haproxy实现七层负载均衡详解(基本配置与算法)
目录
一、haproxy介绍
1.1 haproxy工作原理
1.2 相关配置类型
二、全局配置
2.1相关参数说明
2.2实验示例
实验环境:
2.2.1 设置多进程
2.2.2 设置日志显示
三、proxies代理配置
3.1 参数说明
3.2 default配置相关属性参数
3.2. 配置前端fronttend+后端backend
3.3 配置listen项
3.4 其他示例
3.4.1设置backup
3.4.2 redirect ---设定访问网页重定向
3.4.3 maxconn ----最大链接数
四、socat工具----热处理
4.1 相关配置
4.2 设置多进程
五、haproxy算法
5.1 静态算法
5.1.1 static-rr:基于权重的轮询调度
5.1.2 first
5.2 动态算法
5.2.1 roundrobin
5.2.2 leastconn---基于链接非权重
5.3 其他算法
5.3.1 source
5.3.1.1 map-base 取模法
5.3.1.2 一致性hash
5.3.2 uri
5.3.3 url_param
5.3.4 hdr
5.4 算法总结
使用场景
一、haproxy介绍
- 免费与开源:HAProxy作为一个免费的开源软件,提供了很多商业付费软件所具备的功能。
- 负载均衡能力:它支持L4 (TCP)和L7 (HTTP)两种负载均衡,能够根据不同需求进行选择。
- 会话保持:HAProxy能通过多种方式保持会话,例如基于客户端IP的Hash计算,或服务器发送的cookie。
- 虚拟主机支持:可以配置虚拟主机,以根据不同的域名或URL路径指向不同的后端服务器组。
- 高可用性:通过健康检查和状态监控,确保服务的持续性和可靠性。
- 多并发连接支持:HAProxy能够处理数以万计的并发连接,适用于大规模、高流量的网站和应用。
1.1 haproxy工作原理
其相关工作原理如下:

