【经验总结】ShardingSphere5.2.1 + Springboot 快速开始
Sharding Sphere 官方文档地址:
- https://shardingsphere.apache.org/document/current/cn/overview/
- maven仓库:https://mvnrepository.com/artifact/org.apache.shardingsphere/shardingsphere-jdbc
官方的文档写的很详尽到位,这里会截取部分文档内容便于理解和快速上手,强烈推荐阅读官方文档原文
什么是 ShardingSphere
一、介绍ShardingSphere
Apache ShardingSphere (本文后续简称“SS”)是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。
ShardingSphere一般指代的是以下两个产品:
- ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。
- ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。
关于 《Database Plus 设计哲学》
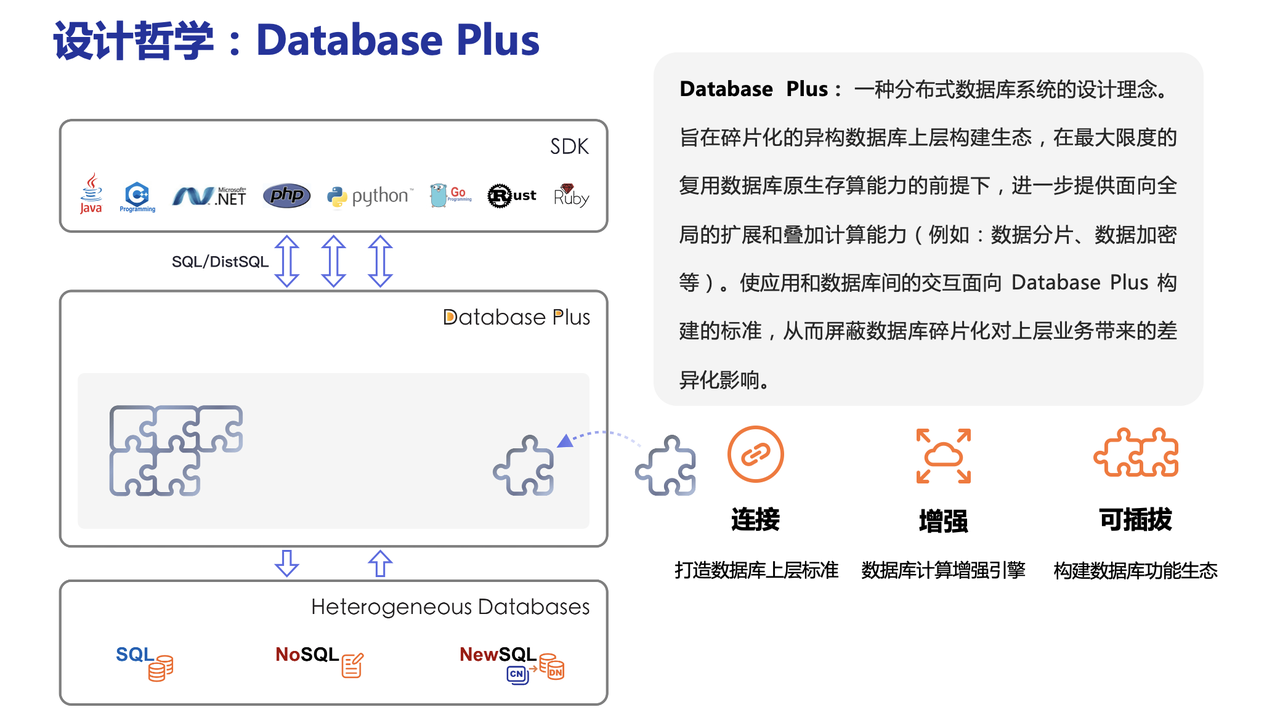
二、部署形态
| ShardingSphere-JDBC | ShardingSphere-Proxy | |
|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 仅 Java | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
| 直观理解 | 引入服务内部使用,配置后实现多数据源管理 | 代理数据库,对服务相当于直连数据库 |
ShardingSphere-JDBC 独立部署
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。
ShardingSphere-Proxy 独立部署
ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。 目前提供 MySQL 和 PostgreSQL 协议,透明化数据库操作,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
- 兼容 MariaDB 等基于 MySQL 协议的数据库,以及 openGauss 等基于 PostgreSQL 协议的数据库;
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端,如:MySQL Command Client, MySQL Workbench, Navicat 等。
混合部署架构
进阶,暂不考虑
三、快速开始选项
采用ShardingSphere-JDBC单机部署,结合springboot,管理postgresql数据库
快速开始
最新的5.5.0配置手册不够详致,这里找到历史的的使用手册(SPRING BOOT STARTER)
- https://shardingsphere.apache.org/document/5.0.0/cn/user-manual/
- https://shardingsphere.apache.org/document/5.2.1/cn/user-manual/
关于版本选择:
这里使用5.0.0版本,5.0.0的spring-boot-starter的版本存在一些bug和官方文档对不起来,改用5.2.1
一、环境准备
必备的依赖
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>${shardingsphere.version}</version>
</dependency>
搭配一些环境基础的依赖
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.2</version>
</dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional>
</dependency><dependency><groupId>org.postgis</groupId><artifactId>postgis-jdbc</artifactId><version>1.3.3</version><scope>compile</scope>
</dependency>
yaml读取错误问题和解决方案
解决方案:https://blog.csdn.net/weixin_47899191/article/details/130743334
报错信息如下:
***************************
APPLICATION FAILED TO START
***************************Description:
An attempt was made to call a method that does not exist. The attempt was made from the following location:org.apache.shardingsphere.infra.util.yaml.constructor.ShardingSphereYamlConstructor$1.<init>(ShardingSphereYamlConstructor.java:44)
解决方案:
覆盖springboot2.x的SnakeYAML依赖,如果你是sringboot3.x,可能不需要,作者没有尝试。
原因参考github上的Issues:https://github.com/apache/shardingsphere/issues/21476
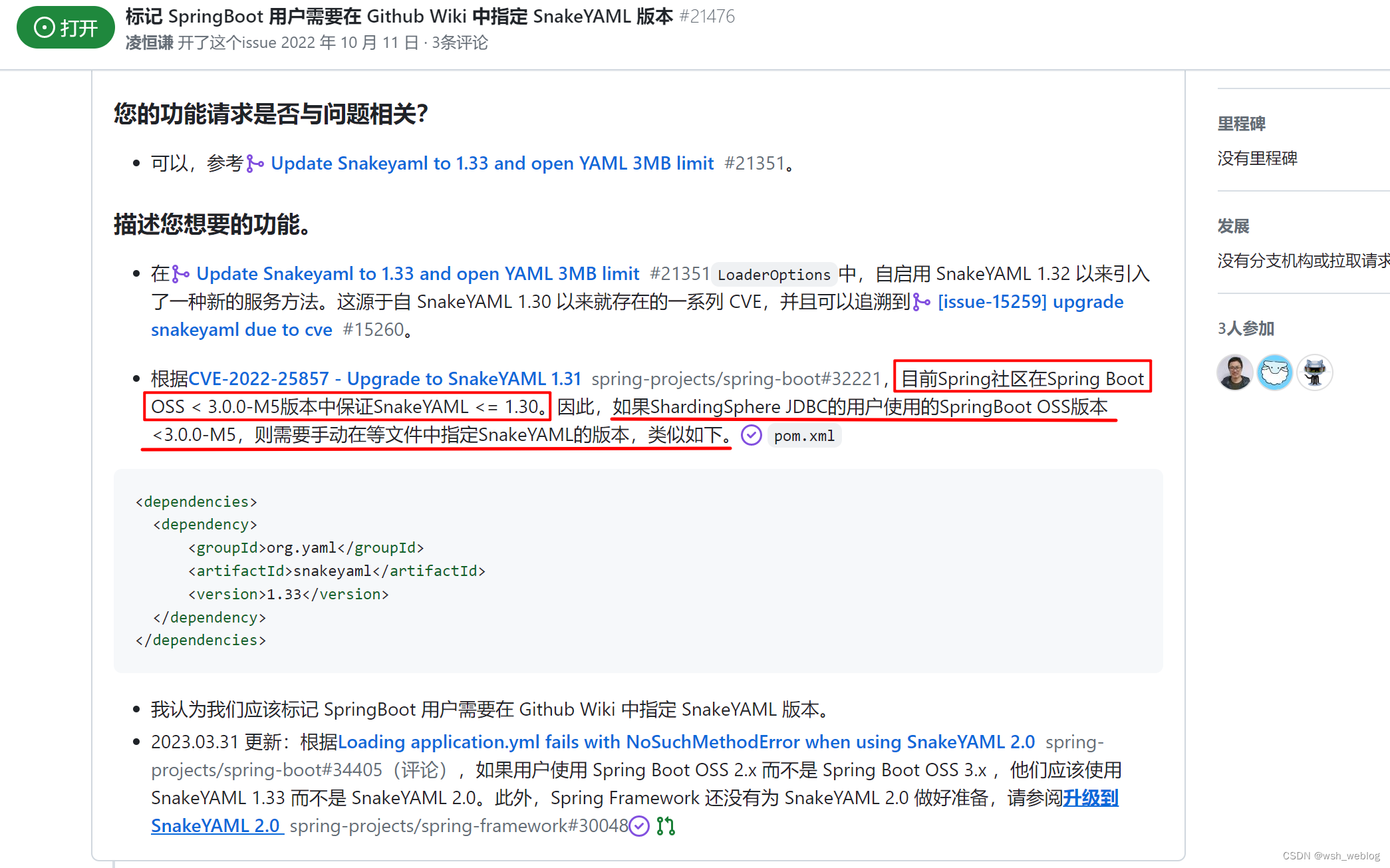
引入依赖覆盖springboot默认版本即解决
<dependency><groupId>org.yaml</groupId><artifactId>snakeyaml</artifactId><version>1.33</version>
</dependency>
二、⭐️快速配置
官方示例(参考
官方给的示例配置如下,可以转换成yml格式更具有可视化
# 配置真实数据源
spring.shardingsphere.datasource.names=ds0,ds1# 配置第 1 个数据源
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://localhost:3306/ds0
