Java语言程序设计——篇十三(2)


🌿🌿🌿跟随博主脚步,从这里开始→博主主页🌿🌿🌿
- 欢迎大家:这里是我的学习笔记、总结知识的地方,喜欢的话请三连,有问题可以私信🌳🌳🌳
您的点赞👍、关注➕、收藏⭐️、评论📝、私信📧是我最大的支持与鼓舞!!!🌻🌻🌻

文本I/O流
- 文本I/O流概述
- Reader类和Writer类
- Reader
- Writer
- FileReader和FileWriter类
- FileReader
- FileWriter
- 实战演练
- BufferedReader和BufferedWriter类
- BufferedReader
- BufferedWriter
- 实战演练
- PrintWriter类的应用
- 使用Scanner对象
- 综合演练
文本I/O流概述
- 文本I/O流以字符为基本单位, 也叫字符I/O流。
- 抽象类Reader和Writer分别是文本输入流和输出流的根类。


Reader类和Writer类
Reader
- Reader类是文本输入流的根类,主要方法有:
int read() 返回值0-65535之间
int read(char[] cbuf)
void close()Writer
- Writer是字符输出流的根类,主要方法有:
void write(int c) 写入c的低16位
void write(char [] cbuf)
void write(String str)
void close()
FileReader和FileWriter类
FileReader
- FileReader类构造方法有:
FileReader(String fileName) FileReader(File file)
FileWriter
- FileWriter类构造方法有:
FileWriter(String fileName) FileWriter(File file) FileWriter(String fileName, boolean append)
实战演练
问题描述:
- 编写程序,使用FileReader和FileWriter 将文件input.txt 的内容复制到output.txt文件中。
- 思路:用input.txt创建FileReader,用output.txt创建FileWriter,从文件输入流读取字符,写入文件输出流。
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException; public class FileCopyExample { public static void main(String[] args) { // 定义源文件和目标文件的路径 String inputFilePath = "input.txt"; String outputFilePath = "output.txt"; // 使用try-with-resources语句自动关闭资源 try (FileReader reader = new FileReader(inputFilePath); FileWriter writer = new FileWriter(outputFilePath)) { // 创建一个字符数组(缓冲区)来存储从文件读取的字符 char[] buffer = new char[1024]; int bytesRead; // 读取文件到缓冲区,直到没有更多的数据 while ((bytesRead = reader.read(buffer)) != -1) { // 将缓冲区中的数据写入输出文件 writer.write(buffer, 0, bytesRead); } System.out.println("文件复制完成。"); } catch (IOException e) { // 如果发生I/O错误,打印错误消息 e.printStackTrace(); } }
}
程序解释
1、导入必要的类:
- FileReader 用于读取字符文件。
- FileWriter 用于写入字符文件。
- IOException 用于处理可能发生的I/O错误。
2、定义文件路径:
- inputFilePath 是源文件input.txt的路径。
- outputFilePath 是目标文件output.txt的路径。
3、使用try-with-resources语句:
- 这个语句自动管理资源(即FileReader和FileWriter对象),并在代码块执行完毕后自动关闭它们。
4、读取和写入:
- 创建一个字符数组(或称为缓冲区)buffer,用于临时存储从input.txt读取的字符。
- 使用while循环和read方法从FileReader中读取数据到缓冲区中,直到没有更多的数据(即read方法返回-1)。
- 在每次循环中,使用write方法将缓冲区中的数据写入到FileWriter中。注意write方法的第三个参数指定了要写入文件的字节数(在这个情况下是bytesRead)。
5、异常处理:
- 如果在读取或写入过程中发生IOException,则捕获该异常并打印堆栈跟踪。
这个示例展示了如何使用Java IO库中的FileReader和FileWriter类来复制文件内容。注意,由于这个示例使用了字符流,所以它最适合用于处理文本文件。如果你需要处理二进制文件,应该考虑使用FileInputStream和FileOutputStream。
BufferedReader和BufferedWriter类
BufferedReader
- BufferedReader类的构造方法如下:
BufferedReader(Reader in) BufferedReader(Reader in, int sz)BufferedReader in = new BufferedReader(new FileReader("input.txt"));
public String readLine()
BufferedWriter
- BufferedWriter类的构造方法如下:
BufferedWriter(Writer out)BufferedWriter(Writer out, int sz)BufferedWriter br = new BufferedWriter(new FileWriter("output.txt"));
实战演练
问题描述
编写程序,统计文本文件article.txt中的单词数量。
思路:从article.txt文件中读取一行,解析成单词组成的字符串数组,累加数组的长度即可。
假设单词的分隔符只用空格、逗号和点号3种。
