【C++】5.类和对象(3)
文章目录
- 3.析构函数
- 析构函数的特点:
- 4.拷贝构造函数
- 拷贝构造的特点:
3.析构函数
析构函数与构造函数功能相反,析构函数不是完成对对象本身的销毁,比如局部对象是存在栈帧的,函数结束栈帧销毁,他就释放了,不需要我们管,C++规定对象在销毁时会自动调用析构函数,完成对象中资源的清理释放工作。析构函数的功能类比我们之前Stack实现的Destroy功能,而像Date没有Destroy,其实就是没有资源需要释放,所以严格说Date是不需要析构函数的。
析构函数的特点:
- 析构函数名是在类名前加上字符
~。- 无参数无返回值。 (这里跟构造类似,也不需要加
void)- 一个类只能有一个析构函数。若未显式定义,系统会自动生成默认的析构函数。
- 对象生命周期结束时,系统会自动调用析构函数。
- 跟构造函数类似,我们不写编译器自动生成的析构函数对内置类型成员不做处理,自定类型成员会调用他的析构函数。
- 还需要注意的是我们显示写析构函数,对于自定义类型成员也会调用他的析构,也就是说自定义类型成员无论什么情况都会自动调用析构函数。
- 如果类中没有申请资源时,析构函数可以不写,直接使用编译器生成的默认析构函数,如
Date;如果默认生成的析构就可以用,也就不需要显示写析构,如MyQueue;但是有资源申请时,一定要自己写析构,否则会造成资源泄漏,如Stack。- 一个局部域的多个对象,
C++规定后定义的先析构。
#include<iostream>
using namespace std;
typedef int STDataType;
class Stack
{public:Stack(int n = 4){_a = (STDataType*)malloc(sizeof(STDataType) * n);if (nullptr == _a){perror("malloc申请空间失败");return;}_capacity = n;_top = 0;}~Stack(){cout << "~Stack()" << endl;free(_a);_a = nullptr;_top = _capacity = 0;}private:STDataType* _a;size_t _capacity;size_t _top;
};
// 两个Stack实现队列
class MyQueue
{public://编译器默认生成MyQueue的析构函数调用了Stack的析构,释放的Stack内部的资源// 显示写析构,也会自动调用Stack的析构/*~MyQueue(){}*/private:Stack pushst;Stack popst;
};
int main()
{Stack st;MyQueue mq;return 0;
}
对比一下用C++和C实现的Stack解决之前括号匹配问题isValid,我们发现有了构造函数和析构函数确实方便了很多,不会再忘记调用Init和Destory函数了,也方便了不少。
#include<iostream>
using namespace std;
// 用最新加了构造和析构的C++版本Stack实现
bool isValid(const char* s) {Stack st;while (*s){if (*s == '[' || *s == '(' || *s == '{'){st.Push(*s);}else{// 右括号比左括号多,数量匹配问题if (st.Empty()){return false;}// 栈里面取左括号char top = st.Top();st.Pop();// 顺序不匹配if ((*s == ']' && top != '[')|| (*s == '}' && top != '{')|| (*s == ')' && top != '(')){return false;}}++s;}// 栈为空,返回真,说明数量都匹配 左括号多,右括号少匹配问题return st.Empty();
}
// 用之前C版本Stack实现
bool isValid(const char* s) {ST st;STInit(&st);while (*s){// 左括号入栈if (*s == '(' || *s == '[' || *s == '{'){STPush(&st, *s);}else // 右括号取栈顶左括号尝试匹配{if (STEmpty(&st)){STDestroy(&st);return false;}char top = STTop(&st);STPop(&st);// 不匹配if ((top == '(' && *s != ')')|| (top == '{' && *s != '}')|| (top == '[' && *s != ']')){STDestroy(&st);return false;}}++s;}// 栈不为空,说明左括号比右括号多,数量不匹配bool ret = STEmpty(&st);STDestroy(&st);return ret;
