学习笔记五:在k8s中安装EFK组件(elasticsearch+fluentd+kibana)
在k8s 1.3安装EFK组件
- 前置条件
- 上传压缩包
- 安装nfs供应商
- 创建nfs作为存储的供应商
- 通过deployment创建pod用来运行nfs-provisioner
- 安装elasticsearch组件
- 安装kibana组件
- 安装fluentd组件
前置条件
查看k8s版本
kubectl get node -owide

相关安装包
链接:https://pan.baidu.com/s/12S5lKEyzzwFwkCwzsPemHw?pwd=ycqx
提取码:ycqx
上传压缩包
把elasticsearch-7-12-1.tar.gz、fluentd-containerd.tar.gz、 kibana-7-12-1.tar.gz上传到k8snode1机器上,手动解压
ctr -n=k8s.io images import elasticsearch-7-12-1.tar.gz
ctr -n=k8s.io images import kibana-7-12-1.tar.gz
ctr -n=k8s.io images import fluentd-containerd.tar.gz
把nfs-subdir-external-provisioner.tar.gz上传到k8snode1上,手动解压。
ctr -n=k8s.io images import nfs-subdir-external-provisioner.tar.gz

把busybox-1-28.tar.gz上传到k8snode1节点,手动解压
ctr -n k8s.io images import busybox-1-28.tar.gz
把fluentd-containerd.tar.gz上传到k8smaster1机器上,手动解压
ctr -n=k8s.io images import fluentd-containerd.tar.gz
安装nfs供应商
两台服务器都执行
yum install nfs-utils -y
systemctl start nfs
systemctl enable nfs.service
在k8smaster1上创建一个nfs共享目录
mkdir /data/v1 -p
vim /etc/exports
/data/v1 *(rw,no_root_squash)
加载配置,使配置生效
exportfs -arv
systemctl restart nfs
创建nfs作为存储的供应商
创建运行nfs-provisioner需要的sa账号
cat serviceaccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:name: nfs-provisioner
kubectl apply -f serviceaccount.yaml
对sa授权
kubectl create clusterrolebinding nfs-provisioner-clusterrolebinding --clusterrole=cluster-admin --serviceaccount=default:nfs-provisioner

通过deployment创建pod用来运行nfs-provisioner
vim deployment.yaml
kind: Deployment
apiVersion: apps/v1
metadata:name: nfs-provisioner
spec:selector:matchLabels:app: nfs-provisionerreplicas: 1strategy:type: Recreatetemplate:metadata:labels:app: nfs-provisionerspec:serviceAccount: nfs-provisionercontainers:- name: nfs-provisionerimage: registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner:v4.0.0imagePullPolicy: IfNotPresentvolumeMounts:- name: nfs-client-rootmountPath: /persistentvolumesenv:- name: PROVISIONER_NAMEvalue: example.com/nfs- name: NFS_SERVERvalue: 192.168.40.120 #这个需要写nfs服务端所在的ip地址,需要写自己安装了nfs服务的机器ip- name: NFS_PATHvalue: /data/v1 #这个是nfs服务端共享的目录volumes:- name: nfs-client-rootnfs:server: 192.168.40.120 #这个需要写nfs服务端所在的ip地址,需要写自己安装了nfs服务的机器ippath: /data/v1
kubectl apply -f deployment.yaml
验证nfs是否创建成功
kubectl get pods | grep nfs

创建storageclass
vim class.yaml
class.yaml文件内容如下:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: do-block-storage
provisioner: example.com/nfs
注:provisioner: example.com/nfs
#该值需要和nfs provisioner配置的PROVISIONER_NAME处的value值保持一致

