【java基础】Stream流的各种操作
文章目录
- 基本介绍
- 流的创建
- 流的各种常见操作
- forEach方法
- filter方法
- map方法
- peek方法
- flatMap方法
- limit和skip方法
- distinct方法
- sorted方法
- 收集结果
- 收集为数组(toArray)
- 收集为集合(collect)
- 收集为Map
- 关于流的一些说明(终结操作)
- 总结
基本介绍
Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
与集合相比,流提供了一种可以让我们在更高概念级别上指定计算任务的数据视图
注意:学习Stream必须要十分清晰的了解lamdba表达式,如果lambda不清楚,请参考一篇文章彻底搞懂lambda表达式
流的创建
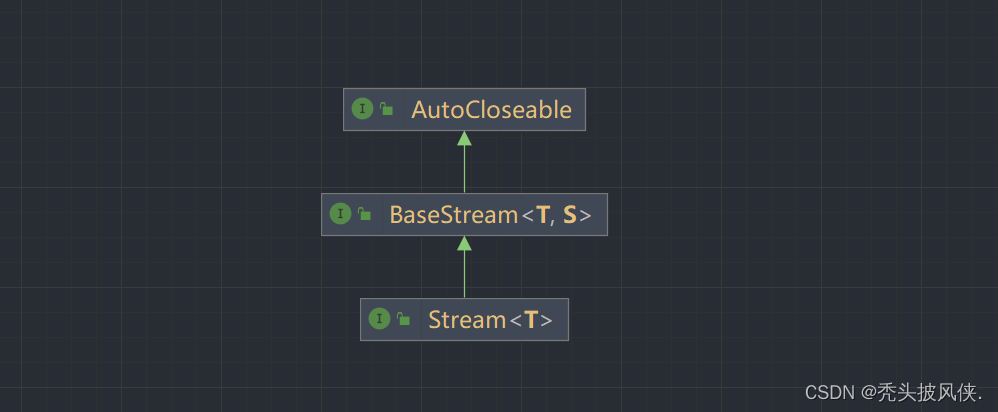
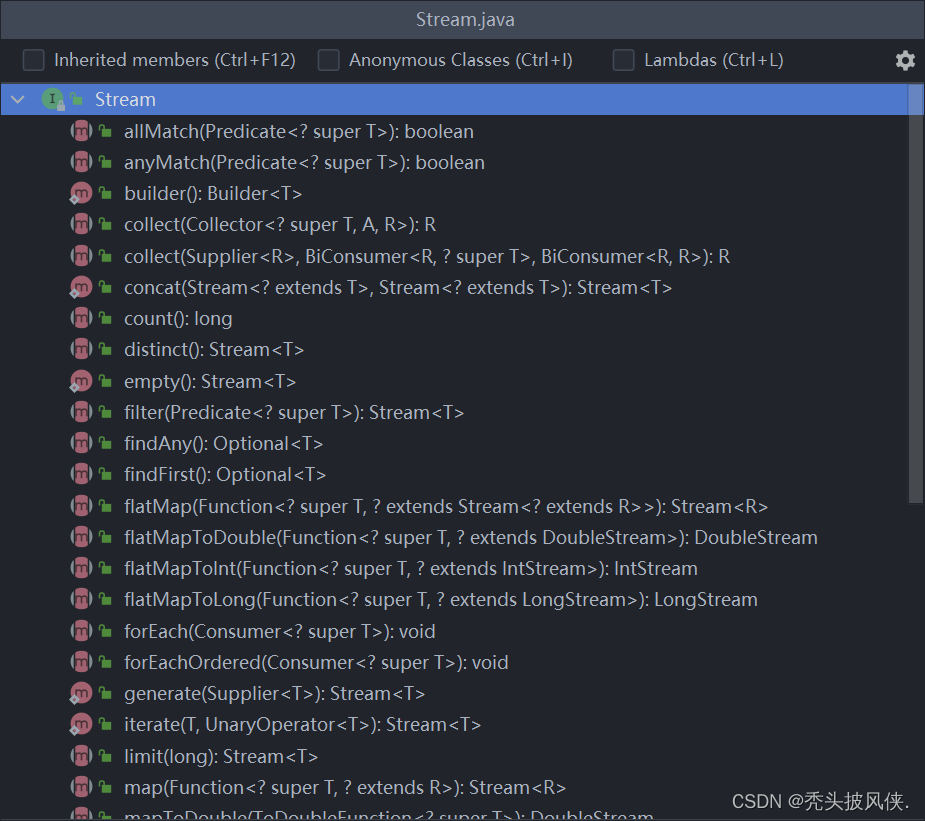
我们在学习流之前,应当先了解一下Stream这个类,Stream类的类图和方法如下
对于创建流,我们可以使用静态方法Stream.of来创建
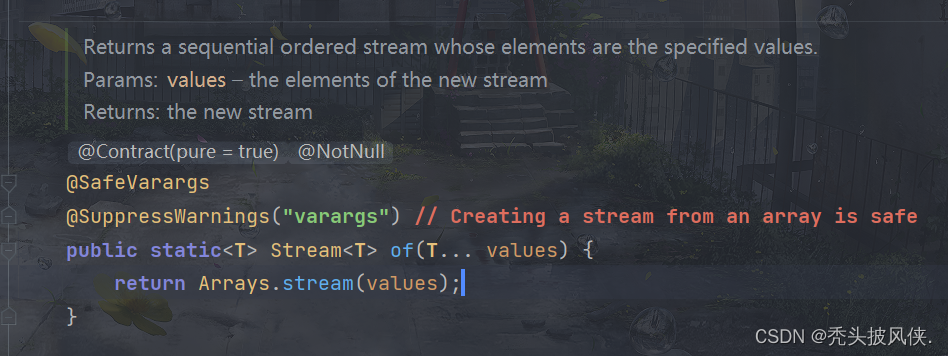
该方法传入一个可变长度的参数,然后就会返回对应类型的流
Stream<Integer> stream = Stream.of(2, 3, 1, 4);
如果要创建一个不包含任何元素的流,可以使用Stream.empty
Stream<Object> empty = Stream.empty();
我们还可以使用Stream的静态方法generate和iterate来创建无限流。
下面就通过generate创建了一个获取随机数的流
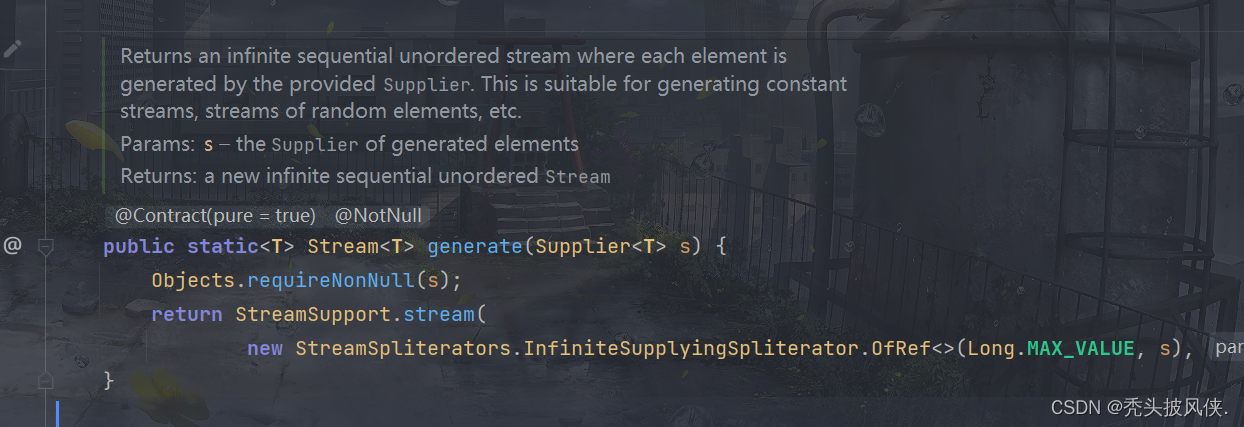
Stream<Double> randomNumStream = Stream.generate(Math::random);
如果想要创建例如0,1,2,3这样有规律的序列流,那么就可以使用iterate方法

