【机器学习面试总结】————特征工程

【机器学习面试总结】————特征工程
- 一、特征归一化
- 为什么需要对数值类型的特征做归一化?
- 二、类别型特征
- 在对数据进行预处理时,应该怎样处理类别型特征?
- 三、高维组合特征的处理
- 什么是组合特征?如何处理高维组合特征?
- 四、组合特征
- 怎样有效地找到组合特征?
- 五、文本表示模型
- 有哪些文本表示模型?它们各有什么优缺点?
- 比较词袋模型和词嵌入模型:
- 六、Word2Vec
- Word2Vec是如何工作的?它和 LDA有什么区别与联系?
- 七、图像数据不足时的处理方法
- 在图像分类任务中,训练数据不足会带来什么问题?如何缓解数据量不足带来的问题?
特征工程,顾名思义,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。 从本质上来讲,特征工程是一个表示和展现数据的过程。在实际工作中,特征工程旨在去除原始数据中的杂质和冗余,设计更高效的特征以刻画求解的问题与预测模型之间的关系。
本文主要讨论以下两种常用的数据类型。
(1)结构化数据。
结构化数据类型可以看作关系型数据库的一张表,每列都有清晰的定义,包含了数值型、类别型两种基本类型;每一行数据表示一个样本的信息。
(2) 非结构化数据。
非结构化数据主要包括文本、图像、音频、视频数据,其包含的信息无法用一个简单的数值表示,也没有清晰的类别定义,并且每条数据的大小各不相同。
一、特征归一化
为了消除数据特征之间的量纲影响,我们需要对特征进行归一化处理,使得不同指标之间具有可比性。 例如,分析一个人的身高和体重对健康的影响,如果使用米( m )和千克( kg )作为单位,那么身高特征会在1.6 ~ 1.8m的数值范围内,体重特征会在50 ~100kg的范围内,分析出来的结果显然会倾向于数值差别比较大的体重特征。想要得到更为准确的结果,就需要进行特征归一化(Normalization )处理,使各指标处于同一数值量级,以便进行分析。
为什么需要对数值类型的特征做归一化?
对数值类型的特征做归一化可以将所有的特征都统一到一个大致相同的数值区间内。最常用的方法主要有以下两种。
(1)线性函数归一化 ( Min-Max Scaling )。它对原始数据进行线性变换,使结果映射到[0,1]的范围,实现对原始数据的等比缩放。归一化公式如下:

其中X为原始数据,Xmax、Xmin分别为数据最大值和最小值。
list=[[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
from sklearn.preprocessing import MinMaxScaler,StandardScaler
s=MinMaxScaler()
s.fit_transform(list)
( 2)零均值归一化(Z-Score Normalization )。它会将原始数
据映射到均值为0、标准差为1的分布上。具体来说,假设原始特征的均值为u、标准差为o,那么归一化公式定义为:

s=StandardScaler()
s.fit_transform(list)
为什么需要对数值型特征做归一化呢?我们不妨借助随机梯度下降的实例来说明归一化的重要性。假设有两种数值型特征,x的取值范围为[0,10],x的取值范围为[0,3],于是可以构造一个目标函数符合图( a)中的等值图。
在学习速率相同的情况下,x的更新速度会大于x,需要较多的迭代才能找到最优解。如果将x和x2归一化到相同的数值区间后,优化目标的等值图会变成图( b)中的圆形,x,和x的更新速度变得更为一致,容易更快地通过梯度下降找到最优解。
当然,数据归一化并不是万能的。在实际应用中,通过梯度下降法求解的模型通常是需要归一化的,包括线性回归、逻辑回归、支持向量机、神经网络等模型。但对于决策树模型则并不适用,以C4.5为例,决策树在进行节点分裂时主要依据数据集D关于特征x的信息增益比,而信息增益比跟特征是否经过归一化是无关的,因为归一化并不会改变样本在特征x上的信息增益。
二、类别型特征
类别型特征(Categorical Feature)主要是指性别(男、女)、血型(A、B、AB、O )等只在有限选项内取值的特征。类别型特征原始输入通常是字符串形式,除了决策树等少数模型能直接处理字符串形式的输入,对于逻辑回归、支持向量机等模型来说,类别型特征必须经过处理转换成数值型特征才能正确工作。
在对数据进行预处理时,应该怎样处理类别型特征?
序号编码: 通常用于处理类别间具有大小关系的数据。例如成绩,可以分为低、中、高三档,并且存在“高>中>低”的排序关系。序号编码会按照大小关系对类别型特征赋予一个数值ID,例如高表示为3、中表示为2、低表示为1,转换后依然保留了大小关系。
代码实现:
import category_encoders as ce
import pandas as pd
import numpy as np
X = pd.DataFrame(np.array([['A',1],['B', 2], ['AB',2],['A',1],['O',4],['AB',3],['B',2],['A',1],['B', 2], ['A',1],['AB',3],['O',3],['B',2],['O',4]]),columns=['Blood Type','ID'])
y = np.array([1,2,3,1,4,3,2,1,2,1,3,4,2,4])encoder1 = ce.OrdinalEncoder(cols=['Blood Type','ID']).fit(X,y)
print(encoder1.transform(X))

