【数据结构七夕专属版】单链表及单链表的实现【附源码和源码讲解】
本篇是博主在学习数据结构时的心得,希望能够帮助到大家,也许有些许遗漏,但博主已经尽了最大努力打破信息差,如果有遗漏还请见谅,嘻嘻,前路漫漫,我们一起前进!!!!
今天是七夕!!!虽然博主没有女朋友,但是在此我也祝各位有情人终成眷属。爱永无止境。
希望你们都能遇到自己的米子哈和大kin库!!!!!!!!!!!!!!!!!!!!!!!

目录
1.单链表的简介
1.1结点
结点申请规则
单链表和顺序表的对比
2、单链表的实现及其对应源码:
2.1单链表的创建:
2.2.链表的申请结点
2.3.单链表的打印
2.4.链表的尾插
2.5. 链表的头插
2.6.链表的尾删
2.7.链表的头删
2. 8.链表的查找
2.9. 链表的指定位置前的结点插入
2.10. 在指定位置后插入结点
2.11.删除pos结点
2.12.销毁链表
1.单链表的简介
链表是⼀种物理存储结构上⾮连续、⾮顺序的存储结构,数据元素的逻辑顺序是通过链表中的 指针链接次序实现的
1.1结点
链表中每个结点都是独⽴申请的(即需要插⼊数据时才去申请⼀块结点的空间),我们需要通过指针变量来保存下⼀个结点位置才能从当前结点找到下⼀个结点。
结点申请规则
- 链式机构在逻辑上是连续的,在物理结构上不⼀定连续
- 结点⼀般是从堆上申请的
- 从堆上申请来的空间,是按照⼀定策略分配出来的,每次申请的空间可能连续,可能不连续
单链表申请空间:
struct SListNode
{
int data;
SListNode*next;
}在我们想要存储一个整形数据时,实际先向内存申请一块空间,这个空间不仅要存放当前结点的数据,还存放着下一个结点的地址。(最后的结点存储的地址为NULL)
单链表和顺序表的对比
- 存储结构:
单链表的存储结构是非连续,非顺序的依靠地址的来寻找链表中的下一位数据。
顺序表在物理存储结构上是连续的,内存读取依次访问数据元素。 - 逻辑顺序:
单链表的逻辑顺序是依靠结点相连接的,
顺序标的逻辑顺序和物理顺序一样是紧挨着的。
- 代码实现:
单链表的实现需要依靠指针,
顺序表可以不用指针,用访问符就能访问到数据。
- 数据的存储:
在顺序表中,只需要开辟一系列的相邻的一块空间进行数据的存储。
在单链表中,每一个数据的位置都要申请,申请下来的空间叫做“结点”。
图解

2、单链表的实现及其对应源码:
单链表包括创建、申请结点、打印、头插、尾插、头删、尾删、链表查找、指定前插入、指定后插入、删除pos结点、删除pos后结点、销毁链表
单链表的实现 :
2.1单链表的创建:
typedef int SLDataType
typedef struct SListNode
{
SLDataType Data;
struct SListNode*next;
}sL;以上代码是对链表结点结构的声明,该链表结点包括一个类型为SLDataType的整形数据和一个地址。
2.2.链表的申请结点
SL*SLTButNode(SLTDataType x)
{
SL*newnode=(SL*)malloc(sizeof(SL));
if(newnode==NULL)
{
perror("malloc fail");
exit(1);
}
newnode->data=x;
newnode->next=NULLl;
}我们用图表示一下:

2.3.单链表的打印
void SLprint(SL*phead)
{
SL*pucr=phead;
while(pcur)
{
printf("%d",pucr->next);}
printf("NULL/n");}
这下我们用图解:

这里有几个注意的点:
1.*phead一定是该链表中的第一个结点。
2.对pcur解引用拿到下一个结点的指针才能进入下一次循环,不然pcur走不动,打印陷入死循环。
2.4.链表的尾插
void SLTPushBack(SL**pphead,SLTDataType x)
{
assert(pphead);
SL*newnode=SLButNode(x);
if(*pphead==NULL)
{
*pphead=newnode;}
else
{SL*pcur=*pphead;
while(pcur->next)
{
pucr=pucr->next;
}
pcur->next=newnode;}如果*pphead是NULL时,说明该链表的头结点还没有建立,所以如果从对一个没有头节点的链表进行尾插,头节点就是尾插的目标。
当*pphead不是NULL的时,代表要在链表结点之后插入,为了更直观的感受,我们用图解的方式来解释:

2.5. 链表的头插
void SLTPushFront(SL**pphead,SLDataType x)
{
assert(pphead&&*pphead);
SL*newnode=SLBuynode(x);newnode->next=*pphead;
*pphead=newnode;}
头插相较于尾插简单的多:
只要将先将头结点赋值给新的结点的存储地址,然后在再将新节点newnode当作新的头结点*pphead即可;

2.6.链表的尾删
void SLTpopBack(SL**pphead)
{
//链表为空:不可以删除
assert(pphead && *pphead);
//处理只有一个结点的情况:要删除的就是头结点
if((*pphead)->next=NULL)
{
free(*pphead);
*pphead=NULL;
}
else
{
SL* ptail = *pphead;
SL* prev = NULL;
while (ptail->next)
{prev = ptail;ptail = ptail->next;
}
prev->next = NULL;
free(ptail);
ptail = NULL;}这里我们还是用图解的方式来讲解:
尾删详解:这里用prev作为ptail的前一个指针,当ptail找到最后一个结点的时候,prev就是尾删的尾结点,所以先将prev的存储的下一个结点地址(prev->next)置为NULL,再将ptail所指的空间释放,最后ptail指向NULL,这就是尾删的过程

2.7.链表的头删
void SLTPopFront(SLTNode** pphead)
{assert(pphead && *pphead);SL* next = (*pphead)->next;//*pphead --> nextfree(*pphead);*pphead = next;
}这里头删就更加简单了,头结点就是要删除的结点,直接将头结点的指向的下一个结点的地址存储到next中,在进行释放头结点空间,最后在对新结点进行操作

2. 8.链表的查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{assert(phead);SLTNode* pcur = phead;while (pcur){if (pcur->data == x){return pcur;}pcur = pcur->next;}//没有找到return NULL;
}查找详解:
- 我们用pcur指针对单链表进行遍历,遍历过程中如果找到是否有与x匹配的数据,说明找到了,返回与x相等数据的pcur指针。
- 用pcur遍历完之后,如果没有找到与之匹配的数据,说明没有找到,返回NULL 。

2.9. 链表的指定位置前的结点插入
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{assert(pphead);assert(pos);if (pos == *pphead){SLTPushFront(pphead, x);}else{SLTNode* newnode = SLTBuyNode(x);//找prev :pos的前一个结点SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}//prev newnode --> posnewnode->next = pos;prev->next = newnode;}
}插入(位置前)详解:
- 如果pos的位置在头结点,我们直接在头结点头插即可。
- 如果pos不在头结点,我们先创建一个新的结点,用prev指针找到pos的前一个结点的地址,pos的本质是一个地址,我们用将新节点存储的地址给pos,newnode的地址给到prev指针所指向结点的存储地址。这样我们就将新节点插入到了pos结点的前面

2.10. 在指定位置后插入结点
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos);SLTNode* newnode = SLTBuyNode(x);//pos newnode --> pos->nextnewnode->next = pos->next;pos->next = newnode;
}插入(位置后)详解:
在指定位置后插入数据不需要用循环找pos后的位置了,因为pos所在的结点存储的地址就是下一个结点的地址,所以将pos存储的下一个结点的地址赋值给newnode的存储地址,之后再将pos的存储地址给newnode的地址,这样就完成了位置后插入。

