模型部署之TorchScript
一.关于torchscript和jit介绍
1.关于torchscript
TorchScript是Pytorch模型(继承自nn.Module)的中间表示,保存后的torchscript模型可以在像C++这种高性能的环境中运行
TorchScript是一种从PyTorch代码创建可序列化和可优化模型的方法。任何TorchScript程序都可以从Python进程中保存,并加载到没有Python依赖的进程中。
简单来说,TorchScript能将动态图转为静态图,在pytorch的灵活的动态图特性下,torchscript提供了依然能够获取模型结构(模型定义)的工具。
2.关于torch.jit
什么是 JIT?
首先要知道 JIT 是一种概念,全称是 Just In Time Compilation,中文译为「即时编译」,是一种程序优化的方法,一种常见的使用场景是「正则表达式」。例如,在 Python 中使用正则表达式:
prog = re.compile(pattern)
result = prog.match(string)
#或
result = re.match(pattern, string)
上面两个例子是直接从 Python 官方文档中摘出来的 ,并且从文档中可知,两种写法从结果上来说是「等价」的。但注意第一种写法种,会先对正则表达式进行 compile,然后再进行使用。如果继续阅读 Python 的文档,可以找到下面这段话:
using re.compile() and saving the resulting regular expression object for reuse is more efficient when the expression will be used several times in a single program.
也就是说,如果多次使用到某一个正则表达式,则建议先对其进行 compile,然后再通过 compile 之后得到的对象来做正则匹配。而这个 compile 的过程,就可以理解为 JIT(即时编译)。
PyTorch 从面世以来一直以「易用性」著称,最贴合原生 Python 的开发方式,这得益于 PyTorch 的「动态图」结构。我们可以在 PyTorch 的模型前向中加任何 Python 的流程控制语句,甚至是下断点单步跟进都不会有任何问题,但是如果是 TensorFlow,则需要使用 tf.cond 等 TensorFlow 自己开发的流程控制。动态图模型通过牺牲一些高级特性来换取易用性。
JIT的优势:
1.模型部署
PyTorch 的 1.0 版本发布的最核心的两个新特性就是 JIT 和 C++ API,这两个特性一起发布不是没有道理的,JIT 是 Python 和 C++ 的桥梁,我们可以使用 Python 训练模型,然后通过 JIT 将模型转为语言无关的模块,从而让 C++ 可以非常方便得调用,从此「使用 Python 训练模型,使用 C++ 将模型部署到生产环境」对 PyTorch 来说成为了一件很容易的事。而因为使用了 C++,我们现在几乎可以把 PyTorch 模型部署到任意平台和设备上:树莓派、iOS、Android 等等…
- 性能提升
既然是为部署生产所提供的特性,那免不了在性能上面做了极大的优化,如果推断的场景对性能要求高,则可以考虑将模型(torch.nn.Module)转换为 TorchScript Module,再进行推断。
- 模型可视化
TensorFlow 或 Keras 对模型可视化工具(TensorBoard等)非常友好,因为本身就是静态图的编程模型,在模型定义好后整个模型的结构和正向逻辑就已经清楚了;但 PyTorch 本身是不支持的,所以 PyTorch 模型在可视化上一直表现得不好,但 JIT 改善了这一情况。现在可以使用 JIT 的 trace 功能来得到 PyTorch 模型针对某一输入的正向逻辑,通过正向逻辑可以得到模型大致的结构。(但如果在 forward 方法中有很多条件控制语句,这依然不是一个好的方法)
3.TorchScript Module 的两种生成方式
1.编码(Scripting)
可以直接使用 TorchScript Language 来定义一个 PyTorch JIT Module,然后用 torch.jit.script 来将他转换成 TorchScript Module 并保存成文件。而 TorchScript Language 本身也是 Python 代码,所以可以直接写在 Python 文件中。
使用 TorchScript Language 就如同使用 TensorFlow 一样,需要前定义好完整的图。对于 TensorFlow 我们知道不能直接使用 Python 中的 if 等语句来做条件控制,而是需要用 tf.cond,但对于 TorchScript 我们依然能够直接使用 if 和 for 等条件控制语句,所以即使是在静态图上,PyTorch 依然秉承了「易用」的特性。TorchScript Language 是静态类型的 Python 子集,静态类型也是用了 Python 3 的 typing 模块来实现,所以写 TorchScript Language 的体验也跟 Python 一模一样,只是某些 Python 特性无法使用(因为是子集),可以通过 TorchScript Language Reference 来查看和原生 Python 的异同。
理论上,使用 Scripting 的方式定义的 TorchScript Module 对模型可视化工具非常友好,因为已经提前定义了整个图结构。
- 追踪(Tracing)
使用 TorchScript Module 的更简单的办法是使用 Tracing,Tracing 可以直接将 PyTorch 模型(torch.nn.Module)转换成 TorchScript Module。「追踪」顾名思义,就是需要提供一个「输入」来让模型 forward 一遍,以通过该输入的流转路径,获得图的结构。这种方式对于 forward 逻辑简单的模型来说非常实用,但如果 forward 里面本身夹杂了很多流程控制语句,则可能会有问题,因为同一个输入不可能遍历到所有的逻辑分枝。
二.生成一个用于推理的torch模型
1.加载已导出的torch checkpointer模型
加载预训练模型配置文件和改写的模型结构
# 【multitask_classify_ner 多任务分类模型代码(包括classify任务和ner任务)】
class BertFourLevelArea(BertPreTrainedModel):"""BERT model for four level area."""def __init__(self, config, num_labels_cls, num_labels_ner, inner_dim, RoPE):super(BertFourLevelArea, self).