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.regex.Pattern; public class WordCount { public static void main(String[] args) { String filePath = "article.txt"; int totalWords = 0; try (BufferedReader reader = new BufferedReader(new FileReader(filePath))) { String line; while ((line = reader.readLine()) != null) { // 使用正则表达式分割单词,这里假设单词之间由空格、逗号或点号分隔 String[] words = line.split("[\\s,.]+"); // \\s 匹配任何空白字符,+表示一个或多个 // 累加当前行的单词数量 totalWords += words.length; // 注意:这种简单的计数方式会将连续的分隔符视为空字符串,因此可能需要进一步处理 // 但在这个特定情况下,由于我们关注的是单词的总数,所以可以接受这种“额外”的计数 } System.out.println("Total words in the file: " + totalWords); } catch (IOException e) { e.printStackTrace(); } }
}
注意:
我们使用了split("[\\s,.]+")来根据空格、逗号和点号(一个或多个)分割字符串。这里的+确保了即使连续出现多个分隔符,它们也只被视为一个分隔点,从而避免生成空字符串(尽管在这个计数场景下空字符串不会影响最终结果)。
请确保article.txt文件存在于程序的运行目录中,或者提供正确的文件路径。
如果文件很大,或者性能是一个关注点,可能需要考虑更高效的读取和解析策略,比如使用Scanner类或者NIO包中的类来读取文件。
- PrintWriter类实现文本打印输出流,构造方法如下:
PrintWriter(Writer out)
PrintWriter(Writer out, boolean autoFlush)
void println(boolean b)
void println(int i)
void println(String s)
void println(Object obj)
PrintWriter printf(String format, Object…args)
PrintWriter类的应用
问题描述
编写程序,随机产生10个100到200之间的整数,然后使用PrintWriter对象输出到文件number.txt中。
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Random; public class RandomNumbersToFile { public static void main(String[] args) { // 创建 Random 对象 Random random = new Random(); // 创建 FileWriter 对象,如果文件不存在则创建文件 try (FileWriter fileWriter = new FileWriter("number.txt"); PrintWriter printWriter = new PrintWriter(fileWriter)) { // 循环生成10个随机数 for (int i = 0; i < 10; i++) { // 生成 100 到 200 之间的随机整数 int randomNumber = random.nextInt(101) + 100; // 因为nextInt(n)生成的是0到n-1之间的随机数 // 写入随机数到文件 printWriter.println(randomNumber); } // 注意:由于使用了try-with-resources语句,不需要显式关闭PrintWriter和FileWriter } catch (IOException e) { e.printStackTrace(); System.out.println("发生错误,无法写入文件。"); } System.out.println("随机数已写入到number.txt文件中。"); }
}
这个程序首先创建了一个Random对象用于生成随机数。然后,它使用FileWriter和PrintWriter对象将随机数写入到number.txt文件中。注意,由于FileWriter构造函数在文件不存在时会创建文件,因此不需要事先手动创建number.txt文件。程序中的循环会生成10个随机数,并使用println方法将每个随机数写入文件(每个数占一行)。最后,使用try-with-resources语句来确保PrintWriter和FileWriter在使用后能够被正确关闭,这避免了潜在的资源泄露问题。
使用Scanner对象
- 使用Scanner类从键盘读取数据,这是在创建Scanner对象时将标准输入设备System.in作为其构造方法的参数。
Scanner input = new Scanner(System.in);int n = input.nextInt();
- 使用Scanner还可以关联文本文件,从文本文件中读取数据。
- Scanner类的常用的构造方法有:
Scanner(String source)Scanner(InputStream source)
- Scanner常用方法:
byte nextByte()double nextDouble()String nextLine() boolean hasNextDouble()void close()
综合演练
问题描述
编写程序,使用Scanner类从程序13.5创建的文本文件number.txt中读出每个整数。
思路: 先用number.txt创建FileInputStream对象,再用它创建Scanner对象,用nextInt()方法从中读出整数。
import java.io.File;
import java.io.FileNotFoundException;
import java.util.Scanner; public class ReadNumbersFromFile { public static void main(String[] args) { // 指定文件路径 String filePath = "number.txt"; // 使用File对象指向文件 File file = new File(filePath); // 创建Scanner对象来读取文件 try (Scanner scanner = new Scanner(file)) { // 检查文件是否成功打开 if (!scanner.hasNext()) { System.out.println("文件为空或无法读取"); return; } // 循环读取文件中的整数 while (scanner.hasNextInt()) { int number = scanner.nextInt(); System.out.println(number); // 打印读取到的整数 } // 注意:由于使用了try-with-resources语句,Scanner对象会在结束时自动关闭 } catch (FileNotFoundException e) { System.out.println("文件未找到:" + filePath); e.printStackTrace(); } }
}
博主用心写,读者点关注,互动传真情,知识不迷路。
相关文章:
Java语言程序设计——篇十三(2)
🌿🌿🌿跟随博主脚步,从这里开始→博主主页🌿🌿🌿 欢迎大家:这里是我的学习笔记、总结知识的地方,喜欢的话请三连,有问题可以私信🌳🌳&…...