Stream<Integer> iterate = Stream.iterate(0, num -> num+1);
除了上面几个静态方法,对于流的创建还有许多方法,例如Arrays.stream方法
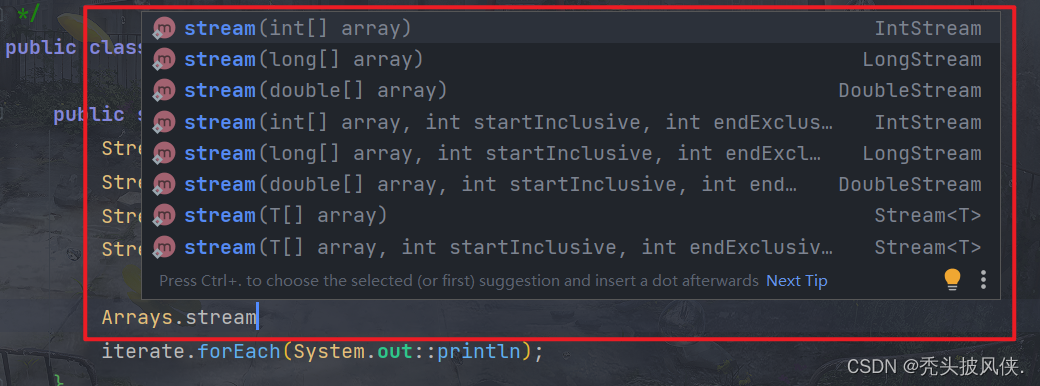
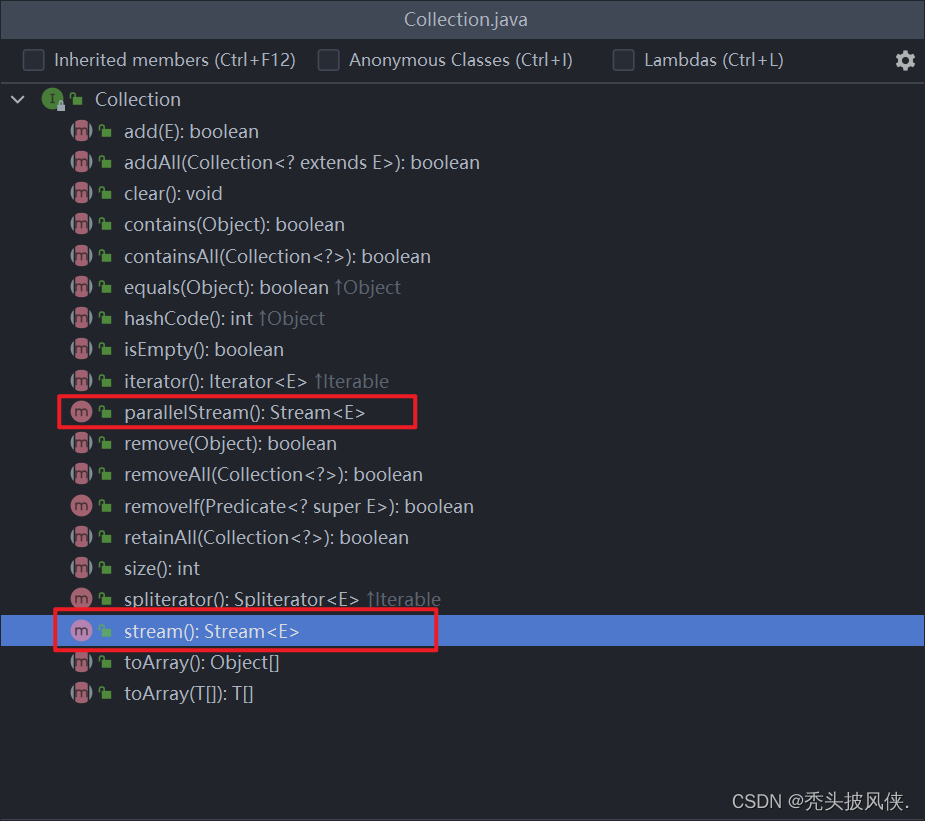
在Collection中有stream方法和parallelStream方法都可以返回一个Stream流,这也就说明了所有的集合都可以调用这2个方法返回对应的流
对于流,我们有几点注意事项如下
- 流并不存储元素,这些元素可能存储在底层的集合中,或者是按需生成的
- 流的操作不会改变其数据源
- 流的操作尽可能惰性执行。这意味着直至需要其结果时,操作才会执行
流的各种常见操作
这里主要介绍在流里面使用频率较高的几个操作,每个方法都会给出该方法的源注释,以及基本使用,请参考注释和代码来进行理解
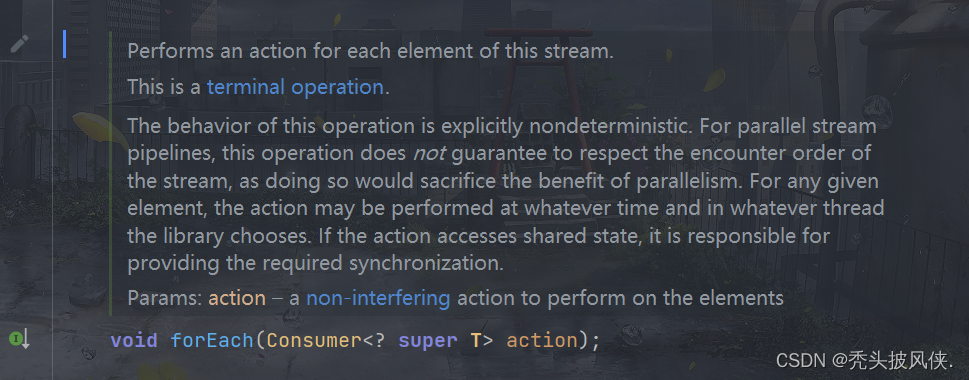
forEach方法
这个方法可以对流里面的每一个元素执行操作
Stream<Integer> stream = Stream.of(2, 3, 1, 4);stream.forEach(System.out::println);
输出结果如下
2
3
4
1
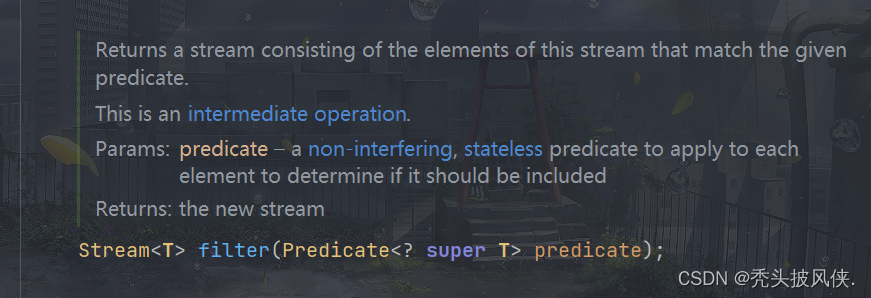
filter方法
该方法可以过滤掉流中不满足要求的元素,会返回一个新流
Stream<Integer> stream = Stream.of(2, 3, 1, 4);Stream<Integer> newStream = stream.filter(num -> num > 2);System.out.print("过滤之后:");newStream.forEach(x -> System.out.print(x + " "));
上面代码输出如下
过滤之后:3 4
map方法
当我们想要按照某种方式来转换流中的值的时候,我们就可以使用map

