强化学习之Actor-Critic算法(基于值函数和策略的结合)——以CartPole环境为例
0.简介
DQN算法作为基于值函数的方法代表,基于值函数的方法只学习一个价值函数。REINFORCE算法作为基于策略的方法代表,基于策略的方法只学习一个策略函数。Actor-Critic算法则结合了两种学习方法,其本质是基于策略的方法,因为其目标是优化一个带参的策略,只是会额外学习价值函数帮助策略函数更好地学习。
我们回顾一下在 REINFORCE 算法中,目标函数的梯度中有一项轨迹回报,来指导策略的更新。而值函数的概念正是基于期望回报,我们能不能考虑拟合一个值函数来指导策略进行学习呢?这正是 Actor-Critic 算法所做的。让我们先回顾一下策略梯度的形式,在策略梯度中,我们可以把梯度写成下面这个形式:
其中 ψ t 可以有很多种形式:
在 REINFORCE 的最后部分,我们提到了 REINFORCE通过蒙特卡洛采样的方法对梯度的估计是无偏的,但是方差非常大,我们可以用第三种形式引入基线 (baseline) b ( s t ) 来减小方差。此外我们也可以采用 Actor-Critic 算法,估计 一个动作价值函数 Q 来代替蒙特卡洛采样得到的回报,这便是第 4 种形式。这个时候,我们也可以把状态价值函数 V 作为基线,从偍牧但是用神经网络进行估计的方法可以减小方差、提高鲁棒性。除此之外,REINFORCE 算法基于蒙特卡洛采样,只能在序列结束后进行更新,而 Actor-Critic 的方法则可以在每一步之后都进行更新。
我们将 Actor-Critic 分为两个部分: 分别是 Actor (策略网络) 和 Critic (价值网络):
- Critic 要做的是通过 Actor 与环境交互收集的数据学习一个价值函数,这个价值函数会用于帮助 Actor 进行更新策略。
- Actor 要做的则是与环境交互,并利用 Ctitic 价值函数来用策略梯度学习一个更好的策略。
与 DQN 中一样,我们采取类似于目标网络的方法,上式中 r + γ V ω ( s t + 1 )作为时序差分目标,不会产生梯度来更新价值函数。所以价值函数的梯度为
然后使用梯度下降方法即可。接下来让我们总体看看 Actor-Critic 算法的流程吧!
- 初始化策略网络参数 θ ,价值网络参数 ω
- 不断进行如下循环 (每个循环是一条序列) :
。 用当前策略 π θ 平样轨 迹 { s 1 , a 1 , r 1 , s 2 , a 2 , r 2 … }
。 为每一步数据计算: δ t = r t + γ V ω ( s t + 1 ) − V ω ( s )
。 更新价值参数 w = w + α ω ∑ t δ t ∇ ω V ω ( s )
。 更新策略参数 θ = θ + α θ ∑ t δ t ∇ θ log π θ ( a ∣ s )
好了!这就是 Actor-Critic 算法的流程啦,让我们来用代码实现它看看效果如何吧!
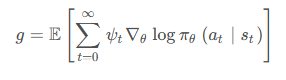