}
int main()
{cout << isValid("[()][]") << endl;cout << isValid("[(])[]") << endl;return 0;
}
/*
关于编译器自动生成的析构函数,是否会完成一些事情呢?下面的程序我们会看到,编译器
生成的默认析构函数,对自定类型成员调用它的析构函数。
*/
class Time
{
public:~Time(){cout << "~Time()" << endl;}
private:int _hour;int _minute;int _second;
};class Date
{
private:// 基本类型(内置类型)int _year = 1970;int _month = 1;int _day = 1;// 自定义类型Time _t;
};
int main()
{Date d;return 0;
}/*程序运行结束后输出:~Time()在main方法中根本没有直接创建Time类的对象,为什么最后会调用Time类的析构函数?因为:main方法中创建了Date对象d,而d中包含4个成员变量,其中_year, _month, _day三个是内置类型成员,销毁时不需要资源清理,最后系统直接将其内存回收即可;而_t是Time类对象,所以在d销毁时,要将其内部包含的Time类的_t对象销毁,所以要调用Time类的析构函数。但是:main函数中不能直接调用Time类的析构函数,实际要释放的是Date类对象,所以编译器会调用Date类的析构函数,而Date没有显式提供,则编译器会给Date类生成一个默认的析构函数,目的是在其内部调用Time类的析构函数,即当Date对象销毁时,要保证其内部每个自定义对象都可以正确销毁main函数中并没有直接调用Time类析构函数,而是显式调用编译器为Date类生成的默认析构函数注意:创建哪个类的对象则调用该类的析构函数,销毁那个类的对象则调用该类的析构函数
*//*
如果类中没有申请资源时,析构函数可以不写,直接使用编译器生成的默认析构函数,比如Date类;
有资源申请时,一定要写,否则会造成资源泄漏,比如Stack类。
*/
注意:
一般情况下,有动态申请的资源,就需要显示所写的析构函数,来释放资源。
例如:栈需要写析构
没有动态申请的资源,不需要写析构函数。因为没有资源需要释放。
例如:
class Data{ private:int _year;int _month;int _day;int _arr[100]; };需要释放资源的成员都是自定义类型,不需要写析构函数。
例如:
class MyQue{ private:Stack _pushst;Stack _popst; };因为默认生成的构造会自动调用默认构造函数
默认生成的析构会自动调用默认析构函数
4.拷贝构造函数
如果一个构造函数的第一个参数是自身类类型的引用,且任何额外的参数都有默认值,则此构造函数也叫做拷贝构造函数,也就是说拷贝构造是一个特殊的构造函数。
拷贝构造的特点:
- 拷贝构造函数是构造函数的一个重载。
- 拷贝构造函数的第一个参数必须是类类型对象的引用,使用传值方式编译器直接报错,因为语法逻辑上会引发无穷递归调用。 拷贝构造函数也可以多个参数,但是第一个参数必须是类类型对象的引用,后面的参数必须有缺省值。
C++规定自定义类型对象进行拷贝行为必须调用拷贝构造,所以这里自定义类型传值传参和传值返回都会调用拷贝构造完成。- 若未显式定义拷贝构造,编译器会生成自动生成拷贝构造函数。自动生成的拷贝构造对内置类型成员变量会完成值拷贝/浅拷贝(一个字节一个字节的拷贝),对自定义类型成员变量会调用他的拷贝构造。
- 像