2.11.删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead && *pphead);assert(pos);//头删if (pos == *pphead){SLTPopFront(pphead);}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}//prev pos pos->nextprev->next = pos->next;free(pos);pos = NULL;}
}
//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos)
{assert(pos && pos->next);//pos pos->next pos->next->nextSLTNode* del = pos->next;pos->next = pos->next->next;free(del);del = NULL;
}删除pos结点详解:
删除pos结点:用prev指针找到pos前一个结点的位置,用prev所在的结点的存储地址改为pos->next(pos后一个结点)。之后释放pos结点的空间,最后将pos指针置为NULL
删除pos之后的结点:用del代表pos的下一个结点,将pos的下下个结点的地址给pos的存储地址,释放del,将del指针置为NULL;
2.12.销毁链表
void SListDestroy(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;
}超详细源码:
cpp文件:
#define _CRT_SECURE_NO_WARNINGS 1
#include"Slist.h"
void SLprint(SLTNode*phead)
{SLTNode* pcur = phead;while (pcur){printf("%d", pcur->data);}printf("NULL/n");}
SLTNode* SLTBuyNode(SLTDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if(newnode==NULL){perror("malloc fail");exit(1);}newnode->data = x;newnode->next = NULL;
}void SLTPushBack(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);if (pphead == NULL){*pphead = newnode;}else{//找尾结点SLTNode* pcur = *pphead;while (pcur->next){pcur = pcur->next;}//pcur newnodepcur->next = newnode;
n }
}
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);//newnode *ppheadnewnode->next = *pphead;*pphead = newnode;
}
void SLTPopBack(SLTNode** pphead)
{//链表为空:不可以删除assert(pphead && *pphead);//处理只有一个结点的情况:要删除的就是头结点 if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}else{//找 prev ptailSLTNode* ptail = *pphead;SLTNode* prev = NULL;while (ptail->next){prev = ptail;ptail = ptail->next;}prev->next = NULL;free(ptail);ptail = NULL;}}void SLTPopFront(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* next = (*pphead)->next;//*pphead --> nextfree(*pphead);*pphead = next;
}SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{assert(phead);SLTNode* pcur = phead;while (pcur){if (pcur->data == x){return pcur;}pcur = pcur->next;}//没有找到return NULL;
}void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{assert(pphead);assert(pos);if (pos == *pphead){SLTPushFront(pphead, x);}else{SLTNode* newnode = SLTBuyNode(x);//找prev :pos的前一个结点SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}//prev newnode --> posnewnode->next = pos;prev->next = newnode;}
}
//在指定位置之后插⼊数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos);SLTNode* newnode = SLTBuyNode(x);//pos newnode --> pos->nextnewnode->next = pos->next;pos->next = newnode;
}
//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead && *pphead);assert(pos);//头删if (pos == *pphead){SLTPopFront(pphead);}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}//prev pos pos->nextprev->next = pos->next;free(pos);pos = NULL;}
}
//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos)
{assert(pos && pos->next);//pos pos->next pos->next->nextSLTNode* del = pos->next;pos->next = pos->next->next;free(del);del = NULL;
}
//销毁链表
void SListDestroy(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;
}
.h文件
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>//定义链表(结点)的结构typedef int SLTDataType;typedef struct SListNode {SLTDataType data;struct SListNode* next;
}SLTNode;void SLTPrint(SLTNode* phead);//插入
void SLTPushBack(SLTNode** pphead, SLTDataType x);//尾插
void SLTPushFront(SLTNode** pphead, SLTDataType x);//头插//删除
void SLTPopBack(SLTNode** pphead);
void SLTPopFront(SLTNode** pphead);//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);//在指定位置之前插⼊数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//在指定位置之后插⼊数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x);//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos);
//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos);
//销毁链表
void SListDestroy(SLTNode** pphead);结束语:
本篇单链表的章节到这里就结束了..........
感谢各位能观看到这里,感谢大家支持博主,很开心能和大家一起共同进步,一起学习!!!!!我希望能让更多的人看到这篇文章,希望大家能够多点赞,多交流。可以点波收藏,忘记的时候可以观看,在此wheel down先谢过大家!!!!!
时间漫长,我们一起度过,前路未知,我们一起并肩。

相关文章:
【数据结构七夕专属版】单链表及单链表的实现【附源码和源码讲解】
本篇是博主在学习数据结构时的心得,希望能够帮助到大家,也许有些许遗漏,但博主已经尽了最大努力打破信息差,如果有遗漏还请见谅,嘻嘻,前路漫漫,我们一起前进!!࿰…...

鸿蒙笔记--Socket
这一节主要了解鸿蒙Socket通信,在鸿蒙系统中,Socket TCP通讯是一种常用的网络通信方式,它提供了可靠的、面向连接的数据传输服务。它主要用到ohos.net.socket这个库; constructTCPSocketInstance:创建一个 TCPSocket;…...