1.通过虚拟ur|或主机ip进行流量识别,根据应用层信息进行解析,决定是否需要进行负载均衡。
2.代理后台服务器与客户端建立连接,如nginx可代理前后端,与前端客户端tcp连接,与后端服务器建立tcp连接。
3.支持7层代理的软件:
Nginx:基于http协议(nginx七层是通过proxy_pass)
Haproxy:七层代理,会话保持、标记、路径转移等。
- 非阻塞事件驱动引擎:HAProxy内部使用一个高效的事件驱动机制,这使得它能够在高并发场景下表现出色。
- 数据面优化:专注于数据的快速转发,尽可能减少数据处理的层级,将大部分工作放在内核中完成。
- 连接处理流程:处理传入连接时,HAProxy遵循一系列步骤,包括接受连接、应用规则、传递到后端、做出负载均衡决策、处理响应等。
- 健康检查与信息交换:定期检查后端服务器的健康状态,并可与其他HAProxy节点交换信息,以实现集群内的协调。
1.2 相关配置类型
全局配置:主要是配置相关进程及安全配置相关的参数 ,性能调整相关参数,Debug参数
proxies:代理配置段
- defaults:为frontend, backend, listen提供默认配置。为前端和后端提供默认的配置参数,这些参数可以被后续级别的配置覆盖
- frontend:前端,相当于nginx中的server {}。定义了客户端请求的接收方式以及如何将请求转发至后端服务器组
- backend:后端,相当于nginx中的upstream {}。指定了实际服务器的相关配置,如服务器列表、负载均衡策略等
- listen:同时拥有前端和后端配置,配置简单,生产推荐使用
二、全局配置
2.1相关参数说明
| 参数 | 作用 |
| chroot | 锁定运行目录 |
| deamon | 以守护进程运行 |
| user, group, uid, gid | 运行 haproxy 的用户身份 |
| stats socket | 套接字文件 |
| nbproc N | 开启的 haproxy worker 进程数,默认进程数是一个 |
| nbthread 1 (和 nbproc 互斥) | 指定每个 haproxy 进程开启的线程数,默认为每个进程一个 线程 |
| cpu-map 1 0 | 绑定 haproxy worker 进程至指定 CPU ,将第 1 个 work进程绑定至 0 号 CPU |
| cpu-map 2 1 | 绑定 haproxy worker 进程至指定 CPU ,将第 2 个 work进程绑定至 1 号 CPU |
| maxconn N | 每个 haproxy 进程的最大并发连接数 |
| maxsslconn N | 每个 haproxy 进程 ssl 最大连接数 , 用于 haproxy配置了证书的场景下 |
| maxconnrate N | 每个进程每秒创建的最大连接数量 |
| spread-checks N | 后端 server 状态 check 随机提前或延迟百分比时间,建议2-5(20%-50%) 之间,默认值 0 |
| pidfile | 指定 pid 文件路径 |
| log 127.0.0.1 local2 info | 定义全局的 syslog 服务器;日志服务器需要开启 UDP协议, 最多可以定义两个 |
2.2实验示例
实验环境:
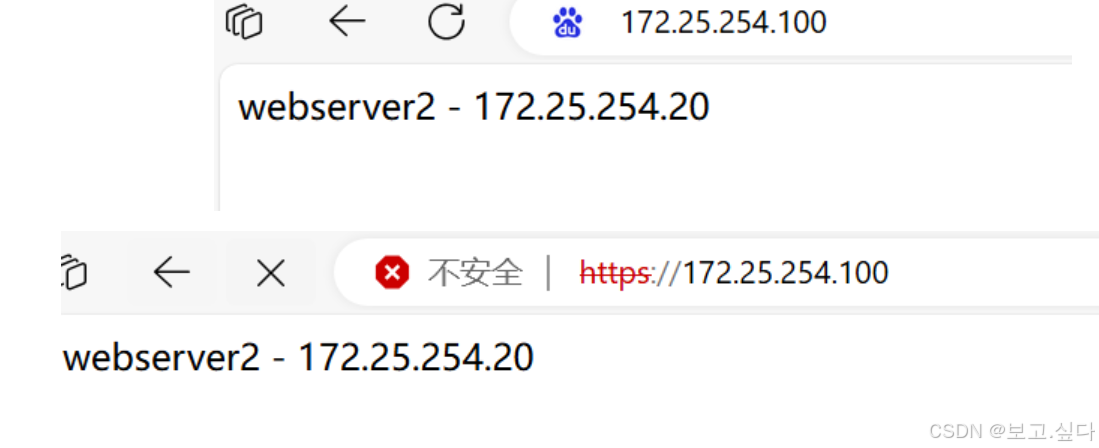
准备三台虚拟机,一台做haproxy负载配置,其他两台分别做web服务器配置。主机名分别设为haproxy(172.25.254.100),web1(172.25.254.10),web2(172.25.254.20)。相关实验环境配置如下,并且后面进行haproxy相关配置都是在此基础上
#web1和web2上配置nginx服务 [root@web1 ~]# dnf install nginx -y [root@web1 ~]# cat /usr/share/nginx/html/index.html webserver1-172.25.254.10 [root@web1 ~]# systemctl enable--now nginx[root@web2 ~]# dnf install nginx -y [root@web2 ~]# cat /usr/share/nginx/html/index.html webserver2-172.25.254.20 [root@web2 ~]# systemctl enable--now nginx#在haproxy上下载haproxy服务 [root@haproxy ~]# dnf install haproxy -y [root@haproxy ~]# systemctl enable--now haproxy
2.2.1 设置多进程
没设置之前先查看一下进程数:只有一个

设置我们是在配置文件里面设置:添加如下内容:
nbproc 2 # 启用多进程cpu-map 1 0 # 进程和 cpu 核心绑定防止 cpu 抖动从而减少系统资源消耗cpu-map 2 1 #2 表示第二个进程, 1 表示第二个 cpu 核心
就是如下图注意要在全局配置里面查看:
最后再查看一下进程数:就会有两个了

然后想要开启多线程就在后面添加 nbthread 2就行了,但是要注意其与多进程互斥,不能同时设置。 并且我们一般在企业中都是设置的多进程。
2.2.2 设置日志显示
在全局配置起日志作用的就是log 127.0.0.1 local2.如下图

