【阿旭机器学习实战】【39】脑肿瘤数据分析与预测案例:数据分析、预处理、模型训练预测、评估
《------往期经典推荐------》
一、【100个深度学习实战项目】【链接】,持续更新~~
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 1.原始数据分析
- 1.1 查看数据基本信息
- 1.2 绘图查看数据分布
- 2.数据预处理
- 2.1 数据特征编码与on-hot处理
- 3.模型训练与调优
- 3.1 数据划分
- 3.2 模型训练调优
- 3.3 模型评估
1.原始数据分析
1.1 查看数据基本信息
#import libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
#Load Data
data = pd.read_csv('/kaggle/input/brain-tumor-dataset/brain_tumor_dataset.csv')
#insights from data
data.head()
| Tumor Type | Location | Size (cm) | Grade | Patient Age | Gender | |
|---|---|---|---|---|---|---|
| 0 | Oligodendroglioma | Occipital Lobe | 9.23 | I | 48 | Female |
| 1 | Ependymoma | Occipital Lobe | 0.87 | II | 47 | Male |
| 2 | Meningioma | Occipital Lobe | 2.33 | II | 12 | Female |
| 3 | Ependymoma | Occipital Lobe | 1.45 | III | 38 | Female |
| 4 | Ependymoma | Brainstem | 6.45 | I | 35 | Female |
data.shape
(1000, 6)
脑肿瘤的类型查看,共5种。
data['Tumor Type'].unique()
array(['Oligodendroglioma', 'Ependymoma', 'Meningioma', 'Astrocytoma','Glioblastoma'], dtype=object)
data.describe()
| Size (cm) | Patient Age | |
|---|---|---|
| count | 1000.000000 | 1000.000000 |
| mean | 5.221500 | 43.519000 |
| std | 2.827318 | 25.005818 |
| min | 0.510000 | 1.000000 |
| 25% | 2.760000 | 22.000000 |
| 50% | 5.265000 | 43.000000 |
| 75% | 7.692500 | 65.000000 |