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=# 配置第 2 个数据源
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://localhost:3306/ds1
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=# 配置 t_order 表规则
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}# 配置分库策略
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=database_inline# 配置分表策略
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=table_inline# 省略配置 t_order_item 表规则...
# ...# 配置 分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.props.algorithm-expression=ds_${user_id % 2}
spring.shardingsphere.rules.sharding.sharding-algorithms.table_inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.table_inline.props.algorithm-expression=t_order_${order_id % 2}
快速配置yaml(测试可行
结合potgresql配置如下
server:port: 9696spring:shardingsphere:mode:type: Standalonerepository:type: JDBCprops:# 禁用执行SQL用于获取表元数据sql-show: true# 禁用执行SQL用于获取数据库元数据
# check-table-metadata-enabled: falsedatasource:# 配置真实数据源 相当于ds0,ds1names: ds0,ds1ds0:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: org.postgresql.Driverjdbc-url: jdbc:postgresql://localhost:5432/sd0username: postgrespassword: rootds1:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: org.postgresql.Driverjdbc-url: jdbc:postgresql://localhost:5432/sd1username: postgrespassword: rootrules:sharding:tables:#这里以student表为例student:# 表名的分片规则: # 由数据源名 + 表名组成(参考 Inline 语法规则)actual-data-nodes: ds$->{0..1}.student$->{0..1}# 分布式序列策略key-generate-strategy:# 自增列名称,缺省表示不使用自增主键生成器column: id# 分布式序列算法名称key-generator-name: snowflake# 配置分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一:standard/complex/hint/nonedatabase-strategy:# 用于单分片键的标准分片场景standard:# 分片列名称 这里指定age作为分库键sharding-column: age# 分片算法名称sharding-algorithm-name: student_age_inline# 配置分表策略,分库键class_id,分库策略student_class_id_inlinetable-strategy:standard:sharding-column: class_idsharding-algorithm-name: student_class_id_inline# 配置分片算法sharding-algorithms:# 分库策略:根据age取余2student_age_inline:type: INLINEprops:algorithm-expression: ds$->{age % 2}# 分表策略:根据classid取余2student_class_id_inline:type: INLINEprops:algorithm-expression: student$->{class_id % 2}key-generators:# 配置主键生成算法-雪花算法snowflake:type: SNOWFLAKE配置逻辑梳理
只抄配置不如理解配置逻辑
- 可选:手续配置SS的运行模式(不配置就默认单机
- 可选:SS的运行配置
- 必选:数据源配置 datasource:(告诉SS数据库信息
- 声明数据源别名
- 分别给每个数据源声明连接池,驱动,地址,账号密码等
- 必选:配置分库分表测试rules:
- 指定要分库分表的表名
- 配置数据节点(告诉SS哪些库哪些表中有这张表的数据
- 配置分库/分表策略(告诉SS如何分配这张表的数据
- 分库建
- 分库策略
- 必选:配置分库/分表策略
三、问题记录
① 使用 Spring Boot 2.x 集成 ShardingSphere 时,配置文件中的属性设置不生效?以及 “Inline sharding algorithm expression cannot be null”异常
解决方法来自官方FAQ:https://shardingsphere.apache.org/document/5.2.1/cn/faq/
需要特别注意,Spring Boot 2.x 环境下配置文件的属性名称约束为仅允许小写字母、数字和短横线,即
[a-z][0-9]和-。 原因如下: Spring Boot 2.x 环境下,ShardingSphere 通过 Binder 来绑定配置文件,属性名称不规范(如:驼峰或下划线等)会导致属性设置不生效从而校验属性值时抛出NullPointerException异常。参考以下错误示例:
- 下划线示例:database_inline
- 驼峰示例:databaseInline
我在配置过程中也有遇到这个问题,通过将shardingsphere-jdbc-core-spring-boot-starter依赖从版本5.0.0升级到5.2.1即可解决,遇到类似的问题两种解决方案都可以考虑。