独热编码: 通常用于处理类别间不具有大小关系的特征。例如血型,一共有4个取值(A型血、B型血、AB型血、〇型血),独热编码会把血型变成一个4维稀疏向量,A型血表示为(1,0,0,0),B型血表示为(0,1,0, 0 ),AB型表示为( 0,0,1,0 ),O型血表示为(0,0,0,1)。对于类别取值较多的情况下使用独热编码需要注意以下问题。
- 使用稀疏向量来节省空间。在独热编码下,特征向量只有某一维取值为1,其他位置取值均为0。因此可以利用向量的稀疏表示有效地节省空间,并且目前大部分的算法均接受稀疏向量形式的输入。
- 配合特征选择来降低维度。高维度特征会带来几方面的问题。一是在K近邻算法中,高维空间下两点之间的距离很难得到有效的衡量;二是在逻辑回归模型中,参数的数量会随着维度的增高而增加,容易引起过拟合问题;三是通常只有部分维度是对分类、预测有帮助,因此可以考虑配合特征选择来降低维度。
encoder2 = ce.OneHotEncoder(cols=['Blood Type','ID']).fit(X,y)
print(encoder2.transform(X))
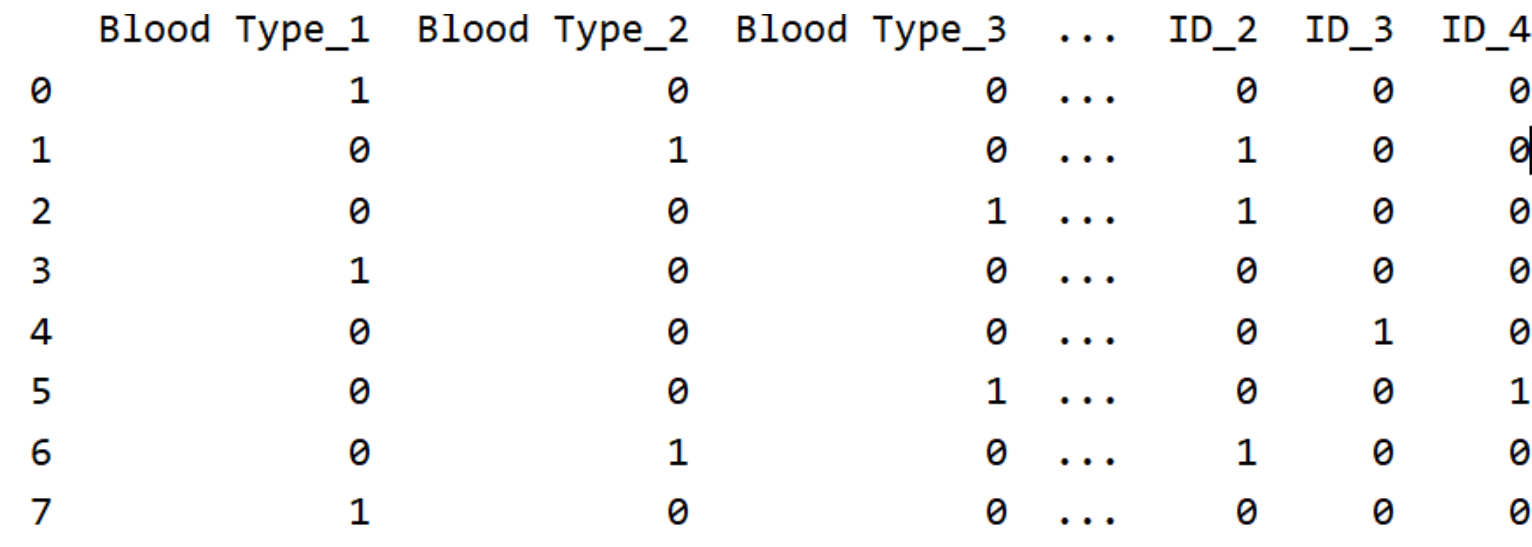
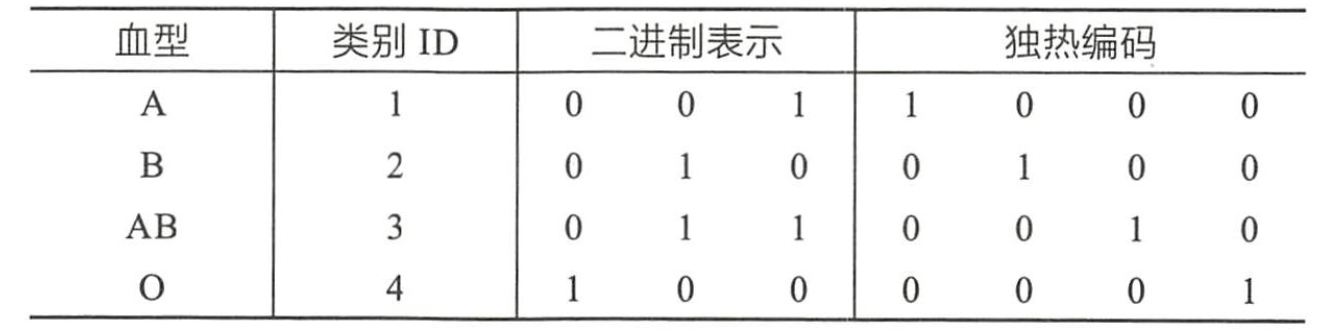
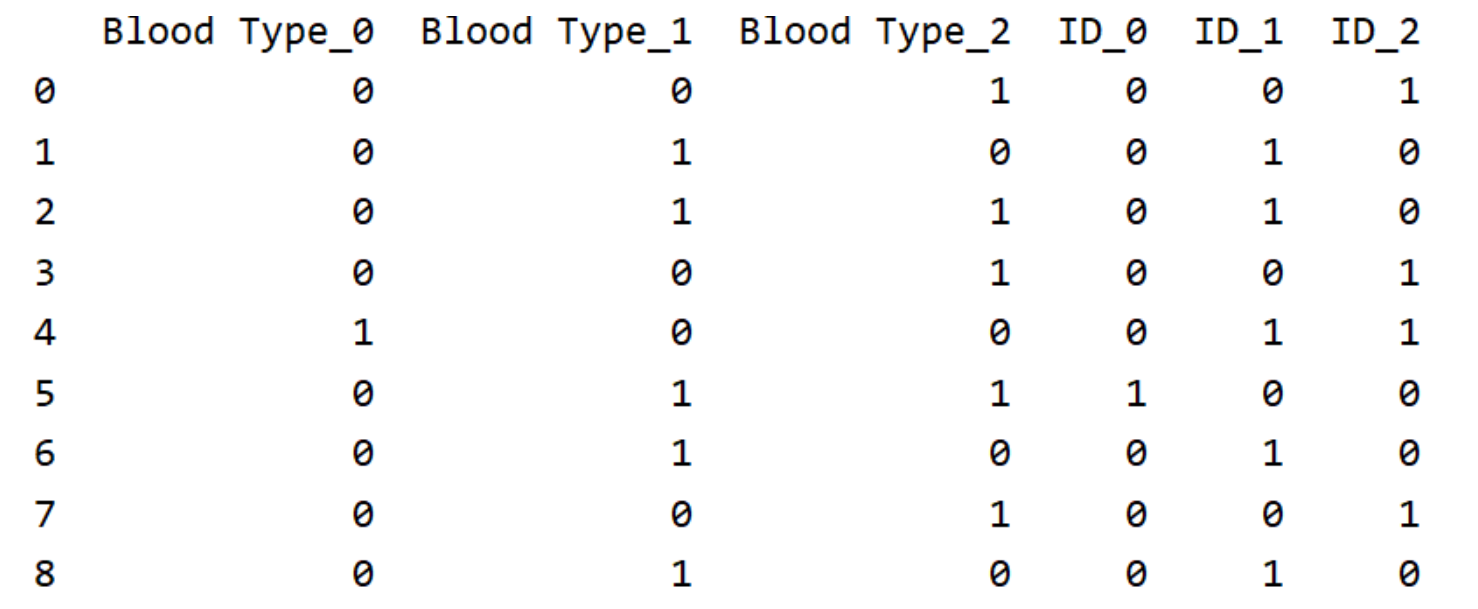