__init__(config, num_labels_cls, num_labels_ner, inner_dim, RoPE)self.bert = BertModel(config)self.num_labels_cls = num_labels_clsself.num_labels_ner = num_labels_nerself.inner_dim = inner_dimself.hidden_size = config.hidden_sizeself.dense_ner = nn.Linear(self.hidden_size, self.num_labels_ner * self.inner_dim * 2)self.dense_cls = nn.Linear(self.hidden_size, num_labels_cls)self.RoPE = RoPEself.dropout = nn.Dropout(config.hidden_dropout_prob)self.apply(self.init_bert_weights)def sinusoidal_position_embedding(self, batch_size, seq_len, output_dim):position_ids = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(-1)indices = torch.arange(0, output_dim // 2, dtype=torch.float)indices = torch.pow(10000, -2 * indices / output_dim)embeddings = position_ids * indicesembeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1)embeddings = embeddings.repeat((batch_size, *([1]*len(embeddings.shape))))embeddings = torch.reshape(embeddings, (batch_size, seq_len, output_dim))embeddings = embeddings.to(self.device)return embeddingsdef forward(self, input_ids, token_type_ids=None, attention_mask=None):# sequence_output: Last Encoder Layer.shape: (batch_size, seq_len, hidden_size)encoded_layers, pooled_output = self.bert(input_ids, token_type_ids, attention_mask)sequence_output = encoded_layers[-1]batch_size = sequence_output.size()[0]seq_len = sequence_output.size()[1]# 【Bert Ner GlobalPointer】:# outputs: (batch_size, seq_len, num_labels_ner*inner_dim*2)outputs = self.dense_ner(sequence_output)# outputs: (batch_size, seq_len, num_labels_ner, inner_dim*2)outputs = torch.split(outputs, self.inner_dim * 2, dim=-1) # TODO:1outputs = torch.stack(outputs, dim=-2) # TODO:2# qw,kw: (batch_size, seq_len, num_labels_ner, inner_dim)qw, kw = outputs[...,:self.inner_dim], outputs[...,self.inner_dim:] # TODO:3if self.RoPE:# pos_emb:(batch_size, seq_len, inner_dim)pos_emb = self.sinusoidal_position_embedding(batch_size, seq_len, self.inner_dim)# cos_pos,sin_pos: (batch_size, seq_len, 1, inner_dim)cos_pos = pos_emb[..., None, 1::2].repeat_interleave(2, dim=-1)sin_pos = pos_emb[..., None,::2].repeat_interleave(2, dim=-1)qw2 = torch.stack([-qw[..., 1::2], qw[...,::2]], -1)qw2 = qw2.reshape(qw.shape)qw = qw * cos_pos + qw2 * sin_poskw2 = torch.stack([-kw[..., 1::2], kw[...,::2]], -1)kw2 = kw2.reshape(kw.shape)kw = kw * cos_pos + kw2 * sin_pos# logits_ner:(batch_size, num_labels_ner, seq_len, seq_len)logits_ner = torch.einsum('bmhd,bnhd->bhmn', qw, kw) # TODO:4# padding maskpad_mask = attention_mask.unsqueeze(1).unsqueeze(1).expand(batch_size, self.num_labels_ner, seq_len, seq_len) # TODO:5# pad_mask_h = attention_mask.unsqueeze(1).unsqueeze(-1).expand(batch_size, self.num_labels_ner, seq_len, seq_len)# pad_mask = pad_mask_v&pad_mask_hlogits_ner = logits_ner*pad_mask - (1-pad_mask)*1e12 # TODO:6# 排除下三角mask = torch.tril(torch.ones_like(logits_ner), -1) # TODO:7logits_ner = logits_ner - mask * 1e12 # TODO:8# 【Bert Classify】:pooled_output = self.dropout(pooled_output)logits_cls = self.dense_cls(pooled_output)return logits_cls, logits_ner#【加载预训练模型参数】
config = modeling.BertConfig.from_json_file('/root/ljh/space-based/Deep_Learning/Pytorch/multitask_classify_ner/pretrain_model/bert-base-chinese/config.json')#【加载我们训练的模型 】
#【num_labels_cls 和 num_labels_ner为我们训练的label_counts 这次训练的分类任务标签数为1524 ,NER任务的分类数为13】
num_labels_cls = 1524
num_labels_ner = 13
model = modeling.BertFourLevelArea(config,num_labels_cls=num_labels_cls,num_labels_ner=num_labels_ner,inner_dim=64,RoPE=False
)2.载入模型模型参数
加载已经训练好的模型参数
#【训练完成的tourch 模型地址】
init_checkpoint='/root/ljh/space-based/Deep_Learning/Pytorch/multitask_classify_ner/outputs.bak/multitask_classify_ner/pytorch_model.bin'
#【载入模型】
checkpoint = torch.load(init_checkpoint, map_location=torch.device("cuda"))
checkpoint = checkpoint["model"] if "model" in checkpoint.keys() else checkpoint
