【C++】map 和 set
文章目录
- 一、关联式容器与键值对
- 1、关联式容器
- 2、键值对 pair
- 3、树形结构的关联式容器
- 二、set
- 1、set 的介绍
- 2、set 的使用
- 三、multiset
- 四、map
- 1、map 的介绍
- 2、map 的使用
- 五、multimap
一、关联式容器与键值对
1、关联式容器
在C++初阶的时候,我们已经接触了 STL 中的部分容器并进行了模拟实现,比如 vector、list、stack、queue 等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身;
同样,关联式容器也是用来存储数据的,但与序列式容器不同的是,关联式容器里面存储的是 <key, value> 结构的键值对,因此在数据检索时比序列式容器效率更高。
2、键值对 pair
键值对是用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量 – key 和 value;其中 key 代表键值,value 代表与 key 对应的信息。
我们在上一节学习二叉搜索树的时候提到的 KV 模型 (key-value 模型) 中的 KV 其实就是键值对;我们可以用上一节中提到的英汉互译的例子来理解 key-value 键值对 – 现在要建立一个英汉互译的字典,那该字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义。
STL 中键值对的定义如下:(SGI 版本)
template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first; //keyT2 second; //valuepair() : first(T1()), second(T2()) //默认构造{}pair(const T1& a, const T2& b) : first(a), second(b){}
};
可以看到,C++ 中的键值对是通过 pair 类来表示的,pair 类中的 first 就是键值 key,second 就是 key 对应的信息 value;那么以后我们在设计 KV 模型的容器时只需要在容器/容器的每一个节点中定义一个 pair 对象即可;
这里有的同学可能会有疑问,为什么不直接在容器中定义 key 和 value 变量,而是将 key、value 合并到 pair 中整体作为一个类型来使用呢?这是因为 C++ 一次只能返回一个值,如果我们将 key 和 value 单独定义在容器中,那么我们就无法同时返回 key 和 value;而如果我们将 key、value 定义到另一个类中,那我们就可以直接返回 pair,然后再到 pair 中分别去取 first 和 second 即可。
make_pair 函数
由于 pair 是类模板,所以我们通常是以 显式实例化 + 匿名对象 的方式来进行使用,但是由于显式实例化比较麻烦,所以 C++ 还提供了 make_pair 函数,其定义如下:
template <class T1, class T2>
pair<T1, T2> make_pair(T1 x, T2 y)
{return (pair<T1, T2>(x, y));
}
如上,make_pair 返回的是一个 pair 的匿名对象,匿名对象会自动调用 pair 的默认构造完成初始化;但由于 make_pair 是一个函数模板,所以模板参数的类型可以根据实参来自动推导完成隐式实例化,这样我们就不用每次都显式指明参数类型了。
注:由于 make_pair 使用起来比 pair 方便很多,所以我们一般都是直接使用 make_pair,而不使用 pair。
3、树形结构的关联式容器
根据应用场景的不同,STL 总共实现了两种不同结构的关联式容器 – 树型结构与哈希结构;树型结构的关联式容器主要有四种 – map、set、multimap、multiset,这四种容器的共同点是使用平衡二叉搜索树作为其底层结构,容器中的元素是一个有序的序列;本文将介绍这四个容器的使用。
二、set
1、set 的介绍
