计网之HTTP协议和Fiddler的使用
文章目录
- 一. HTTP概述和fidder的使用
- 1. 什么是HTTP
- 2. 抓包工具fidder的使用
- 2.1 注意事项
- 2.2 fidder的使用
- 二. HTTP协议格式
- 1. HTTP请求格式
- 1.1 基本格式
- 1.2 认识URL
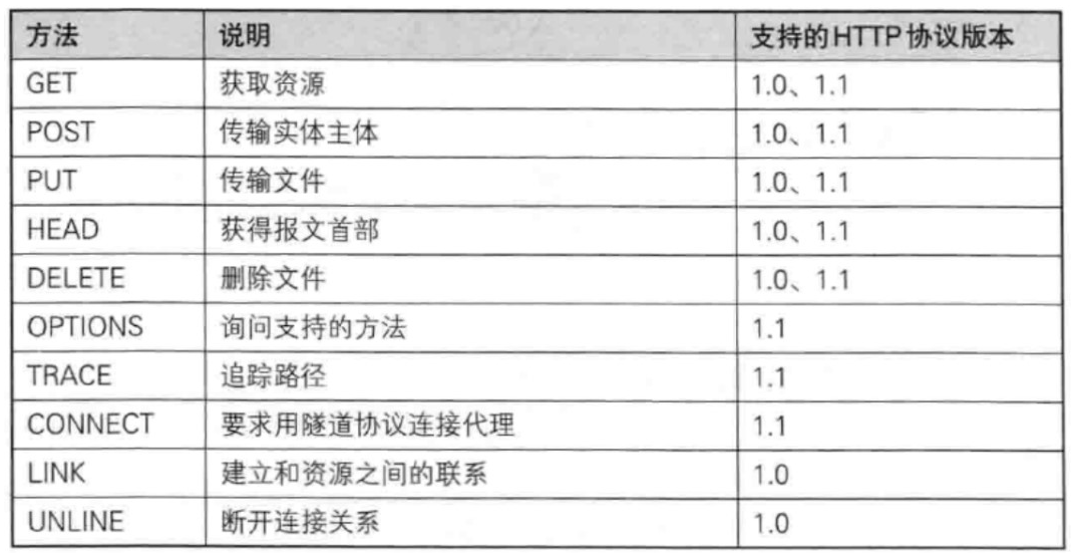
- 1.3 方法
- 2. 请求报头关键字段
- 3. HTTP响应格式
- 3.1 基本格式
- 3.2 状态码
一. HTTP概述和fidder的使用
1. 什么是HTTP
HTTP全称为 “超文本传输协议”, 是属于应用层最广泛使用的协议之一, 目前主要使用的是HTTP1.1和HTTP2.0, 在本篇中主要介绍的是HTTP1.1版本, HTTP往往是基于传输层的TCP协议实现的(HTTP1.0, HTTP1.1, HTTP2.0 均为TCP, HTTP3基于UDP实现).
所谓 “超文本” 的含义, 就是传输的内容不仅仅是文本(比如 html, css 这些个就是文本), 还可以是一些其他的资源, 比如图片, 视频, 音频等二进制的数据.
我们平时打开一个网站, 浏览器获取到的网页就是基于HTTP来传输数据的, HTTP是浏览器和服务器之间交互的桥梁, 当我们在浏览器中输入一个 百度的 “网址(URL)” 时, 浏览器就会给百度的服务器发送了一个HTTP请求, 百度的服务器返回了一个HTTP响应; 这个响应结果被浏览器解析之后, 就展示成我们看到的页面内容, 这个过程中浏览器可能会给服务器发送多个 HTTP 请求, 服务器会对应返回多个响应, 这些响应里就包含了页面HTML, CSS, JavaScript, 图片, 字体等信息.
2. 抓包工具fidder的使用
我们要想看到HTTP协议的详细交互过程就需要借助第三方工具对HTTP进行抓包, Fiddle是一款专门抓取HTTP/HTTPS包的工具, 下载安装起来很方便, 去官网下载, 然后一路next就行, 网址为https://www.telerik.com/fiddler.
2.1 注意事项
安装完成后要想正确使用有几个点需要注意:
- Fiddle本质上是处在一个 “代理” 的角色, 是有可能和其他的代理冲突的, 使用的时候要关闭其他的代理程序(包括一些浏览器插件).
- 当下互联网上的绝大部分服务器使用的都是
https(基于http的进化版协议), Fiddle默认是不能抓取https包的, 需要我们手动设置一下并且安证装书, 操作如下:
首先找到Tools选项, 选择Options, 找到HTTPS.
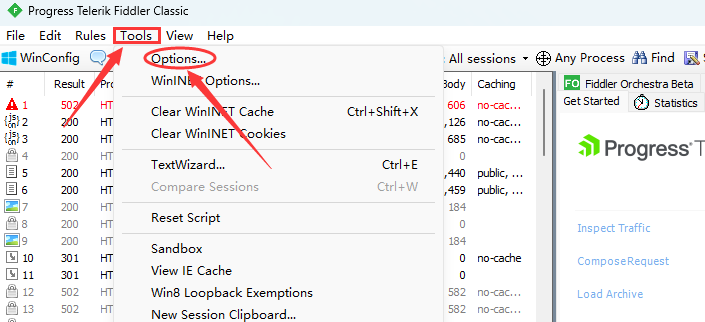
然后将下图中的选项全部勾上, 点击OK, 此时会有一个窗口跳出来提示安转证书, 这里一定要点yes, 不然就要重装Fidder了.
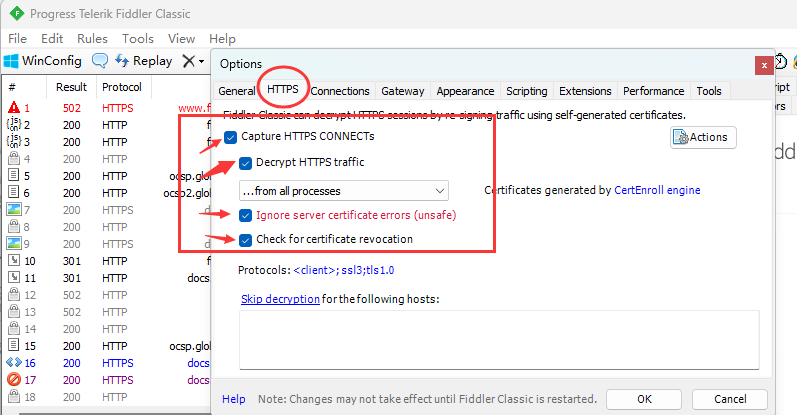
Fidder本质上就是一个代理程序, Fidder开启时服务器和客户端之间的传输都需要经过先经过Fidder这里, 即客户端给服务器发送请求会先将请求发送给Fidder, 然后Fidder再把请求发送给服务器; 同样的服务器的响应也需要先经过Fidder, 然后再发送给客户端; 代理分为正向代理和反向代理两种, 代表着客户端的代理, 叫做正向代理, 代表着服务器的代理, 叫做反向代理.
2.2 fidder的使用
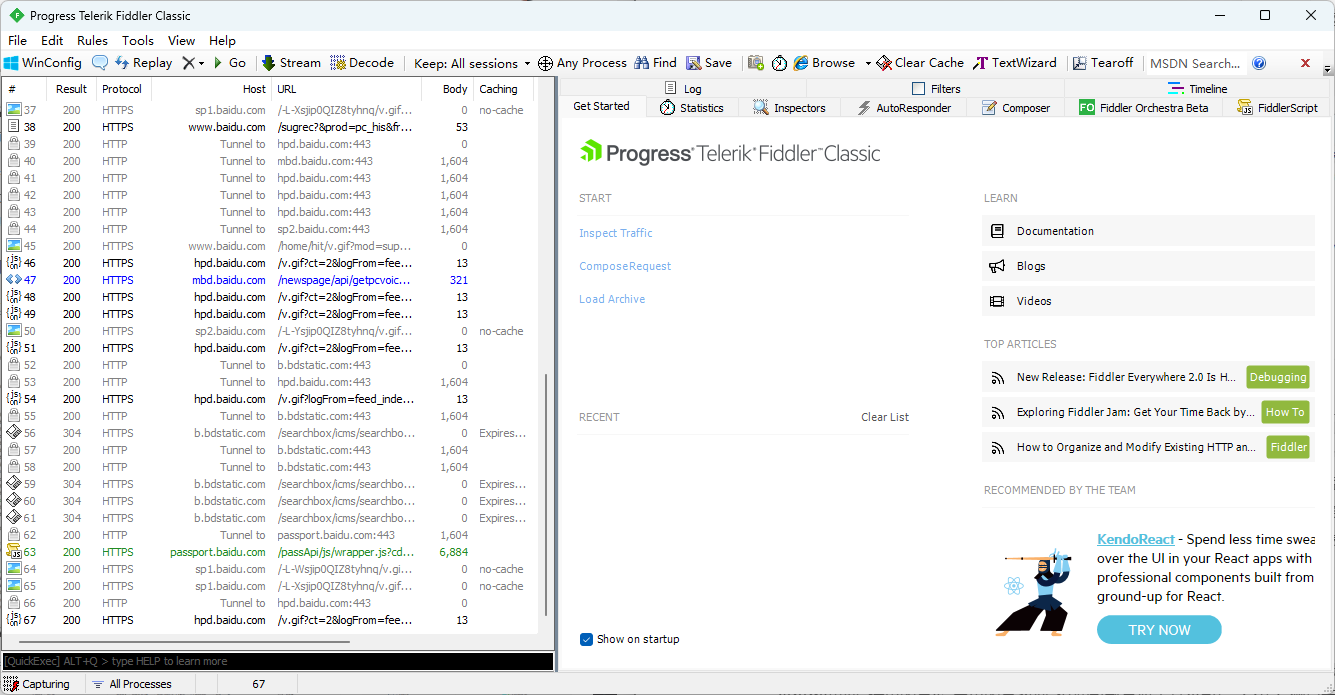
比如在浏览器中输入百度的网址进行访问, Fidder左侧就是捕获到的http/https包, 也就是电脑上浏览器使用http和服务器交互的过程, 一般蓝色的就说明传输的是一个html页面, 绿色的是js, 黑色的是数据, 这些结果都是浏览器在访问百度主页时产生的http请求, 浏览器打开一个页面, 对应的HTTP请求可能是一个, 也可能是多个, 最需要关注的是图片中蓝色的包, 这个是在请求百度的首页页面, 其他的请求都是基于这个请求产生的(百度主页里, 其他代码有产生了别的请求).