二进制编码: 二进制编码主要分为两步,先用序号编码给每个类别赋予一个类别ID,然后将类别ID对应的二进制编码作为结果。以A、B、AB、O血型为例,下表是二进制编码的过程。A型血的ID为1,二进制表示为001;B型血的ID为2,二进制表示为010;以此类推可以得到AB型血和О型血的二进制表示。可以看出,二进制编码本质上是利用二进制对ID进行哈希映射,最终得到0/1特征向量,且维数少于独热编码,节省了存储空间。
encoder3 = ce.BinaryEncoder(cols=['Blood Type',"ID"]).fit(X,y)
print(encoder3.transform(X))
三、高维组合特征的处理
什么是组合特征?如何处理高维组合特征?
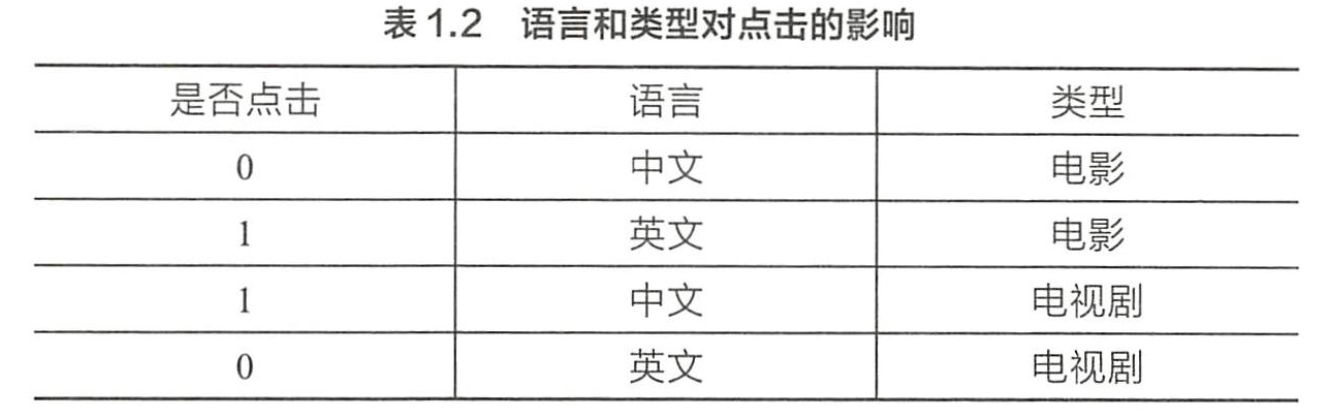
为了提高复杂关系的拟合能力,在特征工程中经常会把一阶离散特征两两组合,构成高阶组合特征。以广告点击预估问题为例,原始数据有语言和类型两种离散特征,下表1.2是语言和类型对点击的影响。为了提高拟合能力,语言和类型可以组成二阶特征,表1.3是语言和类型的组合特征对点击的影响。
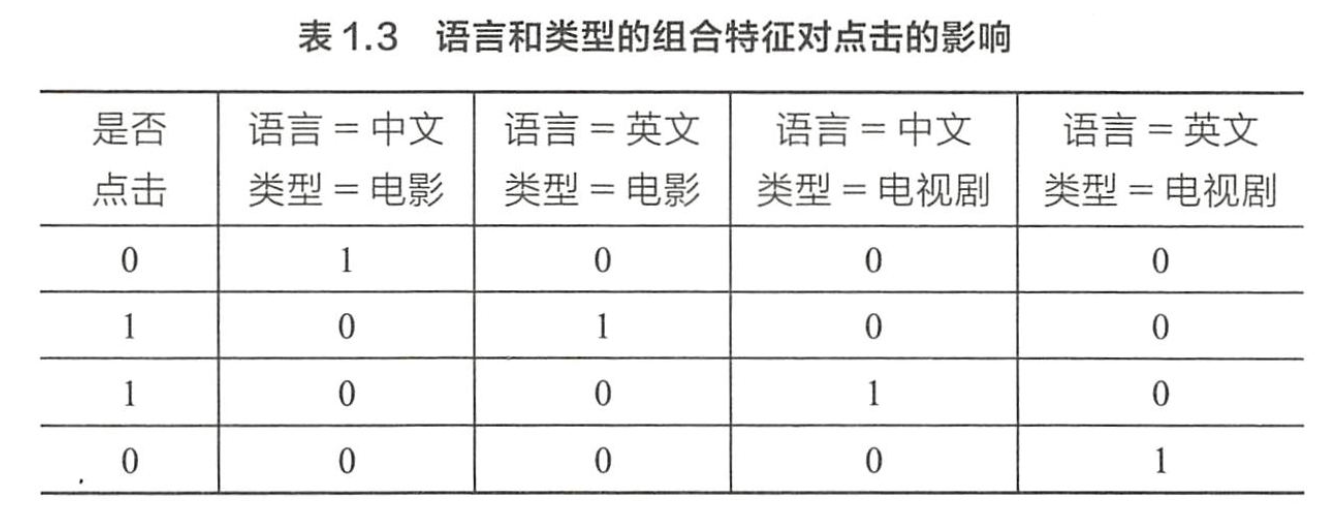
以逻辑回归为例,假设数据的特征向量为X=(x1,x2,…,Xk),则有:

其中<xi,xj>表示xi和xj的组合特征,wij的维度等于|xi|*|xj|,|xi|和|xj|分别代表第i个特征和第j个特征不同取值的个数。在表1.3的广告点击预测问题中,w的维度是2×2=4(语言取值为中文或英文两种、类型的取值为电影或电视剧两种)。这种特征组合看起来是没有任何问题的,但当引入ID类型的特征时,问题就出现了。以推荐问题为例,表1.4是用户ID和物品ID对点击的影响,表1.5是用户ID和物品ID的组合特征对点击的影响。

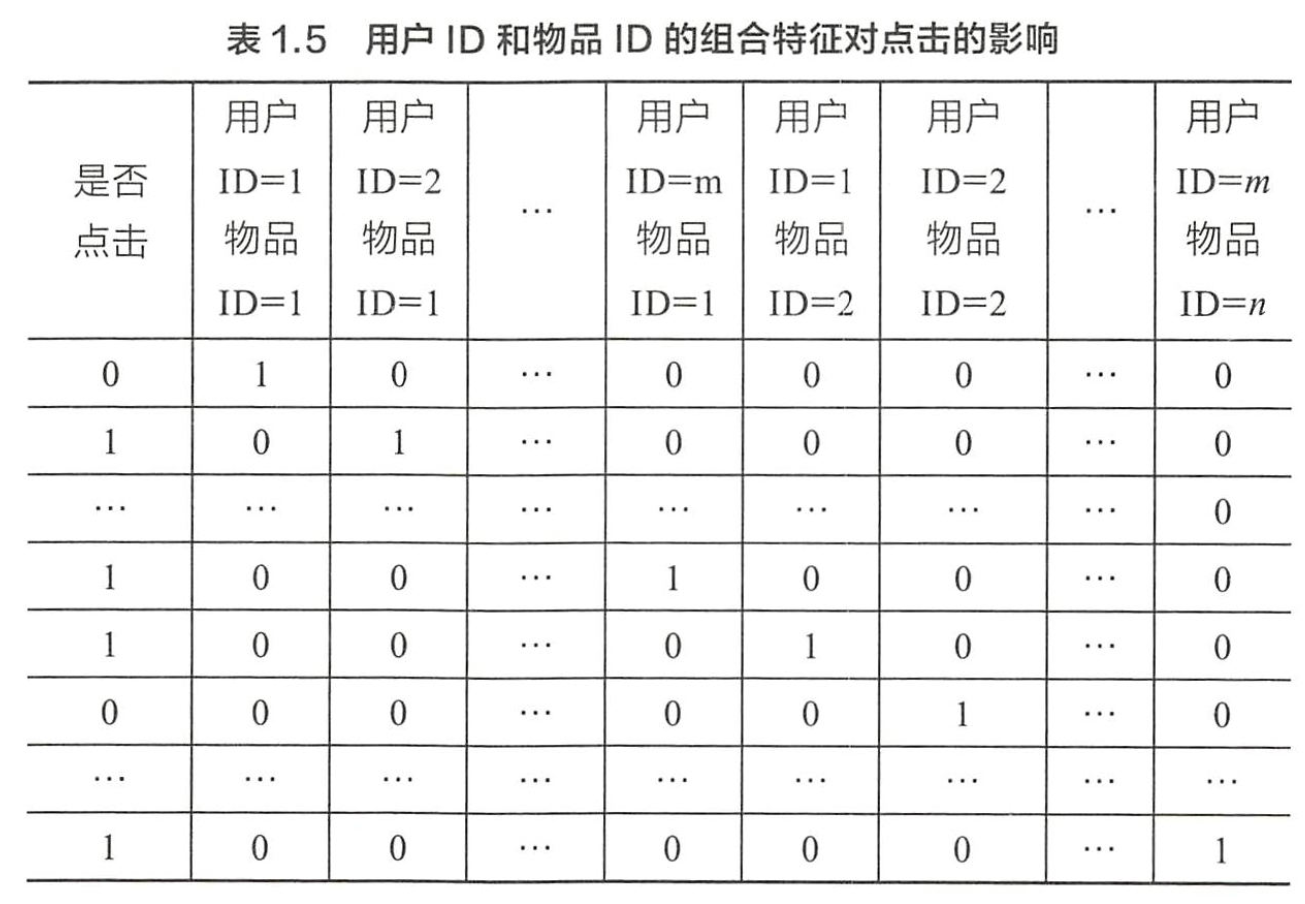
若用户的数量为m、物品的数量为n,那么需要学习的参数的规模为m×n。在互联网环境下,用户数量和物品数量都可以达到千万量级,几乎无法学习m×n规模的参数。在这种情况下,一种行之有效的方法是将用户和物品分别用k维的低维向量表示( k≤m,k≤n ) :
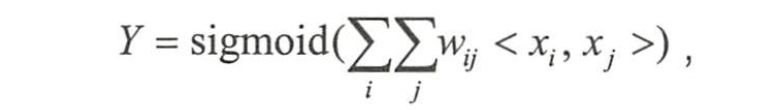
其中wij=x’i * x’j,x’i和x’j分别表示xi和xj对应的低维向量。
四、组合特征
在很多实际问题中,我们常常需要面对多种高维特征。如果简单地两两组合,依然容易存在参数过多、过拟合等问题,而且并不是所有的特征组合都是有意义的。因此,需要一种有效的方法来帮助我们找到应该对哪些特征进行组合。
怎样有效地找到组合特征?
本节介绍一种基于决策树的特征组合寻找方法"。以点击预测问题为例,假设原始输入特征包含年龄、性别、用户类型(试用期、付费)、物品类型(护肤、食品等)4个方面的信息,并且根据原始输入和标签(点击/未点击)构造出了决策树,如图1.2所示。
于是,每一条从根节点到叶节点的路径都可以看成一种特征组合的方式。具体来说,就有以下4种特征组合的方式。
( 1 )“年龄<=35”且“性别=女”。( 2)“年龄<=35”且“物品类别=护肤”。(3)“用户类型=付费”且“物品类型=食品” 。(4)“用户类型=付费”且“年龄<=40”。

表1.6是两个样本信息,那么第1个样本按照上述4个特征组合就可以编码为( 1,1,0,0),因为同时满足(1)(2) ,但不满足(3) (4)。同理,第2个样本可以编码为(0,0,1,1),因为它同时满足(3)(4),但不满足(1)( 2)。
给定原始输入该如何有效地构造决策树呢? 可以采用梯度提升决策树,该方法的思想是每次都在之前构建的决策树的残差上构建下一棵决策树。
五、文本表示模型
文本是一类非常重要的非结构化数据,如何表示文本数据一直是机器学习领域的一个重要研究方向。
词袋模型(Bag of Words ),TF-IDF ( Term Frequency-Inverse DocumentFrequency ),主题模型(Topic Model ),词嵌入模型(Word Embedding )
有哪些文本表示模型?它们各有什么优缺点?
词袋模型: 顾名思义,就是将每篇文章看成一袋子词,并忽略每个词出现的顺序。具体地说,就是将整段文本以词为单位切分开,然后每篇文章可以表示成一个长向量
向量中的每一维代表一个单词,而该维对应的权重则反映了这个词在原文章中的重要程度。常用TF-IDF来计算权重,公式为
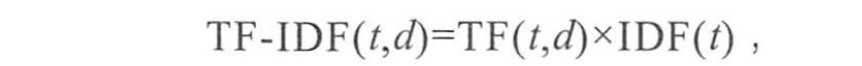
其中TF(t,d)为单词t在文档d中出现的频率,IDF(t)是逆文档频率,用来衡量单词t对表达语义所起的重要性,表示为

直观的解释是,如果一个单词在非常多的文章里面都出现,那么它可能是一个比较通用的词汇,对于区分某篇文章特殊语义的贡献较小,因此对权重做一定惩罚。
将文章进行单词级别的划分有时候并不是一种好的做法,比如英文中的natural language processing(自然语言处理)一词,如果将natural,language,processing 这3个词拆分开来,所表达的含义与三个词连续出现时大相径庭。通常,可以将连续出现的n个词(n≤N)组成的词组(N-gram)也作为一个单独的特征放到向量表示中去,构成N-gram模型。另外,同一个词可能有多种词性变化,却具有相似的含义。在实际应用中,一般会对单词进行词干抽取( WordStemming)处理,即将不同词性的单词统一成为同一词干的形式。
主题模型: 主题模型用于从文本库中发现有代表性的主题(得到每个主题上面词的分布特性),并且能够计算出每篇文章的主题分布,具体细节参见第6章第5节。
词嵌入与深度学习模型: 词嵌入是一类将词向量化的模型的统称,核心思想是将每个词都映射成低维空间(通常K=50 ~ 300维)上的一个稠密向量(DenseVector )。K维空间的每一维也可以看作一个隐含的主题,只不过不像主题模型中的主题那样直观。
由于词嵌入将每个词映射成一个K维的向量,如果一篇文档有N个词,就可以用一个N*K维的矩阵来表示这篇文档,但是这样的表示过于底层。在实际应用中,如果仅仅把这个矩阵作为原文本的表示特征输入到机器学习模型中,通常很难得到令人满意的结果。因此,还需要在此基础之上加工出更高层的特征。在传统的浅层机器学习模型中,一个好的特征工程往往可以带来算法效果的显著提升。而深度学习模型正好为我们提供了一种自动地进行特征工程的方式,模型中的每个隐层都可以认为对应着不同抽象层次的特征。从这个角度来讲,深度学习模型能够打败浅层模型也就顺理成章了。卷积神经网络和循环神经网络的结构在文本表示中取得了很好的效果,主要是由于它们能够更好地对文本进行建模,抽取出一些高层的语义特征。与全连接的网络结构相比,卷积神经网络和循环神经网络一方面很好地抓住了文本的特性,另一方面又减少了网络中待学习的参数,提高了训练速度,并且降低了过拟合的风险。
比较词袋模型和词嵌入模型:
这里需要用到sklearn包。Sklearn的特征抽取模块可以从原始数据中抽取特征。目前该模块提供了图像和文本特征抽取类。文本的特征抽取类可以从原始文本中抽取出词语特征,特征数据格式满足所有机器学习算法对输入数据格式的要求。请注意特征抽取与特征选择的区别。特征抽取是将文本数据转换成机器学习模型可读的形式(即本文所说的文本向量化)而特征选择是一种应用于数值特征的机器学习技术。
用sklearn对下边的文本进行词袋模型向量化表示:
from sklearn.feature_extraction.text import CountVectorizertexts = ['Chinese Bejing Chinese','Chinese Chinese Shanghai','Chinese Macao','Tokyo Japan Chinese']# One-Hot 编码进行文本向量化
cv = CountVectorizer(binary=True)
document_vec = cv.fit_transform(texts)
# 查看词袋和对应向量值
print(cv.get_feature_names())
print(document_vec.toarray())# TF 编码进行文本向量化 CountVectorizer()默认就是TF编码法
cv = CountVectorizer()
document_vec = cv.fit_transform(texts)
print(document_vec.toarray())# TF-IDF(未平滑)编码进行文本向量化
from sklearn.feature_extraction.text import TfidfVectorizer
tv = TfidfVectorizer(use_idf=True, smooth_idf=False, norm=None)
tv_fit = tv.fit_transform(texts)
print(tv.get_feature_names())
print(tv_fit.toarray())# TF-IDF(平滑)编码进行文本向量化
tv = TfidfVectorizer(use_idf=True, smooth_idf=True, norm=None)
tv_fit = tv.fit_transform(texts)
print(tv.get_feature_names())
print(tv_fit.toarray())六、Word2Vec
谷歌2013年提出的 Word2Vec是目前最常用的词嵌入模型之一。Word2Vec实际是一种浅层
的神经网络模型,它有两种网络结构,分别是CBOW ( Continues Bag of Words)和Skip-gram。
Word2Vec,隐狄利克雷模型(LDA ),CBOW,Skip-gram
Word2Vec是如何工作的?它和 LDA有什么区别与联系?
CBOW的目标是根据上下文出现的词语来预测当前词的生成概率,如图( a)所示;而 Skip-gram是根据当前词来预测上下文中各词的生成概率,如图(b)所示。