set 是按照一定次序存储元素的容器,其底层是一棵平衡二叉搜索树,由于二叉搜索树的每个节点的值满足左孩子 < 根 < 右孩子,并且二叉搜索树中没有重复的节点,所以 set 可以用来排序、去重和查找,同时由于这是一棵平衡树,所以 set 查找的时间复杂度为 O(logN),效率非常高;
同时,set 是一种 K模型 的容器,也就是说,set 中只有键值 key,而没有对应的 value,并且每个 key 都是唯一的;set 中的元素也不允许修改,因为这可能会破坏搜索树的结构,但是 set 允许插入和删除。
总结:
- set 是K模型的容器,所以 set 中插入元素时,只需要插入 key 即可,不需要构造键值对;
- set中的元素不可以重复,因此可以使用set进行去重;
- 由于 set 底层是搜索树,所以使用 set 的迭代器遍历 set 中的元素,可以得到有序序列,即 set 可以用来排序;
- set 默认使用的仿函数为 less,所以 set 中的元素默认按照小于来比较;
- 由于 set 底层是平衡树搜索树,所以 set 中查找某个元素,时间复杂度为 O(logN);
- set 中的元素不允许修改,因为这可能破坏搜索树的结构;
- set 中的底层使用平衡二叉搜索树 (红黑树) 来实现。
注:可能有的同学对 O(logN) 的时间复杂度没有什么具体的概念,那么我们可以列举一组数据大家就很清楚了:set 从1000个数据找查找某个数据最多找10次,从100万个数据中找某一个数据最多找20次,从10亿个数据中找某一个数据最多找30次;换一种说法,如果以身份证号作为 key 值存入 set 中 (假设内存足够),那么我们从地球所有人类中查找某一个身份证号对应的人时最多只用找 31 次;相信现在大家对 O(logN) 是什么量级的存在已经有了很清楚的认识了。
2、set 的使用
构造
和传统容器一样,set 也支持单个元素构造、迭代器区间构造以及拷贝构造:
迭代器
迭代器也一样,包括正向迭代器和反向迭代器,正向和反向又分为 const 和 非const:
修改
set 有如下修改操作:
其中 swap 就是交换两棵树的根,clear 就是释放树中的所有节点,emplace 和 emplace_hint 我们放在 C++11 章节中学习,大家现在不用管它;最重要的修改操作是 insert 和 erase;
insert 支持插入一个值、在某个迭代器位置插入值、插入一段迭代器区间,我们学会第一个即可,插入的过程就是二叉搜索树的插入过程;需要注意的是 insert 的返回值是 pair 类型,pair 中第一个元素代表插入的迭代器位置,第二个元素代表是否插入成功 (插入重复节点会返回 false):
erase 也有三种,常用的是第一种和第二种,删除指定键值的数据和删除指定迭代器位置的数据:
操作
set 还有一些其他操作相关的函数:
其中比较重要的只有 find,由于 set 中不允许出现相同的 key,因此在 set 中 count 函数的返回值只有1/0,可以说没有什么价值,set 中定义 count 主要是因为 count 在 multiset 中有作用,这里是为了保持一致;lower_bound 和 upper_bound 是得到一个左闭右开的迭代器区间,然后我们可以对这段区间进行某些操作,但实际中其实没什么人用;
find 的作用是在搜索树中查找 key 对应的节点,然后返回节点位置的迭代器,如果找不到,find 会返回 end():
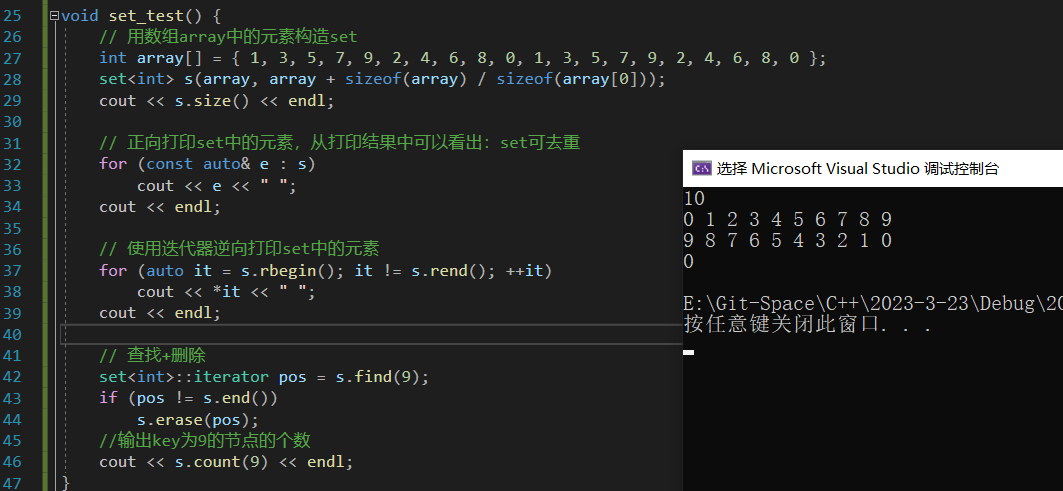
set 使用范例
void set_test() {// 用数组array中的元素构造setint array[] = { 1, 3, 5, 7, 9, 2, 4, 6, 8, 0, 1, 3, 5, 7, 9, 2, 4, 6, 8, 0 };set<int> s(array, array + sizeof(array) / sizeof(array[0]));cout << s.size() << endl;// 正向打印set中的元素,从打印结果中可以看出:set可去重for (const auto& e : s)cout << e << " ";cout << endl;// 使用迭代器逆向打印set中的元素for (auto it = s.rbegin(); it != s.rend(); ++it)cout << *it << " ";cout << endl;// 查找+删除set<int>::iterator pos = s.find(9);if (pos != s.end())s.erase(pos);//输出key为9的节点的个数cout << s.count(9) << endl;
