国产开源大模型都有哪些?
随着ChatGPT引领的大模型热潮,国内的公司开始相继投入研发自己的人工智能大模型,截止到2023年10月,国产公司的大模型有近百个,包括一些通用大模型,比如百度的文心一言,也有特定领域的专用大模型,比如蚂蚁金服的CodeFuse,京东的言犀等。
国内的大模型尚处于百花齐放的状态。
而随着GPT的一路爆火,国内大模型的开源生态也开始火热。各大商业机构和科研组织都在不断发布自己的大模型产品和成果。当然,国产的商业产品也很多,但因为缺少模型细节,实在不好细究。
今天来简单分析当前国产开源大模型的生态发展情况。数据来自DataLearnerAI,统计的开源模型主要包括机构自己训练开源的模型,并不包括所有种类和一些已经不更新的模型。
01
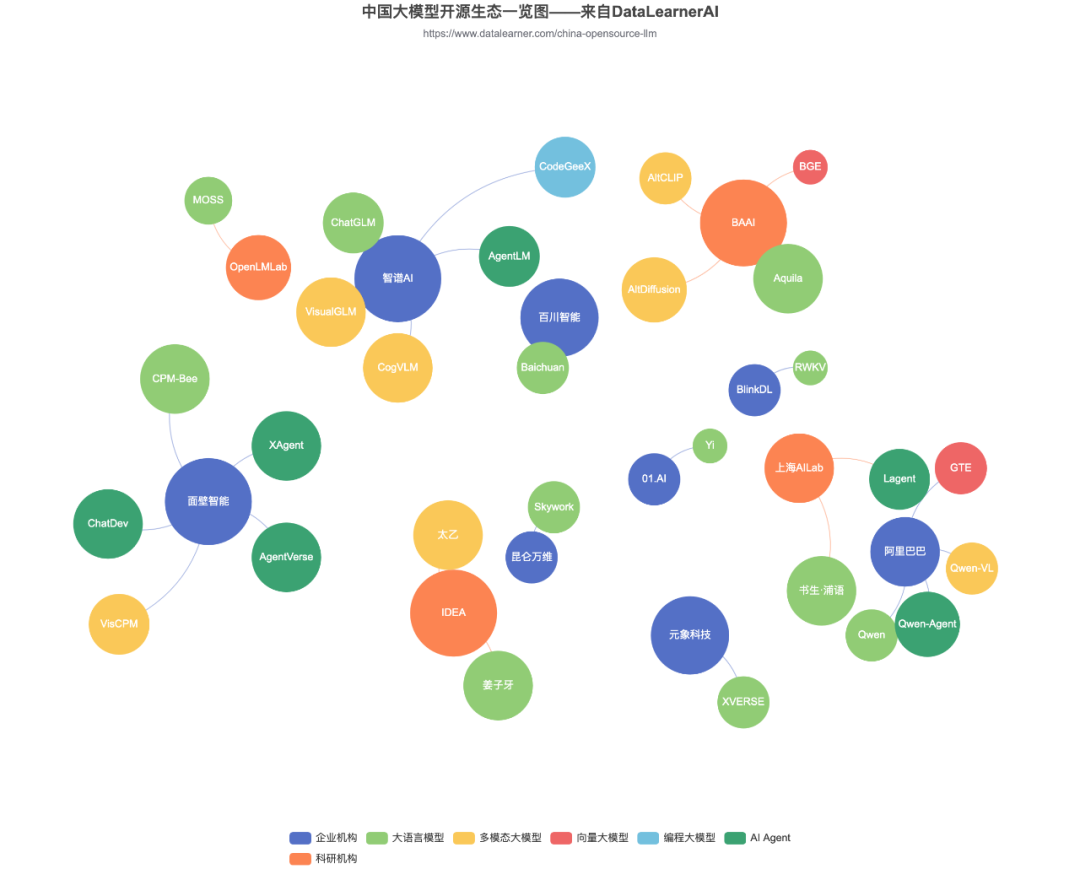
国产开源大模型的发布者
从国产开源大模型的发布者来看,主要包括二类:
-
企业机构:为了获得商业影响力而开源的模型,如智谱AI开源的ChatGLM系列。
-
科研机构:主要展示最新的科研成果,如北京智源人工智能研究院发布的Aquila系列大模型。
02
国产开源大模型的类型
国产开源大模型的数量很多,类型也很丰富,包括_大语言模型__、多模态大模型、向量大模型、__编程大模型__和__AI Agent框架(模型)_几类。
不同机构的模型丰富程度不同。
智谱AI、阿里巴巴的开源大模型都较为丰富,都开源了四种大模型。
具体来看,智谱AI开源的大模型包括:
-
大语言模型ChatGLM系列
-
多模态大模型CogVLM
-
Agent大模型AgentLM
-
编程大模型CodeGeeX
具体来看,阿里巴巴的开源大模型包括:
-
大语言模型Qwen
-
多模态大模型Qwen-VL
-
向量大模型GTE
-
Agent大模型Qwen-Agent
其它大多数企业或者机构开源的模型都是1-3类左右。
特别地,
-
智谱AI是目前唯一开源了编程大模型的机构;
-
开源向量大模型的机构只有北京智源人工智能研究院(BGE)和阿里巴巴(GTE)两家;
-