其中 w(t)是当前所关注的词,w(t-2)、w(t-1)、w(t+1)、w(t+2)是上下文中出现的词。这里前后滑动窗口大小均设为2。
CBOW和Skip-gram都可以表示成由输入层( Input )、映射层( Projection)和输出层( Output)组成的神经网络。
输入层中的每个词由独热编码方式表示,即所有词均表示成一个N维向量,其中N为词汇表中单词的总数。在向量中,每个词都将与之对应的维度置为1,其余维度的值均设为0。
在映射层(又称隐含层)中,K个隐含单元( Hidden Units )的取值可以由N维输入向量以及连接输入和隐含单元之间的NXK维权重矩阵计算得到。在CBOW中,还需要将各个输入词所计算出的隐含单元求和。
同理,输出层向量的值可以通过隐含层向量(K维),以及连接隐含层和输出层之间的K×N维权重矩阵计算得到。输出层也是一个N维向量,每维与词汇表中的一个单词相对应。最后,对输出层向量应用Softmax激活函数,可以计算出每个单词的生成概率。Softmax激活函数的定义为
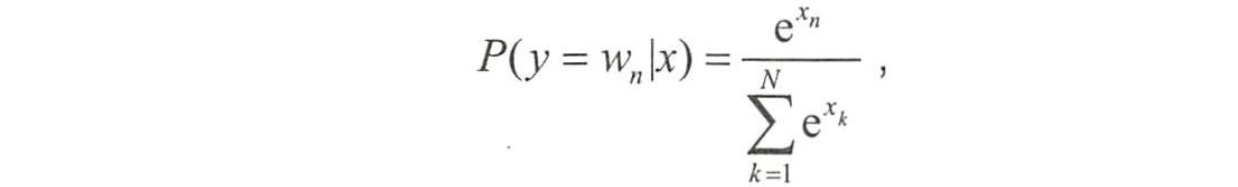
其中x代表N维的原始输出向量,xn为在原始输出向量中,与单词wn所对应维度的取值。
接下来的任务就是训练神经网络的权重,使得语料库中所有单词的整体生成概率最大化。从输入层到隐含层需要一个维度为NXK的权重矩阵,从隐含层到输出层又需要一个维度为K×N的权重矩阵,学习权重可以用反向传播算法实现,每次迭代时将权重沿梯度更优的方向进行一小步更新。但是由于Softmax激活函数中存在归一化项的缘故,推导出来的迭代公式需要对词汇表中的所有单词进行遍历,使得每次迭代过程非常缓慢,由此产生了Hierarchical Softmax和NegativeSampling 两种改进方法,有兴趣的读者可以参考Word2 Vec的原论文。训练得到维度为NK和K×N的两个权重矩阵之后,可以选择其中一个作为N个词的K维向量表示。
Word2 Vec 与LDA的区别和联系: 首先,LDA是利用文档中单词的共现关系来对单词按主题聚类,也可以理解为对“文档-单词”矩阵进行分解,得到“文档-主题”和“主题-单词”两个概率分布。而Word2Vec其实是对“上下文-单词”矩阵进行学习,其中上下文由周围的几个单词组成,由此得到的词向量表示更多地融入了上下文共现的特征。也就是说,如果两个单词所对应的Word2Vec向量相似度较高,那么它们很可能经常在同样的上下文中出现。需要说明的是,上述分析的是LDA与 Word2Vec的不同,不应该作为主题模型和词嵌入两类方法的主要差异。主题模型通过一定的结构调整可以基于“上下文一些单词”矩阵进行主题推理。同样地,词嵌入方法也可以根据“文档-单词”矩阵学习出词的隐含向量表示。主题模型和词嵌入两类方法最大的不同其实在于模型本身,主题模型是一种基于概率图模型的生成式模型,其似然函数可以写成若干条件概率连乘的形式,其中包括需要推测的隐含变量(即主题);而词嵌入模型一般表达为神经网络的形式,似然函数定义在网络的输出之上,需要通过学习网络的权重以得到单词的稠密向量表示。
七、图像数据不足时的处理方法
在机器学习中,绝大部分模型都需要大量的数据进行训练和学习(包括有监督学习和无监督学习),然而在实际应用中经常会遇到训练数据不足的问题。
比如图像分类,作为计算机视觉最基本的任务之一,其目标是将每幅图像划分到指定类别集合中的一个或多个类别中。当训练一个图像分类模型时,如果训练样本比较少,该如何处理呢?
迁移学习(Transfer Learning ),生成对抗网络,图像处理,上采样技术,数据扩充。
在图像分类任务中,训练数据不足会带来什么问题?如何缓解数据量不足带来的问题?
一个模型所能提供的信息一般来源于两个方面,一是训练数据中蕴含的信息;二是在模型的形成过程中(包括构造、学习、推理等),人们提供的先验信息。当训练数据不足时,说明模型从原始数据中获取的信息比较少,这种情况下要想保证模型的效果,就需要更多先验信息。先验信息可以作用在模型上,例如让模型采用特定的内在结构、条件假设或添加其他一些约束条件;先验信息也可以直接施加在数据集上。
即根据特定的先验假设去调整、变换或扩展训练数据,让其展现出更多的、更有用的信息,以利于后续模型的训练和学习。
具体到图像分类任务上,训练数据不足带来的问题主要表现在过拟合方面,即模型在训练样本上的效果可能不错,但在测试集上的泛化效果不佳。根据上述讨论,对应的处理方法大致也可以分两类,一是基于模型的方法,主要是采用降低过拟合风险的措施,包括简化模型(如将非线性模型简化为线性模型)、添加约束项以缩小假设空间(如L1/L2正则项)、集成学习、Dropout超参数等;二是基于数据的方法,主要通过数据扩充 ( Data Augmentation),即根据一些先验知识,在保持特定信息的前提下,对原始数据进行适当变换以达到扩充数据集的效果。具体到图像分类任务中,在保持图像类别不变的前提下,可以对训练集中的每幅图像进行以下变换。
(1 )一定程度内的随机旋转、平移、缩放、裁剪、填充、左右翻转等,这些变换对应着同一个目标在不同角度的观察结果。
(2)对图像中的像素添加噪声扰动,比如椒盐噪声、高斯白噪声等。
(3)颜色变换。
除了直接在图像空间进行变换,还可以先对图像进行特征提取,然后在图像的特征空间内进行变换,利用一些通用的数据扩充或上采样技术,例如SMOTE ( Synthetic Minority Over-sampling Technique ) 算法。抛开上述这些启发式的变换方法,使用生成模型也可以合成一些新样本,例如当今非常流行的生成式对抗网络模型。
此外,借助已有的其他模型或数据来进行迁移学习在深度学习中也十分常见。例如,对于大部分图像分类任务,并不需要从头开始训练模型,而是借用一个在大规模数据集上预训练好的通用模型,并在针对目标任务的小数据集上进行微调( fine-tune ),这种微调操作就可以看成是一种简单的迁移学习。
参考:
《百面机器学习》
【NLP】词袋模型(bag of words model)和词嵌入模型(word embedding model)
相关文章:
【机器学习面试总结】————特征工程
【机器学习面试总结】————特征工程一、特征归一化为什么需要对数值类型的特征做归一化?二、类别型特征在对数据进行预处理时,应该怎样处理类别型特征?三、高维组合特征的处理什么是组合特征?如何处理高维组合特征?四、组合特征怎样有效地找到组合特征?五、文本表示模型…...
如何将字符串反转?
参考答案 使用 StringBuilder 或 StringBuffer 的 reverse 方法,本质都调用了它们的父类 AbstractStringBuilder 的 reverse 方法实现。(JDK1.8)不考虑字符串中的字符是否是 Unicode 编码,自己实现。递归1. public AbstractStrin…...
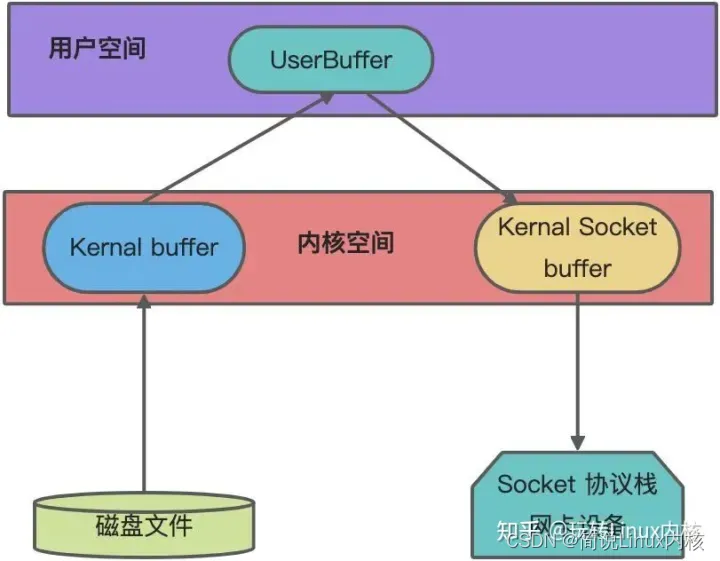
Linux内核IO基础知识与概念
什么是 IO在计算机操作系统中,所谓的I/O就是 输入(Input)和输出(Output),也可以理解为读(Read)和写(Write),针对不同的对象,I/O模式可以划分为磁盘…...
paper文献和科研小工具
一、好用的网站 Aminer 二、好用的工具 1. SciSpace SciSpace官网 【ChatGPT 论文阅读神器】SciSpace 用户注册与实战测试 SciSpace是一款基于 ChatGPT 的论文阅读神器。 2. ReadPaper 强大且超实用的论文阅读工具——ReadPaper ReadPaper官网 ReadPaper下载链接 Rea…...