model.load_state_dict(checkpoint)
device = torch.device("cuda")#【将模型导入GPU】
model = model.to(device)
#【模型初始化】
model.eval()
3.构建torch.jit追踪参数
在我们的地址清洗多任务模型的forwad前向传播逻辑中并没有多种判断条件的结构,因此我们选择 追踪(Tracing)的形式来记录模型的前向传播过程和结构。
#【定义tokenizer 】
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained('/root/ljh/space-based/Deep_Learning/Pytorch/multitask_classify_ner/pretrain_model/bert-base-chinese', add_special_tokens=True, do_lower_case=False)input_str='上海上海市青浦区华隆路E通世界华新园'
max_seq_length=64#【生成bert模型输出】
def input2feature(input_str, max_seq_length=48):# 预处理字符tokens_a = tokenizer.tokenize(input_str)# 如果超过长度限制,则进行截断if len(input_str) > max_seq_length - 2:tokens_a = tokens_a[0:(max_seq_length - 2)]tokens = ["[CLS]"] + tokens_a + ["[SEP]"]input_ids = tokenizer.convert_tokens_to_ids(tokens)input_length = len(input_ids)input_mask = [1] * input_lengthsegment_ids = [0] * input_lengthwhile len(input_ids) < max_seq_length:input_ids.append(0)input_mask.append(0)segment_ids.append(0)return input_ids, input_mask, segment_ids#【输入地址token化 input_ids --> list()】
input_ids, input_mask, segment_ids = input2feature(input_str, max_seq_length)# 【list -> tensor】
input_ids = torch.tensor(input_ids, dtype=torch.long)
input_mask = torch.tensor(input_mask, dtype=torch.long)
segment_ids = torch.tensor(segment_ids, dtype=torch.long)#【这里stack 是因为模型内部定义的输出参数需要stack 】
input_ids = torch.stack([input_ids], dim=0)
input_mask = torch.stack([input_mask], dim=0)
segment_ids = torch.stack([segment_ids], dim=0)#【将参数推送至cuda设备中】
device = torch.device("cuda")
input_ids = input_ids.to(device)
input_mask = input_mask.to(device)
segment_ids = segment_ids.to(device)#【input_ids.shape --> torch.Size([1, 64])】
4.使用torch.jit 导出TorchScript Module模型
jit 使用追踪(Tracing)的形式来记录模型的前向传播过程和结构
#【根据输出的input_ids, input_mask, segment_id记录前向传播过程】
script_model = torch.jit.trace(model,[input_ids, input_mask, segment_ids],strict=True)
#【保存】
torch.jit.save(script_model, "./multitask_test/multitask_model/1/model.pt")
5.验证TorchScript Module是否正确
#【查看torch模型结果】
cls_res, ner_res = model(input_ids, input_mask, segment_ids)import numpy as np
np.argmax(cls_res.detach().cpu().numpy())
#【result:673】#【load torchscript model】
jit_model = torch.jit.load('./multitask_test/multitask_model/1/model.pt')
example_outputs_cls,example_outputs_ner = jit_model(input_ids, input_mask, segment_ids)
np.argmax(example_outputs_cls.detach().cpu().numpy())
#【result:673】三. 使用triton server 启动 torchscript model模型
1. 修改config.ptxtx 配置文件
name: "multitask_model"
platform: "pytorch_libtorch"
max_batch_size: 8
input [{name: "input_ids"data_type: TYPE_INT64dims: 64},{name: "segment_ids"data_type: TYPE_INT64dims: 64 },{name: "input_mask"data_type: TYPE_INT64dims: 64}
]
output [{name: "cls_logits"data_type: TYPE_FP32dims: [1, 1524]},{name: "ner_logits"data_type: TYPE_FP32dims: [ -1, 13, 64, 64 ]}
]dynamic_batching {preferred_batch_size: [ 1, 2, 4, 8 ]max_queue_delay_microseconds: 50}instance_group [
{count: 1kind: KIND_GPUgpus: [0]
}
]2.模型目录结构
multitask_test
└── multitask_model
├── 1
│ └── model.pt
├── config.pbtxt
└── label_cls.csv
3.启动triton
tritonserver --model-store=/root/ljh/space-based/Deep_Learning/Pytorch/multitask_classify_ner/multitask_test --strict-model-config=false --exit-on-error=false
四. torchscript model模型部署待解决点
在尝试使用torchscript多卡部署的过程中会出现model模型与cuda绑定的情况,在使用triton启动模型之后只有与模型进行绑定的cuda设备才能够正常执行。
类似问题参考:https://github.com/triton-inference-server/server/issues/2626
相关文章:

模型部署之TorchScript
一.关于torchscript和jit介绍 1.关于torchscript TorchScript是Pytorch模型(继承自nn.Module)的中间表示,保存后的torchscript模型可以在像C这种高性能的环境中运行 TorchScript是一种从PyTorch代码创建可序列化和可优化模型的方法。任何T…...
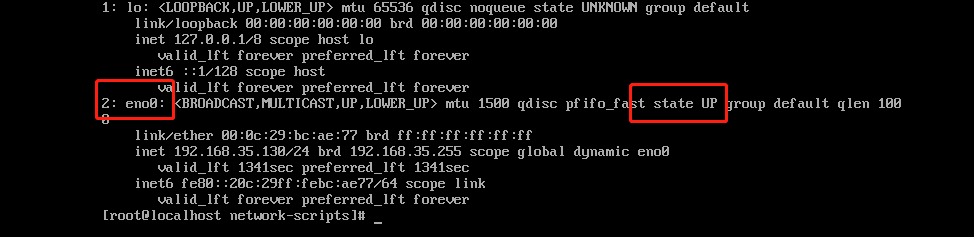
修改linux网卡配置文件的文件名
修改linux网卡配置文件的文件名 查看自己系统中网卡配置文件的文件名 #查看网卡的配置文件名,已经网络的状态 ip a查看系统是否可以使用ifconfig命令 #输入命令 ifconfig #出现以下图片表示ifconfig的命令可用。可能出现的错误:ifconfig command no foun…...