| max | 10.000000 | 89.000000 |
#Percentage of missing values in the dataset
missing_percentage = (data.isnull().sum() / len(data)) * 100
print(missing_percentage)
Tumor Type 0.0
Location 0.0
Size (cm) 0.0
Grade 0.0
Patient Age 0.0
Gender 0.0
dtype: float64
没有缺失数据
1.2 绘图查看数据分布
import seaborn as snsplt.figure(figsize=(10, 6))
sns.histplot(data['Patient Age'], bins=10, kde=True, color='skyblue')
plt.title('Distribution of Patient Ages')
plt.xlabel('Age')
plt.ylabel('Count')
plt.grid(True)
plt.show()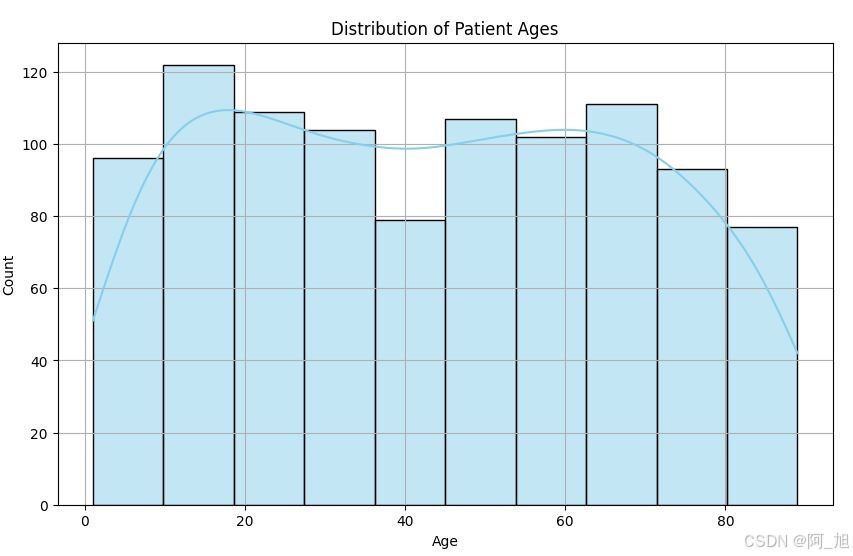
plt.figure(figsize=(10, 6))
sns.boxplot(x='Tumor Type', y='Size (cm)', data=data, palette='pastel')
plt.title('Tumor Sizes by Type')
plt.xticks(rotation=45)
plt.xlabel('Tumor Type')
plt.ylabel('Size (cm)')
plt.grid(True)
plt.show()
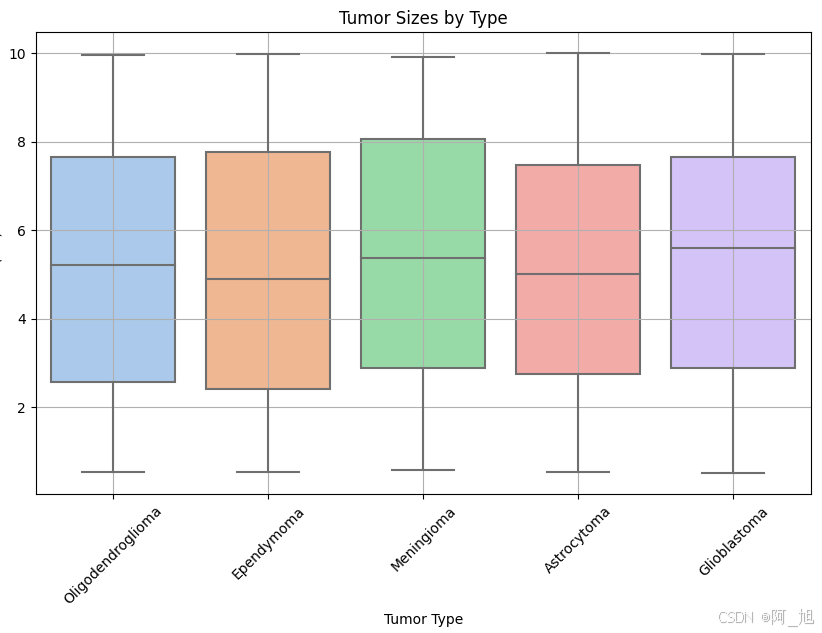
plt.figure(figsize=(8, 6))
sns.countplot(x='Tumor Type', data=data, palette='Set3')
plt.title('Count of Tumor Types')
plt.xlabel('Tumor Type')
plt.ylabel('Count')
plt.xticks(rotation=45)
plt.grid(True)
plt.show()
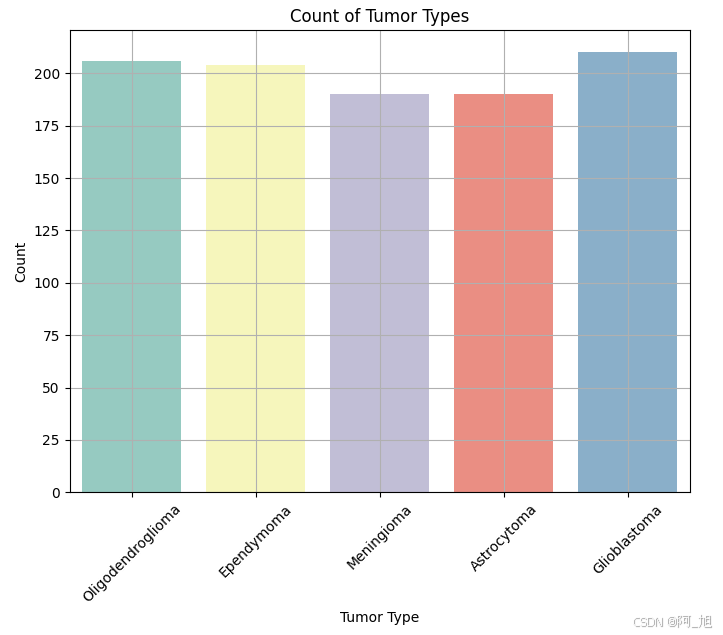
plt.figure(figsize=(10, 6))
sns.scatterplot(x='Size (cm)', y='Patient Age', hue='Tumor Type', data=data, palette='Set2', s=100)
plt.title('Tumor Sizes vs. Patient Ages')
plt.xlabel('Size (cm)')
plt.ylabel('Patient Age')
plt.grid(True)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()