安装python+python的基础语法
安装python python2为内置,安装python3----3.6.8 最新安装3.12使用源码安装 1.查看yum源,epel [rootpython01 ~]# yum list installed |grep epel 2.安装python3 [rootpython01 ~]# yum -y install python3 3.查看版本 [rootpython01 ~]# python…...

html+css网页制作 国家体育总局2个页面模版(无js)
htmlcss网页制作 国家体育总局2个页面模版(无js) 网页作品代码简单,可使用任意HTML编辑软件(如:Dreamweaver、HBuilder、Vscode 、Sublime 、Webstorm、Text 、Notepad 等任意html编辑软件进行运行及修改编辑等操作&a…...

Effective Java学习笔记第27、28条原生态类型和非受检警告
目录 什么是泛型 泛型与编译器 不要轻易使用原生态类型 可以通过通配符类型来替代原生态类型 几个适合原生态类型的场景 消除非受检的警告 什么是非受检警告 如果无法消除警告 本书27-33条主要介绍泛型。首先介绍什么是泛型,它的应用场景是什么。然后重点介…...

javaEE和javaSE
引用自:https://developer.baidu.com/article/detail.html?id3312755 文章目录 前景描述javaSE简介使用场景 javaEE(J2EE)简介使用场景 结语 前景描述 javaEE和javaSE是java中比较常见的两个概念,但是又比较容易忘记,在此进行记…...

Leetcode 17.电话号码的字母组合
目录 题目 方法一 思路 代码 题目 17. 电话号码的字母组合 难度:中等 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对…...

位1的个数
编写一个函数,获取一个正整数的二进制形式并返回其二进制表达式中设置位的个数(也被称为汉明重量)。 示例 1: 输入:n 11 输出:3 解释:输入的二进制串 1011 中,共有 3 个设置位。示…...

RPA在政务服务中的挑战与解决方案
随着数字化时代的到来,数字政务的建设已成必然趋势,RPA作为数字化转型的重要工具之一,能够帮助政府单位快速实现业务流程的自动化和智能化,提高工作效率和质量,为建设数字政务提供强有力的支持,因此正被越来…...

RabbitMQ docker安装
后台配置文件 rabbitmq:image: rabbitmq:latestcontainer_name: rabbitmqports:- "5672:5672" # RabbitMQ server port- "15672:15672" # RabbitMQ management console portenvironment:RABBITMQ_DEFAULT_USER: adminRABBITMQ_DEFAULT_PASS: admin 若要打…...

关于vs调试的一些基本技巧方法,建议新手学习
文章目录 1.Debug 和 Release2.VS的调试快捷键3.对程序的监视和内存观察3.1监视3.2内存 4.编程常见错误归类4.1编译型错误4.2链接型错误4.3运行时错误 1.Debug 和 Release 在我们使用的编译器 vs 中,这个位置有两个选项,分别为Debug和Release,…...
创建索引(2)使用 CREATE INDEX 语句在已经存在的表上创建索引)
MySQL——索引(二)创建索引(2)使用 CREATE INDEX 语句在已经存在的表上创建索引
若想在一个已经存在的表上创建索引,可以使用 CREATE INDEX 语句,CREATEINDEX语句创建索引的具体语法格式如下所示: CREATE [UNIQUEIFULLTEXTISPATIAL]INDEX 索引名 ON 表名(字段名[(长度)J[ASCIDESC]); 在上述语法格式中,UNIQUE、FULLTEXT 和…...

前端HTML总结
目录 前言 正文 head SEO body 网页的主要组成元素: body标签中常见的标签: 自闭合标签: 无语义标签: 特殊符号: 列表 子项: 样式修改: 定义列表: 语义化࿱…...

【动态规划】647. 回文子串
力扣链接:. - 力扣(LeetCode) 动规大法开始吟唱: dp[i][j]含义:从i到j的子串是否为回文子串 递推公式:当s[i] s[j]时 1. j-i<1时, dp[i][j]为true 2. 否则,若dp[i1][j-1]为true&#x…...
python-约瑟夫环(赛氪OJ)
[题目描述] n 个人( 0,1,2,3,4...n−1 ),围成一圈,从编号为 k 的人开始报数,报数报到 m 的人出队。 下次从出队的人之后开始重新报数,循环往复,当队伍中只剩最后一个人的时候,那个人…...

Less 教程:从入门到精通
Less 教程:从入门到精通 1. 引言 Less 是一种流行的动态样式表语言,它扩展了 CSS 的功能,使其更加强大和灵活。通过本教程,我们将深入探讨 Less 的基本概念、特性以及如何在项目中实际应用它。 2. Less 的基本概念 2.1 变量 …...