这里我们需要在rsyslog配置文件中添加内容。------/etc/rsyslog.conf中添加


然后我们重启服务的时候就会自动报日志了。如下图 

三、proxies代理配置
3.1 参数说明
| 参数 | 作用 |
| defaults [] | 默认配置项,针对以下的 frontend 、 backend 和 listen生效,可以多个name 也可以没有 name |
| frontend | 前端 servername ,类似于 Nginx 的一个虚拟主机 server 和 LVS服务集 群 |
| backend | 后端服务器组,等于 nginx 的 upstream 和 LVS 中的 RS 服务器 |
| listen | 将 frontend 和 backend 合并在一起配置,相对于 frontend 和 backend 配置更简洁,生产常用 |
3.2 default配置相关属性参数
3.2. 配置前端fronttend+后端backend
在配置文件/etc/haproxy/haproxy.cfg里面写配置:
#在/etc/haproxy/haproxy.cfg里面添加
frontend webclusterbind *:80 #指定监听的地址mode httpuse_backend webcluster-host #调用backend名称backend webcluster-hostbalance roundrobinserver web1 172.25.254.10:80 #定义后端和端口real server 必须指定IPserver web2 172.25.254.20:80
其中后端配置的server项有有很多属性可供使用:
check #对指定real进行健康状态检查,如果不加此设置,默认不开启检查,只有check后面没有其它配置也可以启用检查功能#默认对相应的后端服务器IP和端口,利用TCP连接进行周期性健康性检查,注意必须指定 端口才能实现健康性检查addr <IP> #可指定的健康状态监测IP,可以是专门的数据网段,减少业务网络的流量port <num> #指定的健康状态监测端口inter <num> #健康状态检查间隔时间,默认2000 msfall <num> #后端服务器从线上转为线下的检查的连续失效次数,默认为3rise <num> #后端服务器从下线恢复上线的检查的连续有效次数,默认为2weight <weight> #默认为1,最大值为256,0(状态为蓝色)表示不参与负载均衡,但仍接受持久连接backup #将后端服务器标记为备份状态,只在所有非备份主机down机时提供服务,类似SorryServerdisabled #将后端服务器标记为不可用状态,即维护状态,除了持久模式#将不再接受连接,状态为深黄色,优雅下线,不再接受新用户的请求redirect prefix http://www.baidu.com/ #将请求临时(302)重定向至其它URL,只适用于http模式maxconn <maxconn> #当前后端server的最大并发连接数
重启后再查看:就实现了负载均衡

3.3 配置listen项
在配置文件/etc/haproxy/haproxy.cfg里面写配置:
#vim /etc/haproxy/haproxy.cfg添加listen webclusterbind *:80mode httpbalance roundrobinserver web1 172.25.254.10:80 check inter 2 fall 3 rise 5 weight 1 server web2 172.25.254.20:80 check inter 2 fall 3 rise 5 weight 1
重启测试查看:这个方法是将前后端合在一起的,其实现的效果和上面差不多

3.4 其他示例
3.4.1设置backup
在haproxy上面做:在httpd的配置文件里面将监听端口改成8080。

在配置文件中添加如下内容:
listen webclusterbind *:80mode httpbalance roundrobinserver web1 172.25.254.10:80 check inter 2 fall 3 rise 5 weight 1 server web2 172.25.254.20:80 check inter 2 fall 3 rise 5 weight 1server web_sorry 172.25.254.100:8080 backup
这个配置是当两台realserver出现故障时,才会起作用。
我们也可以server中添加disabled属性将real server设置为不能访问
3.4.2 redirect ---设定访问网页重定向
在配置文件中添加如下内容:将其重定向到百度上
redirect prefix http://www.baidu.com
listen webclusterbind *:80mode httpbalance roundrobinredirect prefix http://www.baidu.comserver web1 172.25.254.10:80 check inter 2 fall 3 rise 5 weight 1 server web2 172.25.254.20:80 check inter 2 fall 3 rise 5 weight 1server web_sorry 172.25.254.100:8080 backup3.4.3 maxconn ----最大链接数
在配置文件中添加如下内容: maxconn 2
超过最大链接数就会出现backup现象
listen webclusterbind *:80mode httpbalance roundrobinserver web1 172.25.254.10:80 maxconn 2 check inter 2 fall 3 rise 5 weight 1 server web2 172.25.254.20:80 check inter 2 fall 3 rise 5 weight 1server web_sorry 172.25.254.100:8080 backup四、socat工具----热处理
其是一种动态调整haproxy工作方式参数,在配置文件/etc/haproxy/haproxy.cfg中位置如下

配置文件修改后要重启。
4.1 相关配置
然后我们来下载socat工具,并且写一些命令配置:
#下载工具
[root@haproxy ~]# dnf install socat -y
#查看socat工具帮助
[root@haproxy ~]# echo "help" | socat stdio /var/lib/haproxy/stats#查看进程状态
[root@haproxy ~]# echo "show info" | socat stdio /var/lib/haproxy/stats#查看权重
[root@haproxy ~]# echo get weight webcluster/web1 | socat stdio /var/lib/haproxy/stats#修改权重
[root@haproxy ~]# echo "set weight webcluster/web1 1 " | socat stdio /var/lib/haproxy/stats#下线后端服务器
[root@haproxy ~]# echo "disable server webcluster/web1" | socat stdio /var/lib/haproxy/stats#上线后端服务器
[root@haproxy ~]# echo "enable server webcluster/web1" | socat stdio /var/lib/haproxy/stats4.2 设置多进程
如果开启多进程那么我们在对进程的sock文件进行操作时其对进程的操作时随机的
globallog 127.0.0.1 local2chroot /var/lib/haproxypidfile /var/run/haproxy.pidmaxconn 4000user haproxygroup haproxydaemon# turn on stats unix socket #添加这个设置多个进程文件stats socket /var/lib/haproxy/stats1 mode 600 level admin process 1stats socket /var/lib/haproxy/stats2 mode 600 level admin process 2# utilize system-wide crypto-policiesssl-default-bind-ciphers PROFILE=SYSTEMssl-default-server-ciphers PROFILE=SYSTEM #开启多进程nbproc 2cpu-map 1 0cpu-map 2 1重启服务,测试查看:
就会出现多个进程文件