Stream<Integer> stream = Stream.of(2, 3, 1, 4);Stream<Integer> newStream = stream.map(num -> num + 1);newStream.forEach(System.out::println);
上面代码输出如下
3
4
2
5
peek方法
该方法可以对流中的每一个元素进行操作,返回新的流
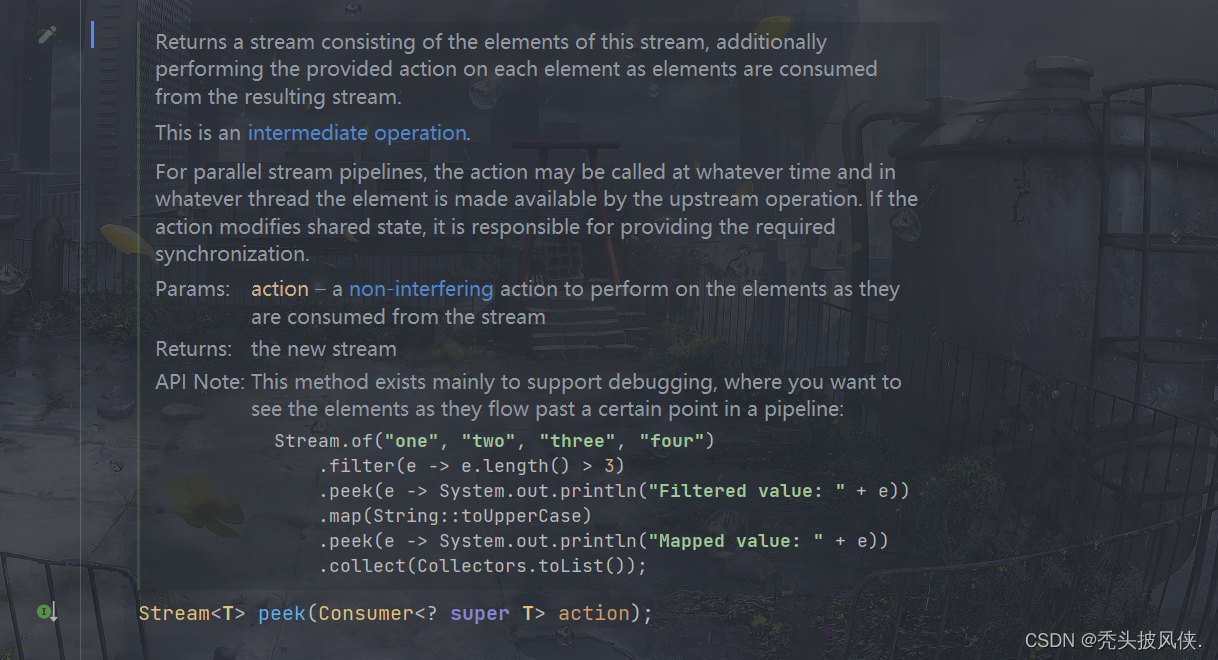
public class Dog {public String name;public Integer age;public Dog(String name, Integer age) {this.name = name;this.age = age;}@Overridepublic String toString() {return "Dog{" +"name='" + name + '\'' +", age=" + age +'}';}
}
Dog[] dogs = {new Dog("tom", 1),new Dog("旺财", 2)};Stream<Dog> dogStream = Arrays.stream(dogs);Stream<Dog> newDogStream = dogStream.peek(dog -> dog.age = 999);newDogStream.forEach(System.out::println);
上面代码输出如下
Dog{name='tom', age=999}
Dog{name='旺财', age=999}
flatMap方法
该方法产生一个流,它是通过将传入lambda表达式应用于当前流中所有元素所产生的结果连接到一起而获得的。(注意,这里的每个结果都是一个流。)
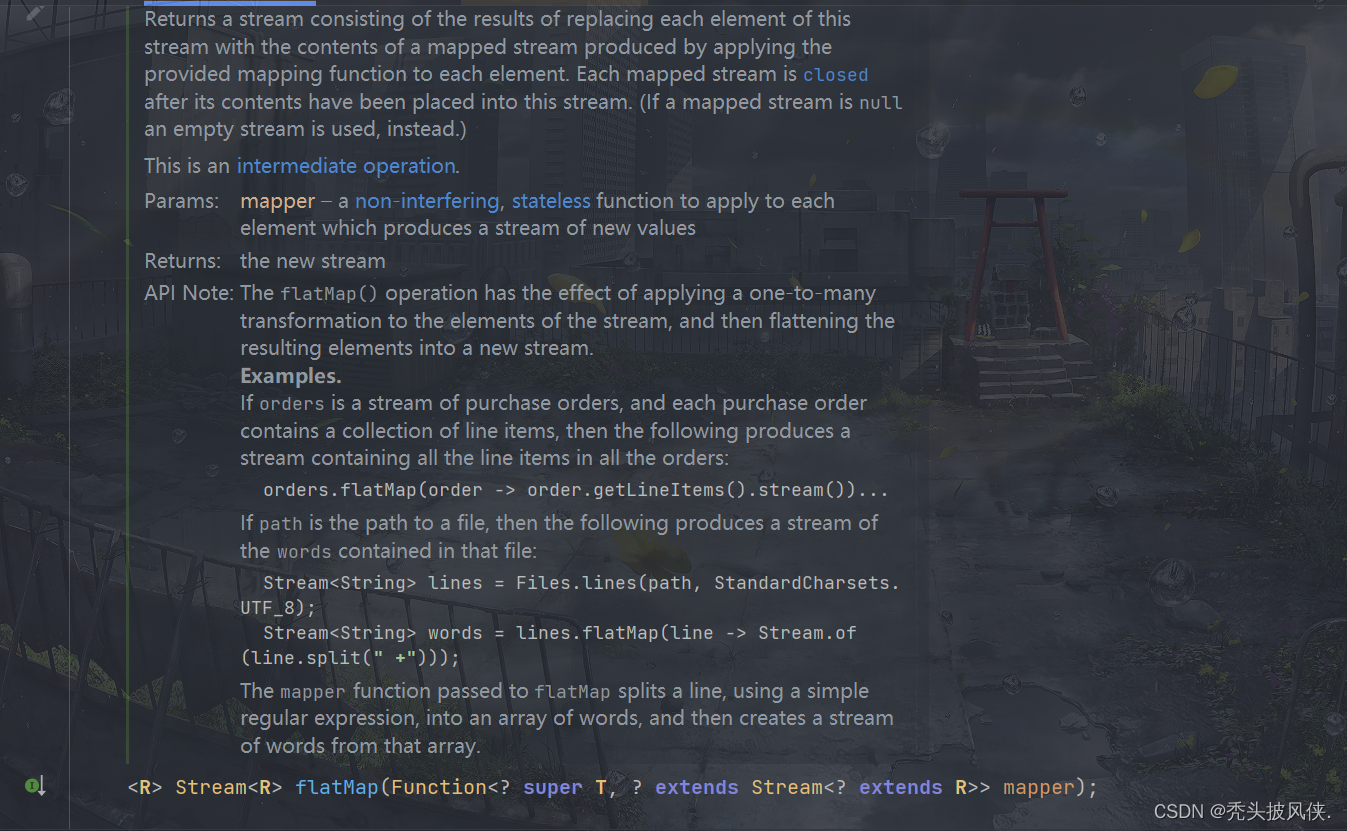
List<Stream<Integer>> streamList = new ArrayList<>();Stream<Integer> stream1 = Stream.of(1, 2, 3);Stream<Integer> stream2 = Stream.of(4, 5, 6);Stream<Integer> stream3 = Stream.of(7, 8, 9);streamList.add(stream1);streamList.add(stream2);streamList.add(stream3);Stream<Stream<Integer>> stream = streamList.stream();// flatMap里面的lambda表达式应当返回一个流Stream<Integer> integerStream = stream.flatMap(x -> x);integerStream.forEach(System.out::println);
上面代码输出如下
1
2
3
4
5
6
7
8
9
limit和skip方法
limit方法可以对流进行裁剪,只取前n个流,skip方法则是跳过前n个流
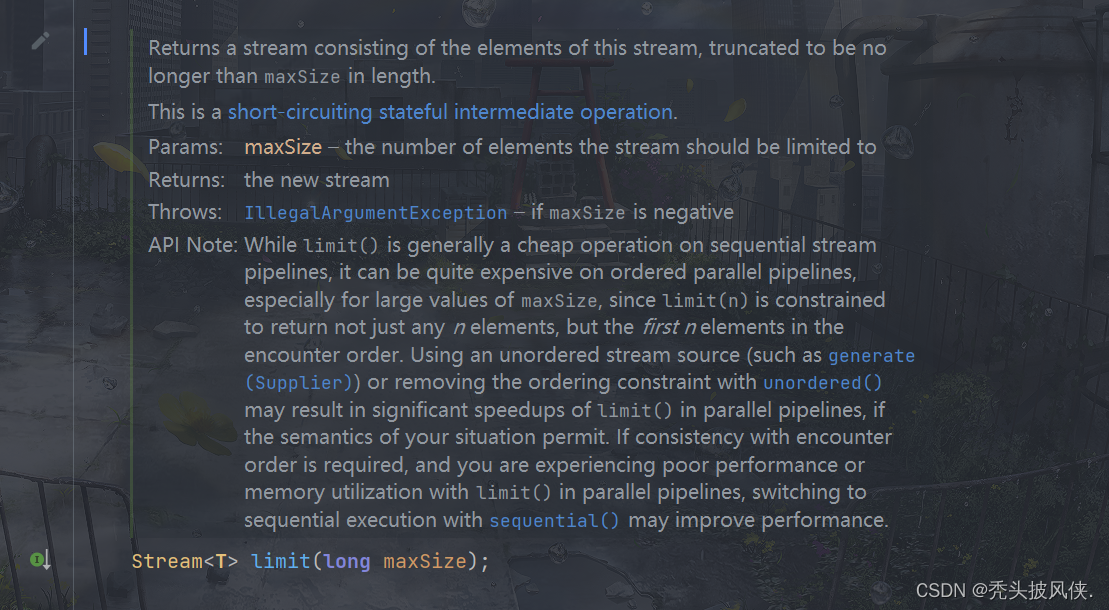
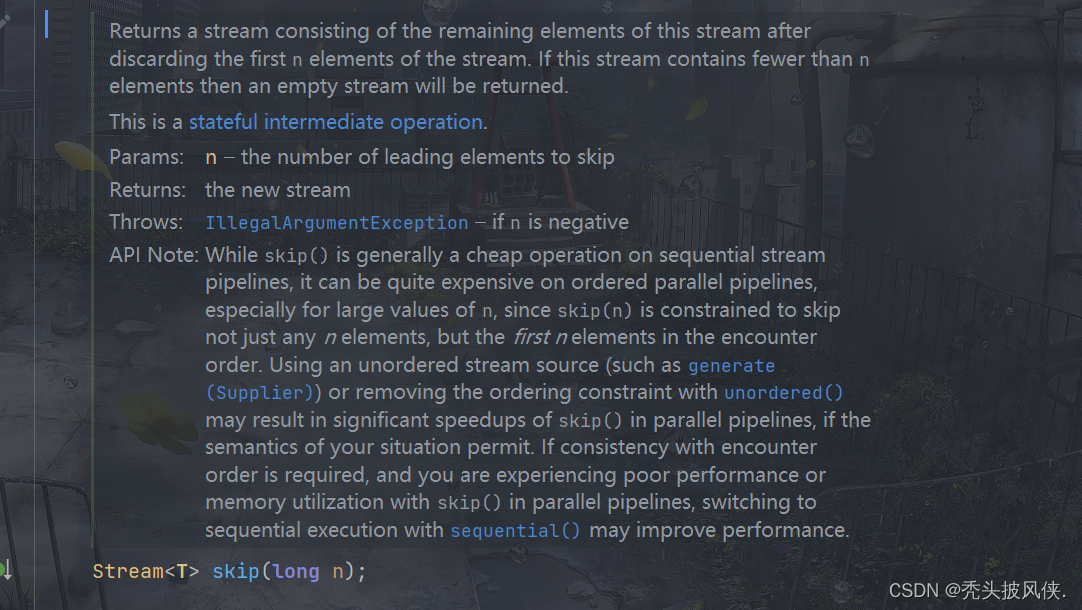
由于limit和skip用法基本由于,这里就用limit作为例子
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);Stream<Integer> newStream = stream.limit(4);newStream.forEach(System.out::println);
上面代码输出如下
1
2
3
4
distinct方法
这个方法相当于去重