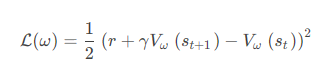
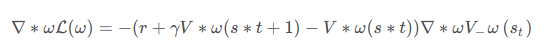
1.导库
import gym
import torch
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm2.策略网络PolicyNet定义
class PolicyNet(torch.nn.Module):#策略网络def __init__(self,statedim,hiddendim,actiondim):super(PolicyNet,self).__init__()self.fc1=torch.nn.Linear(statedim,hiddendim)self.fc2=torch.nn.Linear(hiddendim,actiondim)def forward(self,x):x=torch.nn.functional.relu(self.fc1(x))return torch.nn.functional.softmax(self.fc2(x),dim=1)3.价值网络ValueNet定义
class ValueNet(torch.nn.Module):#价值网络def __init__(self,statedim,hiddendim):super(ValueNet,self).__init__()self.fc1=torch.nn.Linear(statedim,hiddendim)self.fc2=torch.nn.Linear(hiddendim,1)def forward(self,x):x=torch.nn.functional.relu(self.fc1(x))return self.fc2(x)4.ActorCritic算法实现
class ActorCritic:#演员-评论家算法def __init__(self,statedim,hiddendim,actiondim,actor_learningrate,critic_learningrate,gamma,device):self.actor=PolicyNet(statedim,hiddendim,actiondim).to(device)#策略网络self.critic=ValueNet(statedim,hiddendim).to(device)#价值网络self.actor_optimizer=torch.optim.Adam(self.actor.parameters(),lr=actor_learningrate)#策略网络优化器self.critic_optimizer=torch.optim.Adam(self.critic.parameters(),lr=critic_learningrate)#价值网络优化器self.gamma=gammaself.device=devicedef takeaction(self,state):#根据策略网络采取动作state=torch.tensor([state],dtype=torch.float).to(self.device)probs=self.actor(state)actiondist=torch.distributions.Categorical(probs)action=actiondist.sample()return action.item()#返回选择的动作的索引的标量形式def update(self,transitiondist):#更新策略网络和价值网络states,actions,rewards,nextstates,dones=transitiondist["states"],transitiondist["actions"],transitiondist["rewards"],transitiondist["nextstates"],transitiondist["dones"]states=torch.tensor(states,dtype=torch.float).to(self.device)actions=torch.tensor(actions).view(-1,1).to(self.device)rewards=torch.tensor(rewards,dtype=torch.float).view(-1,1).to(self.device)nextstates=torch.tensor(nextstates,dtype=torch.float).to(self.device)dones=torch.tensor(dones,dtype=torch.float).view(-1,1).to(self.device)td_target=rewards+self.gamma*self.critic(nextstates)*(1-dones)#时序差分目标td_delta=td_target-self.critic(states)#时序差分误差log_probs=torch.log(self.actor(states).gather(1,actions))#.detach() 来创建一个与原始张量值相同但不可训练的副本。这个副本可以在不影响原始张量的情况下进行各种操作,并且不会在反向传播中被更新。actor_loss=torch.mean(-log_probs*td_delta.detach())#策略网络的损失函数;#.detach()的作用是将这个张量从计算图中分离出来,这样在计算损失时不会对其进行反向传播,通常是为了防止某些不希望被更新的部分被意外更新。critic_loss=torch.mean(torch.nn.functional.mse_loss(self.critic(states),td_target.detach()))#均方差损失函数self.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()actor_loss.backward()#计算策略网络的梯度critic_loss.backward()#计算价值网络的梯度self.actor_optimizer.step()#策略网络参数更新self.critic_optimizer.step()#价值网络参数更新5.训练本算法的函数实现
def train_on_policy_agent(env,agent,episodesnum,pbarnum,printreturnnum,seedid):#训练演员-评论家算法returnlist=[]for k in range(pbarnum):with tqdm(total=int(episodesnum/pbarnum),desc='Iteration %d' % k) as pbar:for episode in range(int(episodesnum/pbarnum)):episodereturn=0transitiondist={"states":[],"actions":[],"nextstates":[],"rewards":[],"dones":[]}state=env.reset(seed=seedid)[0]done=Falsewhile not done:action=agent.takeaction(state)nextstate,reward,done,truncated,_=env.step(action)done=done or truncatedtransitiondist["states"].append(state)transitiondist["actions"].append(action)transitiondist["nextstates"].append(nextstate)transitiondist["rewards"].append(reward)transitiondist["dones"].append(done)state=nextstateepisodereturn+=rewardreturnlist.append(episodereturn)agent.update(transitiondist)if (episode+1)%(printreturnnum)==0:pbar.set_postfix({"episode":"%d"%(episodesnum/pbarnum*k+episode+1),"return":"%.3f"%np.mean(returnlist[-printreturnnum:])})pbar.update(1)return returnlist6.移动平滑处理时间序列函数实现
def moving_average(a, window_size):cumulative_sum = np.cumsum(np.insert(a, 0, 0)) middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_sizer = np.arange(1, window_size-1, 2)begin = np.cumsum(a[:window_size-1])[::2] / rend = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]return np.concatenate((begin, middle, end))7.参数配置
actor_learningrate=1e-3
critic_learningrate=1e-2
episodesnum=1000
hiddendim=128
gamma=0.98
pbarnum=10
printreturnnum=10
seedid=0
device=torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")8.车杆环境实验
env=gym.make("CartPole-v1")#env=gym.make("CartPole-v1",render_mode="human")
env.reset(seed=seedid)
torch.manual_seed(seedid)
statedim=env.observation_space.shape[0]
actiondim=env.action_space.n
agent=ActorCritic(statedim,hiddendim,actiondim,actor_learningrate,critic_learningrate,gamma,device)
returnlist=train_on_policy_agent(env,agent,episodesnum,pbarnum,printreturnnum,seedid)
episodelist=list(range(len(returnlist)))
plt.plot(episodelist,returnlist)
plt.xlabel("Episodes")
plt.ylabel("Returns")
plt.title("Actor-Critic on {}-{}".format(env.spec.name,env.spec.id))
plt.show()
mvreturn=moving_average(returnlist,9)
plt.plot(episodelist,mvreturn)
plt.xlabel("Episodes")
plt.ylabel("Returns")
plt.title("Actor-Critic on {}-{}".format(env.spec.name,env.spec.id))
plt.show()9.实验结果


