使用Gitlab实现monorepo多项目CICD
CI/CD是什么
CI/CD(Continuous Intergration/Continuous Delpoy),即持续集成/持续部署,或称为持续集成/持续交付,作为一套面向开发和运维团队的解决方案,CI/CD 主要解决集成新代码和向用户频繁交付应用的问题。更直接地说,就是可以解放开发人员的双手,将时间和精力专注于代码本身。
传统的前端部署往往都要经历:本地代码更新 => 本地打包项目 => 清空服务器相应目录 => 上传项目包至相应目录几个阶段,这些都是机械重复的步骤,并且手动操作非常容易出错。对于这一过程,我们往往可以通过CI/CD 方式进行优化。
从前端的角度看,CICD的流程中涉及:
-
CI:代码
push到托管平台之后的lint测试、单元测试 -
CD:将
build后的项目丢到远端 Nginx 的静态资源目录下
自动化部署的好处
-
按照传统方式
时间成本高:手动部署占用开发时间。
沟通效率低:开发与测试间沟通频繁且易出错。
错误风险高:人为操作易导致配置错误等问题。
难以追踪:缺乏统一的日志记录和追踪。
灵活性差:难以快速响应紧急部署需求。
-
使用自动化部署
节省时间:自动完成部署流程,提升开发效率。
提高沟通效率:实时共享部署状态,减少沟通成本。
减少错误:降低人为错误,提高部署稳定性。
增强代码质量:集成代码检查,确保代码质量。
提高灵活性:快速响应代码变更和紧急部署。
增强可追溯性:记录详细日志,便于问题追踪。
支持CI/CD:加速产品迭代和交付。
构建/部署
说的简单点,就是先利用 webpack 或者 gulp 这类的工具把工程打包,然后把打包得到的文件放在服务器上某个托管静态资源的 Web 容器里,像 Java 就可以放在 Tomcat,不过现在流行用 Nginx 托管静态资源。有了 Web 容器,前端打包的那些文件(比如index.html, main.js等等)就可以被访问到了。
手动档
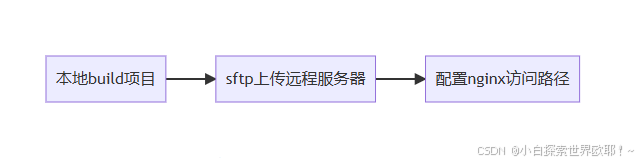
1、本地执行 npm run build构建项目
2、使用 FileZilla 或其他支持 sftp 的软件上传打包后的项目(当然也有其他方式)
3、修改 Nginx 的 nginx.conf 文件,配置项目的访问路径
手动部署操作起来很简单,但缺点也很明显,每次构建完都要人为地进行部署的动作,一方面减少了实际敲代码的时间,另一方面,人工操作免不了会有疏忽出错的时候。
半自动挡
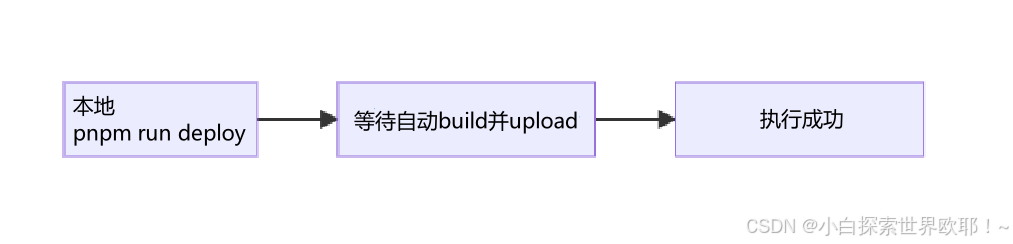
1、本地配置好脚本
2、使用 package.json 中配置的命令执行
3、等待自动打包上传流程结束
虽然这样的操作也很方便且不易出错,但每次都要等待代码打包上传完了才能下机,还是挺浪费时间的。
自动挡
随着工程化的发展和工具链的成熟,项目部署不再像以前简单粗暴。前端代码的健壮性、可靠性越来越被重视,项目发布前往往需要 代码约束 和 代码测试 ,校验通过后服务器拉取最新的代码,进行 build 和 nginx 配置后才算完成整个部署的过程。