面壁智能(ModelBest)开源了较多的AI Agent模型和框架,如AgentVerse、XAgent等。
03
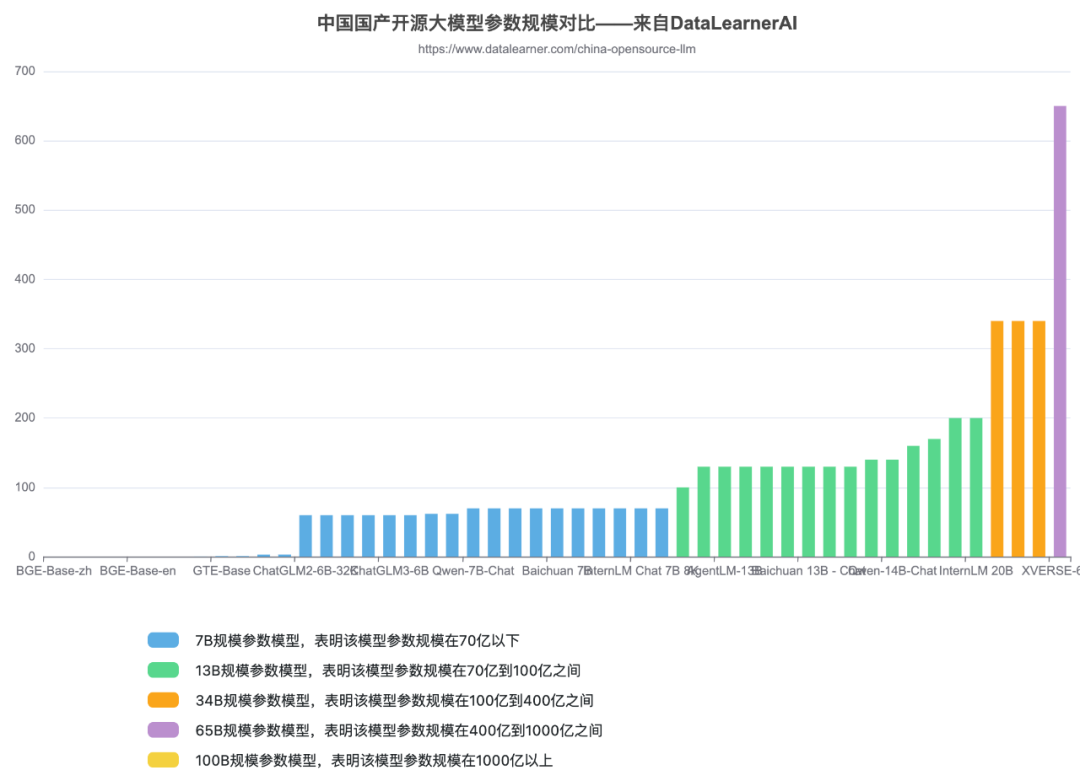
国产开源大模型的参数规模
将模型开源的参数规模分为五类:
-
7B规模参数模型,表明该模型参数规模在70亿以下
-
13B规模参数模型,表明该模型参数规模在70亿到100亿之间
-
34B规模参数模型,表明该模型参数规模在100亿到400亿之间
-
65B规模参数模型,表明该模型参数规模在400亿到1000亿之间
-
100B规模参数模型,表明该模型参数规模在1000亿以上
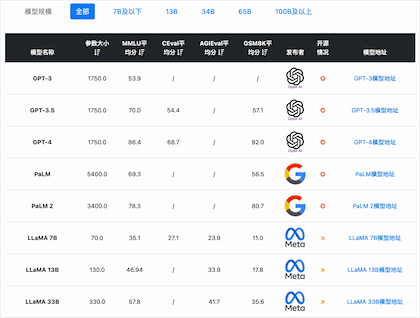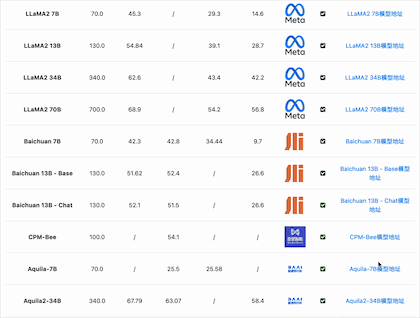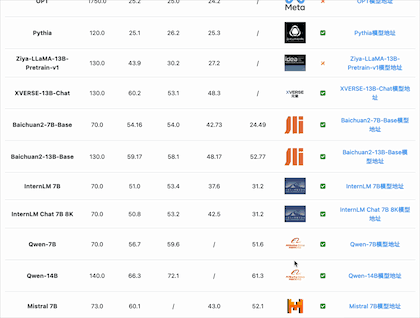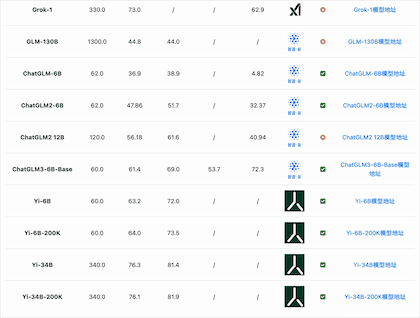
智谱AI最早开源的模型是ChatGLM系列,参数规模是60-70亿左右,之后大多数的开源大模型的参数量都在这个范围。
Meta 的开源大模型LLaMA1的最大参数规模是650亿,LLaMA2是700亿。
经过一段时间的发展,国内340亿参数规模的模型分别有2个:北京智源的Aquila-34b、李开复零一万物开源的Yi-34b(包括200K的版本)。
目前国产开源大模型的参数规模终于提高到了650亿规模,如元象科技发布的XVERSE-65B。
04
国产开源大模型的测评结果
在综合能力评测上,选择4个评测基准来看看国产开源模型的能力如何。
-
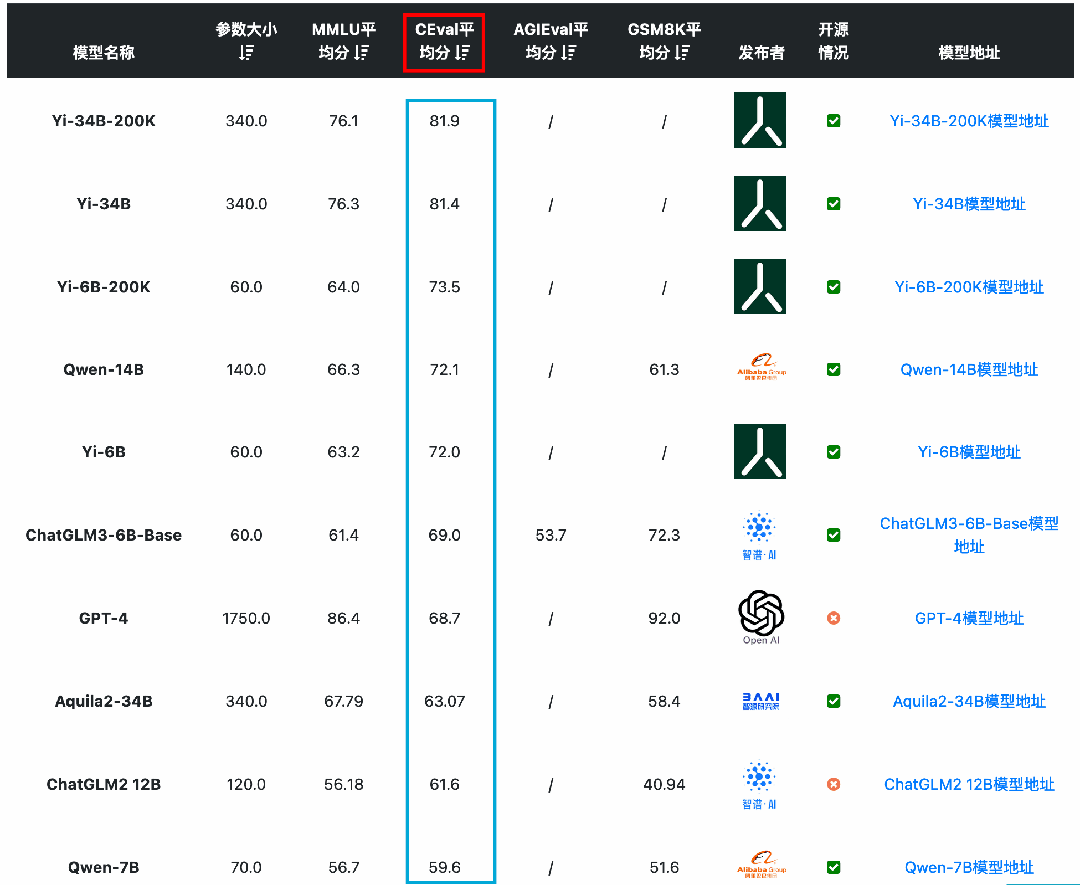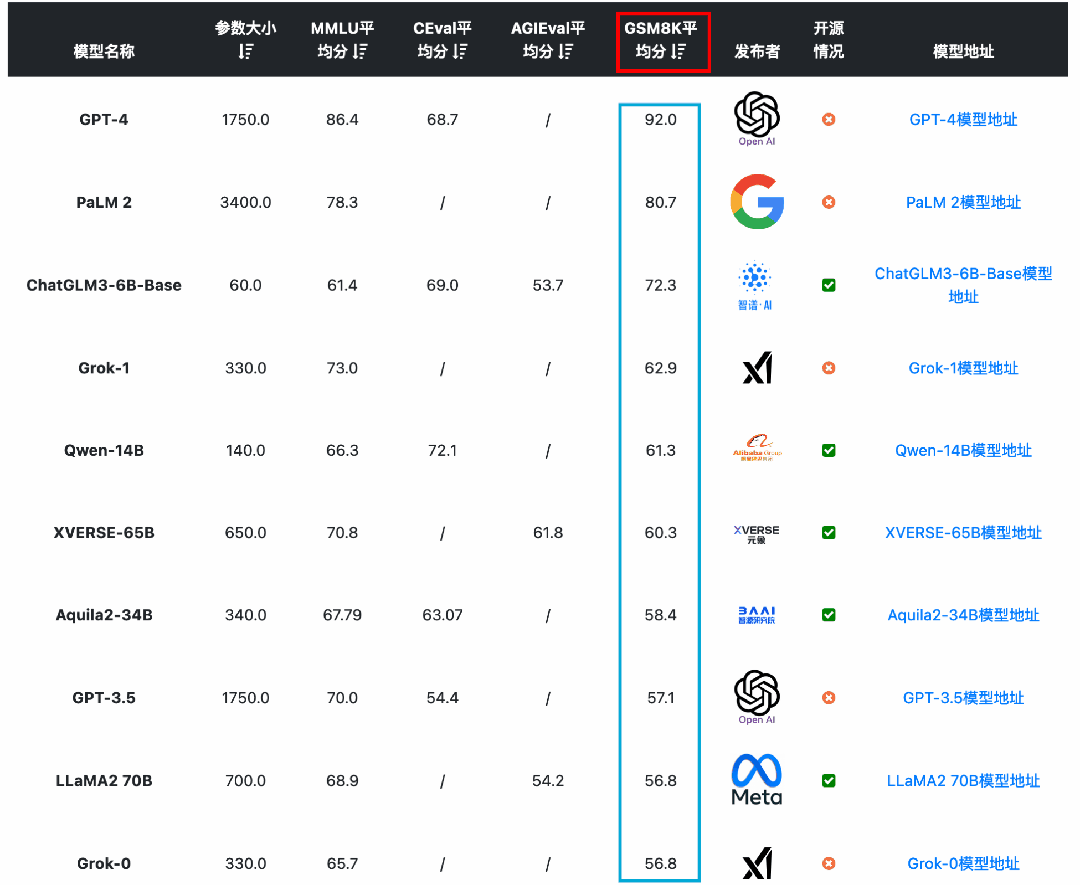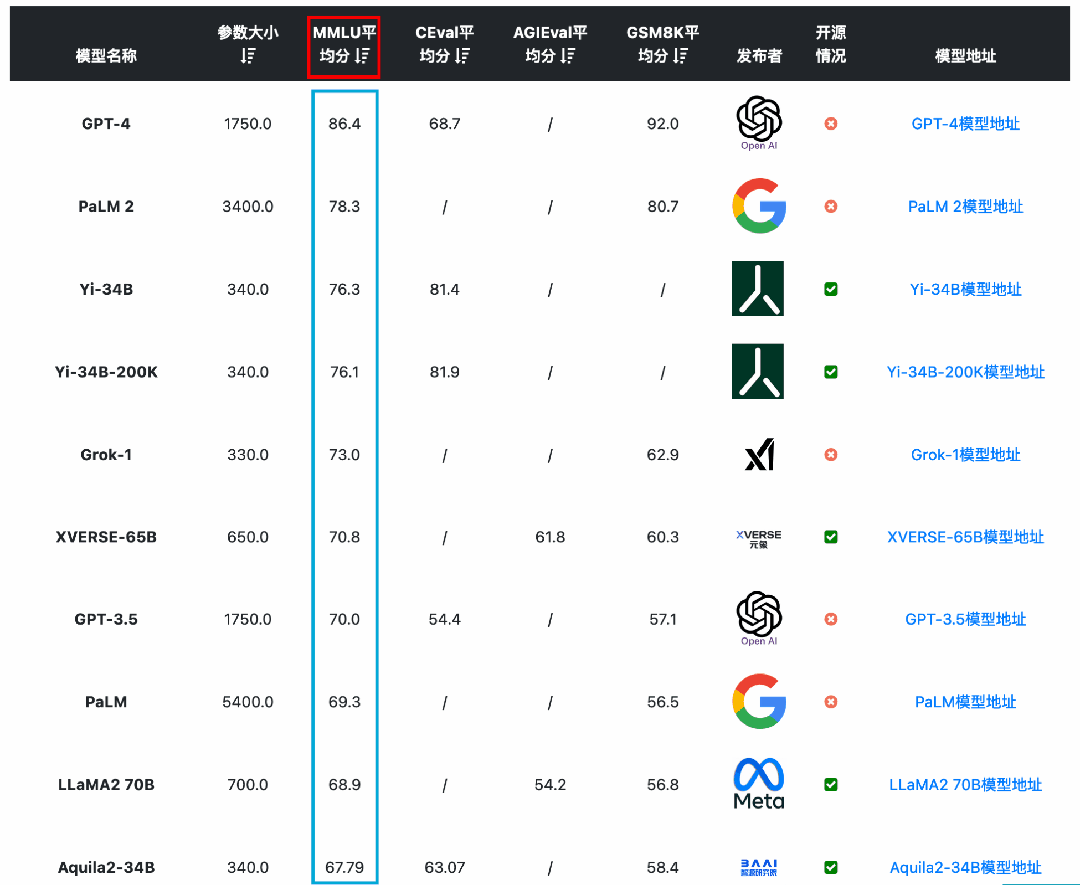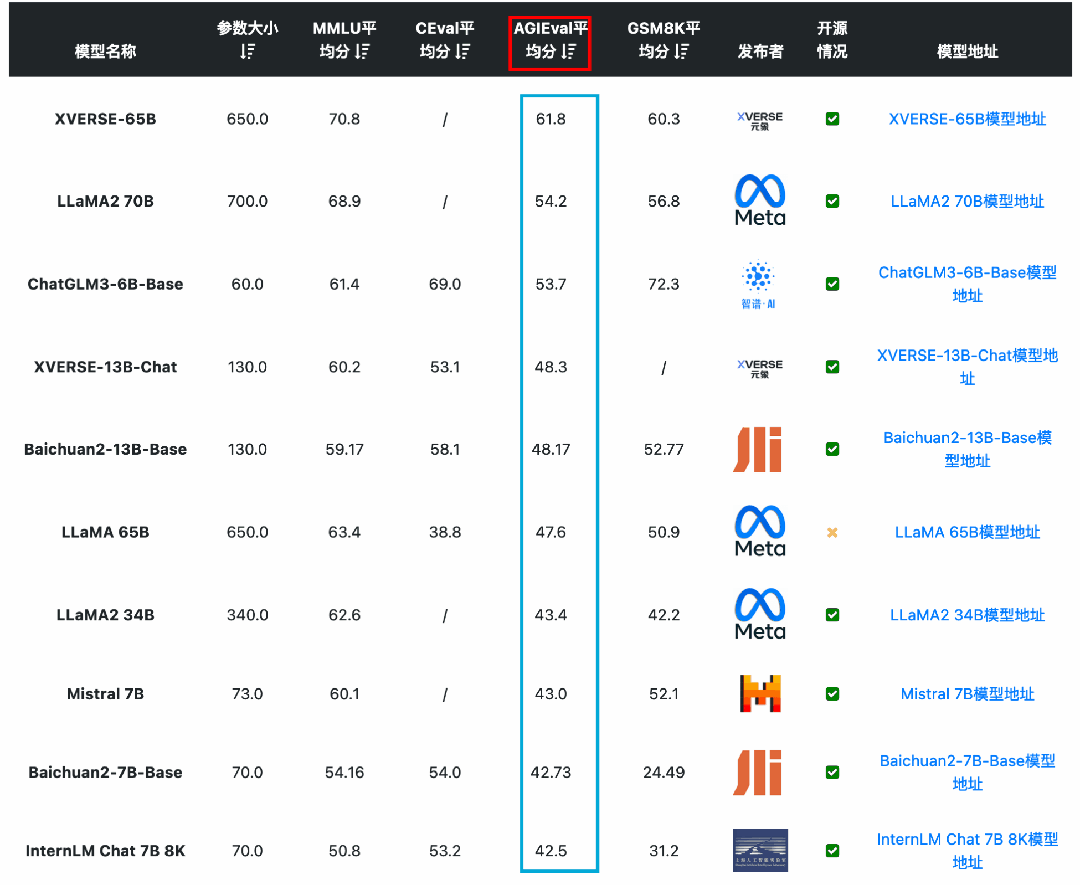
