统计回归与Matlab软件实现上(一元多元线性回归模型)
引言
关于数学建模的基本方法
- 机理驱动
由于客观事物内部规律的复杂及人们认识程度的限制,无法得到内在因果关系,建立合乎机理规律的数学模型 - 数据驱动
直接从数据出发,找到隐含在数据背后的最佳模型,是数学模型建立的另一大思路
统计回归方法是基于统计理论建立的最基本的一类数据驱动建模方法
学习目的
- 用统计回归方法估计数据中隐含的模型
- 对模型参数和模型结果的可靠性做必要检验
- 分析建模过程中的一些细节问题:异常数据的辨识与处理,变量的筛选
- 用MATLAB软件实现
一元线性回归模型的概念
一元线性回归模型基本概念
一般地,称由
y = β 0 + β 1 x + ε y=\beta_{0}+\beta_{1}x+\varepsilon y=β0+β1x+ε
确定的模型为一元线性回归模型
- β 0 , β 1 \beta_{0},\beta_{1} β0,β1为回归系数
- x x x为自变量、回归变量或解释变量
- y y y为因变量或被解释变量
- ε \varepsilon ε为随机误差
随机误差 ε \varepsilon ε的基本假设
- 高斯-马尔科夫条件
{ E ( ε ) = 0 c o v ( ε , ε ) = σ 2 \left\{\begin{matrix} E(\varepsilon)=0 \\ cov(\varepsilon,\varepsilon)=\sigma^{2} \end{matrix}\right. {E(ε)=0cov(ε,ε)=σ2
- 随机误差项必须是0均值的
- 方差等于 σ 2 \sigma^{2} σ2,是恒定的,即与 x x x的取值无关
- 正太分布假设
ε ∼ N ( 0 , σ 2 ) \varepsilon \sim N(0,\sigma^{2}) ε∼N(0,σ2)
随机误差项要服从0均值的正太分布,并且方差同样是恒定的,与 x x x无关
一元线性回归分析的主要任务
- 基于样本数据,对参数 β 0 , β 1 , σ \beta_{0},\beta_{1},\sigma β0,β1,σ做参数估计
- 对模型参数 β 0 , β 1 \beta_{0},\beta_{1} β0,β1以及模型显著性作假设检验分析
- 对 y y y的值作预测,即对 y y y作点(区间)估计
Matlab实现
[b, bint, r, rint, stats]=regress(Y,X,alpha)
- bint,回归系数的区间估计
- r,残差
- rint,残差的置信区间
- stats,检验回归模型的统计量:决定系数 r 2 r^{2} r2,F值,与F值对应的概率p
- alpha,显著性水平,缺省时为0.05
模型的参数估计与软件实现
回归系数的最小二乘估计
有 n n n组独立样本: ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y ( n ) ) (x_{1},y_{1}),(x_{2},y_{2}),\dots,(x_{n},y(n)) (x1,y1),(x2,y2),…,(xn,y(n)),带入回归方程可得
{ y i = β 0 + β 1 x i + ε i , i = 1 , 2 , … , n E ( ε i ) = 0 , v a r ( ε i ) = σ 2 \left\{\begin{matrix} y_{i}=\beta_{0}+\beta_{1}x_{i}+\varepsilon_{i},\ i=1,2,\dots,n \\ E(\varepsilon_{i})=0,\ var(\varepsilon_{i})=\sigma^{2} \end{matrix}\right. {yi=β0+β1xi+εi, i=1,2,…,nE(εi)=0, var(εi)=σ2
其中, ε 1 , ε 2 , … , ε n \varepsilon_{1},\varepsilon_{2},\dots,\varepsilon_{n} ε1,ε2,…,εn相互独立
![![[Pasted image 20240811090041.png]]](https://i-blog.csdnimg.cn/direct/36906c86fa1740638e5c6b164a29fe60.png)
- 拟合误差或残差: r i = y i − y i ′ r_{i}=y_{i}-y'_{i} ri=yi−yi′
- 最好直线:使残差平方和最小的直线
Q ( β 0 , β 1 ) = ∑ i = 1 n ( y i − y i ′ ) 2 = ∑ i = 1 n ( y i − β 0 − β i x i ) 2 Q(\beta_{0},\beta_{1})=\sum_{i=1}^{n}(y_{i}-y'_{i})^{2}=\sum_{i=1}^{n}(y_{i}-\beta_{0}-\beta_{i}x_{i})^{2} Q(β0,β1)=i=1∑n(yi−yi′)2=i=1∑n(yi−β0−βixi)2
最小化的参数值 β 0 ′ , β 1 ′ \beta'_{0},\beta'_{1} β0′,β1′称为 β 0 , β 1 \beta_{0},\beta_{1} β0,β1的最小二乘估计
该优化问题的求解,可以基于极值原理实现
通过残差平方和,分别对 β 0 , β 1 \beta_{0},\beta_{1} β0,β1求偏导数,令偏导数等于0
{ ∂ Q ∂ β 0 = 0 ∂ Q ∂ β 1 = 0 \left\{\begin{matrix} \frac{\partial Q}{\partial \beta_{0}}=0 \\ \frac{\partial Q}{\partial \beta_{1}}=0 \end{matrix}\right. {∂β0∂Q=0∂β1∂Q=0
得到的是二元一次线性方程组
相应的最小二乘估计为
{ β ^ 0 = y ˉ − β ^ 1 x ˉ β ^ 1 = x ˉ y ˉ − x ˉ y ˉ x 2 ˉ − x ˉ 2 \left\{\begin{matrix} \hat{\beta}_{0}=\bar{y}-\hat{\beta}_{1}\bar{x} \\ \hat{\beta}_{1}=\frac{\bar{x}\bar{y}-\bar{x}\bar{y}}{\bar{x^{2}}-\bar{x}^{2}} \end{matrix}\right. {β^0=yˉ−β^1xˉβ^1=x2ˉ−xˉ2xˉyˉ−xˉyˉ
其中
x ˉ = 1 n ∑ i = 1 n x i , y ˉ = 1 n ∑ i = 1 n y i , \bar{x}=\frac{1}{n}\sum_{i=1}^{n}x_{i},\quad \bar{y}=\frac{1}{n}\sum_{i=1}^{n}y_{i}, xˉ=n1i=1∑nxi,yˉ=n1i=1∑nyi,
x ˉ 2 = 1 n ∑ i = 1 n x i 2 , x ˉ y ˉ = 1 n ∑ i = 1 n x i y i \bar{x}^{2}=\frac{1}{n}\sum_{i=1}^{n}x_{i}^{2},\quad \bar{x}\bar{y}=\frac{1}{n}\sum_{i=1}^{n}x_{i}y_{i} xˉ2=n1i=1∑nxi2,xˉyˉ=n1i=1∑nxiyi
Matlab实现
regress命令
b=regress(Y, X)
待求解的线性方程组
y i = β 0 + β 1 x i + ε i , i = 1 , 2 , … , n y_{i}=\beta_{0}+\beta_{1}x_{i}+\varepsilon_{i},\ i=1,2,\dots,n yi=β0+β1xi+εi, i=1,2,…,n
[ y 1 y 2 … y n ] = [ 1 x 1 1 x 2 … … 1 x n ] [ β 0 β 1 ] \begin{bmatrix} y_{1} \\ y_{2} \\ \dots \\ y_{n} \end{bmatrix}=\begin{bmatrix} 1&&x_{1} \\ 1&&x_{2} \\ \dots&&\dots \\ 1&&x_{n} \end{bmatrix}\begin{bmatrix} \beta_{0} \\ \beta_{1} \end{bmatrix} y1y2…yn = 11…1x1x2…xn [β0β1]
- Y指的是y的矩阵向量
- X指的是系数矩阵x
- 等式左边的b指的是参数 β \beta β的最小二乘估计
- 输入数据
x=[143 145 146 147 149 150 153 154 155 156 157 158 159 160 162 164]';
X=[ones(16,1)x];
Y=[88 85 88 91 92 93 93 95 96 98 97 96 98 99 100 102]';
x表示所有的自变量,16各人的身高数据,是列向量,‘是转秩
X是两列的矩阵,第一个是16个1组成的列向量,第二个是自变量x的列向量
Y是16个腿长数据,也是列向量
2. 参数估计
b=regress(Y, X)
得b
b=[-16.0730 0.7194]'
β 0 ′ = − 16.0730 ; β 1 ′ = 0.7194 \beta'_{0}=-16.0730;\ \beta'_{1}=0.7194 β0′=−16.0730; β1′=0.7194
经验回归方程
y = − 16.0739 + 0.7194 x y=-16.0739+0.7194x y=−16.0739+0.7194x
回归系数的置信区间估计
在正太假设的前提下
β ^ 0 ∼ N ( β 0 , ( 1 n + x ^ 2 L x x ) σ 2 ) \hat{\beta}_{0}\sim N\left( \beta_{0},\left( \frac{1}{n}+\frac{\hat{x}^{2}}{L_{xx}} \right)\sigma^{2} \right) β^0∼N(β0,(n1+Lxxx^2)σ2)