年轻人为啥热衷去寺庙?
年轻人的苦,寺庙最清楚。 周末的寺庙挤满了年轻人,北京雍和宫限流了,杭州灵隐寺十八籽的手串限购了,南京鸡鸣寺从地铁站出口就开始排队了...... “上班和上学,你选择哪个?” ”我选择上香“ 工作和学习…...

Java Spring 框架
当今世界,Java Spring 成为了最流行的 Java 开发框架之一。Spring 框架是一个轻量级的、高效的框架,它是 Java 应用程序开发的理想选择。在本文中,我们将深入探讨 Java Spring 框架的特性、优点以及如何使用它来构建高质量的应用程序。 1.Ja…...

基于OpenCV的人脸识别
目录 🥩 前言 🍖 环境使用 🍖 模块使用 🍖 模块介绍 🍖 模块安装问题: 🥩 OpenCV 简介 🍖 安装 OpenCV 模块 🥩 OpenCV 基本使用 🍖 读取图片 🍗 【…...

一文带你看懂电压放大器和功率放大器的区别
很多人对于电压放大器和功率放大器总是分不太清,在实际应用过程中,电压放大器和功率放大器所起到的作用都是相同的。对于功率放大器和电压放大器的区别,今天就让安泰电子来带我们一起看看。功率放大器和电压放大器的主要区别是:功…...

C++虚函数与多态
C虚函数与多态虚函数抽象类纯虚函数虚析构函数多态虚函数的几个问题纯虚函数和ADT虚函数 virtual修饰的成员函数就是虚函数, 1.虚函数对类的内存影响:增加一个指针类型大小(32位和64位) 2.无论有多少个虚函数,只增加一…...

蓝桥杯Web前端练习-----渐变色背景生成器
介绍 相信做过前端开发的小伙伴们对渐变色在 UI 设计中的流行度一定不陌生,网页上也时常可以看到各类复杂的渐变色生成工具。使用原生的 CSS 变量加一些 JS 函数就能做出一个简单的渐变色背景生成器。 现在渐变色生成器只完成了颜色选取的功能,需要大家…...

Python中的微型巨人-Flask
文章目录前言主要内容优点及特性主要使用创建实例定义路由获取请求定制响应渲染Jinja2模板重定向和反向解析抛出HTTP异常总结更多宝藏前言 😎🥳😎🤠😮🤖🙈💭🍳…...

密码学中的承诺
Commitment 概述 密码学承诺是一个涉及两方的二阶段交互协议,双方分别为承诺方和接收方。简述来说,它的功能涵盖不可更改性和确定性。 承诺方发送的消息密文,一旦发出就意味着不会再更改,而接收方收到这个消息可以进行验证结果。…...
)
redis入门实战一、五种数据结构的基本操作(二)
redis入门实战一、五种数据结构的基本操作【二】 一、String1)、set2)、getset3)、msetnx 给多个元素赋值,原子操作4)、字符串 追加 & 取部分数据5)、数值可以做加减,指定增量大小6)、获取长度7)、 bitmap①、setbit②、bitop 二进制与或运算(效率高)③、bitcou…...

day13 模块和异常捕获总结
day13 模块和异常捕获 一、生成器 (一)、什么是生成器 1)容器(是一种可以创建多个数据的容器),生成器中保存的是创建数据的方法,而不是数据本身。2)特点: a. 打印生成…...
【Linux】进程优先级 环境变量
进程优先级 环境变量 一、进程优先级1、基本概念2、查看以及修改系统进程的优先级3、一些其他的关于进程优先级的指令和函数调用4、与进程优先级有关的一些进程性质二、环境变量1、基本概念2、和环境变量相关的命令3、Linux中的常见环境变量介绍4、环境变量的组织方式以及在C代…...