python结合csv和正则实现条件筛选数据统计分数
前景提要: 有一个项目的数值和员工统计的对不上,如果一页一页翻找自己手动算,一个就有16、7页, 功能实现 1、创建csv文件 需要将每一个模块的所有数据头提取出来,这个可以直接用爬虫或者手工复制出来,因…...

Ubuntu系统的基础操作和使用|Linux|安装|网络连接|更新与升级系统|系统维护|故障排除|监控|桌面环境|虚拟机|快捷键
目录 1. Ubuntu系统的安装与初步设置 1.1 下载与安装Ubuntu 1.2 创建用户和设置密码 1.3 配置网络连接 1.4 更新与升级系统 2. Ubuntu的基本操作 2.1 文件与目录管理 2.2 系统进程管理 2.3 软件安装与管理 2.4 权限与用户管理 3. 系统维护与故障排除 3.1 系统日志查…...

day 38
2824.统计和小于目标的下标对数目 int countPairs(int* nums, int numsSize, int target){int x0;for(int i0;i<numsSize;i){for(int ji1;j<numsSize;j){if(nums[i]nums[j]<target){x;}}}return x; }2951.找出峰值 int* findPeaks(int* mountain, int mountainSize,…...

352532
c语言中的小小白-CSDN博客c语言中的小小白关注算法,c,c语言,贪心算法,链表,mysql,动态规划,后端,线性回归,数据结构,排序算法领域.https://blog.csdn.net/bhbcdxb123?spm1001.2014.3001.5343 给大家分享一句我很喜欢我话: 知不足而奋进,望远山而前行&am…...

Day.38 | 1143.最长公共子序列 1035.不相交的线 53.最大子序和 392.判断子序列
1143.最长公共子序列 要点:dp[i][j] dp[i - 1][j - 1] 1; dp[i][j] max(dp[i - 1][j], dp[i][j - 1]); class Solution { public:int longestCommonSubsequence(string text1, string text2) {vector<vector<int>> dp(text1.size() 1, vector<…...

pytorch 3 计算图
计算图结构 分析: 起始节点 ab 5 - 3ac 2b 3d 5b 6e 7c d^2f 2e最终输出 g 3f - o(其中 o 是另一个输入) 前向传播 前向传播按照上述顺序计算每个节点的值。 反向传播过程 反向传播的目标是计算损失函数(这里假设为…...