双击某个包后, 会在右侧显示详细信息, http是有一定的格式的, Fidder按照不同的格式解析会呈现出不同的显示效果, 右侧的上下两栏中, 上面是请求, 下面是对应的响应.
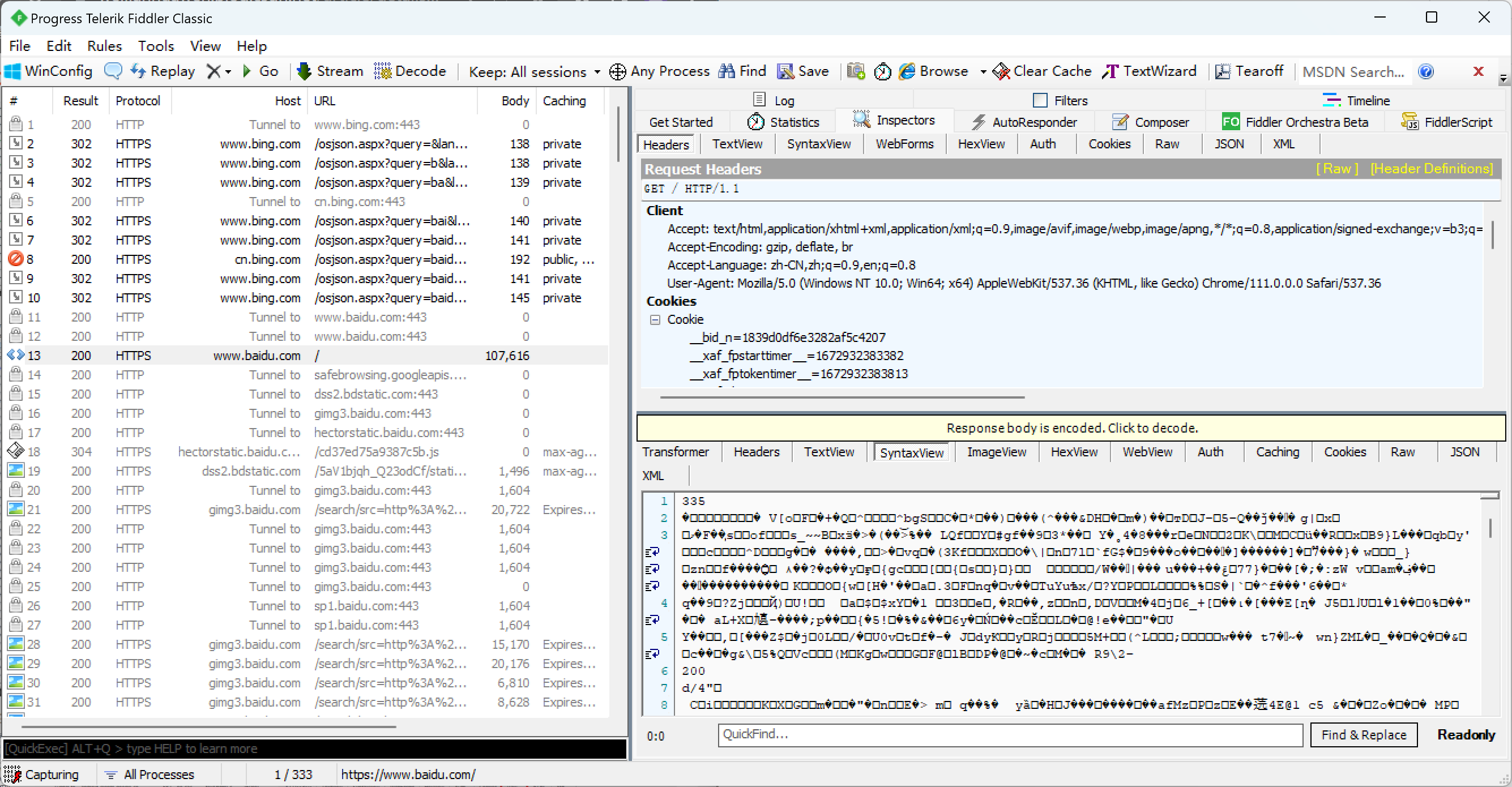
点击Raw, 在这个模式下可以看到http的本体(最原始的效果).
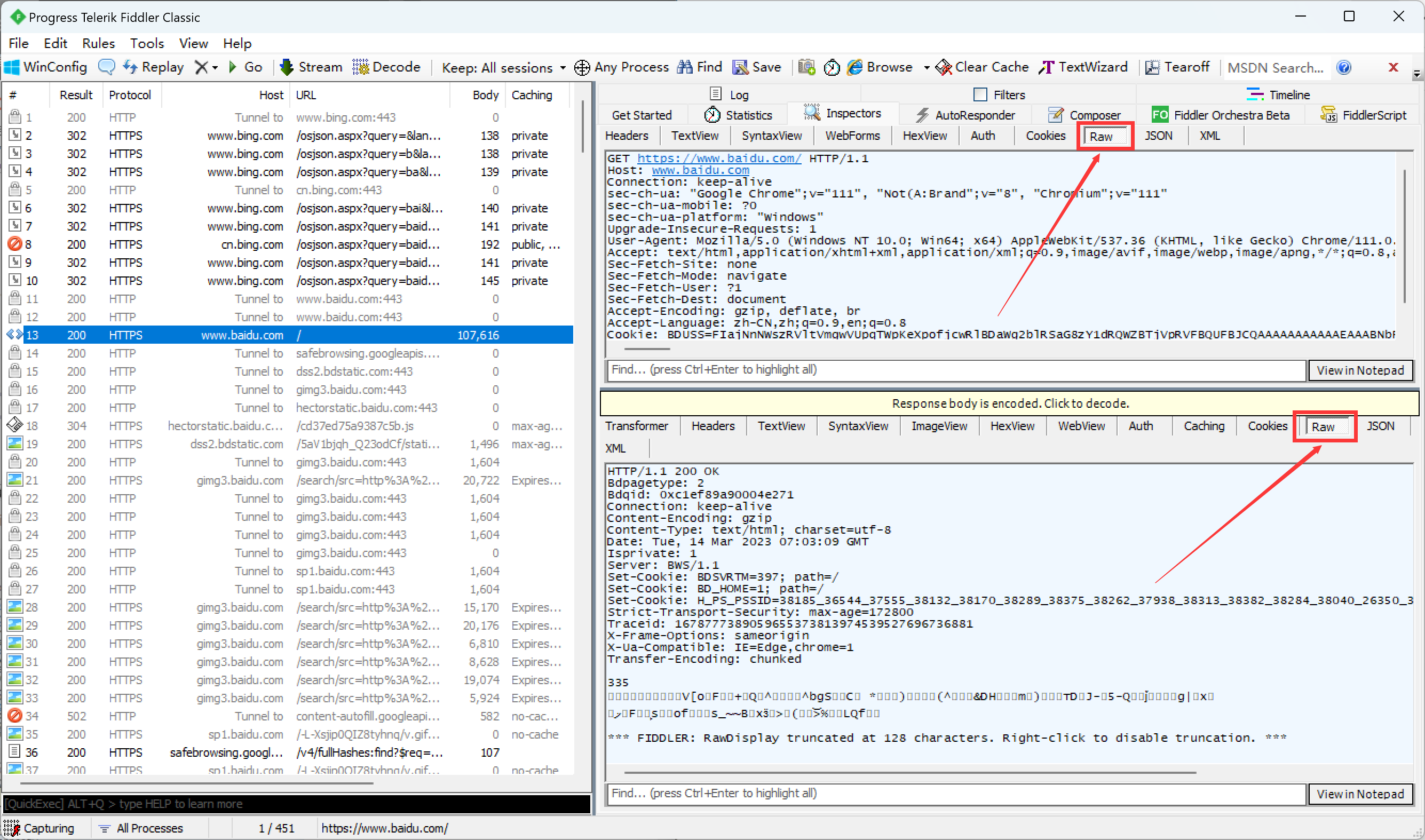
点击View in Notepad可以使用记事本打开, 更方便的查看详细内容.