UE实现建筑分层抽屉展示效果
文章目录 1.实现目标2.实现过程2.1 基础设置2.2 核心函数3.参考资料1.实现目标 使用时间轴对建筑楼层的位置偏移进行控制,实现分层抽屉的动画展示效果。 2.实现过程 建筑抽屉的实现原理比较简单,即对Actor的位置进行偏移,计算并更新其世界位置即可。这里还是基于ArchVizExp…...

【C语言进阶:刨根究底字符串函数】 strstr 函数
本节重点内容: 深入理解strstr函数的使用学会strstr函数的模拟实现⚡strstr strstr的基本使用: #define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include<string.h>int main() {char arr1[] "abcdebcdef";char arr2[] &…...
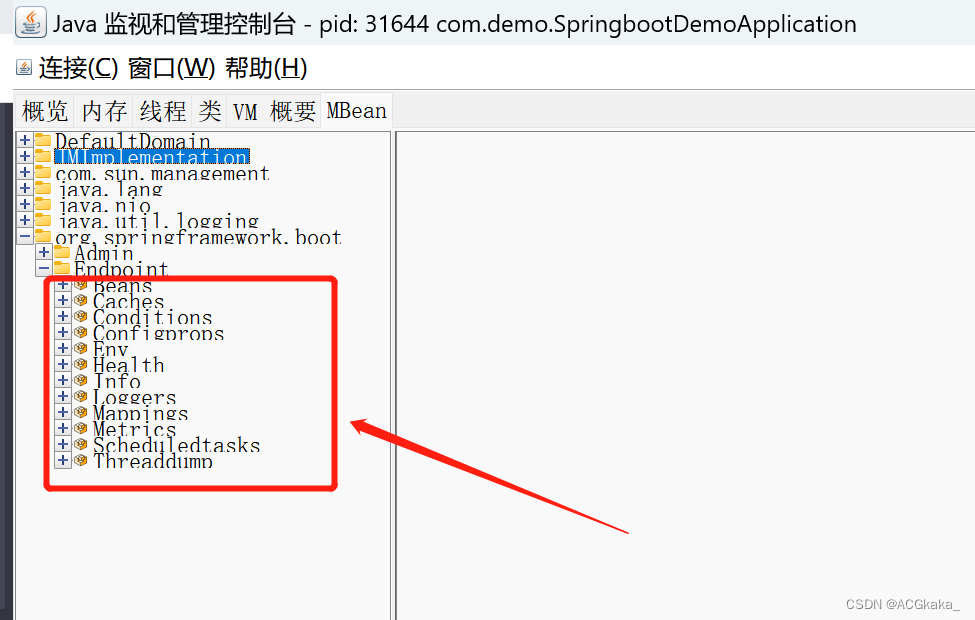
SpringBoot实战(十二)集成Actuator
目录一、简介二、Maven依赖三、使用入门1.HTTP 方式访问端点2.JMX 方式访问端点3.端点信息整理4.端点的启用与禁用5.端点的公开6.保护 HTTP 端点7.配置 CORS 跨域官方文档: https://docs.spring.io/spring-boot/docs/2.4.5/reference/htmlsingle/#production-ready …...

学习系统编程No.7【进程替换】
引言: 北京时间:2023/3/21/7:17,这篇博客本来昨天晚上就能开始写的,但是由于笔试强训的原因,导致时间用在了做题上,通过快2个小时的垂死挣扎,我充分意识到了自己做题能力的缺陷和运用新知识的缺…...
、Java并发)
【3.22】操作系统内存管理(整理)、Java并发
3. 内存管理 为什么要有虚拟内存? 我们想要同时在内存中运行多个程序,就需要把进程所使用的地址隔离,所以使用了虚拟内存。简单来说,虚拟内存地址是程序使用的内存地址。物理内存地址是实际存在硬件里面的地址。 操作系统为每个…...

