k8s—Prometheus+Grafana+Altermaneger构建监控平台
目录
一、安装node-exporter
1.下载所需镜像
2.编写node-export.yaml文件并应用
3.测试node-exporter并获取数据
二、Prometheus server安装和配置
1.创建sa(serviceaccount)账号,对sa做rabc授权
1)创建一个 sa 账号 monitor
2)把 sa 账号 monitor 通过 clusterrolebing 绑定到 clusterrole 上
2.创建Prometheus数据存储目录
3.安装Prometheus server服务
3.1创建configmap用来存放Prometheus配置信息
1)创建yaml文件
2)应用并查看
3.2 通过deployment部署prometheus
1)上传所需镜像
2)编写yaml文件
3)应用并查看
3.3给Prometheus pod创建一个service
1)编写yaml文件
2)应用并查看
3)结果测试
3.4 Prometheus 热加载
三、Grafana的安装和配置
1.Grafana介绍
2.安装和Grafana
1)上传镜像
2)编写yaml文件
3)应用并查看
3.Grafana接入Prometheus数据源
3.1 浏览器访问
经上述查看,映射端口为30244,在浏览器输入IP:端口号即可访问
3.2 配置grafana界面
1)选择Create your first data source
2)导入监控模板
3)导入docker_rev1.json监控模板
4)如果 Grafana 导入 Prometheusz 之后,发现仪表盘没有数据,如何排查?
四、安装kube-state-metrics组件
1.介绍kube-state-metrics组件
2.安装kube-state-metrics组件
1)创建sa并对其授权
2)上传镜像
3)编写yaml文件并应用
4)创建service
5)导入监控模板
五、配置alertmanager组件
1.创建alertmanager-cm.yaml配置文件
2.Prometheus报警流程
3.创建Prometheus和告警规则的配置文件
1)下图是配置文件中需要修改的地方:
2)删除上次设置的configmap配置
3)配置文件configmap
4)应用配置文件
4.安装Prometheus和altermanager
4.1 安装
1)删除上述操作步骤安装的Prometheus的deployment资源
2)生成etcd-certs
3)拉取镜像
4)编写deployment的yaml文件并应用
5)创建alertmanager的service以便于访问
6)浏览器访问测试
4.2 访问web界面查看效果
1)访问Prometheus的web页面
2)修改配置文件
3)再次访问web页面
一、安装node-exporter
1.下载所需镜像
# 我直接用的镜像压缩包,上传到服务器然后docker load
# 所有节点都要有这个镜像
[root@k8s-master ~]# docker load -i node-exporter.tar.gz
ad68498f8d86: Loading layer [==================================================>] 4.628MB/4.628MB
ad8512dce2a7: Loading layer [==================================================>] 2.781MB/2.781MB
cc1adb06ef21: Loading layer [==================================================>] 16.9MB/16.9MB
Loaded image: prom/node-exporter:v0.16.02.编写node-export.yaml文件并应用
[root@k8s-master node-exporter]# vim node-export.yaml
[root@k8s-master node-exporter]# cat node-export.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:name: node-exporternamespace: monitor-sa #记得创建命名空间,否则后面会出错labels:name: node-exporter
spec:selector:matchLabels:name: node-exportertemplate:metadata:labels:name: node-exporterspec:hostPID: true #表示pod中的容器可以直接使用主机的网络,与宿主机进行通信hostIPC: truehostNetwork: true #会直接将宿主机的9100端口映射出来,不需要创建servicecontainers:- name: node-exporterimage: prom/node-exporter:v0.16.0ports:- containerPort: 9100resources:requests:cpu: 0.15 #容器运行至少需要0.15核CPUsecurityContext:privileged: true #开启特权模式args:- --path.procfs #配置挂载宿主机的路径- /host/proc- --path.sysfs- /host/sys- --collector.filesystem.ignored-mount-points- '"^/(sys|proc|dev|host|etc)($|/)"'volumeMounts:- name: devmountPath: /host/dev- name: procmountPath: /host/proc- name: sysmountPath: /host/sys- name: rootfsmountPath: /rootfstolerations:- key: "node-role.kubernetes.io/master"operator: "Exists"effect: "NoSchedule"volumes:- name: prochostPath:path: /proc- name: devhostPath:path: /dev- name: syshostPath:path: /sys- name: rootfshostPath:path: /
[root@k8s-master node-exporter]# kubectl apply -f node-export.yaml
Error from server (NotFound): error when creating "node-export.yaml": namespaces "monitor-sa" not found #命名空间没有创建;
[root@k8s-master node-exporter]# kubectl create ns monitor-sa
namespace/monitor-sa created
[root@k8s-master node-exporter]# kubectl apply -f node-export.yaml
daemonset.apps/node-exporter created# 查看创建好的pod;发现IP与宿主机IP相同
[root@k8s-master node-exporter]# kubectl get pod -n monitor-sa -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-exporter-fdvjc 1/1 Running 0 8m21s 192.168.22.136 k8s-node2 <none> <none>
node-exporter-gzfnq 1/1 Running 0 8m21s 192.168.22.134 k8s-master <none> <none>
node-exporter-r85gw 1/1 Running 0 8m21s 192.168.22.135 k8s-node1 <none> <none>
3.测试node-exporter并获取数据
# 通过curl 宿主机IP:9100/metrics 采集数据
# 我访问的是node1节点的CPU[root@k8s-master node-exporter]# curl 192.168.22.135:9100/metrics | grep node_cpu_seconds% Total % Received % Xferd Average Speed Time Time Time CurrentDload Upload Total Spent Left Speed
100 74373 100 74373 0 0 413k 0 --:--:-- --:--:-- --:--:-- 417k
# HELP node_cpu_seconds_total Seconds the cpus spent in each mode. #解释当前指标的含义
# TYPE node_cpu_seconds_total counter #说明当前指标的数据类型
node_cpu_seconds_total{cpu="0",mode="idle"} 18145.96
node_cpu_seconds_total{cpu="0",mode="iowait"} 1.43
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 0.05
node_cpu_seconds_total{cpu="0",mode="softirq"} 29.26
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 443.06
node_cpu_seconds_total{cpu="0",mode="user"} 383.4
node_cpu_seconds_total{cpu="1",mode="idle"} 18073.89
node_cpu_seconds_total{cpu="1",mode="iowait"} 1.23
node_cpu_seconds_total{cpu="1",mode="irq"} 0
node_cpu_seconds_total{cpu="1",mode="nice"} 0.02
node_cpu_seconds_total{cpu="1",mode="softirq"} 61.35
node_cpu_seconds_total{cpu="1",mode="steal"} 0
node_cpu_seconds_total{cpu="1",mode="system"} 446.99
node_cpu_seconds_total{cpu="1",mode="user"} 361.69# node1节点的负载情况[root@k8s-master node-exporter]# curl 192.168.22.135:9100/metrics | grep node_load% Total % Received % Xferd Average Speed Time Time Time CurrentDload Upload Total Spent Left Speed0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 0.1 #最近一分钟以内的负载情况
# HELP node_load15 15m load average.
# TYPE node_load15 gauge
node_load15 0.09
# HELP node_load5 5m load average.
# TYPE node_load5 gauge
node_load5 0.04
100 74460 100 74460 0 0 6343k 0 --:--:-- --:--:-- --:--:-- 6610k二、Prometheus server安装和配置
1.创建sa(serviceaccount)账号,对sa做rabc授权
1)创建一个 sa 账号 monitor
[root@k8s-master node-exporter]# kubectl create serviceaccount monitor -n monitor-sa
serviceaccount/monitor created2)把 sa 账号 monitor 通过 clusterrolebing 绑定到 clusterrole 上
[root@k8s-master node-exporter]# kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
clusterrolebinding.rbac.authorization.k8s.io/monitor-clusterrolebinding created2.创建Prometheus数据存储目录
