哈佛大学单细胞课程|笔记汇总 (二)
哈佛大学单细胞课程|笔记汇总 (一)
(二)Single-cell RNA-seq data - raw data to count matrix
根据所用文库制备方法的不同,RNA序列(也被称为reads或tag)将从转录本((10X Genomics, CEL-seq2, Drop-seq, inDrops)的3'端(或5'端)或全长转录本(Smart-seq)中获得。
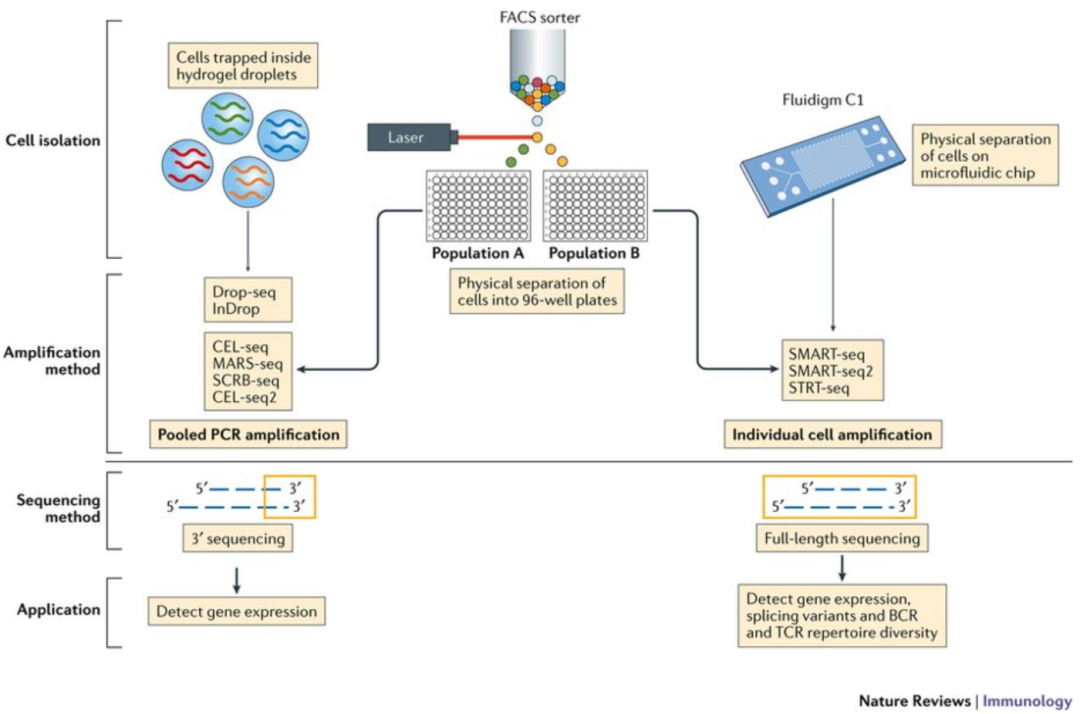
Image credit: Papalexi E and Satija R. Single-cell RNA sequencing to explore immune cell heterogeneity, Nature Reviews Immunology 2018 (https://doi.org/10.1038/nri.2017.76)
不同测序方式的优点:
3’(或5’)末端测序:
-
通过使用UMI进行更准确的定量,从而将生物学重复与扩增重复(PCR)区别开来;
-
测序的细胞数量更多,可以更好地鉴定细胞类型群;
-
每个细胞成本更低;
-
大于10,000个细胞的结果最佳
全长测序:
-
检测亚型水平(
isoform-level)表达差异; -
鉴定等位基因特异性差异表达;
-
对较少数量的细胞进行更深的测序;
-
最适用于细胞数少的样品。
我们将主要介绍3’端测序,重点是基于液滴的方法 (inDrops, Drop-seq, 10X Genomics)。
3’-end reads (includes all droplet-based methods)
在3’端测序中,同一转录本的不同reads片段仅会源自转录本的3’端,相同序列的可能性很高,同时在建库过程中的PCR步骤可能导致reads的重复,因此为了区分是生物学还是技术上的重复,我们使用唯一标识符(unique molecular identifiers,UMI)进行标注。
-
比对到相同的转录本、UMI不同的reads来源于不同的分子,为正常生物转录,每个read都被计数。
-
UMI相同的reads来自同一分子,为技术重复,计为1个read。
-
上面两条描述是理想情况,方便理解,实际处理起来要复杂一些。
我们以下图为例,下图中分子ACTB的UMI均相同,因此只能记为1个molecule,而ARL1的UMI不同所以可以记为2个molecule。
