MySQL——索引(二)创建索引(2)使用 CREATE INDEX 语句在已经存在的表上创建索引
若想在一个已经存在的表上创建索引,可以使用 CREATE INDEX 语句,CREATEINDEX语句创建索引的具体语法格式如下所示:
CREATE [UNIQUEIFULLTEXTISPATIAL]INDEX 索引名
ON 表名(字段名[(长度)J[ASCIDESC]);在上述语法格式中,UNIQUE、FULLTEXT 和 SPATIAL都是可选参数,分别用于表示唯一性索引、全文索引和空间索引;INDEX用于指明字段为索引。
为了便于学习如何使用CREATE INDEX语句在已经存在的表上创建索引,接下来,创建一个 book 表,该表中没有建立任何索引,创建 book 表的 SQL语句如下所示
mysql> create table book(-> bookid INT NOT NULL,-> bookname VARCHAR(255) NOT NULL,-> authors VARCHAR(255) NOT NULL,-> info VARCHAR(255) NULL,-> comment VARCHAR(255) NULL,-> publicyear YEAR NOT NULL-> );
Query OK, 0 rows affected (0.01 sec)创建好数据表 book 后,下面通过具体的案例为读者演示如何使用 CREAT INDEX语句在已存在的数据表中创建索引,具体如下。
1)创建普通索引
例如,在 book 表中的 bookid 字段上建立一个名称为 index_id 的普通索引,SQL 语句如下所示:
mysql> CREATE INDEX index_id ON book(bookid);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0上述 SQL 语句执行后,使用 SHOW CREATE TABLE 语句查看表的结构,结果如下所示:
mysql> show create table book \G
*************************** 1. row ***************************Table: book
Create Table: CREATE TABLE `book` (`bookid` int NOT NULL,`bookname` varchar(255) NOT NULL,`authors` varchar(255) NOT NULL,`info` varchar(255) DEFAULT NULL,`comment` varchar(255) DEFAULT NULL,`publicyear` year NOT NULL,KEY `index_id` (`bookid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)从上述结果可以看出,book 表中的 bookid 字段上已经建立了一个名称为 index_id的普通索引。
2)创建唯一性索引
例如,在 book 表中的 bookid 字段上建立一个名称为 uniqueidx 的唯一性索引,SQL 语句如下所示:
mysql> CREATE UNIQUE INDEX uniqueidx ON book(bookid);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0上述 SQL 语句执行后,使用 SHOW CREATE TABLE 语句查看表的结构,结果如下所示:
mysql> show create table book \G
*************************** 1. row ***************************Table: book
Create Table: CREATE TABLE `book` (`bookid` int NOT NULL,`bookname` varchar(255) NOT NULL,`authors` varchar(255) NOT NULL,`info` varchar(255) DEFAULT NULL,`comment` varchar(255) DEFAULT NULL,`publicyear` year NOT NULL,UNIQUE KEY `uniqueidx` (`bookid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)从上述结果可以看出,book 表中的 bookid 字段上已经建立了一个名称为 uniqueids的唯一性索引。
3)创建单列索引
例如,在 book 表中的 comment 字段上建立一个名称为 singleidx 的单列索引SQL语句如下所示:
CREATE INDEX singleidx ON book(comment);上述 SQL 语句执行后,使用 SHOW CREATE TABLE 语句查看表的结构,结果如下所示:
mysql> CREATE INDEX singleidx ON book(comment);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0从上述结果可以看出,book 表中的 comment 字段上已经建立了一个名称为singleidx 的单列索引。
4)创建多列索引
例如,在 book 表中的 authors 和 info 字段上建立一个名称为 mulitidx 的多列索引,SQL 语句如下所示:
CREATE INDEX mulitidx ON book(authors(20),info(20));
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0上述SQL语句执行后,使用 SHOW CREATE TABLE 语句查看表的结构,结果如下所示:
mysql> show create table book \G
*************************** 1. row ***************************Table: book
Create Table: CREATE TABLE `book` (`bookid` int NOT NULL,`bookname` varchar(255) NOT NULL,`authors` varchar(255) NOT NULL,`info` varchar(255) DEFAULT NULL,`comment` varchar(255) DEFAULT NULL,`publicyear` year NOT NULL,UNIQUE KEY `uniqueidx` (`bookid`),KEY `singleidx` (`comment`),KEY `mulitidx` (`authors`(20),`info`(20))
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)从上述结果可以看出,book 表中的 authors 和 info 字段上已经建立了一个名称为mulitidx的多列索引。
5)创建全文索引
例如,删除表 book,重新创建表 book,在表中的 info 字段上创建全文索引.首先删除表 book,SQL 语句如下:
mysql> DROP TABLE book;
Query OK, 0 rows affected (0.00 sec)然后重新创建表 book,SQL 语句如下:
mysql> create table book(-> bookid INT NOT NULL,-> bookname VARCHAR(255) NOT NULL,-> authors VARCHAR(255) NOT NULL,-> info VARCHAR(255) NULL,-> comment VARCHAR(255) NULL,-> publicyear YEAR NOT NULL-> )ENGINE=MyISAM;
Query OK, 0 rows affected (0.01 sec)使用 CREATE INDEX语句在 book 表的 info 字段上创建名称为 fulltextidx 的全文索引,SQL语句如下:
mysql> CREATE FULLTEXT INDEX fulltextidx ON book(info);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0为了验证全文索引 fulltextidx 是否创建成功,使用 SHOW CREATE TABLE 语句查看表的结构,结果如下所示:
mysql> show create table book \G
*************************** 1. row ***************************Table: book
Create Table: CREATE TABLE `book` (`bookid` int NOT NULL,`bookname` varchar(255) NOT NULL,`authors` varchar(255) NOT NULL,`info` varchar(255) DEFAULT NULL,`comment` varchar(255) DEFAULT NULL,`publicyear` year NOT NULL,FULLTEXT KEY `fulltextidx` (`info`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)从上述结果可以看出,book 表中的 info 字段上已经建立了一个名称为 fulltextidy的全文索引。
6)创建空间索引
例如,创建表 t7,在表中的g字段上创建名称为 spatidx 的空间索引首先创建数据表 t7,SQL语句如下:
mysql> create table t7(-> g GEOMETRY NOT NULL-> )ENGINE=MyISAM;
Query OK, 0 rows affected (0.00 sec)使用 CREATE INDEX 语句在 t7 表的g字段上创建名称为 spatidx 的空间索引SQL语句如下:
mysql> CREATE SPATIAL INDEX spatidx ON t7(g);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0为了验证空间索引spatidx是否创建成功,使用 SHOW CREATE TABLE 语句查看表的结构,结果如下所示:
mysql> show create table t7 \G
*************************** 1. row ***************************Table: t7
Create Table: CREATE TABLE `t7` (`g` geometry NOT NULL,SPATIAL KEY `spatidx` (`g`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)从上述结果可以看出,book 表中的g字段上已经建立了一个名称为 spatidx 的空间索引。
相关文章:
创建索引(2)使用 CREATE INDEX 语句在已经存在的表上创建索引)
MySQL——索引(二)创建索引(2)使用 CREATE INDEX 语句在已经存在的表上创建索引
若想在一个已经存在的表上创建索引,可以使用 CREATE INDEX 语句,CREATEINDEX语句创建索引的具体语法格式如下所示: CREATE [UNIQUEIFULLTEXTISPATIAL]INDEX 索引名 ON 表名(字段名[(长度)J[ASCIDESC]); 在上述语法格式中,UNIQUE、FULLTEXT 和…...