Actor-Critic算法很快收敛到最优策略,训练过程非常稳定,抖动情况与REINFORCE算法相比有了明显改进,这说明价值函数的引入减少了方差。
10.小结
Actor-Critic算法是基于值函数和基于策略的方法的叠加,价值模块Critic在策略模块Actor采样的数据中学习分辨什么是好的动作,什么是不好的动作,进而指导Actor进行策略更新,随着Actor训练不断进行,与环境交互产生的数据分布也发生改变,这需要Critic尽快适应新数据分布并给出好的判别。TRPO、PPO、DDPG、SAC等深度强化学习算法都是在Actor-Critic算法基础上进行发展改进的,其作为基础,深入理解大有裨益。
相关文章:

强化学习之Actor-Critic算法(基于值函数和策略的结合)——以CartPole环境为例
0.简介 DQN算法作为基于值函数的方法代表,基于值函数的方法只学习一个价值函数。REINFORCE算法作为基于策略的方法代表,基于策略的方法只学习一个策略函数。Actor-Critic算法则结合了两种学习方法,其本质是基于策略的方法,因为其目…...
Linux学习记录(五)-------三类读写函数
文章目录 三种读写函数1.行缓存2.无缓存3.全缓存4.fgets和fputs5.gets和puts 三种读写函数 1.行缓存 遇到新行(\n),或者写满缓存时,即调用系统函数 读:fgets,gets,printf,fprintf,sprintf写:fputs,puts,scanf 2.无缓…...
)
2024年8月13日(lvs NAT脚本 RS脚本 ds脚本)
lvs-nat模式的优点配置简单,缺点是请求和响应都必须经过ds,容易称为性能瓶颈 希望有这样的模式,请求的时候使用input链进行负载均衡,响应的时候就不要经过ds,直接由rs响应给客户端 在nat模式的时候,请求vip,接收vip的响应 构想 请求vip,接受rip响应,这是不允许lvs-dr模式 NAT脚…...

css实现水滴效果图
效果图: <template><div style"width: 100%;height:500px;padding:20px;"><div class"water"></div></div> </template> <script> export default {data() {return {};},watch: {},created() {},me…...