从MMLU(大模型语义理解能力)来看,国产开源模型的能力已经很优秀。李开复零一万物开源的Yi-34B模型的MMLU得分已经超过GPT-3.5,得分76.3,仅次于闭源的GPT-4和PaLM2模型。
-
从GSM8K(数学逻辑能力)来看,国产开源模型的能力也能很强悍。智谱AI的ChatGLM3-6B-Base模型以60多亿参数规模的结果超过了GPT-3.5、Qwen-14B等知名模型,排名仅次于GPT-4和PaLM2。
-
从C-Eval(大模型中文理解能力)来看,国产开源模型的能力优势更是明显。李开复零一万物开源的Yi-34B模型的C-Eval得分81.9,通义千问Qwen-14B得分72.1,ChatGLM3-6B得分69.0,优于GPT-4(68.7)。
-
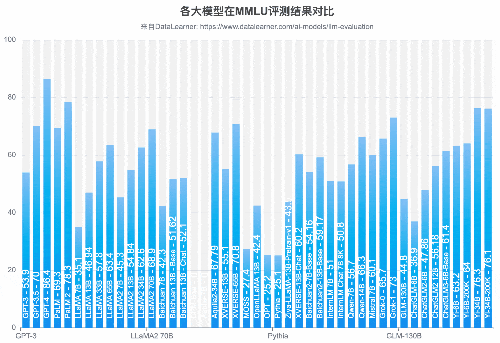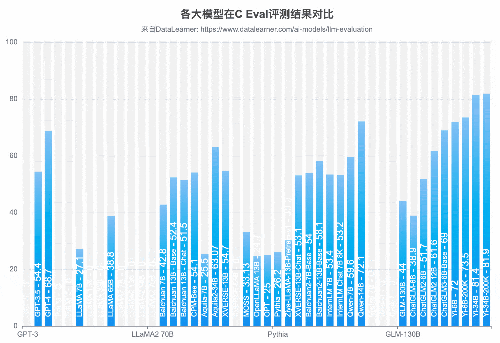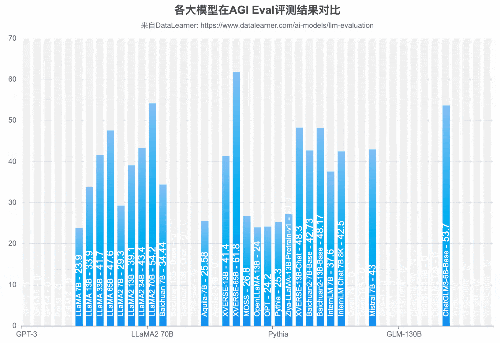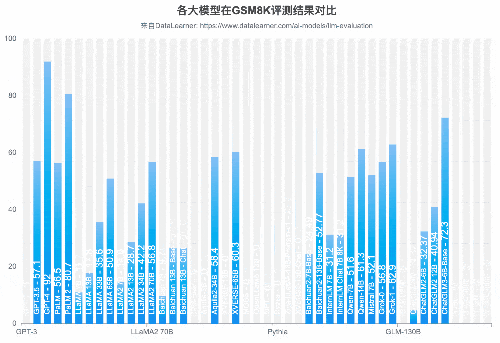
从AGI Eval(大模型在人类认知和解决问题的一般能力)来看,国产开源模型的能力也很强。元象科技发布的XVERSE-65B得分61.8位列第一,其次是LLaMA2-70B得分54.2,第三名是ChatGLM3-6B得分53.7。
MMLU
MMLU:全称Massive Multitask Language Understanding,是一种针对大模型的语言理解能力的测评,是目前最著名的大模型语义理解测评之一,由UC Berkeley大学的研究人员在2020年9月推出。该测试涵盖57项任务,包括初等数学、美国历史、计算机科学、法律等。任务涵盖的知识很广泛,语言是英文,用以评测大模型基本的知识覆盖范围和理解能力。论文地址:https://arxiv.org/abs/2009.03300
C-Eval
C-Eval:C-Eval 是一个全面的中文基础模型评估套件。由上海交通大学、清华大学和匹兹堡大学研究人员在2023年5月份联合推出,它包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别。用以评测大模型中文理解能力。论文地址:https://arxiv.org/abs/2305.08322
