Efficient-KAN 源码详解
Efficient-KAN源码链接
Efficient-KAN (GitHub)
改进细节
1.内存效率提升
KAN网络的原始实现的性能问题主要在于它需要扩展所有中间变量以执行不同的激活函数。对于具有in_features个输入和out_features个输出的层,原始实现需要将输入扩展为shape为(batch_size, out_features, in_features)的tensor以执行激活函数。然而,所有激活函数都是一组固定基函数(3阶B样条)的线性组合。鉴于此,拟将计算重新表述为不同的基函数激活输入,然后将它们线性组合。这种重新表述可以显著减少内存消耗,并使计算变得更加简单的矩阵乘法,自然地适用于前向和后向传递。
2.正则化方法的改变
稀疏化被认为对KAN的可解释性至关重要。作者提出了一种定义在输入样本上的L1正则化,它需要对**(batch_size, out_features, in_features)** tensor进行非线性操作,因此与重新表述不兼容。拟改为对权重进行L1正则化,这在NN中更为常见,并且与重新表述兼容。
3.激活函数缩放选项
除了可学习的激活函数(B样条),原始实现还包括对每个激活函数的可学习缩放 ( w s ) (w_s) (ws)。拟提供一个名为enable_standalone_scale_spline的选项,默认情况下为True,以包含此功能。禁用它会使模型更高效,但可能会影响结果。这需要更多实验验证。
4.参数初始化的改变
为了解决在MNIST数据集上的性能问题,该代码修改了参数的初始化方式,采用Kaiming初始化。
KAN_fast.py解析
基本参数和类定义
import torch
import torch.nn.functional as F
import mathclass KANLinear(torch.nn.Module):def __init__(self,in_features,out_features,grid_size=5, # 网格大小,默认为 5spline_order=3, # 分段多项式的阶数,默认为 3scale_noise=0.1, # 缩放噪声,默认为 0.1scale_base=1.0, # 基础缩放,默认为 1.0scale_spline=1.0, # 分段多项式的缩放,默认为 1.0enable_standalone_scale_spline=True,base_activation=torch.nn.SiLU, # 基础激活函数,默认为 SiLU(Sigmoid Linear Unit)grid_eps=0.02,grid_range=[-1, 1], # 网格范围,默认为 [-1, 1]):super(KANLinear, self).__init__()self.in_features = in_featuresself.out_features = out_featuresself.grid_size = grid_size # 设置网格大小和分段多项式的阶数self.spline_order = spline_orderh = (grid_range[1] - grid_range[0]) / grid_size # 计算网格步长
生成网格
grid = ( # 生成网格(torch.arange(-spline_order, grid_size + spline_order + 1) * h+ grid_range[0] ).expand(in_features, -1).contiguous())
self.register_buffer("grid", grid) # 将网格作为缓冲区注册
1. torch.arange(-spline_order, grid_size + spline_order + 1)
**torch.arange(start, end)**:生成一个从start到end-1的整数序列(左闭右开区间)。**-spline_order**:从负的spline_order开始。**grid_size + spline_order + 1**:终止于grid_size + spline_order(不包括+1)。
这个序列的长度是 grid_size + 2 * spline_order + 1,用于涵盖所有需要的网格点,包括两端的扩展区域。
2. * h
- 这一步将生成的整数序列乘以步长
h,将索引序列转换为实际的网格位置。
3. + grid_range[0]
- 这一步将整个网格位置进行平移,使得网格的起始点与
grid_range[0]对齐。
如果 grid_range[0] = -1,则每个位置都会减去 1
4. .expand(in_features, -1)
**.expand()**:将这个网格复制in_features次,以适应输入特征的维度。具体来说,它将原本的一维网格向量扩展成一个in_features×(grid_size + 2 * spline_order + 1)的二维张量。 其中每一行都是相同的网格向量。
5. .contiguous()
**.contiguous()**:确保扩展后的张量在内存中是连续存储的,方便后续的计算和操作。虽然在大多数情况下这个操作是可选的,但它可以提高计算效率并避免潜在的问题。
最终效果:
这段代码生成了一个二维张量 grid,它的形状为 [in_features, grid_size + 2 * spline_order + 1],其中每一行都是相同的、覆盖整个 grid_range 并适当扩展的网格点序列。这个网格用于模型中的 B 样条或其他基函数计算,使得模型可以在输入数据范围内执行灵活的插值和拟合操作。
初始化可训练参数
