CNN代码实战
CNN的原理
从 DNN 到 CNN
(1)卷积层与汇聚
⚫ 深度神经网络 DNN 中,相邻层的所有神经元之间都有连接,这叫全连接;卷积神经网络 CNN 中,新增了卷积层(Convolution)与汇聚(Pooling)。
⚫ DNN 的全连接层对应 CNN 的卷积层,汇聚是与激活函数类似的附件;单个卷积层的结构是:卷积层-激活函数-(汇聚),其中汇聚可省略。
(2)CNN:专攻多维数据
在深度神经网络 DNN 课程的最后一章,使用 DNN 进行了手写数字的识别。但是,图像至少就有二维,向全连接层输入时,需要多维数据拉平为 1 维数据,这样一来,图像的形状就被忽视了,很多特征是隐藏在空间属性里的,而卷积层可以保持输入数据的维数不变,当输入数据是二维图像时,卷积层会以多维数据的形式接收输入数据,并同样以多维数据的形式输出至下一层

导包
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
制作数据集
# 制作数据集
# 数据集转换参数
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0.1307, 0.3081)
])
# 下载训练集与测试集
train_Data = datasets.MNIST(
root = 'D:/Postgraduate/CNN', # 下载路径
train = True, # 是 train 集
download = True, # 如果该路径没有该数据集,就下载
transform = transform # 数据集转换参数
)
test_Data = datasets.MNIST(
root = 'D:/Postgraduate/CNN', # 下载路径
train = False, # 是 test 集
download = True, # 如果该路径没有该数据集,就下载
transform = transform # 数据集转换参数
)
# 批次加载器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=256)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=256)
训练网络
class CNN(nn.Module):def __init__(self):super(CNN,self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Tanh(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Tanh(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(16, 120, kernel_size=5), nn.Tanh(),nn.Flatten(),nn.Linear(120, 84), nn.Tanh(),nn.Linear(84, 10)
)def forward(self, x):y = self.net(x)return y
# 创建子类的实例,并搬到 GPU 上
model = CNN().to('cuda:0')
# 训练网络
# 损失函数的选择
loss_fn = nn.CrossEntropyLoss() # 自带 softmax 激活函数
# 优化算法的选择
learning_rate = 0.9 # 设置学习率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,
)
# 训练网络
epochs = 5
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):for (x, y) in train_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)loss = loss_fn(Pred, y) # 计算损失函数losses.append(loss.item()) # 记录损失函数的变化optimizer.zero_grad() # 清理上一轮滞留的梯度loss.backward() # 一次反向传播optimizer.step() # 优化内部参数
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()测试网络
# 测试网络
correct = 0
total = 0
with torch.no_grad(): # 该局部关闭梯度计算功能for (x, y) in test_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum( (predicted == y) )total += y.size(0)
print(f'测试集精准度: {100*correct/total} %')使用网络
# 保存网络
torch.save(model, 'CNN.path')
new_model = torch.load('CNN.path')完整代码
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt# 制作数据集
# 数据集转换参数
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0.1307, 0.3081)
])
# 下载训练集与测试集
train_Data = datasets.MNIST(
root = 'D:/Postgraduate/python_project/CNN', # 下载路径
train = True, # 是 train 集
download = True, # 如果该路径没有该数据集,就下载
transform = transform # 数据集转换参数
)
test_Data = datasets.MNIST(
root = 'D:/Postgraduate/python_project/CNN', # 下载路径
train = False, # 是 test 集
download = True, # 如果该路径没有该数据集,就下载
transform = transform # 数据集转换参数
)
# 批次加载器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=256)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=256)class CNN(nn.Module):def __init__(self):super(CNN,self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Tanh(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Tanh(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(16, 120, kernel_size=5), nn.Tanh(),nn.Flatten(),nn.Linear(120, 84), nn.Tanh(),nn.Linear(84, 10)
)def forward(self, x):y = self.net(x)return y
# 创建子类的实例,并搬到 GPU 上
model = CNN().to('cuda:0')
# 训练网络
# 损失函数的选择
loss_fn = nn.CrossEntropyLoss() # 自带 softmax 激活函数
# 优化算法的选择
learning_rate = 0.9 # 设置学习率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,
)
# 训练网络
epochs = 5
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):for (x, y) in train_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)loss = loss_fn(Pred, y) # 计算损失函数losses.append(loss.item()) # 记录损失函数的变化optimizer.zero_grad() # 清理上一轮滞留的梯度loss.backward() # 一次反向传播optimizer.step() # 优化内部参数
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()# 测试网络
correct = 0
total = 0
with torch.no_grad(): # 该局部关闭梯度计算功能for (x, y) in test_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum( (predicted == y) )total += y.size(0)
print(f'测试集精准度: {100*correct/total} %')# 保存网络
torch.save(model, 'CNN.path')
new_model = torch.load('CNN.path')运行截图