}
如果大家对 set 的使用还有不清楚的地方,建议查阅 set 文档:set - C++ Reference (cplusplus.com)
三、multiset
multiset 的介绍
multiset 也是 K模型 的容器,它和 set 唯一的区别在于 multiset 中允许存在重复的 key 值节点,所以 multiset 可以用来排序和查找,但是不能用来去重。
multiset 的使用
multiset 的使用其实和 set 也几乎一样,唯一需要注意的是 find 和 count 函数 – 由于 multiset 中允许存在重复 key 值的节点,所以 multiset 中 count 函数就有作用了,我们可以通过 count 函数来统计同一 key 中在 multiset 中的数量:
multiset 中 find 函数的使用也和 set 有所区别 – 由于 set 中没有重复的节点,所以 find 时要么返回该节点位置的迭代器,要么返回 end();而 multiset 中可能有重复的节点,所以 find 时返回的是同一 key 值中的哪一个节点呢?实际上 find 返回的是中序遍历过程中第一个匹配的节点位置的迭代器:
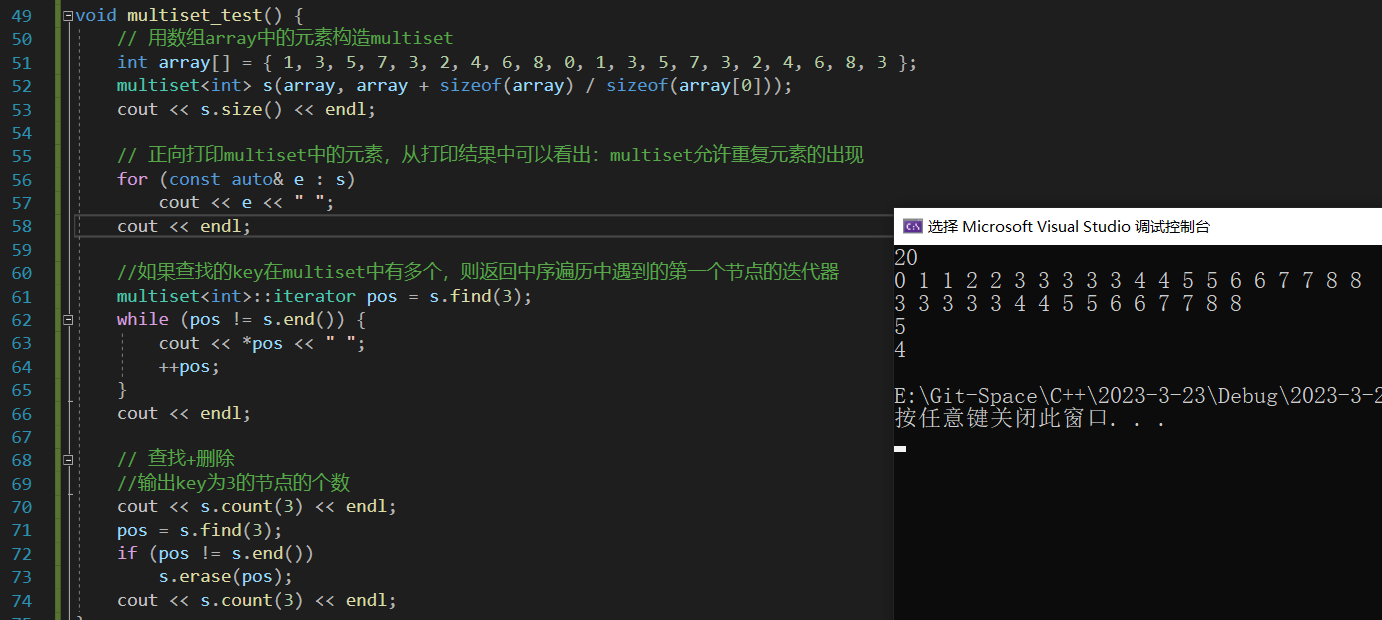
multiset 使用范例
void multiset_test() {// 用数组array中的元素构造multisetint array[] = { 1, 3, 5, 7, 3, 2, 4, 6, 8, 0, 1, 3, 5, 7, 3, 2, 4, 6, 8, 3 };multiset<int> s(array, array + sizeof(array) / sizeof(array[0]));cout << s.size() << endl;// 正向打印multiset中的元素,从打印结果中可以看出:multiset允许重复元素的出现for (const auto& e : s)cout << e << " ";cout << endl;//如果查找的key在multiset中有多个,则返回中序遍历中遇到的第一个节点的迭代器multiset<int>::iterator pos = s.find(3);while (pos != s.end()) {cout << *pos << " ";++pos;}cout << endl;// 查找+删除//输出key为3的节点的个数cout << s.count(3) << endl;pos = s.find(3);if (pos != s.end())s.erase(pos);cout << s.count(3) << endl;
}
如果大家对 multiset 的使用还有不清楚的地方,建议查阅 multiset 文档:multiset - C++ Reference (cplusplus.com)
四、map
1、map 的介绍
map 和 set 一样都是按照一定次序存储元素的容器,其底层也是一棵平衡二叉搜索树;和 set 不同的是,map 是 KV模型 的容器,在map 中,键值 key 通常用于排序和惟一地标识元素,而值 value中 用于存储与此键值 key 关联的内容,键值 key 和值value的类型可以不同;在 map 内部,key-value 通过成员类型 pair 绑定在一起,也就是我们文章开始提到的键值对;
需要注意的是:map 中的元素是按照键值 key 进行比较排序的,而与 key 对应的 value 无关,同时,map 中也不允许有重复 key 值的节点;map 也可用于排序、查找和去重,且 map 查找的时间复杂度也为 O(logN)。
特别注意:map 允许修改节点中 key 对应的 value 的值,但是不允许修改 key,因为这样可能会破坏搜索树的结构。
2、map 的使用
构造