接口测试面试题目,你都会了吗?
面试题 什么是接口测试? 接口自动化测试的流程是什么? GET请求和POST请求区别是什么? 接口测试的常用工具有哪些? HTTP接口的请求参数类型有哪些? 如何从上一个接口获取相关的响应数据传递到下一个接口࿱…...
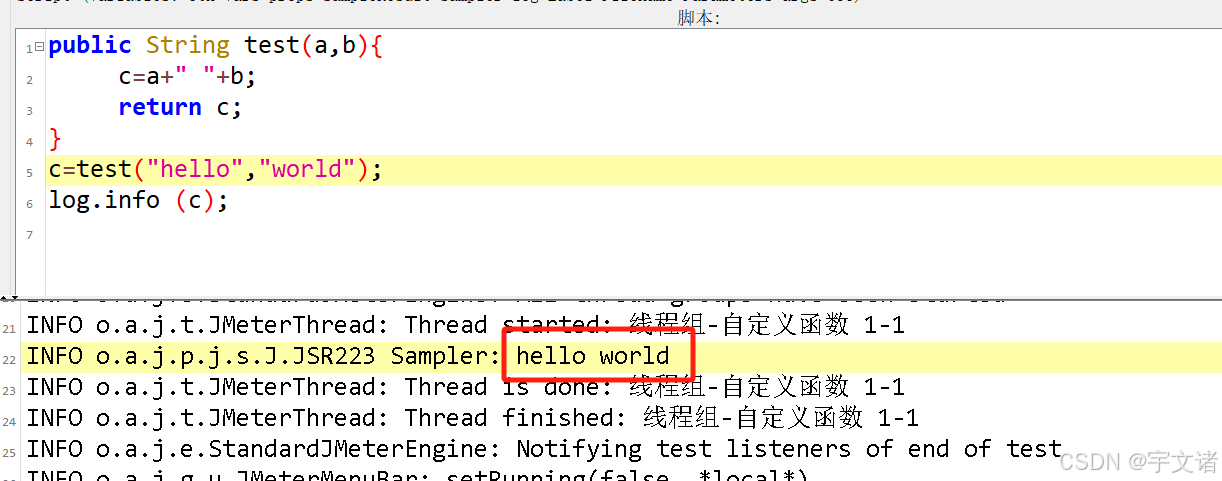
jmeter-beanshell学习16-自定义函数
之前写了一个从文件获取指定数据,用的时候发现不太好用,写了一大段,只能取出一个数,再想取另一个数,再粘一大段。太不好看了,就想到了函数。查了一下确实可以写。 public int test(a,b){return ab; } ctes…...
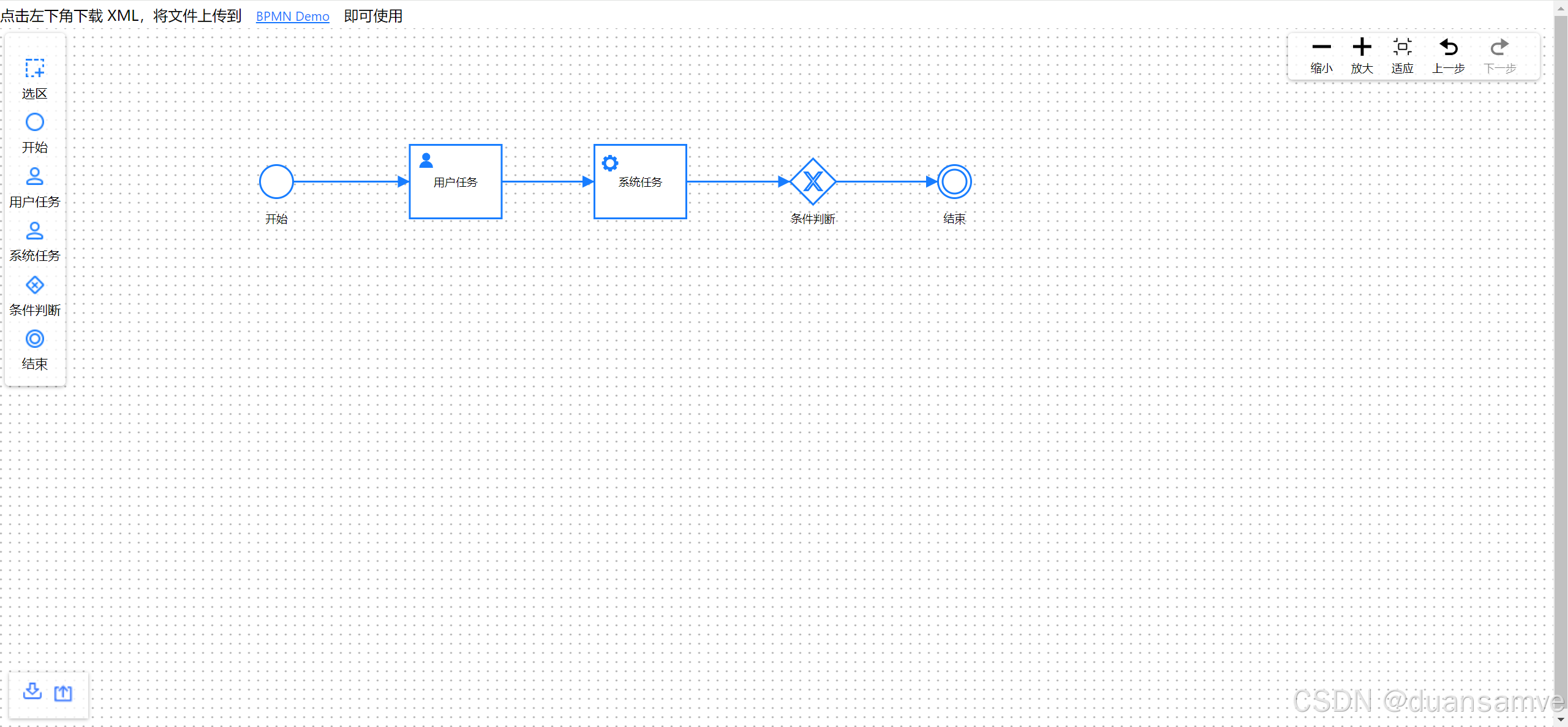
LogicFlow工作流在React和Vue3中的使用
LogicFlow 是一款流程图编辑框架,提供了一系列流程图交互、编辑所必需的功能和简单灵活的节点自定义、插件等拓展机制,方便我们快速在业务系统内满足类流程图的需求。 核心能力 可视化模型:通过 LogicFlow 提供的直观可视化界面,…...