安装elasticsearch组件
下面安装步骤均在k8s控制节点操作:
创建kube-logging名称空间
在安装Elasticsearch集群之前,我们先创建一个名称空间,在这个名称空间下安装日志收工具elasticsearch、fluentd、kibana。
我们创建一个kube-logging名称空间,将EFK组件安装到该名称空间中。
vim kube-logging.yaml
kind: Namespace
apiVersion: v1
metadata:name: kube-logging
kubectl apply -f kube-logging.yaml
查看kube-logging名称空间是否创建成功
kubectl get namespaces | grep kube-logging
创建headless service
- 首先,我们需要部署一个有3个节点的Elasticsearch集群。我们使用3个Elasticsearch Pods可以避免高可用中的多节点群集中发生的“裂脑”的问题。 Elasticsearch脑裂可参考如下:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html#split-brain
- 在kube-logging名称空间定义了一个名为 elasticsearch 的 Service服务,带有app=elasticsearch标签,当我们将 Elasticsearch StatefulSet 与此服务关联时,服务将返回带有标签app=elasticsearch的 Elasticsearch Pods的DNS A记录,然后设置clusterIP=None,将该服务设置成无头服务。
- 最后,我们分别定义端口9200、9300,分别用于与 REST API 交互,以及用于节点间通信。
vim elasticsearch_svc.yaml
kind: Service
apiVersion: v1
metadata:name: elasticsearchnamespace: kube-logginglabels:app: elasticsearch
spec:selector:app: elasticsearchclusterIP: Noneports:- port: 9200name: rest- port: 9300name: inter-node
kubectl apply -f elasticsearch_svc.yaml
查看elasticsearch的service是否创建成功
kubectl get services --namespace=kube-logging

创建elasticsearch
现在我们已经为 Pod 设置了无头服务和一个稳定的域名.elasticsearch.kube-logging.svc.cluster.local
接下来我们通过 StatefulSet来创建具体的 Elasticsearch的Pod 应用
vim elasticsearch-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:name: es-clusternamespace: kube-logging
spec:serviceName: elasticsearchreplicas: 3selector:matchLabels:app: elasticsearchtemplate:metadata:labels:app: elasticsearchspec:containers:- name: elasticsearchimage: elasticsearch:7.12.1imagePullPolicy: IfNotPresentresources:limits:cpu: 1000mrequests:cpu: 100mports:- containerPort: 9200name: restprotocol: TCP- containerPort: 9300name: inter-nodeprotocol: TCPvolumeMounts:- name: datamountPath: /usr/share/elasticsearch/dataenv:- name: cluster.namevalue: k8s-logs- name: node.namevalueFrom:fieldRef:fieldPath: metadata.name- name: discovery.seed_hostsvalue: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"- name: cluster.initial_master_nodesvalue: "es-cluster-0,es-cluster-1,es-cluster-2"- name: ES_JAVA_OPTSvalue: "-Xms512m -Xmx512m"initContainers:- name: fix-permissionsimage: busybox:1.28imagePullPolicy: IfNotPresentcommand: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]securityContext:privileged: truevolumeMounts:- name: datamountPath: /usr/share/elasticsearch/data- name: increase-vm-max-mapimage: busybox:1.28imagePullPolicy: IfNotPresentcommand: ["sysctl", "-w", "vm.max_map_count=262144"]securityContext:privileged: true- name: increase-fd-ulimitimage: busybox:1.28imagePullPolicy: IfNotPresentcommand: ["sh", "-c", "ulimit -n 65536"]securityContext:privileged: truevolumeClaimTemplates: - metadata:name: datalabels:app: elasticsearchspec:accessModes: [ "ReadWriteOnce" ]storageClassName: do-block-storageresources:requests:storage: 10Gi
-
在statefulset中定义了pod,容器的名字是elasticsearch,镜像是docker.elastic.co/elasticsearch/elasticsearch:7.12.1
-
使用resources字段来指定容器至少需要0.1个vCPU,并且容器最多可以使用1个vCPU了解有关资源请求和限制,可参考https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/。
-
容器暴露了9200和9300两个端口,名称要和上面定义的 Service 保持一致,通过volumeMount声明了数据持久化目录,定义了一个data数据卷,通过volumeMount把它挂载到容器里的/usr/share/elasticsearch/data目录。
-
容器中设置了一些环境变量:
-
cluster.name:Elasticsearch 集群的名称,我们这里是 k8s-logs。
-
node.name:节点的名称,通过metadata.name来获取。这将解析为 es-cluster-[0,1,2],取决于节点的指定顺序。
-
discovery.seed_hosts:此字段用于设置在Elasticsearch集群中节点相互连接的发现方法,它为我们的集群指定了一个静态主机列表。
-
由于我们之前配置的是无头服务,我们的 Pod 具有唯一的 DNS 地址es-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local,因此我们相应地设置此地址变量即可。由于都在同一个 namespace 下面,所以我们可以将其缩短为es-cluster-[0,1,2].elasticsearch。
第一个名为 fix-permissions 的容器用来运行 chown 命令,将 Elasticsearch 数据目录的用户和组更改为1000:1000(Elasticsearch 用户的 UID)。因为默认情况下,Kubernetes 用 root 用户挂载数据目录,这会使得 Elasticsearch 无法访问该数据目录
第二个名为 increase-vm-max-map 的容器用来增加操作系统对mmap计数的限制,默认情况下该值可能太低,导致内存不足的错误
最后一个初始化容器是用来执行ulimit命令增加打开文件描述符的最大数量的。
我们这里使用 volumeClaimTemplates 来定义持久化模板,Kubernetes 会使用它为 Pod 创建 PersistentVolume,设置访问模式为ReadWriteOnce,这意味着它只能被 mount 到单个节点上进行读写,然后最重要的是使用了一个名为do-block-storage的 StorageClass 对象,所以我们需要提前创建该对象,我们这里使用的 NFS 作为存储后端,所以需要安装一个对应的nfs provisioner 驱动。
kubectl apply -f elasticsearch-statefulset.yaml
kubectl get pods -n kube-logging
kubectl get svc -n kube-logging