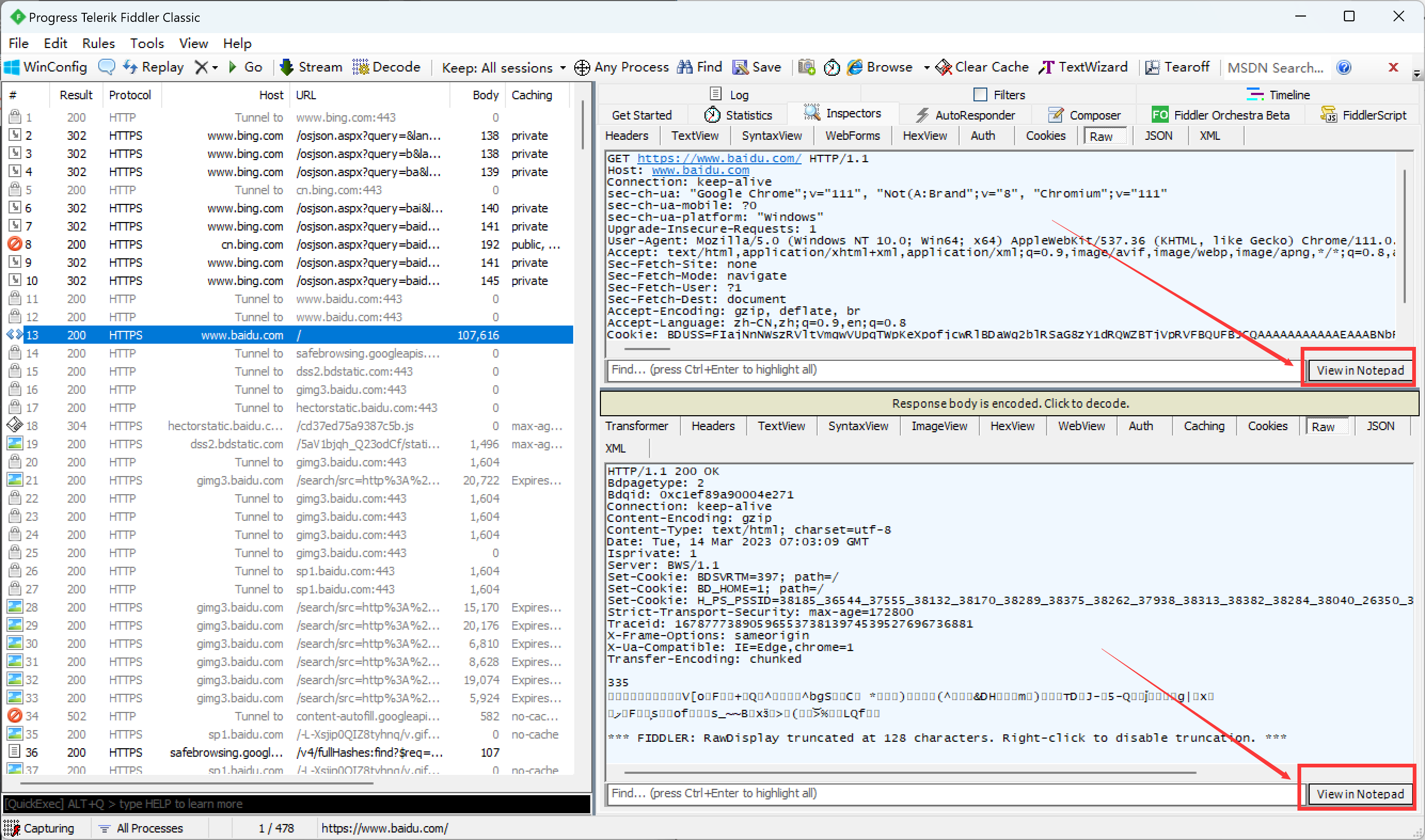
观察上图中响应可以看到里面有一串乱码, 这是为了节省网络带宽, 有的服务器会对响应数据进行压缩变成了二进制数据(进行了重新编码), 点击下面的黄色按钮就可以解压缩显示正常的响应结果.

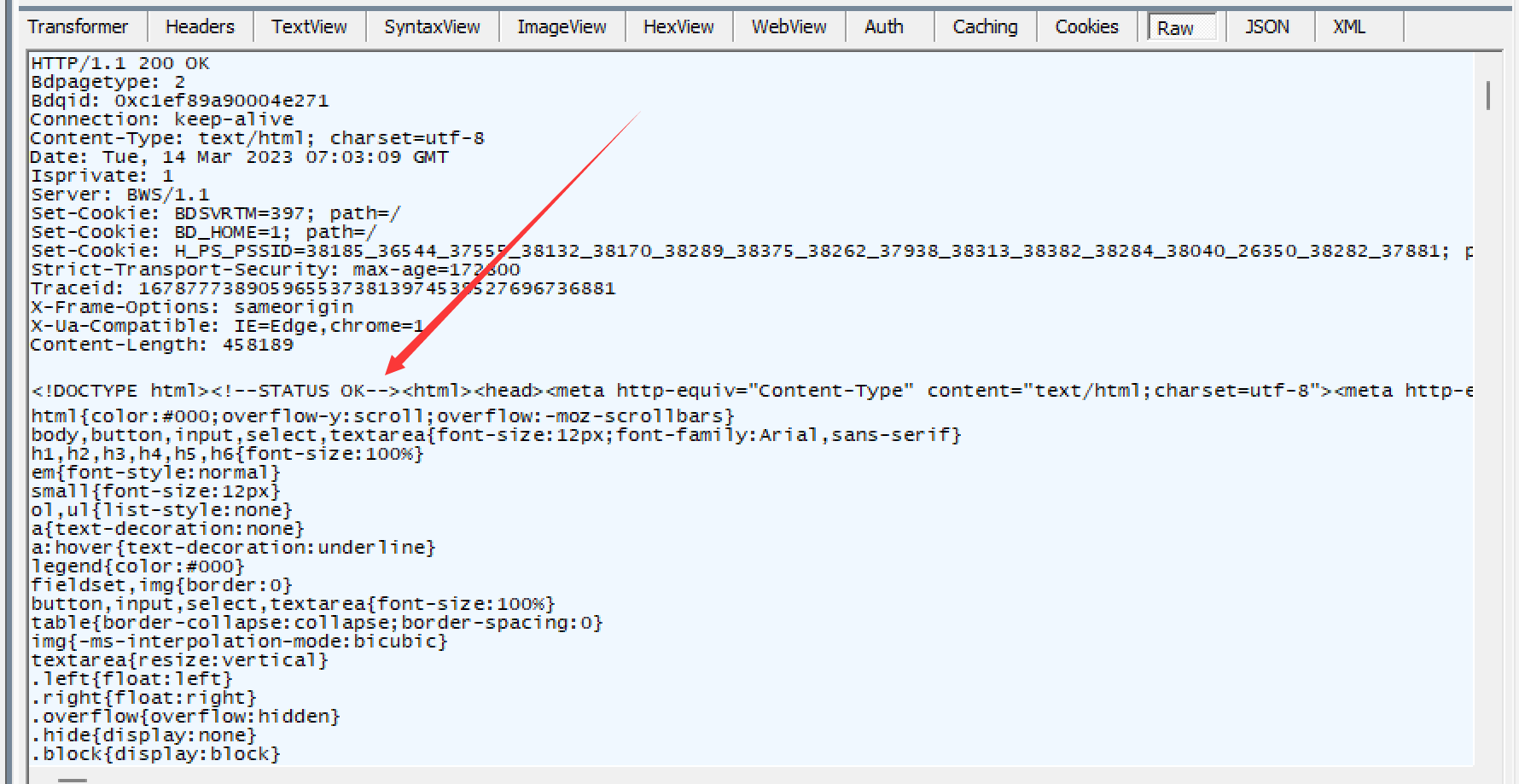
这里解压缩后得到的文本数据就是百度主页html里面的内容, 这些就是Fidder的基本理解和使用了, 还要补充一下就是并不是所有的数据都可以进行压缩的, 有的数据重新编码之后, 可能体积会更大, 但是像一般的html/js这样的文本文件, 压缩率还是很高的.
二. HTTP协议格式
在上面Fidder的抓包结果其实可以观察到, http协议其实是个行文本格式的数据, 相比于tcp这种二进制格式来说, 更方便用户进行直接观察, HTTP请求本质上就是给tcp scket里写了一个符合http格式的字符串, 下面就来介绍一下http协议的报文格式, 基本格式如下:
1. HTTP请求格式
1.1 基本格式
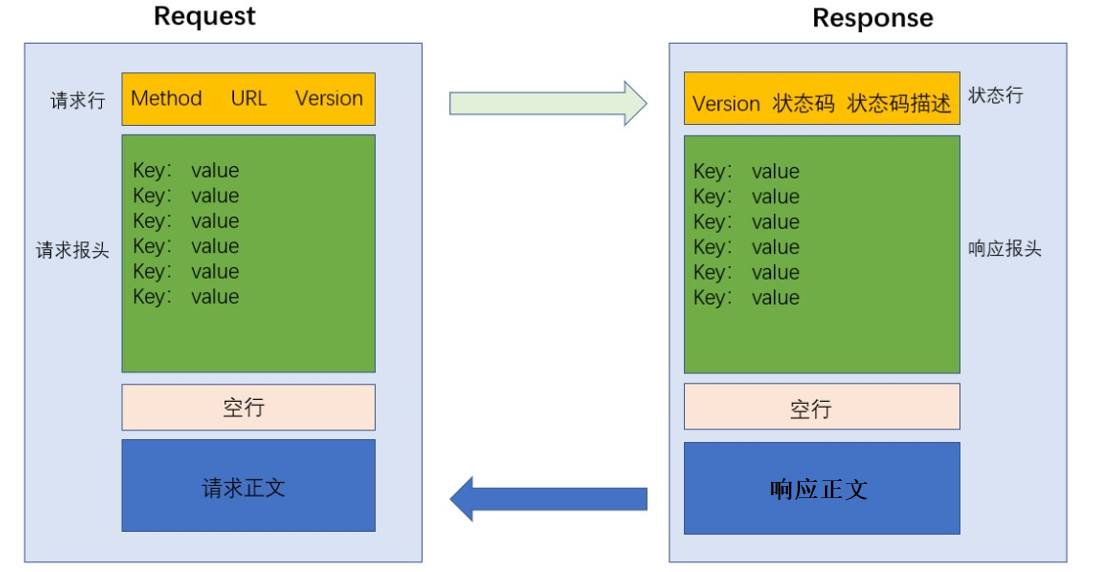
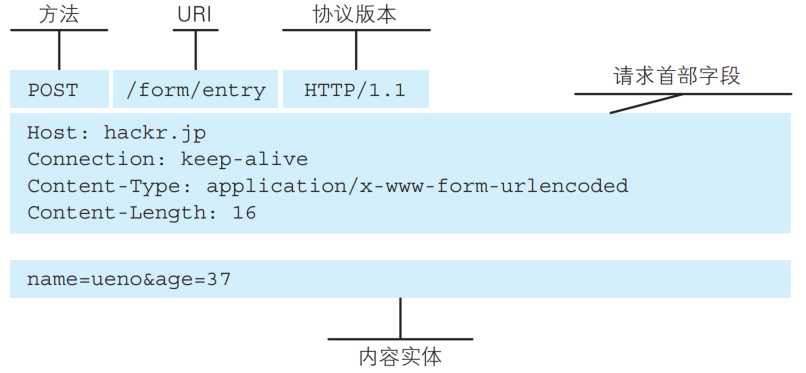
http请求的报文格式由请求行, 请求报头(header), 请求正文(body)这三部分组成, 报头与正文之间使用空行做标记进行分隔.