location_counts = data['Location'].value_counts()
plt.figure(figsize=(8, 8))
plt.pie(location_counts, labels=location_counts.index, autopct='%1.1f%%', colors=sns.color_palette('pastel'))
plt.title('Distribution of Tumor Locations')
plt.axis('equal')
plt.show()
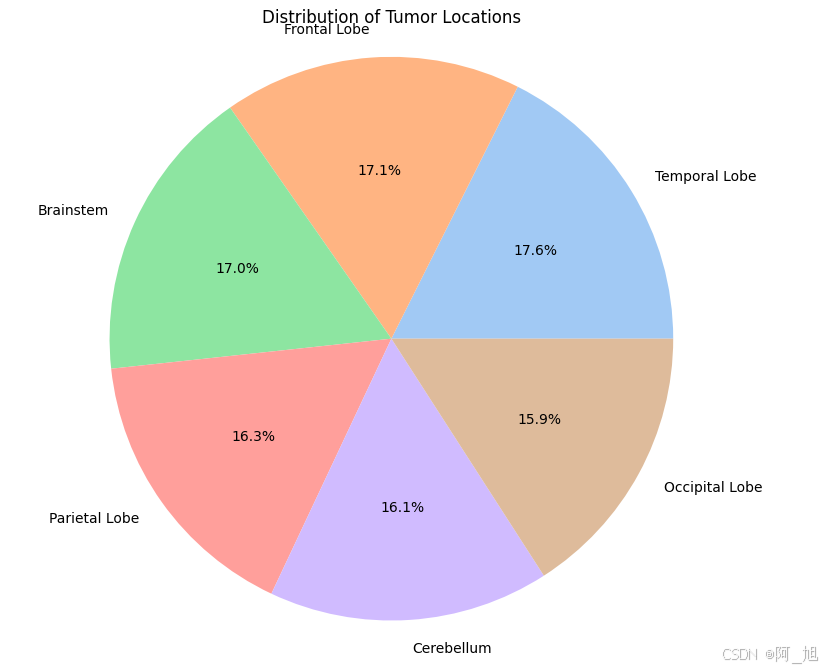
2.数据预处理
2.1 数据特征编码与on-hot处理
#Data Preprocessing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
import pandas as pddata['Gender'] = LabelEncoder().fit_transform(data['Gender']) # Encode Gender (0 for Female, 1 for Male)
data['Location'] = LabelEncoder().fit_transform(data['Location']) # Encode Location
data['Grade'] = LabelEncoder().fit_transform(data['Grade'])data['Tumor Type'] = LabelEncoder().fit_transform(data['Tumor Type']) # Encode Tumor Typecolumns = ['Gender','Location','Grade']
enc = OneHotEncoder()
# 将['Gender','Location','Grade']这3列进行独热编码
new_data = enc.fit_transform(data[columns]).toarray()
new_data.shape
(1000, 12)
data.head()
| Tumor Type | Location | Size (cm) | Grade | Patient Age | Gender | |
|---|---|---|---|---|---|---|
| 0 | 4 | 3 | 9.23 | 0 | 48 | 0 |
| 1 | 1 | 3 | 0.87 | 1 | 47 | 1 |
| 2 | 3 | 3 | 2.33 | 1 | 12 | 0 |
| 3 | 1 | 3 | 1.45 | 2 | 38 | 0 |
| 4 | 1 | 0 | 6.45 | 0 | 35 | 0 |
from sklearn.preprocessing import StandardScaler
# 1、实例化一个转换器类
transfer = StandardScaler()
# 2、调用fit_transform
data[['Size (cm)','Patient Age']] = transfer.fit_transform(data[['Size (cm)','Patient Age']])
old_data = data[['Tumor Type','Size (cm)','Patient Age']]
old_data.head()
one_hot_data = pd.DataFrame(new_data)
one_hot_data.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 3 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
final_data =pd.concat([old_data, one_hot_data], axis=1)
final_data.head()
| Tumor Type | Size (cm) | Patient Age | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 1.418484 | 0.179288 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 1 | 1 | -1.539861 | 0.139277 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2 | 3 | -1.023212 | -1.261097 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 3 | 1 | -1.334617 | -0.220819 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | 1 | 0.434728 | -0.340851 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
final_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 15 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 Tumor Type 1000 non-null int64 1 Size (cm) 1000 non-null float642 Patient Age 1000 non-null float643 0 1000 non-null float644 1 1000 non-null float645 2 1000 non-null float646 3 1000 non-null float647 4 1000 non-null float648 5 1000 non-null float649 6 1000 non-null float6410 7 1000 non-null float6411 8 1000 non-null float6412 9 1000 non-null float6413 10 1000 non-null float6414 11 1000 non-null float64
dtypes: float64(14), int64(1)
memory usage: 117.3 KB
3.模型训练与调优
3.1 数据划分
# Defining features and target
X = final_data.iloc[:,1:].values
y = final_data['Tumor Type'].values # Example target variable# Splitting data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train.shape
(800, 14)
3.2 模型训练调优
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report, accuracy_score, confusion_matrix
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCVparam_grid = {'C': [0.1, 1, 10, 100],'kernel': ['linear', 'poly', 'rbf', 'sigmoid'],'degree': [3, 5] # 仅对多项式核有效
}
grid_search = GridSearchCV(SVC(random_state=42), param_grid, cv=5, n_jobs=-1)
grid_search.fit(X_train, y_train)
best_params = grid_search.best_params_
print("Best Parameters from Grid Search:")
print(best_params)
Best Parameters from Grid Search:
{'C': 0.1, 'degree': 3, 'kernel': 'linear'}
3.3 模型评估
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)
print("Best Model Classification Report:")
print(classification_report(y_test, y_pred))
# Print Confusion Matrix
print(confusion_matrix(y_test, y_pred))
好了,这篇文章就介绍到这里,如果对你有帮助,感谢点赞关注!
相关文章:
【阿旭机器学习实战】【39】脑肿瘤数据分析与预测案例:数据分析、预处理、模型训练预测、评估
《------往期经典推荐------》 一、【100个深度学习实战项目】【链接】,持续更新~~ 二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~ 三、深度学习【Pytorch】专栏【链接】 四、【Stable Diffusion绘画系列】专…...

