笔记(day17)集合概述、List、Set、比较器
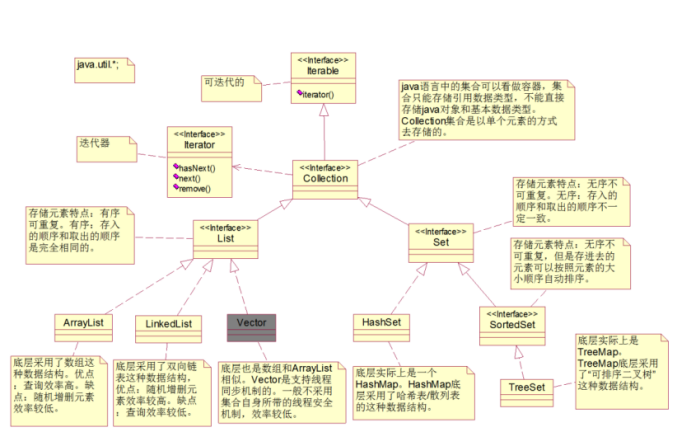
集合Collection
一.概述
集合可以理解为数据结构的封装,根据不同的特性及操作性能进行分类
二.继承体系
三.Collection中常用方法
collection是集合中的父类,所以collection中的方法是所有集合中都有的
集合中只能保存引用类型(Object),无法保存基本类型
Collection 中并没有查询和修改操作
-
判断是否为空 isEmpty();
Collection c = new ArrayList(); c.isEmpty(); -
添加 add
c.add(""); -
删除 remove 根据内容删除元素
c.remove("a"); -
已有元素个数 size()
c.size(); -
是否包含某个元素 contains()
c.contains(1); -
清空集合元素 clean()
c.clean(); -
转换为数组 toArray()
Object[] arr = c.toArray();
四.迭代器
4.1 概述
迭代器模式∶它可以使对于序列的底层数据结构的遍历行为与被遍历的对象分离,可以让我们无序关心底层数据结构直接的差异性,提供了统一遍历的标准.(无论底层为何种数据结构都可以使用这个标准进行遍历)
4.2 常用方法
注意 : 迭代器一旦生成,集合不能进行修改,除非重新生成迭代器,也就意味着,在迭代器中删除,只能使用迭代器的remove 不能使用集合的remove
-
hashNext : 判断是否还有元素(boolean)
-
next : 光标向下移动一位,并返回指向的数据
-
remove : 删除当前指向的元素
4.3 forEach
增强for循环foreach是 jdk5.0引入的
语法
会把集合中的每个数据,依次赋值给变量
for(数据类型变量名∶集合){
}
是迭代器iterator的简写方式,如果只是需要做基本的遍历操作,就可以使用使用foreach
但是如果想要做删除操作,还是要使用iterator的,因为foreach无法进行删除操作
public static void main(String[] args){Collection c = new ArrayList();c.add(1);c.add("a");c.add(3);for (Object object : c) {System.out.println(object);}
}
五.List
有序(添加和取出顺序一致)
可重复(可以添加重复数据)
5.2 ArrayList
随机性添加和删除效率较低,查询和修改效率较高
//默认容量为10,每次扩容扩大1.5倍
//创建对象时容量为0,第一次添加数据的时候,长度初始化为10;
ArrayList arr = new ArrayList();
// 尾部添加
arr.add(1);
// 指定位置添加,把数据2添加到第0位上
arr.add(0,2);//获取 根据下标查询数据
arr.get(0);//修改
arr.set(1,12);//根据内容删除
arr.remove("a");
//传入int,则为根据索引删除
arr.remove(0);
//假如我们要根据内容删除,而这个内容恰好是数字,则需要封装包装类
arr.remove(Integer.valueOf(12));//遍历
for(int i = 0; i < arr.size(); i++){System.out.print(arr.get(i)+" ");
}
for(Object object : arr){System.out.print(object);
}
5.3 LinkedList
5.3.1 概述
LinkedList : 底层是一个双向链表,随机性添加和删除效率较高,查询和修改效率较低
5.3.2 使用方法
基本上和ArrayList的使用是一样的
LinkedList arr = new LinkedList();
// 尾部添加
arr.add(1);
arr.add("a");
// 添加到指定位置,把数据2 添加到第0位上
arr.add(0, 2);
// 尾部添加
arr.addLast(4);
arr.offerLast(4);
arr.offer(6);
// 首位添加
arr.push(2);
arr.addFirst(4);
arr.offerFirst(5);
// 核心的添加方法 linkLast 和 linkFirst// 获取 根据下标查询数据
System.out.println(arr.get(0));
// 修改 把下标1的值换成12
arr.set(1, 12);// 根据内容删除
arr.remove("a");
// 传入int,则为根据索引删除
arr.remove(0);
// 假如我们要根据内容删除,而这个内容恰好是数字,则需要封装包装类
arr.remove(Integer.valueOf(12));
System.out.println(arr);arr.add(1);
arr.add(12);
arr.add(31);
arr.add(3);
arr.add(5);
for (int i = 0; i < arr.size(); i++) {System.out.println(arr.get(i));
}
for (Object object : arr) {System.out.println(object);
}5.3.3 Get方法实现理念