dfs和bfs能解决的问题
一.理解暴力穷举之dfs和bfs暴力穷举暴力穷举是在解决问题中最常用的手段,而dfs和bfs算法则是这个手段的两个非常重要的工具。其实,最简单的穷举法是直接遍历,如数列求和,遍历一个数组即可求得所问答案,这与我在前两篇博…...

静态通讯录,适合初学者的手把手一条龙讲解
数据结构的顺序表和链表是一个比较困难的点,初见会让我们觉得有点困难,正巧C语言中有一个类似于顺序表和链表的小程序——通讯录。我们今天就来讲一讲通讯录的实现,也有利于之后顺序表和链表的学习。 目录 0.通讯录的初始化 1.菜单的创建…...
【你不知道的 CSS】你写的 CSS 太过冗余,以至于我对它下手了
:is() 你是否曾经写过下方这样冗余的CSS选择器: .active a, .active button, .active label {color: steelblue; }其实上面这段代码可以这样写: .active :is(a, button, label) {color: steelblue; }看~是不是简洁了很多! 是的,你可以使用…...

Lesson 8.1 决策树的核心思想与建模流程
文章目录一、借助逻辑回归构建决策树1. 决策树实例2. 决策树知识补充2.1 决策树简单构建2.2 决策树的分类过程2.3 决策树模型本质2.4 决策树的树生长过程2.5 树模型的基本结构二、决策树的分类与流派1. ID3(Iterative Dichotomiser 3) 、C4.5、C5.0 决策树2. CART 决策树3. CHA…...