深度学习基础 - 梯度垂直于等高线的切线
深度学习基础 - 梯度垂直于等高线的切线 flyfish 梯度 给定一个标量函数 f ( x , y ) f(x, y) f(x,y),它的梯度(gradient)是一个向量,表示为 ∇ f ( x , y ) \nabla f(x, y) ∇f(x,y),定义为: ∇ f ( x…...

py2exe打包
要用到py2exe打包python程序,记录一下。 写一个setup.py文件,内容如下: from distutils.core import setup import py2exeoptions {"py2exe":{"compressed": 1, # 0或1 1压缩,0不压缩"optimize&quo…...

Gerrit存在两个未审核提交且这两个提交有冲突时的解决方案
Gerrit存在两个未审核提交且这两个提交有冲突时的解决方案 问题背景 用户A提交了一个记录,用户A的记录未审核此时用户B又提交了,这个时候管理员去合并代码,合了其中一个后再去合另一个发现合并不了,提示冲突,这个时候另…...

基于单片机的智能风扇设计
摘 要: 传统风扇无法根据周围环境的温度变化进行风速的调整,必须人为地干预才能达到需求 。 本文基于单片机的智能风扇主要解决以往风扇存在的问题,其有两种工作模式: 手动操作模式和自动运行模式,人们可以根据需要进行模式选择。 在自动运行…...

【实战】Spring Security Oauth2自定义授权模式接入手机验证
文章目录 前言技术积累Oauth2简介Oauth2的四种模式授权码模式简化模式密码模式客户端模式自定义模式 实战演示1、mavan依赖引入2、自定义手机用户3、自定义手机用户信息获取服务4、自定义认证令牌5、自定义授权模式6、自定义实际认证提供者7、认证服务配置8、Oauth2配置9、资源…...