安装kibana组件
vim kibana.yaml
apiVersion: v1
kind: Service
metadata:name: kibananamespace: kube-logginglabels:app: kibana
spec:ports:- port: 5601selector:app: kibana
---
apiVersion: apps/v1
kind: Deployment
metadata:name: kibananamespace: kube-logginglabels:app: kibana
spec:replicas: 1selector:matchLabels:app: kibanatemplate:metadata:labels:app: kibanaspec:containers:- name: kibanaimage: kibana:7.12.1imagePullPolicy: IfNotPresentresources:limits:cpu: 1000mrequests:cpu: 100menv:- name: ELASTICSEARCH_URLvalue: http://elasticsearch:9200ports:- containerPort: 5601
kubectl apply -f kibana.yaml
kubectl get pods -n kube-logging
kubectl get svc -n kube-logging
修改service的type类型为NodePort:
kubectl edit svc kibana -n kube-logging
把type: ClusterIP变成type: NodePort

kubectl get svc -n kube-logging

kubectl get node -owide

通过上面获取到的节点IP,和服务端口
在浏览器中打开http://192.168.40.121:31692即可,如果看到如下欢迎界面证明 Kibana 已经成功部署到了Kubernetes集群之中。
安装fluentd组件
我们使用daemonset控制器部署fluentd组件,这样可以保证集群中的每个节点都可以运行同样fluentd的pod副本,这样就可以收集k8s集群中每个节点的日志
在k8s集群中,容器应用程序的输入输出日志会重定向到node节点里的json文件中,fluentd可以tail和过滤以及把日志转换成指定的格式发送到elasticsearch集群中。
除了容器日志,fluentd也可以采集kubelet、kube-proxy、docker的日志。
vim fluentd.yaml
apiVersion: v1
kind: ServiceAccount
metadata:name: fluentdnamespace: kube-logginglabels:app: fluentd
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: fluentdlabels:app: fluentd
rules:
- apiGroups:- ""resources:- pods- namespacesverbs:- get- list- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: fluentd
roleRef:kind: ClusterRolename: fluentdapiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccountname: fluentdnamespace: kube-logging
---
apiVersion: apps/v1
kind: DaemonSet
metadata:name: fluentdnamespace: kube-logginglabels:app: fluentd
spec:selector:matchLabels:app: fluentdtemplate:metadata:labels:app: fluentdspec:serviceAccount: fluentdserviceAccountName: fluentdtolerations:- key: node-role.kubernetes.io/control-planeeffect: NoSchedulecontainers:- name: fluentdimage: docker.io/fluent/fluentd-kubernetes-daemonset:v1.16-debian-elasticsearch7-1imagePullPolicy: IfNotPresentenv:- name: FLUENT_ELASTICSEARCH_HOSTvalue: "elasticsearch.kube-logging.svc.cluster.local"- name: FLUENT_ELASTICSEARCH_PORTvalue: "9200"- name: FLUENT_ELASTICSEARCH_SCHEMEvalue: "http"- name: FLUENTD_SYSTEMD_CONFvalue: disable- name: FLUENT_CONTAINER_TAIL_PARSER_TYPEvalue: "cri"- name: FLUENT_CONTAINER_TAIL_PARSER_TIME_FORMATvalue: "%Y-%m-%dT%H:%M:%S.%L%z"resources:limits:memory: 512Mirequests:cpu: 100mmemory: 200MivolumeMounts:- name: varlogmountPath: /var/log- name: containersmountPath: /var/log/containersreadOnly: trueterminationGracePeriodSeconds: 30volumes:- name: varloghostPath:path: /var/log- name: containershostPath:path: /var/log/containers
kubectl apply -f fluentd.yaml
kubectl get pods -n kube-logging -owide