β 1 ^ ∼ N ( β 1 , σ 2 L x x ) \hat{\beta_{1}}\sim N\left( \beta_{1}, \frac{\sigma^{2}}{L_{xx}} \right) β1^∼N(β1,Lxxσ2)
其中
L x x = ∑ i = 1 n ( x i − x ˉ ) 2 L_{xx}=\sum_{i=1}^{n}(x_{i}-\bar{x})^{2} Lxx=i=1∑n(xi−xˉ)2
由于 σ \sigma σ未知,可以构造t统计量来进行区间估计
t = β 1 ′ − β 1 ( σ ′ ) 2 L x x ∼ t ( n − 2 ) t=\frac{\beta'_{1}-\beta_{1}}{\sqrt{ \frac{(\sigma')^{2}}{L_{xx}} }}\sim t(n-2) t=Lxx(σ′)2β1′−β1∼t(n−2)
其中
L x x = ∑ i = 1 n ( x i − x ˉ ) 2 L_{xx}=\sum_{i=1}^{n}(x_{i}-\bar{x})^{2} Lxx=i=1∑n(xi−xˉ)2
σ ^ 2 = 1 n − 2 ∑ i = 1 n ( y i − y ^ i ) 2 \hat{\sigma}^{2}=\frac{1}{n-2}\sum_{i=1}^{n}(y_{i}-\hat{y}_{i})^{2} σ^2=n−21i=1∑n(yi−y^i)2
![![[Pasted image 20240811095120.png]]](https://i-blog.csdnimg.cn/direct/afc17750df1740a99cb789230ca0b757.png)
P ( − t a 2 ( n − 2 ) < β 1 ^ − β 2 σ ^ 2 L x x < t a 2 ( n − 2 ) ) = 1 − α P\left( -t_{\frac{a}{2}}(n-2)<\frac{\hat{\beta_{1}}-\beta_{2}}{\sqrt{ \frac{\hat{ \sigma}^{2}}{L_{xx}} }}<t_{\frac{a}{2}}(n-2) \right)=1-\alpha P −t2a(n−2)<Lxxσ^2β1^−β2<t2a(n−2) =1−α
t统计量落在这两个值之间的概率是 1 − α 1-\alpha 1−α
故 β 1 \beta_{1} β1的置信水平为 1 − α 1-\alpha 1−α的置信区间估计为
[ β 1 ′ − t a 2 ( n − 2 ) ( σ ′ ) 2 L x x , β 1 ′ + t a 2 ( n − 2 ) ( σ ′ ) 2 L x x ] \left[ \beta'_{1}-t_{\frac{a}{2}}(n-2)\sqrt{ \frac{(\sigma')^{2}}{L_{xx}} } ,\beta'_{1}+t_{\frac{a}{2}}(n-2)\sqrt{ \frac{(\sigma')^{2}}{L_{xx}} } \right] β1′−t2a(n−2)Lxx(σ′)2,β1′+t2a(n−2)Lxx(σ′)2
同理也可以得到 β 0 \beta_{0} β0的置信区间估计
Matlab实现
[b, bint]=regress(Y, X, 0.05)
bint就是区间估计结果
Y,隐变量的取值向量
X,系数矩阵
0.05,置信水平=1-0.05=95%
用上面的数据得
b = -16.0730 0.7194bint = -33.7071 1.56120.6047 0.8340
bint第一行是 β 0 ′ \beta'_{0} β0′的置信区间估计结果
第二行是 β 1 ′ \beta'_{1} β1′的置信区间估计结果
置信水平是95%的区级估计
[ − 33.71 , 1.56 ] 和 [ 0.60 , 0.83 ] [-33.71,1.56]和[0.60,0.83] [−33.71,1.56]和[0.60,0.83]
模型的残差分析
残差分析的基本概念
残差:样本的观测值与样本的预测值之差
r i = y i − y i ′ r_{i}=y_{i}-y'_{i} ri=yi−yi′
残差向量:所有样本的拟合误差,组成的列向量
r = [ r 1 r 2 … r n ] r=\begin{bmatrix} r_{1} \\ r_{2} \\ \dots \\ r_{n} \end{bmatrix} r= r1r2…rn
残差应该满足的一些基本性质
0均值
E ( ε i ) = 0 E(\varepsilon_{i})=0 E(εi)=0
残差与残差之间是不相关的
c o v ( ε i , ε j ) = 0 cov(\varepsilon_{i},\varepsilon_{j})=0 cov(εi,εj)=0
残差的方差
v a r ( ε i ) = ( 1 − h i i ) σ 2 var(\varepsilon_{i})=(1-h_{ii})\sigma^{2} var(εi)=(1−hii)σ2
残差图分析
![![[Pasted image 20240811101029.png]]](https://i-blog.csdnimg.cn/direct/770a980f994e4cd78856539c33465511.png)
横坐标是自变量x,纵坐标是残差
残差是在0附近随机波动,残差与残差之间不存在明显的关联性
![![[Pasted image 20240811101153.png]]](https://i-blog.csdnimg.cn/direct/059f8da2b133480cb8f8dd0512922ffb.png)
异方差现象,与x有关系,不符合条件
![![[Pasted image 20240811101229.png]]](https://i-blog.csdnimg.cn/direct/d8e99cee30f64763be9441143ac56ddc.png)
不是0均值,残差与残差之间有联系
![![[Pasted image 20240811101301.png]]](https://i-blog.csdnimg.cn/direct/d57db2d691ae41c2a55db528977b0403.png)
前后之间有关联,不是随机波动
软件实现
简单残差图命令
plot(r, '*')
hold on
ezplot('0',[1,length(r)])
用plot命令画出残差,用星号表示
hold on,表示前面的不要擦除,继续画图
ezplot,画出0的基准线
![![[Pasted image 20240811101944.png]]](https://i-blog.csdnimg.cn/direct/3eda96bcaab14046b1d0bc347835d817.png)
Matlab残差图作图命令
rcoplot(r, rint)
r表示残差向量
rint表示残差的置信区间
![![[Pasted image 20240811102204.png]]](https://i-blog.csdnimg.cn/direct/b7c91f62c9e64c9b99b99bd732c01e08.png)
中间的圆圈,表示残差
每个残差都有区间线段,表示置信区间
- 一般认为,正常的样本,残差的置信区间,应该是要跨越0的
- 如果置信区间明显远离0,表示这个样本是异常的
模型的检验与软件实现
模型检验之决定系数
总体平方和
T S S = ∑ i = 1 n ( y i − y ˉ ) 2 TSS=\sum_{i=1}^{n}(y_{i}-\bar{y})^{2} TSS=i=1∑n(yi−yˉ)2
隐变量的观测值减去观测值得平均值的平方和
能够反应样本观测值与中心的偏离程度
能够近似衡量样本观测值序列所包含的信息的多少
TSS的分解
T S S = ∑ i = 1 n ( y i − y ˉ ) 2 = ∑ i = 1 n ( y i − y i ^ + y i ^ − y ˉ ) 2 TSS=\sum_{i=1}^{n}(y_{i}-\bar{y})^{2}=\sum_{i=1}^{n}(y_{i}-\hat{y_{i}}+\hat{y_{i}}-\bar{y})^{2} TSS=i=1∑n(yi−yˉ)2=i=1∑n(yi−yi^+yi^−yˉ)2
= ∑ i = 1 n ( y ^ i − y ˉ ) 2 + ( y i − y ^ i ) 2 + 2 ( y i − y ^ i ) ( y ^ i − y ˉ ) =\sum_{i=1}^{n}(\hat{y}_{i}-\bar{y})^{2}+(y_{i}-\hat{y}_{i})^{2}+2(y_{i}-\hat{y}_{i})(\hat{y}_{i}-\bar{y}) =i=1∑n(y^i−yˉ)2+(yi−y^i)2+2(yi−y^i)(y^i−yˉ)
= ∑ i = 1 n ( y ^ i − y ˉ ) 2 + ∑ i = 1 n ( y i − y ^ i ) 2 + ∑ i = 1 n 2 ( y i − y ^ i ) ( y ^ i − y ˉ ) =\sum_{i=1}^{n}(\hat{y}_{i}-\bar{y})^{2}+\sum_{i=1}^{n}(y_{i}-\hat{y}_{i})^{2}+\sum_{i=1}^{n}2(y_{i}-\hat{y}_{i})(\hat{y}_{i}-\bar{y}) =i=1∑n(y^i−yˉ)2+i=1∑n(yi−y^i)2+i=1∑n2(yi−y^i)(y^i−yˉ)
交叉项的和严格等于0
∑ i = 1 n ( y i − y ˉ ) 2 = ∑ i = 1 n ( y ^ i − y ˉ ) 2 + ∑ i = 1 n ( y i − y ^ i ) 2 \sum_{i=1}^{n}(y_{i}-\bar{y})^{2}=\sum_{i=1}^{n}(\hat{y}_{i}-\bar{y})^{2}+\sum_{i=1}^{n}(y_{i}-\hat{y}_{i})^{2} i=1∑n(yi−yˉ)2=i=1∑n(y^i−yˉ)2+i=1∑n(yi−y^i)2
总体平方和=回归平方和(ESS)+残差平方和(RSS)
- 回归平方和表示的是模型能够解释的那一部分平方和的信息,反应的是回归模型能够解释的观测值中的信息的多少