五、haproxy算法
HAProxy 通过固定参数 balance 指明对后端服务器的调度算法balance 参数可以配置在 listen 或 backend 选项中。HAProxy 的调度算法分为静态和动态调度算法有些算法可以根据参数在静态和动态算法中相互转换。
5.1 静态算法
5.1.1 static-rr:基于权重的轮询调度
- 不支持运行时利用socat进行权重的动态调整(只支持0和1,不支持其它值)
- 不支持端服务器慢启动
- 其后端主机数量没有限制,相当于LVS中的 wrr
慢启动是指在服务器刚刚启动上不会把他所应该承担的访问压力全部给它,而是先给一部分,当没问题后在给一部分
在配置文件中 添加balance static-rr:
listen webclusterbind *:80mode http
#添加static-rrbalance static-rrserver web1 172.25.254.10:80 check inter 2 fall 3 rise 5 weight 1 server web2 172.25.254.20:80 check inter 2 fall 3 rise 5 weight 1server web_sorry 172.25.254.100:8080 backup5.1.2 first
- 根据服务器在列表中的位置,自上而下进行调度
- 其只会当第一台服务器的连接数达到上限,新请求才会分配给下一台服务
- 其会忽略服务器的权重设置
- 不支持用socat进行动态修改权重,可以设置0和1,可以设置其它值但无效
在配置文件中 添加balance first:
listen webclusterbind *:80mode http
#添加firstbalance firstserver web1 172.25.254.10:80 check inter 2 fall 3 rise 5 weight 1 server web2 172.25.254.20:80 check inter 2 fall 3 rise 5 weight 1server web_sorry 172.25.254.100:8080 backup最后用socat进行修改权重时,发现无法修改。
5.2 动态算法
动态算法就是
- 基于后端服务器状态进行调度适当调整,
- 新请求将优先调度至当前负载较低的服务器
- 权重可以在haproxy运行时动态调整无需重启
5.2.1 roundrobin
- 基于权重的轮询动态调度算法,
- 支持权重的运行时调整,不同于lvs中的rr轮训模式,
- HAProxy中的roundrobin支持慢启动(新加的服务器会逐渐增加转发数),
- 其每个后端backend中最多支持4095个real server,
- 支持对real server权重动态调整,
- roundrobin为默认调度算法,此算法使用广泛
listen webclusterbind *:80mode http
#添加roundrobinbalance roundrobinserver web1 172.25.254.10:80 check inter 2 fall 3 rise 5 weight 1 server web2 172.25.254.20:80 check inter 2 fall 3 rise 5 weight 1server web_sorry 172.25.254.100:8080 backup测试: 发现可以修改权重
[root@haproxy ~]# echo "set weight webcluster/web1 1 " | socat stdio /var/lib/haproxy/stats5.2.2 leastconn---基于链接非权重
- leastconn加权的最少连接的动态
- 支持权重的运行时调整和慢启动,即:根据当前连接最少的后端服务器而非权重进行优先调度(新客户端连接)
- 比较适合长连接的场景使用,比如:MySQL等场景。
listen webclusterbind *:80mode http
#添加leastconnbalance leastconnserver web1 172.25.254.10:80 check inter 2 fall 3 rise 5 weight 1 server web2 172.25.254.20:80 check inter 2 fall 3 rise 5 weight 1server web_sorry 172.25.254.100:8080 backup5.3 其他算法
5.3.1 source
源地址 hash ,基于用户源地址 hash并将请求转发到后端服务器,后续同一个源地址请求将被转发至同一 个后端 web服务器。此方式当后端服务器数据量发生变化时,会导致很多用户的请求转发至新的后端服务器,默认为静态方式,但是可以通过 hash-type 支持的选项更改这个算法一般是在不插入 Cookie 的TCP模式下使用,也可给拒绝会话 cookie 的客户提供最好的会话粘性,适用于 session会话保持但不支持 cookie和缓存的场景源地址有两种转发客户端请求到后端服务器的服务器选取计算方式,分别是取模法和一致性 hash
5.3.1.1 map-base 取模法
- map-based:取模法,对source地址进行hash计算,再基于服务器总权重的取模,最终结果决定将此请求转发至对应的后端服务器。
- 此方法是静态的,即不支持在线调整权重,不支持慢启动,可实现对后端服务器均衡调度
- 缺点是当服务器的总权重发生变化时,即有服务器上线或下线,都会因总权重发生变化而导致调度结果整体改变
所谓取模运算,就是计算两个数相除之后的余数, 10%7=3, 7%4=3map-based 算法:基于权重取模, hash(source_ip)% 所有后端服务器相加的总权重比如当源 hash 值时 1111 , 1112 , 1113 ,三台服务器 a b c 的权重均为 1 ,即 abc 的调度标签分别会被设定为 0 1 2 ( 1111%3=1 , 1112%3=2 , 1113%3=0 )1111 ----- > nodeb1112 ------> nodec1113 ------> nodea如果 a 下线后,权重数量发生变化1111%2=1 , 1112%2=0 , 1113%2=11112 和 1113 被调度到的主机都发生变化,这样会导致会话丢失
在配置文件中配置如下:
listen webclusterbind *:80mode http
#添加sourcebalance sourcehash-type map-baseserver web1 172.25.254.10:80 check inter 2 fall 3 rise 5 weight 1 server web2 172.25.254.20:80 check inter 2 fall 3 rise 5 weight 1server web_sorry 172.25.254.100:8080 backup测试:
#不支持动态调整权重值
[root@haproxy ~]# echo "set weight webserver_80/webserver1 2" | socat stdio
/var/lib/haproxy/haproxy.sock
Backend is using a static LB algorithm and only accepts weights '0%' and '100%'.
#只能动态上线和下线
[root@haproxy ~]# echo "set weight webserver_80/webserver1 0" | socat stdio
/var/lib/haproxy/haproxy.sock
[root@haproxy ~]# echo "get weight webserver_80/webserver1" | socat stdio
/var/lib/haproxy/haproxy.sock
0 (initial 1)5.3.1.2 一致性hash
一致性哈希,当服务器的总权重发生变化时,对调度结果影响是局部的,不会引起大的变动 hash ( o) mod n该 hash 算法是动态的,支持使用 socat 等工具进行在线权重调整,支持慢启动
具体算法:
- 后端服务器哈希环点keyA=hash(后端服务器虚拟ip)%(2^32)
- 客户机哈希环点key1=hash(client_ip)%(2^32) 得到的值在[0---4294967295]之间,
- 将keyA和key1都放在hash环上,将用户请求调度到离key1最近的keyA对应的后端服务器