比如用Fidder抓到的访问百度页面的请求包, 如下:
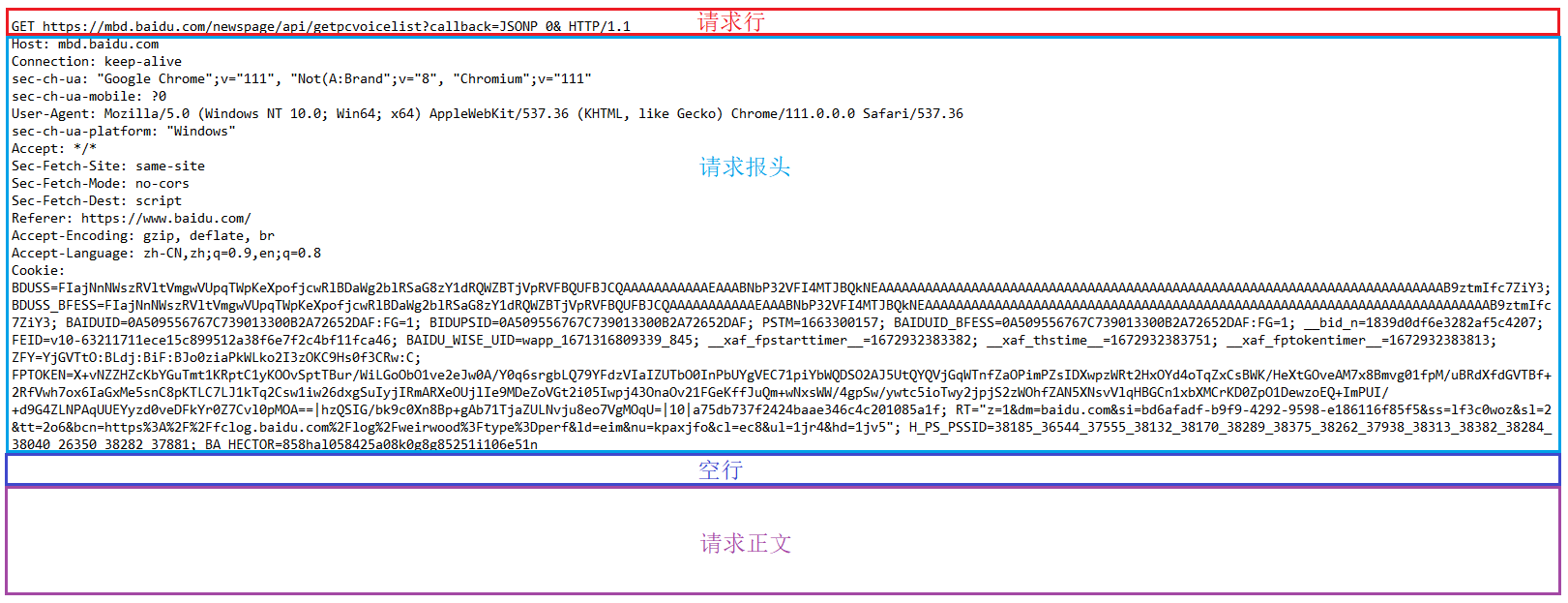
请求行包含三个部分, 分别是方法, URL, HTTP版本号, 使用空格来分隔.
方法用来描述请求的目的是什么, 比如GET方法一般是用来获取服务器的资源.
URL是唯一资源定位符, 俗称网址, 用来标识互联网上唯一资源的位置.
首行的最后标明了所使用http协议的版本.
请求报头包含很多行, 由许多的键值对组成, 键和值之间使用:来进行分割, 键值对的数量是不固定的.
请求正文是可选项, 不一定有, 像上面的那个例子请求正文就是空的.
1.2 认识URL
URL是唯一资源定位符, 与之相似的还有URI, 这个是唯一资源标识符, 起到身份标识的作用, 和其他资源进行区分, 而实际上, URL也可以起到身份标识的作用, URL可以理解为URI的一种实现, 就像接口与实现类的关系一样, 实际开发中, 这两个也不做区分, 经常会把这两个词混用.
URL的详细规则由因特网标准RFC1738进行了约定, 且TCP, IP, UDP的协议格式都是RFC系列文档定义的, URL不是HTTP专属的, 很多的协议都可以使用URL.
URL格式:
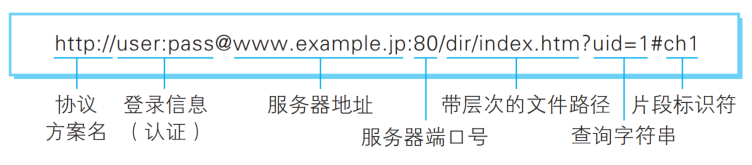
URL最关键的四个部分是域名/IP, 端口号, 带层次的路径, 查询字符串, URL里的的有些内容不可省略(必选项), 有些内容可以省略, 具体如下:
-
协议方案名: 必选项, 使用http或https等协议方案名获取访问资源时要指定协议类型, 不区分字母大小写, 最后附一个冒号
:, 使用//与后面的字段分隔, 也可使用 jdbc:mysql:// 或 javascript: // 这类指定数据程序或脚本程序的方案名. -
登录信息: 可选项, 现在基本已经不用了.
-
服务器地址: 必选项, 可以使用DNS可解析的域名或直接使用
IP地址来表示, 使用:与端口号分隔, 没有端口号则:省略. -
服务器端口号: 可选项, 描述了要访问主机上的哪一个应用程序, 若该字段为空, 浏览器会提供默认的端口号, http是
80, https是443. -
带层次的文件路径: 必选项, 描述访问的服务器上指定位置的资源, 不同的路径, 拿到的资源是不同的, 最简单的路径就是一个
/, 代表的是http服务器的根目录, 可以理解为http服务器是系统上的一个进程, 就让这个进程管理系统上的一个特定的目录, 这个目录里面的资源都可以让外面进行访问,/管理的根目录可以是系统上的任意一个目, 由http服务器具体配置. -
查询字符串: 可选项, 是获取资源的时候带的参数, 是以键值对的方式组织(
query string), 以?开头, 键值对之间使用&分割, 键和值之间使用=分割; 表示浏览器或者客户端传给服务器自定义的信息, 对获取的资源提出进一步的要求, 一般是程序员自定义, 所以这部分除非是自己写的, 要不然大概率是看不懂的, 使用#与片段标识符分隔. -
片段标识符: 可选项, 使用片段标识符通常可标记出已获取资源中的子资源(文档内的
某个位置), 但在RFC中并没有明确规定其使用方法.
在浏览器中输入请求百度主页的网址https://www.baidu.com/, 会得到如下页面, 这里的文件路径就是/.
而如果将文件路径换成/default.html, 得到的就是和上面不同的一个网页了.
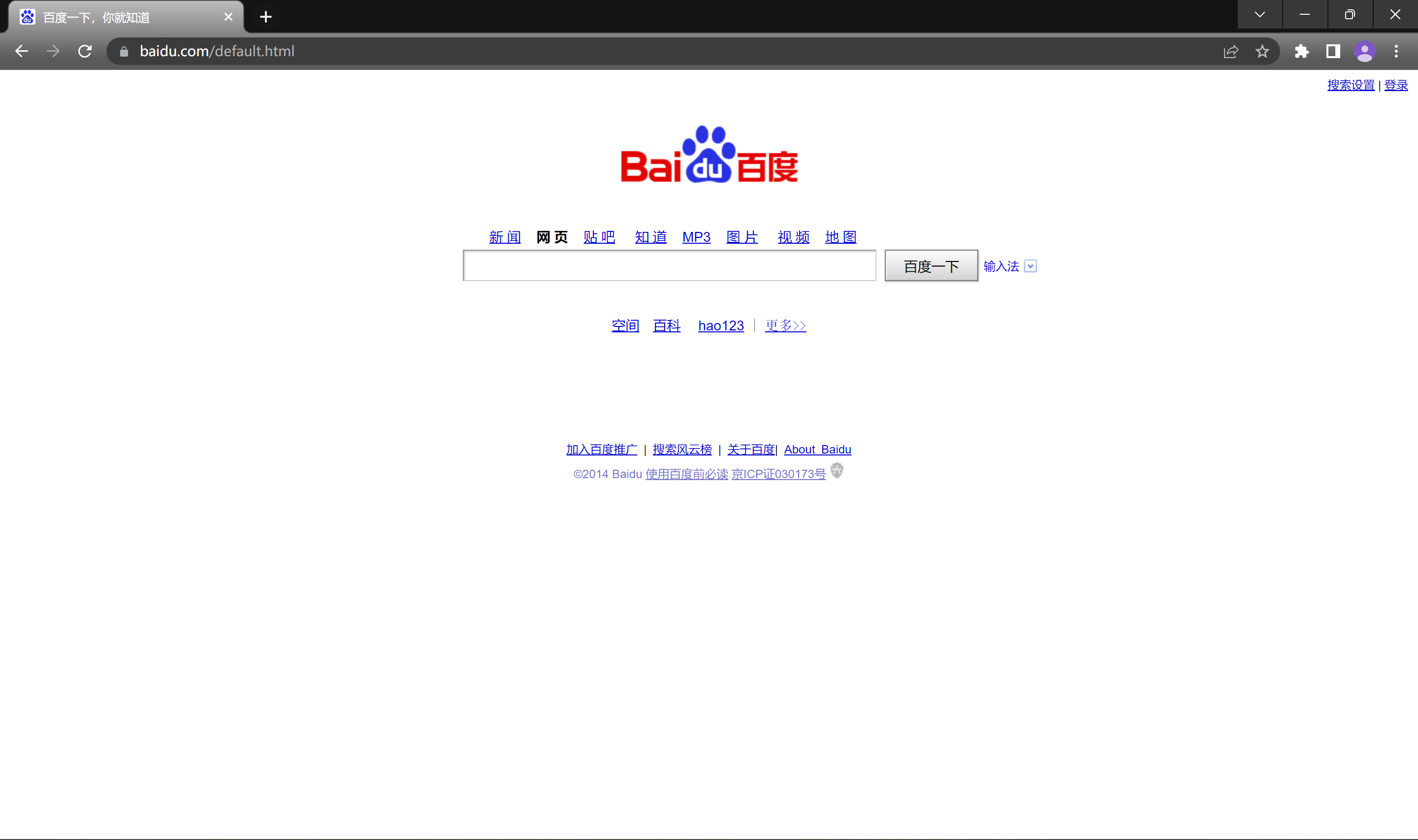
在百度搜索框中输入天使彦搜索, 得到如下页面.