【VScode】如何在anaconda虚拟环境中打开vscode项目
文章目录 【必备知识】打开anaconda虚拟环境切换到项目工作目录激活anaconda虚拟路径让vscode从当前目录打开 【必备知识】 anaconda环境变量配置及配置python虚拟环境 https://blog.csdn.net/xzzteach/article/details/140621596 打开anaconda虚拟环境 切换到项目工作目录 …...

Flink任务提交流程和运行模式
任务提交流程 Flink 的提交流程随着部署模式、资源管理平台的不同,会有不同的变化。这里做进一步的抽象,形成一个大概高视角的任务执行流程图,如下: Flink按照集群和资源管理的划分运行模式有:Standalone、Flink On…...

【机器学习】 Sigmoid函数:机器学习中的关键激活函数
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 Sigmoid函数:机器学习中的关键激活函数1. 引言2. Sigmoid函数定义3.…...
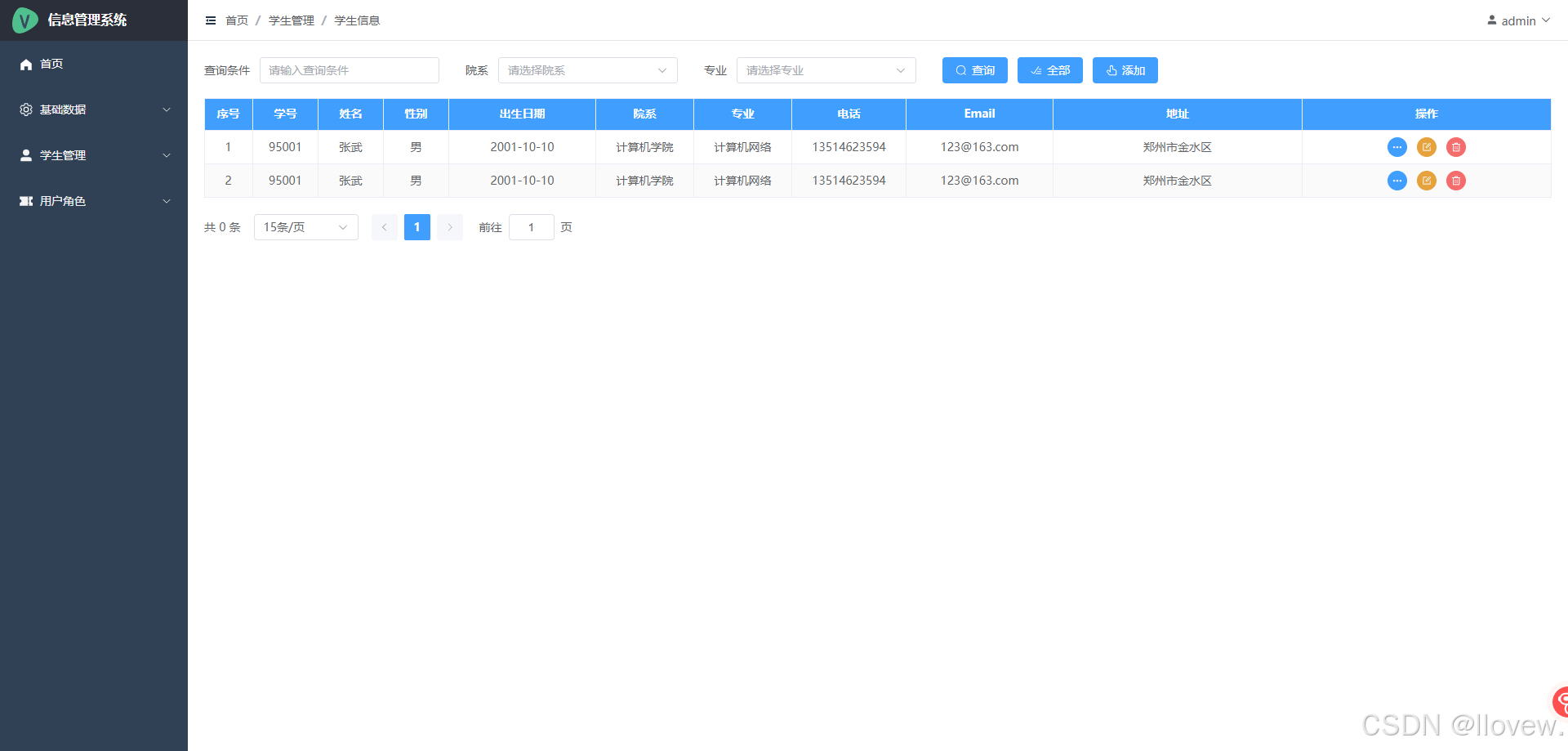
Vue+Element Plus后台管理主界面搭建实现
续接Django REST Framework,使用Vite构建Vue3的前端项目 1. 后台管理系统主界面框架搭建 后台系统主界面搭建 新建后台管理文件目录 完成后台整体布局 // 1.主界面 index.vue<script setup lang"ts"></script><template><el-…...