迭代器

修改

修改中的重点的仍然是 insert 和 erase,swap 为交换两棵树的根,clear 为释放树中的每一个节点;
和 set 一样,map 的 insert 也支持插入一个值、在某个迭代器位置插入值、插入一段迭代器区间,我们还是学会第一个即可,插入的过程就是二叉搜索树的插入过程;需要注意的是 insert 的返回值是 pair 类型,pair 中第一个元素代表插入的迭代器位置,第二个元素代表是否插入成功 (插入重复节点会返回 false)::
erase 一样也有三种,常用的是第一种和第二种,删除指定键值的数据和删除指定迭代器位置的数据:
元素访问
需要重点注意的是,map 重载了 [] 运算符,其函数原型如下:
//mapped_type: pair中第二个参数,即first
//key_type: pair中第一个参数,即second
mapped_type& operator[] (const key_type& k);
函数定义如下:
mapped_type& operator[] (const key_type& k)
{(*((this->insert(make_pair(k, mapped_type()))).first)).second;
}
可以看到,map 中 operator[] 函数的实现看起来非常复杂,我们可以将它拆解一下:
V& operator[] (const K& k)
{pair<iterator, bool> ret = insert(make_pair(k, V()));//return *(ret.first)->second;return ret.first->second;
}
可以看到,operator[] 函数会先向 map 中插入 k,这里插入的结果有两种 – 如果 map 中已经有与该值相等的节点,则插入失败,返回的 pair 中存放着该节点位置的迭代器和false;如果 map 中没有与该值相等的节点,则会向 map 中插 key 值等于 k 的节点,该节点对应的 value 值为 V 默认构造的缺省值;
然后,operator[] 会取出 pair 中的迭代器 (ret.first),然后对迭代器进行解引用得到一个 pair<k, v> 对象,最后再返回排 pair 对象中的 second 的引用,即 key 对应的 value 的引用;所以我们可以在函数外部直接修改 key 对应的 value 的值。
所以,map 中的 operator[] 是集插入、查找、修改为一体的一个函数;示例如下: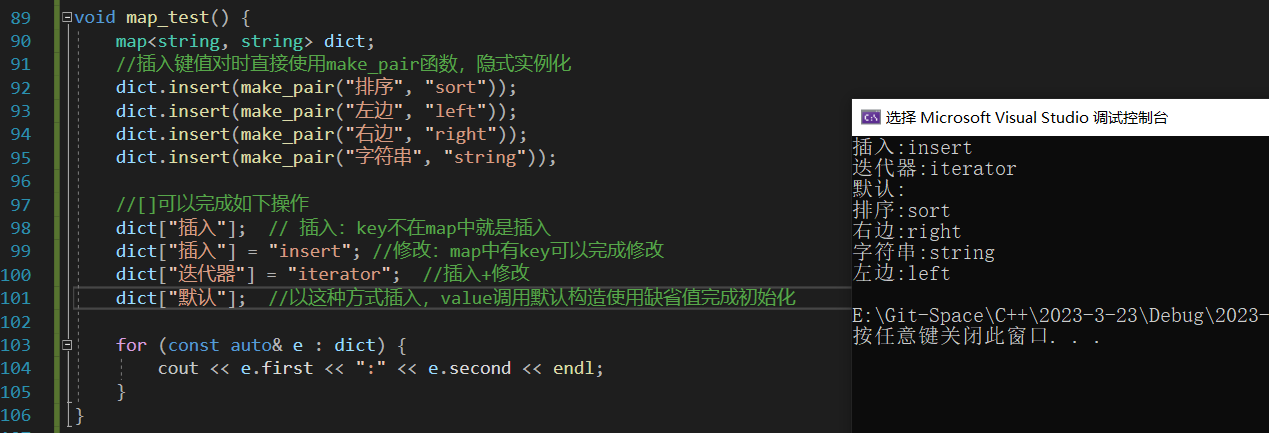
注意:
- 这里修改的是 key 对应的 value,而并没有修改 key,所以并没有破坏搜索树的结构;
- 我们上面拆解 operator[] 函数时之所以能将 *(ret.first)->second 改写为 ret.first->second 是因为编译器为了可读性省略了一个 -> 操作符,实际上应该是 ret.first->->second;关于这里的细节我在 list 模拟实现 中说过,有兴趣的可以去看看。
操作
和 set 一样,map 中有 count 函数是因为 multimap 需要count 函数,这里是为了保持一致性:
map 使用范例