- 残差平方和表示模型没有学习到的信息的多少
决定模型 R 2 R^{2} R2统计量:
R 2 = E S S T S S = 1 − R S S T S S R^{2}=\frac{ESS}{TSS}=1- \frac{RSS}{TSS} R2=TSSESS=1−TSSRSS
R 2 R^{2} R2也被称为判定系数或拟合优度
- 取值范围一定在01之间
- 越接近1,样本数据拟合效果越好
Matlab实现
[b, bint, r, rint, stats] = regress(Y, X, 0.05)
得
stats:0.9282 180.9531 0.0000 1.7437
因此 R 2 = 0.9282 R^{2}=0.9282 R2=0.9282
模型检验之F统计量检验
原假设 H 0 H_{0} H0:回归方程 y = β 0 + β 1 x y=\beta_{0}+\beta_{1}x y=β0+β1x不显著成立
也就是线性项可有可无,即 β 1 = 0 \beta_{1}=0 β1=0
备择假设 H 1 H_{1} H1回归方程 y = β 0 + β 1 x y=\beta_{0}+\beta_{1}x y=β0+β1x显著成立
即 β 1 ≠ 0 \beta_{1}\ne 0 β1=0
在 H 0 H_{0} H0成立的假定下,构造统计量
F = E S S 1 R S S n − 2 ∼ F ( 1 , n − 2 ) F=\frac{\frac{ESS}{1}}{\frac{RSS}{n-2}}\sim F(1,n-2) F=n−2RSS1ESS∼F(1,n−2)
其中
E S S = ∑ i = 1 n ( y ^ i − y ˉ ) 2 ESS=\sum_{i=1}^{n}(\hat{y}_{i}-\bar{y})^{2} ESS=i=1∑n(y^i−yˉ)2
自由度是1
R S S = ∑ i = 1 n ( y i − y ^ i ) 2 RSS=\sum_{i=1}^{n}(y_{i}-\hat{y}_{i})^{2} RSS=i=1∑n(yi−y^i)2
自由度是n-2
![![[Pasted image 20240811113722.png]]](https://i-blog.csdnimg.cn/direct/a160d8c4dd3a4c5ab9e724887ea3d8f9.png)
概率密度曲线
F α F_{\alpha} Fα:上 α \alpha α分位点,临界值点
如果F值,大于临界值,就拒绝原假设,即线性回归模型显著
如果F值。小于临界值,接受原假设,即线性回归模型不显著
Matlab实现
[b, bint, r, rint, stats] = regress(Y, X, 0.05)
得
stats:0.9282 180.9531 0.0000 1.7437
因此F值=180.9531
因为数据是16个人的数据,临界值 F α ( 1 , n − 2 ) F_{\alpha}(1,n-2) Fα(1,n−2),就是 F α ( 1 , 14 ) F_{\alpha}(1,14) Fα(1,14)
α \alpha α取0.05
可以查询F分布表,查到分位点
或
x_a = finv(0.95, 1, 14)
0.95表示落在临界值左侧的概率
1和14分别表示F分布的两个自由度
返回值就是临界值
得: F 0.05 ( 1 , 14 ) = 4.6001 F_{0.05}(1,14)=4.6001 F0.05(1,14)=4.6001
有 F 值 ≫ F 0.05 ( 1 , 14 ) F值\gg F_{0.05}(1,14) F值≫F0.05(1,14),可以得出拒绝原假设得结论,所以线性回归关系是显著成立的
与F值对应的p值
![![[Pasted image 20240811113722.png]]](https://i-blog.csdnimg.cn/direct/8952b561e6cc4b70aa0e03b8b4e76580.png)
F值对应的右侧的这一块面积,就是p值
是分布落在F值右边的概率
当原假设成立的前提下,自由度是1和n-2的随机变量落在F值右侧的概率
p = P ( F ( 1 , n − 2 ) > F 值 ∣ H 0 成立 ) p=P(F(1,n-2)>F值|H_{0}成立) p=P(F(1,n−2)>F值∣H0成立)
- p值可以理解为接受回归模型的风险,即犯错的概率
Matlab实现
[b, bint, r, rint, stats] = regress(Y, X, 0.05)
得
stats:0.9282 180.9531 0.0000 1.7437
p值是0.000
>> stats(3)
输入以上语句来得到p值
ans=2.1312e-09
2.1312 × 1 0 − 9 2.1312\times 10^{-9} 2.1312×10−9
因此,接受回归模型正确的风险为2.1312e-09
σ 2 \sigma^{2} σ2的无偏估计
stats的第四个统计指标
σ 2 \sigma^{2} σ2是模型的随机误差项的方差
σ ^ 2 = 1 n − 2 ∑ i = 1 n ε i 2 = 1 n − 2 ∑ i = 1 n ( y i − y ^ i ) 2 \hat{\sigma}^{2}=\frac{1}{n-2}\sum_{i=1}^{n}\varepsilon_{i}^{2}=\frac{1}{n-2}\sum_{i=1}^{n}(y_{i}-\hat{y}_{i})^{2} σ^2=n−21i=1∑nεi2=n−21i=1∑n(yi−y^i)2
残差平方和除以自由度n-2
模型预测
- 点预测
将对 x 0 x_{0} x0代入经验回归方程,得点预测结果
y ^ 0 = β ^ 0 + β ^ 1 x 0 \hat{y}_{0}=\hat{\beta}_{0}+\hat{\beta}_{1}x_{0} y^0=β^0+β^1x0 - 区间预测
置信水平 1 − α 1-\alpha 1−α下,对 y 0 y_{0} y0进行区间估计
[ y ^ − δ ( x 0 ) , y ^ + δ ( x 0 ) ] [\hat{y}-\delta(x_{0}), \quad \hat{y}+\delta(x_{0})] [y^−δ(x0),y^+δ(x0)]
其中
δ ( x 0 ) = σ ^ 1 + 1 n + ( x 0 − x ˉ ) 2 L x x t a 2 ( n − 2 ) \delta(x_{0})=\hat{\sigma}\sqrt{ 1+ \frac{1}{n}+\frac{(x_{0}-\bar{x})^{2}}{L_{xx}} }t_{\frac{a}{2}}(n-2) δ(x0)=σ^1+n1+Lxx(x0−xˉ)2t2a(n−2)
X T X = ( C i j ) X^{T}X=(C_{ij}) XTX=(Cij)
Matalab实现
y_hat = b(1)+b(2)*x
plot(x, Y, 'k+', x, y_hat, 'r')
把x的取值向量,直接代入到经验回归模型当中
b(1)就是 β 0 \beta_{0} β0
b(2)就是 β 1 \beta_{1} β1
y_hat是预测值
Y表示原始的样本观测值,用黑色加号表示
预测值用红色的实线表示
![![[Pasted image 20240811121841.png]]](https://i-blog.csdnimg.cn/direct/2ac8d9a9c4d84ea5b5726f39ccc8b48f.png)
多元线性回归模型与软件实现
基本概念
一般地,称由
y = β 0 + β 1 x 2 + ⋯ + β m x m + ϵ y=\beta_{0}+\beta_{1}x_{2}+\dots+\beta_{m}x_{m}+\epsilon y=β0+β1x2+⋯+βmxm+ϵ
确定的模型,为m元线性回归模型,也可表示为矩阵形式
{ Y = X β + ϵ E ( ε ) = 0 , c o v ( ε , ε ) = σ 2 I n \left\{\begin{matrix} Y=X\beta+\epsilon \\ E(\varepsilon)=0,cov(\varepsilon,\varepsilon)=\sigma^{2}I_{n} \end{matrix}\right. {Y=Xβ+ϵE(ε)=0,cov(ε,ε)=σ2In
其中
Y = ( y 1 y 2 … y n ) X = ( 1 x 11 x 12 … x 1 m 1 x 12 x 22 … x 2 m … … … … … 1 x 1 n x n 2 … x n m ) Y=\begin{pmatrix} y_{1} \\ y_{2} \\ \dots \\ y_{n} \end{pmatrix}\quad X=\begin{pmatrix} 1&&x_{11}&&x_{12}&&\dots&&x_{1m} \\ 1&&x_{12}&&x_{22}&&\dots&&x_{2m} \\ \dots&&\dots&&\dots&&\dots&&\dots \\ 1&&x_{1n}&&x_{n2}&&\dots&&x_{nm} \end{pmatrix} Y= y1y2…yn X= 11…1x11x12…x1nx12x22…xn2…………x1mx2m…xnm
β = ( β 0 β 1 … β n ) ε = ( ε 1 ε 2 … ε n ) \beta=\begin{pmatrix} \beta_{0} \\ \beta_{1} \\ \dots \\ \beta_{n} \end{pmatrix}\quad\varepsilon=\begin{pmatrix} \varepsilon_{1} \\ \varepsilon_{2} \\ \dots \\ \varepsilon_{n} \end{pmatrix} β= β0β1…βn ε= ε1ε2…εn
主要任务
- 对参数 β \beta β和 σ 2 \sigma^{2} σ2作点估计
- 对模型参数、模型显著性作检验分析
- 对 y y y的值作预测,即对 y y y作点(区间)估计
模型参数的估计