会产生hash环偏斜问题:
通过增加虚拟服务器 IP 数量,比如:一个后端服务器根据权重为 1 生成 1000 个虚拟 IP ,再 hash。而后端服务器权重为 2 则生成 2000 的虚拟 IP ,再 bash, 最终在 hash 环上生成 3000 个节点,从而解决 hash 环偏斜问题。


listen webclusterbind *:80mode http
#添加sourcebalance sourcehash-type consistentserver web1 172.25.254.10:80 check inter 2 fall 3 rise 5 weight 1 server web2 172.25.254.20:80 check inter 2 fall 3 rise 5 weight 1server web_sorry 172.25.254.100:8080 backup5.3.2 uri
语法:
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>左半部分: /<path>;<params>整个 uri : /<path>;<params>?<query>#<frag>

uri取模法示例:
listen webclusterbind *:80mode httpbalance uriserver web1 172.25.254.10:80 check inter 2 fall 3 rise 5 weight 1 server web2 172.25.254.20:80 check inter 2 fall 3 rise 5 weight 1server web_sorry 172.25.254.100:8080 backup与hash一致性一起使用:
listen webclusterbind *:80mode httpbalance urihash-type consistentserver web1 172.25.254.10:80 check inter 2 fall 3 rise 5 weight 1 server web2 172.25.254.20:80 check inter 2 fall 3 rise 5 weight 1server web_sorry 172.25.254.100:8080 backup测试访问:创建不同的文件当作uri