void map_test() {map<string, string> m;//向map中插入元素的方式:用pair直接来构造键值对m.insert(pair<string, string>("peach", "桃子"));//为了方便,我们建议直接用make_pair函数来构造键值对m.insert(make_pair("banan", "香蕉"));// 借用operator[]向map中插入元素,operator[]的原理如下://--------------------------------------------------------------------------------------//// 用<key, T()>构造一个键值对,然后调用insert()函数将该键值对插入到map中// 如果key已经存在,插入失败,insert函数返回该key所在位置的迭代器// 如果key不存在,插入成功,insert函数返回新插入元素所在位置的迭代器// operator[]函数最后将insert返回值键值对中的value返回// 注意:通过[]插入的键值对的value使用默认构造完成初始化,我们需要通过修改[]的返回值来对其重新赋值//---------------------------------------------------------------------------------------//// 将<"apple", "">插入map中,插入成功,返回value的引用,将“苹果”赋值给该引用结果,m["apple"] = "苹果";// 用迭代器去遍历map中的元素,可以得到一个按照key排序的序列for (auto& e : m)cout << e.first << ":" << e.second << endl;cout << endl;// map中的键值对key一定是唯一的,如果key存在将插入失败auto ret = m.insert(make_pair("peach", "桃色"));if (ret.second)cout << "<peach, 桃色>不在map中, 已经插入" << endl;elsecout << "键值为 peach 的元素已经存在:" << ret.first->first << "--->" << ret.first->second << " 插入失败" << endl;// 删除key为"apple"的元素m.erase("apple");if (1 == m.count("apple"))cout << "apple还在" << endl;elsecout << "apple被吃了" << endl;
}
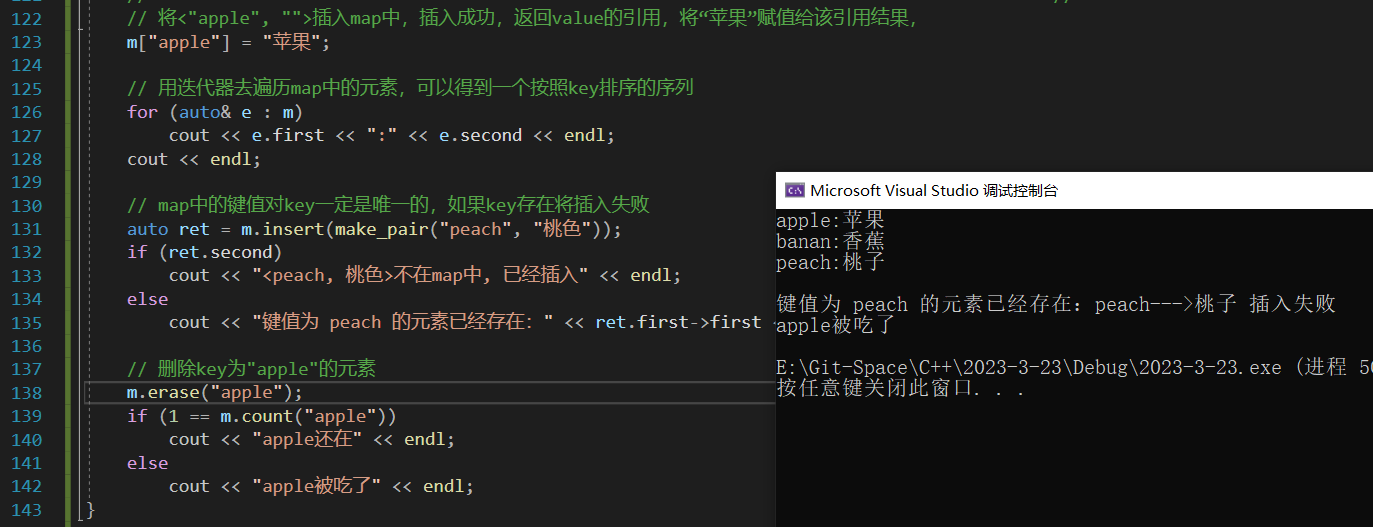
如果大家对 map 的使用还有不清楚的地方,建议查阅 map 使用文档:map - C++ Reference (cplusplus.com)
五、multimap
和 set 与 multiset 的关系一样,multimap 存在的意义是允许 map 中存在 key 值相同的节点,multimap 与map 的区别和 multiset 与 set 的区别一样 – find 返回中序遍历中遇到的第一个节点的迭代器,count 返回和 key 值相等的节点的个数:

需要注意的是,multimap 中并没有重载 [] 运算符,因为 multimap 中的元素是可以重复的,如果使用 [] 运算符,会导致多个元素的 key 值相同,无法确定具体访问哪一个元素。
如果大家对 multimap的使用还有不清楚的地方,建议查阅 multimap文档:multimap - C++ Reference (cplusplus.com)
相关文章:
【C++】map 和 set
文章目录一、关联式容器与键值对1、关联式容器2、键值对 pair3、树形结构的关联式容器二、set1、set 的介绍2、set 的使用三、multiset四、map1、map 的介绍2、map 的使用五、multimap一、关联式容器与键值对 1、关联式容器 在C初阶的时候,我们已经接触了 STL 中的…...
基于SpringBoot的酒店管理系统
系统环境 开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7(一定要5.7版本) 数据库工具:Navicat11 开发软件:eclipse/myeclipse/i…...

JAVA框架知识整理
框架知识整理 SpringBoot、SpringMVC、Spring的区别和他们的作用? SpringBoot是一个微服务框架,其简化了Spring应用的创建、运行、测试、部署。使开发人员无需过多的关注XML配置。里面整合了许多框架例如SpringMVC、Spring Security和Spring Data JPA。…...
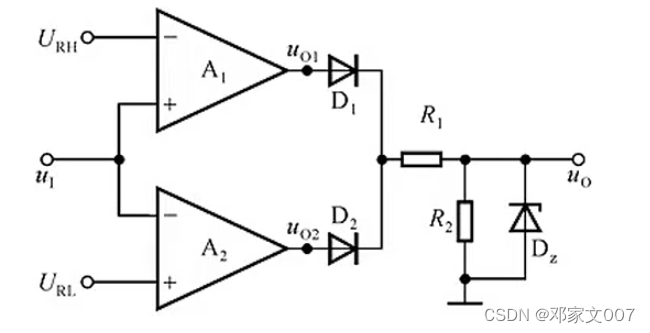
运算放大器:电压比较器
目录一、单限电压比较器二、滞回电压比较器三、窗口电压比较器最近在学习电机控制,遇到了与运算放大电路相关的知识,然而太久没有接触模拟电路,对该知识已经淡忘了,及时温故而知新,做好笔记,若有错误、不足…...
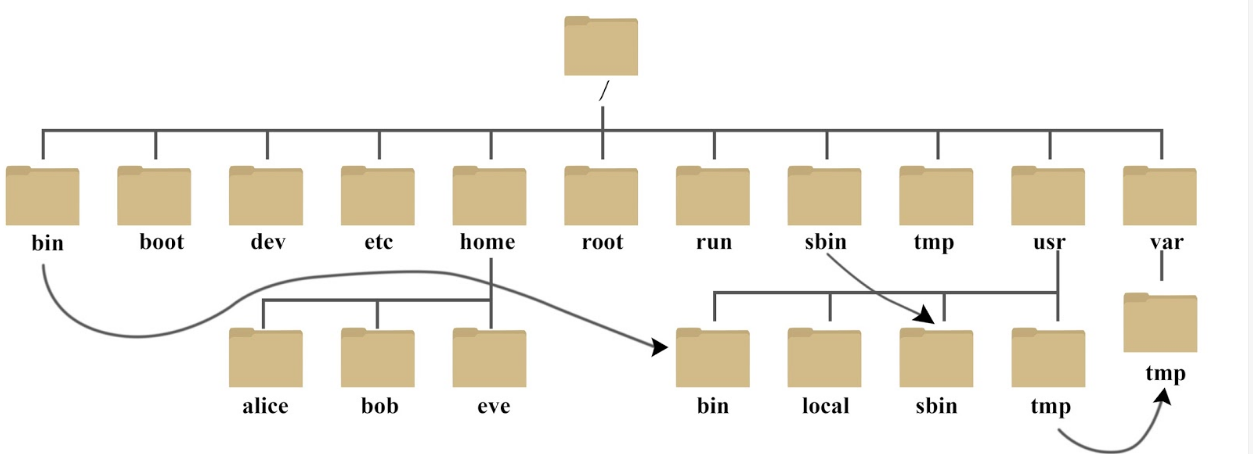
Linux的基础知识
根目录和家目录根目录:是Linux中最底层的目录,用"/"表示家目录:当前用户所在的路径,用“~”表示,root用户的家目录和普通用户的家目录不一样,普通用户的家目录在/home路径下,每一个用…...

【JavaEE】 IntelliJ IDEA 2022.2最新版Tomcat导入依赖详细教程全解及创建第一个Servlet程序
目录 一、软件资源 二、放置settings.xml文件 三、创建项目 四、引入依赖 五、创建目录 六、编写代码 写在前面:☞What is Servlet? Servlet其实是一种实现动态页面的技术。是一组由Tomcat提供给程序员的API(应用程序编程接口)…...

常见的卷积神经网络结构——分类、检测和分割
本文持续更新~~ 本文整理了近些年来常见的卷积神经网络结构,涵盖了计算机视觉领域的几大基本任务:分类任务、检测任务和分割任务。对于较复杂的网络,本文只会记录其中的核心模块以及重要的网络设计思想,并不会记录完整的网络结构。…...

20230323英语学习
Why Can You “Hear the Ocean” in Seashells? 为啥能在贝壳里“听见海的声音”? We’re told a number of stories as kids. One of the more harmless of these little lies is the one about seashells.You know the one: hold up a seashell to your ear, an…...

【粉丝投稿】上海某大厂的面试题,岗位是测开(25K*16)
简单介绍一句,大专出身,三年经验。跳了四次槽,面试了无数次,现在把自己的面试经验整理出来分享给大家,堪称必杀技! 1,一切从实际出发,对实际工作进行适当修饰 2,不会的简…...

shell简单使用介绍
脚本的基本元素声明,在解释并执行当前脚本文件中的语句之前,需要声明使用的命令解释器#一般写的解释器为 #!/bin/bash这里的#不再是注释了,而是必要的声明命令,也就是需要执行的语句注释,对代码进行解释说明分为单行注…...

RK3568平台开发系列讲解(调试篇)内核函数调用堆栈打印方法汇总
🚀返回专栏总目录 文章目录 一、dump_stack 函数二、WARN_ON(condition)函数三、BUG_ON (condition)函数四、panic (fmt...)函数沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇将对驱动调试方法进行汇总学习。 一、dump_stack 函数 dump_stack 作用:打印内核调…...