Date这样的类成员变量全是内置类型且没有指向什么资源,编译器自动生成的拷贝构造就可以完成需要的拷贝,所以不需要我们显示实现拷贝构造。像Stack这样的类,虽然也都是内置类型,但是_a指向了资源,编译器自动生成的拷贝构造完成的值拷贝/浅拷贝不符合我们的需求,所以需要我们自己实现深拷贝(对指向的资源也进行拷贝)。像MyQueue这样的类型内部主要是自定义类型Stack成员,编译器自动生成的拷贝构造会调用Stack的拷贝构造,也不需要我们显示实现MyQueue的拷贝构造。这里还有一个小技巧,如果一个类显示实现了析构并释放资源,那么他就需要显示写拷贝构造,否则就不需要。- 传值返回会产生一个临时对象调用拷贝构造,传值引用返回,返回的是返回对象的别名(引用),没有产生拷贝。但是如果返回对象是一个当前函数局部域的局部对象,函数结束就销毁了,那么使用引用返回是有问题的,这时的引用相当于一个野引用,类似一个野指针一样。传引用返回可以减少拷贝,但是一定要确保返回对象,在当前函数结束后还在,才能用引用返回。
class Date
{
public:Date(int year = 1900, int month = 1, int day = 1){_year = year;_month = month;_day = day;}// d2(d1)//Date(Date& d);// 正确写法//拷贝构造函数Date(const Date& d){cout << "Date(Date& d)" << endl;//注意:_year = d._year;这个里面的_year不是private:里面的int _year;//_year = d._year;这个左边的_year是d2的_year,也就是this->_year,因为this指针是d2,也就是d2传给了this//右边的d._year是d,也就是d1的_year_year = d._year;_month = d._month;_day = d._day;/*d._year = _year;d._month = _month;d._day = _day;*/}
private:int _year;int _month;int _day;
};class MyQueue
{
private:/*Stack _pushst;Stack _popst;*/
};void func(int i){}void func(Date d) {}int main()
{// 可以不写,默认生成的拷贝构造就可以用Date d1(2023, 4, 25);Date d2(d1);//Data(Data& d)里面的d是d1的别名//this指针是d2,也就是d2传给了this//内置类型直接拷贝,void func(int i);//直接把4个字节的10拷贝给ifunc(10);//自定义类型的拷贝,规定了要定义拷贝构造去拷贝//void func(Date d){}会先调用Date(const Date& d);然后进入void func(Date d) //如果Date(const Date& d);改成了Date(Date d);那么就会出现无限递归,编译器会报错func(d1);// 必须自己实现,实现深拷贝/*Stack st1;Stack st2(st1);*/return 0;
}
警惕无穷递归!
class Date
{
public:Date(int year = 1900, int month = 1, int day = 1){_year = year;_month = month;_day = day;}Date(const Date& d);// 正确写法//Date(const Date& d) // 错误写法:编译报错,会引发无穷递归//{// _year = d._year;// _month = d._month;// _day = d._day;//}private:int _year;int _month;int _day;
};int main()
{Date d1;Date d2(d1);return 0;
}
1):内置类型成员完成值拷贝/浅拷贝
2):自定义类型成员会调用它的拷贝构造
自定义类型指向浅拷贝会出现两个问题:
析构两次,报错
一个函数修改会影响另一个函数
Data和MyQueue都不需要写。因为MyQueue里面会调用Stack,而Stack需要自己实现。Stack的实现和MyQueue无关。
Stack需要自己实现
class Stack
{