self.base_weight = torch.nn.Parameter(torch.Tensor(out_features, in_features)) # 初始化基础权重和分段多项式权重self.spline_weight = torch.nn.Parameter(torch.Tensor(out_features, in_features, grid_size + spline_order))if enable_standalone_scale_spline: # 如果启用独立的分段多项式缩放,则初始化分段多项式缩放参数self.spline_scaler = torch.nn.Parameter(torch.Tensor(out_features, in_features))
1. self.base_weight = torch.nn.Parameter(torch.Tensor(out_features, in_features)) ( w b ) (w_b) (wb)
**torch.Tensor(out_features, in_features)**:创建一个形状为(out_features, in_features)的未初始化张量,用于存储基础线性层的权重。这个张量的元素初始时没有具体的数值,通常在后续的reset_parameters()方法中进行初始化。**torch.nn.Parameter**:将这个张量封装成torch.nn.Parameter对象。这意味着这个张量会被视为模型的可训练参数,PyTorch 会自动将其包含在模型的参数列表中,并在反向传播时更新其值。**self.base_weight**:这个属性存储的是基础线性变换的权重矩阵。这个矩阵将在前向传播过程中被用来对输入特征进行线性变换。
2. self.spline_weight = torch.nn.Parameter(torch.Tensor(out_features, in_features, grid_size + spline_order)) ( c i ) (c_i) (ci)
**torch.Tensor(out_features, in_features, grid_size + spline_order)**:创建一个形状为(out_features, in_features, grid_size + spline_order)的未初始化张量,用于存储分段多项式的权重。这些权重将用于 B 样条或其他类似方法的计算。**torch.nn.Parameter**:同样地,将这个张量封装成torch.nn.Parameter,使其成为模型的可训练参数。**self.spline_weight**:这个属性存储的是与分段多项式相关的权重。这些权重决定了如何将输入特征映射到输出特征,特别是在使用 B 样条等非线性激活函数时。
为什么 spline_weight 的形状是 (out_features, in_features, grid_size + spline_order)?
**out_features**和**in_features**:与base_weight类似,表示输出和输入的特征数量。**grid_size + spline_order**:这个维度表示在 B 样条或其他分段多项式方法中,每个输入特征需要使用的基函数的数量。通过这些基函数的线性组合,可以生成灵活的非线性激活。
3. if enable_standalone_scale_spline:
- 这个条件语句检查
enable_standalone_scale_spline是否为True。如果为True,则会为每个分段多项式激活函数引入一个独立的缩放参数。
4. self.spline_scaler = torch.nn.Parameter(torch.Tensor(out_features, in_features)) ( w s ) (w_s) (ws)
**torch.Tensor(out_features, in_features)**:创建一个形状为(out_features, in_features)的张量,用于存储独立的分段多项式缩放参数。**torch.nn.Parameter**:将张量封装成torch.nn.Parameter,使其成为可训练参数。**self.spline_scaler**:这个属性存储的是分段多项式的缩放参数。每个spline_weight都有一个对应的缩放参数,可以单独调整其幅度,从而提供更大的灵活性。
其他实例属性
self.scale_noise = scale_noise # 保存缩放噪声、基础缩放、分段多项式的缩放、是否启用独立的分段多项式缩放、基础激活函数和网格范围的容差self.scale_base = scale_baseself.scale_spline = scale_splineself.enable_standalone_scale_spline = enable_standalone_scale_splineself.base_activation = base_activation()self.grid_eps = grid_epsself.reset_parameters() # 重置参数
Kaiming初始化权重(reset_parameters)
def reset_parameters(self):torch.nn.init.kaiming_uniform_(self.base_weight, a=math.sqrt(5) * self.scale_base)# 使用 Kaiming 均匀初始化基础权重with torch.no_grad():noise = (# 生成缩放噪声(torch.rand(self.grid_size + 1, self相关文章:

Efficient-KAN 源码详解
Efficient-KAN源码链接 Efficient-KAN (GitHub) 改进细节 1.内存效率提升 KAN网络的原始实现的性能问题主要在于它需要扩展所有中间变量以执行不同的激活函数。对于具有in_features个输入和out_features个输出的层,原始实现需要将输入扩展为shape为(batch_size, out_featur…...

Jlink commander使用方法(附指令大全)
Jlinkcmd它可以方便用户在非仿真的情况下,hold内核、单步、全速、设置断点、查看内核和外设寄存器、读取flash代码等等,方便大家拥有最高的权限查看在运行中的MCU情况,查找非IDE仿真情况下,MCU运行异常的原因。 目录 驱动安装 …...

Java SpringBoot实现PDF转图片
不是单页图片,是多页PDF转成一张图片的逻辑。 我这里的场景是PDF转成图片之后返回给前端,前端再在图片上实现签字,并且可拖拽的逻辑,就是签订合同的场景。 但是这里只写后端多页PDF转图片的逻辑。 先说逻辑,后面直接…...

elasticsearch SQL:在Elasticsearch中启用和使用SQL功能
❃博主首页 : 「码到三十五」 ,同名公众号 :「码到三十五」,wx号 : 「liwu0213」 ☠博主专栏 : <mysql高手> <elasticsearch高手> <源码解读> <java核心> <面试攻关> ♝博主的话 :…...

Java 并发编程:线程变量 ThreadLocal
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 029 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进…...
)
【OpenHarmony4.1 之 U-Boot 2024.07源码深度解析】018 - init_sequence_f 各函数源码分析(二)
【OpenHarmony4.1 之 U-Boot 2024.07源码深度解析】018 - init_sequence_f 各函数源码分析(二) 一、arch_cpu_init二、arch_cpu_init系列文章汇总:《【OpenHarmony4.1 之 U-Boot 源码深度解析】000 - 文章链接汇总》 本文链接:《【OpenHarmony4.1 之 U-Boot 2024.07源码深度…...

LVS原理——详细介绍
目录 介绍 lvs简介 LVS作用 LVS 的优势与不足 LVS概念与相关术语 LVS的3种工作模式 LVS调度算法 LVS-dr模式 LVS-tun模式 ipvsadm工具使用 实验 nat模式集群部署 实验环境 webserver1配置 webserver2配置 lvs配置 dr模式集群部署 实验环境 router 效果呈现…...

MYSQL 5.7.36 等保 建设记录
文章目录 前言一、开启审计日志1.1 查看当前状态1.2 开启方式1.3 查看开启后状态 二、密码有效期2.1 查看当前状态2.2 开启方式2.3 查看开启后状态 三、密码复杂度3.1 查看当前状态3.2 开启方式3.3 查看开启后状态 四、连接控制4.1 查看当前状态4.2 开启方式4.3 查看开启后状态…...