Redis数据失效监听
一、配置Redis开启 打开conf/redis.conf 文件,添加参数:notify-keyspace-events Ex 二、验证配置 步骤一:进入redis客户端:redis-cli步骤二:执行 CONFIG GET notify-keyspace-events ,如果有返回值证明配…...

【达梦数据库】-SQL调优思路
【达梦数据库】-SQL调优思路 --查看统计信息是否准确 select table_name,num_rows,blocks,last_analyzed from user_tables where table_name表名; #默认每周六1点进行全库信息统计1、确认SQL --sql select * from test;2、查看ET ---------------------------------------…...

DispatcherServlet 源码分析
一.DispatcherServlet 源码分析 本文仅了解源码内容即可。 1.观察我们的服务启动⽇志: 当Tomcat启动之后, 有⼀个核⼼的类DispatcherServlet, 它来控制程序的执⾏顺序.所有请求都会先进到DispatcherServlet,执⾏doDispatch 调度⽅法. 如果有拦截器, 会先执⾏拦截器…...

代码随想录算法训练营第十八天| 530.二叉搜索树的最小绝对差 ● 501.二叉搜索树中的众数 ● 236. 二叉树的最近公共祖先
题目: 530. 二叉搜索树的最小绝对差 给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。 差值是一个正数,其数值等于两值之差的绝对值。 示例 1: 输入:root [4,2,6,1,3] 输出:…...
D卷(JavaPythonC++Node.jsC语言))
会议室占用的时间(75%用例)D卷(JavaPythonC++Node.jsC语言)
现有若干个会议,所有会议共享--个会议室,用数组表示各个会议的开始时间和结束时间,格式为: 会议1开始时间,会议1结束时间 会议2开始时间,会议2结束时间 请计算会议室占用时间段。 输入描述: 第一行输入一个整数 n,表示会议数量 之后输入n行,每行两个整数,以空格分隔,…...

C++初阶_1:namespace
本章详细解说:namespace 。 namespace: namespace,意为:命名空间,c的关键字(关键字,就是提示:取变量名,函数名时不能与之撞名)。 namespace的价值: 为了解…...

低代码开发平台:效率革命还是质量隐忧?
如何看待“低代码”开发平台的兴起? 近年来,“低代码”开发平台如雨后春笋般涌现,承诺让非专业人士也能快速构建应用程序。这种新兴技术正在挑战传统软件开发模式,引发了IT行业的广泛讨论。低代码平台是提高效率的利器࿰…...

在 Django 表单中传递自定义表单值到视图
在Django中,我们可以通过表单的初始化参数initial来传递自定义的初始值给表单字段。如果我们想要在视图中设置表单的初始值,可以在视图中创建表单的实例时,传递一个字典给initial参数。 1、问题背景 我们遇到了这样一个问题:在使…...

Android之复制文本(TextView)剪贴板
效果图: 功能简单就是点击“复制”,将邀请码复制到 剪贴板中 布局 <androidx.constraintlayout.widget.ConstraintLayoutandroid:id"id/clCode"android:layout_width"dimen/dp_0"android:layout_height"dimen/dp_49"…...

Ubuntu24.04设置国内镜像软件源
参考文章: Ubuntu24.04更换源地址(新版源更换方式) - 陌路寒暄 一、禁用原来的软件源 Ubuntu24.04 的源地址配置文件发生改变,不再使用以前的 sources.list 文件,升级 24.04 之后,该文件内容变成了一行注…...

分布式与微服务详解
1. 单机架构 只有一台机器,这个机器负责所有的工作 (这里假定一个电商网站) 现在大部分公司的产品都是单机架构 。 2. 分布式架构 一台机器的硬件资源是有限的,服务器处理请求是需要占用硬件资源的,如果业务增长&a…...

