MySQL——索引(二)创建索引(1)创建表的时候创建索引
要想使用索引提高数据表的访问速度,首先要创建一个常引。创建索引的方式有三种,具体如下。
创建表的时候可以直接创建索引,这种方式最简单、方便,其基本的语法格式如下所示:
CREATE TABLE 表名 (字段名 数据类型 [完整性约束条件],字段名 数据类型[完整性约束条件],...字段名 数据类型[UNIQUE|FULLTEXT|SPATIAL] INDEX|KEY[别名](字段名1[(长度)][ASC|DESC]); 关于上述语法的相关解释具体如下。
(1)UNIQUE:可选参数,表示唯一索引。
(2)FULLTEXT:可选参数,表示全文索引。
(3)SPATIAL:可选参数,表示空间索引。
(4)INDEX和 KEY:用来表示字段的索引,二者选一即可。
(5)别名:可选参数,表示创建的索引的名称。
(6)字段名1:指定索引对应字段的名称。
(7)长度:可选参数,用于表示索引的长度。
(8)ASC 和 DESC:可选参数,其中,ASC 表示升序排列,DESC 表示降序排列。
为了帮助读者更好地了解如何在创建表的时候创建索引,接下来,通过具体的案例分别对 MySQL 中的6种索引类型进行讲解,具体如下:
1)创建普通索引
例如,在 t1 表中 id 字段上建立索引,SQL 语句如下:
mysql> create table t1(id INT,-> name VARCHAR(20),-> score FLOAT,-> INDEX (id)-> );
Query OK, 0 rows affected (0.03 sec)上述 SQL语句执行后,使用 SHOW.CREATE TABLE 语句查看表的结构,结果如下所示:
mysql> show create table t1\G
*************************** 1. row ***************************Table: t1
Create Table: CREATE TABLE `t1` (`id` int DEFAULT NULL,`name` varchar(20) DEFAULT NULL,`score` float DEFAULT NULL,KEY `id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
从上述结果可以看出,id字段上已经创建了一个名称为id 的索引。为了查看索引是否被使用,可以使用 EXPLAIN 语句进行查看,SQL代码如下:
EXPLAIN SELECT * FROM t1 WHERE id=1 \G执行结果如下所示:
mysql> EXPLAIN SELECT * FROM t1 WHERE id=1 \G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: t1partitions: NULLtype: ref
possible_keys: idkey: idkey_len: 5ref: constrows: 1filtered: 100.00Extra: NULL
1 row in set, 1 warning (0.01 sec)从上述执行结果可以看出,possible_keys 和 key 的值都为 id,说明id 索引已经存在并且已经开始被使用了。
2)创建唯一性索引
例如,创建一个表名为 t2 的表,在表中的id 字段上建立索引名为 unique_id 的唯一性索引,并且按照升序排列,SQL语句如下:
mysql> create table t2(id INT NOT NULL,-> name VARCHAR(20) NOT NULL,-> score FLOAT,-> UNIQUE INDEX unique_id(id ASC)-> );
Query OK, 0 rows affected (0.02 sec)上述 SQL 语句执行后,使用 SHOW CREATE TABLE 语句查看表的结构,结果如下所示:
mysql> show create table t2\G
*************************** 1. row ***************************Table: t2
Create Table: CREATE TABLE `t2` (`id` int NOT NULL,`name` varchar(20) NOT NULL,`score` float DEFAULT NULL,UNIQUE KEY `unique_id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.01 sec)从上述结果可以看出,id 字段上已经建立了一个名称为 unique_id 的唯一性索引。
3)创建全文索引
例如,创建一个表名为 t3 的表,在表中的 name 字段上建立索引名为 fulltextname 的全文索引,SQL语句如下:
mysql> create table t3(id INT NOT NULL,-> name VARCHAR(20) NOT NULL,-> score FLOAT,-> FULLTEXT INDEX fulltext_name(name)-> )ENGINE=MyISAM;
Query OK, 0 rows affected (0.01 sec)上述 SQL语句执行后,使用 SHOW CREATE TABLE 语句查看表的结构,结果如下所示:
mysql> show create table t3\G
*************************** 1. row ***************************Table: t3
Create Table: CREATE TABLE `t3` (`id` int NOT NULL,`name` varchar(20) NOT NULL,`score` float DEFAULT NULL,FULLTEXT KEY `fulltext_name` (`name`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)从上述结果可以看出,name字段上已经建立了一个名为 fulltext_name 的全文索引.需要注意的是,由于目前只有 MyISAM 存储引擎支持全文索引,InnoDB 存储引擎还不支持全文索引,因此,在建立全文索引时,一定要注意表存储引擎的类型,对于经常需要索引的字符串、文字数据等信息,可以考虑存储到 MyISAM 存储引擎的表中。