Python循环语句:不到长城心不死
Python中的循环语句是编程中非常重要的结构,它们允许你重复执行一段代码多次,直到满足某个条件为止。Python提供了两种主要的循环类型:for循环和while循环。 文章目录 1. for 循环2. while 循环循环控制语句range() 函数结合循环语句和 rang…...
Unity教程(九)角色攻击的改进
Unity开发2D类银河恶魔城游戏学习笔记 Unity教程(零)Unity和VS的使用相关内容 Unity教程(一)开始学习状态机 Unity教程(二)角色移动的实现 Unity教程(三)角色跳跃的实现 Unity教程&…...

宠物空气净化器真的能除毛吗?有哪些选购技巧和品牌推荐修改版
夏日炎炎,有猫超甜。作为一名资深铲屎官,家里养有猫让我倍感幸福,夏天里有空调、有西瓜、有猫,这几个搭配在一起真的是超级爽。但在这么高温的夏天,家里养有宠物还是有不少烦恼的。比如家里的浮毛一直飘,似…...
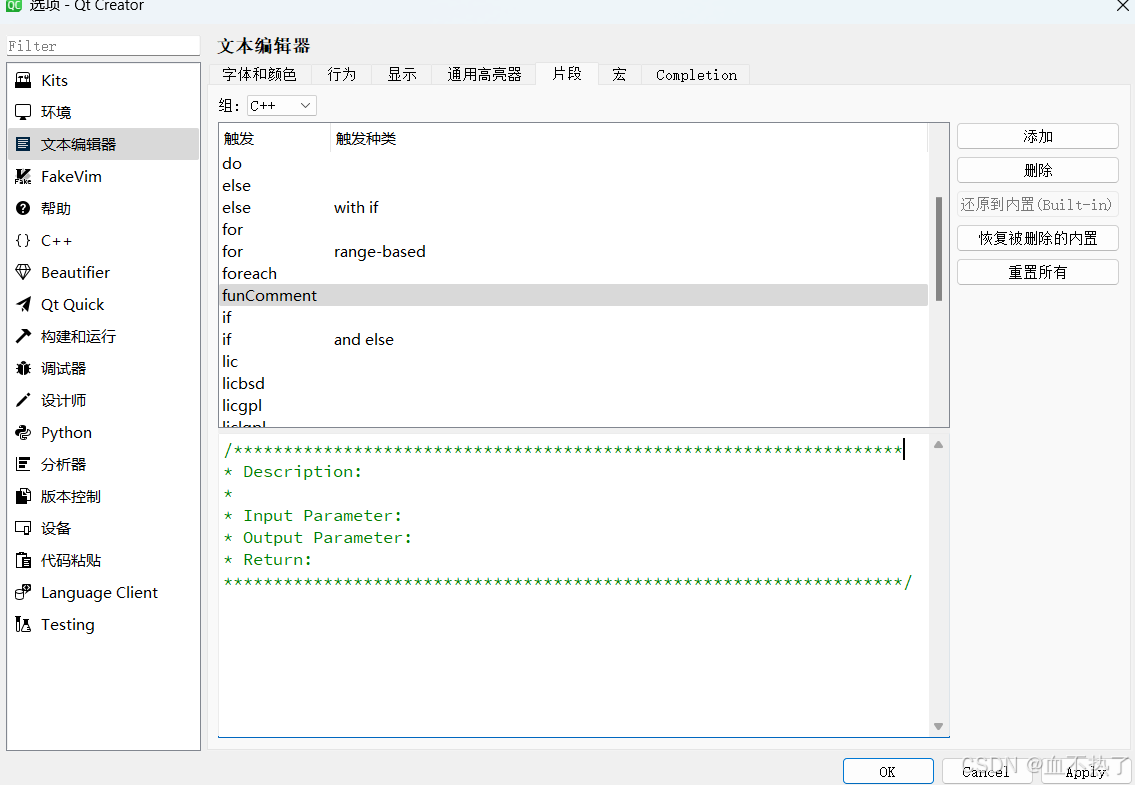
Qt自定义注释
前言 是谁在Qt中编写代码,函数注释,类注释时,注释符号一个一个的敲? comment注释brief简洁的 Detailed详细的 第一步: 打开Qt 工具->选项->文本编辑器->片段 第二步: 点击添加 然后点击OK…...
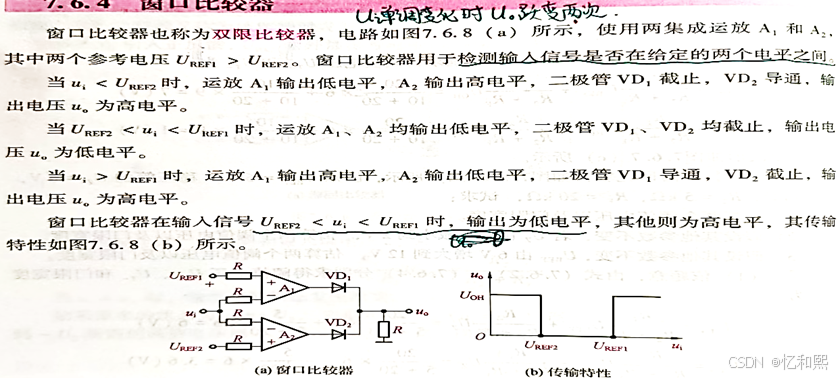
【模电笔记】——信号的运算和处理电路(含电压比较器)
tips:本章节的笔记已经打包到word文档里啦,建议大家下载文章顶部资源(有时看不到是在审核中,等等就能下载了。手机端下载后里面的插图可能会乱,建议电脑下载,兼容性更好且易于观看),…...
与==)
Java之 equals()与==
目录 运算符用途:用于比较两个引用是否指向同一个对象。比较内容:比较的是内存地址(引用)。适用范围:适用于基本数据类型和对象引用 equals() 方法用途:用于比较两个对象的内容是否相同。比较内容…...