Stream<Integer> stream = Stream.of(1, 2, 3, 3, 1, 4);Stream<Integer> newStream = stream.distinct();newStream.forEach(System.out::println);
代码输出如下
1
2
3
4
sorted方法
这个方法一看就知道是排序用的
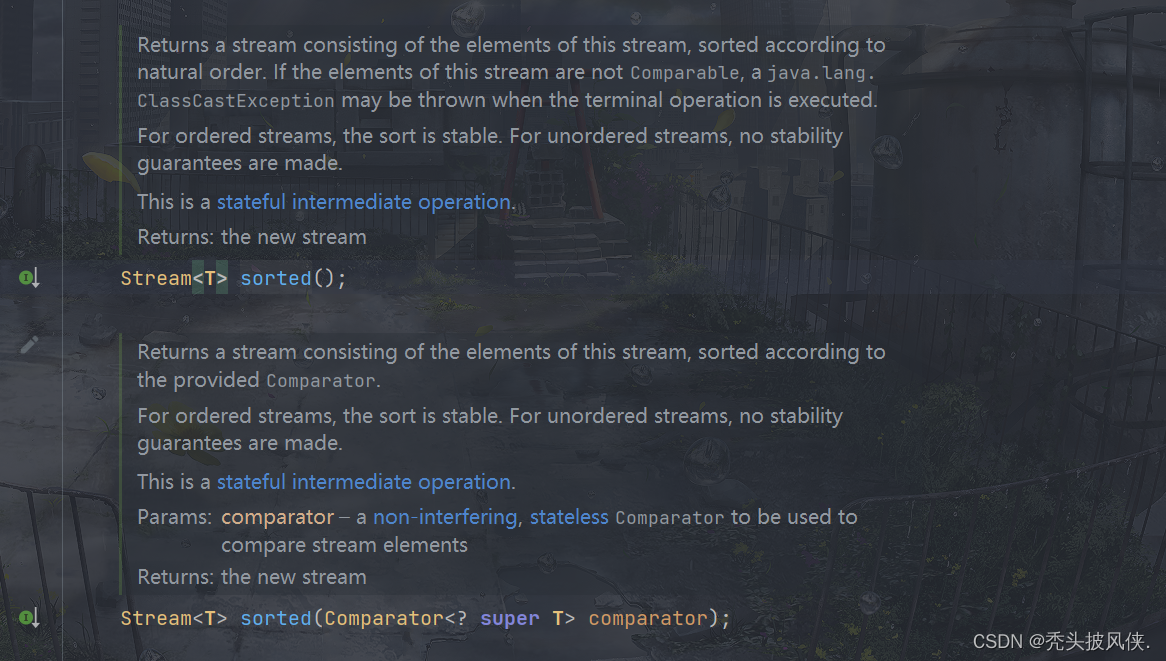
该方法有2个,一个带有Comparator,就是用于指定排序方式的
Stream<Integer> stream = Stream.of(4, 1, 3, 2);Stream<Integer> newStream = stream.sorted();newStream.forEach(System.out::println);
代码输出如下
1
2
3
4
收集结果
在上面我们都只是对流进行操作,现在来讲解下如何将流里面的数据收集到集合中。
收集为数组(toArray)
我们可以调用流里面的toArray方法,传入对应的类型数组即可
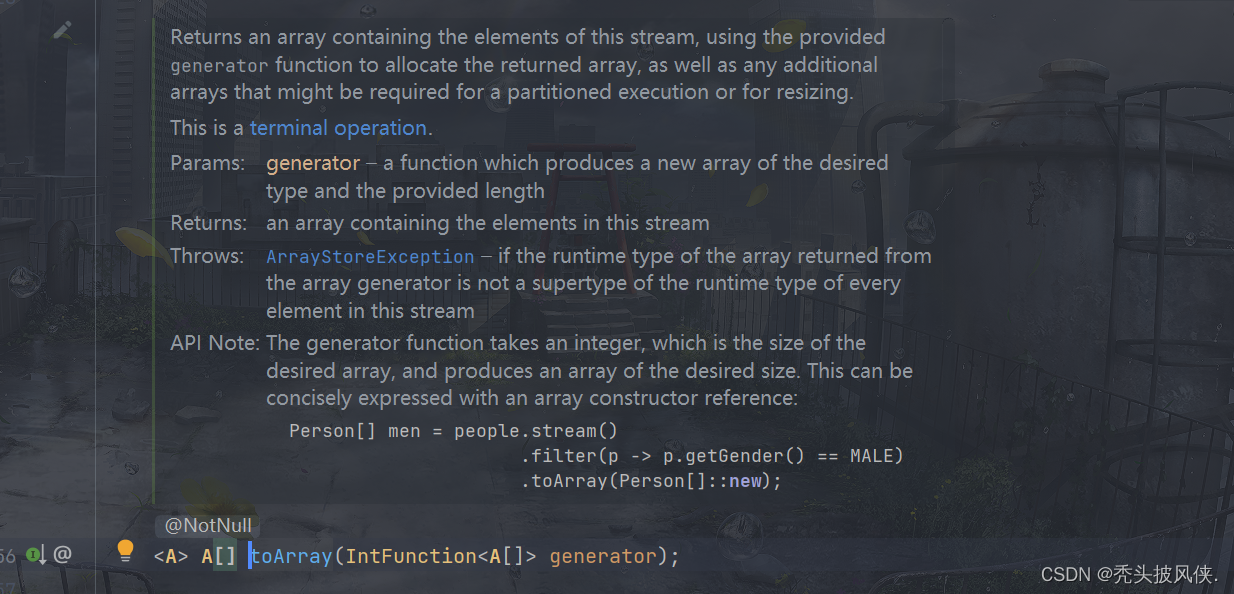
Stream<String> namesStream = Stream.of("tom", "luck", "jerry");String[] names = namesStream.toArray(String[]::new);System.out.println(Arrays.toString(names));
上面代码输出如下
[tom, luck, jerry]
收集为集合(collect)
调用stream里面的collect方法,然后传入指定的Collector实例即可,Collector提供了大量用于生成常见收集器的工厂方法。
Collector类的方法如下
可以发现有很多方法,这里先介绍几个常用的,其他的方法在后面文章中进行说明。
List<Integer> nums = Arrays.asList(1,2,3,1,4);
toList()可以将结果收集为List
List<Integer> list = nums.stream().collect(Collectors.toList());
toSet()可以将结果收集为Set
Set<Integer> set = nums.stream().collect(Collectors.toSet());
toCollection()可以指定收集的集的种类
TreeSet<Integer> treeSet = nums.stream().collect(Collectors.toCollection(TreeSet::new));
在Collector这个类里面还有其他的很多方法,建议大家去看看这个类的文档,对每个方法都有个影响,需要用到某种操作的时候查找文档即可。
收集为Map
Map也是集合,但是Map收集要比如List,Set等要麻烦一点,所以这里单独说明一下,toMap方法如下
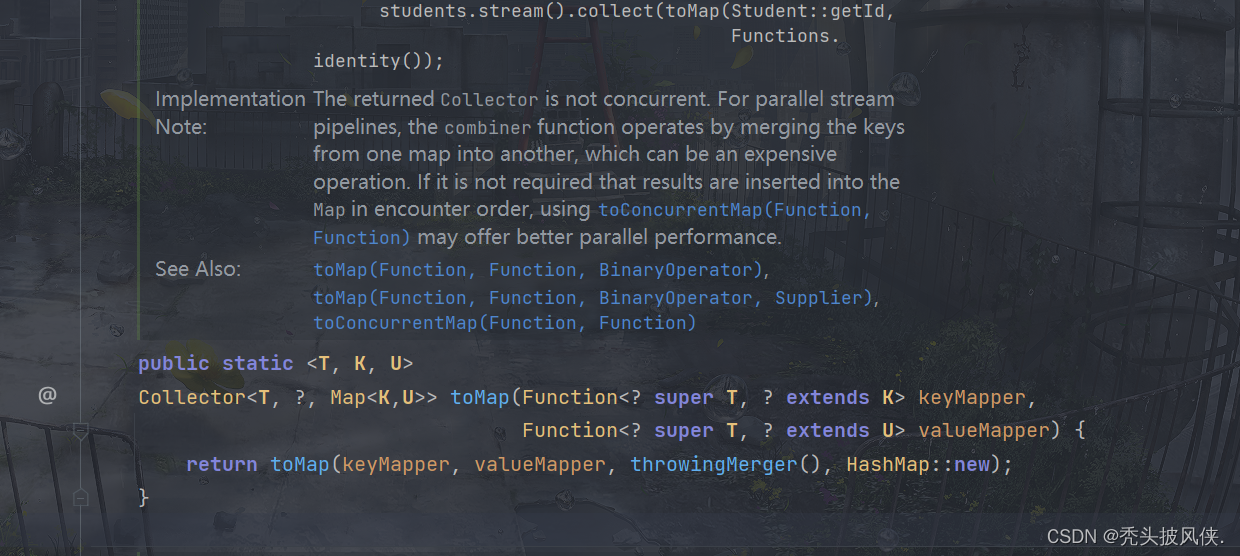
我们需要指定k和v是什么,其实就是对于每一个元素,用什么来作为k和v
Stream<String> namesStream = Stream.of("tom", "jack", "lucy");Map<Character, String> namesMap = namesStream.collect(Collectors.toMap(k -> k.charAt(0), v -> v.toUpperCase()));System.out.println(namesMap);
上面代码就用字符串的第一个字符作为k,然后用字符串的大写作为v。上面代码输出如下
{t=TOM, j=JACK, l=LUCY}
使用toMap还有一点需要说明,就是key不能冲突,看下面代码,就会产生key冲突