前端HTML总结
目录 前言 正文 head SEO body 网页的主要组成元素: body标签中常见的标签: 自闭合标签: 无语义标签: 特殊符号: 列表 子项: 样式修改: 定义列表: 语义化࿱…...

【动态规划】647. 回文子串
力扣链接:. - 力扣(LeetCode) 动规大法开始吟唱: dp[i][j]含义:从i到j的子串是否为回文子串 递推公式:当s[i] s[j]时 1. j-i<1时, dp[i][j]为true 2. 否则,若dp[i1][j-1]为true&#x…...
python-约瑟夫环(赛氪OJ)
[题目描述] n 个人( 0,1,2,3,4...n−1 ),围成一圈,从编号为 k 的人开始报数,报数报到 m 的人出队。 下次从出队的人之后开始重新报数,循环往复,当队伍中只剩最后一个人的时候,那个人…...

Less 教程:从入门到精通
Less 教程:从入门到精通 1. 引言 Less 是一种流行的动态样式表语言,它扩展了 CSS 的功能,使其更加强大和灵活。通过本教程,我们将深入探讨 Less 的基本概念、特性以及如何在项目中实际应用它。 2. Less 的基本概念 2.1 变量 …...

【VScode】如何在anaconda虚拟环境中打开vscode项目
文章目录 【必备知识】打开anaconda虚拟环境切换到项目工作目录激活anaconda虚拟路径让vscode从当前目录打开 【必备知识】 anaconda环境变量配置及配置python虚拟环境 https://blog.csdn.net/xzzteach/article/details/140621596 打开anaconda虚拟环境 切换到项目工作目录 …...

Flink任务提交流程和运行模式
任务提交流程 Flink 的提交流程随着部署模式、资源管理平台的不同,会有不同的变化。这里做进一步的抽象,形成一个大概高视角的任务执行流程图,如下: Flink按照集群和资源管理的划分运行模式有:Standalone、Flink On…...

【机器学习】 Sigmoid函数:机器学习中的关键激活函数
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 Sigmoid函数:机器学习中的关键激活函数1. 引言2. Sigmoid函数定义3.…...
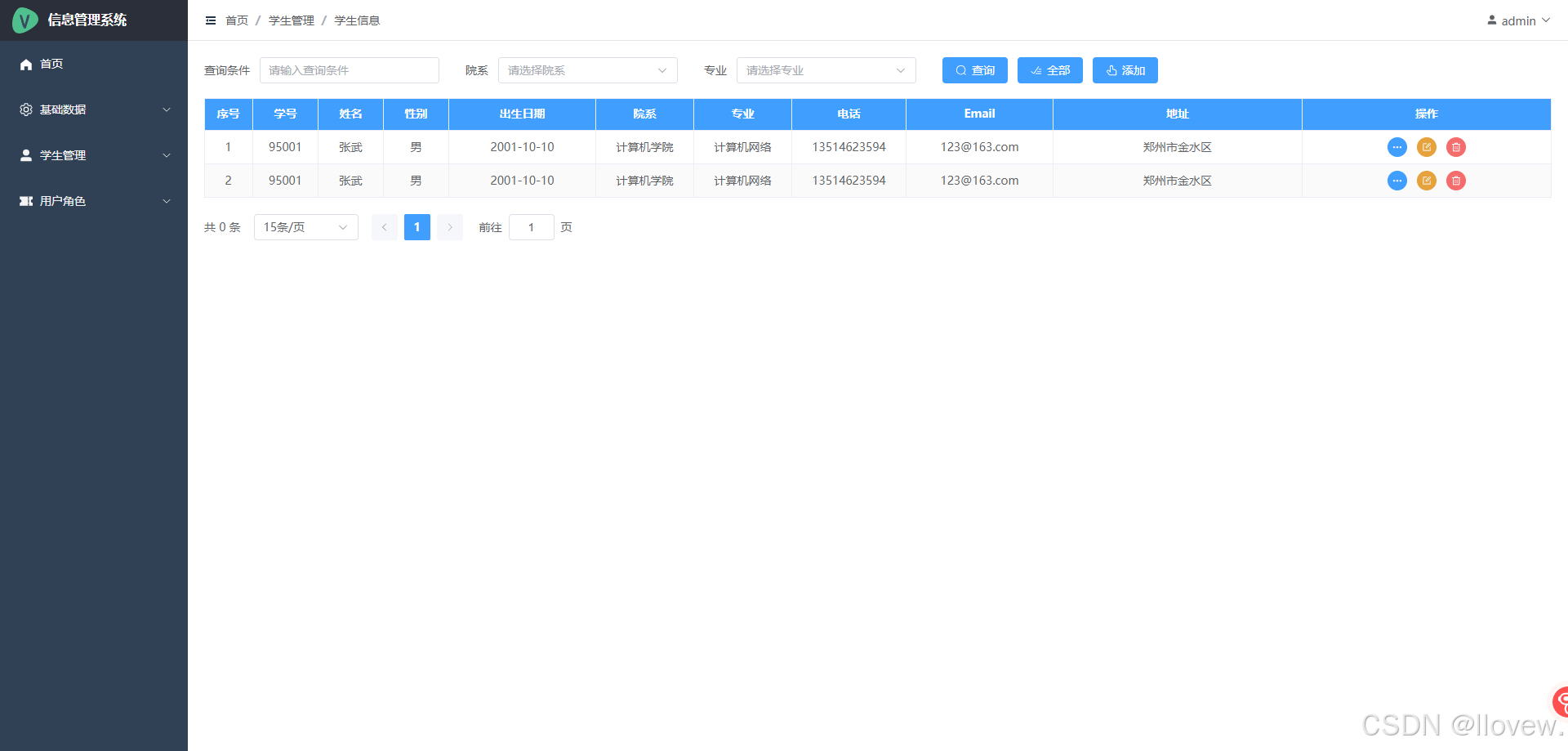
Vue+Element Plus后台管理主界面搭建实现
续接Django REST Framework,使用Vite构建Vue3的前端项目 1. 后台管理系统主界面框架搭建 后台系统主界面搭建 新建后台管理文件目录 完成后台整体布局 // 1.主界面 index.vue<script setup lang"ts"></script><template><el-…...