链表是不支持下标的,只是提供了类似于下标的操作方式,但是本质还是利用循环,一个一个去找,跟数组的下标访问压根不是一回事儿
5.3.4 linkedList类

5.3.5 Node节点类

5.3.6 添加底层实现


5.3.7 删除


六.set
6.1 特性
无序 : 不保证有序, 可能有序, 可能无序
不可重复 : 不能添加重复数据
不能做修改和查询操作
6.2 TreeSet
6.2.1 特征
底层是红黑树,添加的元素会按照特定的顺序进行排序
数字 : 从小到大
日期 : 自然日期
字符串 : 按照每位的ASCII码值进行排序
既然会排序,说明一定会进行比较不同类型是没有可比性的,因此treeSet必须保存同一类型
6.2.2 使用
没有查询和修改功能
TreeSet ts = new TreeSet);
//添加
ts.add(1);
ts.add(12);
ts.add(3);
ts.add(9);
//java.lang.ClassCastException: java.lang.Integer cannot be cast toll java.lang.String
// ts.add("aa");
//根据内容删除
ts.remove(2);
//没有查询和修改功能
ts.size();
ts.isEmpty();
ts.contains(2);
ts.clear();
System.out.println(ts);
6.2.3 注意
TreeSet set = new TreeSet();
set.add("1");
set.add("7");
//没有重复数据
set.add("1");
//先比较第一位,按位比较
set.add("14");
set.add("16");
set.add("6");
System.out.print(set);//1 14 16 6 7;
6.3 HashSet
6.3.1 概述
底层是Haspmap,set其实就是map的key部分,因此不能做查询和修改操作
七.排序
7.1 comparable
为什么会自动排序呢?因为添加的这些对象的类,都实现了Comparable接口,并实现了compareTo方法
要排序的类会根据compareTo方法的返回值,进行排序
返回0说明相等,就不添加
返回小于0的值,就说明要添加的元素比集合中的小,就会被放到前面
返回大于0的值,就说明要添加的元素比集合中的大,就会被放到后面
因此我们自定义的类想要被排序,就要实现comparable接口并覆写compareTo方法
public class Test_01 {public static void main(String[] args) {TreeSet ts = new TreeSet();ts.add(new User(18, "张三"));ts.add(new User(16, "张三"));ts.add(new User(19, "张三"));ts.add(new User(15, "张三"));for (Object object : ts) {System.out.println(object);} }
}
class User implements Comparable{@Overridepublic int compareTo(Object o) {if(o instanceof User){User user = (User) o;return user.age - this.age;}return 0;}private int age;private String name;public User(int age, String name) {super();this.age = age;this.name = name;}public User() {super();}@Overridepublic String toString() {return "User [age=" + age + ", name=" + name + "]";}
}
7.2 comparator
数字会默认从小到大排序,那么如果我们的需求是,要求数字从大到小排序呢?
数字升序是因为Integer类中有compareTo方法,并定义了升序排序,而我们并没有办法去修改Integer类中的源码,但是我们可以扩展Comparator:比较器类,当comparable和comparator同时存在的时候.comparator优先级大于comparable
应用场景︰
如果保存的元素的类,是我们写的,肯定要实现comparable接口
如果保存的元素的类,不是我们写的,并且排序规则也无法满足我们的需求,需要使用comparator来进行扩展
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;class User implements Comparator<User> {private String name;private int age;private boolean sex;public User() {}public User(String name, int age, boolean sex) {this.name = name;this.age = age;this.sex = sex;}@Overridepublic String toString() {return "User{" +"name='" + name + '\'' +", age=" + age +", sex=" + sex +'}';}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public boolean isSex() {return sex;}public void setSex(boolean sex) {this.sex = sex;}@Overridepublic int compare(User o1, User o2) {return o1.age-o2.age;}
}
public class Test{public static void main(String[] args) {User user1=new User("dingli",25,true);User user2=new User("huxiaojuan",24,false);User user3=new User("xxx",24,false);List<User> list=new ArrayList<User>();list.add(user1);list.add(user2);list.add(user3);Collections.sort(list, new User()); //类实现了的Comparator能满足需求System.out.println("类自身实现Comparator:"+list);//现在我想要按照名字升序,显然类中实现的不能满足要求,于是可以在类外自己实现想要的比较器Collections.sort(list, new Comparator<User>() {@Overridepublic int compare(User o1, User o2) {return o1.getName().compareTo(o2.getName()); //按照名字升序}});System.out.println("匿名内部类方式:"+list);//由于Comparator接口是一个函数式接口,因此根据jdk1.8新特性,我们可以采用Lambda表达式简化代码Collections.sort(list,(u1,u2)->{return u1.getName().compareTo(u2.getName());});System.out.println("Lambda表达式方式:"+list);}
}
7.3 Collections
Collections.sort() 方法是用于对 List 集合中的元素进行排序的。这个方法有两个重载版本:一个接受一个 List 参数(要求列表中的元素实现了 Comparable 接口),另一个接受一个 List 参数和一个 Comparator 参数(允许你指定一个自定义的比较器)。
public static void main(String[] args) {ArrayList al = new ArrayList();al.add(1);al.add(16);al.add(5);al.add(2);al.add(7);Collections.sort(al);System.out.println(al);//[1, 2, 5, 7, 16]Collections.sort(al,new Comparator() {@Overridepublic int compare(Object o1, Object o2) {return (Integer)o2 - (Integer)o1 ;}});System.out.println(al);//[16, 7, 5, 2, 1]}
7.4 总结
- Comparable 是“比较”的意思,而 Comparator 是“比较器”的意思;