1、代码扫描 npm run lint检查代码是否规范
2、npm run unit进行单元测试
3、git push提交更改到远端仓库
4、登录服务器,git pull拉取最新代码
5、npm run build构建项目
6、配置 nginx 访问路径
6、配置 nginx 访问路径 这个阶段,我们借助一些工具,能够减少代码不规范或隐藏bug的问题。
但所有的操作还是得一行一行命令去敲,项目真正的部署也还是需要手动去操作服务器。也可以将上面的操作细节都集成到一个 shell 脚本里,通知执行 shell 也能减少很多重复的工作。
CI/CD 做了什么
一个版本发布的过程主要分为以下几个步骤:
-
代码合并:测试环境或生产环境都有独立的分支,等所有待发版的代码都合并到对应分支后,就可以考虑发版了。
-
打包:或者叫构建。以生产环境部署为例,我们切到生产环境分支并 pull 最新代码后,就可以开始打包步骤了。这一步主要是通过一些 bundler 完成的,比如 webpack。而打包命令一般都是定义在
package.json的scripts中了,比如定义的命令是build:prod,那么只要运行npm run build:prod就行了。 -
部署:把打包得到的文件放在 web 容器中,而 web 容器通常在 Linux 服务器上,这涉及到远程传输文件,这个时候我们一般要借助 shell 脚本或者 xftp。
而 CI/CD 做的事情就是:用自动化技术接管流程。
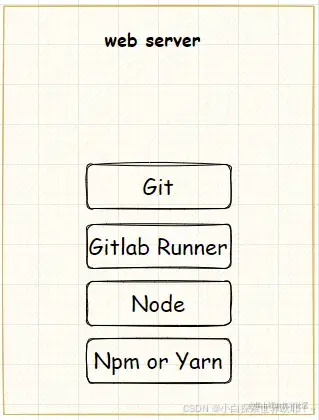
核心工具
GitLab Runner
GitLab Runner是配合GitLab CI/CD完成工作的核心程序,出于性能考虑,GitLab Runner应该与Gitlab部署在不同的服务器上(Gitlab在单独的仓库服务器上,GitLab Runner在部署web应用的服务器上)。GitLab Runner在与GitLab关联后,可以在服务器上完成诸如项目拉取、文件打包、资源复制等各种命令操作。
Git
web服务器上需要安装Git来进行远程仓库的获取工作。
Node
用于在web服务器上完成打包工作。
NPM or Yarn or pnpm
用于在web服务器上完成依赖下载等工作(用yarn,pnpm亦可)。
Gitlab CI/CD是如何工作的
从 GitLab 8.0 开始,GitLab CI 就已经集成在 GitLab 中,我们只要在项目中添加一个 .gitlab-ci.yml 文件,然后添加一个 Runner,即可进行持续集成。 而且随着 GitLab 的升级,GitLab CI 变得越来越强大。
Pipeline