JAVA—异常
认识异常,学会从报错信息中发现问题,解决问题。并学会构建自定义异常,提醒编程时注意 目录 1.认识异常 2.自定义异常 1.自定义运行时异常 2.自定义编译时异常 3.异常的处理 1.认识异常 异常就是代表程序出现的问题,用来查询B…...

常见八股面试题:Dubbo 和 Spring Cloud Gateway 有什么区别?
大家好,我是鸭鸭! 此答案节选自鸭鸭最近弄的面试刷题神器面试鸭,更多大厂常问面试题,可以点击进行阅读哈! 目前这个面试刷题神器刚出,有网页和小程序双端可以阅读! 回归面试题! …...

k8s分布式存储-ceph
文章目录 Cephdeploy-ceph部署1.系统环境初始化1.1 修改主机名,DNS解析1.2 时间同步1.3 配置apt基础源与ceph源1.4关闭selinux与防火墙1.5 **创建** ceph **集群部署用户** cephadmin1.6分发密钥 2. ceph部署2.1 **安装** ceph 部署工具2.2 **初始化** mon **节点**…...

Redis cluster集群部署
redis搭建集群模式、Cluster模式(6节点,3主3从集群模式,添加删除节点)_redis cluster节点带数据增减-CSDN博客...

Java泛型的理解
前言 泛型是Java中一个比较重要的特性,是于JDK5引入新特性,其主要目的是为了提供编译时的类型安全检测机制和简化代码。本文主要探讨一下泛型的使用。 假如说没有泛型 假如说没有泛型,可以举一个例子: ArrayList list new Ar…...

Linux 照片图像编辑器
前言 照片图像编辑器是一种软件程序,它允许用户对数字照片或图像进行各种编辑和修改。以下是一些常见的功能及其解释: 裁剪与旋转 : 裁剪:移除图像的某些部分,以改善构图或符合特定尺寸要求。旋转:改变图像的方向,可以校正歪斜的照片或者为了艺术效果而旋转。调整亮度…...
【51单片机仿真】基于51单片机设计的智能六位密码锁(匿*输入/密码修改/警示/保存/恢复/初始密码)源码仿真设计文档演示视频——文末资料下载
基于51单片机设计的智能六位密码锁 演示视频 基于51单片机设计的智能六位密码锁 功能简介 - 能够从键盘中输入密码,并相应地在显示器上显示"*" - 能够判断密码是否正确,正确则开锁,错误则输出相应信息 - 能够实现密码的修改 -…...

【Vue3】组件通信之mitt
【Vue3】组件通信之mitt 背景简介开发环境开发步骤及源码总结 背景 随着年龄的增长,很多曾经烂熟于心的技术原理已被岁月摩擦得愈发模糊起来,技术出身的人总是很难放下一些执念,遂将这些知识整理成文,以纪念曾经努力学习奋斗的日…...
状态压缩动态规划——状压dp
状压dp:意思是将状态进行压缩,从而更容易地写出状态转移方程 通常做法:将每个状态(一个集合)用二进制表示,每个位的1就代表着这个编号的元素存在,0就代表着这个编号的元素不存在,如…...