一文吃透:暗水印是什么?企业防泄密可以加暗水印吗?
设计部主管:昨天下班的时候我在办公室捡到一张文件,上面可是我们最新产品的设计草稿,严禁打印的,到底是谁干的? 员工:办公室没有监控,似乎很难查到哦。 网络部经理:不用担心&#…...

Ajax-02.Axios
Axios入门 1.引入Axios的js文件 <script src"js/axios-0.18.0.js"></script> Axios 请求方式别名: axios.get(url[,config]) axios.delete(url[,config]) axios.post(url[,data[,config]]) axios.put(url[,data[,config]]) 发送GET/POST请求 axios.get…...

NodeJS的核心配置文件package.json和package.lock.json详解
package.json 文件 package.json 文件是 Node.js 项目的核心配置文件,它包含了项目的基本信息、依赖关系以及一些脚本命令等。以下是 package.json 文件的主要字段说明: name:项目的名称,必须是小写,可以包含字母、数…...

开源数据采集和跟踪系统:助力营销决策的关键工具
开源数据采集和跟踪系统:助力营销决策的关键工具 在现代营销中,数据是最重要的资产之一。了解用户行为、优化广告效果、提升转化率,这一切都离不开精准的数据分析。为了帮助商家更好地掌握这些数据,市场上出现了许多开源的数据采…...

Luminar Neo for Mac/Win:创新AI图像编辑软件的强大功能
Luminar Neo,这款由Skylum公司倾力打造的图像编辑软件,为Mac和Windows用户带来了前所未有的创作体验与编辑便利。作为一款融合了先进AI技术的图像处理工具,Luminar Neo以其独特的功能和高效的操作流程,成为了摄影师、设计师及摄影…...

Mac平台M1PRO芯片MiniCPM-V-2.6网页部署跑通
Mac平台M1PRO芯片MiniCPM-V-2.6网页部署跑通 契机 ⚙ 2.6的小钢炮可以输入视频了,我必须拉到本地跑跑。主要解决2.6版本默认绑定flash_atten问题,pip install flash_attn也无法安装,因为强制依赖cuda。主要解决的就是这个问题,还…...

MyBatis:Maven,Git,TortoiseGit,Gradle
1,Maven Maven是一个非常优秀的项目管理工具,采用一种“约定优于配置(CoC)”的策略来管理项目。使用Maven不仅可以把源代码构建成可发布的项目(包括编译、打包、测试和分发),还可以生成报告、生…...