4)创建单列索引
例如,创建一个表名为 t4 的表,在表中的 name 字段上建立索引名为 single.name的单列索引,SQL语句如下:
mysql> create table t4(id INT NOT NULL,-> name VARCHAR(20) NOT NULL,-> score FLOAT,-> INDEX single_name(name(20))-> );
Query OK, 0 rows affected (0.01 sec)上述 SQL语甸执行后,使用SHOW CREATE TABLE 语句登有衣的结构,结果如下所示:
mysql> show create table t4\G
*************************** 1. row ***************************Table: t4
Create Table: CREATE TABLE `t4` (`id` int NOT NULL,`name` varchar(20) NOT NULL,`score` float DEFAULT NULL,KEY `single_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)从上述结果可以看出,name字段上已经建立了一个名称为 single_name 的单列索引,并且索引的长度为 20。
5)创建多列索引
例如,创建一个表名为 t5 的表,在表中的 id 和 name 字段上建立索引名为multi 的多列索引,SQL语句如下:
mysql> create table t5(id INT NOT NULL,-> name VARCHAR(20) NOT NULL,-> score FLOAT,-> INDEX multi(id,name(20))-> );
Query OK, 0 rows affected (0.02 sec)上述 SQL语句执行后,使用 SHOW CREATE TABLE 语句查看表的结构,结果如下所示:
mysql> show create table t5\G
*************************** 1. row ***************************Table: t5
Create Table: CREATE TABLE `t5` (`id` int NOT NULL,`name` varchar(20) NOT NULL,`score` float DEFAULT NULL,KEY `multi` (`id`,`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)从上述结果可以看出,id 和 name 字段上已经建立了一个名为 multi 的多列索引需要注意的是,在多列索引中,只有査询条件中使用了这些字段中的第一个字段时,多列索引才会被使用。为了验证这个说法是否正确,将id字段作为查询条件,通过 EXPLAD语句查看索引的使用情况,SQL执行结果如下所示:
mysql> EXPLAIN SELECT * FROM t5 WHERE id=1 \G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: t5partitions: NULLtype: ref
possible_keys: multikey: multikey_len: 4ref: constrows: 1filtered: 100.00Extra: NULL
1 row in set, 1 warning (0.01 sec)从上述执行结果可以看出,possible_keys 和 key 的值都为 multi,说明 multi 索引已经存在,并且已经开始被使用了。但是,如果只使用 name 字段作为查询条件,SQL 执行结果如下所示:
mysql> EXPLAIN SELECT * FROM t5 WHERE name='Mike' \G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: t5partitions: NULLtype: ALL
possible_keys: NULLkey: NULLkey_len: NULLref: NULLrows: 1filtered: 100.00Extra: Using where
1 row in set, 1 warning (0.01 sec)从上述执行结果可以看出,possible_keys 和 key 的值都为 NULL,说明 multi 索引还没有被使用。
6)创建空间索引
例如,创建一个表名为 t6 的表,在空间类型为 GEOMETRY 的字段上创建空间索引,SQL 语句如下:
mysql> create table t6(id INT,-> space GEOMETRY NOT NULL,-> SPATIAL INDEX sp(space)-> )ENGINE=MyISAM;
Query OK, 0 rows affected, 1 warning (0.01 sec)上述 SQL语句执行后,使用 SHOW CREATE TABLE 语句查看表的结构,结果如下所示:
mysql> show create table t6\G
*************************** 1. row ***************************Table: t6
Create Table: CREATE TABLE `t6` (`id` int DEFAULT NULL,`space` geometry NOT NULL,SPATIAL KEY `sp` (`space`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)从上述结果可以看出,t6 表中的 space 字段上已经建立了一个名称为 sp 的空间索引。需要注意的是,创建空间索引时,所在字段的值不能为空值,并且表的存储引擎为MyISAM。
相关文章:
创建索引(1)创建表的时候创建索引)
MySQL——索引(二)创建索引(1)创建表的时候创建索引
要想使用索引提高数据表的访问速度,首先要创建一个常引。创建索引的方式有三种,具体如下。 创建表的时候可以直接创建索引,这种方式最简单、方便,其基本的语法格式如下所示: CREATE TABLE 表名 (字段名 数据类型 [完整性约束条件…...