Fluentd 启动成功后,我们可以前往 Kibana 的 Dashboard 页面中,点击左侧的Discover,可以看到如下配置页面:

在这里可以配置我们需要的 Elasticsearch 索引,前面 Fluentd 配置文件中我们采集的日志使用的是 logstash 格式
这里只需要在文本框中输入logstash-*即可匹配到 Elasticsearch 集群中的所有日志数据,然后点击下一步,进入以下页面:

logstash-*

点击next step,出现如下
选择@timestamp,创建索引

点击左侧的discover,可看到如下:

测试收集pod容器日志
vim pod.yaml
apiVersion: v1
kind: Pod
metadata:name: counter
spec:containers:- name: countimage: busybox:1.28imagePullPolicy: IfNotPresentargs: [/bin/sh, -c,'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
kubectl apply -f pod.yaml
登录到kibana的控制面板,在discover处的搜索栏中输入kubernetes.pod_name:counter,这将过滤名为的Pod的日志数据counter,如下所示:
kubernetes.pod_name:counter

相关文章:
学习笔记五:在k8s中安装EFK组件(elasticsearch+fluentd+kibana)
在k8s 1.3安装EFK组件 前置条件上传压缩包安装nfs供应商创建nfs作为存储的供应商通过deployment创建pod用来运行nfs-provisioner 安装elasticsearch组件安装kibana组件安装fluentd组件 前置条件 查看k8s版本 kubectl get node -owide相关安装包 链接:https://pan.ba…...

Golang编译-如何忽略某些文件去编译
在 Go 语言中,编译好的二进制文件不会被再次加入到编译过程中。Go 编译器只会编译源代码文件(如 .go 文件),而不会将已经编译好的二进制文件(如可执行文件或静态库)作为输入来进行编译。 详细解释…...
有哪些适合中型企业的人力资源管理系统推荐?
本文主要介绍了以下几款人力资源管理系统:Moka、OrangeHRM、Verint、希沃人事、UKG Pro、大易Dayee、DingTalk、致远OA、卓望ShineHR、GoCo。 在选择人力资源管理系统时,中型企业面临着诸多挑战:如何确保系统既能满足现有需求,又能…...

活动回顾|首次 Cloudberry Database Meetup · 北京站成功举办
8 月 3 日,由酷克数据 HashData 主办的 Cloudberry Database Meetup 北京站活动圆满结束。本次 Meetup 以“以开源应对 Greenplum 闭源,原厂开发者再聚首”为主题,深入探讨了 Greenplum 闭源所带来的影响,并聚焦于 Cloudberry Dat…...

C语言 软件设计的七大原则,及其应用案例
1. 单一职责原则 (Single Responsibility Principle, SRP) 定义: 一个模块或函数应当只有一个引起变化的原因。 应用案例: 在嵌入式系统中,可以将传感器数据的读取和处理分开成不同的函数。例如: // 读取传感器数据的函数 floa…...

