Java stream性能比较
环境
- Ubuntu 22.04
- IntelliJ IDEA 2022.1.3
- JDK 17
- CPU:8核
➜ ~ cat /proc/cpuinfo | egrep -ie 'physical id|cpu cores'
physical id : 0
cpu cores : 1
physical id : 2
cpu cores : 1
physical id : 4
cpu cores : 1
physical id : 6
cpu cores : 1
physical id : 8
cpu cores : 1
physical id : 10
cpu cores : 1
physical id : 12
cpu cores : 1
physical id : 14
cpu cores : 1
目标
文本通过实际测试,从以下几个维度比较Java stream的性能:
- stream VS. parallelStream
- 分步 VS. 总体,分步指的是每次操作都转换为List,下个操作前再转换为stream,而总体指的是全部操作之后再转换为List。显然,总体的性能会好于分步的性能
- 不同数据量对性能的影响
准备
新建maven项目 test0317 。
打开 pom.xml 文件,添加如下内容:
<!-- https://mvnrepository.com/artifact/junit/junit --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13.2</version><scope>test</scope></dependency>
在 src/test/java/com.example.test0317 目录下创建package package1 ,并创建类 Test0317 :
package com.example.test0317.package1;import org.junit.Test;import java.util.List;
import java.util.stream.Stream;public class Test0317 {private List<Double> list1 = null;private long size = 10000000;private long start = 0;private long end = 0;private long time = 0;
}
测试
测试1(stream,10000000,分步)
@Testpublic void test1() {System.out.println("\n****** test1: stream, " + size + ", step by step ******");for (int i = 0; i < 3; i++) {list1 = Stream.generate(Math::random).limit(size).toList();start = System.currentTimeMillis();list1 = list1.stream().map(e -> e + 1).toList();list1 = list1.stream().map(e -> e * 2).toList();list1 = list1.stream().sorted().toList();end = System.currentTimeMillis();time = end - start;System.out.println("time = " + time);}}
运行结果如下:
****** test1: stream, 10000000, step by step ******
time = 6062
time = 5931
time = 6917
测试2(parallelStream,10000000,分步)
@Testpublic void test2() {System.out.println("\n****** test2: parallelStream, " + size + ", step by step ******");for (int i = 0; i < 3; i++) {list1 = Stream.generate(Math::random).limit(10000000).toList();start = System.currentTimeMillis();list1 = list1.parallelStream().map(e -> e + 1).toList();list1 = list1.parallelStream().map(e -> e * 2).toList();list1 = list1.parallelStream().sorted().toList();end = System.currentTimeMillis();time = end - start;System.out.println("time = " + time);}}
运行结果如下:
****** test2: parallelStream, 10000000, step by step ******
time = 2038
time = 1822
time = 2000
测试3(stream,10000000,总体)
@Testpublic void test3() {System.out.println("\n****** test3: stream, " + size + ", whole ******");for (int i = 0; i < 3; i++) {list1 = Stream.generate(Math::random).limit(10000000).toList();start = System.currentTimeMillis();list1 = list1.stream().map(e -> e + 1).map(e -> e * 2).sorted().toList();end = System.currentTimeMillis();time = end - start;System.out.println("time = " + time);}}
运行结果如下:
****** test3: stream, 10000000, whole ******
time = 6118
time = 5774
time = 6310
测试4(parallelStream,10000000,总体)
@Testpublic void test4() {System.out.println("\n****** test4: parallelStream, " + size + ", whole ******");for (int i = 0; i < 3; i++) {list1 = Stream.generate(Math::random).limit(10000000).toList();start = System.currentTimeMillis();list1 = list1.parallelStream().map(e -> e + 1).map(e -> e * 2).sorted().toList();end = System.currentTimeMillis();time = end - start;System.out.println("time = " + time);}}
运行结果如下:
****** test4: parallelStream, 10000000, whole ******
time = 1771
