开源通用验证码识别OCR —— DdddOcr 源码赏析(一)
文章目录
- @[toc]
- 前言
- DdddOcr
- 环境准备
- 安装DdddOcr
- 使用示例
- 源码分析
- 实例化DdddOcr
- 实例化过程
- 分类识别
- 分类识别过程
- 未完待续
文章目录
- @[toc]
- 前言
- DdddOcr
- 环境准备
- 安装DdddOcr
- 使用示例
- 源码分析
- 实例化DdddOcr
- 实例化过程
- 分类识别
- 分类识别过程
- 未完待续
前言
DdddOcr 源码赏析

DdddOcr
DdddOcr是开源的通用验证码识别OCR
官方传送门
环境准备
安装DdddOcr
pip install ddddocr
使用示例
示例图片如下

import ddddocrocr = ddddocr.DdddOcr(show_ad=False)image = open("example.png", "rb").read()
result = ocr.classification(image)
print(result)
# 识别结果 aFtf
源码分析
我们以实例代码为例,分析源码里面都做了什么
实例化DdddOcr
ocr = ddddocr.DdddOcr(show_ad=False)
对应源码如下
class DdddOcr(object):def __init__(self, ocr: bool = True, det: bool = False, old: bool = False, beta: bool = False,use_gpu: bool = False,device_id: int = 0, show_ad=True, import_onnx_path: str = "", charsets_path: str = ""):if show_ad:print("欢迎使用ddddocr,本项目专注带动行业内卷,个人博客:wenanzhe.com")print("训练数据支持来源于:http://146.56.204.113:19199/preview")print("爬虫框架feapder可快速一键接入,快速开启爬虫之旅:https://github.com/Boris-code/feapder")print("谷歌reCaptcha验证码 / hCaptcha验证码 / funCaptcha验证码商业级识别接口:https://yescaptcha.com/i/NSwk7i")if not hasattr(Image, 'ANTIALIAS'):setattr(Image, 'ANTIALIAS', Image.LANCZOS)self.use_import_onnx = Falseself.__word = Falseself.__resize = []self.__charset_range = []self.__channel = 1if import_onnx_path != "":det = Falseocr = Falseself.__graph_path = import_onnx_pathwith open(charsets_path, 'r', encoding="utf-8") as f:info = json.loads(f.read())self.__charset = info['charset']self.__word = info['word']self.__resize = info['image']self.__channel = info['channel']self.use_import_onnx = Trueif det:ocr = Falseself.__graph_path = os.path.join(os.path.dirname(__file__), 'common_det.onnx')self.__charset = []
实例化过程
1 show_ad
先来一波广告推广,开源不易,尤其是DdddOcr这么良心的开源Ocr,大家多多支持DdddOcr
2 ANTIALIAS 判断
if not hasattr(Image, 'ANTIALIAS'):setattr(Image, 'ANTIALIAS', Image.LANCZOS)
Image.LANCZOS,这是一种图像重采样过滤器,通常用于图像缩放时减少锯齿状边缘和模糊。
这段代码的作用主要是向后兼容或者为旧代码提供一种便捷的访问方式,使得即使PIL或Pillow库的官方API中没有直接提供ANTIALIAS这个属性,开发者也可以通过这种方式来使用LANCZOS过滤器进行图像缩放等操作。
3 然后初始化一些变量
self.use_import_onnx = Falseself.__word = Falseself.__resize = []self.__charset_range = []self.__channel = 1
4 判断是否使用自己的Ocr模型
if import_onnx_path != "":det = Falseocr = Falseself.__graph_path = import_onnx_pathwith open(charsets_path, 'r', encoding="utf-8") as f:info = json.loads(f.read())self.__charset = info['charset']self.__word = info['word']self.__resize = info['image']self.__channel = info['channel']self.use_import_onnx = True
如果使用自己的Ocr模型,通过import_onnx_path指定模型路径,同时charsets_path指定字符集信息
5 是否启用目标检测
if det:ocr = Falseself.__graph_path = os.path.join(os.path.dirname(__file__), 'common_det.onnx')self.__charset = []1.6 是否启用ocr
beta为True表示启用新的ocr模型, 为False启用老的ocr模型