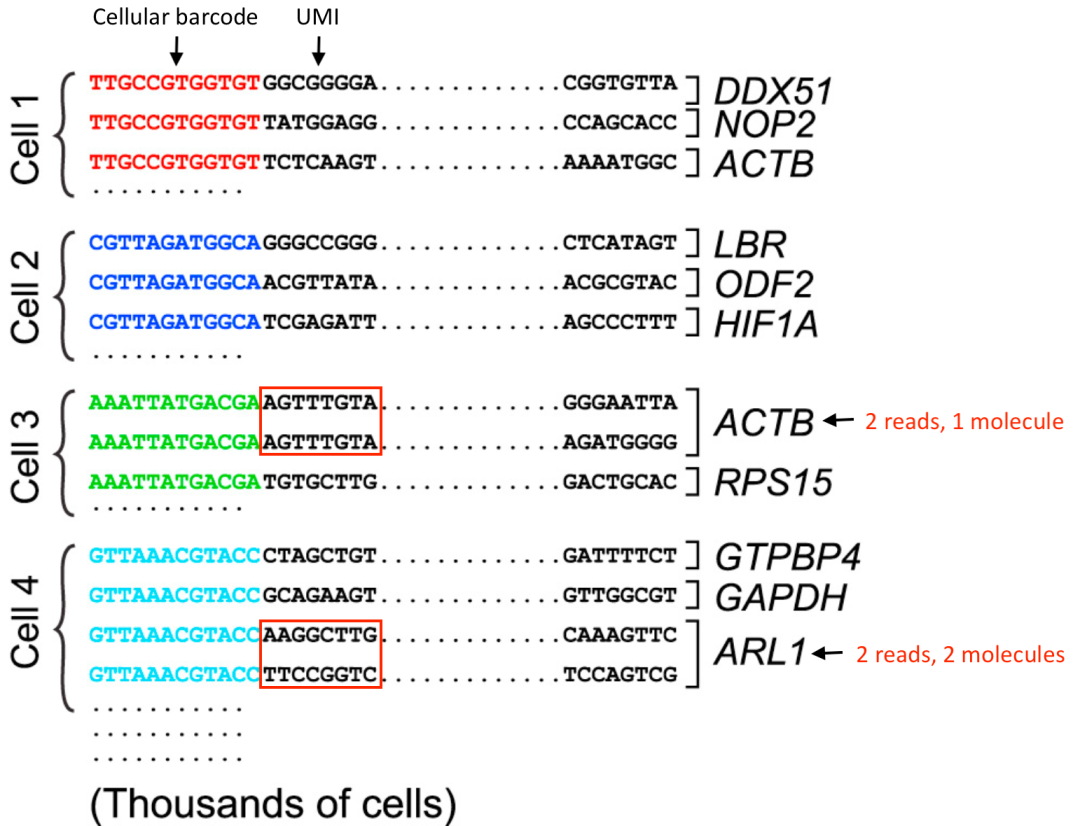
Image credit: modified from Macosko EZ et al. Highly Parallel Genome-wide Expression Profiling of Individual Cells Using Nanoliter Droplets, Cell 2015 (https://doi.org/10.1016/j.cell.2015.05.002)_
在细胞水平进行正确定量都需要以下条件:
-
Sample index: 样本来源
-
Added during library preparation - needs to be documented
-
-
Cellular barcode: 细胞来源
-
Each library preparation method has a stock of cellular barcodes used during the library preparation
-
-
Unique molecular identifier (UMI): 转录本来源
-
The UMI will be used to collapse PCR duplicates
-
-
Sequencing read1: the Read1 sequence
-
Sequencing read2: the Read2 sequence
例如,使用inDrops v3库准备方法时,以下内容是reads的所有信息:
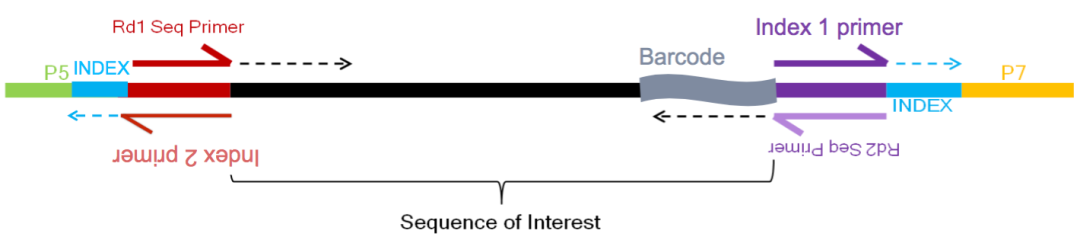
Image credit: Sarah Boswell(https://scholar.harvard.edu/saboswell), Director of the Single Cell Sequencing Core at HMS_
-
R1 (61 bp Read 1): sequence of the read (Red top arrow)
-
R2 (8 bp Index Read 1 (i7)): cellular barcode - which cell read originated from (Purple top arrow)
-