public:Stack(int capacity = 4){cout << "Stack()" << endl;_a = (int*)malloc(sizeof(int) * capacity);if (nullptr == _a){perror("malloc申请空间失败");return;}_capacity = capacity; _top = 0;}// st2(st1)Stack(const Stack& st){_a = (int*)malloc(sizeof(int) * st._capacity);if (nullptr == _a){perror("malloc申请空间失败");return;}memcpy(_a, st._a, sizeof(int) * st._top);_top = st._top;_capacity = st._capacity;}~Stack(){cout << "~Stack()" << endl;free(_a);_a = nullptr;_capacity = _top = 0;}private:int* _a = nullptr;int _top = 0;int _capacity;
};class Date
{
public:Date(int year = 1900, int month = 1, int day = 1){_year = year;_month = month;_day = day;}private:int _year;int _month;int _day;
};class MyQueue
{
private:Stack _pushst;Stack _popst;
};int main()
{//1):内置类型成员完成值拷贝/浅拷贝// 可以不写,默认生成的拷贝构造就可以用Date d1(2023, 4, 25);Date d2(d1);//Data(Data& d)里面的d是d1的别名//this指针是d2,也就是d2传给了this//2);自定义类型成员会调用它的拷贝构造//如果只传值,那么就会导致两个函数指向了同一个空间,析构函数调用的话就崩了// 而且就算不析构函数也会出问题。比如给其中一个函数赋值会影响另一个函数// 所以必须调用拷贝构造函数// 必须自己实现拷贝构造函数,实现深拷贝//栈后进先出,后创建的先析构,st2先析构,st1后析构//添加Stack(const Stack& st);前,会报错,因为st1和st2的析构函数指向了同一个空间,而一个空间无法释放两次//添加Stack(const Stack& st);后,不报错了//Stack(const Stack& st);就是我们自己实现的深拷贝Stack st1;Stack st2(st1);return 0;
}
注意:
在编译器生成的默认拷贝构造函数中,内置类型是按照字节方式直接拷贝的,而自定义类型是调用其拷贝构造函数完成拷贝的。
为了提高程序效率,一般对象传参时,尽量使用引用类型,返回时根据实际场景,能用引用尽量使用引用。
//这个采用引用返回是可以的,因为采用引用返回可以减少拷贝,而且函数结束后返回的值是没被销毁的
Stack& func1(){static Stack st;return st;
}
//这个采用引用返回是不可以的,因为函数结束后返回的值是被销毁了
Stack& func2(){Stack st;return st;
}int main(){func1();func2();return 0;
}
传引用返回要谨慎,传值引用没事
Stack& Func()
{static Stack st;//改成Stack st;就不行,因为Stack st;在Func()结束后就销毁了,就会导致拷贝构造传值错误st.Push(1);st.Push(2);st.Push(3);//...return st;
}int main()
{Stack ret = Func();cout << ret.Top() << endl;return 0;
}
class Date
{
public:Date(int year = 1, int month = 1, int day = 1){_year = year;_month = month;_day = day;}// Date d2(d1);//是拷贝构造/*Date(const Date& d){_year = d._year;_month = d._month;_day = d._day;}*/// 不是拷贝构造,就是一个普通构造//Date(Date* p)//{// _year = p->_year;// _month = p->_month;// _day = p->_day;//}//析构函数~Date(){cout << "~Date()" << endl;}
private:int _year;int _month;int _day;
};typedef int STDataType;
class Stack
{