AGI Eval
AGI Eval:微软发布的大模型基础能力评测基准,在2023年4月推出,主要评测大模型在人类认知和解决问题的一般能力,涵盖全球20种面向普通人类考生的官方、公共和高标准录取和资格考试,包含中英文数据。因此,该测试更加倾向于人类考试结果,涵盖了中英文,论文地址:https://arxiv.org/abs/2304.06364
GSM8K
GSM8K:OpenAI发布的大模型数学推理能力评测基准,涵盖了8500个中学水平的高质量数学题数据集。数据集比之前的数学文字题数据集规模更大,语言更具多样性,题目也更具挑战性。该项测试在2021年10月份发布,至今仍然是非常困难的一种测试基准。论文地址:https://arxiv.org/abs/2110.14168
在大模型编程能力评测上,选择的评测基准包括2个:
Human Eval
HumanEval是一个用于评估代码生成模型性能的数据集,由OpenAI在2021年推出。这个数据集包含164个手工编写的编程问题,每个问题都包括一个函数签名、文档字符串(docstring)、函数体以及几个单元测试。这些问题涵盖了语言理解、推理、算法和简单数学等方面。这个数据集的一个重要特点是,它不仅仅依赖于代码的语法正确性,还依赖于功能正确性。也就是说,生成的代码需要通过所有相关的单元测试才能被认为是正确的。这种方法更接近于实际编程任务,因为在实际编程中,代码不仅需要语法正确,还需要能够正确执行预定任务。结果通过pass@k表示,其中k表示模型一次性生成多少种不同的答案中,至少包含1个正确的结果。例如Pass@1就是只生成一个答案,准确的比例。如果是Pass@10表示一次性生成10个答案其中至少有一个准确的比例。目前,收集的包含Pass@1、Pass@10和Pass@100
MBPP