R3 (8 bp Index Read 2 (i5)): sample/library index - which sample read originated from (Red bottom arrow)
-
R4 (14 bp Read 2): read 2 and remaining cellular barcode and UMI - which transcript read originated from (Purple bottom arrow)
对于不同的基于液滴的scRNA-seq方法,scRNA-seq的分析工作流程相似,但是UMI、细胞ID和样品索引的解析会有所不同。例如,以下是10X序列reads的示意图,其中index,UMI和barcode的位置不同 :
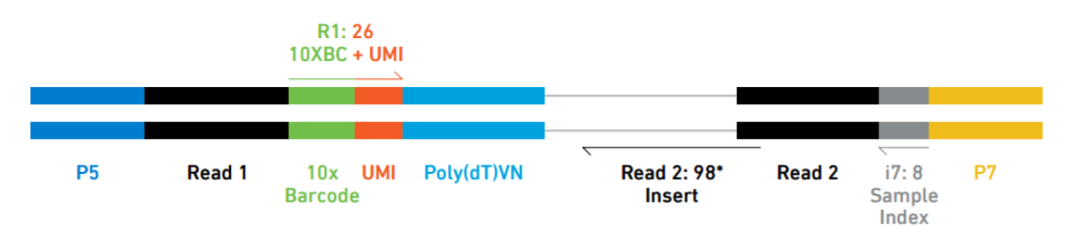
Image credit: Sarah Boswell(https://scholar.harvard.edu/saboswell), Director of the Single Cell Sequencing Core at HMS_
Single-cell RNA-seq workflow
scRNA-seq方法能通过测序的reads解析barcodes和UMI,它们在特定步骤里会轻微地不同,但除了方法外,大致流程都是一致的,常规工作流程如下所示:
Image credit: Luecken, MD and Theis, FJ. Current best practices in single‐cell RNA‐seq analysis: a tutorial, Mol Syst Biol 2019 (doi: https://doi.org/10.15252/msb.20188746) 中文解读见:重磅综述:三万字长文读懂单细胞RNA测序分析的最佳实践教程 (原理、代码和评述)
工作流程的步骤是:
-
生成count矩阵(
method-specific steps):reads格式化,对样本进行多路分解(
demultiplexing,即通过barcodes确定reads的来源),比对和定量。 -
原始count的质量控制:
过滤质量较差的细胞。
-
细胞聚类:
基于转录活性的相似性对细胞进行聚类(细胞类型数=簇数)?
-
marker识别:识别每个cluster的标记基因。
-
可选的下游步骤。
无论进行那种分析,生物学重复都是必要的!
Generation of count matrix