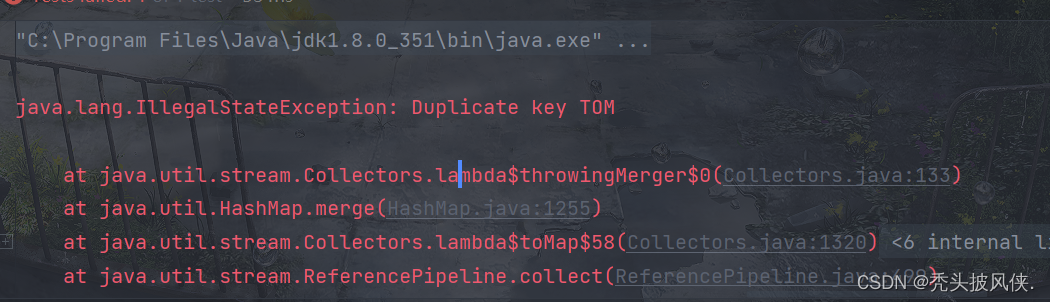
Stream<String> namesStream = Stream.of("tom", "jack", "lucy","ttpfx");Map<Character, String> namesMap = namesStream.collect(Collectors.toMap(k -> k.charAt(0), v -> v.toUpperCase()));System.out.println(namesMap);
如果产生key冲突,那么collect方法会抛出一个一个IllegalStateException异常
对于key冲突的情况,我们应该给出解决key冲突的逻辑,toMap还有一个重载的方法,用于解决key冲突。也就是保留新值还是旧值
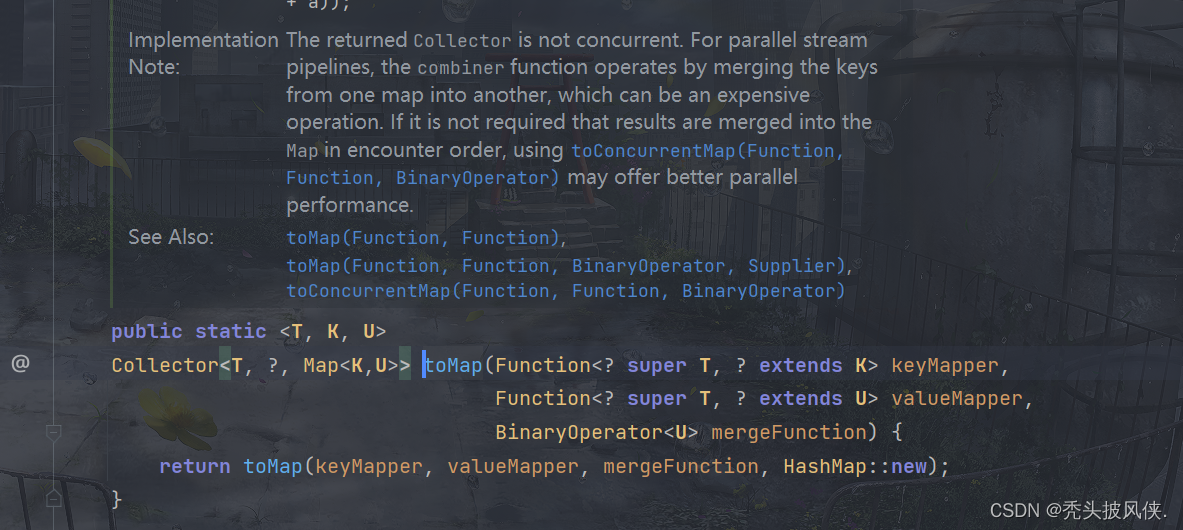
我们遇到key冲突旧保存最新的值即可
Stream<String> namesStream = Stream.of("tom", "jack", "lucy", "ttpfx");Map<Character, String> namesMap = namesStream.collect(Collectors.toMap(k -> k.charAt(0),v -> v.toUpperCase(),(oldV, newV) -> newV));System.out.println(namesMap);
上面代码输出如下
{t=TTPFX, j=JACK, l=LUCY}
对于toMap,都有一个等价的toConcurrentMap
关于流的一些说明(终结操作)
我们先来看下面代码
Stream<Integer> stream = Stream.of(2, 3, 1, 4);stream.forEach(System.out::println);Stream<Integer> newStream = stream.filter(x -> x > 2);newStream.forEach(System.out::println);
上面代码逻辑很简单,就是先输出流里面的元素,然后过滤一下,最后再输出。按理说这个代码应该是没有问题的,我们运行一下
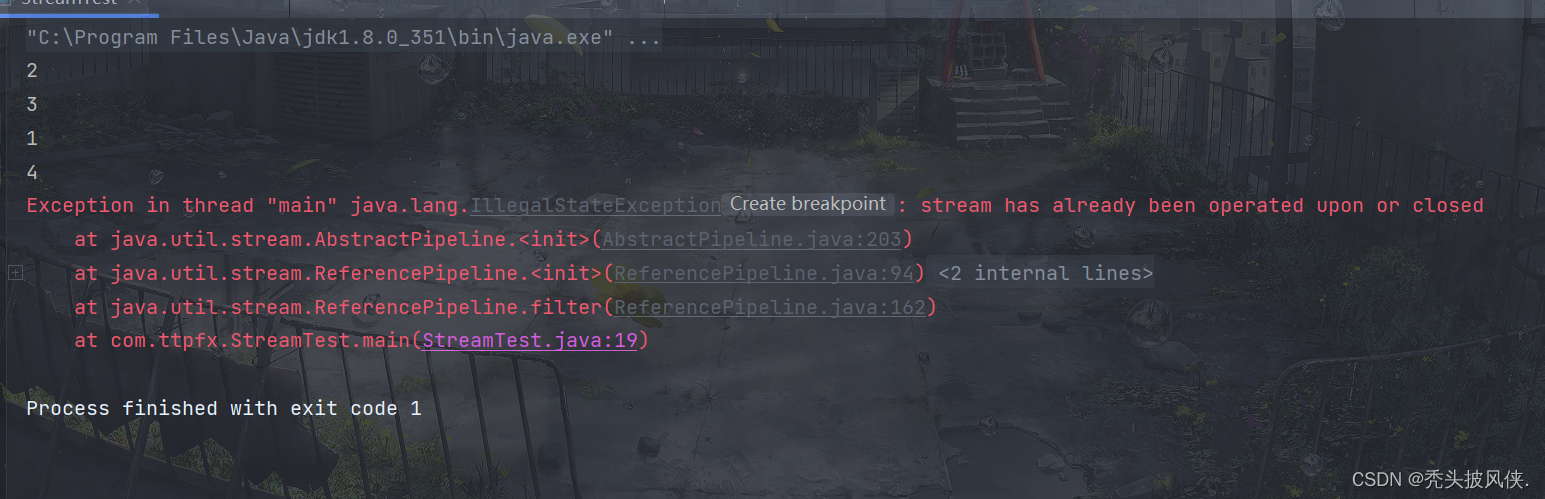
可以发现报错了,报错的原因就是说流已经关闭了,很奇怪啊,我们明明没有执行close操作
造成流关闭的原因就是 forEach方法。还记得在文章开始的说明吗?流是惰性执行的,在流执行终止操作前,流其实都没有执行。而forEach就是一个终止操作。对于终结方法,我们可以简单理解为就是返回值不是Stream的方法。
我们用代码验证一下Stream的惰性执行
List<Integer> list = new ArrayList<>();list.add(1);Stream<Integer> stream = list.stream();list.add(2);long count = stream.count();System.out.println(count);
大家想一下,count是多少?由于Stream是惰性执行的,那么count显然应该就是2
总结
在这篇文章中介绍了Stream的一些基本使用,对于Stream还有许多的方法没有说明,这些会在后面的文章中进行说明。Stream里面还有一个很重要的Optional,这个将在下一篇文章中进行说明。
相关文章:
【java基础】Stream流的各种操作
文章目录基本介绍流的创建流的各种常见操作forEach方法filter方法map方法peek方法flatMap方法limit和skip方法distinct方法sorted方法收集结果收集为数组(toArray)收集为集合(collect)收集为Map关于流的一些说明(终结操…...