MBPP(Mostly Basic Programming Problems)是一个数据集,主要包含了974个短小的Python函数问题,由谷歌在2021年推出,这些问题主要是为初级程序员设计的。数据集还包含了这些程序的文本描述和用于检查功能正确性的测试用例。结果通过pass@k表示,其中k表示模型一次性生成多少种不同的答案中,至少包含1个正确的结果。例如Pass@1就是只生成一个答案,准确的比例。如果是Pass@10表示一次性生成10个答案其中至少有一个准确的比例。目前,收集的包含Pass@1、Pass@10和Pass@100
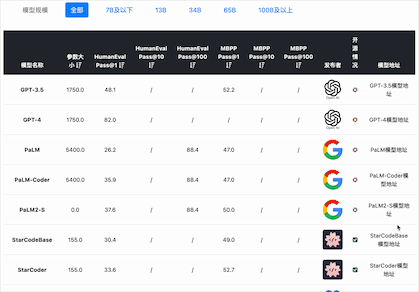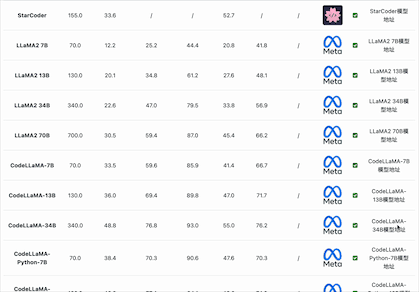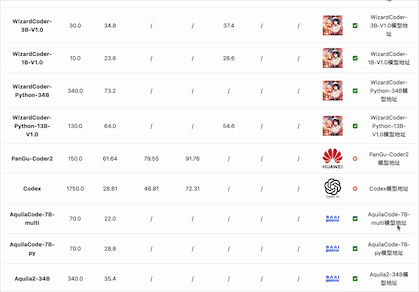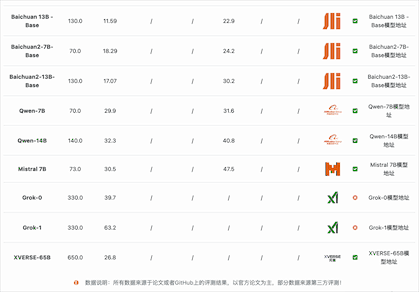
在编码能力上,国产开源模型的表现较差。按照HumanEval Pass@ 1的得分结果看,除了闭源的PanGu-Coder2的得分超过了60分(排名第7),其它国产开源模型都没怎么公布或者排名靠后。而在MBPP的得分上国内开源和闭源模型更是没能进入前十的榜单,排名均靠后。
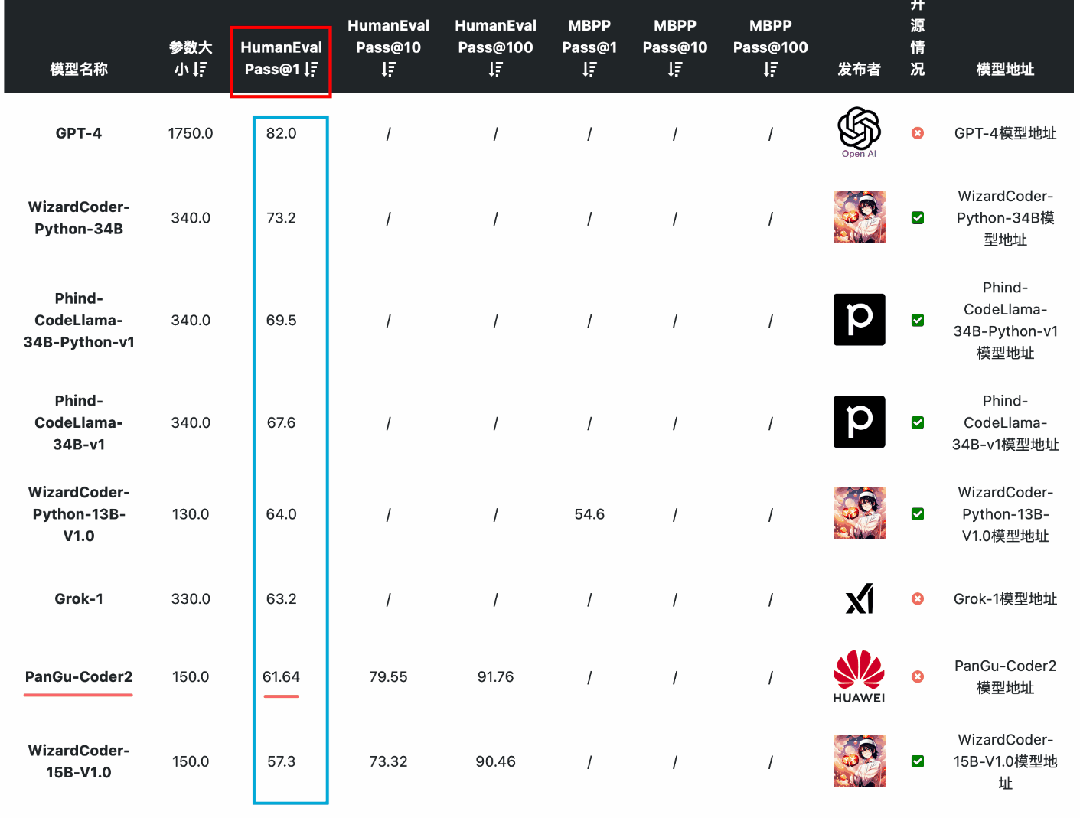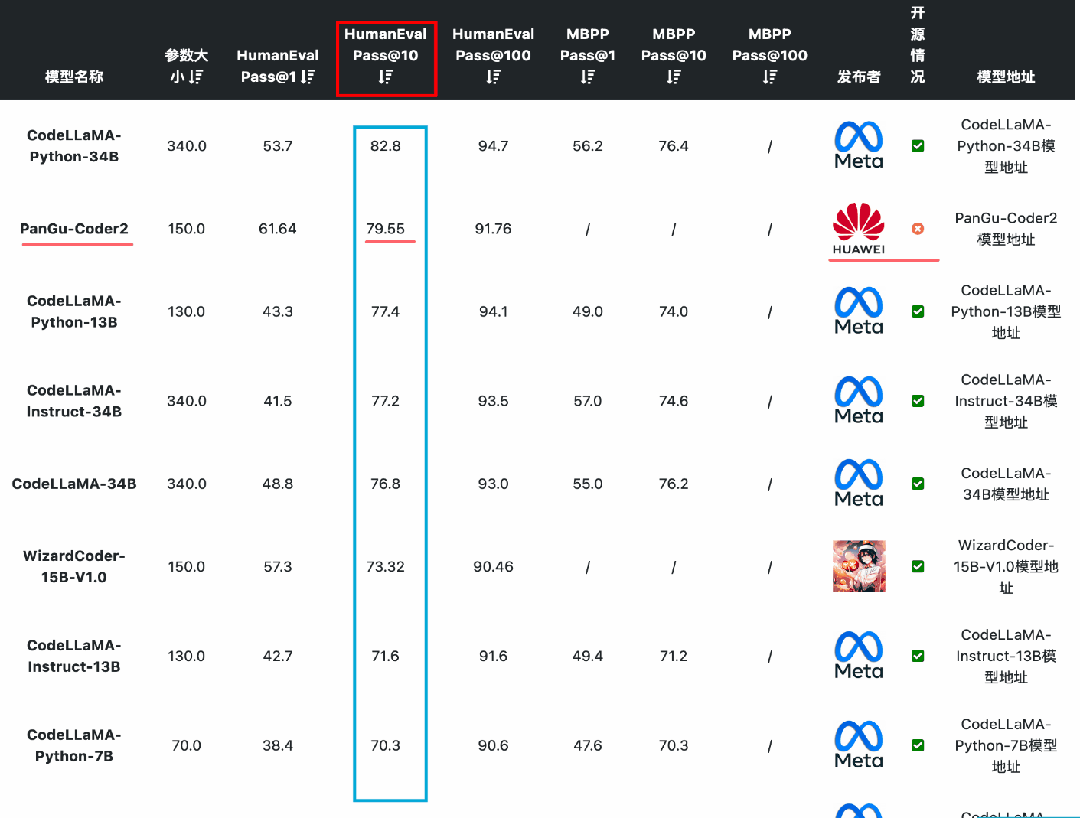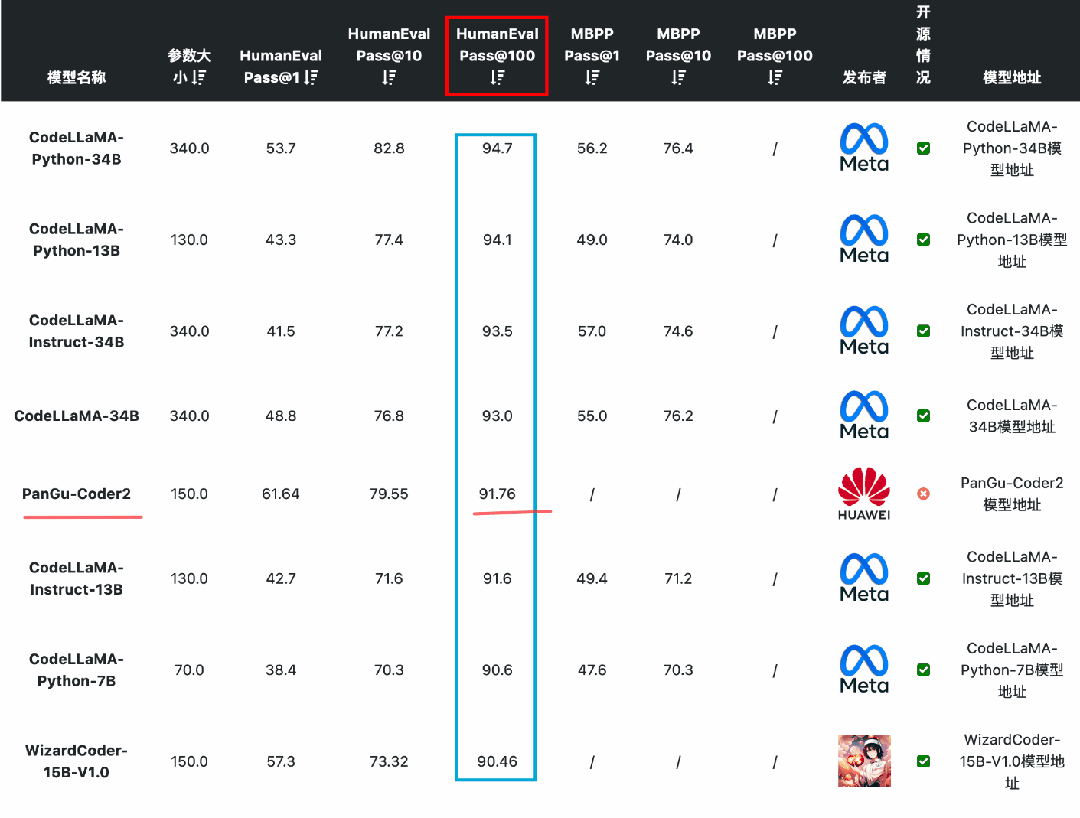
05
国产开源大模型总结
从模型的发布数量、参数规模、模型种类来看,国产开源模型的生态已经比较不错。但是,我们也能清楚看到一些不足和未来值得改进的方向:
-
国产开源大模型的参数分布比较集中,其中超过200亿参数规模的数量较少;
-
国产开源大模型的类型多样性不足,比如编程大模型、向量大模型等很少发布开源;
-
国产开源大模型的编程能力普遍不足,还有待加强。
相关文章:
国产开源大模型都有哪些?
随着ChatGPT引领的大模型热潮,国内的公司开始相继投入研发自己的人工智能大模型,截止到2023年10月,国产公司的大模型有近百个,包括一些通用大模型,比如百度的文心一言,也有特定领域的专用大模型,…...