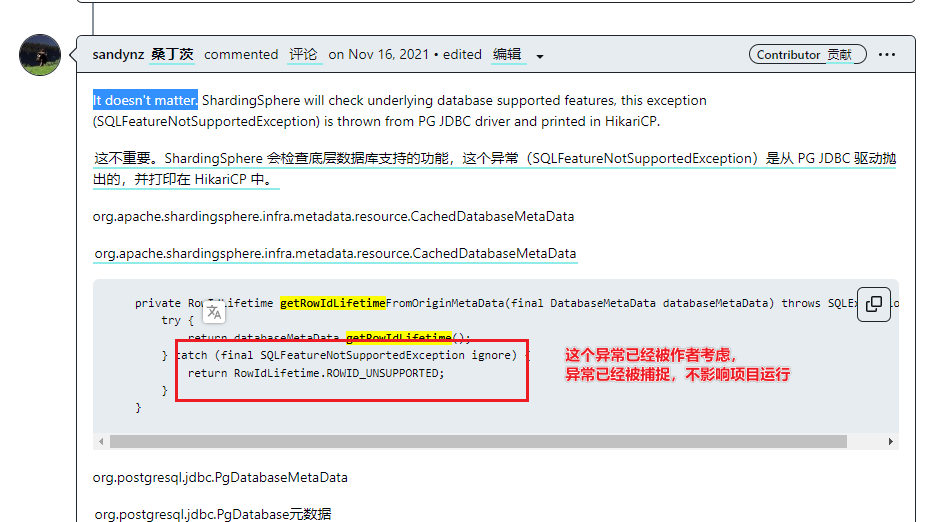
② …getRowIdLifetime() 方法尚未被实作。问题记录和解决.
报错信息如下:

AI建议:
这个错误表明你正在使用的PostgreSQL JDBC驱动版本不支持
getRowIdLifetime()方法。这个方法是在JDBC 4.1规范中引入的,如果你的驱动版本较旧,可能不会实现这个方法。
解决方案:
没找到合适的解决方案(提升pgsql驱动到最高版本也无解),阅读源码后发现这个方法没有实现已经被代码低层catch,查阅官方git的议题org.postgresql.jdbc.PgDatabaseMetaData.getRowIdLifetime() 方法尚未被实作,也可以找到作者的回复“It doesn’t matter”,也就是其实不影响使用
PS:我之前使用3.0.0版本的SS其实没有这个问题,不过不影响使用,就算了吧,反正It doesn’t matter
相关文章:
【经验总结】ShardingSphere5.2.1 + Springboot 快速开始
Sharding Sphere 官方文档地址: https://shardingsphere.apache.org/document/current/cn/overview/maven仓库:https://mvnrepository.com/artifact/org.apache.shardingsphere/shardingsphere-jdbc 官方的文档写的很详尽到位,这里会截取部分…...
基于Golang实现Kubernetes边车模式
本文介绍了如何基于 Go 语言实现 Kubernetes Sidecar 模式,并通过实际示例演示创建 Golang 实现的微服务服务、Docker 容器化以及在 Kubernetes 上的部署和管理。原文: Sidecar Pattern with Kubernetes and Go[1] 在这篇文章中,我们会介绍 Sidecar 模式…...