[root@web1 ~]# curl 172.25.254.100/index2.html
172.25.254.20 ---index2.html
[root@web1 ~]# curl 172.25.254.100/index3.html
172.25.254.10 ---index3.html
[root@web1 ~]# curl 172.25.254.100/index1.html
172.25.254.20 ---index1.html5.3.3 url_param
url_param 对用户请求的 url 中的 params 部分中的一个参数 key 对应的 value 值作 hash计算,并由服务器 总权重相除以后派发至某挑出的服务器 ,后端搜索同一个数据会被调度到同一个服务器,多用与电商,通常用于追踪用户,以确保来自同一个用户的请求始终发往同一个real server如果无没 key ,将按 roundrobin 算法
配置如下:
haproxy ~]# vim /etc/haproxy/haproxy.cfg
#添加
listen webclusterbind 172.25.254.100:80mode httpbalance url_param name,userid #支持对多个url_param hashhash-type consistentserver web1 172.25.254.10:80 weight 1 check inter 3s fall 3 rise 5server web2 172.25.254.20:80 weight 1 check inter 3s fall 3 rise 5
测试:
[root@web1 ~]# curl 172.25.254.100/index1.html?name=lee
172.25.254.20 ---index1.html
[root@web1 ~]# curl 172.25.254.100/index1.html?name=lee
172.25.254.10 ---index1.html
[root@web1 ~]# curl 172.25.254.100/index1.html?name=test
172.25.254.20 ---index1.html
[root@web1 ~]# curl 172.25.254.100/index1.html?name=test
172.25.254.20 ---index1.html5.3.4 hdr
针对用户每个http头部(header)请求中的指定信息做hash,
此处由 name 指定的 http 首部将会被取出并做 hash计算,然后由服务器总权重取模以后派发至某挑出的服务器,如果无有效值,则会使用默认的轮询调度。
配置:
haproxy ~]# vim /etc/haproxy/haproxy.cfg
listen webclusterbind *:80mode httpbalance hdr(Usr-Agent)hash-type consistentserver web1 172.25.254.10:80 check inter 2 fall 3 rise 5 weight 1 server web2 172.25.254.20:80 check inter 2 fall 3 rise 5 weight 1server web_sorry 172.25.254.100:8080 backup测试
#测试查看
curl -v 172.25.254.100
curl -vA "firefox" 172.25.254.100
curl -vA "sougou" 172.25.254.1005.4 算法总结
#静态
static-rr--------->tcp/http
first------------->tcp/http
#动态
roundrobin-------->tcp/http
leastconn--------->tcp/http
#以下静态和动态取决于hash_type是否consistent
source------------>tcp/http
Uri--------------->http
url_param--------->http
hdr--------------->http使用场景
first #使用较少
static-rr #做了session共享的web集群
roundrobin
leastconn #数据库
source #基于客户端公网IP的会话保持
Uri--------------->http #缓存服务器,CDN服务商,蓝汛、百度、阿里云、腾讯
url_param--------->http #可以实现session保持
hdr #基于客户端请求报文头部做下一步处理相关文章:
haproxy实现七层负载均衡详解(基本配置与算法)
目录 一、haproxy介绍 1.1 haproxy工作原理 1.2 相关配置类型 二、全局配置 2.1相关参数说明 2.2实验示例 实验环境: 2.2.1 设置多进程 2.2.2 设置日志显示 三、proxies代理配置 3.1 参数说明 3.2 default配置相关属性参数 3.2. 配置前端fronttend后端ba…...

海量日志数据收集监控平台应该怎么设计和实现
设计和实现一个海量日志数据收集和监控平台,需要考虑以下几个关键方面:数据采集、数据存储、实时处理、监控与告警、可视化分析、扩展性和高可用性。以下是一个详细的设计和实现方案: 1. 需求分析 日志来源:明确日志的来源&…...
-MFC-C/C++ - CSliderCtrl)
Windows图形界面(GUI)-MFC-C/C++ - CSliderCtrl
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 CSliderCtrl 创建滑动条 设置滑动条属性 成员函数 消息处理 注意事项 示例代码 CSliderCtrl 创建滑动条 在对话框编辑器中,从工具箱中拖拽一个Slider Control到对话框…...

常见中间件漏洞复现之【WebLogic】!
Weblogic介绍 WebLogic是美国Oracle公司出品的⼀个application server,确切的说是⼀个基于JAVAEE架构的中间件,默认端⼝:7001 WebLogic是⽤于开发、集成、部署和管理⼤型分布式Web应⽤、⽹络应⽤和数据库应⽤的Java应⽤服务器。将Java的动态…...

Linux服务器中限制远程IP登录的深入指南
在当今的数字化时代,Linux服务器的安全性是企业和个人用户不可忽视的重要方面。远程登录,尤其是通过SSH(Secure Shell)协议,是服务器管理中最常见的操作之一。然而,不限制远程登录的IP地址可能会暴露服务器…...

卫星通信中的拥塞控制算法
结论:现有的Cubic和BBR2算法可直接用于卫星通信网络的拥塞控制中,专为卫星设置的拥塞控制算法目前没有集成到系统中,但各自的性能表现需要根据实测情况进行取舍。 TCP Hybla...
全网超详细haproxy七层代理
一:负载均衡 1、概念 负载均衡: Load Balance ,简称 LB ,是一种服务或基于硬件设备等实现的高可用反向代理技术, 负载均 衡将特定的业务(web 服务、网络流量等 ) 分担给指定的一个或多个后端特定的服务器或设 备&…...