public:Stack(int n = 4){_a = (STDataType*)malloc(sizeof(STDataType) * n);if (nullptr == _a){perror("malloc申请空间失败");return;}_capacity = n;_top = 0;}void Push(STDataType x){if (_top == _capacity){int newcapacity = _capacity * 2;STDataType* tmp = (STDataType*)realloc(_a, newcapacity *sizeof(STDataType));if (tmp == NULL){perror("realloc fail");return;}_a = tmp;_capacity = newcapacity;}_a[_top++] = x;}STDataType Top(){assert(_top > 0);return _a[_top - 1];}// st2(st1)Stack(const Stack& st){_a = (STDataType*)malloc(sizeof(STDataType) * st._capacity);if (nullptr == _a){perror("malloc申请空间失败");return;}memcpy(_a, st._a, sizeof(STDataType) * st._top);_top = st._top;_capacity = st._capacity;}~Stack(){cout << "~Stack()" << endl;free(_a);_a = nullptr;_top = _capacity = 0;}private:STDataType* _a;size_t _capacity;size_t _top;
};class MyQueue
{
public:
private:Stack pushst;Stack popst;
};void Func(Stack st){}void Func(int x){}Date f()
{Date ret;//...return ret;
}int main()
{Date d1(2024, 8, 9);//都是拷贝构造//自动生成的拷贝构造对内置类型成员变量会完成值拷贝 / 浅拷贝(一个字节一个字节的拷贝)Date d2(d1);Date d4 = d1;Date d5(f());Date d6 = f();//Satck不可以浅拷贝,因为Stack这里_a是一个指针,直接浅拷贝会导致两个指针指向同一块空间,析构就会崩溃Stack st1(10);Stack st2(st1);Func(st1);Func(1);MyQueue m1;MyQueue m2(m1);return 0;
}
这里就不调用拷贝构造了,因为这里是引用返回,不是传值返回
传值返回,返回的是值的拷贝,所以要调用拷贝构造
引用返回,返回的不是值的拷贝,返回的是它的别名,所以不调用拷贝构造
Date& operator=(const Date& d)//返回的是*this这个对象的别名,*this是d4 {if (this != &d)//以预防d1 = d1;的情况{_year = d._year;_month = d._month;_day = d._day;}return *this; }
相关文章:
)
【C++】5.类和对象(3)
文章目录 3.析构函数析构函数的特点: 4.拷贝构造函数拷贝构造的特点: 3.析构函数 析构函数与构造函数功能相反,析构函数不是完成对对象本身的销毁,比如局部对象是存在栈帧的,函数结束栈帧销毁,他就释放了&…...
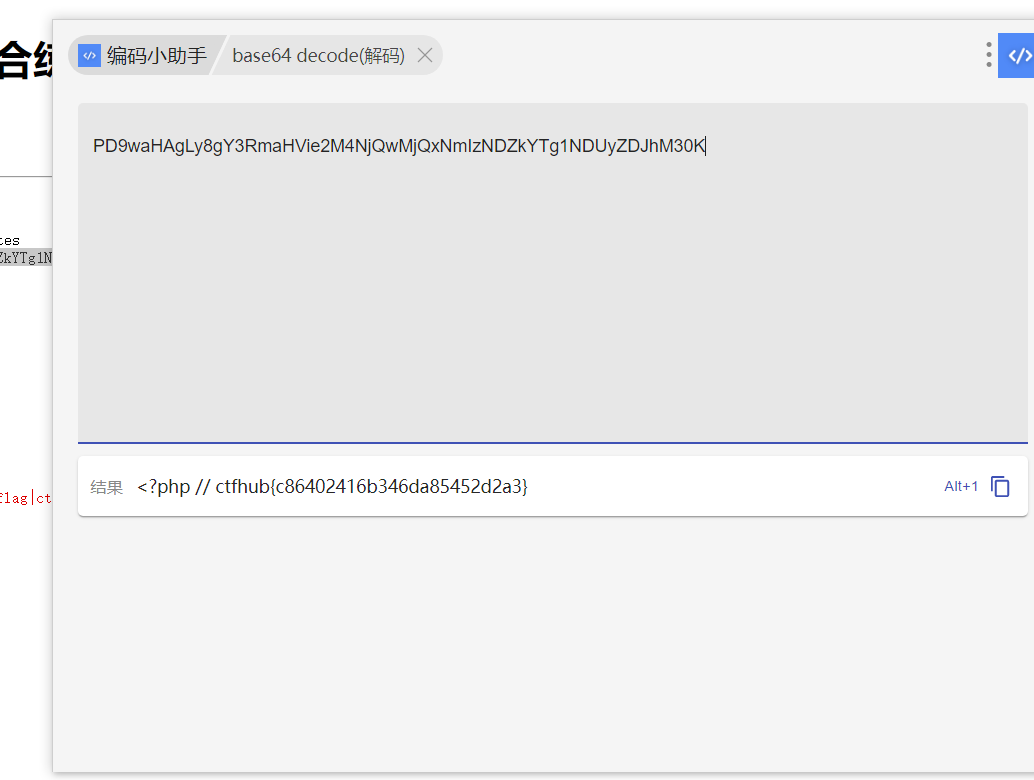
CTF-RCE
eval执行 ?cmdsystemctl("ls"); ?cmdsystemctl("ls /"); ?cmdsystemctl("cat /flag_27523); 命令注入 输入ip试试发先可以执行 127.0.0.1 查看一下看看有社么 127.0.0.1 | ls 试着看看php文件 127.0.0.1 | cat 297581345892.php 貌似这个文件有…...
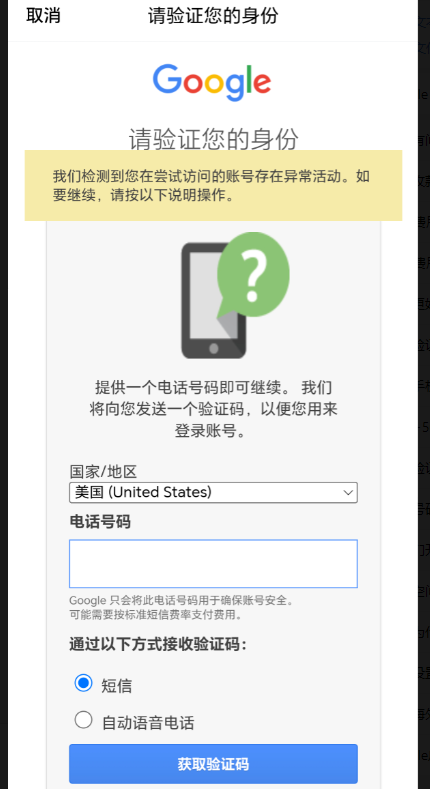
谷歌账号登录时,多次验证后变成“您的计算机或网络可能在发送自动查询内容”,原因分析和解决建议
最近有多个朋友联系GG账号服务,反馈说谷歌账号登录的时候,提示谷歌账号活动异常,需要输入手机号验证,但是自己的手机号无法验证,要不提示无法用于进行验证,要不提示用于验证的次数过多。 有一些朋友第一次遇…...