- Comparable 是通过重写 compareTo 方法实现排序的,而 Comparator 是通过重写 compare 方法实现排序的
- 一个类只有实现了Comparable接口才支持排序,当一个类已经实现Comparable接口但是他的排序方式不满足我的需求时,才使用Comparator接口来满足需求
- 自己写的类优先实现Comparable接口
- 当一个类没有comparab接口是时没办法直接进行排序的,必须去再次实现Comparator接口才可以排序(就算类实现了Comparator接口也无法直接使用Collections.sort() 方法排序)
- 当Comparable和Comparator同时存在时,Comparator优先级高
使用规则:
- 如果排序逻辑是要排序的对象固有的并且不会更改,使用 Comparable。
- 如果需要定义多个排序规则或对未实现 Comparable 的对象进行排序时,使用 Comparator。
- 如果一个类实现了 Comparable 接口支持自然排序,仍然可以使用 Comparator 进行自定义排序。
八.散列表
8.1 概述
存放单链表的数组(数组里存放的是节点)
(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
8.2 底层实现
java中,把散列表封装在HashTable HashMap 和 HashSet中,HashTable已经过时,不推荐使用,被HashMap代替
需要注意 : 使用散列表,需要 同时覆写equals方法和hashCode方法,才能确保数据的唯一性节点中包含4个属性 : key , value , hash , next
添加过程 :
- 调用key的hashCode方法,生成hash值
- 进行hash算法得到对应的值
- 生成数组下标,判断该位置是否有数据
- 如果没有数据,则创建节点对象,把key和value保存在节点中,并把节点对象 保存在数组中
- 如果有数据,则调用key的equals方法和对应链表中每一个数据进行比较
- 如果相同,则不添加,但是value值覆盖原来的value
- 如果都不相同,说明他们只是下标一样,内容并不一样,所以把该节点对象插入在链表的尾部
- 1.8开始新特性,为了提高查询效率,引入红黑树,因为链表查询效率较低,所以会在添加的时候进行判断如果链表个数大于等于7,把该链表转换为红黑树存储
HashMap默认初始化容量为16,并且默认加载因子是0.75 (16*0.75=12 , 也就是说到达12个就开始扩容)
九.map
9.1 HashMap
key不可以重复, value 可以重复
public static void main(String[] args) {
Map map = new HashMap();
// 添加
map.put("A", 11);
map.put("A", 12);
map.put("B", 11);
map.put("B", 13);
System.out.println(map);// {A=12, B=13}
// 查询 根据key值查询 value的值
System.out.println(map.get("A"));// 12
System.out.println(map.get("B"));// 13// 改 , 和添加一样,已有key为修改,没有的key 为添加
map.put("B", 17);// 删除 根据key删除整个映射关系
map.remove("A");
System.out.println(map);// {B=17}// 个数
System.out.println(map.size());// 1// 判断是否包含某个key
System.out.println(map.containsKey("A"));// false// 判断是否包含某个value
System.out.println(map.containsValue(17));// true// 清空
map.clear();
System.out.println(map);// {}map.put("A", 13);
map.put("B", 23);// keySet 获取所有的类封装到set中返回
Set set = map.keySet();
for (Object object : set) {System.out.print(object + " : " + map.get(object)+" ");//A : 13 B : 23
}System.out.println();// values 获取所有value并封装到集合中返回
Collection values = map.values();
for (Object object : values) {System.out.print(object+" ");//13 23
}System.out.println();// entrySet 把key和value封装到entry对象中,并保存在set中返回
Set entrys = map.entrySet();
for (Object object : entrys) {Entry entry = (Entry) object;System.out.print(entry.getKey()+" : "+entry.getValue()+" ");//A : 13 B : 23 }
}9.2 TreeMap
使用treeMap ,key元素类,必须实现Comparable接口并覆写compareTo方法注意treeMap中,排序是按照key进行的和value没有关系
public static void main(String[] args) {TreeMap map = new TreeMap();map.put("a",12);map.put("b",11);map.put("x",10);map.put("a1",22);System.outprintln(map);
}
十.泛型
10.1 概述
在编译时,进行类型检查
默认集合中是可以保存任意类型元素的(Object),使用泛型后可以使类型统一
因为我们在使用集合的时候,虽然可以保存任意类型元素,但是往往我们只会保存同一种类型由于内部是Object类型,导致所有类型存储的时候都会发生多态,而多态丢失子类特有的属性
因此我们使用的时候,需要向下转型(强制类型转换)如果使用泛型,则不再需要类型转换,使用更方便
泛型只能写引用类型
10.2 使用
public static void main(String[] args) {List<Integer> list = new ArrayList<Integer>();list.add(2);list.add(5);list.add(1);//报错,只可以添加int类型的数据//list.add("2");
}
TreeMap map = new TreeMap();
map.put("a",12);
map.put("b",11);
map.put("x",10);
map.put("a1",22);
System.outprintln(map);
}
# 十.泛型## 10.1 概述 在编译时,进行类型检查
默认集合中是可以保存任意类型元素的(Object),使用泛型后可以使类型统一
因为我们在使用集合的时候,虽然可以保存任意类型元素,但是往往我们只会保存同一种类型由于内部是Object类型,导致所有类型存储的时候都会发生多态,而多态丢失子类特有的属性
因此我们使用的时候,需要向下转型(强制类型转换)如果使用泛型,则不再需要类型转换,使用更方便
**泛型只能写引用类型**## 10.2 使用```java
public static void main(String[] args) {List<Integer> list = new ArrayList<Integer>();list.add(2);list.add(5);list.add(1);//报错,只可以添加int类型的数据//list.add("2");
}
相关文章:
笔记(day17)集合概述、List、Set、比较器
集合Collection 一.概述 集合可以理解为数据结构的封装,根据不同的特性及操作性能进行分类 二.继承体系 三.Collection中常用方法 collection是集合中的父类,所以collection中的方法是所有集合中都有的 集合中只能保存引用类型(Object),无法保存基本类型 Colle…...
)
C语言从头学45——I/O函数(二)
本文继续学习I/O函数,并延续前文的编号。 (三)、sscanf() 函数 sscanf() 函数与scanf() 有些相似,不同之处sscanf() 是从已有的字符串里面获取数据;这个函数也是定义在stdio.h中。 功能:处理已经输入到计算机中的字…...
Python爬虫——爬取bilibili中的视频
爬取bilibili中的视频 本次爬取,还是运用的是requests方法 首先进入bilibili官网中,选取你想要爬取的视频,进入视频播放页面,按F12,将网络中的名称栏向上拉找到第一个并点击,可以在标头中,找到…...