Docker日志文件全局配置
这段配置是Docker容器的日志驱动配置,具体来说是json-file日志驱动的配置。这个配置的作用是定义容器日志文件的大小和数量限制。 {"log-driver": "json-file","log-opts": {"max-size": "500m","max-file…...

bia文件中码偏差对实时PPP解算分析
1. 码偏差对定位影响 码偏差对未知收敛时间有影响,对最终精度影响不大(权比1000:1)...
探索list与iterator的区别及yield的用法
1 问题 探索list与iterator的区别探索yield的用法 2 方法 通过网上学习后了解到 List返回的类型是list,list只会查询一级缓存。list()中返回的List中每个对象都是原本的对象。查询的时候没遍历一个对象会产生一条sql;而iterator这个迭代器返回的类型是it…...

github技巧和bug解决方法短篇收集
有一些几句话就可以说明白的观点或者解决的的问题,小虎单独收集到这里。 Commits没有算入每天的activity fork的仓库是不算的。 Commits made in a fork will not count toward your contributions. 参考: Contribution activity not shown for github…...

学习笔记五:在k8s中安装EFK组件(elasticsearch+fluentd+kibana)
在k8s 1.3安装EFK组件 前置条件上传压缩包安装nfs供应商创建nfs作为存储的供应商通过deployment创建pod用来运行nfs-provisioner 安装elasticsearch组件安装kibana组件安装fluentd组件 前置条件 查看k8s版本 kubectl get node -owide相关安装包 链接:https://pan.ba…...

Golang编译-如何忽略某些文件去编译
在 Go 语言中,编译好的二进制文件不会被再次加入到编译过程中。Go 编译器只会编译源代码文件(如 .go 文件),而不会将已经编译好的二进制文件(如可执行文件或静态库)作为输入来进行编译。 详细解释…...
有哪些适合中型企业的人力资源管理系统推荐?
本文主要介绍了以下几款人力资源管理系统:Moka、OrangeHRM、Verint、希沃人事、UKG Pro、大易Dayee、DingTalk、致远OA、卓望ShineHR、GoCo。 在选择人力资源管理系统时,中型企业面临着诸多挑战:如何确保系统既能满足现有需求,又能…...

活动回顾|首次 Cloudberry Database Meetup · 北京站成功举办
8 月 3 日,由酷克数据 HashData 主办的 Cloudberry Database Meetup 北京站活动圆满结束。本次 Meetup 以“以开源应对 Greenplum 闭源,原厂开发者再聚首”为主题,深入探讨了 Greenplum 闭源所带来的影响,并聚焦于 Cloudberry Dat…...

C语言 软件设计的七大原则,及其应用案例
1. 单一职责原则 (Single Responsibility Principle, SRP) 定义: 一个模块或函数应当只有一个引起变化的原因。 应用案例: 在嵌入式系统中,可以将传感器数据的读取和处理分开成不同的函数。例如: // 读取传感器数据的函数 floa…...