if ocr:if not beta:self.__graph_path = os.path.join(os.path.dirname(__file__), 'common_old.onnx')self.__charset = [....]else:self.__graph_path = os.path.join(os.path.dirname(__file__), 'common.onnx')self.__charset = [...]
6 是否启用GPU
if use_gpu:self.__providers = [('CUDAExecutionProvider', {'device_id': device_id,'arena_extend_strategy': 'kNextPowerOfTwo','cuda_mem_limit': 2 * 1024 * 1024 * 1024,'cudnn_conv_algo_search': 'EXHAUSTIVE','do_copy_in_default_stream': True,}),]else:self.__providers = ['CPUExecutionProvider',]
这里根据use_gpu来决定是使用GPU还是CPU作为计算提供者(ExecutionProvider)
如果use_gpu为True,即决定使用GPU进行计算,那么会创建一个名为CUDAExecutionProvider的提供者配置列表,并设置了一系列与CUDA(GPU计算平台)相关的参数。这些参数包括:
- device_id:指定使用的GPU设备的ID,这允许在多GPU环境中选择特定的GPU进行计算。
- arena_extend_strategy:内存分配策略,这里设置为’kNextPowerOfTwo’,意味着内存分配时会向上取到最近的2的幂次方大小,这有助于减少内存碎片。
- cuda_mem_limit:限制CUDA设备(GPU)的内存使用量,这里设置为2GB(2 * 1024 * 1024 * 1024字节)。
- cudnn_conv_algo_search:指定卷积算法搜索策略,'EXHAUSTIVE’表示使用穷举搜索策略来找到最佳的卷积算法,这可能会增加预处理时间但可能提高执行效率。
- do_copy_in_default_stream:指定是否在默认流中执行数据复制操作,这里设置为True。
如果use_gpu为False,即决定使用CPU进行计算,那么会简单地设置计算提供者列表为仅包含一个’CPUExecutionProvider’的列表。
7 加载onnx模型
self.__ort_session = onnxruntime.InferenceSession(self.__graph_path, providers=self.__providers)❓疑问❓
从代码来看只能加载一种模型,ocr模型(新/旧)、det模型、自己的onnx模型,三种模型三选一,这里self.__graph_path指定模型路径时,却使用了3个if, 而不是if-elif-else结构,个人感觉不太合理, 只能说瑕不掩瑜
源码结构如下
if import_onnx_path != "":self.__graph_path = import_onnx_path
if det:self.__graph_path = os.path.join(os.path.dirname(__file__), 'common_det.onnx')
if ocr:if not beta:self.__graph_path = os.path.join(os.path.dirname(__file__), 'common_old.onnx')else:self.__graph_path = os.path.join(os.path.dirname(__file__), 'common.onnx')
分类识别
image = open("example.jpg", "rb").read()
result = ocr.classification(image)
print(result)
对应源码如下
def classification(self, img, png_fix: bool = False, probability=False):if self.det:raise TypeError("当前识别类型为目标检测")if not isinstance(img, (bytes, str, pathlib.PurePath, Image.Image)):raise TypeError("未知图片类型")if isinstance(img, bytes):image = Image.open(io.BytesIO(img))elif isinstance(img, Image.Image):image = img.copy()elif isinstance(img, str):image = base64_to_image(img)else:assert isinstance(img, pathlib.PurePath)image = Image.open(img)if not self.use_import_onnx:image = image.resize((int(image.size[0] * (64 / image.size[1])), 64), Image.ANTIALIAS).convert('L')else:if self.__resize[0] == -1:if self.__word:image = image.resize((self.__resize[1], self.__resize[1]), Image.ANTIALIAS)else:image = image.resize((int(image.size[0] * (self.__resize[1] / image.size[1])), self.__resize[1]),Image.ANTIALIAS)else:image = image.resize((self.__resize[0], self.__resize[1]), Image.ANTIALIAS)if self.