# 在node1节点创建目录[root@k8s-node1 ~]# mkdir /data
[root@k8s-node1 ~]# chmod 777 /data3.安装Prometheus server服务
3.1创建configmap用来存放Prometheus配置信息
1)创建yaml文件
[root@k8s-master yaml]# vim prometheus-cfg.yaml
[root@k8s-master yaml]# cat prometheus-cfg.yaml
---
kind: ConfigMap
apiVersion: v1
metadata:labels:app: prometheusname: prometheus-confignamespace: monitor-sa
data:prometheus.yml: |global:scrape_interval: 15s #采集目标主机监控数据的时间间隔scrape_timeout: 10s #数据采集超时时间,默认10秒evaluation_interval: 1m #触发告警检测的时间,默认是1mscrape_configs: #配置数据源,称为target,每个target用job_name命名- job_name: 'kubernetes-node'kubernetes_sd_configs: #使用的是k8s的服务发现- role: node #使用node角色,它使用默认的kubelet提供的http端口来发现集群中的每个node节点relabel_configs: #重新标记- source_labels: [__address__] #配置的原始标签,匹配地址regex: '(.*):10250' #匹配带有10250端口的urlreplacement: '${1}:9100' #把匹配到的 ip:10250 的 ip 保留target_label: __address__ #新生成的 url 是${1}获取到的 ip:9100action: replace- action: labelmapregex: __meta_kubernetes_node_label_(.+)- job_name: 'kubernetes-node-cadvisor' # 抓取 cAdvisor 数据,是获取 kubelet 上/metrics/cadvisor 接口数据来获取容器的资源使用情况kubernetes_sd_configs:- role: nodescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- action: labelmap #把匹配到的标签保留regex: __meta_kubernetes_node_label_(.+)- target_label: __address__replacement: kubernetes.default.svc:443- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __metrics_path__replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor- job_name: 'kubernetes-apiserver'kubernetes_sd_configs:- role: endpoints #使用 k8s 中的 endpoint 服务发现,采集 apiserver 6443 端口获取到的数据scheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] #endpoint 这个对象的名称空间,endpoint 对象的服务名,exnpoint 的端口名称action: keep #采集满足条件的实例,其他实例不采集regex: default;kubernetes;https- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true # 重新打标仅抓取到的具有 "prometheus.io/scrape: true" 的 annotation 的端点,意思是说如果某个 service 具有 prometheus.io/scrape = true annotation 声明则抓取- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?) #重新设置 scheme,匹配源标签__meta_kubernetes_service_annotation_prometheus_io_scheme 也就是 prometheus.io/scheme annotation,如果源标签的值匹配到 regex,则把值替换为__scheme__对应的值- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+) # 应用中自定义暴露的指标,不过这里写的要和 service 中做好约定,如果 service 中这样写 prometheus.io/app-metricspath: '/metrics' 那么你这里就要
__meta_kubernetes_service_annotation_prometheus_io_app_metrics_path 这样写- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2 #暴露自定义的应用的端口,就是把地址和你在 service 中定义的 "prometheus.io/port = <port>" 声明做一个拼接,然后赋值给__address__,这样 prometheus 就能获取自定义应用的端口,然后通过这个端口再结合__metrics_path__来获取指标- action: labelmap #保留下面匹配到的标签regex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replace #替换__meta_kubernetes_namespace 变成 kubernetes_namespacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name 2)应用并查看
[root@k8s-master yaml]# kubectl apply -f prometheus-cfg.yaml
configmap/prometheus-config created
[root@k8s-master yaml]# kubectl get cm -n monitor-sa
NAME DATA AGE
prometheus-config 1 48m3.2 通过deployment部署prometheus
1)上传所需镜像
# node1节点,定义的yaml文件中指定了k8s-node1节点[root@k8s-node1 ~]# docker load -i prometheus-2-2-1.tar.gz
6a749002dd6a: Loading layer 1.338MB/1.338MB
5f70bf18a086: Loading layer 1.024kB/1.024kB
1692ded805c8: Loading layer 2.629MB/2.629MB
035489d93827: Loading layer 66.18MB/66.18MB
8b6ef3a2ab2c: Loading layer 44.5MB/44.5MB
ff98586f6325: Loading layer 3.584kB/3.584kB
017a13aba9f4: Loading layer 12.8kB/12.8kB
4d04d79bb1a5: Loading layer 27.65kB/27.65kB
75f6c078fa6b: Loading layer 10.75kB/10.75kB
5e8313e8e2ba: Loading layer 6.144kB/6.144kB
Loaded image: prom/prometheus:v2.2.12)编写yaml文件
[root@k8s-master yaml]# vim prometheus-deploy.yaml
[root@k8s-master yaml]# cat prometheus-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-servernamespace: monitor-salabels:app: prometheus
spec:replicas: 1selector:matchLabels:app: prometheuscomponent: server#matchExpressions:#- {key: app, operator: In, values: [prometheus]}#- {key: component, operator: In, values: [server]}template:metadata:labels:app: prometheuscomponent: serverannotations:prometheus.io/scrape: 'false'spec:nodeName: k8s-node1serviceAccountName: monitorcontainers:- name: prometheusimage: prom/prometheus:v2.2.1imagePullPolicy: IfNotPresentcommand:- prometheus- --config.file=/etc/prometheus/prometheus.yml- --storage.tsdb.path=/prometheus #旧数据存储目录- --storage.tsdb.retention=720h #何时删除旧数据,默认为 15 天- --web.enable-lifecycle #开启热加载ports:- containerPort: 9090protocol: TCPvolumeMounts:- mountPath: /etc/prometheus/prometheus.ymlname: prometheus-configsubPath: prometheus.yml- mountPath: /prometheus/name: prometheus-storage-volumevolumes:- name: prometheus-configconfigMap:name: prometheus-configitems:- key: prometheus.ymlpath: prometheus.ymlmode: 0644- name: prometheus-storage-volumehostPath:path: /datatype: Directory3)应用并查看
[root@k8s-master yaml]# kubectl apply -f prometheus-deploy.yaml
deployment.apps/prometheus-server created
[root@k8s-master yaml]# kubectl get deploy -n monitor-sa
NAME READY UP-TO-DATE AVAILABLE AGE
prometheus-server 1/1 1 1 26s3.3给Prometheus pod创建一个service
1)编写yaml文件
[root@k8s-master yaml]# vim prometheus-svc.yaml
[root@k8s-master yaml]# cat prometheus-svc.yaml
apiVersion: v1
kind: Service
metadata:name: prometheusnamespace: monitor-salabels:app: prometheus
spec:type: NodePortports:- port: 9090targetPort: 9090protocol: TCPselector:app: prometheuscomponent: server2)应用并查看
[root@k8s-master yaml]# kubectl apply -f prometheus-svc.yaml
service/prometheus created
[root@k8s-master yaml]# kubectl get svc -n monitor-sa
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.104.137.10 <none> 9090:30481/TCP 12s3)结果测试
通过查询可以看到service在宿主机上映射的端口是30481,访问k8s集群的node1节点的IP:端口/graph,就可以访问到web ui界面

