Apache Flink中TaskManager,SubTask,TaskSlot,并行度之间的关系
Apache Flink 中Application 与 Job
- 一个完整的Flink Application 一般组成如下:
- Source 数据来源
- Transformation 数据转换处理等
- Sink 数据传输
- Flink 中一个或者多个Operator(算子)组合对数据进行转换形成一个 Transformation,一个FlinkApplication开始于一个或者多个Source,结束于一个或者多个Sink
DataFlow数据流图
- 一个Flink Job执行时候会按照Source,Transformation,Sink顺序执行,形成了一个Stream DataFlow(数据流图),数据流图是个整体展示Flink作业执行流程的高级试图。

SubTask子任务与并行度
- 集群中运行Flink代码本质上就是以为并行度方式来执行,这样可以提高处理数据的吞吐量和速度。
- 当一个Flink中有多个Operator,每个Operator有多个Subtask(子任务),不同的Operator的Subtask个数可以不一样,一个Operator有几个SubTask就代当前算子的并行度(Parallelism)是多少,Subtask在不同现场,不同物理机器或者不同容器中完全独立执行。

- 以上图是DataFlow视图,下半部分是并行度DataFlow视图,Source,Map,keyBy等操作都是 2个并行度,对应有2个subtask分布式执行,Sink操作并行度1,只有一个subtask,一共是7个subTask,
- 一个Flink Application 的并行度通常任务是所有Operator中最大的并行执行能力,以上最大2个并行度
- 并行度设置有三种方法:
- Operator Level(算子层面):编码的方式xxx.setparallelism(2)。当前算子有效
- Eecution Environment Level(执行环境层面):env.setparallelism() 全局代码有效
- Client Level(客户端层面):在Web UI上之间配置
- System Level(系统层面):通过yaml文件配置:parallenlism.default :5
Operator Chains 算子链
- Flink作业中,可以指定Operator Chains(算子链)将相关性非常强的算子操作绑定在一起,这样能够让转换过程上下游的Task数据处理逻辑由一个Task执行,避免因为数据在网络或者线程之间传输导致的开销,减少数据处理延迟提高数据吞吐量。
- 如下案例,下图流程处理程序Source/map 就形成了一个算子链,keyBy/window/apply新城了算子链,分布式执行中原本需要多个task执行的操作由于存在算子链,我们可以用一SubTask分不少执行即可。

-
Flink中哪些操作可以合并一起?这主要取决于算子之间的并行度与算子数据之间传递的模式。
-
一个数据流在算子之间传递数据可以是一对一(One-to-One)的模式传递
-
也可以是重新分区(Redistributing)的模式传递,两个有区别
- One-to-one:一对一模式例如上图中source 和Map()算子之间,保留了原宿的分区和顺序,这样处理流程是map()算子的subTask[1]处理的数据全部都是来自source的task[1] 产生的数据,并且顺序保持一致,例如 map。fllter,flatMap这些算子操作都是One-to-One数据传递模式
- Redistributing:重新分区模式(如上面的mao 和keyBy/window之间,以及keyBy/window和Sink之间),改变了流的分区,这种情况下数据流向的分区变化了。每个算子的subtask将数据发送到不同的目标subtask,这取决于使用了什么样的算子操作,例如keyBy()是分组操作,会根据key的hash值重新分区投递,再比如,window/apply 算子操作的并行度是2,流向了并行度1的sink操作,这个过程需要通过rebalance操作将数据均匀发送到下游Subtsk中,这些都是重新分区了。
-
Flink 中 One-to-One的算子操作并行度一致,默认自动合并在一起形成一个算子链,
Fllink 执行图
- Flink 代码提交到集群执行,最终转成task分不少的在各个节点上运行,以下我们用DataFlow的形式展示Flink中Task提交执行流程。