__channel == 1:image = image.convert('L')else:if png_fix:image = png_rgba_black_preprocess(image)else:image = image.convert('RGB')image = np.array(image).astype(np.float32)image = np.expand_dims(image, axis=0) / 255.if not self.use_import_onnx:image = (image - 0.5) / 0.5else:if self.__channel == 1:image = (image - 0.456) / 0.224else:image = (image - np.array([0.485, 0.456, 0.406])) / np.array([0.229, 0.224, 0.225])image = image[0]image = image.transpose((2, 0, 1))ort_inputs = {'input1': np.array([image]).astype(np.float32)}ort_outs = self.__ort_session.run(None, ort_inputs)result = []last_item = 0if self.__word:for item in ort_outs[1]:result.append(self.__charset[item])else:if not self.use_import_onnx:# 概率输出仅限于使用官方模型if probability:ort_outs = ort_outs[0]ort_outs = np.exp(ort_outs) / np.sum(np.exp(ort_outs))ort_outs_sum = np.sum(ort_outs, axis=2)ort_outs_probability = np.empty_like(ort_outs)for i in range(ort_outs.shape[0]):ort_outs_probability[i] = ort_outs[i] / ort_outs_sum[i]ort_outs_probability = np.squeeze(ort_outs_probability).tolist()result = {}if len(self.__charset_range) == 0:# 返回全部result['charsets'] = self.__charsetresult['probability'] = ort_outs_probabilityelse:result['charsets'] = self.__charset_rangeprobability_result_index = []for item in self.__charset_range:if item in self.__charset:probability_result_index.append(self.__charset.index(item))else:# 未知字符probability_result_index.append(-1)probability_result = []for item in ort_outs_probability:probability_result.append([item[i] if i != -1 else -1 for i in probability_result_index ])result['probability'] = probability_resultreturn resultelse:last_item = 0argmax_result = np.squeeze(np.argmax(ort_outs[0], axis=2))for item in argmax_result:if item == last_item:continueelse:last_item = itemif item != 0:result.append(self.__charset[item])return ''.join(result)else:last_item = 0for item in ort_outs[0][0]:if item == last_item:continueelse:last_item = itemif item != 0:result.append(self.__charset[item])return ''.join(result)
分类识别过程
1 目标检测任务不支持分类
if self.det:raise TypeError("当前识别类型为目标检测")- 图片格式转换
if not isinstance(img, (bytes, str, pathlib.PurePath, Image.Image)):raise TypeError("未知图片类型")if isinstance(img, bytes):image = Image.open(io.BytesIO(img))elif isinstance(img, Image.Image):image = img.copy()elif isinstance(img, str):image = base64_to_image(img)else:assert isinstance(img, pathlib.PurePath)image = Image.open(img)
未完待续
明天见
相关文章:
开源通用验证码识别OCR —— DdddOcr 源码赏析(一)
文章目录 [toc] 前言DdddOcr环境准备安装DdddOcr使用示例 源码分析实例化DdddOcr实例化过程 分类识别分类识别过程 未完待续 前言 DdddOcr 源码赏析 DdddOcr DdddOcr是开源的通用验证码识别OCR 官方传送门 环境准备 安装DdddOcr pip install ddddocr使用示例 示例图片如…...
)
上升ECMAScript性能优化技巧与陷阱(下)
4. 深拷贝和浅拷贝的选择不当 在JavaScript中,对象是通过引用传递的,这意味着当你将一个对象赋值给另一个变量时,你实际上是在传递对象的引用,而不是对象本身。这导致了一个常见的问题:当你修改一个对象的属性时&…...