相关文章:
CNN代码实战
CNN的原理 从 DNN 到 CNN (1)卷积层与汇聚 ⚫ 深度神经网络 DNN 中,相邻层的所有神经元之间都有连接,这叫全连接;卷积神经网络 CNN 中,新增了卷积层(Convolution)与汇聚(…...

迁移学习代码复现
一、前言 说来可能令人难以置信,迁移学习技术在实践中是非常简单的,我们仅需要保留训练好的神经网络整体或者部分网络,再在使用迁移学习的情况下把保留的模型重新加载到内存中,就完成了迁移的过程。之后,我们就可以像训练普通神经网络那样训练迁移过来的神经网络了。 我们…...
常用命令)
Elasticsearch(ES)常用命令
常用运维命令 一、基本命令1.1、查看集群的健康状态1.2、查看节点信息1.3、查看索引列表1.4、创建索引1.5、删除索引1.6、关闭索引1.7、打开索引1.8、查看集群资源使用情况(各个节点的状态,包括磁盘,heap,ram的使用情况࿰…...

C/C++ 不定参函数
C语言不定参函数 函数用法总结 Va_list 作用:类型定义,生命一个变量,该变量被用来访问传递给不定参函数的可变参数列表用法:供后续函数进调用,通过该变量访问参数列表 typedefchar* va_list; va_start 作用ÿ…...

C语言——函数专题
1.概念 在C语言中引入函数的概念,有些翻译为子程序。C语言中的函数就是一个完成某项特定任务的一小段代码,这个代码是有特殊的写法和调用方法的。一般我们可以分为两种函数:库函数和自定义函数。 2.库函数 C语言国际标准ANSIC规定了一些常…...

springboot打可执行jar包
1. pom文件如下 <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><m…...

【SQL】科目种类
目录 题目 分析 代码 题目 表: Teacher ------------------- | Column Name | Type | ------------------- | teacher_id | int | | subject_id | int | | dept_id | int | ------------------- 在 SQL 中,(subject_id, dept_id) 是该表的主键。 该表…...

【深度学习】【语音】TTS,最新TTS模型概览,扩散模型TTS,MeloTTS、StyleTTS2、Matcha-TTS
文章目录 基础介绍对比基础介绍 MeloTTS: MeloTTS 是 MyShell.ai 开发的一个多语言语音合成模型,支持包括英语、西班牙语、法语、中文、日语和韩语等多种语言。它以高质量的语音合成为特色,尤其擅长处理中英混合内容。该模型优化了在 CPU 上的实时推理能力,使其在多种应用场…...

【论文笔记】LION: Linear Group RNN for 3D Object Detection in Point Clouds
原文链接:https://arxiv.org/abs/2407.18232 简介:Transformer在3D点云感知任务中有二次复杂度,难以进行长距离关系建模。线性RNN则计算复杂度较低,适合进行长距离关系建模。本文提出基于窗口的网络线性组RNN(即对分组…...

打造高可用集群的基石:深度解析Keepalived实践与优化
高可用集群 集群类型 集群类型主要分为负载均衡集群(LB)、高可用集群(HA)和高性能计算集群(HPC)三大类。每种集群类型都有其特定的应用场景和优势。 1. 负载均衡集群(LB) 负载均衡集…...

Web大学生网页作业成品——环保主题介绍网页网站设计与实现(HTML+CSS)(5个页面)
🎉🎉🎉 常见网页设计作业题材有**汽车、环保、明星、文化、国家、抗疫、景点、人物、体育、植物、公益、图书、节日、游戏、商城、旅游、家乡、学校、电影、动漫、非遗、动物、个人、企业、美食、婚纱、其他**等网页设计题目, 可满足大学生网…...