点击上方的Status中的Targets,可以看到以下界面:


3.4 Prometheus 热加载
为了每次修改配置文件可以热加载 prometheus,也就是不停止 prometheus,就可以使配置生效,想要使配置生效可用如下热加载命令
curl -X POST http://podIP:9090/-/reload
三、Grafana的安装和配置
1.Grafana介绍
Grafana 是一个跨平台的开源的度量分析和可视化工具,可以将采集的数据可视化的展示,并及时通知给告警接收方。它主要有以下特点:
2.安装和Grafana
1)上传镜像
# node1节点[root@k8s-node1 images-prometheus]# docker load -i heapster-grafana-amd64_v5_0_4.tar.gz
6816d98be637: Loading layer 4.642MB/4.642MB
523feee8e0d3: Loading layer 161.5MB/161.5MB
43d2638621da: Loading layer 230.4kB/230.4kB
f24c0fa82e54: Loading layer 2.56kB/2.56kB
334547094992: Loading layer 5.826MB/5.826MB
Loaded image: k8s.gcr.io/heapster-grafana-amd64:v5.0.42)编写yaml文件
[root@k8s-master yaml]# vim grafana.yaml
[root@k8s-master yaml]# cat grafana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: monitoring-grafananamespace: kube-system
spec:replicas: 1selector:matchLabels:task: monitoringk8s-app: grafanatemplate:metadata:labels:task: monitoringk8s-app: grafanaspec:nodeName: k8s-node1containers:- name: grafanaimage: k8s.gcr.io/heapster-grafana-amd64:v5.0.4ports:- containerPort: 3000protocol: TCPvolumeMounts:- mountPath: /etc/ssl/certsname: ca-certificatesreadOnly: true- mountPath: /varname: grafana-storageenv:- name: INFLUXDB_HOSTvalue: monitoring-influxdb- name: GF_SERVER_HTTP_PORTvalue: "3000"# The following env variables are required to make Grafana accessible via# the kubernetes api-server proxy. On production clusters, we recommend# removing these env variables, setup auth for grafana, and expose the grafana# service using a LoadBalancer or a public IP.- name: GF_AUTH_BASIC_ENABLEDvalue: "false"- name: GF_AUTH_ANONYMOUS_ENABLEDvalue: "true"- name: GF_AUTH_ANONYMOUS_ORG_ROLEvalue: Admin- name: GF_SERVER_ROOT_URL# If you're only using the API Server proxy, set this value instead:# value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxyvalue: /volumes:- name: ca-certificateshostPath:path: /etc/ssl/certs- name: grafana-storageemptyDir: {}
---
apiVersion: v1
kind: Service
metadata:labels:# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)# If you are NOT using this as an addon, you should comment out this line.kubernetes.io/cluster-service: 'true'kubernetes.io/name: monitoring-grafananame: monitoring-grafananamespace: kube-system
spec:# In a production setup, we recommend accessing Grafana through an external Loadbalancer# or through a public IP.# type: LoadBalancer# You could also use NodePort to expose the service at a randomly-generated port# type: NodePortports:- port: 80targetPort: 3000selector:k8s-app: grafanatype: NodePort
3)应用并查看
[root@k8s-master yaml]# kubectl apply -f grafana.yaml
deployment.apps/monitoring-grafana created
service/monitoring-grafana created
[root@k8s-master yaml]# kubectl get pod -n kube-system -o wide | grep monitor
monitoring-grafana-7979b958c7-rxcw7 1/1 Running 0 64s 10.244.1.23 k8s-node1 <none> <none>
[root@k8s-master yaml]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 3d16h
monitoring-grafana NodePort 10.107.203.6 <none> 80:30244/TCP 3m48s
3.Grafana接入Prometheus数据源
3.1 浏览器访问
经上述查看,映射端口为30244,在浏览器输入IP:端口号即可访问