Pipeline 是 CI/CD 的最上层组件,它翻译过来是管道,也可理解为流水线,每一个符合.gitlab-ci.yml触发规则的 CI/CD 任务都会产生一个 Pipeline。这个概念有点像工厂中的车间流水线,我们知道车间中有很多条流水线,不同的流水线可能会处理同一类型的生产任务,也可能处理不同类型的生产任务。当一条流水线空闲的时候,就有可能会被用来安排执行其他的生产任务。而 Gitlab 的 Pipeline 虽然没有空闲的概念,一个 Pipeline 执行结束后也不会被复用,但是会将资源让出来给其他的 Pipeline,所以和车间流水线也有异曲同工之妙。
一次 Pipeline 其实相当于一次构建任务,里面可以包含多个流程,如安装依赖、运行测试、编译、部署测试服务器、部署生产服务器等流程。我们的任何提交或者 Merge Request 的合并都可以触发 Pipeline。
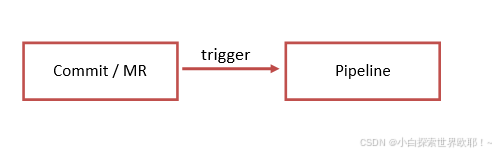
不同 push/merge 所触发的 CI 流程不会互相影响,也就是说,你的一次push引发的CI流程并不会因为接下来另一位同事的push而阻断,它们是互不影响的。这一个特点方便让测试同学根据不同版本进行测试。
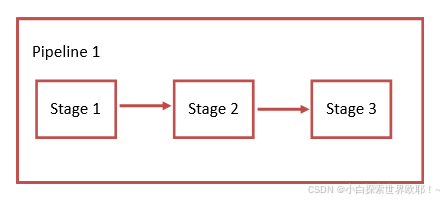
Stages
Stages 表示构建阶段,其实就是上面提到的流程。我们可以在一次 Pipeline 中定义多个 Stages,每个Stage可以完成不同的任务。一个 Pipeline 有若干个stage,每个 stage 上有至少一个 Job。Stages 有下面的特点:
-
所有 Stages 会按照顺序运行,即当一个 Stage 完成后,下一个 Stage 才会开始
-
只有当所有 Stages 完成后,该构建任务 (Pipeline) 才会成功
-
如果任何一个 Stage 失败,那么后面的 Stages 不会执行,该构建任务 (Pipeline) 失败
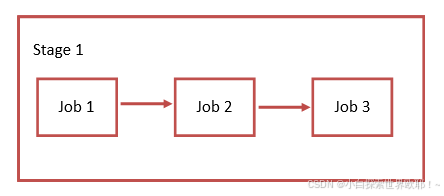
Jobs
Jobs 表示构建工作,就是某个 Stage 里面执行的工作。Job是pipeline的任务节点,它构成了pipeline的基本单元。我们可以在 Stages 里面定义多个 Jobs,每个Job都会配置一个stage属性,表示这个Job所处的阶段。Jobs 有以下特点:
-
相同 Stage 中的 Jobs 会并行执行
-
相同 Stage 中的 Jobs 都执行成功时,该 Stage 才会成功
-
如果任何一个 Job 失败,那么该 Stage 失败,即该构建任务 (Pipeline) 失败
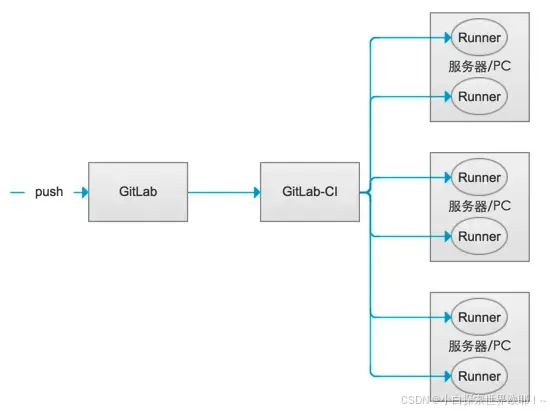
Runner