初学嵌入式-C语言常犯错误详解
1、对于下面这道题,估计有很多人会选择B答案,但其实答案是D 2.int a10, b9,c9,d; d b || (a>c),请问上述代码执行完毕后a b c d的值分别是 。 A、10 9 10 9 B、10 10 10 1 C、10 9 10 1 D、10 10 9 1 答案解释: 在C语言…...
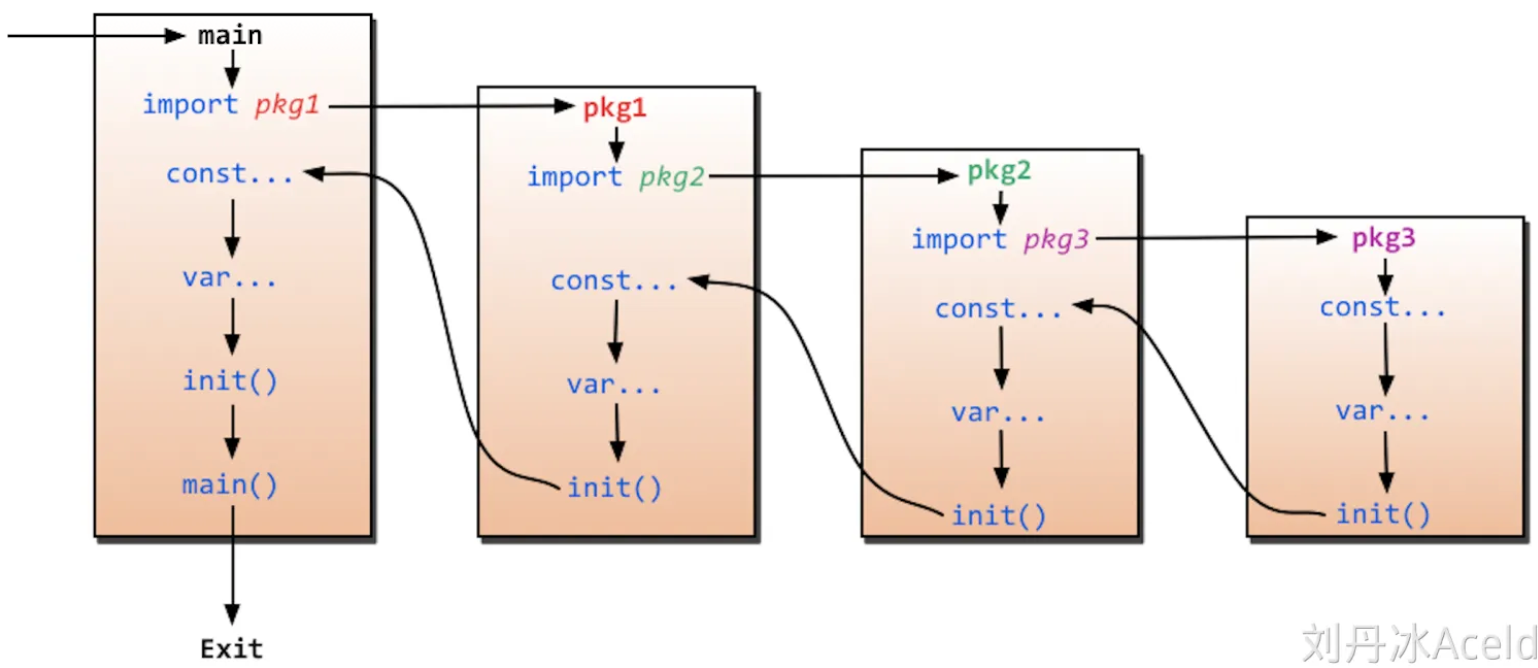
Golang 语法入门
Golang 语法入门 Hello World package mainimport "fmt"func main() {fmt.Println("hello world") }变量 package mainimport "fmt"// 全局变量 var ans 123 var cnt intfunc main() {// 单个局部变量a : 114514// 多个局部变量b, c : 114, …...

Filebeat+Kafka+ELK
架构: 部署: #配置nginx,部署filebeat systemctl stop firewalld setenforce 0 systemctl restart nginx#解压filebeat tar -xf filebeat-6.7.2-linux-x86_64.tar.gz mv filebeat-6.7.2-linux-x86_64 filebeat#日志收集 cd firebeat vim fil…...

Python 为Excel单元格设置填充\背景色 (纯色、渐变、图案)
在使用Excel进行数据处理和分析时,对特定单元格进行背景颜色填充不仅能够提升工作表的视觉吸引力,还能帮助用户快速识别和区分不同类别的数据,增强数据的可读性和理解性。 本文将通过以下三个示例详细介绍如何使用Python在Excel中设置不同的单…...