用最小二乘法对 β 0 , β 1 … β m \beta_{0},\beta_{1}\dots \beta_{m} β0,β1…βm进行参数估计
m i n β 0 , β 1 , … , β m Q = ∑ i = 1 n ( y − β 0 − β 1 x 1 − ⋯ − β m x m ) 2 min_{\beta_{0},\beta_{1},\dots,\beta_{m}}Q=\sum_{i=1}^{n}(y-\beta_{0}-\beta_{1}x_{1}-\dots-\beta_{m}x_{m})^{2} minβ0,β1,…,βmQ=i=1∑n(y−β0−β1x1−⋯−βmxm)2
解得最小二乘估计为
β ^ = ( X T X ) − 1 ( X T Y ) \hat{\beta}=(X^{T}X)^{-1}(X^{{T}}Y) β^=(XTX)−1(XTY)
模型的检验
类似于一元线性回归情形
- 拟合优度检验
- 方程显著性的F检验
- 变量显著性的t检验
基于t统计量:
t = β ^ i σ ^ c i i ∼ t ( n − k − 1 ) t=\frac{\hat{\beta}_{i}}{\hat{\sigma}\sqrt{ c_{ii} }}\sim t(n-k-1) t=σ^ciiβ^i∼t(n−k−1)
对参数 β i \beta_{i} βi进行显著性检验 ( H 0 : β i = 0 ) (H_{0}:\beta_{i}=0) (H0:βi=0)
其中, X T X = ( c j j ) X^{T}X=(c_{jj}) XTX=(cjj)
模型的预测
- 点预测
将对 ( x 1 ∗ , x 2 ∗ , … , x m ∗ ) (x_{1}^{*},x_{2}^{*},\dots,x_{m}^{*}) (x1∗,x2∗,…,xm∗)代入经验回归方程,得点预测结果
y ^ ∗ = β 0 ^ + β 1 ^ x 1 ∗ + β 2 ^ x 2 ∗ + ⋯ + β m ^ x m ∗ \hat{y}^{*}=\hat{\beta_{0}}+\hat{\beta_{1}}x_{1}^{*}+\hat{\beta_{2}}x_{2}^{*}+\dots+\hat{\beta_{m}}x_{m}^{*} y^∗=β0^+β1^x1∗+β2^x2∗+⋯+βm^xm∗ - 区间预测
[ y ^ − σ t a 2 ( n − k − 1 ) 1 + ∑ i , j c i j x i x j , y ^ + σ ^ t a 2 ( n − k − 1 ) 1 + ∑ i , j c i j x i x j ^ ] \begin{bmatrix} \hat{y}-\hat{\sigma t_{\frac{a}{2}}(n-k-1)\sqrt{ 1+\sum_{i,j}c_{ij}x_{i}x_{j} } ,\hat{y}+\hat{\sigma}t_{\frac{a}{2}}(n-k-1)\sqrt{ 1+\sum_{i,j}c_{ij}x_{i}x_{j} }} \end{bmatrix} [y^−σt2a(n−k−1)1+∑i,jcijxixj,y^+σ^t2a(n−k−1)1+∑i,jcijxixj^]
其中 X T X = ( c i j ) X^{T}X=(c_{ij}) XTX=(cij)
Matlab实现
[b, bint, r, rint, stats]=regress(Y, X, alpha)
- 拟合优度 r 2 r^{2} r2越接近1,说明回归方程越显著
- F > F α ( m , n − m − 1 ) F>F_{\alpha}(m,n-m-1) F>Fα(m,n−m−1)时拒绝H0, F F F越大,说明回归方程越显著
- 与 F F F对应得概率 p < α p<\alpha p<α时拒绝H0,回归模型成立
建材销售量的回归模型
![![[Pasted image 20240813111525.png]]](https://i-blog.csdnimg.cn/direct/6ae3fd180b994fb680370dff719c39cd.png)
![![[Pasted image 20240813111558.png]]](https://i-blog.csdnimg.cn/direct/52532f8ed7854fc599d6fb242af87183.png)
![![[Pasted image 20240813111617.png]]](https://i-blog.csdnimg.cn/direct/7a6a39e627d346ad80496637e5332bcb.png)
求解
- 建立建材销售量 y y y与推销开支 x 1 x_{1} x1、实际账目数 x 2 x_{2} x2、同类商品竞争数 x 3 x_{3} x3和地区销售潜力 x 4 x_{4} x4的线性回归模型
y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 3 + β 4 x 4 + ϵ y=\beta_{0}+\beta_{1}x_{1}+\beta_{2}x_{2}+\beta_{3}x_{3}+\beta_{4}x_{4}+\epsilon y=β0+β1x1+β2x2+β3x3+β4x4+ϵ - 用regress命令进行线性回归模型求解
x1=[5.5 2.5 8 3 3 2.9 8 9 4 6.5 5.5 5 6 5 3.5 8 6 4 7.5 7]';
x2=[31 55 67 50 38 71 30 56 42 73 60 44 50 39 55 70 40 50 62 59]';
x3=[10 8 12 7 8 12 12 5 8 5 11 12 6 10 10 6 11 11 9 9]';
x4=[8 6 9 16 15 17 8 10 4 16 7 12 6 4 4 14 6 8 13 11]';
y=[79.3 200.1 163.2 200.1 146 177.7 30.9 291.9 160 339.4 159.6 86.3 237.5 ... 107.2 155 201.4 100.2 135.8 223.3 195]';
x=[ones(size(x1)), x1, x2, x3, x4];
[b, bint, r, rint, stats]=regress(y, X);
- 程序求解结果分析
![![[Pasted image 20240813174026.png]]](https://i-blog.csdnimg.cn/direct/74b894c403044c19bf08ec7af00f404a.png)
- y的90.34%可由模型确定
- F值远超过临界值 F 0.05 ( 4.15 ) = 3.0556 F_{0.05}(4.15)=3.0556 F0.05(4.15)=3.0556
- p值远小于 σ = 0.05 \sigma=0.05 σ=0.05
- 模型整体上成立
- β 1 和 β 4 \beta_{1}和\beta_{4} β1和β4置信区间包含零点, x 1 , x 4 x_{1},x_{4} x1,x4对y的影响不太显著
- 模型的残差分析
![![[Pasted image 20240813174517.png]]](https://i-blog.csdnimg.cn/direct/bc28eb282f0d4aceb1d8a492d1de881f.png)
![![[Pasted image 20240813174543.png]]](https://i-blog.csdnimg.cn/direct/28b5e326932d4966aeb0e77bd0fe60b8.png)
- 第16个样本为异常样本
- 模型的改进
首先,剔除异常样本,并重新回归计算
y(16)=[];
x(16,:)=[];
[b, bint, r, rint, stats]=regress(y, X);
![![[Pasted image 20240813174800.png]]](https://i-blog.csdnimg.cn/direct/8fc6eda34d66456892230287198b9be2.png)
R 2 。 F R^{2}。F R2。F都有较大改进,但回归系数 β 4 \beta_{4} β4的置信区间包含零点
剔除不显著的变量 x 4 x_{4} x4
y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 3 + ϵ y=\beta_{0}+\beta_{1}x_{1}+\beta_{2}x_{2}+\beta_{3}x_{3}+\epsilon y=β0+β1x1+β2x2+β3x3+ϵ
[b, bint, r, rint, stats]=regress(y, X(:,1:end-1))
![![[Pasted image 20240813175235.png]]](https://i-blog.csdnimg.cn/direct/3ace8ac596d54933b5a59b3e1cb8b6af.png)
-
置信区间越短了
![![[Pasted image 20240813175330.png]]](https://i-blog.csdnimg.cn/direct/315d79fec04e4ddb9282928f6746a8fc.png)
-
残差图基本正常
-
最终模型具有较好的显著性
相关文章:
统计回归与Matlab软件实现上(一元多元线性回归模型)
引言 关于数学建模的基本方法 机理驱动 由于客观事物内部规律的复杂及人们认识程度的限制,无法得到内在因果关系,建立合乎机理规律的数学模型数据驱动 直接从数据出发,找到隐含在数据背后的最佳模型,是数学模型建立的另一大思路…...
【项目】基于Vue3.2+ElementUI Plus+Vite 通用后台管理系统
构建项目 环境配置 全局安装vue脚手架 npm install -g vue/cli-init打开脚手架图形化界面 vue ui创建项目 在图形化界面创建项目根据要求填写项目相关信息选择手动配置勾选配置项目选择配置项目然后我们就搭建完成啦🥳,构建可能需要一点时间࿰…...