源代码加密怎么做?企业常用十款源代码加密软件排行榜
在数字化信息时代,源代码是企业的核心资产之一。保护源代码的安全不仅能防止知识产权泄露,还能保护企业的竞争优势。因此,源代码加密成为企业信息安全的重要环节。 源代码是软件的基础,包含了企业独特的技术和解决方案。未加密的源…...

python 文件打开、读、关闭练习
一、题目要求 二、代码实现 f open("D:\\workspace\\word.txt" , "r", encoding "UTF-8")# 方案一 # content f.read() # count content.count("itheima") # print(f"itmeiha在文件中出现了:{count}次")# 方案…...

迈向大规模小目标检测:综述与数据集
为了准确检测小目标,领域内现有方法大多基于通用目标检测范式进行针对性改进,根据这些改进所采用关键技术的不同,可以分为六种类别:(1)面向样本的方法;(2)基于尺度感知的…...

69、zabbix自动、代理、snmp监控
一、zabbix 1.1、自动发现 [roottest1 ~]# systemctl stop firewalld [roottest1 ~]# setenforce 0 [roottest3 ~]# vim /etc/hosts 192.168.168.21 test1 192.168.168.23 test3 [roottest1 ~]# vim /etc/hosts 192.168.168.21 test1 192.168.168.23 test3 ------------…...

搜索引擎设计:如何避免大海捞针般的信息搜索
搜索引擎设计:如何避免大海捞针般的信息搜索 随着互联网的发展,信息的数量呈爆炸式增长。如何在海量信息中快速、准确地找到所需信息,成为了搜索引擎设计中的核心问题。本文将详细探讨搜索引擎的设计原理和技术,从信息获取、索引…...

设计模式- 数据源架构模式
表数据入口(Table Data Gateway) 充当数据库表访问入口的对象。一个实例处理表中所有的行。 表数据入口包含了用于访问单个表或者视图的所有SQL,如选择、插入、更新、删除等。其他代码调用它的方法来实现所有与数据库的交互。 运行机制 表数据入口包括的每个方法…...

Unity 使用字符串更改Text指定文字颜色、大小、换行、透明
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、使用字符串改变文字属性的方法(一)修改颜色(二)修改大小(三)换行(四&…...

数字信号处理2: 离散信号与系统的频谱分析
文章目录 前言一、实验目的二、实验设备三、实验内容四、实验原理五、实验步骤1.序列的离散傅里叶变换及分析2.利用共轭对称性,设计高效算法计算2个N点实序列的DFT。3.线性卷积及循环卷积的实现及二者关系分析4.比较DFT和FFT的运算时间5.利用FFT求信号频谱及分析采样…...