TCP 通信全流程分析:从连接建立到数据传输的深度探索
目录 一、TCP报头 二、三次握手 三、数据传输 四、四次挥手 本文通过一次TCP通信过程的分析来学习TCP协议 一、TCP报头 如图是一份TCP报文的报头,标准报头是20个字节,还可带有选项报头,也就是TCP报头的最小长度是20字节。以下是对报头的各…...

4、提取H264码流中nalu
H264的NALU提取 1、nalu单元 定义nalu的存储单元,ebsp用来存储原始的包含起始码(annexb格式)的原始码流,sodb存储去除防竞争字节后的码流,prefix是3或4字节 nalu_def.h // nalu_def.h #pragma once#include <cs…...
哈佛大学单细胞课程|笔记汇总 (二)
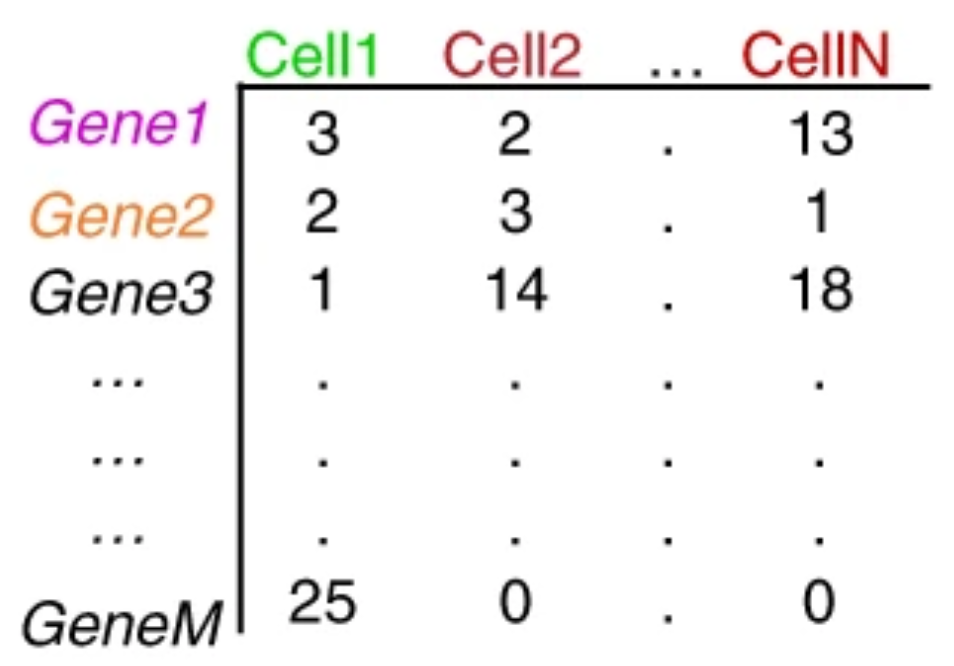
哈佛大学单细胞课程|笔记汇总 (一) (二)Single-cell RNA-seq data - raw data to count matrix 根据所用文库制备方法的不同,RNA序列(也被称为reads或tag)将从转录本((10X Genomic…...

java中抽象类和接口的区别
文章目录 接口和抽象类的区别一、定义的区别1、抽象类2、接口 二、使用场景的区别1、抽象类2、接口 三、使用案例1、抽象类2、接口 接口和抽象类的区别 一、定义的区别 1、抽象类 关键字: abstract 是模棱两可的,似是而非的,无法给出具体明…...