一次内存泄露排查
前因: 因为测试 长时间压测导致 接口反应越来越慢,甚至 导致服务器 崩溃 排查过程 1、top 查看是 哪个进程 占用 内存过高 2、根据 进程 id 去查找 具体是哪个 程序的问题 ps -ef| grep 41356 可以看到 具体的 容器位置 排查该进程 对象存活 状态…...
「Mac安装ps」Adobo Photoshop 2023 下载安装详情教程,支持 AI 插件的 24 版 Photoshop
前言 Adobo Photoshop 2023 已推出,由于目前AI人工智能技术火爆,而很多的 AI 插件最低也需要24版的 photoshop ,所以这里我遍搜集并整理了此新版本的 photoshop 安装使用教程,后续也将提供 AI 插件的下载安装教程 安装文件下载 …...

Redis单线程还是多线程?IO多路复用原理
目录专栏导读一、Redis版本迭代二、Redis4.0之前为什么一直采用单线程?三、Redis6.0引入多线程四、Redis主线程和IO线程是如何完成请求的?1、服务端和客户端建立socket连接2、IO线程读取并解析请求3、主线程执行请求命令4、IO线程会写回socket和主线程清…...
小菜鸟Python历险记:(第五集)
今天写的文章是记录我从零开始学习Python的全过程。在Python中对方法进行备注的时候,往往都是写在方法中的第一行所在位置。在书写注释以后,在调用方法的时候,鼠标点击方法会有一个浮动的提示显示备注内容。具体如下图所示:注释的…...
【思维模型】五分钟了解<复利思维>,为何学习复利思维?什么是复利思维?如何应用复利思维?
【思维模型】五分钟了解<复利思维>,为何学习复利思维?什么是复利思维?如何应用复利思维?1. 为何学习复利思维?2. 什么是复利思维?3. 如何应用复利思维?4. 小结参考&#…...

Vue.js语法详解:从入门到精通
Vue.js是一个流行的JavaScript框架,用于构建用户界面。它的核心特性包括数据双向绑定、组件化架构、虚拟DOM和响应式系统等。在本文中,我们将深入探讨Vue.js的语法,帮助读者更好地理解和应用Vue.js。1.模板语法Vue.js的模板语法采用了类似HTM…...

程序员的代码行数越少越好?
有些人可能会认为,应用程序中的代码行越少,就越容易阅读。这句话只有部分正确,我认为代码可读性的度量标准包括:代码应具备一致性代码应具备自我描述性代码应具备良好的文档代码应使用稳定的现代功能代码不应过于复杂代码的性能不…...

【每日一题Day156】LC1032字符流 | 字典树
字符流【LC1032】 设计一个算法:接收一个字符流,并检查这些字符的后缀是否是字符串数组 words 中的一个字符串。 例如,words ["abc", "xyz"] 且字符流中逐个依次加入 4 个字符 a、x、y 和 z ,你所设计的算法…...
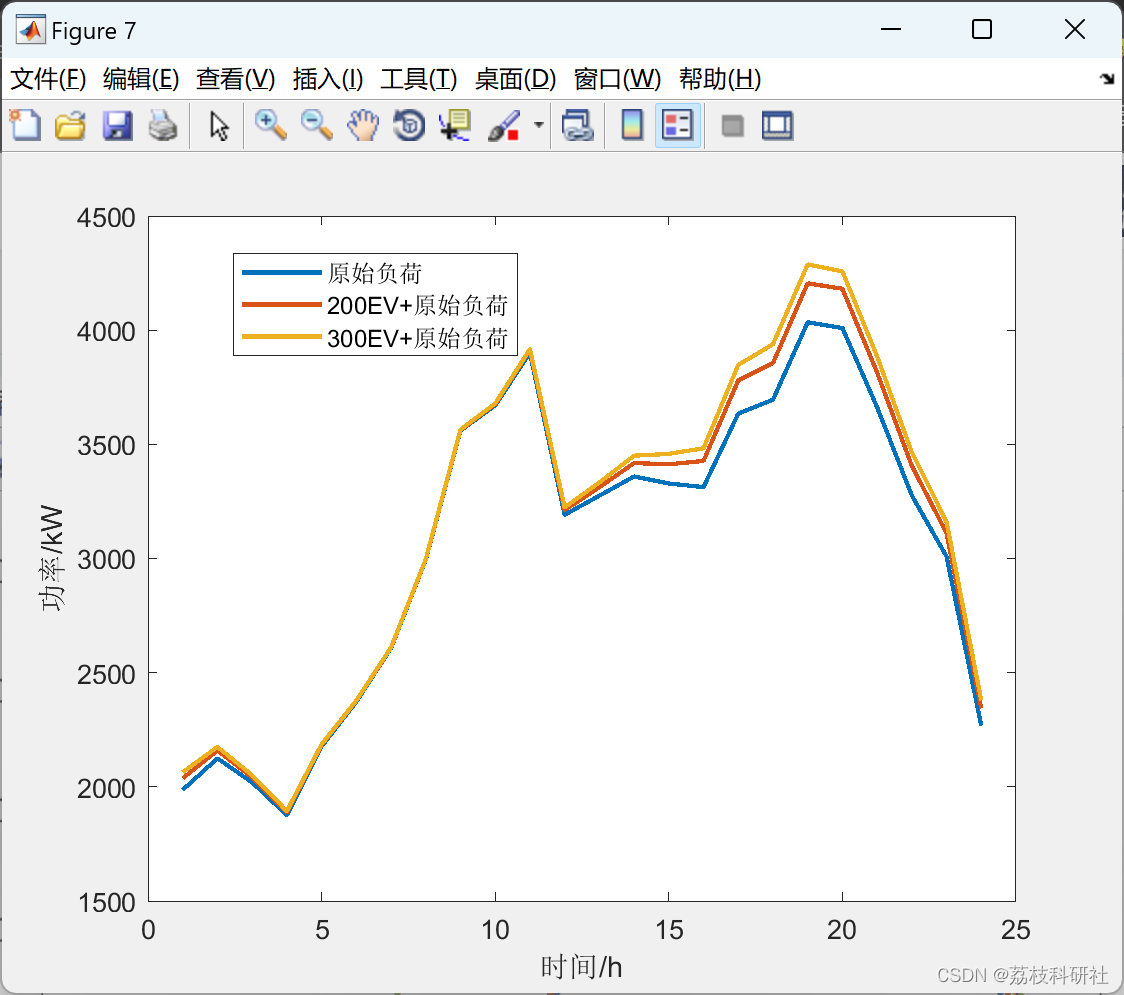
V2G模式下含分布式能源网优化运行研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 📋📋📋本文目录如下:🎁🎁🎁 目录 💥1 概述 📚2 运行结果 &am…...