有了流水线,还必须有辛勤的工人进行生产作业,Runner 在 Gitlab Pipeline 中就扮演着工人角色,根据我们下达的指令进行作业。
它是脚本执行的承载者,.gitlab-ci.yml 的 script 部分的运行就是由 Runner 来负责的。GitLab-CI 浏览过项目里的 .gitlab-ci.yml 文件之后,根据里面的规则,分配到各个 Runner 来运行相应的脚本 script。这些脚本有的是测试项目用的,有的是部署用的。
Runner的类型
在 Gitlab 中,Runner 有很多种,分为 Shared Runner, Group Runner, Specific Runner。
-
Shared Runner 是所有项目都可以使用的,可以理解为机动人员,他可能会在工厂的各个流水线机动作业,随时支援!在整个 Gitlab 应用中,可以服务于各个 Project。使用受运行时间的限制。
-
Specific Runner 只服务于指定的项目,也就是 Project 级别,别的项目咱都不去。使用完全自由。
-
Group Runner 就比较好理解了,他只在这个组上班,别的组他是不会去的。在 Gitlab 中,我们是可以建立不同的 Group 的,比如前端一个 Group,后端一个 Group,甚至前端里面还可以分 N 个 Group。所以,Group Runner 只服务于指定的 Group。
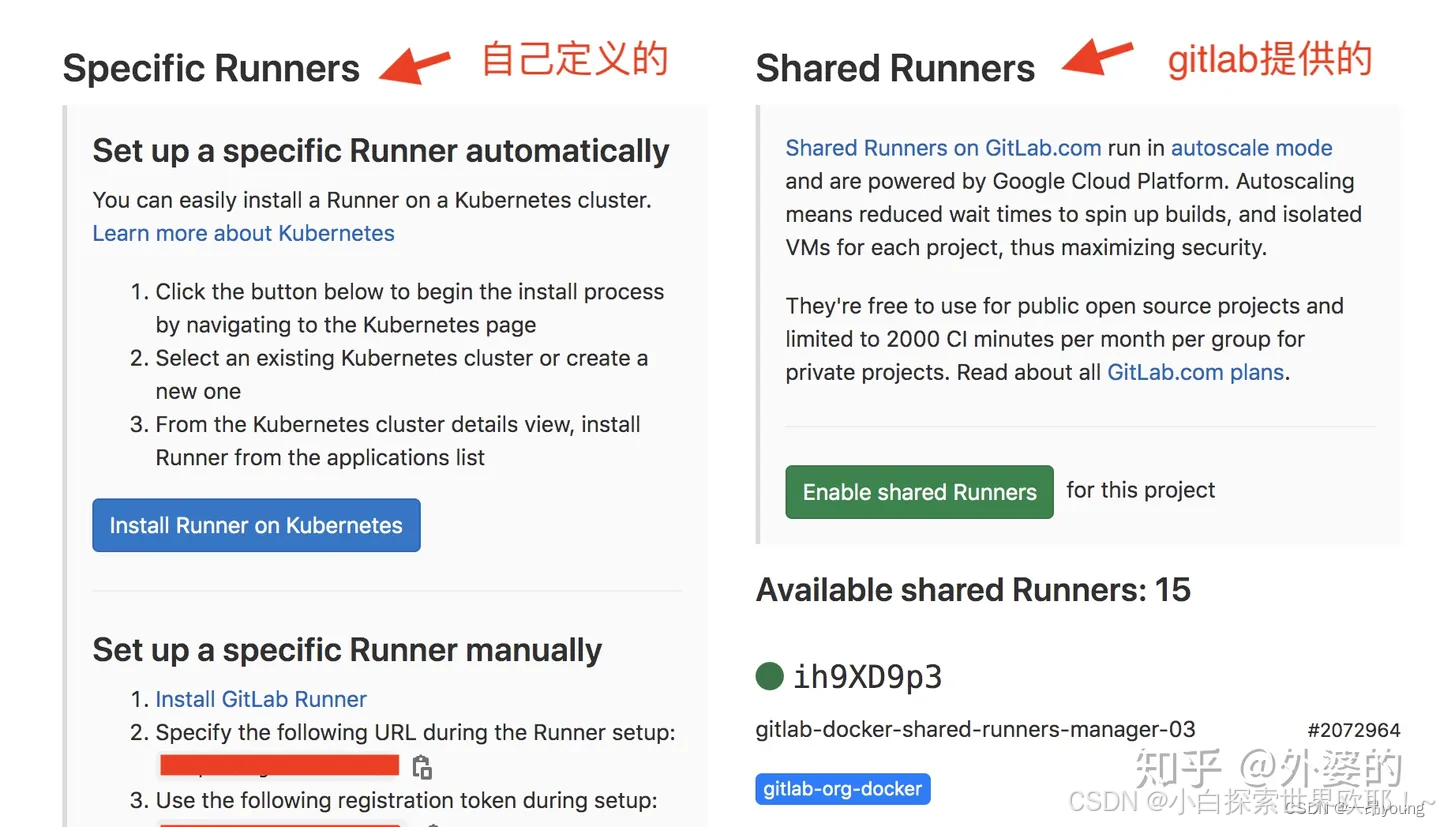
注册Runner
工人是要持证上岗的,同样,Runner 有一个注册的过程,就相当于在工厂中入职登记的意思。具体见 Registering Runners。只有合法注册的 Runner,才有资格执行 Pipeline。
.gitlab-ci.yml
流水线和工人都安排好之后,就必须制定车间生产规章制度了,一条流水线到底怎么干活,总要有个规矩。而
.gitlab-ci.yml文件就是用来制定规则的!它是流水线执行的流程文件,Runner 会据此完成规定的一系列流程,保存并推送至 gitlab 后即可自动开始构建部署,构建中可在 gitlab CI/CD 面板查看构建进程。
.gitlab-ci.yml 是在 git 项目的根目录下的一个文件,记录了一系列的阶段和执行规则。GitLab-CI 在 push 后会解析它,根据里面的内容调用 Runner 来运行。简单来讲,就是当我们 push 了本地代码到 Remote 上(这里就是 gitlab.com),然后 Gitlab就通知服务器,即 Gitlab-Runner 来运行构建任务。然后跑测试用例,测试用例通过了就 build 出相应的环境的代码,自动部署到不同的环境服务器上面去。
