【大数据处理与可视化】三 、Pandas库的运用
【大数据处理与可视化】三 、Pandas库的运用
- 实验目的
- 实验内容
- 实验步骤
- 一、使用pandas库分别创建Series对象和DataFrame对象,并对创建的对象使用索引、排序等相关操作;练习DataFrame对象的统计计算和统计描述的功能。
- 1&2、创建一个DataFrame(df),用data做数据,labels做行索引,显示有关此df及其数据的基本信息的摘要
- 3、查看此df的前三行数据
- 4、选择df中列标签为animal和age的数据
- 5、选择行为[‘d’, ‘e’, ‘i’],且列为['animal', 'age']中的数据
- 6、选择visuts大于3的行
- 7、选择age为缺失值的行
- 8、选择animal为cat,且age小于3的行
- 9、将f行的age改为1.5
- 10、计算visits列的数据总和
- 11、计算每种animal的平均age
- 12、追加一行(k),列的数据自定义(如可以等于a行的数据),然后再删除新追加的k行
- 13、计算每种animal的个数(cat有几个,dog几个...)
- 14、先根据age降序排列,再根据visits升序排列
- 15、将priority列的yes和no用True和False替换
- 16、将animal列的snake用python替换
- 二、给定数据使用Pandas的基础知识对北京高考分数线统计分析,分析出:一本文理科与二本文理科最高的分数线是多少,最低的分数线是多少,相差多少分;求2006年-2008年近13年分数线平均分。
- 1、首先读取表格内容
- 2、通过sort_index()=方法让DataFrame对象按照从大到小的顺序排列
- 3、获取历年一本、二本文理科最高和最低的分数线及极差
- 4、比较2018年一本与二本文理科分数线的差值
- 5、计算2006-2018年的平均分数线
- 实验小结
实验目的
- 能够熟练运用pandas库创建Series对象和DataFrame对象;
- 能够熟练运用Series对象和DataFrame对象的索引操作和排序操作;
- 能够熟练运用pandas库,进行统计计算和统计描述;
- 能够熟练运用pandas库进行读写数据操作
实验内容
一、使用pandas库分别创建Series对象和DataFrame对象,并对创建的对象使用索引、排序等相关操作;练习DataFrame对象的统计计算和统计描述的功能。
1、创建一个DataFrame(df),用data做数据,labels做行索引
2、显示有关此df及其数据的基本信息的摘
3、查看此df的前三行数据
4、选择df中列标签为animal和age的数据
5、选择行为[‘d’, ‘e’, ‘i’],且列为[‘animal’, ‘age’]中的数据
6、选择visuts大于3的行
7、选择age为缺失值的行
8、选择animal为cat,且age小于3的行
9、将f行的age改为1.5
10、计算visits列的数据总和
11、计算每种animal的平均age
12、追加一行(k),列的数据自定义(如可以等于a行的数据),然后再删除新追加的k行
13、计算每种animal的个数(cat有几个,dog几个…)
14、先根据age降序排列,再根据visits升序排列
15、将priority列的yes和no用True和False替换
16、将animal列的snake用python替换
二、给定数据使用Pandas的基础知识对北京高考分数线统计分析,分析出:一本文理科与二本文理科最高的分数线是多少,最低的分数线是多少,相差多少分;求2006年-2008年近13年分数线平均分。
实验步骤
一、使用pandas库分别创建Series对象和DataFrame对象,并对创建的对象使用索引、排序等相关操作;练习DataFrame对象的统计计算和统计描述的功能。
1&2、创建一个DataFrame(df),用data做数据,labels做行索引,显示有关此df及其数据的基本信息的摘要
代码:
import pandas as pd
import numpy as np
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
data = {'animal': pd.Series(['cat', 'cat', 'snake', 'dog', 'dog', 'cat', 'snake', 'cat', 'dog', 'dog'],index=labels),'age': pd.Series([2.5, 3, 0.5, np.nan, 5, 2, 4.5, np.nan, 7, 3],index=labels),'visits': pd.Series([1, 3, 2, 3, 2, 3, 1, 1, 2, 1],index=labels),'priority': pd.Series(['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no'],index=labels)}
df = pd.DataFrame(data)
df
截图:

3、查看此df的前三行数据
代码:df[0:3]
截图:
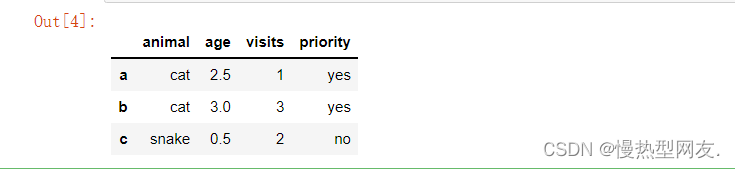
4、选择df中列标签为animal和age的数据
代码:df[['animal','age']]
截图:

5、选择行为[‘d’, ‘e’, ‘i’],且列为[‘animal’, ‘age’]中的数据
代码:df.loc[['d','e','i'],['animal','age']]
截图:

6、选择visuts大于3的行
代码:
visits_bool = df['visits']>3
df[visits_bool]
截图:

7、选择age为缺失值的行
代码:
age_bool = df['age'].isnull()
df[age_bool]
截图:

8、选择animal为cat,且age小于3的行
代码:df[(df['animal']=="cat")&(df["age"]<3)]
截图:

9、将f行的age改为1.5
代码:
df.loc[['f'],['age']] = 1.5
df
截图:

10、计算visits列的数据总和
代码:sum(df['visits'])
截图:

11、计算每种animal的平均age
代码:df.groupby('animal')['age'].mean()
截图:

12、追加一行(k),列的数据自定义(如可以等于a行的数据),然后再删除新追加的k行
代码:
df.loc['k']=df.loc['a'].values
df
df.drop('k')
截图:

13、计算每种animal的个数(cat有几个,dog几个…)
代码:df.groupby('animal').size()
截图:

14、先根据age降序排列,再根据visits升序排列
代码:df.sort_values(by=['age', 'visits'], ascending=[False, True])
截图:

15、将priority列的yes和no用True和False替换
代码:
df['priority'] = df['priority'].replace(to_replace=['yes', 'no'], value=[True, False])
df
截图:

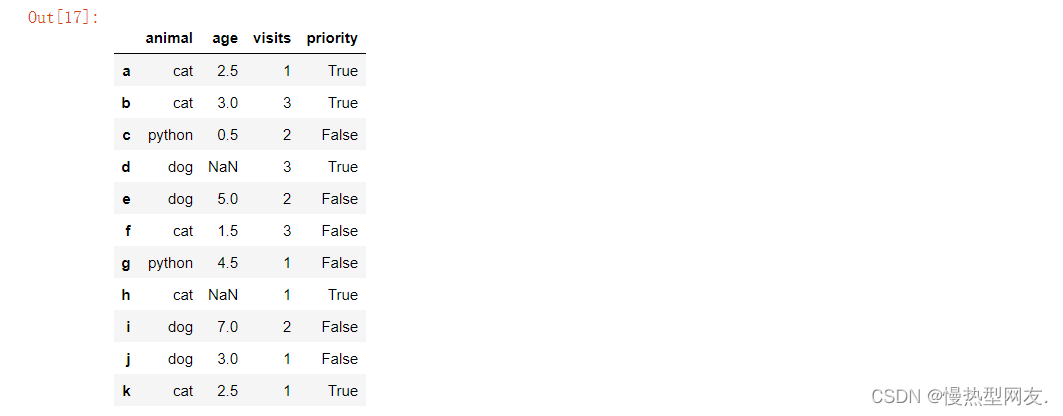
16、将animal列的snake用python替换
代码:
df['animal'] = df['animal'].replace(to_replace='snake', value='python')
df
截图:
二、给定数据使用Pandas的基础知识对北京高考分数线统计分析,分析出:一本文理科与二本文理科最高的分数线是多少,最低的分数线是多少,相差多少分;求2006年-2008年近13年分数线平均分。
1、首先读取表格内容
代码:
import pandas as pd
df_obj=pd.read_excel('D:/scores.xlsx',header=[0,1])
df_obj
截图:

2、通过sort_index()=方法让DataFrame对象按照从大到小的顺序排列
代码:
sorted_obj=df_obj.sort_index(ascending=False)
sorted_obj
截图:

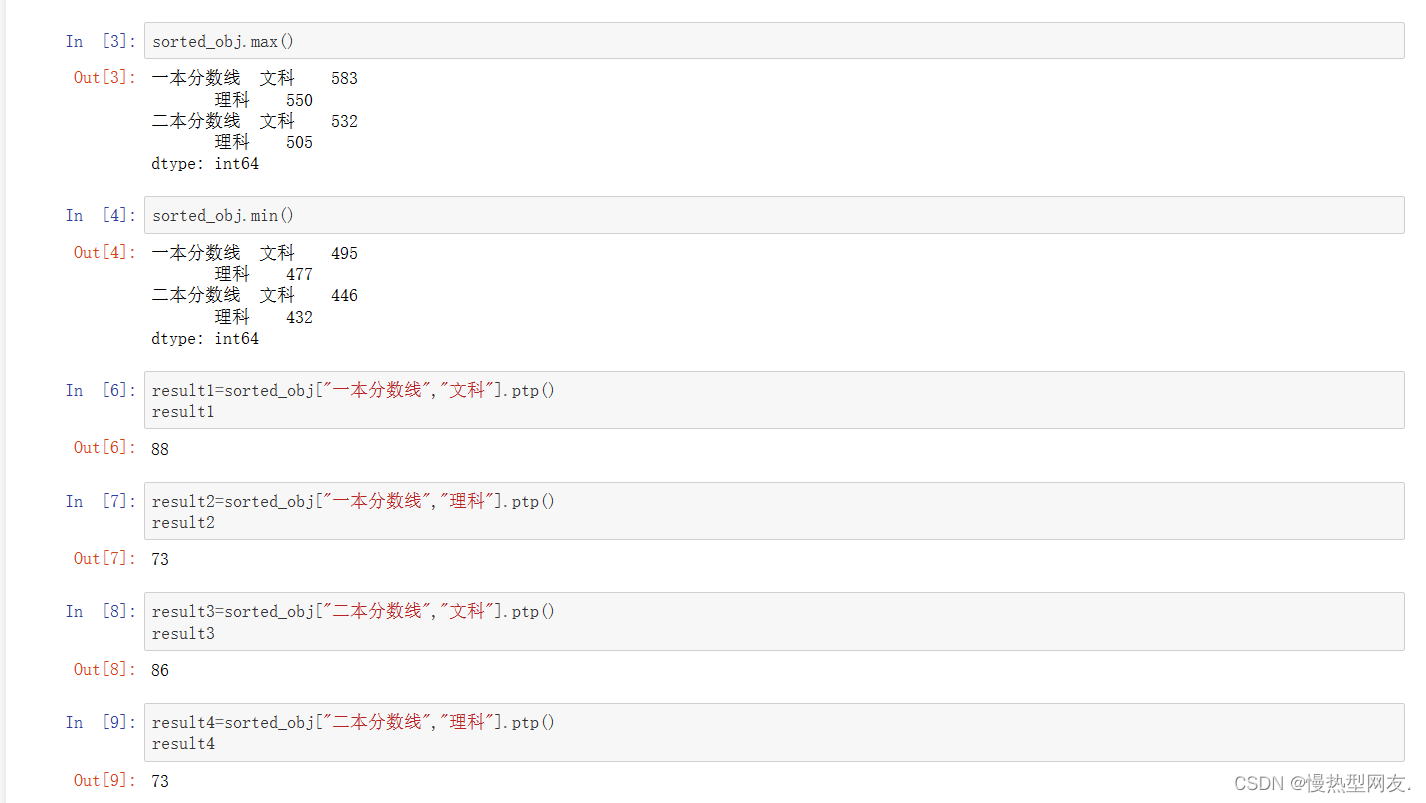
3、获取历年一本、二本文理科最高和最低的分数线及极差
代码:
sorted_obj.max()
sorted_obj.min()
result1=sorted_obj["一本分数线","文科"].ptp()
result1
result2=sorted_obj["一本分数线","理科"].ptp()
result2
result3=sorted_obj["二本分数线","文科"].ptp()
result3
result4=sorted_obj["二本分数线","理科"].ptp()
result4
截图:
4、比较2018年一本与二本文理科分数线的差值
代码:
ser_obj1=sorted_obj["一本分数线","文科"]
ser_obj1[2018] - ser_obj1[2017]ser_obj2=sorted_obj["一本分数线","理科"]
ser_obj2[2018] - ser_obj2[2017]ser_obj3=sorted_obj["二本分数线","文科"]
ser_obj3[2018] - ser_obj3[2017]ser_obj4=sorted_obj["二本分数线","理科"]
ser_obj4[2018] - ser_obj4[2017]
截图:

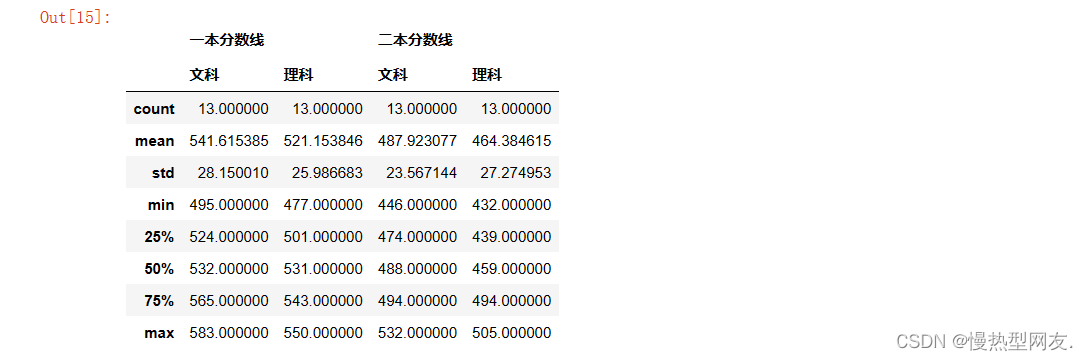
5、计算2006-2018年的平均分数线
代码:sorted_obj.describe()
截图:
实验小结
通过本次实验,我了解了科学计算库Pandas,包括Pandas常用的数据结构、索引的相关操作、算术运算、文件的读取操作等。在实验过程中遇到了很多硬件或者是软件上的问题,请教老师,询问同学,上网查资料,都是解决这些问题的途径。最终将遇到的问题一一解决最终完成实验。
注意事项:
1、有疑问前,知识学习前,先用搜索。
2、熟读写基础知识,学得会不如学得牢。
3、选择交流平台,如QQ群,网站论坛等。
4、尽我能力帮助他人,在帮助他人的同时你会深刻巩固知识。
相关文章:
【大数据处理与可视化】三 、Pandas库的运用
【大数据处理与可视化】三 、Pandas库的运用实验目的实验内容实验步骤一、使用pandas库分别创建Series对象和DataFrame对象,并对创建的对象使用索引、排序等相关操作;练习DataFrame对象的统计计算和统计描述的功能。1&2、创建一个DataFrame(d…...
FPGA解码SDI视频任意尺寸缩放拼接输出 提供工程源码和技术支持
目录1、前言2、SDI理论练习3、设计思路和架构SDI摄像头Gv8601a单端转差GTX解串SDI解码VGA时序恢复YUV转RGB图像缩放FDMA图像缓存实现拼接HDMI驱动4、vivado工程详解5、上板调试验证并演示6、福利:工程代码的获取1、前言 FPGA实现SDI视频编解码目前有两种方案&#…...

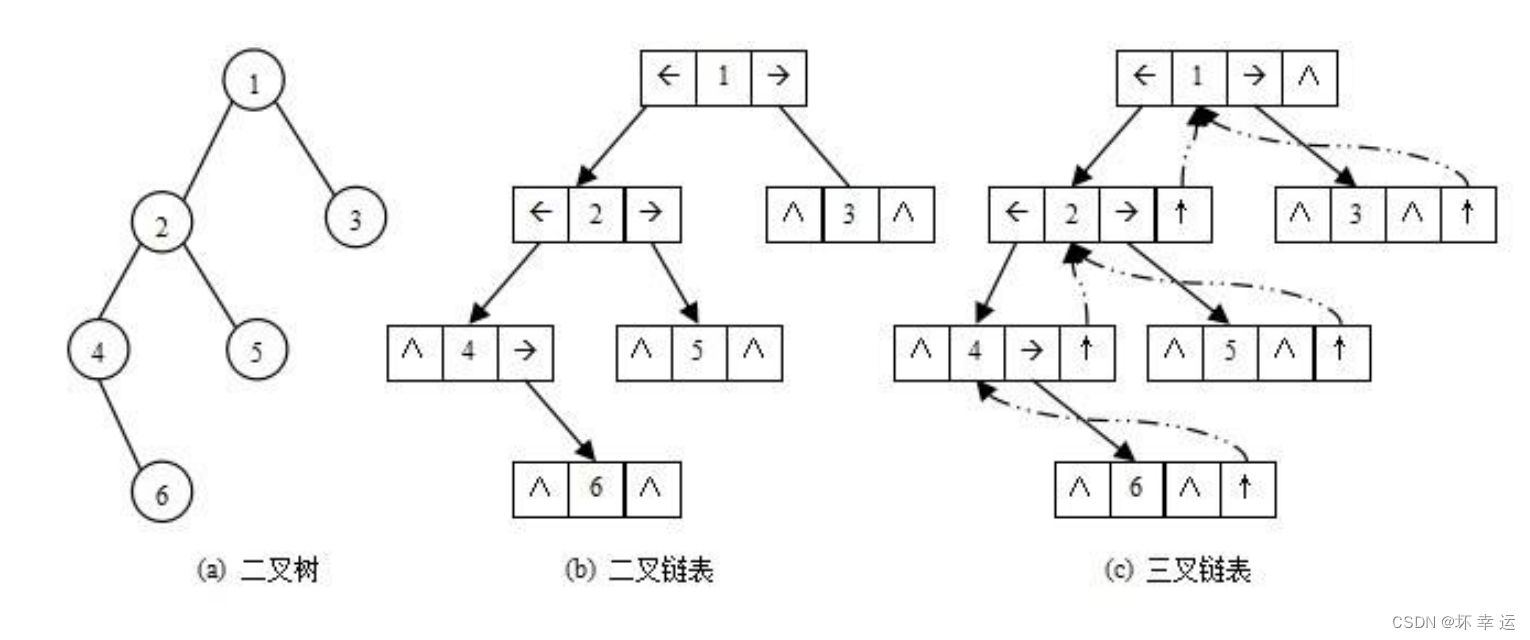
线索二叉树结构
线索二叉树结构1.线索二插树的作用2.线索二叉树的定义3.线索二叉树的结构4. 线索二叉树的操作4.1. 建立一棵中序线索二叉树4.2. 在中序线索二叉树上查找任意结点的中序前驱结点4.3. 在中序线索二叉树上查找任意结点的中序后继结点4.4. 在中序线索二叉树上查找任意结点在先序下的…...

