:从原理到优化(附Python实现对比)
图像处理中的NCC算法:从原理到优化(附Python实现对比) 在计算机视觉领域,模板匹配是一项基础而重要的技术。想象一下这样的场景:你正在开发一个工业质检系统,需要在流水线上快速识别产品上的特定标识&#…...

突破学术排版瓶颈:mpMath插件的4大技术解决方案
突破学术排版瓶颈:mpMath插件的4大技术解决方案 【免费下载链接】mpMath 项目地址: https://gitcode.com/gh_mirrors/mpma/mpMath 当物理系研究生小林在微信公众号编辑器中第12次尝试插入傅里叶变换公式时,屏幕上依然是一堆错位的希腊字母——这…...

Anything to RealCharacters 2.5D转真人引擎效果可视化:预处理前后对比与输出质量评估
Anything to RealCharacters 2.5D转真人引擎效果可视化:预处理前后对比与输出质量评估 你是否曾想过,将心爱的动漫角色、游戏立绘或者卡通头像,一键变成一张以假乱真的真人照片?这听起来像是魔法,但现在,借…...
|高精度长时序LUCC产品)
1985–2024年武汉大学CLCD中国土地利用/覆被数据集(逐年30米栅格)|高精度长时序LUCC产品
🔍 数据简介 CLCD(China Land Cover Dataset) 是由武汉大学测绘遥感信息工程国家重点实验室李熙教授、李德仁院士团队基于Landsat系列卫星影像,结合深度学习与多源辅助数据(如夜间灯光、POI、道路网等)&…...

捉妖雷达Web版:如何解决游戏数据实时同步的技术挑战?
捉妖雷达Web版:如何解决游戏数据实时同步的技术挑战? 【免费下载链接】zhuoyao_radar 捉妖雷达 web版 项目地址: https://gitcode.com/gh_mirrors/zh/zhuoyao_radar 捉妖雷达Web版是一个开源的游戏辅助工具项目,旨在为捉妖游戏玩家提供…...

MedGemma-X实战教程:用status_gradio.sh实时监控GPU利用率与内存泄漏
MedGemma-X实战教程:用status_gradio.sh实时监控GPU利用率与内存泄漏 1. 为什么你需要实时监控MedGemma-X的GPU状态 MedGemma-X不是一台“开箱即用就永远稳定”的黑盒子。它是一套在GPU上高速运转的多模态影像认知系统——当它正在分析一张胸部X光片、生成结构化报…...

告别SSH断连焦虑:用Tmux会话持久化拯救你的远程工作
远程开发者的救星:Tmux实战指南与高阶会话管理技巧 凌晨三点,服务器上的关键编译任务刚执行到一半,突然网络抖动导致SSH连接中断——这种令人抓狂的场景,每一位远程开发者都深有体会。传统终端会话的脆弱性让我们不得不反复重做工…...

python高校大学生家教平台的设计与开发
目录需求分析与功能规划技术栈选型数据库设计关键功能实现测试与部署持续迭代项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作需求分析与功能规划 明确平台核心需求,包括用户角色划分(学生、教师、管理员…...