time = 1873
time = 2011
测试5(stream,20000000,分步)
运行结果如下:
****** test1: stream, 20000000, step by step ******
time = 12870
time = 12642
time = 12425
测试6(parallelStream,20000000,分步)
运行结果如下:
****** test2: parallelStream, 20000000, step by step ******
time = 4216
time = 4247
time = 4420
测试7(stream,20000000,总体)
运行结果如下:
****** test3: stream, 20000000, whole ******
time = 12199
time = 12136
time = 12088
测试8(parallelStream,20000000,总体)
运行结果如下:
****** test4: parallelStream, 20000000, whole ******
time = 3526
time = 3796
time = 4105
上面的测试中,因为CPU是8核,所以parallelStream最多使用8个线程,而下面的测试是指定使用2线程,方法为在JVM的启动选项(VM options)里设置 -Djava.util.concurrent.ForkJoinPool.common.parallelism=2 ,如下图所示:
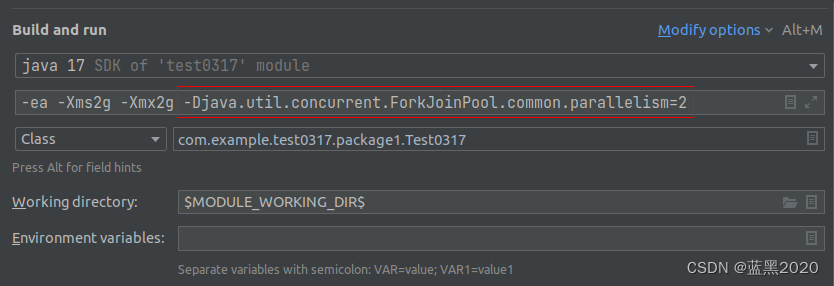
测试9(2线程,parallelStream,10000000,分步)
运行结果如下:
****** test2: parallelStream, 10000000, step by step ******
time = 3446
time = 3246
time = 3523
测试10(2线程,parallelStream,10000000,总体)
运行结果如下:
****** test4: parallelStream, 10000000, whole ******
time = 3173
time = 3136
time = 3259
测试11(2线程,parallelStream,20000000,分步)
运行结果如下:
****** test2: parallelStream, 20000000, step by step ******
time = 7246
time = 7830
time = 7613
测试12(2线程,parallelStream,20000000,总体)
运行结果如下:
****** test4: parallelStream, 20000000, whole ******
time = 7292
time = 7438
time = 7109
总结
测试结果总结如下:
| stream VS. parallelStream | stepwise VS. whole | 元素个数 | 平均时间(秒) | 速度提升 | |
|---|---|---|---|---|---|
| 测试1 | stream | stepwise | 10000000 | 6.3 | baseline |
| 测试2 | parallelStream | stepwise | 10000000 | 2.0 | 3.15 |
| 测试3 | stream | whole | 10000000 | 6.1 | 1.03 |
| 测试4 | parallelStream | whole | 10000000 | 1.9 | 3.32 |
总结:在8核,10000000个元素的情况下,parallelStream相比stream性能提升很大,而总体相比分步只是略有性能提升。
如果把10000000个元素换为20000000个元素,测试结果如下:
| stream VS. parallelStream | stepwise VS. whole | 元素个数 | 平均时间(秒) | 速度提升 | |
|---|---|---|---|---|---|
| 测试5 | stream | stepwise | 20000000 | 12.6 | baseline |
| 测试6 | parallelStream | stepwise | 20000000 | 4.3 | 2.93 |
| 测试7 | stream | whole | 20000000 | 12.1 | 1.04 |
| 测试8 | parallelStream | whole | 20000000 | 3.8 | 3.32 |
可见,如果元素个数加倍,则对于每个测试结果,运行时间也都几乎加倍,符合线性增长。
总结:在8核,20000000个元素的情况下,parallelStream相比stream性能提升很大,而总体相比分步只是略有性能提升。
另外,若换成2线程,其性能显然在单线程和8线程之间。测试结果如下:
| stream VS. parallelStream | stepwise VS. whole | 元素个数 | 平均时间(秒) | 速度提升 | |
|---|---|---|---|---|---|
| 测试9 | parallelStream | stepwise | 10000000 | 3.3 | 1.91 |
| 测试10 | parallelStream | whole | 10000000 | 3.1 | 2.03 |
| 测试11 | parallelStream | stepwise | 20000000 | 7.6 | 1.66 |
| 测试12 | parallelStream | whole | 20000000 | 7.3 | 1.73 |
可见,2线程相比单线程,性能提升接近于2倍,但是达不到2倍,这是因为创建和切换线程需要消耗一定的时间和资源,同理,拆分及合并数据也需要消耗一定的时间和资源。
总结:在2线程,10000000或20000000个元素的情况下,parallelStream相比stream的性能提升接近于2倍,而总体相比分步只是略有性能提升。
最后多说一句:在数据量很大(本例中达到千万级别)时,parallelStream相比stream而言,性能有非常大的提升。但是若数据量不大,比如我测试了10000,则parallelStream相比stream,性能不但没有提升,甚至变得更差了,原因前面已经提到了。
不过话说回来,即使parallelStream比起stream性能变差,但因为数据量小,所以消耗的时间总量就少,比如说假设从10毫秒变成15毫秒,虽然多了50%的时间消耗,但是因为绝对值很小,所以问题不大。
从这个角度看来,还是应该尽量用parallelStream来取代stream。
当然,本例只是一个非常简单的模型,在一些复杂的情况下,比如有线程安全的问题,就要考虑应该用stream还是parallelStream。
相关文章:
Java stream性能比较
环境 Ubuntu 22.04IntelliJ IDEA 2022.1.3JDK 17CPU:8核 ➜ ~ cat /proc/cpuinfo | egrep -ie physical id|cpu cores physical id : 0 cpu cores : 1 physical id : 2 cpu cores : 1 physical id : 4 cpu cores : 1 physical id : 6 cpu cores : 1 physical id …...