6.网络爬虫——BeautifulSoup详讲与实战
网络爬虫——BeautifulSoup详讲与实战BeautifulSoup简介:BS4下载安装BS4解析对象Tag节点遍历节点find_all()与find()find_all()find()豆瓣电影实战前言: 📝📝此专栏文章是专门针对网络爬虫基础,欢迎免费订阅&#…...

Vue:路由管理模式
三种模式 Vue.js 的路由管理有三种模式: Hash 模式(默认):在 URL 中使用 # 符号来管理路由。例如,http://example.com/#/about。这个模式的好处是可以避免浏览器向服务器发送不必要的请求,并且不需要特殊…...
7个最好的PDF编辑器,帮你像编辑Word一样编辑PDF
PDF 是具有数字思维的组织的重要交流工具。提供高效的工作流程和更好的安全性,可以创建重要文档并与客户、同事和员工共享。文档的布局已锁定,因此无论在什么设备上查看,格式都保持不变。这是让每个人保持一致的好方法——尤其是那些使用Micr…...
【数据结构】树的介绍
文章目录前言树的概念及结构树的概念树的表示树在实际中的运用二叉树的概念及结构二叉树的概念现实中的二叉树特殊的二叉树二叉树的性质二叉树的储存结构顺序存储链式存储写在最后前言 🚩本章给大家介绍一下树。树的难度相对于前面的数据结构来说,又高了…...
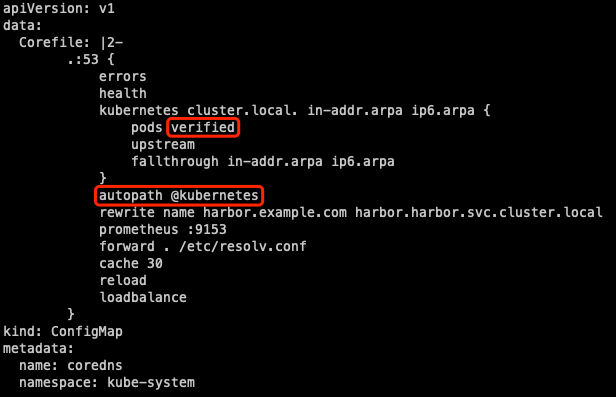
CoreDNS 性能优化
CoreDNS 作为 Kubernetes 集群的域名解析组件,如果性能不够可能会影响业务,本文介绍几种 CoreDNS 的性能优化手段。合理控制 CoreDNS 副本数考虑以下几种方式:根据集群规模预估 coredns 需要的副本数,直接调整 coredns deployment 的副本数:k…...

前端三剑客常见面试题及其答案
目录 1、什么是 HTML? 2、什么是 CSS? 3、什么是 JavaScript? 4、什么是盒模型? 5、什么是浮动? 6、什么是定位? 7、什么是选择器? 8、什么是事件? 前端的三剑客指的是 HTML…...

【DFS专题】深度优先搜索 “暴搜”优质题单推荐 10道题(C++ | 洛谷 | acwing)
文章目录题单一、模板 [极为重要]全排列DFS组合型DFS指数DFS二、专题烤鸡 (指数BFS)P1088 火星人 【全排列】P1149 火彩棒 [预处理 ]P2036 PERKETP1135 奇怪的电梯 暴力P1036 [NOIP2002 普及组] 选数 (组合)P1596 [USACO10OCT]Lake Counting …...