配置好 Runner 后,我们要做的事情就是在项目根目录中添加 .gitlab-ci.yml 文件了,可以控制 CI 流程的不同阶段,例如install/检查/编译/部署服务器,gitlab 平台会扫描.gitlab-ci.yml文件,并据此处理ci流程。 当我们添加了 .gitlab-ci.yml 文件后,每次提交代码或合并 MR 都会自动运行构建任务了。
CI 流程在每次 push/merge 之后触发,每当 push/merge 一次,gitlab-ci 都会检查项目下有没有
.gitlab-ci.yml文件,如果有,它会执行里面编写的脚本,并完整地走一遍从 intall => eslint检查 => 编译 => 部署服务器 的流程。
变量 Variables
Gitlab 通过 Variables 为 CI/CD 提供了更多配置化的能力,方便我们快速取得一些关键信息,用来做流程决策。上述示例中的$CI_COMMIT_REF_NAME和$CI_PROJECT_DIR就是 Gitlab 的预定义变量。
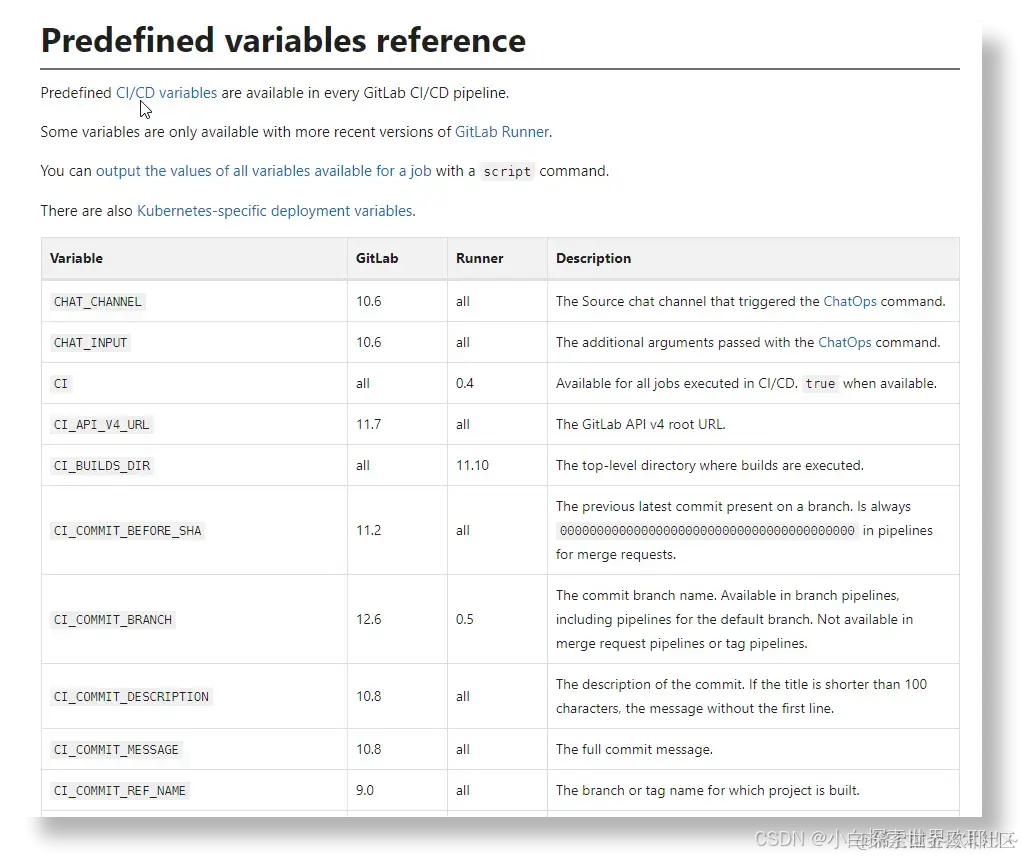
除了预定义变量,我们也可以自行定义一些环境变量,比如服务器 ip,用户名等等,这样就免去了在配置文件中明文列出私密信息的风险;另一方面也方便后期快速调整配置,避免直接修改.gitlab-ci.yml。
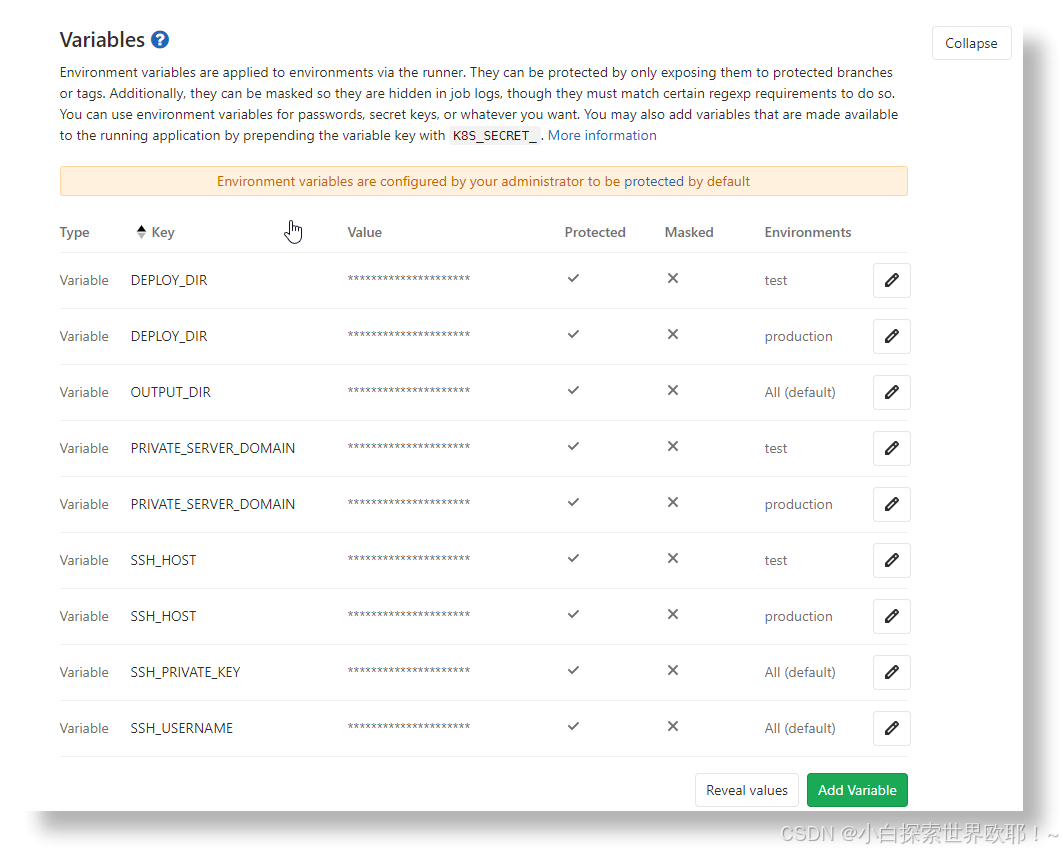
授信问题
在不同主机间通过scp传输文件需要建立信任关系,在 CI/CD 中最好选择免密方式,其基本原理就是把 ssh公钥 交给对方。
在 GitLab 的 CI/CD 流程中,使用 scp 或任何基于 SSH 的命令来在不同的主机之间传输文件时,需要建立一种安全的免密登录方式。这通常通过 SSH 密钥认证来实现,即将一个 SSH 公钥添加到远程服务器的 ~/.ssh/authorized_keys 文件中,这样持有相应私钥的用户就可以无密码登录该服务器了。
使用Gitlab实现多项目CICD
背景
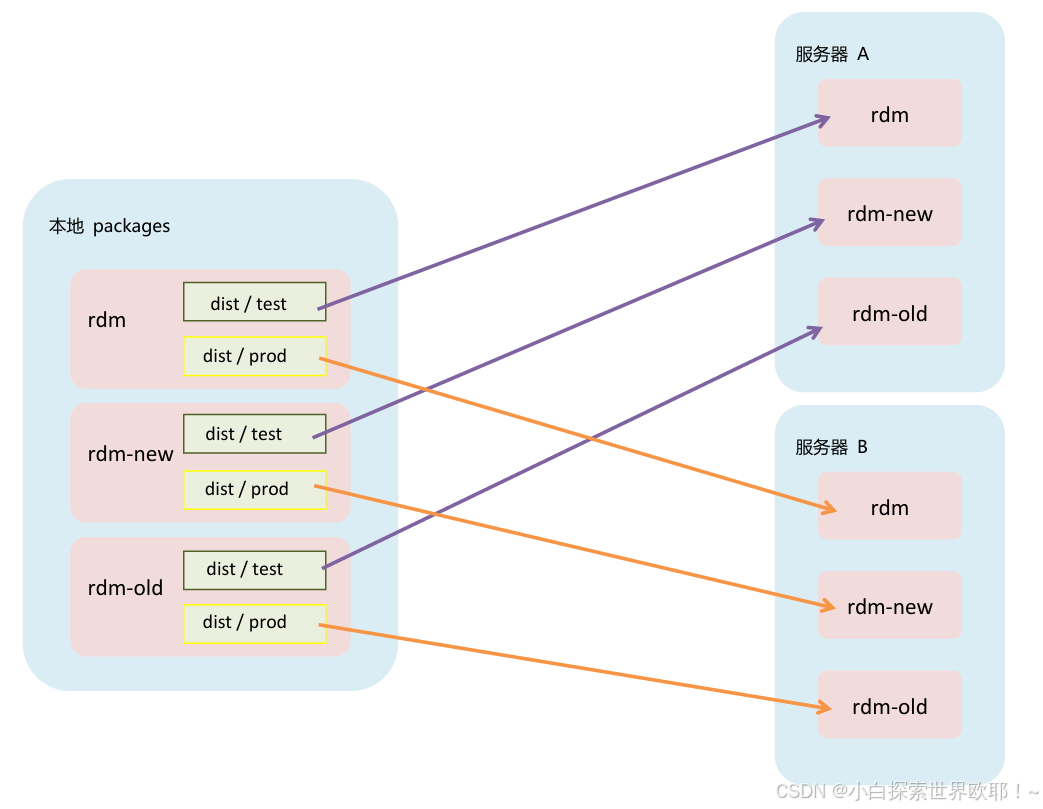
有一个 monorepo 微前端项目,需要一次构建3个项目,放在根目录下的packages文件夹下,分别是rdm、rdm-old、rdm-new,在测试分支打包,分别生成自己的 dist/test,正式服则是 dist/prod,正式服构建到 A 服务器的 rdm、rdm-old、rdm-new 文件夹,测试服到 B 服务器的 rdm、rdm-old、rdm-new 文件夹。现在,我们希望在一次CI/CD流程中构建并部署多个子应用(rdm, rdm-new, rdm-old),同时这些应用需要被部署到不同服务器上的不同的 FTP 目录。
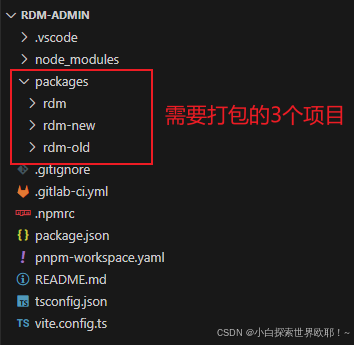