- 客户端会按照transformation转成StreamGraph(任务流图)
- StreamGraph按照Operator Chains 算子链和规则转换成JobGraph(作业图)在JobGraph中将并行度相同且数据流转关系位One-to-One关系的算子合并在一个task处理原来需要两个task处理的逻辑,
- JobGraph会被提交给jobManager,最终由jobManager中的JobMaster转换成ExecutionGraph)(执行图)
- ExecutionGraph中按照每个算子并行度来划分对应的SubTask,每个SubTask最终再次被转换成其他可以部署的对象发送到TaskManager上执行。
- 以上整个流程是Flink任务的底层执行转换流程,基于以上流程有如下结论:
- 在Flink中一个Task一般对应的就是一个算子或者多个算子逻辑,多个算子逻辑经过Operator Chains优化后也是由一个Task执行
- Flink分不少运行中,Task会按照并行度划分成多个SubTask。每个SubTask由一个Thread新城执行,多个SubTask分布在不同现场不同节点形成Fllink分布式的执行。
- SubTask是Flink任务调度的基本单元
TaskSlot任务槽
- 提交到集群中的Flink程序最终都会换成一个一个的SubTask,SubTask是Flink任务调度的基本单元,这些task最终发送到不同taskmanager节点上分布式执行
TaskSlot任务槽
- Flink集群中每一个TaskManager是一个JVM进程,可以在TaskManager中执行一个或者多个Subtask,为了控制Taskmanager中接受的Task数量,TaskManager节点上可以提供TaskSlot(任务槽),一个TaskManger上可以划分多个TaskSlot,TaskSlot是Flink系统中资源调度的最小单元,可以对TaskManager上资源进行划分,每个taskSlot可以运行一个或者多个subtask,每个jobManager上至少有一个taskSlot。

-
以上,每个taskSlot都有固定资源,假设一个TaskManager有三个TaskSlots,那么每个TaskSlot将会平均分TaskManger的内存,那么subtask不会与其他subtask竞争内存,taskslot作用就是分离任务的托管内存,但是不会发生CPU的隔离
-
通过调整taskSlot数量,用户可以指定每一个taskManager油多少taskSlot,
- 可以单个,这样就独占当前JobManager的JVM
- 多个taskSlot就有多个subTask共享同一个JVM,同一个JVM中task共享TCP连接和心跳信息,共享数据集和数据结构,从而减少Taskmanager中的task开销。
-
Flink 可以配置jobManager的taskSlot数量,来决定每个TaskManager上可以执行多个subTask,由于TaskSLot只会对内存进行隔离,不对CPU进行隔离,建议线上配置 taskSlot的📄设置和该Taskmanager节点CPU CORE 的数量保持一致
TaskSlot 共享 & SlotSharingGroup共享组
- 默认情况Flink允许共享taskSlot,即便他们是不同subTask,只要是同一个Flink作业即可,结果就是一个SLot可以持有整个作业的管道

-
Flink中共享taskSlot 解决的问题:
-
我们在提交Flink应用程序时需 要关注我们程序中到底有多少subtask,然后再衡量Flink集群中slot个数是否足够,在一定程序上需 要的slot资源较多。另外一个方面是在Flink中运行的task对CPU资源的占用不同,有CUP密集型task 操作和CPU非密集型task操作情况,例如在Flink集群中source和map操作只是读数据后转换,对CPU占用短,但是window这种穿口计算聚合操作设计大量数据计算,占用CPU资源长,这就导致运行时候source/map,sink操作非常快,window操作时间长,source/map对应的subtask会等待window对应的subtask执行,同样sink的对应的
subtask也会等待window对应的subtask执行,站在集群slot角度上来看就出现了一些taskslot非常" 繁忙",一些taskslot非常"轻松",集群的资源综合利用不高。 -
taskslot共享就可以很好地解决以上问题,Flink任务所有的subtask均衡的分散到不同的taskslot上 执行,一个taskslot贯穿执行整个流程的subtask,这样每个taskslot、每个TaskManager上的资源 使用情况非常均衡。所以允许 slot 共享有两个主要优点:
- Flink集群所需要的taskSlot和作业中使用的最大并行度恰好一样,不需要关注Flink程序总共包含多少个subTask
- 容易获取更好的资源利用,如果没有slot共享,非密集型subtask(source/map)将会阻塞 和 密集型subtask(window)一样多的资源,通过slot共享,确保繁重的subtask在taskManager之间公平分配
相关文章:
Apache Flink中TaskManager,SubTask,TaskSlot,并行度之间的关系
Apache Flink 中Application 与 Job 一个完整的Flink Application 一般组成如下: Source 数据来源Transformation 数据转换处理等Sink 数据传输 Flink 中一个或者多个Operator(算子)组合对数据进行转换形成一个 Transformation,一…...

马斯克xAI新计划:人工智能模型Grok 2测试版即将发布
特斯拉CEO马斯克在X平台上表示,人工智能模型Grok 2测试版即将发布。Grok,作为xAI公司的明星大语言模型,其首代产品Grok 1已凭借神经演化计算与深度学习技术的深度融合,展现了超乎想象的学习速度与智能深度,赢得了业界的…...