获取链表中间位置的两种方法方法
方法一: 我们可以计算链表节点的数量,然后遍历链表找到前半部分的尾节点。 方法二: 我们也可以使用快慢指针在一次遍历中找到:慢指针一次走一步,快指针一次走两步,快慢指针同时出发。当快指针移动到链表的末尾时&am…...
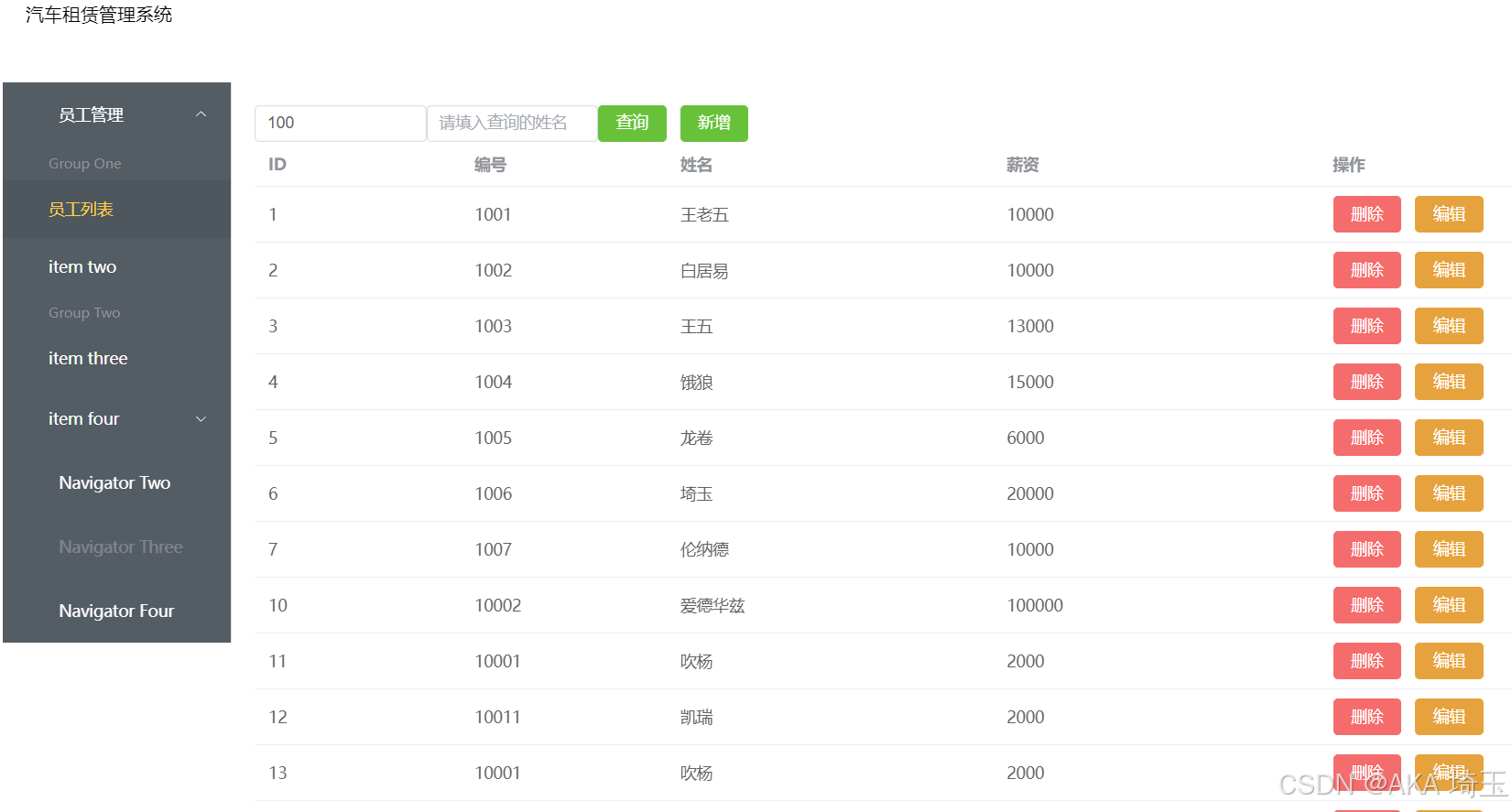
第二十天的学习(2024.8.8)Vue拓展
昨天的笔记中,我们进行的项目已经可以在网页上显示查询到数据库中的数据,今天的笔记中将会完成在网页上进行增删改查的操作 1.删除表中数据 现在网页上只能呈现出数据库中的数据,我们首先添加一个删除按钮,使其可以对数据库数据…...

微信小程序教程011:全局配置:Window
文章目录 1、window1.1、`window`-小程序窗口的组成部分1.2、了解 window 节点常用的配置项1.3、设置导航栏的标题1.4、设置导航栏的背景色1.5、设置导航栏的标题颜色1.6、全局开启下拉刷新功能1.7、设置下拉刷新时窗口的背景色1.8、设置下拉刷新时 loading 的样式1.9、设置上拉…...

Tomcat服务器和Web项目的部署
目录 一、概述和作用 二、安装 1.进入官网 2.Download下面选择想要下载的版本 3.点击Which version查看版本所需要的JRE版本 4.返回上一页下载和电脑和操作系统匹配的Tomcat 5. 安装完成后,点击bin目录下的startup.bat(linux系统下就运行startup.sh&…...