Vue设置滚动条自动保持到最底端
需求描述:在开发中我们常常会遇到需要让滚动条保持到最底端的需求,比如在开发一个聊天框时,请求接口拿到消息列表数据,展示到前端页面时,需要让滚动条自动滚到最底端,以此来展示最后的聊天记录。同时&#…...

uniapp创建一个新项目并导入uview-plus框架
近年来,随着技术的发展,人们越来越意识到跨平台和统一的重要性。对于同一款应用来说,一般都会有移动端、PC端、甚至小程序端。这是由于设备的不同,我们必须要做很多的客户端来满足不同的用户需求。但是由于硬件设施的不同…...
LabVIEW光电在线测振系统
开发了一种基于LabVIEW软件和光电技术的在线测振系统。该系统利用激光作为调制光源,并通过位置敏感型光电传感器(PSD)进行轴振动的实时检测。其主要特点包括非接触式测量、广泛的测量范围、高灵敏度和快速响应时间,且具备优良的抗…...

深度解析开源项目:NVIDIA Profile Inspector 完全指南与实战配置方案
深度解析开源项目:NVIDIA Profile Inspector 完全指南与实战配置方案 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector(NPI)是一款功能强大的…...

星露谷跨地域联机实战:基于FRP的低成本内网穿透方案
1. 为什么需要FRP内网穿透玩星露谷 星露谷物语作为一款支持多人联机的农场模拟游戏,和朋友一起种田钓鱼挖矿的乐趣远胜单人游玩。但官方服务器对国内玩家并不友好,经常出现高延迟甚至连接失败的情况。更头疼的是,当你想和异地好友联机时&…...

Element-UI表格避坑指南:修改展开图标+整行点击+智能隐藏,这些细节你知道吗?
Element-UI表格交互优化实战:图标定制与智能展开的进阶技巧 第一次使用Element-UI的Table组件时,我对着文档折腾了半天才让展开功能正常工作。但当我看到默认的小箭头图标时,总觉得和产品设计风格格格不入;点击展开区域太小导致用…...

Youtu-VL-4B-Instruct-GGUF助力开源社区:如何向GitHub提交高质量的模型使用案例
Youtu-VL-4B-Instruct-GGUF助力开源社区:如何向GitHub提交高质量的模型使用案例 1. 引言:从使用者到贡献者 不知道你有没有这样的经历:在网上找到一个看起来很酷的开源项目,兴致勃勃地打开它的GitHub页面,结果发现文…...

如何破解Godot游戏的黑盒:解密PCK文件中的资源宝藏
如何破解Godot游戏的黑盒:解密PCK文件中的资源宝藏 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 你是否曾好奇Godot游戏内部隐藏着怎样的资源结构?当面对那些看似神秘的.pc…...

ViPER4Windows-Patcher 音效修复工具:让无损音质在Windows 10/11完美呈现
ViPER4Windows-Patcher 音效修复工具:让无损音质在Windows 10/11完美呈现 【免费下载链接】ViPER4Windows-Patcher Patches for fix ViPER4Windows issues on Windows-10/11. 项目地址: https://gitcode.com/gh_mirrors/vi/ViPER4Windows-Patcher dz…...

【MobaXterm进阶】SSH连接稳定性优化:Keepalive与超时设置详解
1. 为什么SSH连接会频繁断开? 很多朋友在用MobaXterm远程连接服务器时都遇到过这样的困扰:明明连接得好好的,过一会儿就莫名其妙断开了。特别是当你正在执行一个耗时较长的任务时,突然中断简直让人抓狂。这种情况在家庭版用户中尤…...

G-Helper:轻量级华硕硬件控制的性能优化解决方案
G-Helper:轻量级华硕硬件控制的性能优化解决方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar, a…...

智能磁盘清理引擎:基于Windows Cleaner的系统空间优化解决方案
智能磁盘清理引擎:基于Windows Cleaner的系统空间优化解决方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 在数字化办公环境中,系统磁…...

重构时间选择体验:flatpickr的现代前端实践指南
重构时间选择体验:flatpickr的现代前端实践指南 【免费下载链接】flatpickr lightweight, powerful javascript datetimepicker with no dependencies 项目地址: https://gitcode.com/gh_mirrors/fl/flatpickr 问题引入:你的时间选择器是否还在制…...