用7EPhone云手机进行TikTok的矩阵运营
“根据市局机构Statista发布的报告显示,截至2024年4月,TikTok全球下载量超过49.2亿次,月度活跃用户数超过15.82亿。TikTok的流量受欢迎程度可想而知,也一跃成为了全球第五大最受欢迎的社交APP。” 人群密集的地方社区也是适合推广…...

谷歌浏览器下载文件被阻止怎么解除
在工作生活中,我们会使用谷歌浏览器下载各种各样的文件,不过偶尔会遇到文件下载被阻止的情况。为了解决这一问题,本文为大家分享了实用的措施建议,一起来了解一下吧。(本文由https://chrome.cmrrs.com/站点的作者进行编…...

apt E: 无法定位软件包 winehq-stable
执行了 添加wine源 wget -NP /etc/apt/sources.list.d/ https://dl.winehq.org/wine-builds/ubuntu/dists/jammy/winehq-jammy.sources还需要执行 更新源 apt update...

P2460[SDOI2007] 科比的比赛
第一次做洛谷系列,紧张,请多关照哦 题目传送门:[SDOI2007] 科比的比赛 - 洛谷 思路分析 这道题大概题意是给定我们的主人公 Kobe Bryant 的 mm 个对手,nn 场比赛相对应的获胜概率。求 Kobe Bryant 最大全部获胜概率和打败对手能…...

linux学习--第二天
--Linux文件系统 -显示文件命令 cat 1. cat -b 文件:从1开始对非空输出行编号 2. cat -n 文件:从1开始对所有行编号 3. cat -s 文件:将连续多行空白行合并 more(显示一屏文本内容) 1. more -num 文件ÿ…...

使用 Flask、Celery 和 Python 实现每月定时任务
为了创建一个使用 Flask、Celery 和 Python 实现的每月定时任务,我们需要按照以下步骤进行: 1.安装必要的库 我们需要安装 Flask、Celery 和 Redis(作为消息代理)。我们可以使用 pip 来安装它们: bash复制代码 p…...

【c语言】整数在内存中的储存(大小端字节序)
整数在内存中的储存(大小端字节序) 1.整数在内存中的储存 2.大小端字节序 3.整数在内存中储存例子 4.字节序判断 5.死循环现象 文章目录 整数在内存中的储存(大小端字节序)整数在内存中的储存大小端字节序什么是大小端为什么会有…...

浅谈SIMD、向量化处理及其在StarRocks中的应用
前言 单指令流多数据流(SIMD)及其衍生出来的向量化处理技术已经有了相当的历史,并且也是高性能数据库、计算引擎、多媒体库等组件的标配利器。笔者在两年多前曾经做过一次有关该主题的内部Geek分享,但可能是由于这个topic离实际研发场景比较远࿰…...

【ML】Image Augmentation)的作用、使用方法及其分类
图像增强(Image Augmentation)的作用、使用方法及其分类 1. 图像增强的定义2. 图像增强的作用3. 什么时候使用图像增强?4. 图像增强详细方法分类梳理4.1 图像增强方法列表4.2 边界框增强方法5. 参考资料 yolov3(一:模型…...
--单一职责原则)
设计模式六大原则(一)--单一职责原则
1. 简介 1.1. 概述 一个类或模块应该只负责完成一项任务或承担一个责任。如果一个类或模块承担了多个职责,那么当需要修改其中一个职责的功能时,就可能会对其他职责产生影响,从而导致代码耦合度增加,维护起来更加困难。 1.2. 主要特点 单一职责原则(Single Responsibi…...

c语言学习,malloc()函数分析
1:malloc() 函数说明: 申请配置size大小内存空间 2:函数原型: void *malloc(size_t size) 3:函数参数: 参数size,为申请内存大小 4:返回值: 配置成功则返回指针&#…...