【机器人学】6-4.六自由度机器人运动学参数辨识-机器人精度验证【附MATLAB代码】
前言 前两个章节以及完成了机器人参数辨识。 【机器人学】6-1.六自由度机器人运动学参数辨识-辨识数学模型的建立 【机器人学】6-2.六自由度机器人运动学参数辨识-优化方法求解辨识参数 这里我们认为激光测量仪测量到的数据为机器人实际到达的位置,而机器人理论到…...
分销商城小程序系统渠道拓展
线上卖货渠道很多,想要不断提高营收和新客获取,除了自己和工具本身努力外,还需要其他人的帮助来提高商城店铺的整体销量。 搭建saas商城系统网站/小程序,后台上货,设置支付、配送、营销、精美模板商城装修等内容&…...

WPF篇(14)-ProgressBar进度条+Calendar日历控件+DatePicker日期控件
ProgressBar进度条 ProgressBar进度条通常在我们执行某个任务需要花费大量时间时使用,这时可以采用进度条显示任务或线程的执行进度,以便给用户良好的使用体验。 ProgressBar类定义 public class ProgressBar : RangeBase {public static readonly De…...
链表高频题目和必备技巧
链表高频题目和必备技巧 1. 链表类题目注意点 1,如果笔试中空间要求不严格,直接使用容器来解决链表问题 2,如果笔试中空间要求严格、或者在面试中面试官强调空间的优化,需要使用额外空间复杂度**O(1)**的方法 3,最…...

Vue3详细介绍,正则采集器所用前端框架
Vue3 引入了一个全新的响应式系统,它是基于ES6的Proxy特性构建的。这个系统使得 Vue 能够更加高效地追踪数据的变化,并在数据发生变化时自动更新DOM。响应式系统的核心是"可观察",当数据变化时,视图会响应这些变化并重新…...
)
数据集--COCO2017(快速下载)
1、数据集介绍 数据集官网:https://cocodataset.org/#home COCO(Common Objects in Context)数据集是计算机视觉领域中最广泛使用的数据集之一,主要用于目标检测、分割和图像标注任务。COCO 数据集由 Microsoft 发布,…...
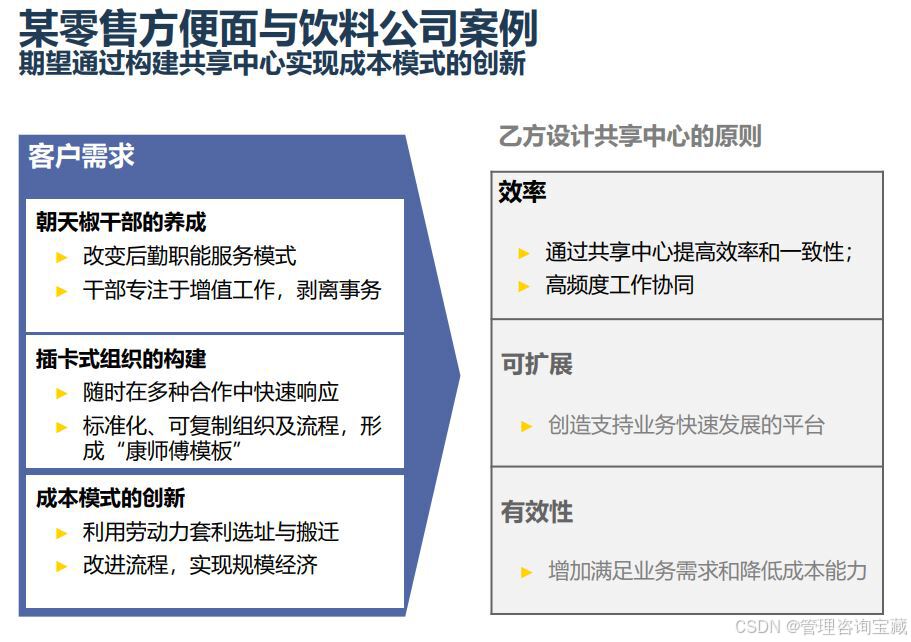
【管理咨询宝藏159】顶级咨询公司人力三支柱建设方案思路
阅读完整版报告内容,请搜索VV号“管理咨询宝藏”。 【管理咨询宝藏159】顶级咨询公司人力三支柱建设方案思路 【格式】PDF版本 【关键词】人力咨询、三支柱、人力体系 【核心观点】 - 集团总部制定全集团共享中心总体规划路径,组织并负责实施与推广。各…...

跨时钟域总结
跨时钟域总结 秋招学习跨时钟域 总结一下吧 异步电路 设计中有两个频率不同的时钟(也可能多个),而有数据在两组时钟之间传输 单bit跨时钟域 慢时钟域数据-> 快时钟域 方法 : 使用两个锁存器 (打两拍) 数据跨时钟域同步过程中,脉冲宽度会改变,不影响同步结…...