电脑文件丢失怎么找回来
电脑文件丢失怎么找回来?最近打开电脑时,它启动得很慢。刚刚开始我没有没在意,就重启了当我再次打开电脑时,发现桌面上的文件消失了,面对这种意外情况,有什么办法可以快速找到呢? 电脑文件丢失后,想要找回…...
Python(白银时代)——面向对象
基本概念 面向过程 是早期的一个编程概念,类似函数,但是没有返回值 具体做法: 把完成某个需求的所有步骤,从头到尾 逐步实现 将某些功能独立的代码 封装成一个又一个 函数 然后顺序调用不同的函数 特点: 注重 步骤…...

pk3DS完全指南:解锁宝可梦3DS游戏的无限可能
pk3DS完全指南:解锁宝可梦3DS游戏的无限可能 【免费下载链接】pk3DS Pokmon (3DS) ROM Editor & Randomizer 项目地址: https://gitcode.com/gh_mirrors/pk/pk3DS 你是否已经厌倦了千篇一律的宝可梦冒险?每次遇到的野生宝可梦都相同ÿ…...

Qwen3.5-4B-Claude-Opus零基础上手:Web交互页面功能详解与最佳实践
Qwen3.5-4B-Claude-Opus零基础上手:Web交互页面功能详解与最佳实践 1. 模型与平台介绍 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF 是一个基于 Qwen3.5-4B 的推理蒸馏模型,特别强化了结构化分析、分步骤回答、代码与逻辑类问题的处理能力。…...

Flask-AppBuilder表单验证终极指南:构建企业级安全应用的10个核心技巧
Flask-AppBuilder表单验证终极指南:构建企业级安全应用的10个核心技巧 【免费下载链接】Flask-AppBuilder Simple and rapid application development framework, built on top of Flask. includes detailed security, auto CRUD generation for your models, googl…...

Dify工作流集成StructBERT:构建自定义文本智能处理应用
Dify工作流集成StructBERT:构建自定义文本智能处理应用 最近在做一个智能客服系统的升级项目,客户那边提了个挺实际的需求:每天有大量工单进来,希望系统能先自动判断一下问题类型,比如是“账号问题”、“支付故障”还…...

Wan2.2-I2V-A14B GPU算力优化:显存碎片整理与缓存复用机制解析
Wan2.2-I2V-A14B GPU算力优化:显存碎片整理与缓存复用机制解析 1. 引言 在视频生成领域,Wan2.2-I2V-A14B模型凭借其出色的生成质量和稳定性,已成为众多企业和开发者的首选。然而,随着视频分辨率和时长的提升,显存资源…...

Java异常体系全景解析:从Checked与Unchecked的本质区别到最佳实践
Java异常体系全景解析:从Checked与Unchecked的本质区别到最佳实践在Java的浩瀚生态中,异常处理机制无疑是构建健壮、可靠应用程序的基石。它不仅仅是简单的错误捕获,更是一套精密的契约系统,决定了程序在遭遇非预期状态时如何“表…...
)
从一道CTF赛题出发:手把手教你用火眼取证分析手机APP数据(附雷电模拟器实战)
从一道CTF赛题出发:手把手教你用火眼取证分析手机APP数据(附雷电模拟器实战) 在网络安全竞赛和电子数据取证领域,手机取证一直是技术含量高且实用性强的核心技能。本文将从一个真实的CTF赛题切入,带您完整走通手机镜像…...

实时手机检测-通用:5分钟快速部署,小白也能轻松上手
实时手机检测-通用:5分钟快速部署,小白也能轻松上手 1. 模型简介 实时手机检测-通用是一款基于DAMOYOLO-S框架的高性能目标检测模型,专门用于在各种场景中快速准确地检测手机设备。这个模型在精度和速度上都超越了传统的YOLO系列方法&#…...

写作压力小了!2026最新AI论文写作工具测评与推荐
2026年真正好用的AI论文写作工具,核心看生成的论文质量、低AI味、格式正确、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

MQTT安全连接不止一种:用MQTTnet库玩转C#客户端单向与双向认证
MQTT安全连接实战:从单向认证到双向认证的C#实现精要 物联网设备间的数据传输安全一直是开发者关注的核心问题。MQTT协议作为轻量级的消息传输协议,在工业自动化、智能家居等领域广泛应用,但其默认的1883端口通信并不加密。本文将深入探讨如何…...