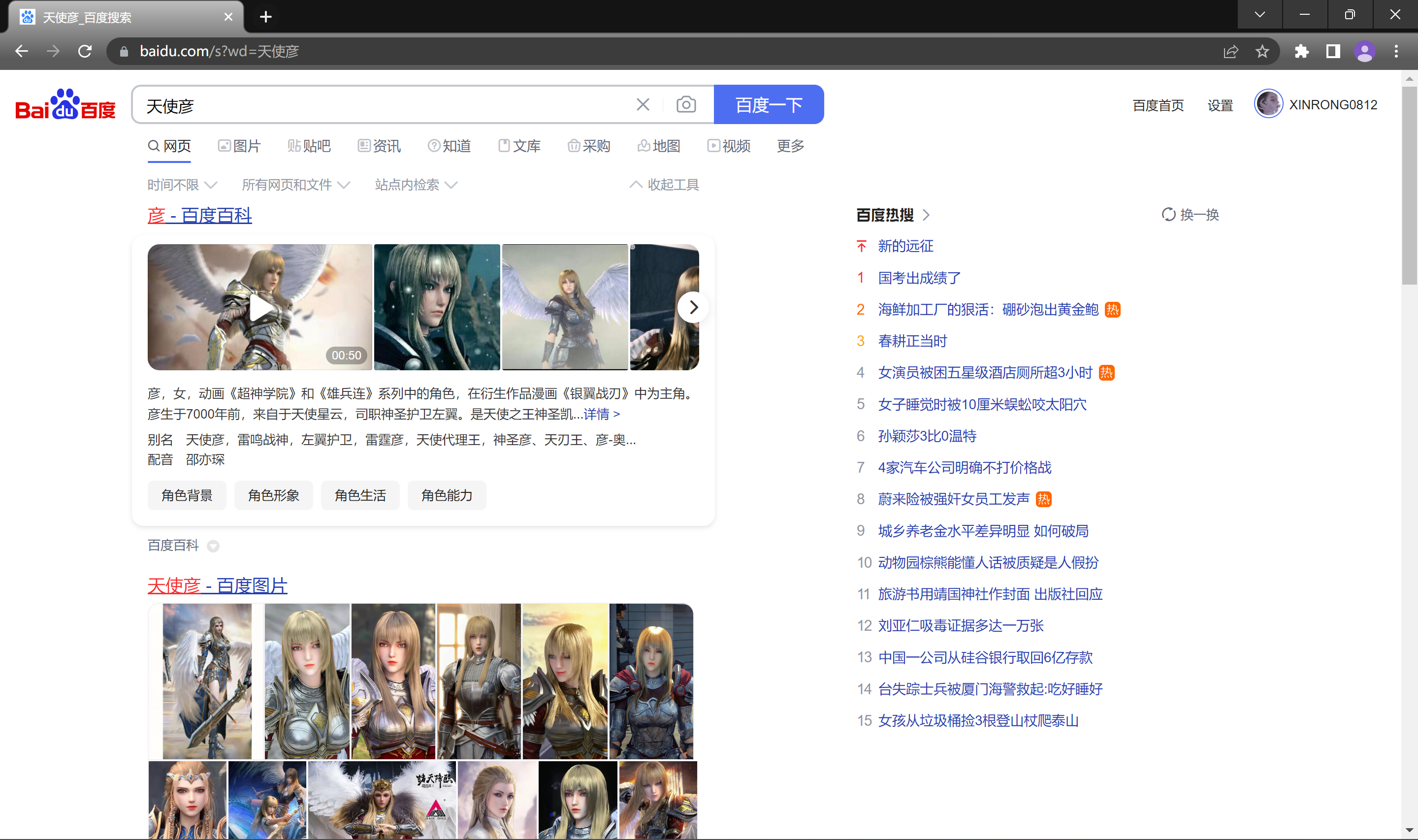
这里我们在浏览器中看到的URL的查询字符串是有文字显示效果的, 但我们再将这个网址复制下来, 复制到记事本中就不是文字效果了.


这里其实是浏览器/http服务器将查询字符串的值使用url encode(转义工具)进行了重新编码, 这样做的原因是URL中有些字符是是有特定含义的(比如/, ?), 这些字符是不能出现在查询字符串中的, 同时这样可以兼容一些不支持中文的字符集, 也方便浏览器和其他一些工具的识别, 如果这里不重新编码, 直接就是中文, 浏览器可能就无法正确识别了; 通常情况下, 一个中文字符由UTF-8或者GBK这样的编码方式构成, 虽然在 URL 中没有特殊含义, 但是仍然需要进行转义, 否则浏览器可能把UTF-8/GBK编码中的某个字节当做URL中的特殊符号.
1.3 方法
请求行中的方法是用来告知服务器请求意图的HTTP方法, 不同的方法描述了不同的语义, 有着不同的意图, 比如GET表示获取资源, POST表示上传资源, 在实际开发中最常用的也是这两个方法, 其他的方法大部分是用不到的, 但实际开发中, 语义仅供参考, 实际代码可能并不是遵照语义去写的.
各种方法功能如下:
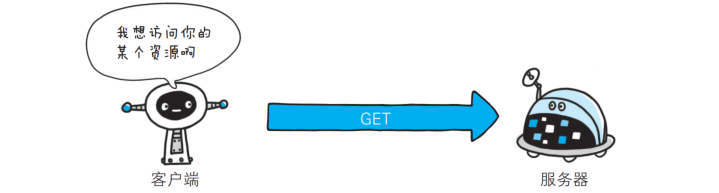
🎯GET: 获取资源
GET是最常用的HTTP方法, 常用于获取服务器上的某个资源, 在浏览器中直接输入URL, 此时浏览器就会发送出一个GET请求, 除此之外, HTML中的link, img, script等标签, 也会触发GET请求, 用JavaScript中的ajax也能构造GET请求.
GET的请求报文首行的第一部分为GET, URL的query string可以为空, 也可以不为空, header部分有若干个键值对结构, body部分为空.
🎯POST: 传输实体主体
POST方法也是一种常见的方法, 多用于提交用户输入的数据给服务器(例如登陆页面跳转的时候会涉及到POST), 通过HTML中的form标签可以构造POST请求, 或者使用JavaScript的ajax也可以构造POST请求.
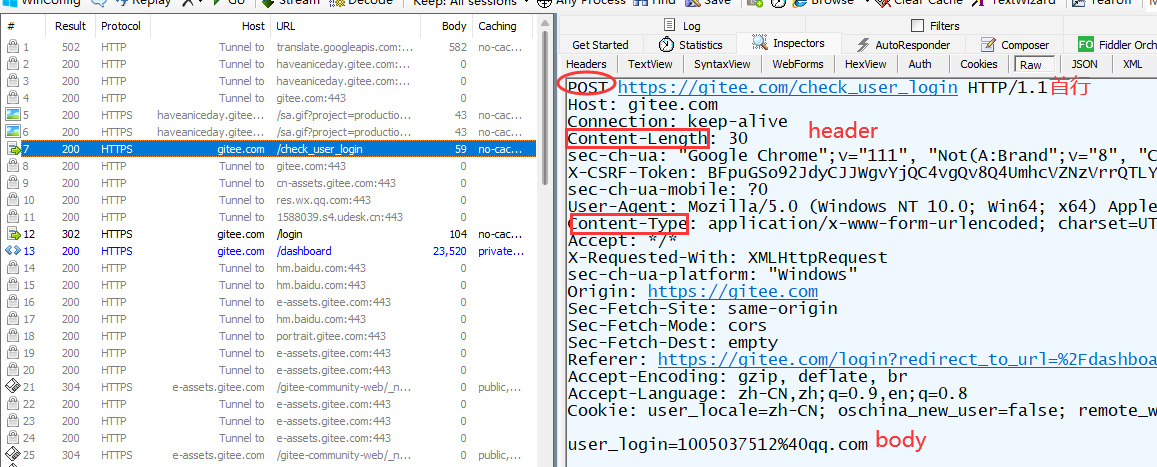
POST的请求报文首行的第一部分为POST, URL的query string一般为空(也可以不为空), header部分有若干个键值对结构, body部分一般不为空, body内的数据格式通过header中的Content-Type指定, body的长度由header中的Content-Length指定, 也就是说body中存放的数据内容和格式都是程序员自主定义的.
我们可以使用Fiddler观察POST方法, 比如在码云(Gitee)的登陆页面, 输入用户名, 密码, 验证码之后, 点击登陆, 就可以看到 POST 请求.
🎯其他方法
PUT与POST相似, 只是具有幂等(相同的输入得到的结果也是确定的)特性, 一般用于更新.
DELETE删除服务器指定资源.
OPTIONS返回服务器所支持的请求方法.