【SpringMVC】详细介绍SpringMVC的执行流程
目录 1. 概念 2.SpringMVC工作原理 3. springMVC的简单使用 1.在pom.xml中导入相关依赖 2.在web.xml中配置dispatcherServlet 3.创建springMVC.xml核心配置文件 4. SPringMVC分层后各个模块的作用 1. 概念 什么是MVC? MVC是下面三个组件的简写,模型…...

工地云SaaS系统,通过物联网与可视化等先进技术的综合应用,搭建的智慧工地管理云平台源码
通过物联网与可视化等先进技术的综合应用,搭建智慧工地管理云平台。以绿色、安全施工管理为主线,从人员、设备、环境、监控#度管理、施工管理、工程管理等多个维度对现场要素进行信息化,实现数据实时更新、人员精确管理、风险及时预警、管理便…...

使用自定义注解和AOP解决登录校验问题
1、如果每次都从Redis获取token,会有很多冗余代码 2、使用面向切面编程的思想 在不改变源代码或者很少改变源代码的情况下,增强类的某些方法。 在业务代码之前设置 切入点 创建切面类,也就是比如登录校验的某些公共方法 切面类从切入点切入流…...

【数据结构初阶】队列
hello! 目录 一、概念与结构 二、队列的实现 Queue.h Queue.c test.c 一、概念与结构 1、概念:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出的特性。 入队列:进行插入操作…...