【数据结构与算法】设计循环队列
文章目录👑前言如何设计循环队列设计循环队列整体的代码📯写在最后👑前言 🚩前面我们 用队列实现了一个栈 ,用栈实现了一个队列 ,相信大家随随便便轻松拿捏,而本章将带大家上点难度,…...

最新版!国内IT软件外包公司汇总~
金三银四已经过去一半,再过几个月又将迎来毕业季,大家有没有找到心仪的工作机会呀?有很多同学说今年的金三银四似乎不存在了。小李:今年的金三银四变成了铜三铁四,不断地投递又不断地造拒。小王:大量已读不…...

MySQL的COUNT语句,竟然都能被面试官虐的这么惨!?
关于数据库中行数统计,无论是MySQL还是Oracle,都有一个函数可以使用,那就是COUNT 但是,就是这个常用的COUNT函数,却暗藏着很多玄机,尤其是在面试的时候,一不小心就会被虐。不信的话请尝试回答下…...
数位DP 详解及其案例实战 [模板+技巧+案例]
零. 案例引入 1.案例引入 leetcode233. 数字 1 的个数 给定一个整数 n,计算所有小于等于 n 的非负整数中数字 1 出现的个数。 输入:n 13 输出:6 2.暴力解 对于上述的案例,暴力解肯定是可行的,但时间复杂度较高,对…...
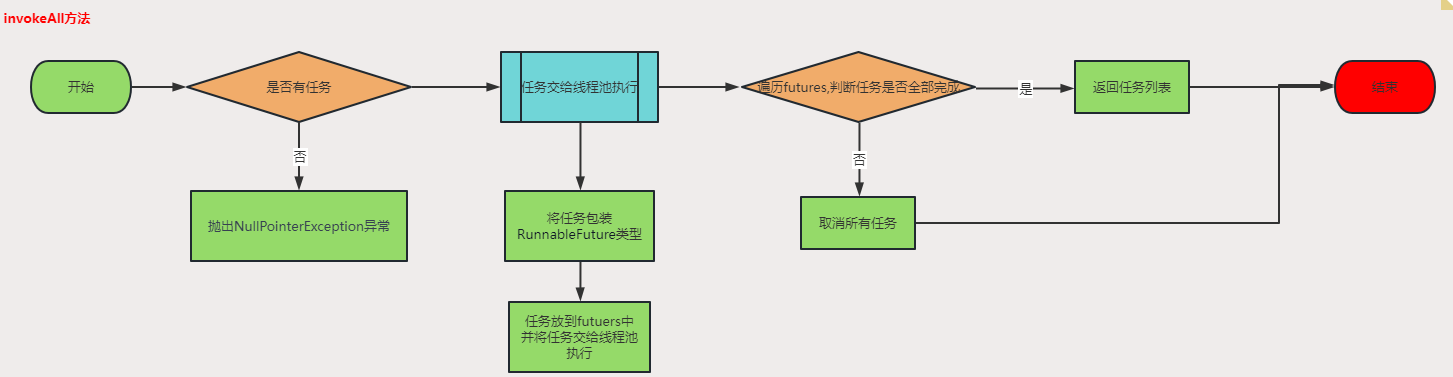
并发编程(六)—AbstractExecutorService源码分析
一、AbstractExecutorService简介AbstractExecutorService是一个抽象类,实现了ExecutorService接口,提供了线程池的基本实现。它是Java Executor框架的核心类,提供了线程池的基本操作,如提交任务、管理线程池、执行任务等。自定义…...