fatal: unable to access ‘https://github.com/xxxxx
ubuntu中git克隆项目异常 git clone https://github.com/xxx Cloning into ‘xxx’… fatal: unable to access ‘https://github.com/xxx/xx.git/’: Could not resolve host: github.com 解决办法使用命令: git config --global http.proxy git config --global…...
——递归与动态规划)
从零开始的CPP(38)——递归与动态规划
leetcode46 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 示例 1: 输入:nums [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]示例 2: 输入&#…...
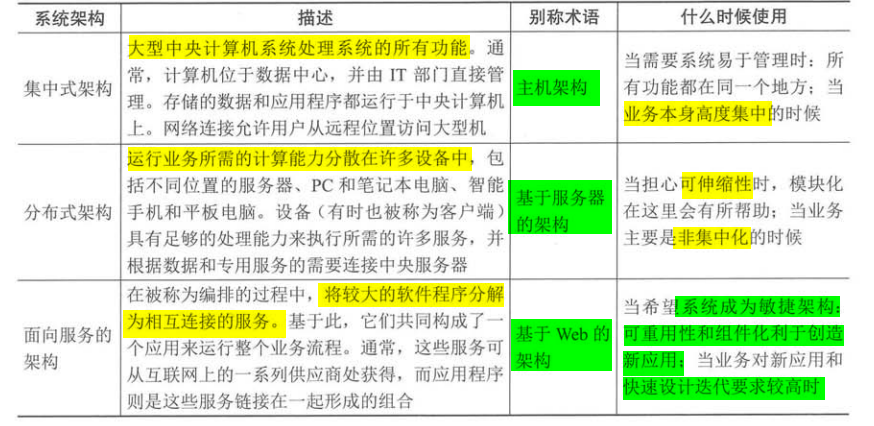
从战略到系统架构:信息系统设计的全面解析
在当今数字化时代,信息系统已成为企业运营、管理和创新的核心驱动力。信息系统设计的重要性不仅关乎企业的技术实现,更直接影响到企业的战略执行和市场竞争能力。本文将从战略视角出发,深入探讨信息系统设计的全过程,包括从战略制…...

GEE调用中国(China Land Cover Dataset,简称CLCD)1990-2022年30米分辨率的土地分类数据
博客推荐 GEE土地分类:中国30米年度土地覆盖产品annual China Land Cover Dataset, CLCD(面积提取)_30米土地利用数据gee-CSDN博客 简介 中国陆地覆盖数据集(China Land Cover Dataset,简称CLCD)是一个用…...

三十八、大数据技术之Kafka(1)
🌻🌻 目录 一、Kafka 概述1.1 定义1.2 消息队列1.2.1 消息队列内部实现原理1.2.2 传统消息队列的应用场景1.2.3 消息队列的两种模式 1.3 Kafka 基础架构 二、 Kafka 快速入门2.1 安装前的准备2.2 安装部署2.2.1 集群规划2.2.2 单节点或集群部署2.2.3 集群…...

将 Tcpdump 输出内容重定向到 Wireshark
在 Linux 系统中使用 Tcpdump 抓包后分析数据包不是很方便。 通常 Wireshark 比 tcpdump 更容易分析应用层协议。 一般的做法是在远程主机上先使用 tcpdump 抓取数据并写入文件,然后再将文件拷贝到本地工作站上用 Wireshark 分析。 还有一种更高效的方法…...
】)
【Python蓝屏程序(管理员)】
说明:该程序为临摹(😀)作品,源地址C蓝屏程序(非管理员) 我试图使用Python调用 NtRaiseHardError API ,实现类似的蓝屏效果。可惜我发现Python在普通权限下,直接调用 NtRaiseHardError API 是不被允许的,因为…...

OpenGL ES->GLSurfaceView绘制图形的流程
自定义View代码 class MyGLSurfaceView(context: Context, attrs: AttributeSet) : GLSurfaceView(context, attrs), GLSurfaceView.Renderer {var mProgrem 0init {// 设置 OpenGL ES 3.0 版本setEGLContextClientVersion(3)// 设置当前类为渲染器, 注册回调接口的实现类set…...

Linux OOM Killer详解
Linux OOM Killer详解 一、概述二、OOM Killer的技术原理1. 内存区域划分2. 内存耗尽与OOM Killer触发3. 选择被杀进程的策略4. 内存回收机制5. 内存分配策略 三、OOM Killer的工作机制1. 内存压力监测2. 触发条件3. 选择被杀进程4. 终止进程 四、实际场景举例场景一࿱…...
)
2024rk(案例二)
试题二(25分) 阅读以下关于数据库缓存的叙述,在答题纸上回答问题1至问题3。 【说明】 某大型电商平台建立了一个在线 B2B 商店系统,并在全国多地建设了货物仓储中心,通过提前备货的方式来提高货物的运送效率。但是在运营过程中,发现会出现很多跨仓储中心调货从而延误货物…...