我们聚焦于基于液滴型的3’端测序(比如inDrops、10X Genomics和Drop-seq),将原始测序数据转换为count矩阵。
测序工具将以BCL或FASTQ格式输出原始测序数据,或生成count矩阵。如果reads是BCL格式,我们将需要转换为FASTQ格式。有一个有用的命令行工具bcl2fastq,可以轻松执行此转换。
NOTE: We do not demultiplex at this step in the workflow. You may have sequenced 6 samples, but the reads for all samples may be present all in the same BCL or FASTQ file.
对于许多scRNA-seq方法,从原始测序数据中生成count矩阵都将经历相似的步骤。
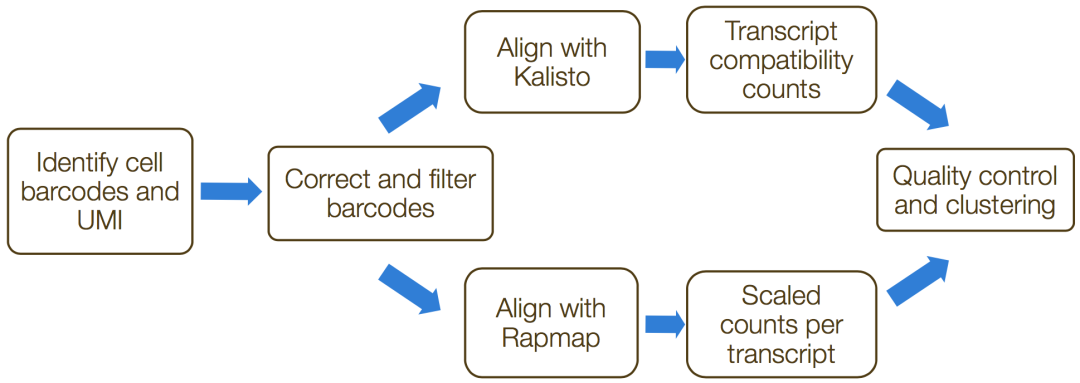
umis(https://github.com/vals/umis)和`zUMIs`(https://github.com/vals/umis)是命令行工具,可用于估计测转录本3'端的scRNA-seq数据的表达。此过程中的步骤包括:
-
格式化reads并过滤嘈杂的细胞
barcodes; -
Demultiplexing the samples(通过barcodes确定reads的来源); -
比对/伪比对到转录本;
-
折叠UMI和定量reads。
当然,如果使用10X Genomics建库方法,Cell Ranger pipeline(https://support.10xgenomics.com/single-cell-gene-expression/software/pipelines/latest/what-is-cell-ranger)将负责执行以上的所有步骤 (10X单细胞测序分析软件:Cell ranger,从拆库到定量)。
格式化reads并过滤非细胞barcodes:
FASTQ文件能解析得到细胞barcodes、UMIs和样本barcodes。对于基于液滴型的方法,一些细胞barcodes会对应的低的reads数(< 1000 reads) ,原因是:
-
encapsulation of free floating RNA from dying cells
-
simple cells (RBCs, etc.) expressing few genes
-
cells that failed for some reason 在比对reads之前,需要从序列数据中过滤掉多余的条形码。
为了进行这种过滤,提取并保存每个细胞的“细胞条形码”和“分子条形码”。
例如,如果使用
“umis”工具,则信息将以以下格式添加到每条reads的标题行中 (NGS基础 - FASTQ格式解释和质量评估):
@HWI-ST808:130:H0B8YADXX:1:1101:2088:2222:CELL_GGTCCA:UMI_CCCT
AGGAAGATGGAGGAGAGAAGGCGGTGAAAGAGACCTGTAAAAAGCCACCGN
+
@@@DDBD>=AFCF+<CAFHDECII:DGGGHGIGGIIIEHGIIIGIIDHII#建库中使用的细胞条形码应该是已知的,未知的条形码会被丢弃,同时对于已知的细胞条形码允许一定的错配。
Demultiplexing the samples:
如果测序多于一个样品执行此步骤,这是一步不由“umis”工具处理,而由“zUMIs”完成的步骤,这步会解析reads以确定与每个与细胞相关的样本条形码。
比对/伪比对到转录:
通过传统(STAR)或轻量型(Kallisto/RapMap)方法,将reads比对回基因。
折叠UMI和定量reads:
使用Kallisto或featureCounts之类的工具仅对唯一的UMI进行量化,得到
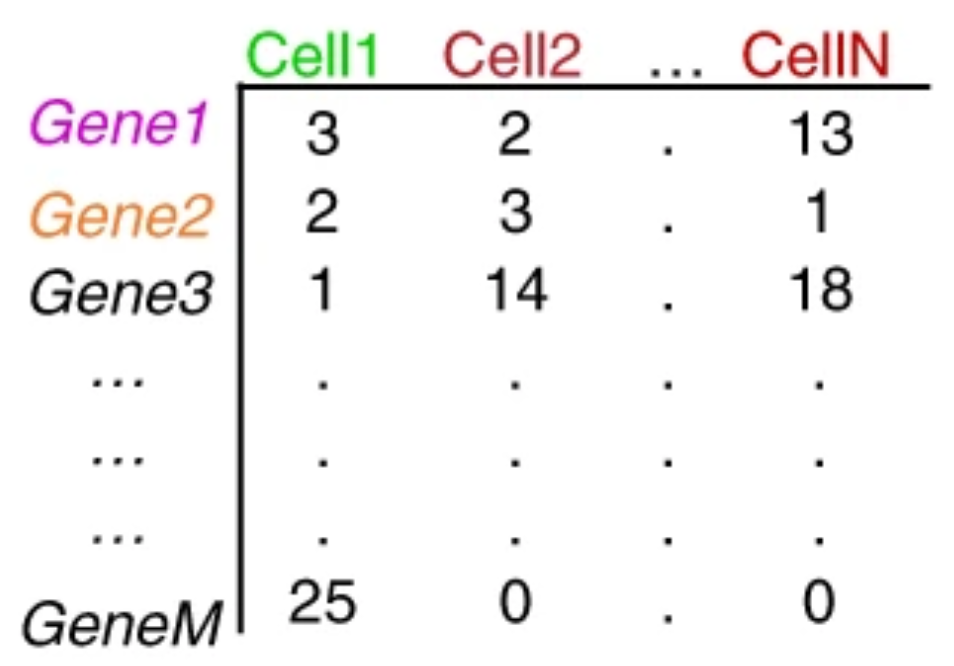
Image credit: extracted from Lafzi et al. Tutorial: guidelines for the experimental design of single-cell RNA sequencing studies, Nature Protocols 2018 (https://doi.org/10.1038/s41596-018-0073-y)
矩阵中的每个值代表源自相应基因在各个细胞中的reads数。
相关文章:
哈佛大学单细胞课程|笔记汇总 (二)
哈佛大学单细胞课程|笔记汇总 (一) (二)Single-cell RNA-seq data - raw data to count matrix 根据所用文库制备方法的不同,RNA序列(也被称为reads或tag)将从转录本((10X Genomic…...