015行为型-职责链模式
目录定义标准模式实现:职责链变体使用链表实现使用数组实现应用场景日志输出spring过滤器spirng 拦截器mybatis动态sql定义 责链模式是一种设计模式,其目的是使多个对象能够处理同一请求,但是并不知道下一个处理请求的对象是谁。它能够解耦请…...
python例程:五子棋(控制台版)程序
目录《五子棋(控制台版)》程序使用说明程序示例代码可执行程序及源码下载路径《五子棋(控制台版)》程序使用说明 在PyCharm中运行《五子棋(控制台版)》即可进入如图1所示的系统主界面。 图1 游戏主界面 具…...

leveldb的Compaction线程
个人随笔 (Owed by: 春夜喜雨 http://blog.csdn.net/chunyexiyu) 1. leveldb的Compaction全局线程 在leveldb中,有一个全局的后台线程BGThread,用于数据库的MinorCompact与MajorCompact。 重点关注“全局线程”: 这个标识着无论一个进程打开…...

邪恶的想法冒出,立马启动python实现美女通通下
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 完整源码、python资料: 点击此处跳转文末名片获取 当我在首页刷到这些的时候~ 我的心里逐渐浮现一个邪念:我把这些小姐姐全都采集,可以嘛? 答案当然是可以的~毕竟就我这技术,…...

蓝桥杯刷题冲刺 | 倒计时18天
作者:指针不指南吗 专栏:蓝桥杯倒计时冲刺 🐾马上就要蓝桥杯了,最后的这几天尤为重要,不可懈怠哦🐾 文章目录0.知识点1.乳草的入侵今天写 搜索题 0.知识点 DFS 设计步骤 确定该题目的状态(包括边…...

经典算法面试题——Java篇-附带赠书活动,评论区随机选取一人赠书
目录 一.图书推荐 二.说一下什么是二分法?使用二分法时需要注意什么?如何用代码实现? 三.什么是插入排序?用代码如何实现? 四.什么是冒泡排序?用代码如何实现? 五.什么是斐波那契数列&#…...

支持RT-Thread最新版本的瑞萨RA2E1开发板终于要大展身手了
支持RT-Thread最新版本的瑞萨RA2E1开发板终于要大展身手了 熟悉RT-Thread和瑞萨MCU的朋友都知道,当前RT-Thread仓库的主线代码是不支持RA2E1这个BSP的。刚好,最近我在联合瑞萨推广一个叫《致敬未来的攻城狮计划》,使用的就是RA2E1开发板&…...

【C语言进阶】 12. 假期测评①
day01 1. 转义字符的判断 以下不正确的定义语句是( ) A: double x[5] {2.0, 4.0, 6.0, 8.0, 10.0}; B: char c2[] {‘\x10’, ‘\xa’, ‘\8’}; C: char c1[] {‘1’,‘2’,‘3’,‘4’,‘5’}; D: int y[53]{0, 1, 3, 5, 7, 9}; 【答案解析】 B 本…...
给程序加个进度条吧,1行Python代码,快速添加~
大家好,这里是程序员晚枫。 你在写代码的过程中,有没有遇到过以下问题? 已经写好的程序,想看看程序执行的进度? 在写代码批量处理文件的时候,如何显示现在处理到第几个文件了? 👆…...