基于Hadoop的超市进货推荐系统设计与实现【springboot案例项目】
文章目录 有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主项目介绍系统分析系统设计数据表设计表4-1:关于我们表4-2:用户表4-3:管理员表表4-4:token表表4-5:系统简介表4-6:收藏…...

ChatGPT能从这几个方面提升学术论文质量
学境思源,一键生成论文初稿: AcademicIdeas - 学境思源AI论文写作 写作和编辑高质量的学术论文是一项具有挑战性的任务。随着人工智能技术的进步,ChatGPT作为一种强大的语言生成工具,正逐渐成为提升论文质量的得力助手。从头脑风…...

Python3的安装及基础指令
Day 20 基础语法 1、环境:python2内置,安装并使用python3,最新版3.12版可以使用源码安装 # 查看python版本号 [rootpython ~]#yum list installed|grep python [rootpython ~]#yum list installed|grep epel [rootpython ~]# yum -y …...

使用Spring与JDK动态代理实现事务管理
使用Spring与JDK动态代理实现事务管理 在现代企业级应用开发中,事务管理是一项关键的技术,它可以保证一系列操作要么全部成功,要么全部失败,从而确保数据的一致性和完整性。Spring框架提供了强大的事务管理能力,但有时…...

服务器硬件及RAID配置
服务器及 RAID 磁盘阵列介绍 RAID0 俗称 “ 条带 ” ,它将两个或多个硬盘组成一个逻辑硬盘,容量是所有硬盘之和,因 为是多个硬盘组合成一个,故可并行写操作,写入速度提高,但此方式硬盘数据没有冗余&#…...
【经验总结】ShardingSphere5.2.1 + Springboot 快速开始
Sharding Sphere 官方文档地址: https://shardingsphere.apache.org/document/current/cn/overview/maven仓库:https://mvnrepository.com/artifact/org.apache.shardingsphere/shardingsphere-jdbc 官方的文档写的很详尽到位,这里会截取部分…...
基于Golang实现Kubernetes边车模式
本文介绍了如何基于 Go 语言实现 Kubernetes Sidecar 模式,并通过实际示例演示创建 Golang 实现的微服务服务、Docker 容器化以及在 Kubernetes 上的部署和管理。原文: Sidecar Pattern with Kubernetes and Go[1] 在这篇文章中,我们会介绍 Sidecar 模式…...