随机生成 UUID
1、随机生成 UUID主方法 /*** 随机生成 UUID* param {*} len 生成字符串的长度* param {*} radix 生成随机字符串的长度**/export function uuid_(len 30, radix 20) {var chars 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz.split()var uuid [],ir…...
报名表EXCEL图片批量下载源码-CyberWinApp-SAAS 本地化及未来之窗行业应用跨平台架构
每次报名表都会包含大量照片,一张一张下载很慢 可以通过未来之窗开源平台架构 开开excel批量下载 实现代码也很简单 function 未来之窗下载(){ let 未来之窗地址 document.getElementById("batchurl").value; let 保存路径 document.getElementById(…...
SpringBoot 整合 Elasticsearch 实现商品搜索
一、Spring Data Elasticsearch Spring Data Elasticsearch 简介 Spring Data Elasticsearch是Spring提供的一种以Spring Data风格来操作数据存储的方式,它可以避免编写大量的样板代码。 常用注解 常用注解说明如下: 注解名称 作用 参数说明 Docu…...

计算机毕业设计 助农产品采购平台 Java+SpringBoot+Vue 前后端分离 文档报告 代码讲解 安装调试
🍊作者:计算机编程-吉哥 🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。 🍊心愿:点…...
Django后台数据获取展示
续接Django REST Framework,使用Vite构建Vue3的前端项目 1.跨域获取后台接口并展示 安装Axios npm install axios --save 前端查看后端所有定义的接口 // 访问后端定义的可视化Api接口文档 http://ip:8000/docs/ // 定义的学生类信息 http://ip:8000/api/v1…...