Spring Boot - 在Spring Boot中实现灵活的API版本控制(下)_ 封装场景启动器Starter
文章目录 Pre设计思路ApiVersion 功能特性使用示例配置示例 ProjectStarter Code自定义注解 ApiVersion配置属性类用于管理API版本自动配置基于Spring MVC的API版本控制实现WebMvcRegistrations接口,用于自定义WebMvc的注册逻辑扩展RequestMappingHandlerMapping的类…...
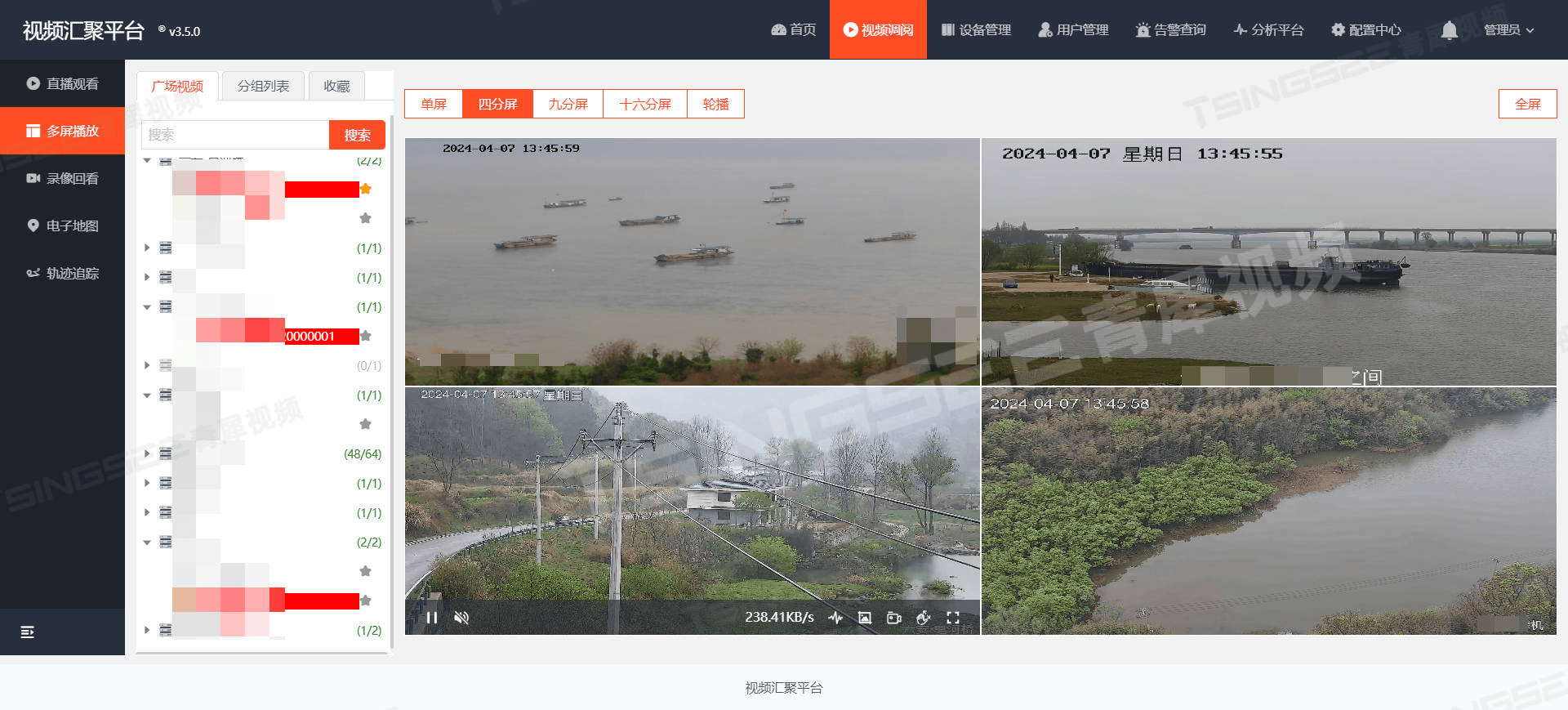
EasyCVR视频转码:T3视频平台不支持GB28181协议,应该如何实现与视频联网平台的对接与视频共享呢?
EasyCVR视频管理系统以其强大的拓展性、灵活的部署方式、高性能的视频能力和智能化的分析能力,为各行各业的视频监控需求提供了优秀的解决方案。 T3视频为公网HTTP-FLV或HLS格式的视频流,目前T3平台暂不支持国标GB28181协议,因此也无法直接接…...