初学嵌入式-C语言常犯错误详解
1、对于下面这道题,估计有很多人会选择B答案,但其实答案是D 2.int a10, b9,c9,d; d b || (a>c),请问上述代码执行完毕后a b c d的值分别是 。 A、10 9 10 9 B、10 10 10 1 C、10 9 10 1 D、10 10 9 1 答案解释: 在C语言…...
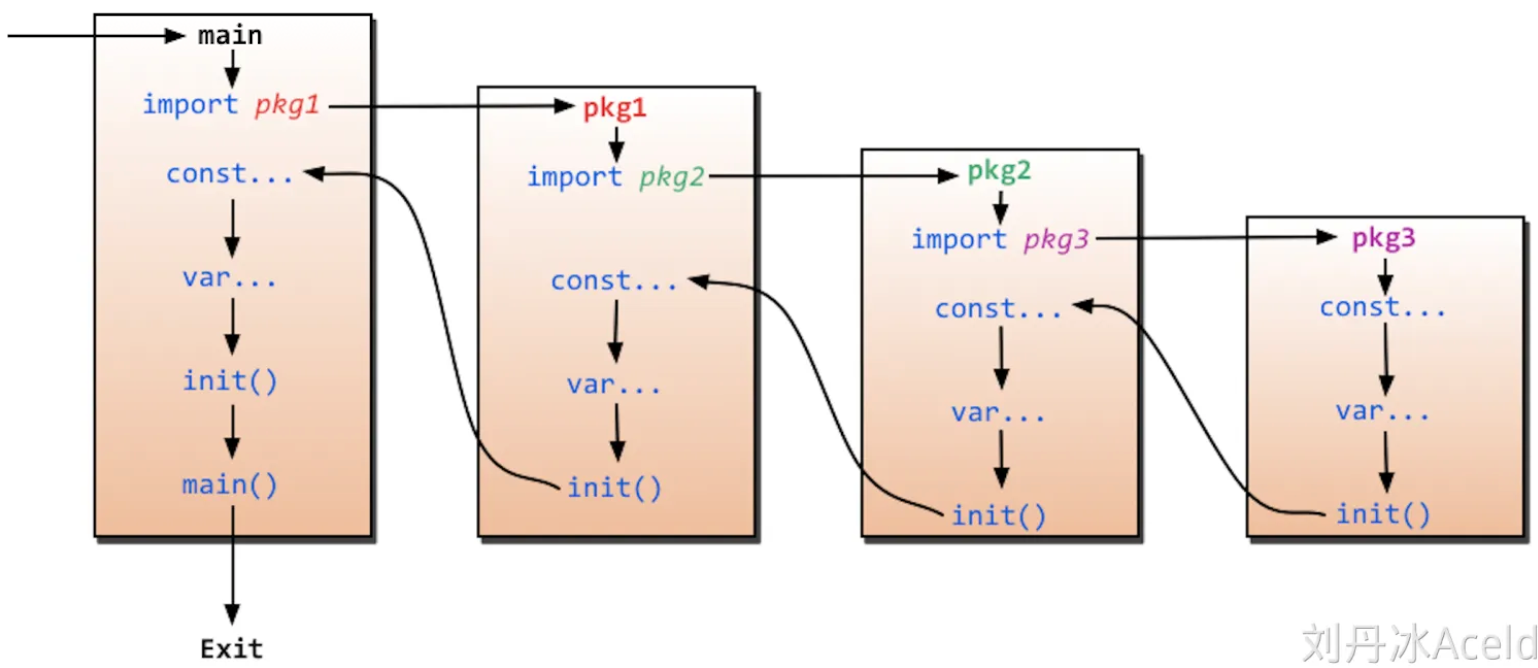
Golang 语法入门
Golang 语法入门 Hello World package mainimport "fmt"func main() {fmt.Println("hello world") }变量 package mainimport "fmt"// 全局变量 var ans 123 var cnt intfunc main() {// 单个局部变量a : 114514// 多个局部变量b, c : 114, …...

Filebeat+Kafka+ELK
架构: 部署: #配置nginx,部署filebeat systemctl stop firewalld setenforce 0 systemctl restart nginx#解压filebeat tar -xf filebeat-6.7.2-linux-x86_64.tar.gz mv filebeat-6.7.2-linux-x86_64 filebeat#日志收集 cd firebeat vim fil…...

Python 为Excel单元格设置填充\背景色 (纯色、渐变、图案)
在使用Excel进行数据处理和分析时,对特定单元格进行背景颜色填充不仅能够提升工作表的视觉吸引力,还能帮助用户快速识别和区分不同类别的数据,增强数据的可读性和理解性。 本文将通过以下三个示例详细介绍如何使用Python在Excel中设置不同的单…...
)
从一次生产事故复盘:我们如何优雅地处理用户上传的‘异常’Excel文件(附Apache POI配置详解)
从生产事故到防御体系:构建Excel文件处理的工程化解决方案那天凌晨2点,我被一阵急促的告警声惊醒。监控系统显示,核心文件处理服务的错误率在10分钟内飙升到35%,大量用户上传的Excel文件无法正常解析。更糟糕的是,部分…...

【DeepSeek-R1代码相似度引擎解密】:3层语义比对机制、Token归一化偏差修正与Jaccard阈值黄金分割点
更多请点击: https://kaifayun.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

AI赋能5G核心网故障诊断:从PCAP解析到智能根因分析的工程实践
1. 项目概述:当AI遇见5G核心网故障诊断在5G核心网的运维与测试一线干了这么多年,最头疼的莫过于面对海量的PCAP抓包文件。一个复杂的信令流程下来,动辄几千甚至上万个数据包,工程师需要像侦探一样,逐帧审视协议交互&am…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

如何进行TVA仿真引擎的“光照地狱”训练?
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制
InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制 【免费下载链接】InVideo 基于UE4实现的rtsp的视频播放插件 项目地址: https://gitcode.com/gh_mirrors/in/InVideo InVideo是一个基于Unreal Engine 5开发的RTSP视频播放插件࿰…...

Keil µVision反汇编窗口内容导出方案与调试技巧
1. 问题背景与需求解析在嵌入式开发过程中,调试环节往往占据大量时间。Keil Vision作为业界广泛使用的集成开发环境(IDE),其调试器功能强大但某些细节功能仍有提升空间。最近我在使用C251架构开发汽车电子控制单元时,就遇到了一个看似简单却影…...