《决胜B端 产品经理升级之路》 知识点总结
什么是b端产品? b端产品是指面向企业或组织的经营管理问题,旨在解决企业规模、成本、效率、品质和风控等方面的产品。这些产品主要帮助企业提高运营效率、降低成本、改善品质和控制风险等。b端产品适用于各种行业和企业类型,可以为企业带来深…...

2024年6月 青少年python一级等级考试真题试卷
202406 青少年软件编程等级考试Python一级真题 试卷总分数:100分 第 1 题 在使用turtle绘制图形时,如果要控制小海龟移动到 x 坐标为 200,y 坐标为150 的位置,以下代码能够实现效果的是?( ) …...
TCFormer:通过标记聚类Transformer实现视觉识别
摘要 Transformer在计算机视觉领域得到了广泛应用,并取得了显著成功。大多数最先进的方法将图像分割成规则网格,并用视觉标记表示每个网格区域。然而,固定的标记分布忽略了不同图像区域的语义含义,导致性能次优。为了解决这个问题…...

haproxy实现七层负载均衡详解(基本配置与算法)
目录 一、haproxy介绍 1.1 haproxy工作原理 1.2 相关配置类型 二、全局配置 2.1相关参数说明 2.2实验示例 实验环境: 2.2.1 设置多进程 2.2.2 设置日志显示 三、proxies代理配置 3.1 参数说明 3.2 default配置相关属性参数 3.2. 配置前端fronttend后端ba…...

海量日志数据收集监控平台应该怎么设计和实现
设计和实现一个海量日志数据收集和监控平台,需要考虑以下几个关键方面:数据采集、数据存储、实时处理、监控与告警、可视化分析、扩展性和高可用性。以下是一个详细的设计和实现方案: 1. 需求分析 日志来源:明确日志的来源&…...
-MFC-C/C++ - CSliderCtrl)
Windows图形界面(GUI)-MFC-C/C++ - CSliderCtrl
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 CSliderCtrl 创建滑动条 设置滑动条属性 成员函数 消息处理 注意事项 示例代码 CSliderCtrl 创建滑动条 在对话框编辑器中,从工具箱中拖拽一个Slider Control到对话框…...

常见中间件漏洞复现之【WebLogic】!
Weblogic介绍 WebLogic是美国Oracle公司出品的⼀个application server,确切的说是⼀个基于JAVAEE架构的中间件,默认端⼝:7001 WebLogic是⽤于开发、集成、部署和管理⼤型分布式Web应⽤、⽹络应⽤和数据库应⽤的Java应⽤服务器。将Java的动态…...

Linux服务器中限制远程IP登录的深入指南
在当今的数字化时代,Linux服务器的安全性是企业和个人用户不可忽视的重要方面。远程登录,尤其是通过SSH(Secure Shell)协议,是服务器管理中最常见的操作之一。然而,不限制远程登录的IP地址可能会暴露服务器…...

卫星通信中的拥塞控制算法
结论:现有的Cubic和BBR2算法可直接用于卫星通信网络的拥塞控制中,专为卫星设置的拥塞控制算法目前没有集成到系统中,但各自的性能表现需要根据实测情况进行取舍。 TCP Hybla...
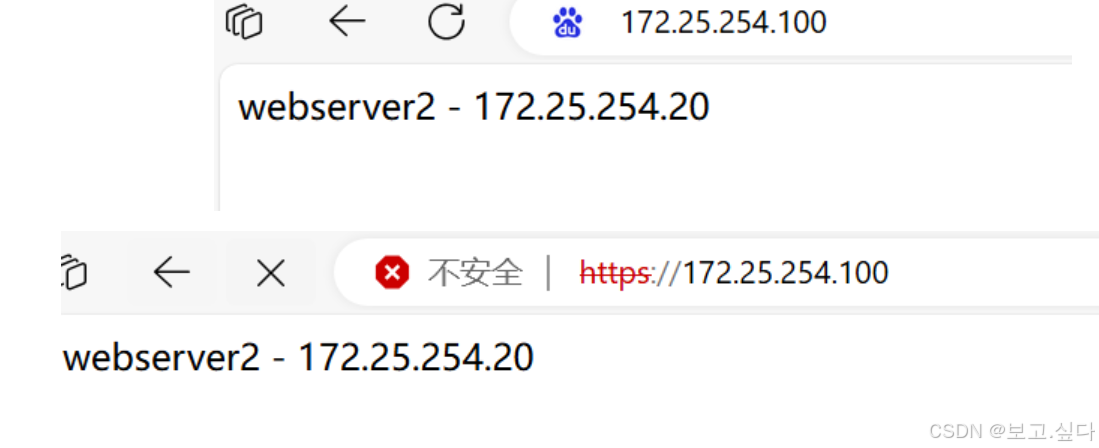
全网超详细haproxy七层代理
一:负载均衡 1、概念 负载均衡: Load Balance ,简称 LB ,是一种服务或基于硬件设备等实现的高可用反向代理技术, 负载均 衡将特定的业务(web 服务、网络流量等 ) 分担给指定的一个或多个后端特定的服务器或设 备&…...