为什么企业电销要用外呼系统
电销要使用外呼系统的原因主要有以下几点: 一、提升工作效率 * **自动拨号**:外呼系统能够自动拨打客户电话,减少电销人员手动拨号的时间,让他们将更多精力集中在与客户的沟通和交流上。 * **数据记录与管理**:系统能…...
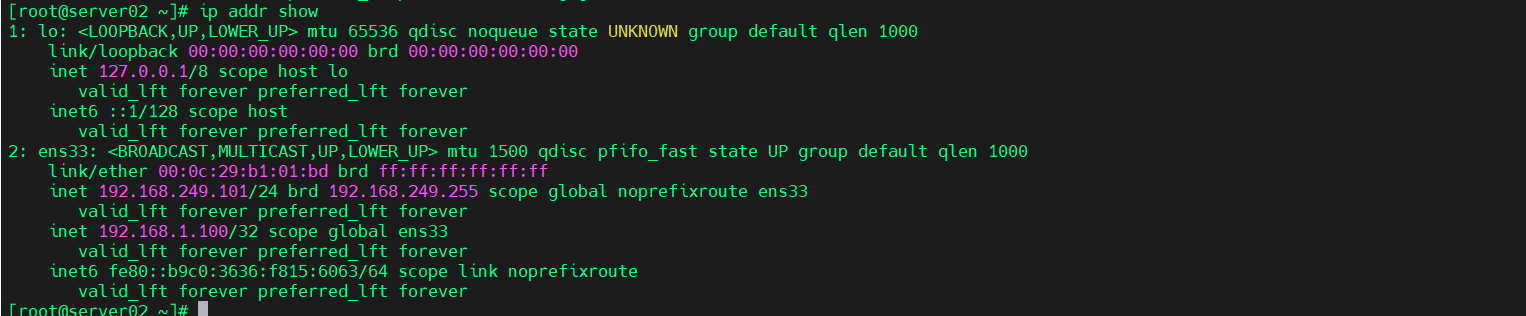
Keepalived + Nginx 主备容灾方案介绍
Keepalived Nginx 主备容灾方案介绍 *服务器**IP地址**角色*Srv01192.168.249.100 VIP: 192.168.249.110NginxKeepaliveSrv02192.168.249.101NginxKeepalive 概述 Keepalived 和 Nginx 的组合是一个常见的高可用性(HA)方案,尤其适用于 Web…...