HEAD类似于GET, 只不过响应体不返回, 只返回响应头.
TRACE回显服务器端收到的请求, 测试的时候会用到这个.CONNECT预留, 暂无使用.
其实GET和POST是没有本质区别的, 在大部分场景下彼此之间都可以相互进行替代, GET可以实现POST所具有的特性, 同样POST也可以实现GET所具有的特性, 这两个方法细节上的差别如下:
- 从语义上来说,
GET请求一般用于服务器获取数据,POST请求一般用于给服务器提交数据, 但这并不是强制性要求, 只是建议这样来写. - 从习惯用法上说, GET不用有body(请求正文),
GET通过query string(查询字符串)来个给服务器传输一些数据;POST有body, POST通过body来传输数据, 并不绝对, 只是使用习惯. - 还有,
GET请求一般是幂等的, 即相同结果得到的输出结果是相同的, 所以GET是可以被缓存的(把请求的结果保存了下来, 下次请求就不必真的去请求, 直接取缓存结果即可);POST请求一般是不幂等的, 所以POST是不可以缓存的.
关于他们两个的区别, 还有一些说法在现在看来是有些争议的, 比如有说法说GET请求所能传输的数据量存在上限(1KB, 2KB, 1024KB等版本), 这些其实是在早期实现浏览器/服务器的时候弄了这样的限制, 但实际上RFC标准文档中对于HTTP GET请求的长度上限是没有明确规定的, 这个说法放在20年前是正确的, 放在当下就不适用了.
还有说POST比GET更安全的, 得出这个结论的依据是如果使用GET请求进行登录, 此时用户名和密码就通过query string来传递, 就会出现在浏览器中的地址栏中会被别人看到, 但实际上, 安全的核心要素是加密, 安全指的是如果黑客窃取数据, 敏感信息不会泄露, 所以这个说法也是不太靠谱的.
2. 请求报头关键字段
header的整体的格式是以 “键值对” 的结构组织的, 每个键值对独占一行, 键和值之间使用:分隔, 这些键值对都HTTP事先定义好的, 具有特定的含义, 这里报头的字段有很多, 这里仅介绍几个常见的关键字段.
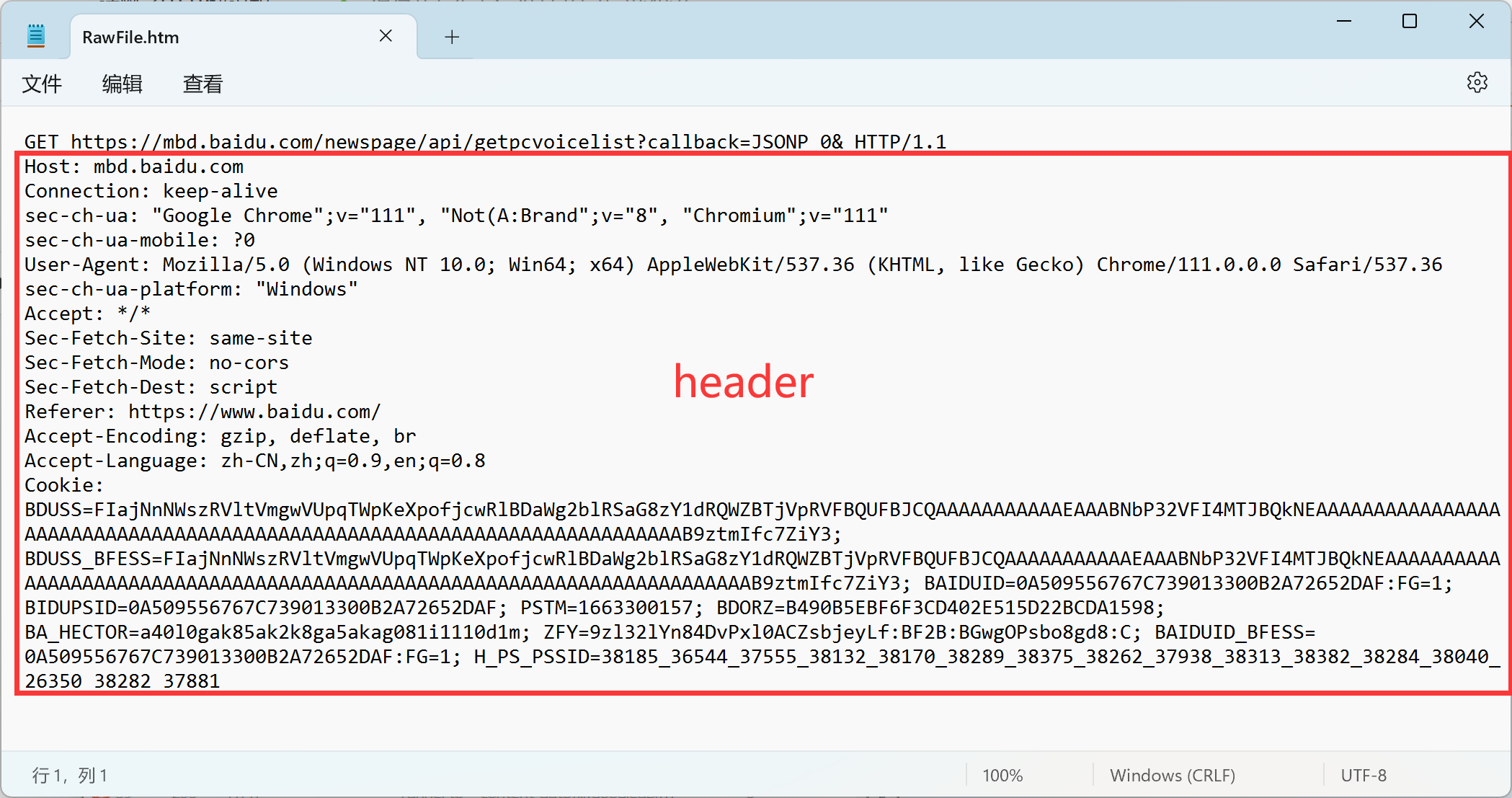
- Host
这个字段大概描述了服务器所在的地址和端口, 即描述了客户端最终要访问的目标, 这里的内容大概率和URL是一样的, 也有一定的情况是不一样的.
- Content-Length
描述了body中的数据长度.
- Content-Type
描述了描述了body中数据的格式, 这里的取值是非常多, 比如值为 application/json说明body中的内容是和应用程序相关的json格式的数据, application/x-www-form-urlencoded是from标签构造的body的数据格式, multipart/form-dataf也是from表单提交的数据格式(在 form 标签中加上 enctyped="multipart/form-data", 通常用于提交图片/文件); 还有text/html, text/css, image/jpg等…
Content-Length和Content-Type这两个字段, 如果是GET请求, 报文中是没有body的, header中也就没有这两个字段了; 如果是POST请求, 是有body的, 那么这两个字段是必须要有的.
- User-Agent(简称UA)
描述了浏览器和操作系统的版本, 之所以有这个字段其实是为了处理和兼容早期版本得浏览器, 在最早期的浏览器上是只支持文本内容的, 浏览器经过之后的发展, 慢慢支持可图片, 音视频, JS等…那么后来的网站开发者写的网页就要考虑网页是否要带这些内容, 索性就针对不同时期的浏览器做了不同版本的网页, 服务器就可以根据User-Agent这个字段来进行判定, 然后给出相应版本的响应, 而现在的User-Agent主要用来区分PC端和移动端.
- Referer
描述了当前页面的来源, 如果直接在浏览器地址栏中输入URL, 或者直接通过收藏夹访问页面时是没有Referer的.
像浏览器中的广告都是都是按点击计费的, 广告主就需要知道用户是通过哪个广告平台跳转到广告主对应的网站, 支付给对应广告平台费用, 但HTTP本身是明文传输的, 很容易有网络运营商劫持的现象出现, 于是就有了HTTPS来解决这个问题.
- Cookie
Cookie是header中非常重要的一个属性, 用来管理服务器与客户端之间状态的, 网页默认不允许访问本地计算机的硬盘的, Cookie本质上是浏览器给网页提供的本地存储数据的机制, 对浏览器访问硬盘做出了明确的限制, Cookie中的内容存在于浏览器中(硬盘).
Cookie中存储的是一个字符串, 这个字符串中有若干的键值对, 键和值之间使用=分隔, 而键值对之间使用;分隔, 还有一些其他的内容.