Mamba-X:为Vision Mamba模型定制的边缘AI硬件加速器架构解析
1. 项目概述:当视觉Transformer遇上状态空间模型最近在边缘AI硬件加速的圈子里,一个名为“Mamba-X”的设计概念开始被频繁讨论。这名字听起来有点神秘,但核心其实很明确:它瞄准的是当下两个最火热的AI架构趋势——Vision Transfor…...

LeetCode 560:和为 K 的子数组 | 前缀和与哈希表
LeetCode 560:和为 K 的子数组 | 前缀和与哈希表 引言 和为 K 的子数组(Subarray Sum Equals K)是 LeetCode 第 560 题,难度为 Medium。题目要求在给定整数数组中找出连续子数组的元素和等于 K 的数量。这道题是前缀和与哈希表结合…...

电池阻抗测量技术:伪随机序列与信号处理应用
1. 电池阻抗测量技术概述电池阻抗测量作为电化学系统状态监测的核心手段,其原理基于对电池施加特定激励信号并测量响应信号,通过分析两者的幅值和相位关系来获取阻抗谱。这种频域分析方法能够反映电池内部电荷转移、扩散过程等动力学特性,为电…...

Rust内存管理模式:从所有权到智能指针的完整指南
引言 作为一名从Python转向Rust的后端开发者,我深刻体会到Rust内存管理的革命性设计。与Python的自动垃圾回收不同,Rust通过所有权系统在编译时保证内存安全,无需运行时开销。本文将深入探讨Rust的内存管理模式,从所有权规则到智…...

Unity手游Mono堆泄漏:80MB硬限下的静默崩溃真相
1. 这不是GC没跑,是Mono堆在 silently 溢出——一个被90% Unity手游团队忽视的“假稳定”现象你有没有遇到过这样的情况:游戏在编辑器里跑得飞快,Profiler显示GC调用次数极少,内存曲线平滑得像湖面;但一打包到Android真…...

CVE、CNVD、CNNVD、NVD四大漏洞编号体系深度解析
1. 这些字母组合不是密码,而是漏洞世界的“身份证号” 刚入行做安全运维那会儿,我在日报里看到一条告警:“检测到 CVE-2021-44228 漏洞利用尝试”,顺手抄下来准备查资料,结果一搜发现——同一款 Log4j 组件,…...

ArcGIS Pro 3.7 重磅升级!这四大模块更新,让GIS效率翻倍
ArcGIS Pro 3.7 正式发布,这次不仅性能大幅提升,还带来了 GeoAI 工具集、实时等高线、本地知识图谱等一系列“黑科技”。无论你是制图师、空间分析师还是开发者。 01 性能与生产力:更快、更顺、更好找 新增「分析地图」窗格 可量化评估地图的…...
)
AI Agent在政务审批系统中的零故障部署实践(工信部试点项目全链路复盘)
更多请点击: https://codechina.net 第一章:AI Agent在政务审批系统中的零故障部署实践(工信部试点项目全链路复盘) 在工信部“智能政务基础设施升级”试点项目中,某省政务服务网完成全国首个面向全流程审批闭环的AI …...

前端实习面试手写题分享
在寻找前端实习的过程中,我们会发现,面试除了考察算法题之外,手写题同样也是高频考点。尤其是在准备中大厂前端面试时,手写能力几乎是必不可少的一部分。这篇文章将围绕几道经典高频手写题展开,包括手写深拷贝、实现寄…...

【电子通识】贴片电阻上的丝印332、5R6、1502、01C怎么读出阻值?
背景 【电子通识】为什么大多数插件电阻使用色环表示阻值-CSDN博客中我们讲到了色环电阻怎么读出电阻值,那么我们现在在一些更精密的电路板上看到的贴片电阻要怎么读出电阻值呢? 一般来说除小于0402封装的贴片电阻外,我们可以看到贴片电阻上都…...