TCP 通信全流程分析:从连接建立到数据传输的深度探索
目录 一、TCP报头 二、三次握手 三、数据传输 四、四次挥手 本文通过一次TCP通信过程的分析来学习TCP协议 一、TCP报头 如图是一份TCP报文的报头,标准报头是20个字节,还可带有选项报头,也就是TCP报头的最小长度是20字节。以下是对报头的各…...

4、提取H264码流中nalu
H264的NALU提取 1、nalu单元 定义nalu的存储单元,ebsp用来存储原始的包含起始码(annexb格式)的原始码流,sodb存储去除防竞争字节后的码流,prefix是3或4字节 nalu_def.h // nalu_def.h #pragma once#include <cs…...
哈佛大学单细胞课程|笔记汇总 (二)
哈佛大学单细胞课程|笔记汇总 (一) (二)Single-cell RNA-seq data - raw data to count matrix 根据所用文库制备方法的不同,RNA序列(也被称为reads或tag)将从转录本((10X Genomic…...

java中抽象类和接口的区别
文章目录 接口和抽象类的区别一、定义的区别1、抽象类2、接口 二、使用场景的区别1、抽象类2、接口 三、使用案例1、抽象类2、接口 接口和抽象类的区别 一、定义的区别 1、抽象类 关键字: abstract 是模棱两可的,似是而非的,无法给出具体明…...