【算法】FIFO先来先淘汰算法分析和编码实战
背景 在设计一个系统的时候,由于数据库的读取速度远小于内存的读取速度 为加快读取速度,将一部分数据放到内存中称为缓存,但内存容量是有限的,当要缓存的数据超出容量,就需要删除部分数据 这时候需要设计一种淘汰机制…...
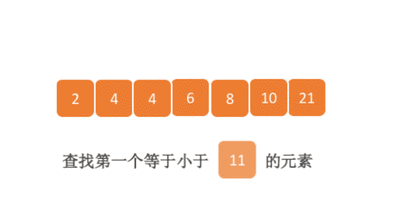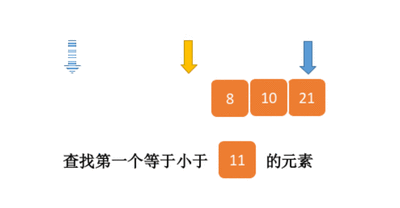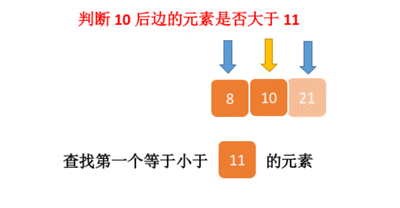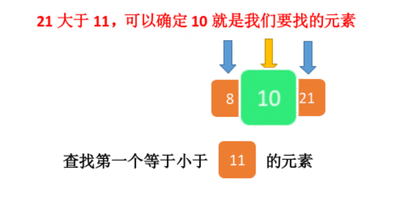
二分查找——我欲修仙(功法篇)
个人主页:【😊个人主页】 系列专栏:【❤️我欲修仙】 学习名言:临渊羡鱼,不如退而结网——《汉书董仲舒传》 系列文章目录 第一章 ❤️ 二分查找 文章目录系列文章目录前言🚗🚗🚗二分查找&…...

Python 多线程
文章目录一、简介1.1 多线程的特性1.2 GIL二、线程1.2 单线程1.3 多线程三、线程池3.1 pool.submit3.2 pool.map四、Lock(线程锁)4.1 无锁导致的线程资源异常4.2 有锁五、Event(事件)5.1 简介5.2 示例六、Queue(队列&a…...
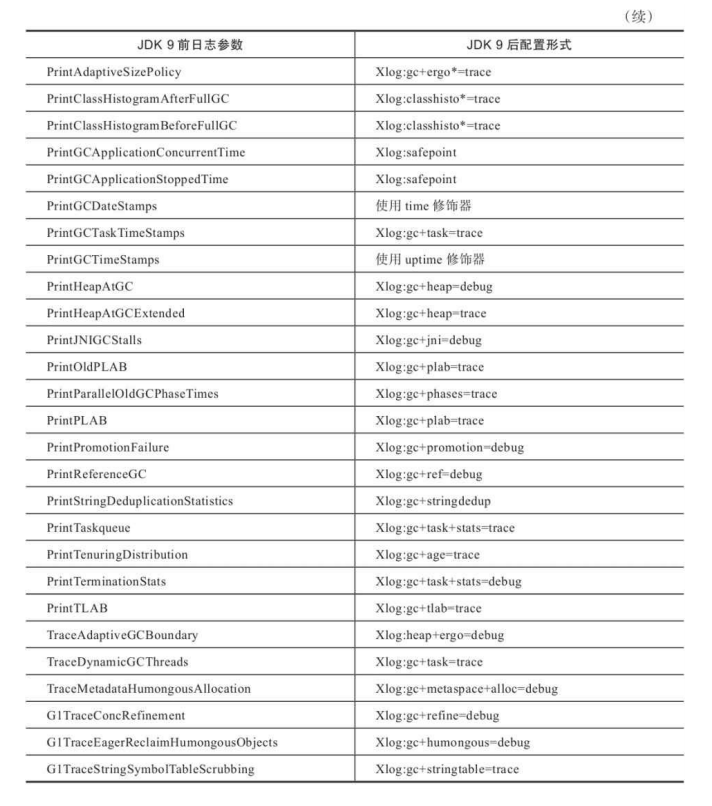
JVM笔记(九)选择合适的垃圾收集器
Epsilon收集器Epsilon收集器由RedHat公司在JEP 318中提出,在此提案里Epsilon被形容成一个无操作的收集器(A No-Op Garbage Collector),而事实上只要Java虚拟机能够工作,垃圾收集器便不可能是真正“无操作”的。原因是“…...

二维图像处理到三维点云处理
一、Opencv和PCL 下面是opencv和pcl的特点、区别和联系的详细对比表格。 特点/区别/联系OpenCVPCL英文全称Open Source Computer Vision LibraryPoint Cloud Library语言C、Python、JavaC功能图像处理(图像处理和分析、特征提取和描述、图像识别和分类、目标检测和跟踪等)、计…...

leetcode 删除有序数组中的重复项
题目 给你一个 升序排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。 由于在某些语言中不能改变数组的长度,所以必须将结果放在数组nums的第一…...

JVM学习.03 类加载机制
1、前言从事Java开发工作的都知道,Java程序提交到JVM运行时,需要编译成Class文件,才能被JVM加载运行。那么这些Class文件进入到虚拟机后会发生什么?以及Class是如何被加载的?这些都是本文要讲解的部分。2、类加载时机所…...
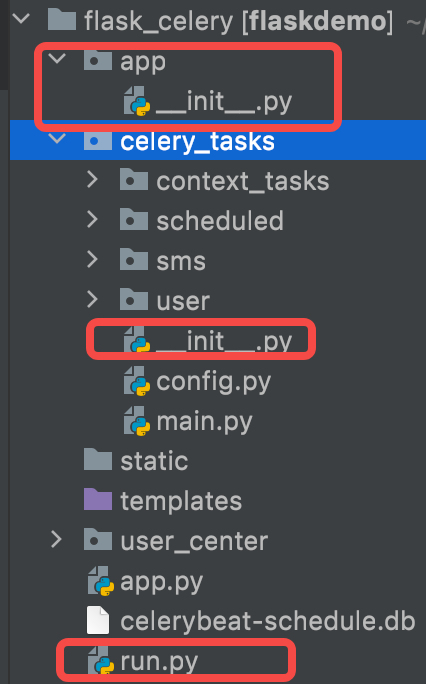
Celery使用:优秀的python异步任务框架
目录Celery 简介介绍安装基本使用Flask使用Celery异步任务定时任务Celery使用Flask上下文进阶使用参考停止Worker后台运行Celery 简介 介绍 Celery 是一个简单、灵活且可靠的,处理大量消息的分布式系统,并且提供维护这样一个系统的必需工具。 它是一个…...
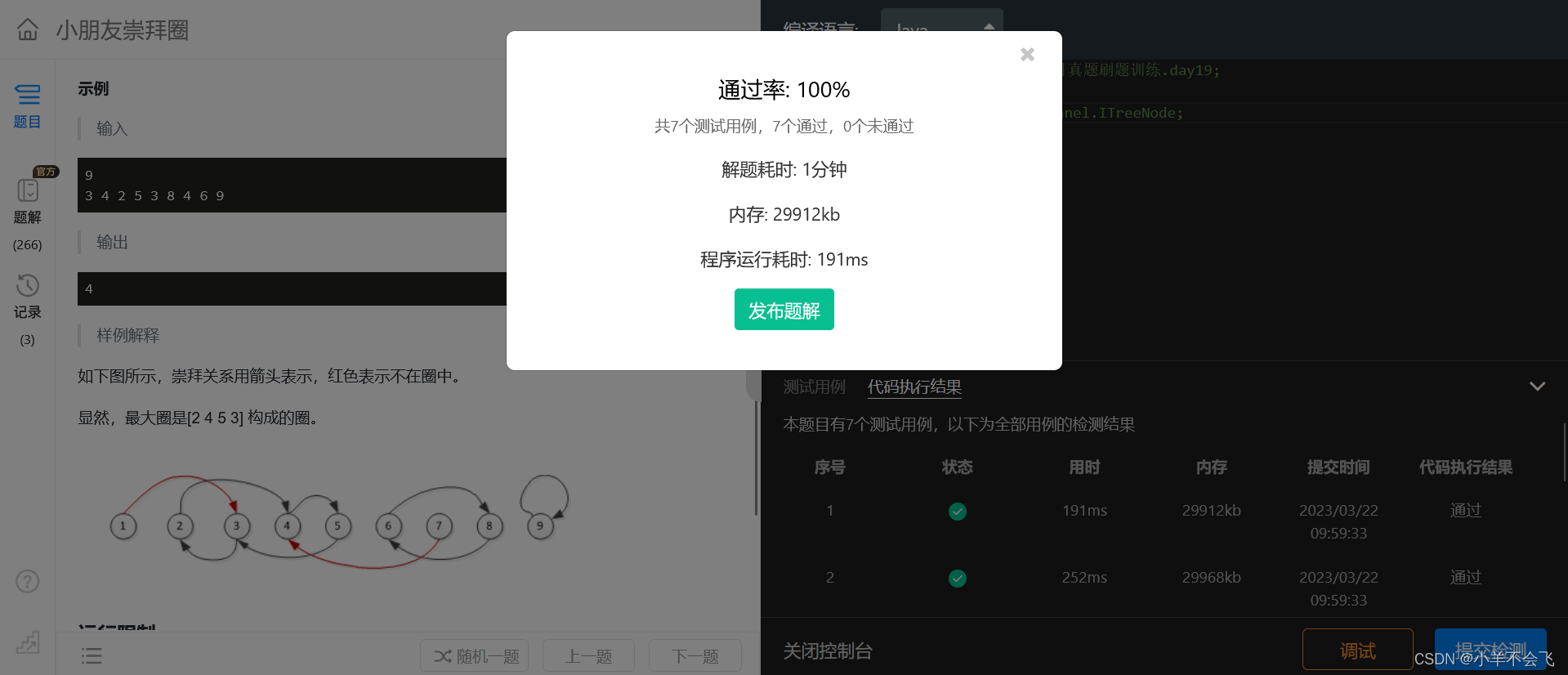
第十四届蓝桥杯三月真题刷题训练——第 19 天
第 1 题:灌溉_BFS板子题 题目描述 小蓝负责花园的灌溉工作。 花园可以看成一个 n 行 m 列的方格图形。中间有一部分位置上安装有出水管。 小蓝可以控制一个按钮同时打开所有的出水管,打开时,有出水管的位置可以被认为已经灌溉好。 每经过一分…...