innodb 如何保证数据的一致性?
InnoDB是MySQL的默认存储引擎之一,它通过多种机制来保证数据的一致性。以下是InnoDB保证数据一致性的主要方式: 1. 事务支持 InnoDB实现了ACID(原子性、一致性、隔离性和持久性)事务模型,这是保证数据一致性的基础。…...

Oracle-OracleConnection
提示:OracleConnection 主要负责与Oracle数据库的交互,特别针对CDC功能,提供了获取和处理数据库更改日志的能力,同时包含数据库连接管理、查询执行和结果处理的通用功能,与DB2Connection作用相似 文章目录 前言一、核心…...
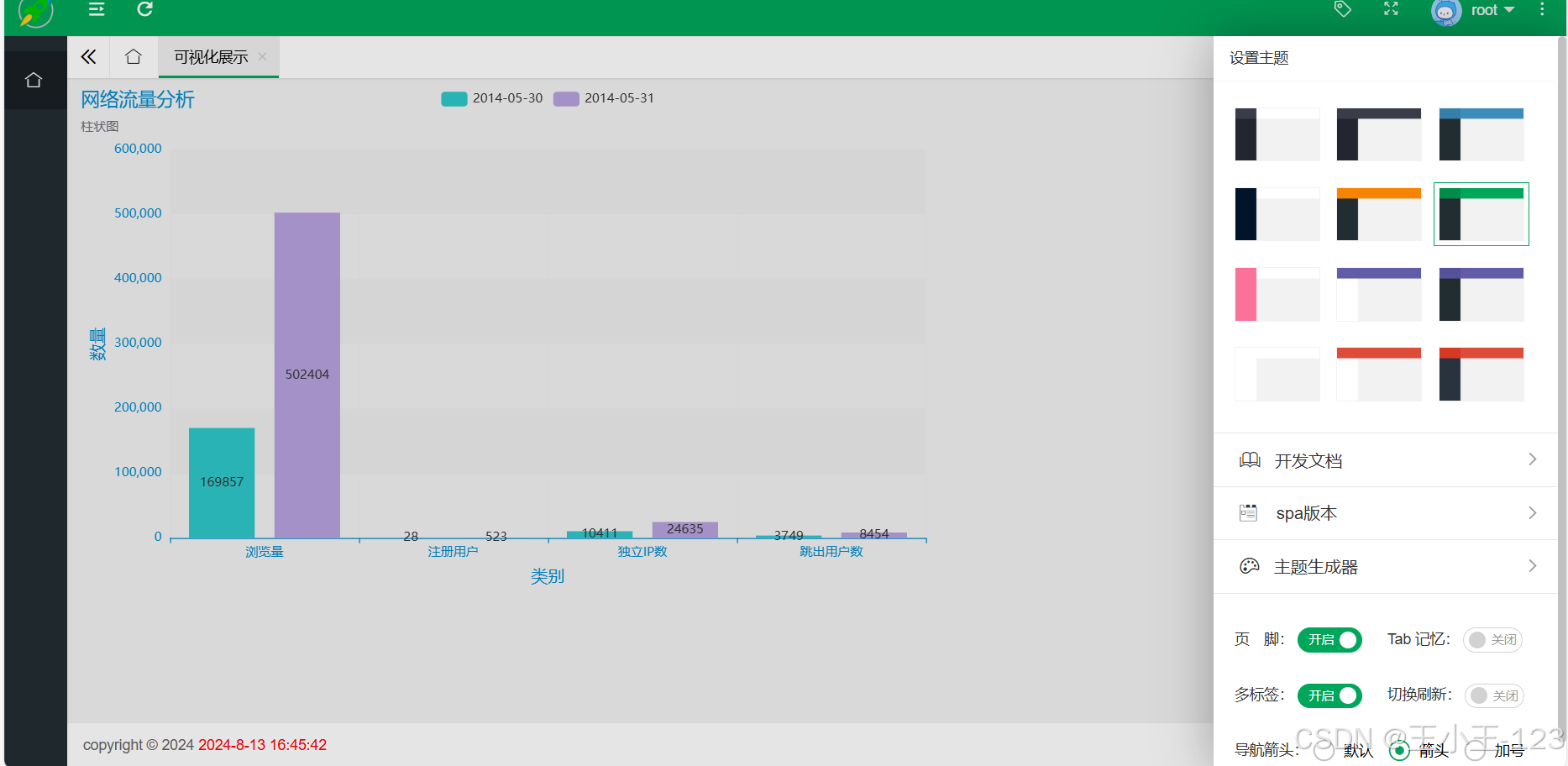
基于hadoop的网络流量分析系统的研究与应用
目录 摘要 1 Abstract 2 第1章 绪论 3 1.1 研究背景 3 1.2 研究目的和意义 4 1.2.1 研究目的 4 1.2.2 研究意义 6 1.3 国内外研究现状分析 7 1.3.1 国内研究现状 7 1.3.2 国外研究现状 9 1.4 研究内容 11 第2章 Hadoop技术及相关组件介绍 12 2.1 HDFS的工作原理及…...