20240805软考架构--------每日打卡题21-25
每日打卡题21-25答案 21、【2014年真题】 难度:一般 在UML提供的系统视图中, (1) 是逻辑视图的一次执行实例,描述了并发与同步结构; (2) 是最基本的需求分析模型。 (1&a…...

GPT-5:未来已来,你准备好了吗?
GPT-5 一年半后发布?对此你有何期待? IT之家6月22日消息,在美国达特茅斯工程学院周四公布的采访中,OpenAI首席技术官米拉穆拉蒂被问及GPT-5是否会在明年发布,给出了肯定答案并表示将在一年半后发布。此外,穆…...

解决C#对Firebase数据序列化失败的难题
背景介绍 在当今的游戏开发领域,Unity与Firebase的结合日益普及。Firebase实时数据库提供了强大的数据存储和同步功能,使开发者能够轻松管理和使用数据。然而,在使用C#进行Firebase数据序列化和反序列化时,常常会遇到一些棘手的问…...

设计模式中的类关系
1. 依赖(Dependency) 定义:一个类使用到另一个类的实例,通常是通过方法参数、局部变量等。依赖关系是最弱的关系,因为它仅仅表示类之间的临时关联。 特征:在 UML 图中,依赖关系用带箭头的虚线…...

glibc的安装及MySQL的安全用户角色权限(twenty-one day)
一、glibc安装 mysql 清空/etc/目录下的my.cnf ls -l /etc/my.cnf rm -rf /etc/my.cnf yum -y remove mariadb find / -name "*mysql*" -exec rm -rf {} \; 安装mysql软件包 wget https://downloads.mysql.com/archives/get/p/23/file/mysql-8.0.33-li nux-glibc2.1…...

AttributeError: ‘ChatGLMTokenizer‘ object has no attribute ‘sp_tokenizer‘. 已解决
📑打牌 : da pai ge的个人主页 🌤️个人专栏 : da pai ge的博客专栏 ☁️宝剑锋从磨砺出,梅花香自苦寒来 ☁️运维工程师的职责:监…...

徐州BGP机房与普通机房的区别有哪些?
BGP也被称为是边界网关协议,是运行在TCP上的一种自治系统的路由协议,能够用来处理因特网大小的网络协议,同时也是能够处理好不相关路由域之间的多路连接的协议,今天小编主要来聊一聊徐州BGP机房与普通机房之间的区别有哪些&#x…...

VBA 程序运行中禁用鼠标键盘
1. Application.Interactive False:Excel 将阻止键盘和鼠标的所有输入,但代码显示的对话框的输入不受影响。 True:打开交互模式。 下面的代码程序一旦运行就会限定在Excel的事先选定的单元格输出。 如果注释掉Application.Interactive F…...
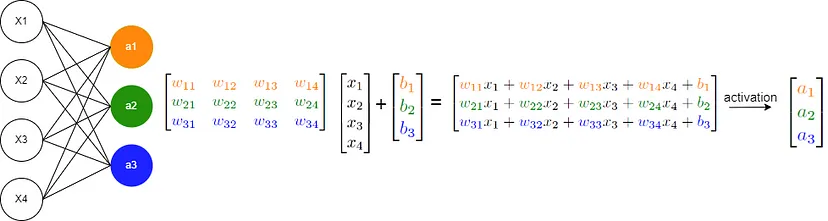
CUDA编程从零到壹
如今,当我们谈论深度学习时,为了提高性能,我们通常会将其实现与使用 GPU 联系起来。 GPU(图形处理单元)最初设计用于加速图像、2D 和 3D 图形的渲染。然而,由于它们能够执行许多并行操作,它们的…...

【国产开源可视化引擎】Meta2d.js API-Utils
Utils 常用功能函数 函数 formatPadding 将 padding 转换成数组格式 [top, right, bottom, left] padding 规则与 css padding 相同 参数: padding: Padding type Padding number | string | number[]; 返回: number[] 示例: formatP…...