常见的Keil5编译报错及其原因和解决方法
以下是几种常见的Keil5编译报错及其原因和解决方法: "Error: L6218E: Undefined symbol"(未定义符号错误) 这通常是由于缺少对应的库文件或者代码中有未声明的变量或函数引起的。解决方法是检查相应的库文件是否已正确添加到工程中…...
Django 实现瀑布流
需求分析 现在是 "图片为王"的时代,在浏览一些网站时,经常会看到类似于这种满屏都是图片。图片大小不一,却按空间排列,就这是瀑布流布局。 以瀑布流形式布局,从数据库中取出图片每次取出等量(7 …...
传输层协议----UDP/TCP
文章目录前言一、再谈端口号端口号的划分认识知名端口号(Well-Know Port Number)两个问题nestatpidof二、UDP协议UDP协议端格式UDP的特点面向数据报UDP的缓冲区UDP使用注意事项基于UDP的应用层协议二、TCP协议TCP协议段格式可靠性问题确认应答(ACK)机制流量控制六个标志位PSHUG…...

教你如何快速在Linux中找到某个目录中最大的文件
工作中经常会有查看某个目录下最大的文件的需求,比如在运维工作中,发现某个系统或功能不工作了,经排查发现是服务器空间满了…那么接下来就需要清理一下临时文件或者日志文件,或者其他不需要的文件,那么就会想要查看一…...

Java二叉树面试题讲解
Java二叉树面试题讲解🚗1.检查两颗树是否相同🚕2.另一颗树的子树🚙3.二叉树最大深度🚌4.判断一颗二叉树是否是平衡二叉树🚎5.对称二叉树🚓6.获取树中结点个数🚑7.判断一个树是不是完全二叉树&am…...

TI MSPM0G3105-Q1汽车MCU实战解析:从核心特性到硬件设计
1. 项目概述:为什么是MSPM0G3105-Q1?在汽车电子和工业控制领域摸爬滚打十几年,我经手过的MCU型号少说也有几十款。每次启动一个新项目,选型都是头等大事,它直接决定了后续开发的难易度、系统的稳定性和最终产品的成本。…...

MultiHighlight插件深度解析:JetBrains IDE智能代码高亮实战指南
MultiHighlight插件深度解析:JetBrains IDE智能代码高亮实战指南 【免费下载链接】MultiHighlight Jetbrains IDE plugin: highlight identifiers with custom colors 🎨💡 项目地址: https://gitcode.com/gh_mirrors/mu/MultiHighlight …...

G-Helper终极指南:华硕笔记本轻量控制中心的3步快速配置方案
G-Helper终极指南:华硕笔记本轻量控制中心的3步快速配置方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbo…...

ECB02蓝牙主机模式避坑实录:STM32F103C8T6连接失败、绑定不清除的5个常见问题解决
ECB02蓝牙主机模式实战避坑指南:STM32F103C8T6连接异常全解析 当你第一次尝试用STM32F103C8T6通过ECB02蓝牙模块建立主机连接时,大概率会遇到各种"灵异现象":模块毫无反应、AT指令石沉大海、设备死活连不上旧设备、数据乱码像天书……...

使用curl命令直接调试taotoken大模型api接口的详细方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令直接调试Taotoken大模型API接口的详细方法 对于需要在无SDK环境下进行底层调试、自动化脚本编写或快速验证接口的开发…...

精细化管控API调用,Taotoken的访问控制与审计日志功能详解
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 精细化管控API调用,Taotoken的访问控制与审计日志功能详解 当企业或团队将大模型能力集成到自身业务中时,除…...

乐聚智能拟募资26亿冲击创业板,人形机器人商业化初期盈利难题待解
乐聚智能冲击创业板,投后估值43.27亿近日,乐聚智能(深圳)股份有限公司向深交所递交招股书,拟在创业板上市,保荐人为东方证券。乐聚智能是首家选择使用创业板第四套标准申请上市的企业,该标准要求…...

我测了四款龙虾助手,最慢最傻的,都是最贵的
如果你现在用着某款龙虾助手觉得还行,先别急着点头—— 你可能只是还没用过真正好用的。 01 一个残酷的排行榜 过去几周,我认真用了四款 CLAW 系列的 AI 编程助手,俗称"龙虾助手":qcalw、easycalw、workbuddy、autoclaw。 结果?差距比我预想的大得多。 直接…...

抖音批量下载工具:3步搞定无水印视频批量保存
抖音批量下载工具:3步搞定无水印视频批量保存 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音…...

三步解锁B站4K高清视频:免费下载大会员专属内容终极指南
三步解锁B站4K高清视频:免费下载大会员专属内容终极指南 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 你是不是也遇到过…...