【C# WPF WeChat UI 简单布局】
创建WPF项目 VS创建一个C#的WPF应用程序: 创建完成后项目目录下会有一个MainWindow.xaml文件以及MainWindow.cs文件,此处将MainWindow.xaml文件作为主页面的布局文件,也即为页面的主题布局都在该文件进行。 布局和数据 主体布局 Wechat的布局可暂时分为三列, 第一列为菜…...
)
关于docker的几个概念(二)
目录 1. 为何Docker CentOS镜像比传统CentOS镜像小得多?2. 镜像的分层结构及其优势3. 讲一下容器的copy-on-write特性,修改容器里面的内容会修改镜像吗?4. 简单描述一下Dockerfile的整个构建镜像过程 1. 为何Docker CentOS镜像比传统CentOS镜…...
)
JAVA集中学习第五周学习记录(一)
系列文章目录 第一章 JAVA集中学习第一周学习记录(一) 第二章 JAVA集中学习第一周项目实践 第三章 JAVA集中学习第一周学习记录(二) 第四章 JAVA集中学习第一周课后习题 第五章 JAVA集中学习第二周学习记录(一) 第六章 JAVA集中学习第二周项目实践 第七章 JAVA集中学习第二周学…...

JavaSE 网络编程
什么是网络编程 计算机与计算机之间通过网络进行数据传输 两种软件架构 网络编程3要素 IP IPv4 IPv6 Testpublic void test01() throws UnknownHostException { // InetAddress.getByName 可以是名字或ipInetAddress address InetAddress.getByName("LAPTOP-7I…...