微信小程序自定义组件生命周期有哪些?
微信小程序自定义组件的生命周期函数分为三类: 创建时执行的生命周期函数、更新时执行的生命周期函数和销毁时执行的生命周期函数。 下面是具体的生命周期函数及其触发时机: 创建时执行的生命周期函数: created:在组件实例刚刚…...
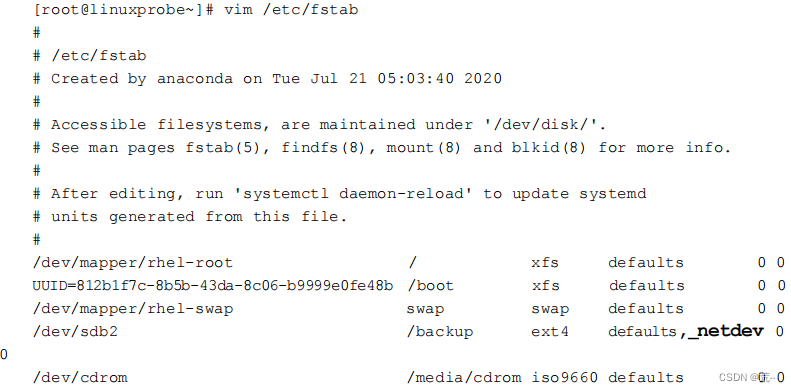
Linux就该这么学(六)
一、从“/”开始 Linux 系统中的文件和目录名称是严格区分大小写的。例如,root、rOOt、rooT 均代表不同的目录,并且文件名称中不得包含斜杠(/)。Linux 系统中的文件存储结构如下图所示。 在 Linux 系统中,最常见的目录…...
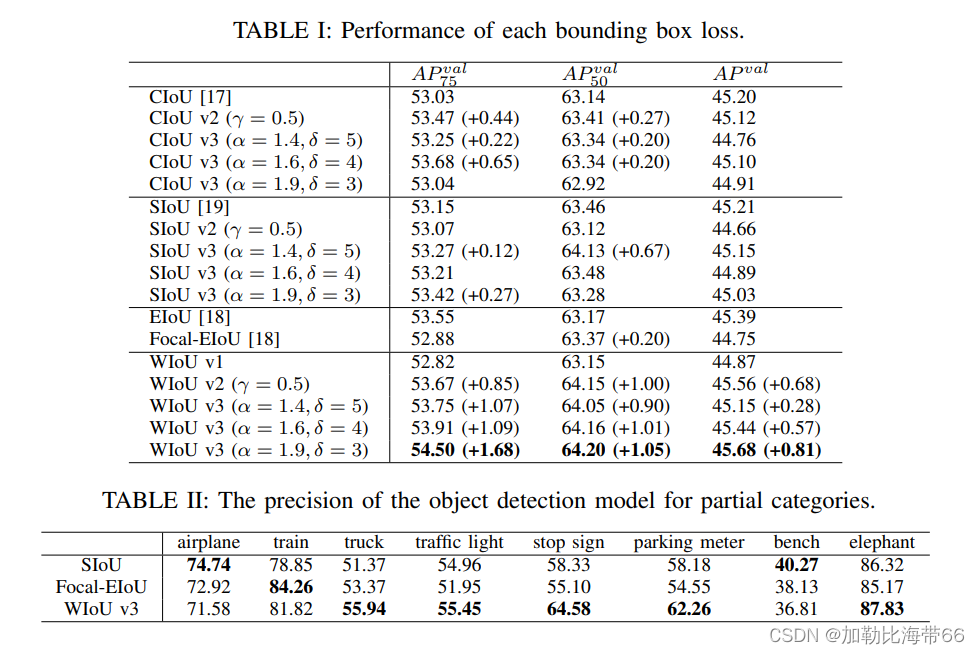
目标检测算法——YOLOv5/v7/v8改进结合涨点Trick之Wise-IoU(超越CIOU/SIOU)
超越CIOU/SIOU | Wise-IoU助力YOLO强势涨点!!! 论文题目:Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism 论文链接:https://arxiv.org/abs/2301.10051 近年来的研究大多假设训练数据中的…...

【蓝桥杯选拔赛真题39】python输出数字组合 青少年组蓝桥杯python 选拔赛STEMA比赛真题解析
目录 python输出数字组合 一、题目要求 1、编程实现 2、输入输出...