Qt登录窗口设计
widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QIcon> //图标类 #include <QPushButton> #include <QLineEdit> //行编辑 #include <QLabel> #include <QTextEdit> #include <QMovie>class Widge…...

探索数据矿藏:我的AI大模型与数据挖掘实战经验分享
🚀 探索数据矿藏:我的AI大模型与数据挖掘实战经验分享 💖 前言:数据的金矿,AI的翅膀 在人工智能的浪潮中,我有幸作为项目负责人,带领团队深入挖掘数据的潜力,利用AI大模型的力量&am…...

linux C语言strcat函数及相关函数
讯飞星火 strcat函数是C语言中的一个字符串处理函数,用于将一个字符串追加到另一个字符串的末尾。它的原型如下: char *strcat(char *dest, const char *src);参数说明: dest:目标字符串,即要将src字符串追加到这个字符串的末尾。src:源字符串,即要追加到dest字符串末…...

使用 sort 进行文本文件处理
sort 使用经验笔记 一、简介 sort 是一个命令行工具,用于对文本文件中的行进行排序。它广泛应用于 Unix/Linux 系统中,可以用来对文件的内容进行简单的排序操作,也可以与其他命令结合使用来完成更复杂的任务。 二、基本用法 排序文件: sor…...

HarmonyOS笔记4:从云数据库获取数据
移动应用获取数据的方式主要有: 1.从网络中获取数据接口API。 2.从华为云数据库获取云数据库的资源。 3.从移动终端直接获取本地的数据 在HarmonyOS笔记3中已经完成了方式一从网络中获取数据接口API的方式。在本篇笔记中,将讨论从云数据库中获取数据。 因…...
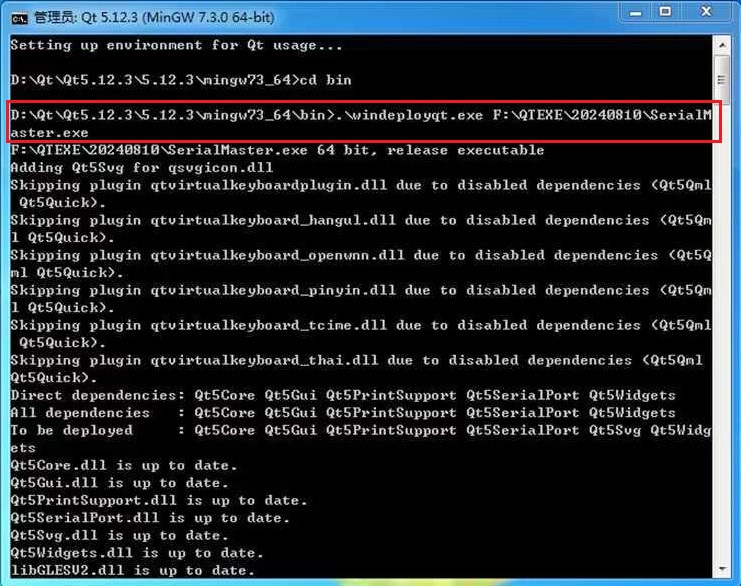
QT5生成独立运行的exe文件
目录 1 生成独立运行的exe文件1.1 设置工程Release版本可执行文件存储路径1.2 将工程编译成Release版本 2 使用QT5自带的windeployqt拷贝软件运行依赖项3 将程序打包成一个独立的可执行软件exe4 解决QT5 This application failed to start because no Qt platform plugin could…...
LabVIEW光纤水听器闭环系统
开发了一种利用LabVIEW软件开发的干涉型光纤水听器闭环工作点控制系统。该系统通过调节光源频率和非平衡干涉仪的光程差,实现了工作点的精确控制,从而提高系统的稳定性和检测精度,避免了使用压电陶瓷,使操作更加简便。 项目背景 …...
)
Shell——流程控制语句(if、case、for、while等)
在 Shell 编程中,流程控制语句用于控制脚本的执行顺序和逻辑。这些语句包括 if、case、for、while 等,它们的使用可以使脚本实现更复杂的逻辑。以下是它们的详细说明和语法结构: 1. if 语句 if 语句用于条件判断,执行符合条件的…...