PCIe学习笔记(22)
Transaction Ordering Transaction Ordering Rules 表2-40定义了PCI Express Transactions的排序要求。该表中定义的规则统一适用于PCI Express上所有类型的事务,包括内存、I/O、配置和消息。该表中定义的排序规则适用于单个流量类(TC)。不同TC标签的事务之间没有…...

Vue3 依赖注入Provide / Inject
在实际开发中,我们经常需要从父组件向子组件传递数据,一般情况下,我们使用 props。但有时候会遇到深度嵌套的组件,而深层的子组件只需要父组件的部分内容。在这种情况下,如果仍然将 prop 沿着组件链逐级传递下去&#…...

告别龟速下载!用阿里云镜像和离线包5分钟搞定DBeaver所有JDBC驱动
告别龟速下载!用阿里云镜像和离线包5分钟搞定DBeaver所有JDBC驱动 每次打开DBeaver准备连接数据库,最让人抓狂的就是等待JDBC驱动下载的进度条。特别是在某些网络环境下,一个简单的MySQL驱动下载可能需要十几分钟,甚至直接失败。作…...

【限时解密】SITS大会未公开议程泄露:下一代缓存协议Cache-LLMv2将于Q3强制接入HuggingFace生态?
更多请点击: https://intelliparadigm.com 第一章:大模型缓存策略优化:SITS大会 在2024年SITS(Scalable Intelligence & Trustworthy Systems)大会上,大模型推理缓存成为性能优化的核心议题。与传统We…...

AI智能体技能管理:MCP服务器安装配置与实战指南
1. 项目概述:一个为AI智能体管理“技能”的MCP服务器 最近在折腾AI智能体(Agent)开发的朋友,应该都遇到过同一个痛点:想让你的Claude、GPT或者Gemini去执行一些特定的、复杂的任务,比如调用某个API、处理特…...

CANN/asc-devkit向量最小值函数
asc_min 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...

如何用python函数制作一个计算工具
大家好,这里是junlang的python文章 今天教大家如何用python函数做一个计算器,希望大家好好学习哦 如何制作 首先我们先定义4个函数,其中除法计算代码请看下面: def add (a,b,c):return (a b - c) def sub (x,y):return(x - y) def mulpl…...

量子度量学习的黑盒验证协议设计与实现
1. 量子度量学习与黑盒验证概述量子度量学习(Quantum Metric Learning)是量子机器学习领域的一个重要分支,其核心目标是通过优化量子特征映射,将经典数据转换为量子希尔伯特空间中的态,使得不同类别的数据在量子态空间…...

Visual Studio AI助手实战:Visual chatGPT Studio提升.NET开发效率
1. 项目概述:当AI助手住进你的IDE 如果你是一名.NET开发者,每天至少有8小时与Visual Studio为伴,那么你肯定体会过那种在代码海洋中寻找灵感的孤独感。调试一个古怪的Bug,重构一段陈年旧代码,或者为某个复杂业务逻辑编…...

AI时代DevSecOps脚手架:5分钟构建安全可靠的React+TypeScript应用
1. 项目概述:一个为AI编码时代量身定制的DevSecOps启动器 如果你和我一样,经常用 Cursor、Lovable 这类 AI 编程工具来快速构建应用原型,那你肯定遇到过这个痛点:点子出来得飞快,代码生成也很快,但一到要部…...

基于RAG与LangChain的法律AI助手:从技术原理到开源实践
1. 项目概述:当AI遇上法律,一个开源法律智能助手的诞生最近几年,AI大模型的热潮席卷了各行各业,从写代码到画图,从客服到教育,似乎没有哪个领域能置身事外。作为一名在技术圈摸爬滚打多年的从业者ÿ…...

如何快速掌握DeepL翻译插件:终极跨语言浏览解决方案
如何快速掌握DeepL翻译插件:终极跨语言浏览解决方案 【免费下载链接】deepl-chrome-extension A DeepL Translator Chrome extension 项目地址: https://gitcode.com/gh_mirrors/de/deepl-chrome-extension 在全球化的数字时代,语言障碍是获取国际…...