【算法】最短路径算法思路小结
一、基础:二叉树的遍历->图的遍历 提到搜索算法,就不得不说两个最基础的思想: BFS(Breadth First Search)广度优先搜索 DFS(Depth First Search)深度优先搜索 刚开始是在二叉树遍历中接触这…...
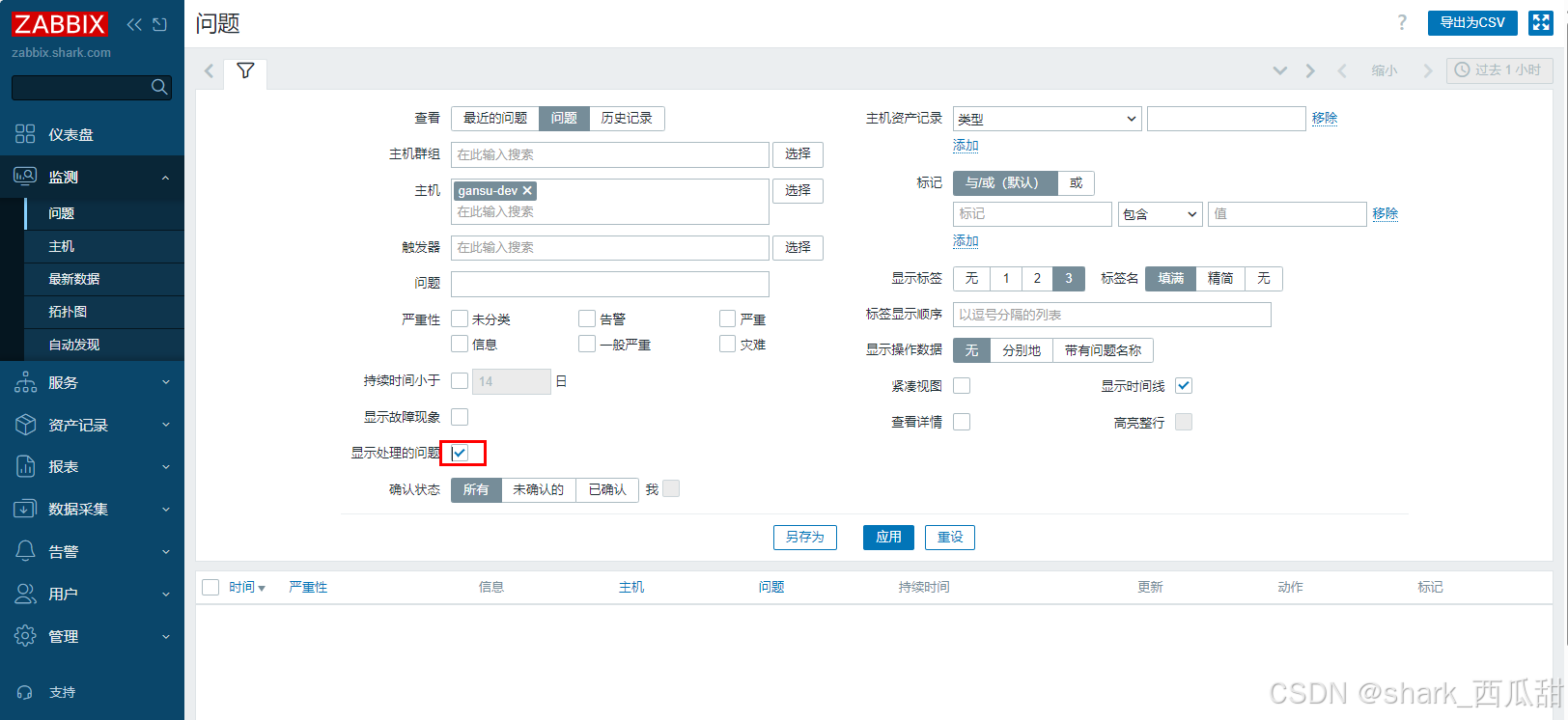
zabbix7.0TLS-05-快速入门-触发器
文章目录 1 概述2 查看主机的触发器3 添加触发器3.1 触发器配置项介绍3.2 扩展文档3.2.1 关于配置项中每个键值返回值的说明3.2.2 触发器函数文档 4 验证触发器5 问题5.1 查了问题总列表5.2 查看问题详情5.3 更新处理问题5.4 查看已经处理的问题 6 问题恢复 1 概述 监控项用于…...