Spring统一处理请求响应与异常
在web开发中,规范所有请求响应类型,不管是对前端数据处理,还是后端统一数据解析都是非常重要的。今天我们简单的方式实现如何实现这一效果 实现方式 定义响应类型 public class ResponseResult<T> {private static final String SUC…...
 WITH common_table_expression)
SqlServer公用表表达式 (CTE) WITH common_table_expression
SQL Server 中的公用表表达式(Common Table Expressions,简称 CTE)是一种临时命名的结果集,它在执行查询时存在,并且只在该查询执行期间有效。CTE 类似于一个临时的视图或者一个内嵌的查询,但它提供了更好的…...
常见中间件漏洞
Tomcat CVE-2017-12615 1.打开环境,抓包 2.切换请求头为 PUT,请求体添加木马,并在请求头添加木马文件名 1.jsp,后方需要以 / 分隔 3.连接 后台弱口令部署war包 1.打开环境,进入指点位置,账户密码均为 tomcat 2.在此处上传一句话…...

elasticsearch的学习(二):Java api操作elasticsearch
简介 使用Java api操作elasticsearch 创建maven项目 pom.xml文件 <?xml version"1.0" encoding"UTF-8"?><project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi…...

docker 部署 ElasticSearch;Kibana
ELasticSearch 创建网络 docker network create es-netES配合Kibana使用时需要组网,使两者运行在同一个网络下 命令 docker run -d \ --name es \ -e "discovery.typesingle-node" \ -v /usr/local/es/data:/usr/share/elasticsearch/data \ -v /usr/…...

k8s使用kustomize来部署应用
k8s使用kustomize来部署应用 本文主要是讲述kustomzie的基本用法。首先,我们说一下部署文件的目录结构。 ./ ├── base │ ├── deployment.yaml │ ├── kustomization.yaml │ └── service.yaml └── overlays└── dev├── kustomization.…...

基于开源FFmpeg和SDL2.0的音视频解码播放和存储系统的实现
目录 1、FFMPEG简介 2、SDL简介 3、视频播放器原理 4、FFMPEG多媒体编解码库 4.1、FFMPEG库 4.2、数据类型 4.3、解码 4.3.1、接口函数 4.3.2、解码流程 4.4、存储(推送) 4.4.1、接口函数 4.4.2、存储流程 5、SDL库介绍 5.1、数据结构 5.…...

保姆级教程,一文了解LVS
目录 一.什么是LVS tips: 二.优点(为什么要用LVS?) 三.作用 四.程序组成 五.LVS 负载均衡集群的类型 六.分布式内容 六.一.分布式存储 六.二.分布式计算 六.三.分布式常见应用 tips: 七.LVS 涉及相关的术语 八.LVS 负…...

【STM32】DMA数据转运(存储器到存储器)
本篇博客重点在于标准库函数的理解与使用,搭建一个框架便于快速开发 目录 DMA简介 DMA时钟使能 DMA初始化 转运起始和终止的地址 转运方向 数据宽度 传输次数 转运触发方式 转运模式 通道优先级 开启DMA通道 DMA初始化框架 更改转运次数 DMA应用实例-…...

【Android】通过代码打开输入法
获取焦点 binding.editText.requestFocus()打开键盘 val imm getSystemService(InputMethodManager::class.java) imm.showSoftInput(binding.editText, InputMethodManager.SHOW_IMPLICIT)...

爬虫集群部署:Scrapyd 框架深度解析
🕵️♂️ 爬虫集群部署:Scrapyd 框架深度解析 🛠️ Scrapyd 环境部署 Scrapyd 是一个开源的 Python 爬虫框架,专为分布式爬虫设计。它允许用户在集群中调度和管理爬虫任务,并提供了简洁的 API 进行控制。以下是 Scr…...

pytorch GPU操作事例
>>> import torch >>> if_cuda torch.cuda.is_available() >>> print("if_cuda",if_cuda) if_cuda True >>> gpu_count torch.cuda.device_count() >>> print("gpu_count",gpu_count) gpu_count 8...