网络安全工程师做什么?
网络安全很复杂。数字化转型、远程工作和不断变化的威胁形势需要不同的工具和不同的技能组合。 系统必须到位以保护端点、身份和无边界网络边界。负责处理这种复杂安全基础设施的工作角色是网络安全工程师。 简而言之,网络安全工程师是负责设计和实施组织安全系…...
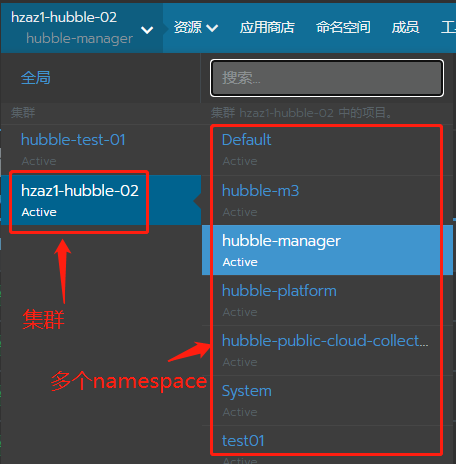
总结:K8S运维常用命令
一、部署./kubectl apply -f biz-healing-pod.yaml 二、查看部署的资源1、podkubectl get pod -A:获取所有pod没有IP?用-o wide参数看详细信息:./kubectl get pod -n deepflow -o wide2、service查看hubble-manager命名空间下有哪些service/d…...
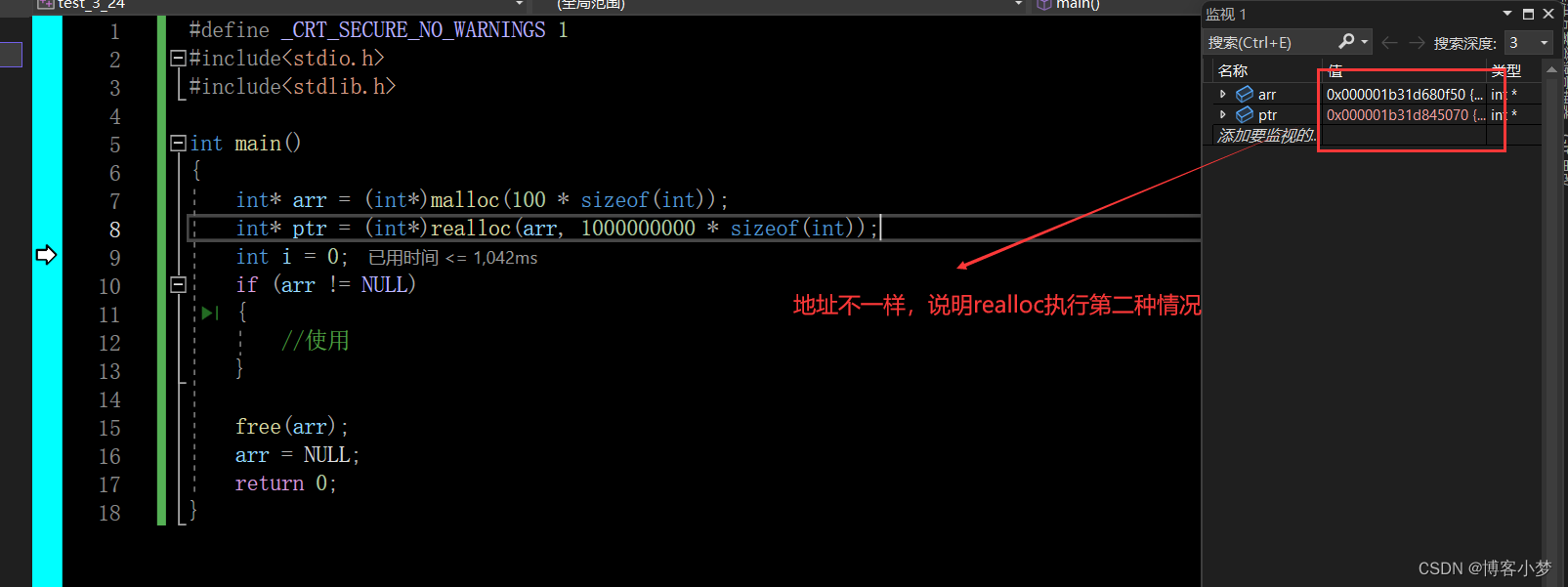
你是真的“C”——进行动态内存分配库函数的使用详解
你是真的“C”——申请动态空间库函数的使用详解😎前言🙌一、为什么需要动态内存分配?💞free 函数😘malloc 库函数😘calloc 库函数😘realloc 库函数😘总结撒花💞…...

Python|蓝桥杯进阶第五卷——数论
欢迎交流学习~~ 专栏: 蓝桥杯Python组刷题日寄 蓝桥杯进阶系列: 🏆 Python | 蓝桥杯进阶第一卷——字符串 🔎 Python | 蓝桥杯进阶第二卷——贪心 💝 Python | 蓝桥杯进阶第三卷——动态规划 ✈️ Python | 蓝桥杯进阶…...