【redis的大key问题】
在使用 Redis 的过程中,如果未能及时发现并处理 Big keys(下文称为“大Key”),可能会导致服务性能下降、用户体验变差,甚至引发大面积故障。 本文将介绍大Key产生的原因、其可能引发的问题及如何快速找出大Key并将其优…...

基于Slack与AI的IDE智能助手:架构设计与实战部署
1. 项目概述:当你的IDE拥有了“光标智能体” 如果你是一名开发者,每天在IDE(集成开发环境)里敲代码的时间超过8小时,那你一定对这样的场景不陌生:光标在代码行间跳跃,你正试图理解一个复杂的函…...

开源AI本地化框架py-gpt:微内核插件化架构与RAG应用实战
1. 项目概述:一个本地化、可扩展的AI应用框架最近在折腾AI应用本地化部署的朋友,可能都绕不开一个核心矛盾:既想享受大语言模型(LLM)强大的对话和推理能力,又对数据隐私、网络依赖和持续付费心存顾虑。市面…...

【实战排错】Vivado 综合卡死与“PID not specified”的深度诊断与修复
1. 故障现象与初步排查 最近在跑Vivado综合时,突然遇到一个让人头疼的问题:综合进程莫名其妙卡死,日志里还跳出"PID not specified"的错误提示。这种情况相信不少FPGA工程师都遇到过,特别是项目紧急的时候,这…...

文献综述效率提升300%?NotebookLM在区域地理分析中的7个颠覆性用法,含真实课题复现代码
更多请点击: https://intelliparadigm.com 第一章:NotebookLM地理学研究辅助 NotebookLM 是 Google 推出的基于用户上传文档进行深度语义理解与问答的 AI 工具,其在地理学研究中展现出独特价值——尤其适用于处理多源异构的地理文献、野外调…...

ARM Cortex-M处理器仿真与Iris组件深度解析
1. ARM Cortex-M系列处理器仿真技术概述在嵌入式系统开发领域,处理器仿真技术已经成为不可或缺的工具链环节。作为ARM架构中专门面向微控制器市场的产品线,Cortex-M系列处理器凭借其优异的能效比和实时性能,广泛应用于物联网终端、工业控制和…...

Task发展历程:从简单任务运行器到现代自动化工具的完整演进史
Task发展历程:从简单任务运行器到现代自动化工具的完整演进史 【免费下载链接】task A fast, cross-platform build tool inspired by Make, designed for modern workflows. 项目地址: https://gitcode.com/gh_mirrors/ta/task Task是一个快速、跨平台的构建…...

MySQL的知识阶段小总结
1.MySQL的库操作1.1 MySQL 显示已建库操作语法格式:show databases;注意事项:是databases而不是database,要加s。使用该SQL语句,可以查找当前服务器所有的数据库。huan如上图所示,画红框的Java13和test113是用户自己创…...

网络通信调试难题的Qt解决方案:mNetAssist深度解析
网络通信调试难题的Qt解决方案:mNetAssist深度解析 【免费下载链接】mNetAssist mNetAssist - A UDP/TCP Assistant 项目地址: https://gitcode.com/gh_mirrors/mn/mNetAssist 网络协议调试过程中,开发者常面临协议兼容性、数据传输验证和连接状态…...

卡梅德生物技术快报|噬菌体肽库展示技术:细胞穿透肽筛选全流程技术实现
1. 问题背景(技术痛点) 细胞递送领域面临三大技术瓶颈: 穿透肽靶向性差,非特异性结合严重;传统筛选流程复杂,周期长、通量低;缺乏标准化验证体系,实验难以复现。噬菌体肽库展示技术…...

嘎嘎降AI和笔灵AI哪个更适合毕业论文:2026年达标率改写质量售后完整测评对比报告
嘎嘎降AI和笔灵AI哪个更适合毕业论文:2026年达标率改写质量售后完整测评对比报告 帮几个不同专业的同学处理过论文AI率,用过的工具加起来也有六七款了。 综合看,嘎嘎降AI(www.aigcleaner.com)是最稳的选择࿰…...