Anything to RealCharacters 2.5D转真人引擎效果可复现性验证:相同输入多轮输出质量评估
Anything to RealCharacters 2.5D转真人引擎效果可复现性验证:相同输入多轮输出质量评估 1. 项目概述与测试背景 Anything to RealCharacters 2.5D转真人引擎是基于通义千问Qwen-Image-Edit-2511底座和专属写实权重的图像转换系统,专门针对RTX 4090显卡…...

从PTA题目到项目实战:用Python和C语言两种思路重构‘插入排序’
从PTA题目到项目实战:用Python和C语言两种思路重构‘插入排序’ 算法学习常常陷入"纸上谈兵"的困境——我们能在OJ平台上AC题目,却难以将算法思想迁移到真实项目中。以插入排序为例,这道PTA基础题背后隐藏着数据处理、性能优化和语…...

DS4Windows终极指南:让PlayStation手柄在PC上释放全部潜能
DS4Windows终极指南:让PlayStation手柄在PC上释放全部潜能 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 当你兴奋地将PlayStation手柄连接到PC,却发现游戏无法识…...

救命!这些毕设太好抄了,3000+毕设案例推荐第1027期
271、基于Java的建材租赁智慧管理系统的设计与实现(论文+代码+PPT)建材租赁智慧管理系统主要功能包括:会员操作、客户资料、建材管理、计量单位、建材损坏收费标准、租赁合同、租费标准、租出登记、归还登记、丢赔管理、入库登记、租金计算、…...

Oracle EBS 6+2 段式 COA 架构 拆到最细、可直接落地 EBS 的版本,每一段的作用、限定词、长度、编码规则、为什么这么设计全部讲清楚
把 62 段式 COA 架构 拆到最细、可直接落地 EBS 的版本,每一段的作用、限定词、长度、编码规则、为什么这么设计全部讲清楚,你可以直接拿去做方案文档。一、62 段式架构总定义6 段 法定核算 管理核算的核心骨架(必须固定)2 段 …...

低成本改造指南:将X96 Max+电视盒子转变为多功能Armbian服务器
低成本改造指南:将X96 Max电视盒子转变为多功能Armbian服务器 【免费下载链接】amlogic-s9xxx-armbian Supports running Armbian on Amlogic, Allwinner, and Rockchip devices. Support a311d, s922x, s905x3, s905x2, s912, s905d, s905x, s905w, s905, s905l, r…...

AI+认知科学:揭秘大脑黑箱,国产工具链崛起
AI认知科学:揭秘大脑黑箱,国产工具链崛起 引言 当人工智能(AI)的触角伸向人类认知的终极疆域——我们的大脑与思维,一场名为“AI for Cognitive Science”的革命正在悄然发生。这不仅是技术的融合,更是理解…...

【AHC】async-http-client 的请求队列是在哪里维护的?排队机制如何工作?
async-http-client 的请求队列是在哪里维护的?排队机制如何工作? 作者:九师兄 发布时间:2026年02月05日 问题引入:Flink 作业因“隐形队列”堆积导致 OOM 某日,我们负责的 实时埋点日志上报系统(基于 Flink 1.17 + async-http-client 3.0.5)突然出现 容器内存溢出(O…...

新手必看!圣女司幼幽-造相Z-Turbo开箱即用,3步生成精美古风人像
新手必看!圣女司幼幽-造相Z-Turbo开箱即用,3步生成精美古风人像 你是不是也遇到过这样的烦恼:脑子里构思好了一位仙气飘飘的古风角色,但要么自己不会画,要么用普通AI工具生成的效果总差那么点意思——衣服质感像塑料&…...

BAAI/bge-m3新手指南:快速上手多语言文本语义分析服务
BAAI/bge-m3新手指南:快速上手多语言文本语义分析服务 1. 认识BAAI/bge-m3语义分析引擎 BAAI/bge-m3是由北京智源人工智能研究院开发的多语言通用嵌入模型,它能够将文本转换为高维向量表示,从而计算不同文本之间的语义相似度。这个模型在MT…...