java中抽象类和接口的区别
文章目录 接口和抽象类的区别一、定义的区别1、抽象类2、接口 二、使用场景的区别1、抽象类2、接口 三、使用案例1、抽象类2、接口 接口和抽象类的区别 一、定义的区别 1、抽象类 关键字: abstract 是模棱两可的,似是而非的,无法给出具体明…...

Spring Boot - 在Spring Boot中实现灵活的API版本控制(下)_ 封装场景启动器Starter
文章目录 Pre设计思路ApiVersion 功能特性使用示例配置示例 ProjectStarter Code自定义注解 ApiVersion配置属性类用于管理API版本自动配置基于Spring MVC的API版本控制实现WebMvcRegistrations接口,用于自定义WebMvc的注册逻辑扩展RequestMappingHandlerMapping的类…...
EasyCVR视频转码:T3视频平台不支持GB28181协议,应该如何实现与视频联网平台的对接与视频共享呢?
EasyCVR视频管理系统以其强大的拓展性、灵活的部署方式、高性能的视频能力和智能化的分析能力,为各行各业的视频监控需求提供了优秀的解决方案。 T3视频为公网HTTP-FLV或HLS格式的视频流,目前T3平台暂不支持国标GB28181协议,因此也无法直接接…...

Spring统一处理请求响应与异常
在web开发中,规范所有请求响应类型,不管是对前端数据处理,还是后端统一数据解析都是非常重要的。今天我们简单的方式实现如何实现这一效果 实现方式 定义响应类型 public class ResponseResult<T> {private static final String SUC…...
 WITH common_table_expression)
SqlServer公用表表达式 (CTE) WITH common_table_expression
SQL Server 中的公用表表达式(Common Table Expressions,简称 CTE)是一种临时命名的结果集,它在执行查询时存在,并且只在该查询执行期间有效。CTE 类似于一个临时的视图或者一个内嵌的查询,但它提供了更好的…...
常见中间件漏洞
Tomcat CVE-2017-12615 1.打开环境,抓包 2.切换请求头为 PUT,请求体添加木马,并在请求头添加木马文件名 1.jsp,后方需要以 / 分隔 3.连接 后台弱口令部署war包 1.打开环境,进入指点位置,账户密码均为 tomcat 2.在此处上传一句话…...