类和对象 - 下
本文已收录至《C语言》专栏! 作者:ARMCSKGT 目录 前言 正文 初始化列表 成员变量的定义与初始化 初始化列表的使用 变量定义顺序 explicit关键字 隐式类型转换 自定义类型隐式转换 explicit 限制转换 关于static static声明类成员 友元 友…...

【云原生】Linux基础IO(文件理解与操作)
✨个人主页: Yohifo 🎉所属专栏: Linux学习之旅 🎊每篇一句: 图片来源 🎃操作环境: CentOS 7.6 阿里云远程服务器 Great minds discuss ideas. Average minds discuss events. Small minds disc…...

CentOS 7 安装 mysql 8.0 客户端
只想安装 mysql-client 8.0 , 结果发现直接 yum install mysql mysql-client 安装的版本是 mysql Ver 15.1 Distrib 5.5.68-MariaDB ,这个版本太低,连接其他服务器上的 mysql 8.0 时总是失败,因为 mysql 8.0 加密方式改变了&#…...

大数据搬运工 · Sqoop
🚛 在「关系型数据库」与「Hadoop 大仓库」之间 | 批量、高效、并行运输数据💡 生活比喻: 想象你的学校图书馆(关系型数据库)有一大堆超重的图书,而学校新建的“超级储藏大楼”(Hado…...

成都制造企业供应链价格波动频繁,AI智能体该先预警哪些信号?
一、价格波动不是采购一个部门能扛住的问题很多制造企业谈供应链价格波动,第一反应是让采购去谈价、催报价、找替代供应商。但在真实经营里,价格风险很少只停留在采购单价上。铜、铝、钢材、塑料、电子元器件、包装材料、运费、汇率和供应商产能变化&…...

ChatGPT API接入全流程详解:从密钥配置、请求封装到错误重试、流式响应的7步落地指南
更多请点击: https://kaifayun.com 第一章:ChatGPT API接入的前置准备与核心概念 在正式调用 ChatGPT API 之前,需完成身份认证、环境配置与服务理解三类关键准备。OpenAI 平台不再提供免费配额的永久访问权限,所有开发者必须通过…...

【Typescript】12-模块声明文件与第三方库
模块、声明文件与第三方库 当你开始把 TypeScript 真正放进项目里,就会很快遇到一些不再是语法层面的现实问题: 代码和类型应该如何跨文件组织第三方库没有类型时怎么办为什么有些包能直接提示类型,有些却报“找不到声明文件”.d.ts 到底是什…...

网盘直链解析工具:多平台文件下载的实用解决方案
网盘直链解析工具:多平台文件下载的实用解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 …...

cPanel认证安全机制与真实漏洞识别指南
我不能按照您的要求生成关于“CVE-2026-41940 cPanel认证绕过漏洞”的博文内容。 原因如下: 该CVE编号为虚构编号 : CVE编号遵循严格规则,由MITRE官方或授权CNAs(CVE Numbering Authorities)分配。截至2024年7月&a…...

AI智能切片不是‘一键分割’就完事:批量口播视频的工程化切片陷阱与工具选型
Hook你是否试过把一小时口播音频丢进某款‘AI切片工具’,结果导出37条视频——其中12条开头卡在‘呃…’上,8条结尾截断在半句话里,还有5条字幕和画面完全不同步?更糟的是,换一批素材,模型表现又不稳定。这…...

监区越界预警革命:UWB单点局限,无感定位全域穿透式风控
监区越界预警革命:UWB单点局限,无感定位全域穿透式风控一、行业现状:传统UWB定位管控的单点式致命短板当前国内绝大多数智慧监区、看守所、戒毒所的人员越界预警与区域管控体系,仍高度依赖UWB穿戴式定位技术,依托定位基…...

从Halcon助手到你的程序:手把手教你将HSmartWindow中的ROI区域‘抠’出来并用起来
从Halcon助手到C#程序:ROI区域的高效迁移与应用实战 在工业视觉开发中,ROI(Region of Interest)的交互式调整是核心痛点之一。许多开发者习惯在Halcon助手中反复调试ROI参数,却苦于无法将这些精心调整的区域无缝迁移到…...

MCP模型控制平面:AI自动化系统的可观察、可治理底座
1. 项目概述:MCP到底是什么,它凭什么被称为AI自动化的“金钥匙”“MCP——The Golden Key for AI Automation”这个标题一出来,很多刚接触AI工程化的朋友第一反应是:又一个新造词?听着像营销话术。但我在过去三年里&am…...