ubuntu24.04 编译安装PHP7.4
ubuntu24.04 编译安装PHP7.4 先安装依赖包(原本是centos上安装依赖,让chatgpt转换了下对应的ubutnu下包名,如果编译过程有缺失,按报错提示再安装下) apt install zlib1g zlib1g-dev libpcre3 libpcre3-dev libfreety…...
Tied and Anchored Stereo Attention Network for Cloud Removal in Optical
论文名称 基于固定锚定立体注意力网络的光学遥感图像去云方法代码运行 论文代码 https://github.com/ningjin00/TASANet?tabreadme-ov-file 论文地址 1环境创建 模型环境给了这几个包,如果你自带环境 那就运行代码 提示缺哪个装哪个 python 3.12rasterio 1.3.10…...
云开发微信小程序--即时聊天(单人聊天,多人聊天室)
云开发微信小程序–即时聊天 介绍:本小程序包含欢迎界面,注册,登录,一对一聊天,群聊,好友添加请求验证过程,修改好友备注以及删除好友,退出群聊,特殊角色卡片展示&#…...
Leetcod编程基础0到1-基础实现内容(个人解法)(笔记)
以下为个人解法,欢迎提供不同思路 1768. 交替合并字符串 题目:给你两个字符串 word1 和 word2 。请你从 word1 开始,通过交替添加字母来合并字符串。如果一个字符串比另一个字符串长,就将多出来的字母追加到合并后字符串的末尾&…...

仲阳天王星运维实习一面
自我介绍? 略谈谈你对“仲阳天王星”的理解? 略实习时间怎么安排,后续时间是怎么规划的? 略给你一个装满水的8升满壶和两个分别是5升、3升的空壶,请想个办法,使得其中一个水壶恰好装4升水,每一步…...

排序算法详解
💎所属专栏:数据结构与算法学习 💎 欢迎大家互三:2的n次方_ 🍁1. 插入排序 🍁1.1 直接插入排序 插入排序是一种简单直观的排序算法,它的原理是通过构建有序序列,对于未排序数…...
)
数学建模实战:用熵权法+PCA搞定你的综合评价问题(附Python完整代码与数据)
数学建模实战:用熵权法PCA搞定你的综合评价问题(附Python完整代码与数据) 在数学建模竞赛中,综合评价问题一直是让参赛者头疼的难题。如何从一堆看似杂乱无章的指标中,提炼出关键信息,给出客观公正的评价&a…...

群晖搭建PS4 HEN服务器 | 无需联网的本地化解决方案
1. 为什么需要本地化HEN服务器? 如果你是一位PS4玩家,可能对HEN(Homebrew ENabler)这个名词并不陌生。它能让你的PS4运行自制软件、备份游戏存档,甚至解锁一些官方系统限制的功能。但传统方式需要PS4联网访问外部HEN服…...

openclaw行为式AI重构:从昂贵Token到高效对象协作
从昂贵的token消耗到高效的对象协作,重新设计行为式AI的核心架构 问题诊断:为什么当前行为式AI如此“昂贵”? OpenClaw等工具的核心架构依赖生成式大模型作为“大脑”,通过反复的推理-行动循环完成任务。这种设计导致: 高Token消耗的根源 重复的上下文传递:每次循环都需…...

利用快马平台快速构建Selenium自动化测试框架原型
今天想和大家分享一个用PythonSelenium快速搭建Web自动化测试框架的经验。最近接手了一个需要频繁回归测试的登录模块,手动测试实在太耗时,于是决定用自动化测试来提高效率。在InsCode(快马)平台上尝试后,发现能快速生成可运行的原型…...

AI驱动开发:在快马平台上让AI模型协作构建你的智能体框架
今天想和大家分享一个最近在InsCode(快马)平台上实践的AI辅助开发项目——构建一个用于代码审查的智能体框架。这个框架特别适合在快马这样的AI开发平台上实现,因为可以直接调用平台内置的多种AI模型来完成智能体之间的协作。 框架设计思路 整个智能体框架由三个核…...

字幕提取与格式转换解决B站内容离线使用难题:BiliBiliCCSubtitle的多场景应用指南
字幕提取与格式转换解决B站内容离线使用难题:BiliBiliCCSubtitle的多场景应用指南 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 当你在B站发现一门优…...

Qwen3.5-4B-Claude-Opus效果展示:正则表达式编写+匹配逻辑逐层分析
Qwen3.5-4B-Claude-Opus效果展示:正则表达式编写匹配逻辑逐层分析 1. 模型能力概览 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF是一个经过特殊优化的推理蒸馏模型,在代码生成和逻辑分析方面展现出独特优势。这个4B参数的轻量级模型特别擅长…...

如何快速解密科学文库加密文档:终极免费解密工具指南
如何快速解密科学文库加密文档:终极免费解密工具指南 【免费下载链接】ScienceDecrypting 破解CAJViewer带有效期的文档,支持破解科学文库、标准全文数据库下载的文档。无损破解,保留文字和目录,解除有效期限制。 项目地址: htt…...

如何让Windows播放器支持所有视频格式:终极媒体解码解决方案
如何让Windows播放器支持所有视频格式:终极媒体解码解决方案 【免费下载链接】LAVFilters LAV Filters - Open-Source DirectShow Media Splitter and Decoders 项目地址: https://gitcode.com/gh_mirrors/la/LAVFilters 你是否曾经遇到过这样的烦恼…...
)
告别网络依赖:用Vue3+Leaflet和IIS搭建本地离线地图服务(附腾讯地图瓦片下载)
构建企业级离线地图解决方案:Vue3Leaflet与IIS深度整合指南 在数字化转型浪潮中,地图功能已成为各类管理系统的基础需求。然而,许多政企单位、军工机构及偏远地区项目往往面临网络不稳定或完全离线的特殊环境。本文将系统介绍如何基于Vue3、L…...