elasticsearch的学习(二):Java api操作elasticsearch
简介 使用Java api操作elasticsearch 创建maven项目 pom.xml文件 <?xml version"1.0" encoding"UTF-8"?><project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi…...

docker 部署 ElasticSearch;Kibana
ELasticSearch 创建网络 docker network create es-netES配合Kibana使用时需要组网,使两者运行在同一个网络下 命令 docker run -d \ --name es \ -e "discovery.typesingle-node" \ -v /usr/local/es/data:/usr/share/elasticsearch/data \ -v /usr/…...

k8s使用kustomize来部署应用
k8s使用kustomize来部署应用 本文主要是讲述kustomzie的基本用法。首先,我们说一下部署文件的目录结构。 ./ ├── base │ ├── deployment.yaml │ ├── kustomization.yaml │ └── service.yaml └── overlays└── dev├── kustomization.…...

基于开源FFmpeg和SDL2.0的音视频解码播放和存储系统的实现
目录 1、FFMPEG简介 2、SDL简介 3、视频播放器原理 4、FFMPEG多媒体编解码库 4.1、FFMPEG库 4.2、数据类型 4.3、解码 4.3.1、接口函数 4.3.2、解码流程 4.4、存储(推送) 4.4.1、接口函数 4.4.2、存储流程 5、SDL库介绍 5.1、数据结构 5.…...

保姆级教程,一文了解LVS
目录 一.什么是LVS tips: 二.优点(为什么要用LVS?) 三.作用 四.程序组成 五.LVS 负载均衡集群的类型 六.分布式内容 六.一.分布式存储 六.二.分布式计算 六.三.分布式常见应用 tips: 七.LVS 涉及相关的术语 八.LVS 负…...

【STM32】DMA数据转运(存储器到存储器)
本篇博客重点在于标准库函数的理解与使用,搭建一个框架便于快速开发 目录 DMA简介 DMA时钟使能 DMA初始化 转运起始和终止的地址 转运方向 数据宽度 传输次数 转运触发方式 转运模式 通道优先级 开启DMA通道 DMA初始化框架 更改转运次数 DMA应用实例-…...

【Android】通过代码打开输入法
获取焦点 binding.editText.requestFocus()打开键盘 val imm getSystemService(InputMethodManager::class.java) imm.showSoftInput(binding.editText, InputMethodManager.SHOW_IMPLICIT)...

爬虫集群部署:Scrapyd 框架深度解析
🕵️♂️ 爬虫集群部署:Scrapyd 框架深度解析 🛠️ Scrapyd 环境部署 Scrapyd 是一个开源的 Python 爬虫框架,专为分布式爬虫设计。它允许用户在集群中调度和管理爬虫任务,并提供了简洁的 API 进行控制。以下是 Scr…...

pytorch GPU操作事例
>>> import torch >>> if_cuda torch.cuda.is_available() >>> print("if_cuda",if_cuda) if_cuda True >>> gpu_count torch.cuda.device_count() >>> print("gpu_count",gpu_count) gpu_count 8...

linux常见性能监控工具
常用命令top、free 、vmsata、iostat 、sar命令 具体更详细命令可以查看手册,这里只是简述方便找工具 整体性能top,内存看free,磁盘cpu内存历史数据可以vmsata、iostat 、sar、iotop top命令 交互:按P按照CPU排序,按M按照内存…...