小红书爆文秘籍:ChatGPT助你从0到1创造热门内容!
在小红书打造爆款文案的策略中,以下是一些调整和同义词替换的建议,以便达到文章去重的要求: 了解目标受众: 在撰写文案前,先深入分析目标读者的属性,如年龄层次、性别、爱好和购买行为。通过ChatGPT, 你能迅…...

django快速实现个人博客(附源码)
文章目录 一、工程目录组织结构二、模型及管理实现1、模型2、admin管理 三、博客展现实现1、视图实现2、模板实现 四、部署及效果五、源代码 Django作为一款成熟的Python Web开发框架提供了丰富的内置功能,如ORM(对象关系映射)、Admin管理界面…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...

接口测试用例设计:超详细防御体系与分层校验实践
1. 为什么“超详细”三个字在接口测试用例里不是修饰词,而是生死线我带过三支不同行业的测试团队——金融支付、SaaS中台、IoT设备管理平台。每次新人入职第一周,我都会收走他们写的前5条接口测试用例,逐行标红批注。不是因为格式不对&#x…...

SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程
SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程 【免费下载链接】speakingurl Generate a slug – transliteration with a lot of options 项目地址: https://gitcode.com/gh_mirrors/sp/speakingurl SpeakingURL是一款强大的URL友好化工具&…...

如何快速掌握MPC视频渲染器:面向初学者的完整教程
如何快速掌握MPC视频渲染器:面向初学者的完整教程 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer 想要在Windows系统上获得影院级的视频播放体验吗?MPC…...

XZ6128A工作电压5-100V 输出电流5A 升压型大功率LED灯恒流驱动控制芯片
概述 XZ6128A是一款高效率、高精度的升压型大功率LED灯恒流驱动控制芯片。 XZ6128A内置高精度误差放大器,固定关断时间控制电路,恒流驱动电路等,特别适合大功率、多个高亮度LED灯串的恒流驱动。 XZ6128A采用固定关断时间的控制方式࿰…...

第2章 谁在危险中——被AI替代的五类程序员
第2章 谁在危险中——被AI替代的五类程序员 核心问题:哪些程序员最容易被AI替代?背后的原因是什么? 2.1 问题定义:一场正在发生的结构性塌陷 2.1.1 数据不会说谎 2026年1月12日,Ravio发布了一份让整个科技圈沉默的报告:过去一年,初级开发者岗位招聘量暴跌73%。 不是…...

独立开发者利用taotoken模型广场为不同任务选择性价比最优模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者利用taotoken模型广场为不同任务选择性价比最优模型 对于独立开发者而言,在有限的预算内高效完成多样化的开…...

京东自动购物终极指南:告别缺货烦恼,智能抢购神器
京东自动购物终极指南:告别缺货烦恼,智能抢购神器 【免费下载链接】Jd-Auto-Shopping 京东商品补货监控及自动下单 项目地址: https://gitcode.com/gh_mirrors/jd/Jd-Auto-Shopping 还在为心仪商品瞬间售罄而苦恼吗?还在熬夜等待补货却…...

Hermes Agent工具如何自定义接入Taotoken提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent工具如何自定义接入Taotoken提供商 Hermes Agent 是一款功能强大的AI智能体开发框架,它支持通过自定义提供…...
)
YOLOv8道路交通信号标志识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 道路交通信号标志的自动检测是智能驾驶与交通管理系统中的核心环节。本文基于YOLOv8目标检测算法,构建了一个涵盖21类常见交通信号标志的检测系统,包括禁令标志、指示标志、警告标志及信号灯等。模型在包含1376张训练图像、488张验证图像和229张测…...