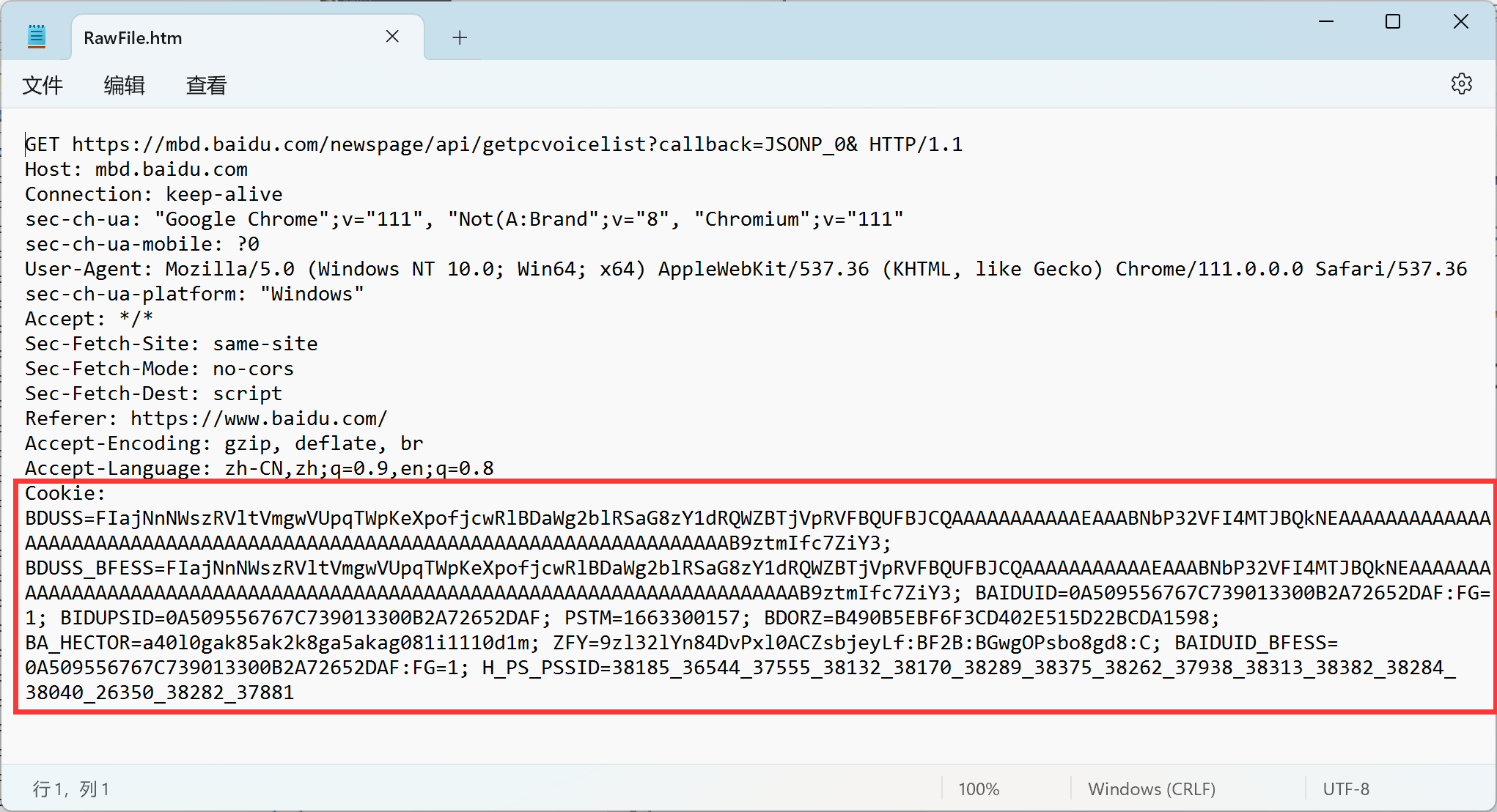
这部分内容也是由程序员自定义的, 我们大概率是看不懂的, 只有开发这部分程序代码的程序员才知道, Cookie在存是时候是按照浏览器+域名的维度来进行细分的, 不同的浏览器有不同的Cookie, 同一个浏览器不同的域名, 对应的也是不同的Cookie, Cookie里面的除了键值对(域名)以外还有过期时间(有效期), 路径等信息, 比如有很多的网站, 登录之后就自动记录了登录状态, 在有效期内访问就不需要重复登录了.
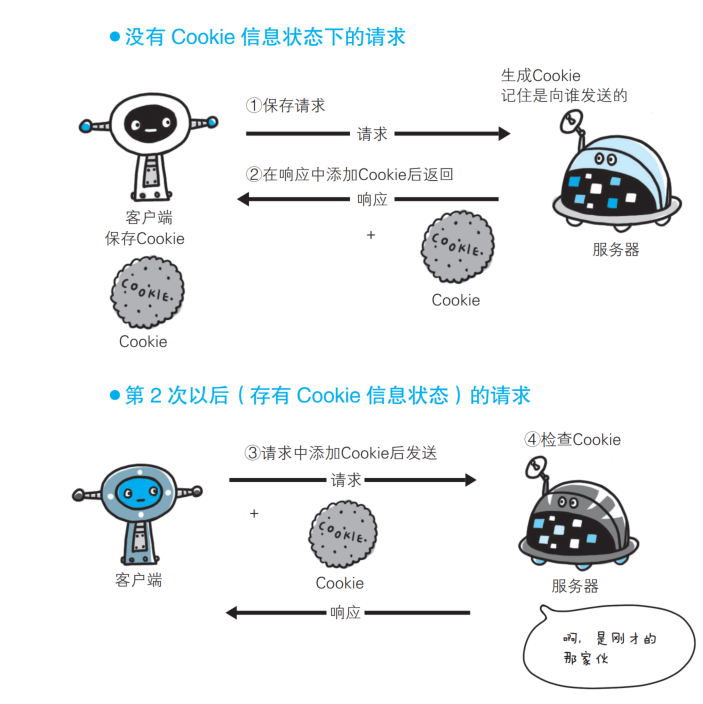
Cookie的作用主要是用户识别及状态管理, 里面存的内容类似于 “上下文”, Web网站服务器为了管理用户的状态会通过Web浏览器, 把一些数据临时写入用户的计算机内, 接着当用户访问该Web网站时, 可通过通信方式取回之前发放的Cookie;
也就是说, Cookie中的数据是来自于服务器的, 服务器来根据用户的状态决定浏览器Cookie中的内容(通过HTTP响应的报头部分的Set-Cookie字段)

要理解一个服务器是要给多个客户端服务的, 服务器不可能去记住每一个客户端的状态, 服务器返回给客户端中的Cookie就是保存了当前用户所使用客户端的中间状态, 当客户端下次访问服务器时, 就会自动的把Cookie的内容带入到请求当中, 服务器就可以知道客户端现在的状态以进行下一步的响应, 所以说, Cookie来自于服务器, 最终还是要回到服务器的.
3. HTTP响应格式
3.1 基本格式
http响应的的报文格式由响应行, 响应报头(header), 响应正文(body)这三部分组成, 报头与正文之间使用空行做标记进行分隔.
比如用Fidder抓到的访问百度页面的响应包, 如下:
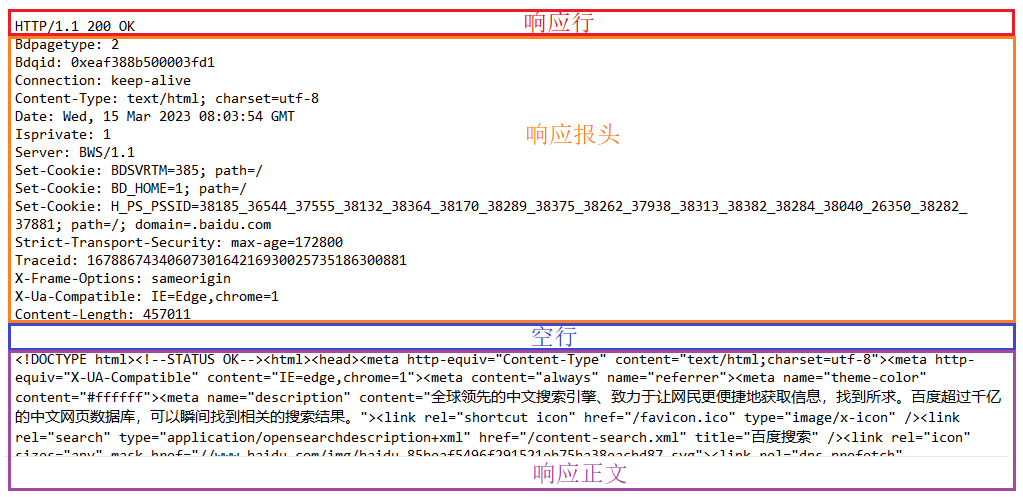
响应行包含三个部分, 分别是协议版本, 状态码, 状态码描述, 使用空格来分隔.
状态码和状态码描述这两个描述了访问一个页面响应的结果, 是访问成功, 还是失败, 还是其他的一些情况…
比如上图中的200就是一个很常见的转态码, 表示访问成功, 对应的描述就是OK.
响应报头的基本格式和请求报头的格式基本一致, 类似于Content-Type , Content-Length等属性的含义也和请求中的含义一致.
响应正文的具体格式也是取决于Content-Type.

3.2 状态码
HTTP状态码负责表示客户端HTTP请求的返回结果, 标记服务器端的处理是否正常, 通知出现的错误等工作; 状态码的职责是当客户端向服务器端发送请求时, 描述返回的请求结果, 借助状态码, 用户可以知道服务器端是正常处理了请求, 还是出现了错误.