3.2 配置grafana界面
1)选择Create your first data source



2)导入监控模板
监控模板链接:https://grafana.com/dashboards
此处导入的是node_exporter.json文件




3)导入docker_rev1.json监控模板
跟上一步操作一样



4)如果 Grafana 导入 Prometheusz 之后,发现仪表盘没有数据,如何排查?
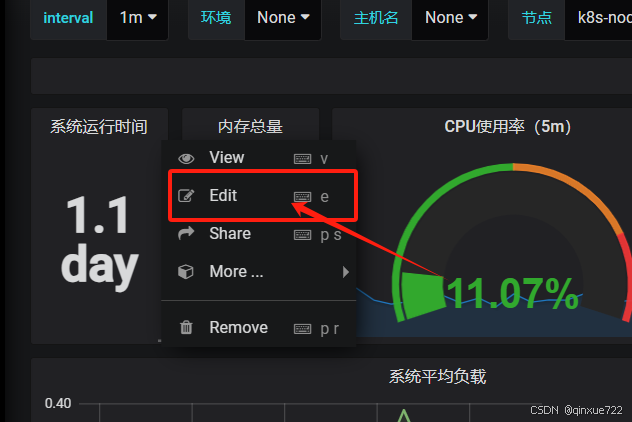

node_memory_MemTotal_bytes就是grafana上采集的内存数据,需要到Prometheus ui界面看看指标是否是相同的

四、安装kube-state-metrics组件
1.介绍kube-state-metrics组件
2.安装kube-state-metrics组件
1)创建sa并对其授权
[root@k8s-master yaml]# vim kube-state-metrics-rbac.yaml
[root@k8s-master yaml]# cat kube-state-metrics-rbac.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:name: kube-state-metricsnamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: kube-state-metrics
rules:
- apiGroups: [""]resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]verbs: ["list", "watch"]
- apiGroups: ["extensions"]resources: ["daemonsets", "deployments", "replicasets"]verbs: ["list", "watch"]
- apiGroups: ["apps"]resources: ["statefulsets"]verbs: ["list", "watch"]
- apiGroups: ["batch"]resources: ["cronjobs", "jobs"]verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]resources: ["horizontalpodautoscalers"]verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: kube-state-metrics
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: kube-state-metrics
subjects:
- kind: ServiceAccountname: kube-state-metricsnamespace: kube-system
[root@k8s-master yaml]# kubectl apply -f kube-state-metrics-rbac.yaml
serviceaccount/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
[root@k8s-master yaml]# kubectl get sa -n kube-system | grep state
kube-state-metrics 1 11m2)上传镜像
[root@k8s-node1 images-prometheus]# docker load -i kube-state-metrics_1_9_0.tar.gz
932da5156413: Loading layer 3.062MB/3.062MB
bd8df7c22fdb: Loading layer 31MB/31MB
Loaded image: quay.io/coreos/kube-state-metrics:v1.9.0
[root@k8s-node1 images-prometheus]# docker images | grep state
quay.io/coreos/kube-state-metrics v1.9.0 101b910a2162 4 years ago 32.8MB
3)编写yaml文件并应用
[root@k8s-master yaml]# vim kube-state-metrics-deploy.yaml
[root@k8s-master yaml]# cat kube-state-metrics-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: kube-state-metricsnamespace: kube-system
spec:replicas: 1selector:matchLabels:app: kube-state-metricstemplate:metadata:labels:app: kube-state-metricsspec:nodeName: k8s-node1serviceAccountName: kube-state-metricscontainers:- name: kube-state-metricsimage: quay.io/coreos/kube-state-metrics:v1.9.0ports:- containerPort: 8080
[root@k8s-master yaml]# kubectl apply -f kube-state-metrics-deploy.yaml
deployment.apps/kube-state-metrics created
[root@k8s-master yaml]# kubectl get pod -n kube-system | grep kube-state
kube-state-metrics-7684896db9-l5vsz 1/1 Running 0 61s
4)创建service
[root@k8s-master yaml]# vim kube-state-metrics-svc.yaml
[root@k8s-master yaml]# cat kube-state-metrics-svc.yaml
apiVersion: v1
kind: Service
metadata:annotations:prometheus.io/scrape: 'true'name: kube-state-metricsnamespace: kube-systemlabels:app: kube-state-metrics
spec:ports:- name: kube-state-metricsport: 8080protocol: TCPselector:app: kube-state-metrics
[root@k8s-master yaml]# kubectl apply -f kube-state-metrics-svc.yaml
service/kube-state-metrics created
[root@k8s-master yaml]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 3d18h
kube-state-metrics ClusterIP 10.104.238.225 <none> 8080/TCP 19s
monitoring-grafana NodePort 10.107.203.6 <none> 80:30244/TCP 148m
[root@k8s-master yaml]#
5)导入监控模板
两个模板:
Kubernetes Cluster (Prometheus)-1577674936972.json
Kubernetes cluster monitoring (via Prometheus) (k8s 1.16)-1577691996738.json



五、配置alertmanager组件
1.创建alertmanager-cm.yaml配置文件
[root@k8s-master yaml]# vim alertmanager-cm.yaml
[root@k8s-master yaml]# cat alertmanager-cm.yaml
kind: ConfigMap
apiVersion: v1
metadata:name: alertmanagernamespace: monitor-sa
data:alertmanager.yml: |-global:resolve_timeout: 1msmtp_smarthost: 'smtp.163.com:25' #网易163邮箱smtp_from: '198********@163.com' #从哪个邮箱发送邮件smtp_auth_username: '198********' #发送邮件的用户smtp_auth_password: 'YLOPKFRHHONSHHXM' #网易邮箱的授权码,要用自己的smtp_require_tls: falseroute:group_by: [alertname] # 采用哪个标签来作为分组依据group_wait: 10s # 组告警等待时间。也就是告警产生后等待 10s,如果有同组告警一起发出group_interval: 10s # 上下两组发送告警的间隔时间repeat_interval: 10m # 重复发送告警的时间,减少相同邮件的发送频率,默认是 1hreceiver: default-receiverreceivers:- name: 'default-receiver'email_configs:- to: '178******@qq.com' #接受邮件的邮箱,不能跟上面的邮箱相同send_resolved: true
[root@k8s-master yaml]# kubectl apply -f alertmanager-cm.yaml
configmap/alertmanager created
2.Prometheus报警流程
3.创建Prometheus和告警规则的配置文件
1)下图是配置文件中需要修改的地方:

2)删除上次设置的configmap配置
# 先删除上次设置的configmap
[root@k8s-master yaml]# kubectl delete -f prometheus-cfg.yaml
configmap "prometheus-config" deleted3)配置文件configmap
# 编写新的configmap配置文件[root@k8s-master yaml]# vim prometheus-alertmanager-cfg.yaml
[root@k8s-master yaml]# cat prometheus-alertmanager-cfg.yaml
kind: ConfigMap
apiVersion: v1
metadata:labels:app: prometheusname: prometheus-confignamespace: monitor-sa
data:prometheus.yml: |rule_files:- /etc/prometheus/rules.ymlalerting:alertmanagers:- static_configs:- targets: ["localhost:9093"]global:scrape_interval: 15sscrape_timeout: 10sevaluation_interval: 1mscrape_configs:- job_name: 'kubernetes-node'kubernetes_sd_configs:- role: noderelabel_configs:- source_labels: [__address__]regex: '(.*):10250'replacement: '${1}:9100'target_label: __address__action: replace- action: labelmapregex: __meta_kubernetes_node_label_(.+)- job_name: 'kubernetes-node-cadvisor'kubernetes_sd_configs:- role: nodescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- target_label: __address__replacement: kubernetes.default.svc:443- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __metrics_path__replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor- job_name: 'kubernetes-apiserver'kubernetes_sd_configs:- role: endpointsscheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]action: keepregex: default;kubernetes;https- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name - job_name: 'kubernetes-pods'kubernetes_sd_configs:- role: podrelabel_configs:- action: keepregex: truesource_labels:- __meta_kubernetes_pod_annotation_prometheus_io_scrape- action: replaceregex: (.+)source_labels:- __meta_kubernetes_pod_annotation_prometheus_io_pathtarget_label: __metrics_path__- action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2source_labels:- __address__- __meta_kubernetes_pod_annotation_prometheus_io_porttarget_label: __address__- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- action: replacesource_labels:- __meta_kubernetes_namespacetarget_label: kubernetes_namespace- action: replacesource_labels:- __meta_kubernetes_pod_nametarget_label: kubernetes_pod_name- job_name: 'kubernetes-schedule'scrape_interval: 5sstatic_configs:- targets: ['192.168.22.134:10251']- job_name: 'kubernetes-controller-manager'scrape_interval: 5sstatic_configs:- targets: ['192.168.22.134:10252']- job_name: 'kubernetes-kube-proxy'scrape_interval: 5sstatic_configs:- targets: ['192.168.22.134:10249','192.168.22.135:10249','192.168.22.136:10249']- job_name: 'kubernetes-etcd'scheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crtcert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crtkey_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.keyscrape_interval: 5sstatic_configs:- targets: ['192.168.22.134:2379']rules.yml: |groups:- name: examplerules:- alert: kube-proxy的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: kube-proxy的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: scheduler的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: scheduler的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: controller-manager的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: controller-manager的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 0for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: apiserver的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: apiserver的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: etcd的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: etcd的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: kube-state-metrics的cpu使用率大于80%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"value: "{{ $value }}%"threshold: "80%" - alert: kube-state-metrics的cpu使用率大于90%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"value: "{{ $value }}%"threshold: "90%" - alert: coredns的cpu使用率大于80%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"value: "{{ $value }}%"threshold: "80%" - alert: coredns的cpu使用率大于90%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"value: "{{ $value }}%"threshold: "90%" - alert: kube-proxy打开句柄数>600expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kube-proxy打开句柄数>1000expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-schedule打开句柄数>600expr: process_open_fds{job=~"kubernetes-schedule"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-schedule打开句柄数>1000expr: process_open_fds{job=~"kubernetes-schedule"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-controller-manager打开句柄数>600expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-controller-manager打开句柄数>1000expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-apiserver打开句柄数>600expr: process_open_fds{job=~"kubernetes-apiserver"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-apiserver打开句柄数>1000expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-etcd打开句柄数>600expr: process_open_fds{job=~"kubernetes-etcd"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-etcd打开句柄数>1000expr: process_open_fds{job=~"kubernetes-etcd"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: corednsexpr: process_open_fds{k8s_app=~"kube-dns"} > 600for: 2slabels:severity: warnning annotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600"value: "{{ $value }}"- alert: corednsexpr: process_open_fds{k8s_app=~"kube-dns"} > 1000for: 2slabels:severity: criticalannotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000"value: "{{ $value }}"- alert: kube-proxyexpr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: schedulerexpr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-controller-managerexpr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-apiserverexpr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-etcdexpr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kube-dnsexpr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000for: 2slabels:severity: warnningannotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: HttpRequestsAvgexpr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000"value: "{{ $value }}"threshold: "1000" - alert: Pod_restartsexpr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0for: 2slabels:severity: warnningannotations:description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的"value: "{{ $value }}"threshold: "0"- alert: Pod_waitingexpr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中"value: "{{ $value }}"threshold: "1" - alert: Pod_terminatedexpr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除"value: "{{ $value }}"threshold: "1"- alert: Etcd_leaderexpr: etcd_server_has_leader{job="kubernetes-etcd"} == 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader"value: "{{ $value }}"threshold: "0"- alert: Etcd_leader_changesexpr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变"value: "{{ $value }}"threshold: "0"- alert: Etcd_failedexpr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败"value: "{{ $value }}"threshold: "0"- alert: Etcd_db_total_sizeexpr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G"value: "{{ $value }}"threshold: "10G"- alert: Endpoint_readyexpr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用"value: "{{ $value }}"threshold: "1"- name: 物理节点状态-监控告警rules:- alert: 物理节点cpu使用率expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90for: 2slabels:severity: ccriticalannotations:summary: "{{ $labels.instance }}cpu使用率过高"description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: 物理节点内存使用率expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90for: 2slabels:severity: criticalannotations:summary: "{{ $labels.instance }}内存使用率过高"description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理"- alert: InstanceDownexpr: up == 0for: 2slabels:severity: criticalannotations: summary: "{{ $labels.instance }}: 服务器宕机"description: "{{ $labels.instance }}: 服务器延时超过2分钟"- alert: 物理节点磁盘的IO性能expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"- alert: 入网流量带宽expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流入网络带宽过高!"description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"- alert: 出网流量带宽expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流出网络带宽过高!"description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"- alert: TCP会话expr: node_netstat_Tcp_CurrEstab > 1000for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"- alert: 磁盘容量expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"4)应用配置文件
[root@k8s-master yaml]# kubectl apply -f prometheus-alertmanager-cfg.yaml
configmap/prometheus-config created
[root@k8s-master yaml]# kubectl get cm -n monitor-sa
NAME DATA AGE
alertmanager 1 25m
prometheus-config 2 3m20s
4.安装Prometheus和altermanager
4.1 安装
1)删除上述操作步骤安装的Prometheus的deployment资源
[root@k8s-master yaml]# kubectl delete -f prometheus-deploy.yaml
deployment.apps "prometheus-server" deleted2)生成etcd-certs
[root@k8s-master yaml]# kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
secret/etcd-certs created[root@k8s-master yaml]# kubectl get secret -n monitor-sa
NAME TYPE DATA AGE
default-token-jjw8z kubernetes.io/service-account-token 3 24h
etcd-certs Opaque 3 40s
monitor-token-jr24f kubernetes.io/service-account-token 3 23h
3)拉取镜像
# 此处我用的node2节点[root@k8s-node2 images-prometheus]# docker load -i alertmanager.tar.gz
4febd3792a1f: Loading layer 1.36MB/1.36MB
68d1a8b41cc0: Loading layer 2.586MB/2.586MB
5f70bf18a086: Loading layer 1.024kB/1.024kB
30d4e7b232e4: Loading layer 12.77MB/12.77MB
6b961451fcb0: Loading layer 16.59MB/16.59MB
b5abc4736d3f: Loading layer 6.144kB/6.144kB
Loaded image: prom/alertmanager:v0.14.0
[root@k8s-node2 images-prometheus]# scp alertmanager.tar.gz k8s-node2:/root/
root@k8s-node2's password:
alertmanager.tar.gz 100% 32MB 16.1MB/s 00:01
[root@k8s-node2 images-prometheus]# docker images | grep alert
prom/alertmanager v0.14.0 23744b2d645c 6 years ago 31.9MB
4)编写deployment的yaml文件并应用
[root@k8s-master yaml]# vim prometheus-alertmanager-deploy.yaml
[root@k8s-master yaml]# cat prometheus-alertmanager-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-servernamespace: monitor-salabels:app: prometheus
spec:replicas: 1selector:matchLabels:app: prometheuscomponent: server#matchExpressions:#- {key: app, operator: In, values: [prometheus]}#- {key: component, operator: In, values: [server]}template:metadata:labels:app: prometheuscomponent: serverannotations:prometheus.io/scrape: 'false'spec:nodeName: k8s-node1 #此处指定的node1节点serviceAccountName: monitorcontainers:- name: prometheusimage: prom/prometheus:v2.2.1imagePullPolicy: IfNotPresentcommand:- "/bin/prometheus"args:- "--config.file=/etc/prometheus/prometheus.yml"- "--storage.tsdb.path=/prometheus"- "--storage.tsdb.retention=24h"- "--web.enable-lifecycle"ports:- containerPort: 9090protocol: TCPvolumeMounts:- mountPath: /etc/prometheusname: prometheus-config- mountPath: /prometheus/name: prometheus-storage-volume- name: k8s-certsmountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/- name: alertmanagerimage: prom/alertmanager:v0.14.0imagePullPolicy: IfNotPresentargs:- "--config.file=/etc/alertmanager/alertmanager.yml"- "--log.level=debug"ports:- containerPort: 9093protocol: TCPname: alertmanagervolumeMounts:- name: alertmanager-configmountPath: /etc/alertmanager- name: alertmanager-storagemountPath: /alertmanager- name: localtimemountPath: /etc/localtimevolumes:- name: prometheus-configconfigMap:name: prometheus-config- name: prometheus-storage-volumehostPath:path: /datatype: Directory- name: k8s-certssecret:secretName: etcd-certs- name: alertmanager-configconfigMap:name: alertmanager- name: alertmanager-storagehostPath:path: /data/alertmanagertype: DirectoryOrCreate- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/Shanghai# 应用yaml文件[root@k8s-master yaml]# kubectl apply -f prometheus-alertmanager-deploy.yaml
deployment.apps/prometheus-server created
[root@k8s-master yaml]# kubectl get pod -n monitor-sa
NAME READY STATUS RESTARTS AGE
node-exporter-fdvjc 1/1 Running 1 24h
node-exporter-gzfnq 1/1 Running 0 24h
node-exporter-r85gw 1/1 Running 0 24h
prometheus-server-6c5bc4d65b-9qzn6 2/2 Running 0 39s5)创建alertmanager的service以便于访问
[root@k8s-master yaml]# vim alertmanager-svc.yaml
[root@k8s-master yaml]# cat alertmanager-svc.yaml
---
apiVersion: v1
kind: Service
metadata:labels:name: prometheuskubernetes.io/cluster-service: 'true'name: alertmanagernamespace: monitor-sa
spec:ports:- name: alertmanagernodePort: 30066port: 9093protocol: TCPtargetPort: 9093selector:app: prometheussessionAffinity: Nonetype: NodePort
[root@k8s-master yaml]# kubectl apply -f alertmanager-svc.yaml
service/alertmanager created
[root@k8s-master yaml]# kubectl get svc -n monitor-sa
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager NodePort 10.98.208.193 <none> 9093:30066/TCP 16s
prometheus NodePort 10.104.137.10 <none> 9090:30481/TCP 20h
6)浏览器访问测试
通过上述查询,可以看到Prometheus映射的端口为30481,alertmanager映射的端口为30066;浏览器输入192.168.22.135:30066/#/alerts访问;
也就是http://node1节点IP:端口号/#/alerts