Ubuntu20.04 运行深蓝路径规划hw1
前言 环境: ubuntu 20.04 ; ROS版本: noetic; 问题 1、出现PCL报错:#error PCL requires C14 or above catkin_make 编译时,出现如下错误 解决: 在grid_path_searcher文件夹下面的CMakeLis…...
企业如何组建安全稳定的跨国通信网络
当企业在海外设有分公司时,如何建立一个安全且稳定的跨国通信网络是一个关键问题。为了确保跨国通信的安全和稳定性,可以考虑以下几种方案。 首先,可以在分公司之间搭建虚拟专用网络。虚拟专用网络通过对传输数据进行加密,保护通信…...

WordPress原创插件:Download-block-plugin下载按钮图标美化
WordPress原创插件:Download-block-plugin下载按钮图标美化 https://download.csdn.net/download/huayula/89632743...

前端【详解】缓存
HTTP 缓存 https://blog.csdn.net/weixin_41192489/article/details/136446539 CDN 缓存 CDN 全称 Content Delivery Network,即内容分发网络。 用户在浏览网站的时候,CDN会选择一个离用户最近的CDN边缘节点来响应用户的请求 CDN边缘节点的缓存机制与HTTP 缓存相同…...

P5821 【LK R-03】密码串匹配
[题目通道](【L&K R-03】密码串匹配 - 洛谷) 一道神题。 如果没有修改操作,翻转A数组或B数组后就是裸的FFT了 如果每次操作都暴力修改FFT时间复杂度显然爆炸 如果每次操作都不修改,记下修改序列,询问时加上修改序列的贡献,…...

httpx,一个网络请求的 Python 新宠儿
大家好!我是爱摸鱼的小鸿,关注我,收看每期的编程干货。 一个简单的库,也许能够开启我们的智慧之门, 一个普通的方法,也许能在危急时刻挽救我们于水深火热, 一个新颖的思维方式,也许能…...