药片机MCGS6.2 与西门子 S7 - 200 PLC 联机程序探究
药片机MCGS6.2和西门子S7-200plc联机程序4,在自动化生产领域,药片机的精准控制至关重要。MCGS6.2 作为一款优秀的人机界面组态软件,与西门子 S7 - 200 PLC 配合,能实现高效的自动化控制。今天咱就唠唠它们联机程序的一些要点。 通…...
)
车ECU安全刷写(Secure Flashing/Programming)
车 ECU 安全刷写,核心是UDS 协议 安全访问 双分区回滚 供电 / 校验 / 合规全闭环。一、核心基础1. 定义与目标ECU 安全刷写:通过 OBD/CAN/Ethernet,按 ISO14229(UDS)、ISO15765 标准,对发动机 / 变速箱 …...

深度学习模型的解释性与可解释AI:从原理到实践
深度学习模型的解释性与可解释AI:从原理到实践 1. 背景介绍 深度学习模型在各种任务中取得了优异的性能,但它们通常被视为"黑盒",缺乏可解释性。随着AI应用在关键领域的普及,模型的可解释性变得越来越重要。本文将深入…...

论文AI率太高怎么降?去AI化实用技巧与工具避坑指南
“整篇论文都是自己原创的,就用AI顺了下逻辑,结果学校AIGC检测直接飙到73%,当场被打回”“熬了3个通宵手动改,AI率才降了不到12%,离答辩只剩一周根本赶不完”“随便找了个降AI工具,把我专业名词改得乱七八糟…...

GHelper终极指南:用轻量化工具彻底替代Armoury Crate,释放华硕ROG笔记本全部性能!
GHelper终极指南:用轻量化工具彻底替代Armoury Crate,释放华硕ROG笔记本全部性能! 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RG…...
三大特性之封装)
Javase(三)三大特性之封装
封装现实生活中,比如鼠标,我们知道它是全部装在一个装置里面,只暴露出一个接口能够我们充电或连接电脑,里面的设计、电路等都不暴露给我们这些使用者看,这样子能很好的保护里面的东西不被破坏。在Java中也是如此&#…...

不只是“生成一张图“:2026年6款真正改变设计工作流的AI界面工具深度测评
AI界面生成工具正在经历从"生成单张界面"到"生成完整产品体验"的代际跃迁。本文深度拆解 UXbot、Figma Make、Google Stitch、Flowstep、Visily AI 和 Moonchild 共6款2026年代表性工具——从设计稿生成到原生代码输出,覆盖完整的产品交付能力谱…...

RHCSA 认证必备:目录文件的管理
目录 一、创建目录 (1)格式 (2)参数 (3)示例 二、查看目录文件 1、查看目录文件 2、统计命令 3、编辑与删除 a.编辑目录文件 b.删除目录文件 一、创建目录 (1)格式 mkdi…...

风冷机房温湿度数据采集解决方案
对部分气候干旱的地区来说,使用风冷技术对数据机房进行冷却是比较合适的方案,但高能耗问题仍需要避免与管控,要求环境温湿度与散热效率进行合理分配。对此,物通博联提供温湿度数据采集到机房管理平台的解决方案。 需求如下 温湿度…...

Ohm模块化扩展与面向对象语法继承:构建可维护解析器的终极指南
Ohm模块化扩展与面向对象语法继承:构建可维护解析器的终极指南 【免费下载链接】ohm A library and language for building parsers, interpreters, compilers, etc. 项目地址: https://gitcode.com/gh_mirrors/oh/ohm Ohm是一个强大的解析器构建库和语言&am…...