4.2 访问web界面查看效果
1)访问Prometheus的web页面
点击status中的targets;

2)修改配置文件
# kube-schedule:vim /etc/kubernetes/manifests/kube-scheduler.yaml#将里面的--bind-address=127.0.0.1改成192.168.22.134;--port=0删除;
#把httpGet:下面的hosts改成192.168.22.134
# 注意是改成master节点的IP# kube-controller-managervim /etc/kubernetes/manifests/kube-controller-manager.yaml#将里面的--bind-address=127.0.0.1改成192.168.22.134;--port=0删除;
#把httpGet:下面的hosts改成192.168.22.134
# 注意是改成master节点的IP# 改完之后重启kubelet# 查看服务:kubectl get cs ;status都是healthy即可# kube-proxykubectl edit configmap kube-proxy -n kube-system# 把metricsBindAddress这段修改成metricsBindAddress: 0.0.0.0:10249#然后再删除pod重新创建即可
kubectl get pods -n kube-system | grep kube-proxy |awk '{print $1}' | xargs kubectl delete pods -n kube-system
3)再次访问web页面


相关文章:
k8s—Prometheus+Grafana+Altermaneger构建监控平台
目录 一、安装node-exporter 1.下载所需镜像 2.编写node-export.yaml文件并应用 3.测试node-exporter并获取数据 二、Prometheus server安装和配置 1.创建sa(serviceaccount)账号,对sa做rabc授权 1)创建一个 sa 账号 monitor 2)把 sa …...
Dijkstra算法求解最短路径 自写代码
#include <iostream> #define Max 503 #define INF 0xcffffffusing namespace std;typedef struct AMGraph { //定义图int vex, arc;int arcs[Max][Max]; //邻接矩阵 };int dist[Max], path[Max]; //dis保存最短路径总权值、path通过保存路径的前驱结…...

C#如何对某个词在字符串中出现的次数进⾏计数(LINQ)
文章目录 基础知识实现方法基础计数LINQ优化处理标点符号总结 LINQ(Language-Integrated Query)是C#和VB.NET中强大的查询语言,它可以用来查询集合、SQL数据库、XML文档等。在C#中,我们可以使用LINQ来简化对字符串中特定单词出现次…...

Linux篇之OS层内核参数的调优
Linux内核参数调优 Linux 内核参数的调优和分类是一个复杂的主题,这涉及到系统性能、稳定性和安全性等多个方面。 内核参数主要可以分为以下几类: 1. 内核参数的分类 1.1 系统性能参数 这些参数影响系统的整体性能,包括 CPU 调度、内存管理…...
)
DLMS/COSEM中的信息安全:安全密钥(上)
加密密钥是一个参数,和加密算法一起使用,加密算法决定了这样一种方式,带有密钥的实体,可以重现和进行逆操作,而没有密钥则不能。对DLMS/COSEM的用途,操作的例子包含: ——明文转换成密文; ——密文转换成明文; ——计算和验证认证码(MAC); …...

Taro基础知识学习
一、安装及使用 CLI工具安装 需要使用 npm 或者 yarn 全局安装 tarojs/cli //使用 npm 安装 CLI npm install -g tarojs/cli//使用 yarn 安装 CLI yarn global add tarojs/cli//使用 cnpm 安装 CLI cnpm install -g tarojs/cli//使用npm info查看Taro的版本信息 npm info ta…...

浮点型在内存中的存储
前言 在上一期中我们讲到了有关于整型在内存中的存储,新朋友可以点开🔗了解一下,那这一期中我们将讲到的浮点数是不是存储方式和整型一致呢? 一、浮点数在内存中的存储 为了探究这个问题我们先来看一段代码 #include<stdio…...

微信小程序之behaviors
目录 概括 Demo演示 进阶演示 1. 若具有同名的属性或方法 2. 若有同名的数据 3. 若有同名的生命周期函数 应用场景 最后 属性&方法 组件中使用 代码示例: 同名字段的覆盖和组合规则 概括 一句话总结: behaviors是用于组件间代码共享的特性, 类似一…...

java.lang.NoClassDefFoundError: ch/qos/logback/core/util/StatusPrinter2
1、问题 SpringBoot升级报错: Exception in thread "main" java.lang.NoClassDefFoundError: ch/qos/logback/core/util/StatusPrinter2 类找不到: Caused by: java.lang.ClassNotFoundException: ch.qos.logback.core.util.StatusPrinter22、…...

WebRTC ICE配置类型
ICE(Interactive Connectivity Establishment)是一个用于建立WebRTC和其他实时通信会话中的点对点连接的框架。ICE协议通过尝试多个候选地址(候选者)来寻找最佳路径来连接两个对等端。ICE有多种配置类型,包括标准ICE、…...

制造知识普及(八)--企业内部物料编码(IPN)与制造商物料编码(MPN)
1、什么是物料编码 通常情况下,物料编码分两种,一种是企业内部物料编码(IPN),由于在企业研发制造和生产中确认物料唯一性的,用于承载设计参数要求和技术要求。另一种是制造商物料编码(MPN&…...

大模型学习笔记 - InstructGPT中的微调与对齐
LLM 微调 之 InstructGPT中的微调与对齐 LLM 微调 之 InstructGPT中的微调与对齐 技术概览 InstructGPT中的微调与对齐 大体步骤标注数据量模型训练 1. SFT 是如何训练的2. Reward Model是如何训练的3. RLHF 是如何训练的具体讲解RLHF 的loss 函数 模型效果参考链接…...
Unity近似的Transform实现
Unity近似的Transform实现 #include <stdint.h> #include<iomanip> #include <sstream>#include "Transform.h"//Transform::Transform(const Transform& a){ // LOGW("xww 2"); //}Transform::Transform(glm::vec3 localPositio…...

openvidu私有化部署
openvidu私有化部署 简介 OpenVidu 是一个允许您实施实时应用程序的平台。您可以从头开始构建全新的 OpenVidu 应用程序,但将 OpenVidu 集成到您现有的应用程序中也非常容易。 OpenVidu 基于 WebRTC 技术,允许开发您可以想象的任何类型的用例…...