大模型与数据分析的融合:创新与发展的新机遇
大模型与数据分析的融合:创新与发展的新机遇 前言大模型与数据分析的融合 前言 大模型与数据分析的融合正成为推动企业发展的关键力量。大模型在数据分析领域展现出了强大的能力。它能够以接近人类的水平理解和处理自然语言,快速、准确地解析大量非结构…...

escodegen浏览器端使用教程:在Web环境中实现代码生成
escodegen浏览器端使用教程:在Web环境中实现代码生成 【免费下载链接】escodegen ECMAScript code generator 项目地址: https://gitcode.com/gh_mirrors/es/escodegen escodegen是一个强大的ECMAScript代码生成器,它能够将抽象语法树(AST)转换回…...

seL4微内核技术演进:下一代安全内核的完整发展路线图指南
seL4微内核技术演进:下一代安全内核的完整发展路线图指南 【免费下载链接】seL4 The seL4 microkernel 项目地址: https://gitcode.com/gh_mirrors/se/seL4 seL4微内核作为全球首个形式化验证的安全操作系统内核,正引领着安全关键系统的发展方向。…...

鸿蒙与微信开发深度融合:技术适配、实操指南与生态展望
鸿蒙与微信开发深度融合:技术适配、实操指南与生态展望 随着鸿蒙系统(HarmonyOS NEXT)的全面普及,其分布式架构、原生生态的优势日益凸显,成为移动应用开发的新赛道。微信作为国民级应用,其鸿蒙版的适配与开…...

实战指南,基于快马平台快速构建用于工业质检的yolo缺陷检测系统
今天想和大家分享一个很实用的工业质检项目实战经验——基于YOLO模型快速搭建零件缺陷检测系统。这个项目特别适合需要快速验证算法效果的场景,我在InsCode(快马)平台上只用半天就完成了从原型到部署的全流程。 项目背景与需求分析 工业质检对精度和实时性要求很高&…...

大模型微调终极指南:从基础概念到实战技巧
前言 近年来,大语言模型(LLM)的爆发式发展正在深刻改变人工智能的格局。然而,如何将这些通用模型适配到特定领域和任务,成为了开发者面临的核心挑战。本文将系统性地梳理大模型后训练的核心方法,从监督微调…...

嵌入式系统错误处理策略与实现技术
1. 嵌入式系统中的错误处理概述在嵌入式软件开发中,错误处理是确保系统稳定性和可靠性的关键环节。与通用计算机系统不同,嵌入式系统往往运行在资源受限的环境中,且需要长时间不间断工作,这使得错误处理策略的选择尤为重要。嵌入式…...

OpenClaw安全实践:千问3.5-27B私有化部署下的权限管控
OpenClaw安全实践:千问3.5-27B私有化部署下的权限管控 1. 为什么需要关注OpenClaw的安全配置? 去年我在尝试用OpenClaw自动整理财务报表时,差点酿成一场灾难。当时我的脚本误将未加密的财务数据同步到了公开目录,幸亏及时发现。…...

OpenClaw任务编排:Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF处理依赖型工作流
OpenClaw任务编排:Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF处理依赖型工作流 1. 为什么需要任务编排 去年夏天,我接手了一个数据分析项目,需要定期从十几个网站抓取数据,清洗后生成分析报告,再邮件发送给团…...

Go语言的缓存策略与实现
Go语言的缓存策略与实现 1. 缓存简介 缓存是一种在计算机系统中用于提高数据访问速度的技术,它通过将频繁访问的数据存储在高速存储介质中,减少对慢速存储介质的访问,从而提高系统的响应速度和吞吐量。 缓存的优势 提高性能:缓存可…...

Python 中的正则表达式:从基础到高级应用
Python 中的正则表达式:从基础到高级应用 1. 背景介绍 正则表达式(Regular Expression,简称 regex 或 regexp)是一种用于匹配字符串中字符组合的模式。在 Python 中,正则表达式是处理文本的强大工具,它可以…...