PHP、JavaScript代码审计工具
软件截图 1. GPT代码审计需要挂代理,和充值才可以使用 2. 全局搜索关键字 3. 危险函数搜索 4. 自动化代码审计 报告 下载地址 GitHub - yuag/Code-audit: 代码审计代码审计. Contribute to yuag/Code-audit development by creating an account on GitHub....

《向量数据库指南》——Ray Data+Anyscale解锁价值评估新篇章
在钧瓷这一古老而深邃的艺术领域中,每一位资深藏家与投资人都深知,随着市场的不断发展与扩大,信息的处理与分析能力对于精准判断、高效收藏与投资决策至关重要。尤其是当我们面对庞大的钧瓷数据库、复杂的交易记录、以及不断更新的市场趋势时,传统的数据处理方式往往显得力…...

知识改变命运 数据结构【杨辉三角(顺序表)】
杨辉三角 首先我们可以发现题目中返回类型是一个 这其实返回的类似与一个二维数组 我们大概分析下题目根据画图可知,我们可以把每一行的元素进行存储,然后再把每一行存储起来,然后就实现了题目 代码: public List<List<…...

Docker三剑客之Docker Engine
Docker Engine作为Docker的核心组件,其功能和重要性不言而喻。以下是对Docker Engine的详细介绍,内容涵盖其定义、核心组件、工作原理、配置方法、安全性以及最佳实践等多个方面,但由于篇幅限制,我将尽量在6000字以内概括性地介绍…...

【Qt】信号与槽(下)
目录 自定义信号 带参数的信号和槽 信号和槽存在的意义 信号与槽的连接方式 一对一 一对多 多对一 意义 信号和槽的其他说明 信号和槽的断开 使用Lambda表达式定义槽函数 信号与槽的优缺点 优点: 松散耦合 缺点: 效率较低 自定义信号 自定义槽函数是非常关键的&a…...
多模态大语言模型(MMLLM)的现状、发展和潜力
1、大模型 随着ChatGPT流行,大模型技术正逐渐成为AI领域的热点。许多行业大佬纷纷投身于这一赛道,展示了大模型的独特魅力和广阔前景。 王慧文,前美团联合创始人,发起“AI英雄帖”。 李志飞,出门问问创始人࿰…...

Linux中apache服务安装与mysql安装
目录 一、apache安装 二、MySQL安装 一、apache安装 准备环境:一台虚拟机、三个安装包(apr-1.6.2.tar.gz、apr-util-1.6.0.tar.gz、httpd-2.4.29.tar.bz2) 安装过程: tar xf apr-1.6.2.tar.gz tar xf apr-util-1.6.0.tar.gz tar xf http…...