基于深度学习的视频伪造检测
基于深度学习的视频伪造检测旨在利用深度学习技术来检测和识别伪造的视频内容。伪造视频,尤其是深伪(Deepfake)视频,近年来随着生成对抗网络(GAN)技术的发展,变得越来越逼真和难以识别。这对个人…...

python机器人编程——开发一个pymatlab工具箱(上)
目录 一、前言二、实现过程2.1 封装属性2.2 数据流化显示2.3 输入数据的适应性 三、核心代码说明3.1 设置缓存3.2 随机信号3.3 根据设置绘图 五、总结四、源码PS.扩展阅读ps1.六自由度机器人相关文章资源ps2.四轴机器相关文章资源ps3.移动小车相关文章资源 一、前言 我们知道m…...

输入类控件
目录 1.Line Edit 代码示例: 录入个人信息 代码示例: 使用正则表达式验证输入框的数据 代码示例: 验证两次输入的密码一致 代码示例: 切换显示密码 2.Text Edit 代码示例: 获取多行输入框的内容 代码示例: 验证输入框的各种信号 3.Combo Box 代码示例: 使用下拉框模拟…...

C++20中的模块
大多数C项目使用多个翻译单元(translation units),因此它们需要在这些单元之间共享声明和定义(share declarations and definitions)。headers的使用在这方面非常突出。模块(module)是一种language feature,用于在翻译单元之间共享声明和定义。它们是某些…...

Selenium与流行框架集成:pytest与Allure报告
Selenium与流行框架集成:pytest与Allure报告 在现代软件开发中,自动化测试是确保产品质量和快速迭代的关键。Selenium作为业界领先的Web自动化测试工具,其灵活性和强大的功能受到广泛认可。为了进一步提升测试效率和报告质量,本文…...

日撸Java三百行(day17:链队列)
目录 一、队列基础知识 1.队列的概念 2.队列的实现 二、代码实现 1.链队列创建 2.链队列遍历 3.入队 4.出队 5.数据测试 6.完整的程序代码 总结 一、队列基础知识 1.队列的概念 今天我们继续学习另一个常见的数据结构——队列。和栈一样,队列也是一种操…...

突破TIDAL音乐离线限制:tidal-dl-ng四象限应用指南
突破TIDAL音乐离线限制:tidal-dl-ng四象限应用指南 【免费下载链接】tidal-dl-ng TIDAL Media Downloader Next Generation! Up to HiRes / TIDAL MAX 24-bit, 192 kHz. 项目地址: https://gitcode.com/gh_mirrors/ti/tidal-dl-ng 场景痛点:当高品…...
保姆级教程:Ollama部署translategemma-27b-it,小白也能玩转多语言翻译
保姆级教程:Ollama部署translategemma-27b-it,小白也能玩转多语言翻译 1. 引言:为什么选择translategemma-27b-it 想象一下,你正在阅读一份重要的外文资料,或者需要与外国客户沟通,但语言成了障碍。传统的…...

倾角传感器在工业自动化中的实战应用:以机械臂和桥梁监测为例
倾角传感器在工业自动化中的实战应用:以机械臂和桥梁监测为例 工业自动化领域对设备姿态的精确感知有着近乎苛刻的要求。想象一下,一台正在焊接汽车底盘的六轴机械臂,如果末端执行器出现0.5度的角度偏差,就可能导致焊缝质量不合格…...
 15 SU4a - 统一通信与协作)
Cisco Unified Communications Manager (CallManager) 15 SU4a - 统一通信与协作
Cisco Unified Communications Manager (CallManager) 15 SU4a - 统一通信与协作 思科统一通信管理器 (CallManager) 请访问原文链接:https://sysin.org/blog/cisco-ucm-15/ 查看最新版。原创作品,转载请保留出处。 作者主页:sysin.org 思…...

[特殊字符] 第85课:戳气球
想系统提升编程能力、查看更完整的学习路线,欢迎访问 AI Compass:https://github.com/tingaicompass/AI-Compass 仓库持续更新刷题题解、Python 基础和 AI 实战内容,适合想高效进阶的你。📖 第85课:戳气球模块:动态规划 | 难度:Ha…...

BepInEx插件框架全解析:从问题诊断到高级应用
BepInEx插件框架全解析:从问题诊断到高级应用 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx作为Unity游戏插件开发的核心框架,为游戏模组化提供了…...

一次性拖鞋自动下料系统设计超声波热熔裁剪机设计【论文+CAD图纸+solidworks三维+开题报告+任务书+实习调研报告+其它相关资料】
一次性拖鞋自动下料系统与超声波热熔裁剪机的设计,聚焦于提升拖鞋制造环节的效率与精度。传统拖鞋生产中,人工下料易受操作误差影响,导致材料浪费与产品尺寸偏差;而普通裁剪方式可能因热熔不充分,出现边缘毛刺或连接不…...

千问3.5-9B模型Java开发环境快速配置:从JDK安装到项目集成
千问3.5-9B模型Java开发环境快速配置:从JDK安装到项目集成 1. 引言 如果你是一名Java开发者,想要快速上手调用千问3.5-9B大模型,这篇文章就是为你准备的。我们将从最基础的JDK安装开始,一步步带你完成整个开发环境的配置&#x…...

MySQL实战:主键与外键的5个常见设计误区及优化方案
MySQL实战:主键与外键的5个常见设计误区及优化方案 在数据库设计领域,主键和外键的合理运用直接影响着系统的稳定性和查询效率。许多开发者在项目初期往往忽视这些基础元素的设计规范,直到面临性能瓶颈或数据混乱时才追悔莫及。本文将揭示那…...

HY-MT1.8B部署避坑指南:从环境配置到Chainlit调用全记录
HY-MT1.8B部署避坑指南:从环境配置到Chainlit调用全记录 1. 引言 1.1 为什么选择HY-MT1.8B 在当今多语言翻译需求日益增长的背景下,找到一个既轻量又高效的翻译模型并非易事。HY-MT1.5-1.8B以其18亿参数的紧凑架构,实现了接近大模型的翻译…...