【运维项目经历|041】上云项目-物理机迁移到阿里云
🍁博主简介: 🏅云计算领域优质创作者 🏅2022年CSDN新星计划python赛道第一名 🏅2022年CSDN原力计划优质作者 🏅阿里云ACE认证高级工程师 🏅阿里云开发者社区专家博主 💊交流社区:CSDN云计算交流社区欢迎您的加入! 目录 项目名称 项目背景 项目目标 项…...
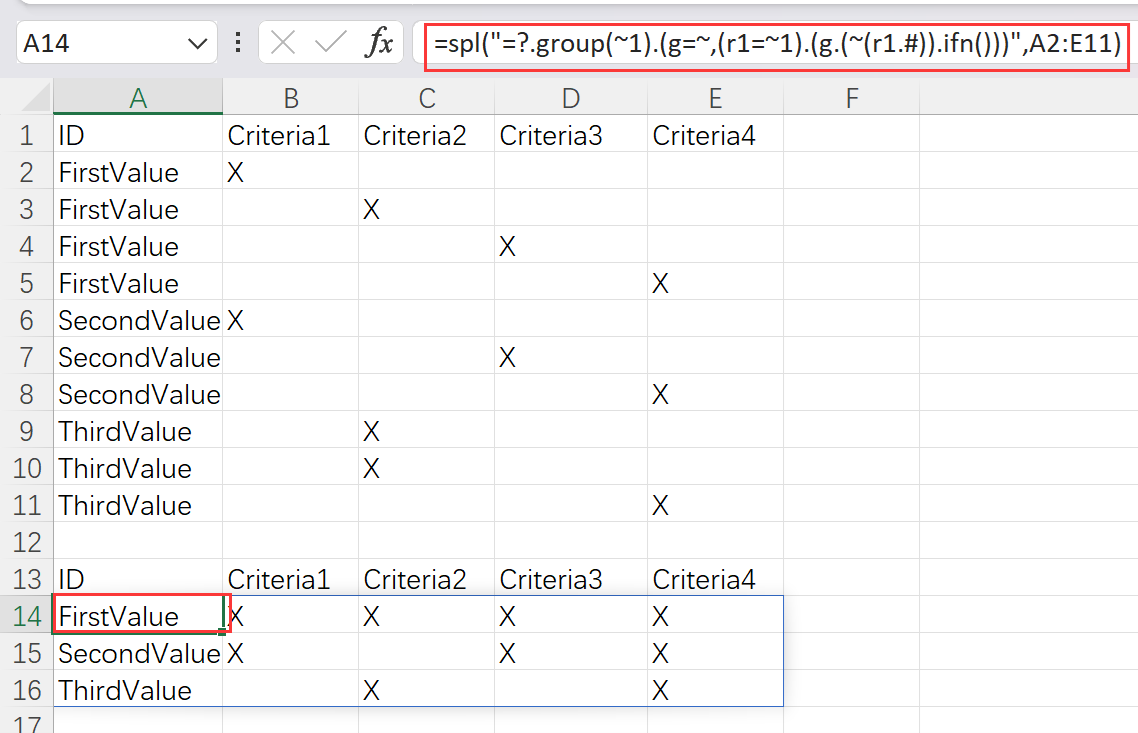
分组并合并其它列的非空值 --Excel难题#83
Excel第1列是分类,第2-42列是平行的多个数据项列,下表用部分列示例。数据有X或null两种情况,同一个分类的同一列数据偶尔有重复。 ABCDE1IDCriteria1Criteria2Criteria3Criteria42FirstValueX3FirstValueX4FirstValueX5FirstValueX6SecondVa…...

VM相关配置及docker
NAT——VMnet8网卡 桥接——WLAN/网线 仅主机——VMnet1网卡 docker与虚拟机的区别 启动docker服务 systemctl start docker 重启 systemctl start docker关闭docker服务 systemctl stop docker.servicedocker的两大概念 镜像:images,应用程序的静态文…...

Redis中Set数据类型常用命令
目录 1. 添加元素 2. 移除元素 3. 检查成员是否存在 4. 获取集合成员 5. 获取集合成员数量 6. 随机获取集合中的一个成员 7. 集合运算 8. 集合的移值 9. 提供集合的随机元素 在Redis中,Set是一种无序且不重复的字符串集合。 1. 添加元素 SADD key member [member ..…...

mysql误删数据恢复记录
背景 1、数据库版本 5.7.36,由于误操作删掉了表的所有数据,但是数据库备份每天凌晨进行、只能从备份恢复昨日的全量数据,当日的数据将会丢失 查看binlog配置 binlog配置 [mysqld] #设置日志三种格式:STATEMENT、ROW、MIXED 。 bi…...

论文阅读:Real-time Controllable Denoising for Image and Video
这篇文章是 CVPR 2023 的一篇文章,探讨了在图像与视频降噪中,如何实时控制降噪强度的问题。 Abstract 图像或者视频降噪,是在细节与平滑度之间的一个微妙的平衡,因为噪声与细节都属于高频信息,降噪在去除噪声的同时&…...