Docker日志文件全局配置
这段配置是Docker容器的日志驱动配置,具体来说是json-file日志驱动的配置。这个配置的作用是定义容器日志文件的大小和数量限制。 {"log-driver": "json-file","log-opts": {"max-size": "500m","max-file…...

bia文件中码偏差对实时PPP解算分析
1. 码偏差对定位影响 码偏差对未知收敛时间有影响,对最终精度影响不大(权比1000:1)...
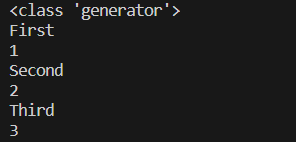
探索list与iterator的区别及yield的用法
1 问题 探索list与iterator的区别探索yield的用法 2 方法 通过网上学习后了解到 List返回的类型是list,list只会查询一级缓存。list()中返回的List中每个对象都是原本的对象。查询的时候没遍历一个对象会产生一条sql;而iterator这个迭代器返回的类型是it…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

PDF 可视化签名盖章页技术解析
本文是我在设备检测系统项目开发中,无设备检测的技术实现备忘录,记载实现过程。 本文以 PC 端页面 sign-pdf.vue 为主线,说明「无设备报检」在报告审批环节如何通过前后端协作,完成报告/记录 PDF 上的签名、印章、报告编号拖放定位,并在审批通过后由后端合并生成带签章的正…...

PCB虚焊/走线断裂/焊盘脱落工程师易漏判
PCB 故障中,30% 并非元件损坏,而是 PCB 本身的隐性故障—— 虚焊、走线断裂、焊盘脱落、过孔开路。这类故障外观隐蔽、时好时坏、排查难度大,很多工程师反复更换元件仍无法解决,最终误判为 “板报废”。一、PCB 隐性故障核心成因…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...
)
Claude端到端测试设计终极清单:覆盖17类非功能需求(含延迟敏感度分级、幻觉熔断阈值、多轮对话状态持久化验证)
更多请点击: https://kaifayun.com 第一章:Claude端到端测试设计的演进逻辑与核心范式 Claude端到端测试并非静态产物,而是随模型能力边界拓展、交互场景复杂化及可靠性要求升级而持续演化的工程实践。其演进逻辑根植于三个关键张力…...

通过Taotoken标准OpenAI协议实现分钟级集成现有代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken标准OpenAI协议实现分钟级集成现有代码 1. 迁移背景与核心思路 许多开发团队在构建AI应用时,会直接使用O…...

基于PGA2311的树莓派Hi-Fi模拟音量控制器设计与实现
1. 项目概述:为树莓派DAC打造的高品质模拟音量控制器玩过树莓派音频播放器的朋友都知道,用上像PCM1794A这类高性能DAC芯片后,音质确实能上一个台阶,但有个不大不小的麻烦:这类芯片本身不带音量控制。软件调音量&#x…...

数字合成器d-FORMANT:从模拟经典到数字复刻的工程实践
1. 项目概述:从模拟经典到数字复刻如果你对合成器稍有了解,或者对电子音乐制作背后的硬件感兴趣,那么“FORMANT”这个名字你一定不陌生。它最初是上世纪70年代由《Elektor》杂志发布的一款模拟单音合成器,以其清晰的模块化设计和出…...

告别繁琐审核!实测AI Agent如何重塑复杂非结构化票据与合同处理流程?
摘要:在企业数字化转型步入深水区的2026年,处理复杂非结构化票据与合同已成为横亘在财务、法务部门面前的“最后一公里”难题。传统RPA因UI变动易崩溃、主流智能体因缺乏API适配而无法落地,导致大量业务仍依赖低效的人工操作。本文由「企服AI…...