【Python练习】序列结构
目录 一、实验目标 二、实验内容...

CDN加速缓存的定义与作用
一、CDN的含义CDN的全称是Content Delivery Network,即内容分发网络。CDN是在原有互联网的基础上再构建虚拟分发网络,利用部署在各地的边缘节点服务器,充分发挥其负载均衡、内容分发智能调度等功能,让用户能够就地拉取数据&#x…...
Java并发高频面试题
分享50道Java并发高频面试题。 线程池 线程池:一个管理线程的池子。 为什么平时都是使用线程池创建线程,直接new一个线程不好吗? 嗯,手动创建线程有两个缺点 不受控风险频繁创建开销大 为什么不受控? 系统资源有…...
CVPR 2023 | 旷视研究院入选论文亮点解读
近日,CVPR 2023 论文接收结果出炉。近年来,CVPR 的投稿数量持续增加,今年收到有效投稿 9155 篇,和 CVPR 2022 相比增加 12%,创历史新高。最终,大会收录论文 2360 篇,接收率为 25.78 %。本次&…...
)
Vue3 学习总结补充(一)
文章目录1、Vue3中为什么修改变量的值后,视图不更新?2、使用 ref 还是 reactive?3、reactive 为什么会有响应性连接丢失情况?4、watch的不同使用方法5、watchEffect和 watch 的区别区别1:数据源的区别区别2:…...