C++ | Leetcode C++题解之第331题验证二叉树的前序序列化
题目: 题解: class Solution { public:bool isValidSerialization(string preorder) {int n preorder.length();int i 0;int slots 1;while (i < n) {if (slots 0) {return false;}if (preorder[i] ,) {i;} else if (preorder[i] #){slots--;i…...

【多模态处理】利用GPT逐一读取本地图片并生成描述并保存,支持崩溃后从最新进度恢复
【多模态处理】利用GPT逐一读取本地图片并生成描述,支持崩溃后从最新进度恢复题 代码功能:核心功能最后碎碎念 代码(使用中转平台url):代码(直接使用openai的key) 注意 代码功能: 读…...

【rk3588】获取相机画面
需求:获取相机画面,并在连接HDMI线,在显示器上显示 查找设备 v4l2-ctl --list-devices H65 USB CAMERA: H65 USB CAMERA (usb-0000:00:14.0-1):/dev/video2/dev/video3播放视频 gst-launch-1.0 v4l2src device/dev/video22 ! video/x-ra…...

Habitat入门教程:如何构建你的第一个自动化应用包
Habitat入门教程:如何构建你的第一个自动化应用包 【免费下载链接】habitat Modern applications with built-in automation 项目地址: https://gitcode.com/gh_mirrors/hab/habitat Habitat是一个现代化的应用自动化平台,它通过内置的自动化功能…...

SVG-Morpheus实战教程:10个实用技巧打造惊艳UI动画
SVG-Morpheus实战教程:10个实用技巧打造惊艳UI动画 【免费下载链接】SVG-Morpheus JavaScript library enabling SVG icons to morph from one to the other. It implements Material Designs Delightful Details transitions. (THIS PROJECT IS NOT MAINTAINED ANY…...

颠覆式网盘直连提取革新:ctfileGet让高速下载成为现实
颠覆式网盘直连提取革新:ctfileGet让高速下载成为现实 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 副标题:突破下载限速困境,3步实现城通网盘直链高效提取 ctfil…...

Windows Defender Remover:系统优化工具与安全组件管理指南
Windows Defender Remover:系统优化工具与安全组件管理指南 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirror…...

2026.4.5
线段树+lazy标记#include<bits/stdc.h> using namespace std; #define int long long #define N 100004 int num[N],tree[4*N],n,q,ans; int len[4*N],lazy[4*N]; char op; int a1,a2,a3; void updata(int xx) {tree[xx]tree[xx*2]tree[xx*21];len[xx]len[xx*…...

AI辅助开发:让快马AI设计智能引擎,深度解决synaptics.exe映像损坏
最近在帮朋友解决一个头疼的Windows系统问题——synaptics.exe损坏的映像错误。这个错误不仅影响触控板功能,还会导致各种奇怪的系统行为。作为一个开发者,我决定尝试用AI辅助开发的方式,打造一个智能诊断修复工具。下面分享我的实践过程&…...

2025.07.15【甲基化】methylKit实战指南:从Bioconductor安装到差异甲基化区域精准注释
1. methylKit:甲基化数据分析的瑞士军刀 第一次接触甲基化数据分析时,我被各种专业术语和复杂流程搞得晕头转向。直到发现了methylKit这个神器,才真正体会到什么叫"一站式解决方案"。作为R语言环境下最成熟的甲基化分析工具之一&a…...
)
mujoco无人机实战建模(二)
前言 我们先复习一下我们的建模顺序 1.全局环境搭建 2.资源准备 3.骨架构建 4.定义自由度(Joints)5.添加形状(Geoms)6添加约束与传动 7 添加动力 8 添加观测 如果有忘记的伙伴可以去看我的第一篇文章mujoco建模(一) 我们这篇文…...

Kratos 的config.proto 修改后 windows 下重新生成
protoc --proto_path. --proto_path./third_party --go_outpathssource_relative:. internal/conf/conf.proto...

BiliTools:解锁B站学习新姿势,5分钟掌握视频AI总结与智能下载
BiliTools:解锁B站学习新姿势,5分钟掌握视频AI总结与智能下载 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bili…...