计算机网络408考研 2014
1 计算机网络408考研2014年真题解析_哔哩哔哩_bilibili 1 111 1 11 1...

通用物体识别-ResNet18镜像5分钟快速部署:零基础搭建AI图像分类服务
通用物体识别-ResNet18镜像5分钟快速部署:零基础搭建AI图像分类服务 1. 引言:为什么选择ResNet-18进行物体识别? 在当今AI技术快速发展的时代,图像分类已经成为许多应用的基础功能。但对于初学者和中小型企业来说,部…...
Pixel Couplet Gen实战案例:基于Retro Game UI的微信小程序春联H5页
Pixel Couplet Gen实战案例:基于Retro Game UI的微信小程序春联H5页 1. 项目背景与设计理念 1.1 传统与数字的碰撞 春节作为中国最重要的传统节日,春联文化已有千年历史。然而在数字时代,传统春联形式面临着与年轻群体脱节的问题。Pixel C…...

终极Fluxion数组操作指南:掌握ArrayUtils.sh提升脚本效率的10个技巧
终极Fluxion数组操作指南:掌握ArrayUtils.sh提升脚本效率的10个技巧 【免费下载链接】fluxion Fluxion is a remake of linset by vk496 with enhanced functionality. 项目地址: https://gitcode.com/gh_mirrors/fl/fluxion Fluxion作为一款功能强大的网络工…...

零基础入门机器人抓取:在快马平台轻松搞定龙虾openclaw安装与第一个程序
最近在学习机器人抓取相关的知识,发现龙虾openclaw是个不错的入门工具。作为一个完全零基础的小白,我在安装和配置环境时遇到了不少困难。好在发现了InsCode(快马)平台,它帮我轻松解决了这些问题。下面分享一下我的学习过程。 了解openclaw …...

SEO优化的预算一般应如何合理安排
SEO优化的预算一般应如何合理安排 在当今数字化时代,网站的搜索引擎优化(SEO)已成为提升网站流量和品牌知名度的重要手段。如何合理分配SEO优化预算成为许多企业和网站管理者面临的一个重要课题。本文将从问题分析、原因说明、解决方法、注意…...

自用超香的 Navidrome 音乐库搭建分享,告别听歌各种糟心事!
前言 作为一个实打实的音乐爱好者,我曾被听歌这件事折腾得够呛 —— 手机播放器加载慢到让人没耐心,喜欢的歌动不动就因为版权问题听不了,充了会员也总觉得不划算,更别说囤了一堆无损音乐却只能在电脑上听的憋屈。直到用上 Navid…...

Z-Image Turbo在工业设计中的应用:产品概念图生成
Z-Image Turbo在工业设计中的应用:产品概念图生成 1. 引言 工业设计师的日常工作中,最耗时但又最关键的环节是什么?答案往往是概念图的创作和渲染。传统的工作流程中,设计师需要先手绘草图,然后在专业软件中建模、渲…...

seo优化服务价格一般是多少_网站快速排名对网站访问量有什么影响
SEO优化服务价格一般是多少_网站快速排名对网站访问量有什么影响 在当前数字化经济的浪潮中,网站的流量和排名直接决定了企业的成功与否。SEO优化服务价格一般是多少?更重要的是,网站快速排名对网站访问量有什么影响呢?这两个问题…...
:如何进行数据整理(下),分类变量如何设置对照组?设置值标签?)
Zstats高级版教程(3):如何进行数据整理(下),分类变量如何设置对照组?设置值标签?
本篇是风暴统计平台教程系列的第三章,将详细说明如何使用数据整理模块,节省后续分析的时间。因为涉及内容比较多,分为上中下三篇,此为下篇。前两篇数据整理教程分别向大家详细介绍了数据整理模块的定量数据转分类、计算新变量、变…...

Qwen3-1.7B能做什么?实测写邮件、生成故事、智能聊天
Qwen3-1.7B能做什么?实测写邮件、生成故事、智能聊天 1. 认识Qwen3-1.7B Qwen3(千问3)是阿里巴巴集团开源的新一代通义千问大语言模型系列中的一员,1.7B版本虽然参数量不大,但在日常应用中表现出色。这个17亿参数的模…...