Spring Boot - 在Spring Boot中实现灵活的API版本控制(下)_ 封装场景启动器Starter
文章目录 Pre设计思路ApiVersion 功能特性使用示例配置示例 ProjectStarter Code自定义注解 ApiVersion配置属性类用于管理API版本自动配置基于Spring MVC的API版本控制实现WebMvcRegistrations接口,用于自定义WebMvc的注册逻辑扩展RequestMappingHandlerMapping的类…...
EasyCVR视频转码:T3视频平台不支持GB28181协议,应该如何实现与视频联网平台的对接与视频共享呢?
EasyCVR视频管理系统以其强大的拓展性、灵活的部署方式、高性能的视频能力和智能化的分析能力,为各行各业的视频监控需求提供了优秀的解决方案。 T3视频为公网HTTP-FLV或HLS格式的视频流,目前T3平台暂不支持国标GB28181协议,因此也无法直接接…...

Spring统一处理请求响应与异常
在web开发中,规范所有请求响应类型,不管是对前端数据处理,还是后端统一数据解析都是非常重要的。今天我们简单的方式实现如何实现这一效果 实现方式 定义响应类型 public class ResponseResult<T> {private static final String SUC…...
 WITH common_table_expression)
SqlServer公用表表达式 (CTE) WITH common_table_expression
SQL Server 中的公用表表达式(Common Table Expressions,简称 CTE)是一种临时命名的结果集,它在执行查询时存在,并且只在该查询执行期间有效。CTE 类似于一个临时的视图或者一个内嵌的查询,但它提供了更好的…...
常见中间件漏洞
Tomcat CVE-2017-12615 1.打开环境,抓包 2.切换请求头为 PUT,请求体添加木马,并在请求头添加木马文件名 1.jsp,后方需要以 / 分隔 3.连接 后台弱口令部署war包 1.打开环境,进入指点位置,账户密码均为 tomcat 2.在此处上传一句话…...

elasticsearch的学习(二):Java api操作elasticsearch
简介 使用Java api操作elasticsearch 创建maven项目 pom.xml文件 <?xml version"1.0" encoding"UTF-8"?><project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi…...

docker 部署 ElasticSearch;Kibana
ELasticSearch 创建网络 docker network create es-netES配合Kibana使用时需要组网,使两者运行在同一个网络下 命令 docker run -d \ --name es \ -e "discovery.typesingle-node" \ -v /usr/local/es/data:/usr/share/elasticsearch/data \ -v /usr/…...

k8s使用kustomize来部署应用
k8s使用kustomize来部署应用 本文主要是讲述kustomzie的基本用法。首先,我们说一下部署文件的目录结构。 ./ ├── base │ ├── deployment.yaml │ ├── kustomization.yaml │ └── service.yaml └── overlays└── dev├── kustomization.…...

SteamAutoCrack:三步告别Steam游戏限制,实现真正的离线自由
SteamAutoCrack:三步告别Steam游戏限制,实现真正的离线自由 【免费下载链接】Steam-auto-crack Steam Game Automatic Cracker 项目地址: https://gitcode.com/gh_mirrors/st/Steam-auto-crack 你是否曾经遇到过这样的困扰:明明购买了…...
)
别再用临时邮箱了!用Python+Selenium自动化管理你的Augment AI多账户(附完整脚本)
构建可持续的Augment AI自动化账户管理系统 在AI辅助编程工具日益普及的今天,开发者们对高效工具的依赖程度越来越高。Augment AI作为一款强大的代码助手,其免费版本300次的使用限制常常成为开发者工作流中的瓶颈。传统解决方案如手动重置或使用临时邮箱…...

Vue-Touch实战案例:构建支持多点触控的图片查看器
Vue-Touch实战案例:构建支持多点触控的图片查看器 【免费下载链接】vue-touch Hammer.js wrapper for Vue.js 项目地址: https://gitcode.com/gh_mirrors/vu/vue-touch 想要为你的Vue.js应用添加流畅的多点触控交互体验吗?Vue-Touch插件正是你需要…...

聚类算法效果评估实战:从轮廓系数到CH分数,手把手教你选对指标
聚类算法效果评估实战:从轮廓系数到CH分数,手把手教你选对指标 在数据科学项目中,聚类分析常常是探索性数据分析的重要环节。无论是客户分群、异常检测还是特征工程,我们都需要面对一个关键问题:如何客观评价聚类结果的…...

小说下载与数字图书馆构建:开源工具novel-downloader完全指南
小说下载与数字图书馆构建:开源工具novel-downloader完全指南 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,读者常面临三大困境:…...

MT5 Zero-Shot中文文本增强企业应用:提升标注效率50%实测报告
MT5 Zero-Shot中文文本增强企业应用:提升标注效率50%实测报告 1. 引言:当数据标注成为AI落地的瓶颈 想象一下这个场景:你的AI团队开发了一个智能客服模型,需要大量高质量的对话数据进行训练。数据工程师们夜以继日地标注数据&am…...

Cadence计算器实战:从波形运算到自定义函数编程
1. 差分信号处理的核心挑战 在模拟电路设计中,差分信号的处理一直是工程师们面临的常见难题。我刚入行时,第一次看到差分信号的波形图完全懵了——两条看似镜像对称的曲线,到底该怎么计算它们的共模电压、差模电压这些关键参数?传…...
)
企业网络准入实战:用华三WX2540H和深信服AC搞定有线无线统一Portal认证(附OA集成)
企业级网络准入实战:华三WX2540H与深信服AC协同部署全攻略 当企业网络规模扩张到数百个终端时,传统MAC地址绑定和静态VLAN分配的管理方式就会暴露出明显短板。某制造企业IT主管张工最近就遇到了这样的困扰:研发部门的访客需要临时网络接入时&…...

如何将Rust二进制文件大小减少70%:min-sized-rust与主流优化方案全对比
如何将Rust二进制文件大小减少70%:min-sized-rust与主流优化方案全对比 【免费下载链接】min-sized-rust 🦀 How to minimize Rust binary size 📦 https://github.com/johnthagen/min-sized-rust 项目地址: https://gitcode.com/gh_mirror…...
Pixel Dream Workshop 创意激发:利用算法生成无限可能的艺术图案与纹理
Pixel Dream Workshop 创意激发:利用算法生成无限可能的艺术图案与纹理 1. 当算法遇见艺术:数字创作的新纪元 在传统艺术创作中,设计师们常常需要花费大量时间手工绘制图案和纹理。而如今,Pixel Dream Workshop的出现彻底改变了…...