Linux实现简易版Shell的代码详解
一、程序流程分析我们日常使用Bash时,通过输入命令执行相应的操作,比如:那么,Bash是如何进行工作的呢?观察一下,就会发现,首先Bash会打印命令行提示符,包括当前用户、主机名以及路径…...

好写作AI“期刊论文魔法工坊”:打造学术发表的秘密武器
在学术的浩瀚星空中,期刊论文宛如璀璨星辰,是研究者展示智慧结晶、推动学科发展的重要途径。然而,撰写一篇高质量且符合期刊要求的论文,却如同在荆棘丛中开辟道路,充满了挑战与艰辛。别担心,好写作AI宛如一…...

收藏!前端打工人破局指南:转AI Agent,告别重复劳动,薪资翻倍
作为前端打工人,那种深陷内耗的痛,真的只有自己懂👇 每天围着页面布局、接口联调死磕,需求堆成山,兼容问题调不停,看似忙碌的日子,全是机械的重复劳动,没有一点成长空间。 干得越久越…...

家用混动SUV舒适度技术科普入门:从实测看核心技术要点
在家用混动SUV的日常使用中,接送孩子上下学、家庭短途出行是最高频的场景,而“舒适度”并非单纯的主观感受,而是一套涵盖空间设计、座椅工程、材质工艺、座舱适配及动力平顺性的综合技术体系。对于有儿童乘坐需求的家庭而言,舒适度…...

2026年专业深度测评:超强增压花洒套装排名前五权威榜单
一、开篇:行业趋势与测评声明随着消费者对居家生活品质要求的精细化提升,以及高层住宅、老旧小区水压不稳问题的普遍存在,具备稳定出水与舒适沐浴体验的超强增压花洒套装已成为市场核心需求。为帮助消费者在众多产品中做出科学决策࿰…...
)
Python 实战:数据归一化 4 种核心方法对比 + 代码实现(机器学习必看)
在机器学习、深度学习的数据预处理中,数据归一化是绕不开的关键步骤。不同特征往往量纲不同(比如年龄 18-60、收入 1000-100000),直接训练模型会导致:梯度下降收敛慢、难以最优解距离类算法(KNN、K-Means、…...

Thorium浏览器:为什么这个基于Chromium的优化版本能解决你90%的性能痛点?
Thorium浏览器:为什么这个基于Chromium的优化版本能解决你90%的性能痛点? 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, lin…...

避坑指南:用OpenCV处理Kinetics-400数据集时,你可能遇到的3个典型问题及解决方案
避坑指南:用OpenCV处理Kinetics-400数据集时,你可能遇到的3个典型问题及解决方案 处理大型视频数据集如Kinetics-400时,即使是最有经验的开发者也会遇到各种意料之外的问题。本文将深入探讨三个最常见的技术陷阱,并提供经过实战验…...

Vue-Weixin 朋友圈功能实现全解析:图片上传与点赞评论交互详解
Vue-Weixin 朋友圈功能实现全解析:图片上传与点赞评论交互详解 【免费下载链接】vue-weixin Vue2 全家桶仿 微信App 项目,支持多人在线聊天和机器人聊天 项目地址: https://gitcode.com/gh_mirrors/vu/vue-weixin Vue-Weixin 是一个基于 Vue2 全家…...

洛谷 P2015:二叉苹果树 ← 有依赖的背包问题
【题目来源】 https://www.luogu.com.cn/problem/P2015 【题目描述】 有一棵苹果树,如果树枝有分叉,一定是分二叉(就是说没有只有一个儿子的结点)。 这棵树共有 N 个结点(叶子点或者树枝分叉点)࿰…...