富婆和富公子都在看的负载均衡和Haproxy大全
一.负载均衡 1.1:什么是负载均衡 负载均衡: Load Balance ,简称 LB ,是一种服务或基于硬件设备等实现的高可用反向代理技术,负载均 衡将特定的业务(web 服务、网络流量等 ) 分担给指定的一个或多个后端特定的服务器或…...

VScode找python环境 (conda)
第一步 CtrlshiftP 第二步 框框里输入:Python:Select Interpreter...

C# Winform序列化和反序列化
在NET Framework 4.7.2中不能用Newtonsoft.Json进行序列化和反序列化,为解决此问题,采用System.Text.Json进行序列化,注意要添加System.Memory的引用。 1、创建测试类 using System; using System.Collections.Generic; using System.Linq; …...

crc原理概述
CRC(循环冗余校验)是一种错误检测技术,用于确保数据在传输或存储过程中没有发生变化。它通过将数据视为一个多项式,利用二进制除法得到一个校验码(CRC值)。接收方使用相同的算法验证数据和CRC值是否匹配&am…...

C++要求或禁止在堆中产生对象
有时你想这样管理某些对象,要让某种类型的对象能够自我销毁,也就是能够“delete this”。很明显这种管理方式需要此类型对象被分配在堆中。而其它一些时候你想获得一种保障:“不在堆中分配对象,从而保证某种类型的类不会发生内存泄…...

为什么阿里开发手册推荐用静态工厂方法代替构造器?
🍅 作者简介:哪吒,CSDN2021博客之星亚军🏆、新星计划导师✌、博客专家💪 🍅 哪吒多年工作总结:Java学习路线总结,搬砖工逆袭Java架构师 🍅 技术交流:定期更新…...

前端写法建议【让项目更加易于维护】
背景 标题前提条件: 没有字典接口、或其他原因,需要前端手动维护的情况 示例环境:vue2,其他项目同理 示例 如果项目有某种类别,前端和后端约定好了,某些情况下,需要前端写死时。 比如有字段…...

EasyExcel 自定义转换器、自定义导出字典映射替换、满足条件内容增加样式,完整代码+详细注释说明
虽然最之前是在其他地方看到的,但最终因缘巧合下找到了原文,还是尊重一下原作者。 参考引用了这位佬的博客,确实方便使用。 https://blog.csdn.net/qq_45914616/article/details/137200688?spm1001.2014.3001.5502 这是一个基于Easyexcel通过…...

C语言学习笔记 Day10(指针--中)
Day10 内容梳理: 目录 Chapter 7 指针 7.4 指针 & 数组 (1)指针操作数组元素 (2)指针加减运算 1)加法 2)减法 (3)指针数组 7.5 多级指针 Chapter 7 指针 …...

网页显示打印 pdf
文件服务使用 minio,使用 nginx 反向代理。 将文件存放在 minio 上,如果是公开的文件,则统一放到一个桶,设置为公开只读。 如果是私有文件,则使用临时链接,给有权限的用户查看和打印。 要实现在 html 页…...

本地柴油发电机组排行2023年最新榜单
柴油发电机是通过燃烧柴油驱动发动机,进而发电的设备,广泛应用于电力中断或无电网地区。1. 柴油发电机的核心工作原理是什么?柴油发电机是一种将化学能转化为电能的设备,其核心是柴油发动机与交流发电机的组合。当柴油在发动机内燃…...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

FeHelper前端助手:30+开发工具集,让你的浏览器变身效率神器
FeHelper前端助手:30开发工具集,让你的浏览器变身效率神器 【免费下载链接】FeHelper 😍FeHelper--Web前端助手(Awesome!Chrome & Firefox & MS-Edge Extension, All in one Toolbox!) 项目地址:…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...

Codex使用API Key授权无法使用插件?
小伙伴们,大家好,我是小溪,见字如面。对于没有ChatGPT账号的小伙伴来说,虽然可以通过API Key授权的方式使用Codex桌面端,但是会有一些限制。比如无法使用插件功能,无法使用Codex移动端进行远程控制等。为了…...

OpenRASP原理与实战:Java应用层实时防护技术详解
1. 为什么我宁愿花三天部署OpenRASP,也不愿再写第五个自定义WAF过滤器去年冬天,我在给一家做在线教育SaaS平台做安全加固时,连续踩了三个坑:第一次用NginxLua写了套SQL注入规则,结果学生提交的“SELECT * FROM courses…...