用直观的方式呈现如下图:
方案
为了实现这个需求,我们可以在.gitlab-ci.yml文件中设置一个共同的构建阶段,然后针对不同的环境(测试服和正式服)和不同的子应用设置不同的部署阶段。
# 定义CI/CD的阶段
stages: - build # 构建阶段 - deploy # 部署阶段 # 定义一些全局变量,用于SSH连接和部署
variables: SSH_USER: "用户名" SSH_PASSWORD: "用户密码" SSH_OPTIONS: "-o StrictHostKeyChecking=no" # 定义一个模板,用于SSH部署
.deploy_template: &deploy_template stage: deploy script: - echo "Deploying to $TARGET_SERVER in $DEPLOY_PATH" - sshpass -p "$SSH_PASSWORD" ssh $SSH_USER@$TARGET_SERVER "mkdir -p $DEPLOY_PATH" - sshpass -p "$SSH_PASSWORD" scp -r $SSH_OPTIONS ./dist/$DEPLOY_TYPE/* $SSH_USER@$TARGET_SERVER:$DEPLOY_PATH # RDM 构建和部署
rdm-build: stage: build script: # 构建脚本- cd packages/rdm - pnpm install - pnpm run build:$CI_COMMIT_REF_NAME # 假设你有一个脚本来根据分支构建到不同的目录 - | # 使用管道符来在单行中写多条命令,如果是主分支,将dist目录重命名为dist/prod if [ "$CI_COMMIT_REF_NAME" == "main" ]; then mv dist dist/prod else mv dist dist/test fi artifacts: # 指定要保留的构建产物 paths: - packages/rdm/dist/prod/ # 如果需要包含主分支的产出 - packages/rdm/dist/test/ # 如果需要包含非主分支的产出 rdm-deploy-prod: <<: *deploy_template variables: # 覆盖模板中的变量 TARGET_SERVER: "正式服-服务器 A 地址" DEPLOY_PATH: "/rdm" # 部署路径 DEPLOY_TYPE: "prod" # 部署类型only: # 仅当提交到prod分支时运行- prod rdm-deploy-test: <<: *deploy_template variables: TARGET_SERVER: "测试服-服务器 B 地址" DEPLOY_PATH: "/rdm" DEPLOY_TYPE: "test" except: - main # RDM-OLD
rdm-old-build: stage: build script: - cd packages/rdm-old - pnpm install - pnpm run build:$CI_COMMIT_REF_NAME # 假设你有一个脚本来根据分支构建到不同的目录 - | # 使用管道符来在单行中写多条命令 if [ "$CI_COMMIT_REF_NAME" == "main" ]; then mv dist dist/prod else mv dist dist/test fi artifacts: paths: - packages/rdm-old/dist/prod/ # 如果需要包含主分支的产出 - packages/rdm-old/dist/test/ # 如果需要包含非主分支的产出 rdm-old-deploy-prod: <<: *deploy_template variables: TARGET_SERVER: "正式服-服务器 A 地址" DEPLOY_PATH: "/rdm-old" DEPLOY_TYPE: "prod" only: - prod rdm-old-deploy-test: <<: *deploy_template variables: TARGET_SERVER: "测试服-服务器 B 地址" DEPLOY_PATH: "/rdm-old" DEPLOY_TYPE: "test" except: - main # RDM-NEW
rdm-new-build: stage: build script: - cd packages/rdm-new - pnpm install - pnpm run build:$CI_COMMIT_REF_NAME # 假设这个脚本会根据分支名称构建到不同的目录,但实际上它不会改变dist的目录名 - | # 使用管道符来在单行中写多条命令 if [ "$CI_COMMIT_REF_NAME" == "main" ]; then mv dist dist/prod else mv dist dist/test fi artifacts: paths: - packages/rdm-new/dist/prod/ # 如果需要包含主分支的产出 - packages/rdm-new/dist/test/ # 如果需要包含非主分支的产出 rdm-new-deploy-prod: <<: *deploy_template variables: TARGET_SERVER: "正式服-服务器 A 地址" DEPLOY_PATH: "/rdm-new" DEPLOY_TYPE: "prod" only: - prod rdm-new-deploy-test: <<: *deploy_template variables: TARGET_SERVER: "测试服-服务器 B 地址" DEPLOY_PATH: "/rdm-new" DEPLOY_TYPE: "test" except: - main 参考资料:
Tutorial: Create and run your first GitLab CI/CD pipeline | GitLab
🛫 前端自动化部署:借助Gitlab CI/CD实现 - 掘金 (juejin.cn)
前端的gitlab的ci初尝试 - 掘金 (juejin.cn)
花半天时间,轻松打造前端CI/CD工作流 - 掘金 (juejin.cn)
相关文章:
使用Gitlab实现monorepo多项目CICD
CI/CD是什么 CI/CD(Continuous Intergration/Continuous Delpoy),即持续集成/持续部署,或称为持续集成/持续交付,作为一套面向开发和运维团队的解决方案,CI/CD 主要解决集成新代码和向用户频繁交付应用的问…...