用Python实现单例模式
什么是单例模式单例模式是指在内存中只会创建且仅创建一次对象的设计模式。在程序中多次使用同一个对象且作用相同时,为了防止频繁地创建对象使得内存飙升,单例模式可以让程序仅在内存中创建一个对象,让所有需要调用的地方都共享这一单例对象…...

交叉编译说明:工具链安装和环境变量配置
目录 一 简单了解交叉编译 ① 什么是交叉编译 ② 为什么需要交叉编译 ③ 宿主机和目标机 二 搭建交叉编译工作环境 ① 安装工具链 ② 配置环境变量 ● 配置临时环境变量 ● 配置永久环境变量 三 交叉编译宿主机和目标机 ● 宿主机编译生成的可执行文件下载到目…...
)
CTF选手必看:RSA算法从数学原理到实战解题技巧(附常见题型解析)
CTF选手必看:RSA算法从数学原理到实战解题技巧(附常见题型解析) 1. RSA算法核心数学原理 RSA算法的安全性建立在大整数分解难题和欧拉定理之上。理解以下数学概念是解题基础: 欧拉函数φ(n):对于npq(p、q为…...
Pixel Mind Decoder 参数调优实战:平衡推理速度与识别准确率
Pixel Mind Decoder 参数调优实战:平衡推理速度与识别准确率 1. 为什么需要参数调优 当你第一次使用Pixel Mind Decoder时,可能会发现同样的输入有时会产生不同的输出质量。这就像开车时需要在速度和油耗之间找到平衡点一样,AI模型的参数调…...

qart.js 性能优化:大型图片处理与版本自动适配技巧
qart.js 性能优化:大型图片处理与版本自动适配技巧 【免费下载链接】qart.js Generate artistic QR code. 🎨 项目地址: https://gitcode.com/gh_mirrors/qa/qart.js qart.js 是一款强大的艺术二维码生成工具,能够将普通二维码与图片融…...
)
避开ArcGIS地形标注3大坑:为什么你的等高线总像‘蚯蚓爬‘?(含DEM处理技巧)
避开ArcGIS地形标注3大坑:为什么你的等高线总像蚯蚓爬?(含DEM处理技巧) 在GIS制图领域,地形标注的质量直接影响地图的专业性和可读性。许多中级用户在使用ArcGIS进行等高线标注时,常常遇到标注模糊、曲线锯…...

往期精彩|阿尔茨海默病合集 | 以往高分文献分析,揭示阿尔茨海默病研究热点
阿尔茨海默病(AD)是在老年人群中最为普遍的神经退行性疾病,也是痴呆症的最常见原因,全球大约有2660万人受到影响。1、Neurology:新的血液生物标志物可以在阿尔茨海默病的早期阶段预测其进展2025年,巴塞罗那…...

Java突变测试终极指南:Pitest如何提升你的代码质量
Java突变测试终极指南:Pitest如何提升你的代码质量 【免费下载链接】pitest State of the art mutation testing system for the JVM 项目地址: https://gitcode.com/gh_mirrors/pi/pitest 突变测试是Java开发中革命性的质量保障技术,而Pitest&am…...
)
HSnet实战:5分钟搞定Few-Shot Segmentation代码复现(附完整数据集配置指南)
HSnet实战指南:从零实现Few-Shot Segmentation的高效复现路径 在计算机视觉领域,Few-Shot Segmentation(FSS)正成为解决标注数据稀缺问题的关键技术。对于刚接触这个领域的研究者来说,复现顶会论文的代码往往是验证思路…...

像素幻梦创意工坊:5分钟零基础搭建你的AI像素艺术生成器
像素幻梦创意工坊:5分钟零基础搭建你的AI像素艺术生成器 1. 前言:开启你的像素艺术之旅 还记得小时候玩过的8-bit游戏吗?那些由一个个小方块组成的奇幻世界,如今可以通过AI技术轻松重现。Pixel Dream Workshop(像素幻…...

HDMI接口电路设计避坑指南:TVS怎么选?阻抗如何调?这10条规则帮你一次过EMC
HDMI接口电路设计避坑指南:TVS怎么选?阻抗如何调?这10条规则帮你一次过EMC 当你在设计一款带有HDMI接口的产品时,是否遇到过这样的场景:明明按照常规思路完成了电路设计,却在EMC测试中屡屡碰壁?…...

【RL-CISPO】MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
note CISPO是2025年6月minimax提出,放到今天还是有价值的。CISPO强化学习: 传统 PPO / GRPO 这类方法,在做 token 级 clipping 时, 会把一些“低概率但很关键”的 token(这类token一般是反思、转折、纠错、重新检查等…...