使用ChatGPT 开放的 API 接口可以开发哪些自研工具?
使用ChatGPT开放的API接口,可以开发多种自研工具,例如: 智能聊天机器人:可以使用ChatGPT提供的语言生成能力,构建一个智能聊天机器人,能够根据用户的输入自动回复,完成自然语言交互。 文本生成工具:可以使用ChatGPT的文本生成能力,开发一个文本生成工具,例如自动生…...
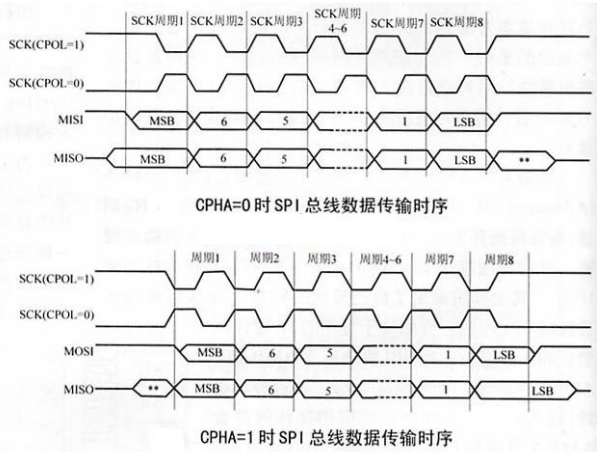
I2C和SPI总线以及通信
通讯属性 概括 Serial/parallel 串行/并行Synchronous/asynchronous 同步/异步Point-to-point / bus 点对点 总线Half-duplex/full-duplex 半双工/全双工Master-slave/ equal partners 主从/对等single-ending / differential 单端/差分 点对点和总线 点对点通讯 只有两个通…...

Spring八股文
Bean的生命周期 1.通过反射生成对象 2.填充Bean的属性 3.调用aware接口的invokeAwareMethod方法,对BeanName、BeanFactory、BeanClassLoader对象的属性设值 4.调用BeanPostProcessor的前置处理方法,其中使用较多的是ApplicationContextPostProcessor…...