设计模式实战:银行账户管理系统的设计与实现
问题描述 设计一个银行账户管理系统,支持不同类型的账户(如储蓄账户、支票账户)进行存取款操作,并能够在账户余额发生变化时通知相关观察者(如用户、银行系统)。系统需要确保账户操作的灵活性和可扩展性。 设计分析 策略模式 策略模式定义了一系列算法,并将每个算法…...

⭕️【论文阅读】《Interactive Class-Agnostic Object Counting》
[2309.05277] Interactive Class-Agnostic Object Counting (arxiv.org) code: cvlab-stonybrook/ICACount: [ICCV23] Official Pytorch Implementation of Interactive Class-Agnostic Object Counting (github.com) 目录 Abstract Abstract 我们提出了一个新…...

高效的编程学习方法和技巧
编程小白如何成为大神?大学新生的最佳入门攻略 编程已成为当代大学生的必备技能,但面对众多编程语言和学习资源,新生们常常感到迷茫。如何选择适合自己的编程语言?如何制定有效的学习计划?如何避免常见的学习陷阱&…...

sublime text插件开发
手工开发了一些ST的py插件,记录过程中遇到的一些问题。 ST3/ST4 begin_edit问题 报错: begin_edit() missing 2 required positional arguments: edit_token and cmdST3时已经不能直接调view.begin_edit方法了,需要通过runCommandTextComm…...

【Linux网络】网络层协议:IP
本篇博客整理了 TCP/IP 分层模型中网络层的 IP 协议,旨在让读者更加深入理解网络协议栈的设计和网络编程。 目录 一、网络层 二、IP 报头 1)报头与有效载荷的分离 2)有效载荷的上交 3)源 IP 与目的 IP 4)生存时间…...

分布式接口文档聚合,Solon 是怎么做的?
1、分布式接口文档聚合,是什么? 如果你有 “22” 个不同的服务(比如微服务),每个服务都有自己的接口文档。每个服务的文档各自打开,估计你会觉得很麻烦的? 再如果,它们是用 openap…...
多尺度病理图像纹理特征作为肺腺癌预后预测的新指标|文献精读·24-08-09
小罗碎碎念 这一期推文分享的文献是2022年发表于 Journal of Translational Medicine 的一篇文章,目前IF6.1。 这篇文章值得刚入门病理AI领域的老师/同学仔细研读,因为思路清晰,该讲到的流程基本都涉及了,详细讲述了病理图像的各种…...

RAG+Agent项目实践系列:基于本地菜谱知识库的大语言模型RAG+Agent的解决方案设计和实现
RAG+Agent项目实践系列:基于本地菜谱知识库的大语言模型RAG+Agent的解决方案设计和实现 为 A 项目构建一个基于菜谱知识库的问答机器人,由业务方提供一系列菜谱知识库和公司概况介绍材料,根据这些知识库要求实现一个问答机器人: 实现用户对于机器人自我身份和公司情况的回…...

JupyterNotebook添加Anaconda中已有的虚拟环境
比如,在Acaconde中存在一个我已经配置好的虚拟环境pose,现在我想在Jupyter中使用它 那么可以使用ipython kernel install --user --name 你要添加的环境 添加到Jupyter中。 对于Jupyter中已有的代码,就可以在Kernel - chanage kernel中改变内核。...

利用vscode-icons-js在Vue3项目中实现文件图标展示
背景: 在开发文件管理系统或类似的项目时,我们常常需要根据文件类型展示对应的文件图标,这样可以提高用户体验。本文将介绍如何在Vue3项目中利用vscode-icons-js库,实现类似VSCode的文件图标展示效果。 先看效果: 一…...

某赛通电子文档安全管理系统 CDGAuthoriseTempletService1 SQL注入漏洞复现(XVE-2024-19611)
0x01 产品简介 某赛通电子文档安全管理系统(简称:CDG)是一款电子文档安全加密软件,该系统利用驱动层透明加密技术,通过对电子文档的加密保护,防止内部员工泄密和外部人员非法窃取企业核心重要数据资产,对电子文档进行全生命周期防护,系统具有透明加密、主动加密、智能…...

做个一套C#面试题
1.int long float double 分别是几个字节 左到右范围从小到大:byte->short->int->long->float->double 各自所占字节大小:1字节、2字节、4字节、8字节、4字节、8字节 2.System.Object四个公共方法的申明 namespace System {//// 摘要…...

【ML】Pre-trained Language Models及其各种微调模型的实现细节和特点
Pre-trained Language Models及其各种微调模型的实现细节和特点 1. Pre-trained Language Models2. semi-supervised Learning3. zero-shot4. Parameter-Efficient Fine-Tuning4.1 含义:4.2 实现方式: 5. LoRA5.1 LoRA 的主要特点:5.2 LoRA 的…...

YARN单机和集群环境部署教程
目录 一、YARN 单机环境部署1. 环境准备2. 安装 Java3. 下载并安装 Hadoop4. 配置环境变量5. 配置 Hadoop配置 hadoop-env.sh配置 core-site.xml配置 hdfs-site.xml配置 yarn-site.xml配置 mapred-site.xml 6. 格式化 HDFS7. 启动 Hadoop 和 YARN8. 验证 YARN9. 运行一个简单的…...
)
Android SurfaceFlinger——Vsync信号发送(五十二)
通过上一篇文章我们创建了一个 EventThread 线程,并且它持有了 SurfaceFlinger 中 resyncWithRateLimit() 方法的指针。这里我们主要来看一下 EventThread 对信号的处理。 一、发送Vsync信号 当 SurfaceFlinger 执行完 queueBuffer() 方法之后,通过 onFrameAvailable 又会回…...