Sublime Text常用快捷键
1. 简介 1.1. 概述 Sublime Text是一个轻量级的文本编辑器,它具有快速的启动速度、易用性以及美观的界面。它支持多种编程语言,并且可以通过各种插件进行功能扩展。Sublime Text由程序员Jon Skinner于2008年1月份开发出来,最初被设计为一个具有丰富扩展功能的Vim。它具有漂…...

高危漏洞CVE-2024-38077的修复指南
“ 根据2024年8月9日,国家信息安全漏洞共享平台(CNVD)收录了Windows远程桌面许可服务远程代码执行漏洞(CNVD-2024-34918,对应CVE-2024-38077)。未经身份认证的攻击者可利用漏洞远程执行代码,获取服务器控制权限。目前,该漏洞的部分技术原理和概念验证伪代码已公开,厂商…...

docker基本管理和应用
docker是一个开源的应用容器引擎,基于go语言开发的 docker是运行在linux的容器化工具,可以理解为轻量级的虚拟机 可以在任何主机上,轻松创建的一个轻量级,可移植的,自给自足的容器 鲸鱼--------->宿主机 集装箱…...

AI招聘在人才盘活中的作用:开启智慧人力新篇章
一、引言:AI赋能招聘新纪元 在21世纪的今天,随着科技的飞速发展,人工智能(AI)已经渗透到社会经济的各个角落,其中,人力资源管理领域也不例外。AI技术的引入,不仅颠覆了传统的招聘模…...

探索SD NAND配套测试工具:工程师的得力助手
在快速发展的存储技术领域,SD NAND因其高速读写、低功耗和高可靠性而广受青睐。然而,对于工程师来说,验证SD NAND的性能并非易事,为了便于工程师验证,MK 米客方德开发设计了SD NAND配套测试工具。 一、SD NAND转接板简…...

三十六、【人工智能】【机器学习】【监督学习】- Bagging算法模型
系列文章目录 第一章 【机器学习】初识机器学习 第二章 【机器学习】【监督学习】- 逻辑回归算法 (Logistic Regression) 第三章 【机器学习】【监督学习】- 支持向量机 (SVM) 第四章【机器学习】【监督学习】- K-近邻算法 (K-NN) 第五章【机器学习】【监督学习】- 决策树…...

2024年8月8日(python基础)
一、检查并配置python环境(python2内置) 1、检测是否安装 [rootlocalhost ~]# yum list installed| grep python [rootlocalhost ~]# yum -y install epel-release 2、安装python3 [rootlocalhost ~]# yum -y install python3 最新版3.12可以使用源码安…...

SpringAOP_面向切面编程
一、什么是StringAOP AOP(Aspect-Oriented Programming: 面向切面编程):将那些与业务无关, 却为业务模块所共同调用的逻辑(例如事务处理、日志管理、权限控制等)封装抽取成一个可重用的模块,这个模块被命名为“切面”&…...

FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程
FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程 【免费下载链接】fceux FCEUX, a NES Emulator 项目地址: https://gitcode.com/gh_mirrors/fc/fceux FCEUX是一款功能强大的开源NES模拟器,让你在现代电脑上完美重温经典红白机游戏。无论…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...

如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。
如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。 Word中脚注线不会删?这里有妙招!,教育,职业教育,好看视频...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击
告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软…...

2026年一键生成论文工具对比实测:5款神器从选题到格式全流程护航
写论文的焦虑,是每个科研人和学生都心照不宣的“隐形压力”。选题无从下手,文献检索耗时费力,逻辑框架反复推翻,格式排版让人抓狂,查重降重更是像在和系统玩“猫鼠游戏”。2026年的AI工具早已不是过去那种“打字机”&a…...

淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理
淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taoji…...

手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器
手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器 无人机开发者和爱好者们,是否曾想过用手机就能完成整个无人机仿真测试流程?告别笨重的电脑束缚,只需一部安卓设备,就能在沙发上调试飞控算法。…...

告别RaiDrive广告!用开源rclone+Alist,免费把阿里云盘/百度网盘变成电脑本地硬盘
开源方案实战:用rcloneAlist打造无广告的云盘本地化体验 每次打开RaiDrive时弹出的广告窗口是否让您感到困扰?商业软件的收费模式是否让您犹豫不决?今天,我们将彻底解决这些问题。通过开源工具Alist和rclone的组合,您不…...