【Kubernetes】虚拟 IP 与 Service 的代理模式
虚拟 IP 与 Service 的代理模式 1.userspace 代理模式2.iptables 代理模式3.IPVS 代理模式 由于 Service 的默认发布类型是 ClusterlP,因此也可以把 ClusterIP 地址叫作 虚拟 IP 地址。在 Kubernetes 创建 Service 时,每个节点上运行的 kube-proxy 会自动…...

AI 项目经理 Agent:拆解任务、分配资源与监控风险
AI项目经理Agent:拆解任务、分配资源与监控风险的全流程落地指南从GPT-4发布以来,“AI替代白领”的声音此起彼伏,但作为一名在互联网大厂带过3个亿级SaaS交付项目、同时搞了2年AI辅助项目管理(AIPM)落地的软件工程师&a…...

对比直接使用原厂 API 体验 Taotoken 在模型选型上的便捷性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用原厂 API 体验 Taotoken 在模型选型上的便捷性 当开发者需要评估不同大模型的能力以适配具体项目时,通常会…...

高性能缓冲管理中的数组翻译技术解析
1. 高性能缓冲管理中的数组翻译技术解析在现代数据库系统中,缓冲管理器是连接内存与持久化存储的关键组件,其核心任务是将逻辑页ID映射到物理内存帧。传统方案如哈希表或指针交换存在三个根本性缺陷:内存开销随数据集线性增长、并行访问时的锁…...

用Adafruit MONSTER M4SK改造Boglin玩具:赋予经典怪物互动电子眼
1. 项目概述:当经典玩具遇上开源硬件如果你和我一样,对上世纪80年代那些造型古怪、充满想象力的玩具情有独钟,同时又是个喜欢动手折腾的创客,那么这个项目绝对能让你兴奋起来。今天我们要聊的,是如何让一个几乎被遗忘的…...

政府新媒体宣发审核和监测对内容合规有哪些意义
在政务新媒体全谱系发展的今天,信息发布面临着意识形态安全、法律合规、公民隐私保护等多重考验。建立完善的宣发审核与监测机制,对保障内容合规具有决定性的意义,它是数字政府建设中不可或缺的“安全阀”与“过滤器”。以下是宣发审核和监测…...

在OpenClaw中快速接入Taotoken实现AI助手功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw中快速接入Taotoken实现AI助手功能 OpenClaw是一款功能强大的AI助手工具,能够帮助开发者进行代码生成、问题…...

Eviews面板数据建模保姆级教程:从Hausman检验到模型选择,一次讲透固定效应与随机效应
Eviews面板数据建模实战指南:从数据导入到模型选择的完整流程 面板数据分析作为计量经济学中的重要工具,能够同时捕捉时间和个体维度的信息。对于刚接触Eviews的研究者来说,如何正确建立面板模型往往令人困惑——从数据准备到模型选择&#x…...

叶绿体注释翻车实录:Geseq vs. NCBI格式差异与特殊基因处理实战
叶绿体注释翻车实录:Geseq vs. NCBI格式差异与特殊基因处理实战 当两个权威工具对同一段叶绿体DNA给出不同注释时,该相信谁?这个问题困扰过每一位从事基因组注释的研究者。去年在完成水稻叶绿体项目时,我同时用Geseq和NCBI标准流程…...

ElevenLabs声音库资源推荐,从免费层到企业级Tier 4权限全解锁:含3个已下架但仍在灰度测试的传奇音色
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs声音库资源推荐 ElevenLabs 提供了业界领先的高质量语音合成服务,其声音库涵盖多语种、多风格及可定制化角色音色。官方声音库分为三类:预置语音(Prebuilt…...
)
别再只用HTTP了!用Flask-SocketIO给你的Python Web应用加上实时聊天功能(附完整前后端代码)
用Flask-SocketIO为Python Web应用注入实时交互能力 当你的博客读者提交评论后,管理员需要刷新页面才能看到新内容;当团队协作工具中的任务状态变更时,同事必须手动同步才能获取最新进展——这些传统HTTP请求带来的延迟与割裂感,正…...