零基础5分钟上手亚马逊云科技AWS核心云架构知识-用S3桶托管静态网页
简介: 小李哥从今天开始将开启全新亚马逊云科技AWS云计算知识学习系列,适用于任何无云计算或者亚马逊云科技技术背景的开发者,让大家0基础5分钟通过这篇文章就能完全学会亚马逊云科技一个经典的服务开发架构。 我将每天介绍一个基于亚马逊云…...

YOLO:使用labelme进行图片数据标签制作,并转换为YOLO格式
作者:CSDN _养乐多_ 本文将介绍如何使用 labelme 进行图片数据标签制作的方法,并将标签的格式从 JSON 格式转换为 YOLO 格式。 文章目录 一、安装labelme二、使用流程三、json格式转为YOLO格式四、按比例划分数据集(训练、验证、测试&#…...

论文解读(15)-UrbanGPT
加油,这一篇也是感受一下大语言模型的力量! 原文: UrbanGPT: Spatio-Temporal Large Language Models UrbanGPT: Spatio-Temporal Large Language Models (arxiv.org) 参考: 时空预测与大语言模型的奇妙碰撞!UrbanG…...

大数据湖体系规划与建设方案(51页PPT)
方案介绍: 大数据湖通过集中存储各种类型的数据(包括结构化、半结构化和非结构化数据),提供了更加灵活、可扩展的数据处理和分析能力。其核心理念是“存储一切,分析一切,创建所需”,即将所有数…...

你的 Android App 可能白白损失了 35% 的性能——R8 全模式配置详解
字节跳动的工程师优化启动速度时,可能花了数周分析 trace、改代码;Monzo 的团队却只改了一行配置,性能指标全线提升了 35%。这不是段子,是 Google 官方 blog 2026 年 3 月底发出来的案例。 问题来了:你的项目ÿ…...

Hyperf方案 分库分表实现
<?php /*** 案例标题:分库分表实现* 说明:基于用户ID取模实现分表路由,水平分片存储海量订单数据* 需要安装的包:* composer require hyperf/db-connection*/declare(strict_types1);// app/Sharding/ShardingStrategy.php…...
)
从Proteus 8.13升级到8.15:为了串口通信,我做了这些事(附完整迁移与配置指南)
从Proteus 8.13升级到8.15:串口通信修复与平滑迁移实战指南 当你的电路仿真项目频繁遭遇串口通信异常,调试窗口不断弹出"COM Port Error"时,很可能是Proteus 8.13版本的已知缺陷在作祟。作为深度使用者,我经历过三次关键…...

实战应用:基于快马平台开发企业级极域电子教室校园分发与管理系统
实战应用:基于快马平台开发企业级极域电子教室校园分发与管理系统 最近接手了一个校园信息化项目,需要为某中学开发一套极域电子教室的分发管理系统。学校希望实现软件版本的分班级分时段管理,同时避免下载高峰期的网络拥堵。经过调研&#…...

nli-distilroberta-base生产环境:低延迟NLI服务在搜索Query改写中应用
nli-distilroberta-base生产环境:低延迟NLI服务在搜索Query改写中应用 1. 项目概述 在搜索引擎优化和智能问答系统中,Query改写是一个关键环节。nli-distilroberta-base是一个基于DistilRoBERTa模型的轻量级自然语言推理(NLI)服务,专门为生…...

网站 SEO 优化检查需要检查哪些方面
网站 SEO 优化检查需要检查哪些方面 在当今互联网时代,一个网站的成功与否在很大程度上取决于其在搜索引擎上的表现。搜索引擎优化(SEO)是提升网站在搜索结果中排名的重要手段。但是,SEO 并不是一劳永逸的事情,需要持…...

uosc与其他MPV脚本对比:为什么uosc是极简MPV播放器UI的终极选择
uosc与其他MPV脚本对比:为什么uosc是极简MPV播放器UI的终极选择 【免费下载链接】uosc Feature-rich minimalist proximity-based UI for MPV player. 项目地址: https://gitcode.com/gh_mirrors/uo/uosc 在众多MPV播放器UI脚本中,uosc以其独特的…...
系统调用详解)
Linux文件偏移量与lseek()系统调用详解
1. 文件读写位置基础概念在Linux系统中,每次打开一个文件时,内核都会维护一个称为"文件偏移量"的指针。这个指针决定了下一个read()或write()操作将从文件的哪个位置开始执行。理解这个机制对于进行精确的文件操作至关重要。文件偏移量从0开始…...

Ubuntu软件包依赖关系全解析,动态规划 - 回文子串问题。
查找软件包的依赖关系 在Ubuntu中,可以使用apt-cache命令查看软件包的依赖关系。运行以下命令列出指定软件包的所有依赖项: apt-cache depends <package-name>将<package-name>替换为目标软件包名称。该命令会显示直接依赖、推荐依赖以及可选…...
 实现原理与生产应用)
AI Agent 时代的分布式闭源众创 AI Coding 云编程平台 (CSCD) 实现原理与生产应用
AI Agent 时代的分布式闭源众创 AI Coding 云编程平台 (CSCD) 实现原理与生产应用 文章目录 AI Agent 时代的分布式闭源众创 AI Coding 云编程平台 (CSCD) 实现原理与生产应用 第 1 章 AI Agent 时代与 CSCD 平台概述 1.1 AI Agent 时代的到来 1.1.1 从传统编程到 AI 辅助编程的…...