家里浮毛粉尘到处飞?宠物空气净化器出动帮你解决
由于家里收养的十几只流浪猫咪夏季掉毛非常严重,整个房子弥漫着猫毛,而且这十几只里面有七八只还是长毛的品种,掉落的毛发都因为太长而直接掉落成毛团,而短毛的那几只也在掉毛,这十几只掉下的浮毛,家里已经…...

计算机网络ISO七层网络模型及TCP
思维导图(通俗理解) 首先,先用最通俗的话来描述ISO七层模型,思维导图结构如下: ISO七层网络模型概念 应用层(Application Layer):应用层是OSI模型的最高层,直接与用户交…...

机器学习知识点全面总结
一、机器学习基础概念 1、什么是机器学习 机器学习是一种人工智能技术,通过对数据的学习和分析,让计算机系统自动提高其性能。简而言之,机器学习是一种从数据中学习规律和模式的方法,通过数据来预测、分类或者决策。 机器学习的本…...

【研发日记】嵌入式处理器技能解锁(三)——TI C2000 DSP的C28x内核
文章目录 前言 背景介绍 C28x内核 浮点单元(FPU) 快速整数除法单元(FINTDIV) 三角数学单元(TMU) VCRC单元 CPU总线 指令流水线 总结 参考资料 前言 见《【研发日记】嵌入式处理器技能解锁(一)——多任务异步执行调度的三种方法》 见《【研发日记】嵌入式处理器技能解…...

LeetCode.27.移除元素
题目描述: 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素。元素的顺序可能发生改变。然后返回 nums 中与 val 不同的元素的数量。 假设 nums 中不等于 val 的元素数量为 k,要通过此题,您需要执行以…...
可重入锁总结)
redis面试(十二)可重入锁总结
可重入锁总结 从实现原理以及源码的层面,真正剖析和了解到了redis分布式锁的企业级的实现,这个分布式锁实现的还是非常漂亮的,麻雀虽小,五脏俱全,分布式的可重入锁,总结一下流程 (1࿰…...

软件测试知识点3
063、一份测试计划应该包括哪些内容? 背景、项目简介、目的、测试范围、测试策略、人员分工、资源要求、进度计划、参考文档、常用术语、提交文档、风险分析。 065、如何定位测试用例的作用? 组织性:编写、组织性、功能覆盖、重复性、跟踪、测试确认 066、什么…...

WPF Treeview开启虚拟化后如何找到TreeViewItem
用VirtualizingStackPanel的BringIndexIntoViewPublic方法就好,没必要像微软给的例子那样还要继承一个VirtualizingStackPanel /// <summary> /// Recursively search for an item in this subtree. /// </summary> /// <param name"container…...

给python初学者的一些建议
写在开篇 关于Python,可以这么说,这几年借着数据科学、机器学习与人工智能的东风,Python 老树开新花,在风口浪尖上居高不下。 Python 之所以这么受大家的青睐,是因为它语言简洁,上手容易,让非…...

【Python学习手册(第四版)】学习笔记17-作用域
个人总结难免疏漏,请多包涵。更多内容请查看原文。本文以及学习笔记系列仅用于个人学习、研究交流。 本文介绍Python作用域,介绍了变量名解析的LEGB原则,以及内置作用域,全局作用域global语句,嵌套作用域及nonlocal语…...

大语言模型(LLM)文本预处理实战
大语言模型(LLM)文本预处理实战 文章目录 大语言模型(LLM)文本预处理实战2.1 理解词嵌入2.2 文本分词2.3 将 token 转换为 token ID2.4 添加特殊上下文 token2.5 字节对编码 (BytePair Encoding, BPE)2.6 使用滑动窗口进行数据采样…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...

DMA-330地址空间限制与扩展方案解析
1. DMA-330地址空间限制解析DMA-330作为Arm CoreLink系列中的直接内存访问控制器,其物理寻址能力直接由AxADDR信号宽度决定。这个32位地址总线宽度意味着它原生仅支持4GB(2^32字节)的物理地址空间访问。在实际嵌入式系统设计中,这…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南
终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否渴望享受WeMod Pro会员的所…...