20 k8sMetric 简介
一. Metric 简介metrics-server 可实现 Kubernetes 的 Resource Metrics API(metrics.k8s.io),通过此 API 可以查询 Pod 与 Node 的部分监控指标,Pod 的监控指标用于 HPA、VPA 与 kubectl top pods -n ns 命令,而 Node…...
面试问了解Linux内存管理吗?10张图给你安排的明明白白
linux内存管理,内存管理好像离我们很远,但这个知识点虽然冷门(估计很多人学完根本就没机会用上)但绝对是基础中的基础,这就像武侠中的内功修炼,学完之后看不到立竿见影的效果,但对你日后的开发工…...
【C++】内联函数inline
文章目录概念使用特性原理概念 C中内联函数的出现解决了C语言宏函数的不足,类似于宏展开,这种在函数调用处直接嵌入函数体的函数称为内联函数,又称内嵌函数或内置函数。 以inline修饰的函数叫做内联函数,编译时C编译器会在调用内…...
C++演讲比赛流程管理系统_黑马
任务 学校演讲比赛,12人,两轮,第一轮淘汰赛,第二轮决赛 选手编号 [ 10001 - 10012 ] 分组比赛 每组6人 10个评委 去除最高分 最低分,求平均分 为该轮成绩 每组淘汰后三名,前三名晋级决赛 决赛 前三名胜出 …...

谈谈低代码的安全问题,一文全给你解决喽
低代码是一种软件开发方法,通过使用图形化用户界面和可视化建模工具,以及自动生成代码的技术,使得开发人员可以更快速地构建和发布应用程序。 作为近些年软件开发市场热门之一,市面上也涌现了许多低代码产品,诸如简道云…...
[数据结构]二叉树OJ(leetcode)
目录 二叉树OJ(leetcode)训练习题:: 1.单值二叉树 2.检查两棵树是否相同 3.二叉树的前序遍历 4.另一棵树的子树 5.二叉树的构建及遍历 6.二叉树的销毁 7.判断二叉树是否是完全二叉树 二叉树OJ(leetcode)训练习题:: 1.单值二叉…...

flutter 输入时插入分隔符
每四位插入一个分隔符import package:flutter/services.dart;class DividerInputFormatter extends TextInputFormatter {final int rear; //第一个分割位数,后面分割位,,数final String pattern; //分割符DividerInputFormatter({this.rear 4, this.pattern });overrideTex…...

静态版通讯录——“C”
各位CSDN的uu你们好呀,之前小雅兰学过了一些结构体、枚举、联合的知识,现在,小雅兰把这些知识实践一下,那么,就让我们进入通讯录的世界吧 实现一个通讯录: 可以存放100个人的信息每个人的信息:名…...

前端基础开发环境搭建工具等
一、基本开发环境(软件)安装1、Vscode(代码编辑器)官网下载网址:https://code.visualstudio.com/2、nvm(node多版本管理器,每个node版本都有对应的npm版本)安装包下载地址࿱…...

华为OD机试题【IPv4 地址转换成整数】用 Java 解 | 含解题说明
华为Od必看系列 华为OD机试 全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理 已参加机试人员的实战技巧华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典本篇题目:IPv4 地址转换成整数 题目 存在…...
[数据结构]排序算法
目录 常用排序算法的实现:: 1.排序的概念及其运用 2.插入排序 3.希尔排序 4.选择排序 5.冒泡排序 6.堆排序 7.快速排序 8.归并排序 9.排序算法复杂度及稳定性分析 10.排序选择题练习 常用排序算法的实现:: 1.排序的概念及其运用…...

从Polar靶场“中等”难度题,聊聊新手CTFer最容易踩的5个Web安全坑
从Polar靶场“中等”难度题,聊聊新手CTFer最容易踩的5个Web安全坑 当你第一次踏入CTF的Web安全领域,Polar靶场的中等难度题目就像一座看似平缓却暗藏陷阱的山峰。许多新手在这里反复跌倒,不是因为技术门槛过高,而是忽略了那些本该…...

容器资源限制
1、创建一个临时容器c1 docker run -it --namec1 --rm centos:v1监控容器的资源使用情况 docker statsmemload工具可以直接占用消耗资源 将memload工具拷贝到c1容器的opt目录下 docker cp memload-7.0-1.r29766.x86_64.rpm c1:/opt在运行的容器中安装上传的安装包 rpm -ivh /op…...

WarcraftHelper:5分钟解决魔兽争霸III现代兼容性问题的终极指南
WarcraftHelper:5分钟解决魔兽争霸III现代兼容性问题的终极指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典魔兽争霸III在W…...

【飞机】基于matlab数据驱动的多传感器飞机健康监测系统【含Matlab源码 15551期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

如何在跨平台场景下实现高效远程桌面控制?BilldDesk Pro的现代化解决方案
如何在跨平台场景下实现高效远程桌面控制?BilldDesk Pro的现代化解决方案 【免费下载链接】billd-desk 基于Vue3 WebRTC Nodejs Flutter搭建的远程桌面控制、游戏串流 项目地址: https://gitcode.com/gh_mirrors/bi/billd-desk 在远程办公和技术支持日益普…...
亲测好用的AI写作辅助平台,毕业生收藏备用)
(良心整理)亲测好用的AI写作辅助平台,毕业生收藏备用
毕业季论文写作真的这么难吗?选题方向模糊、文献资料繁杂、写作进度缓慢、查重修改头疼、格式规范混乱…… 这份亲测好用的AI论文工具清单,涵盖中英文写作、全流程支持、专项功能、免费与高性价比选项,从开题构思到最终定稿全程护航ÿ…...

【限时解密】:OpenAI DevDay未公布的Agent Runtime协议草案V2.1——它正悄然定义下一代智能体互操作标准
更多请点击: https://kaifayun.com 第一章:AI Agent智能体未来趋势 AI Agent正从单一任务执行者演变为具备自主目标分解、跨工具协同与持续环境反馈的类人智能体。其发展不再局限于模型规模扩张,而转向认知架构升级、可信机制构建与人机协作…...

手把手教你从零搭建 MCP Server:AI 连接万物的保姆级实战教程
为什么要学 MCP? 说实话,最近半年 AI 开发圈最火的协议就是 MCP(Model Context Protocol)了。你可能已经用上了各种 AI 助手,但有没有想过:这些 AI 怎么连接你的数据库?怎么读你的本地文件&…...

Veo生成模糊/断帧/色偏?立刻停用默认设置!20年视频架构师紧急发布的5项必改Veo 2K/4K硬核配置
更多请点击: https://intelliparadigm.com 第一章:Veo 2K/4K视频生成质量崩塌的根源诊断 当Veo模型在2K或4K分辨率下输出视频时,高频细节严重丢失、运动伪影显著增强、纹理结构模糊化,这一现象并非单纯算力不足所致,而…...

五分钟完成Taotoken的Python SDK配置并调用多模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 五分钟完成Taotoken的Python SDK配置并调用多模型 基础教程类,面向刚注册Taotoken的Python开发者,指导其完…...