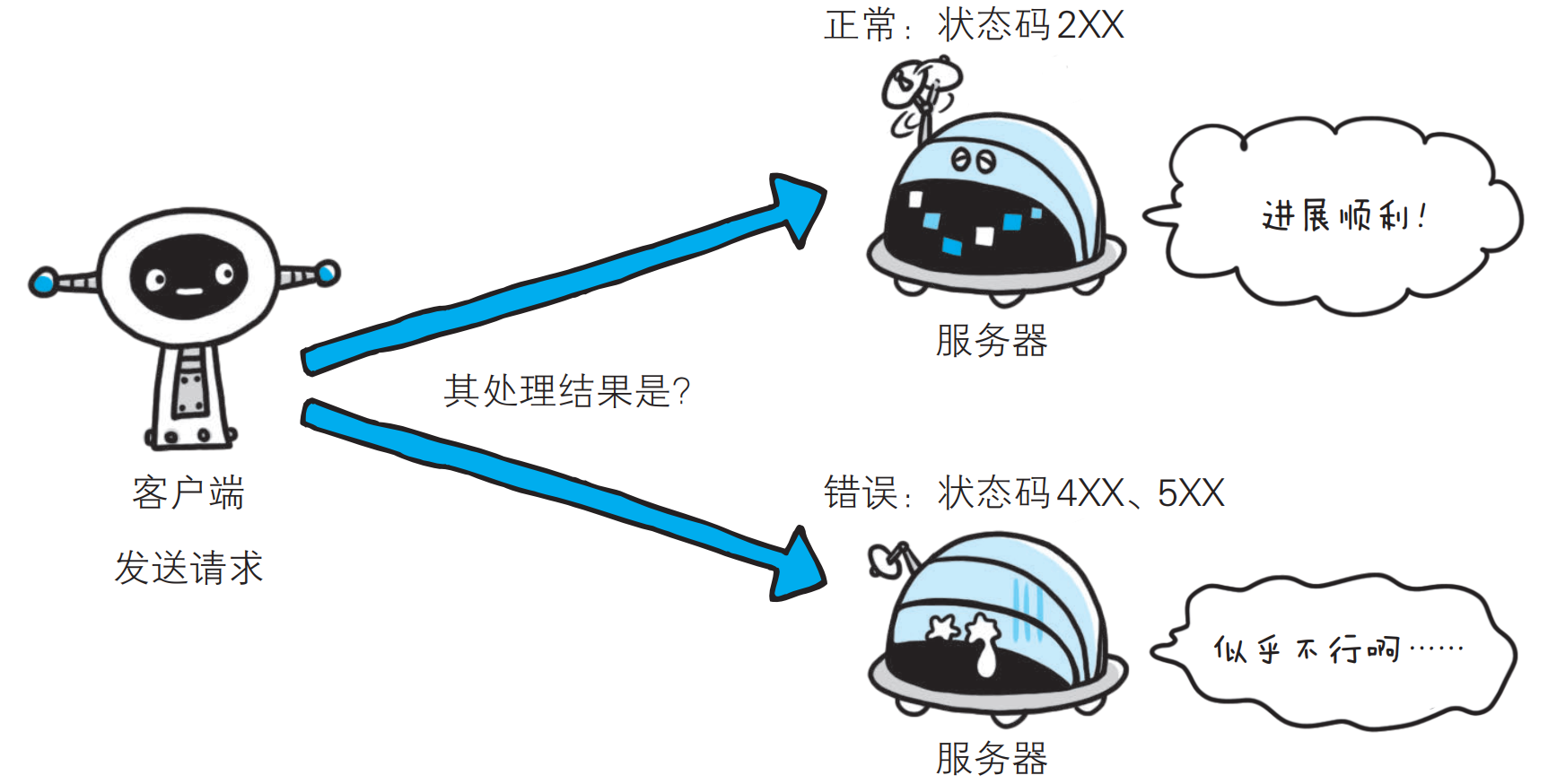
状态码如: 200 OK,以3位数字和原因短语组成.
状态码的类别如下:
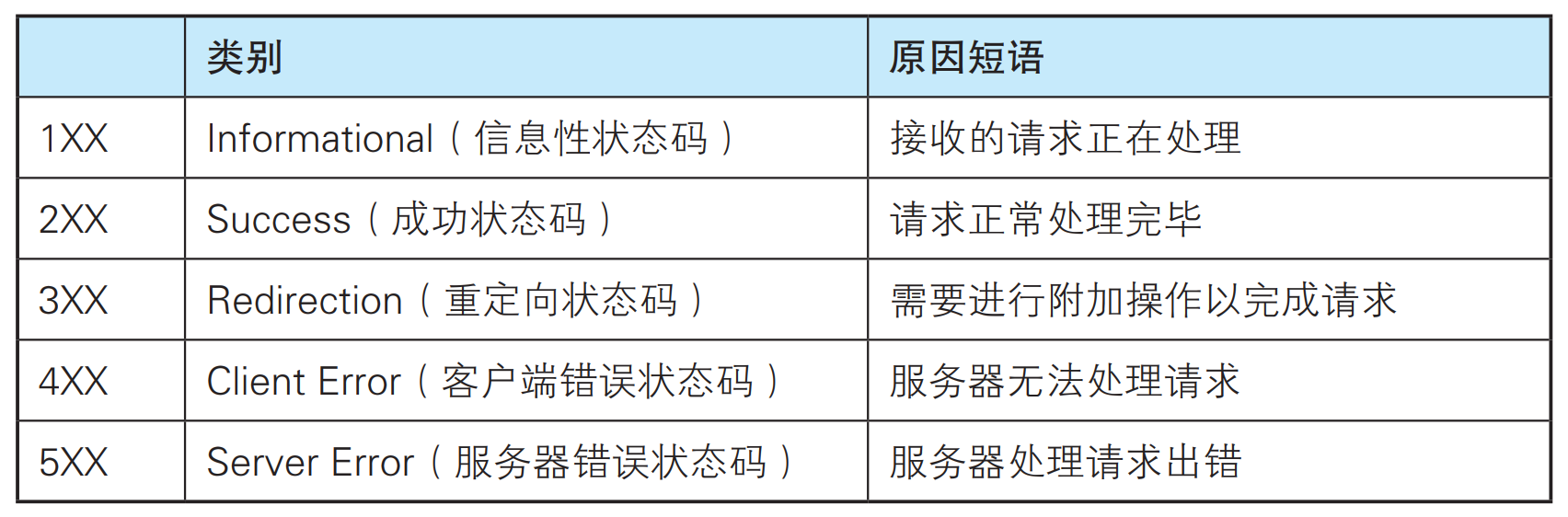
下面列出的是各个大类下的一些常见的状态码:
🍂2XX 成功: 2XX 的响应结果表明请求被正常处理了.
- 200 OK
表示从客户端发来的请求在服务器端被正常处理了.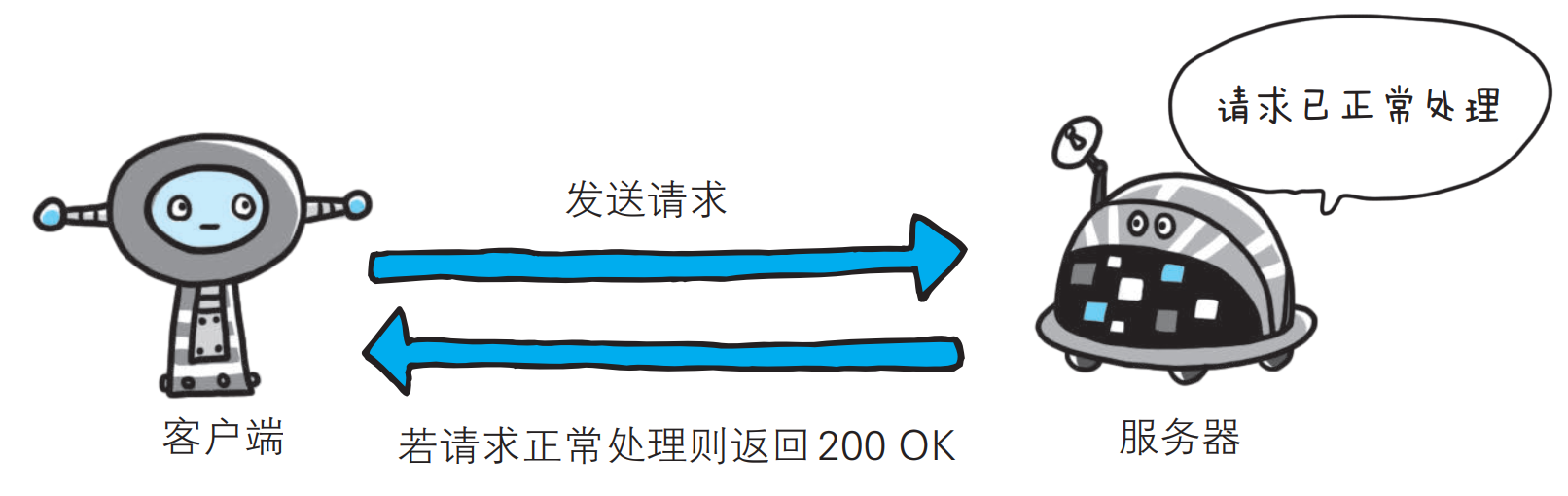
- 204 No Content
该状态码代表服务器接收的请求已成功处理, 但在返回的响应报文中不含实体的主体部分, 比如, 当从浏览器发出请求处理后, 返回204响应, 那么浏览器显示的页面不发生更新.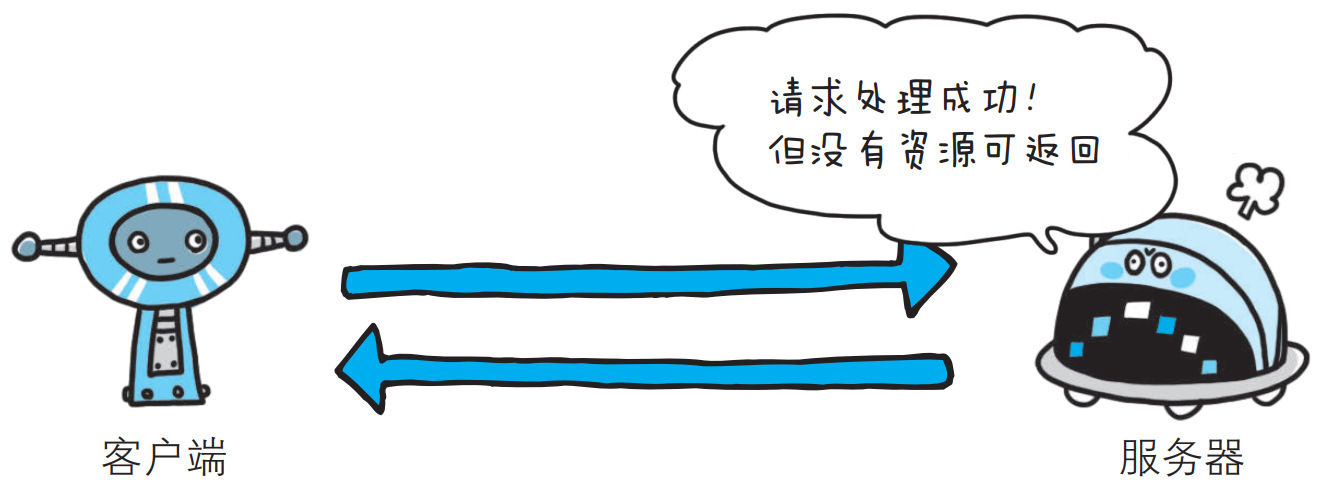
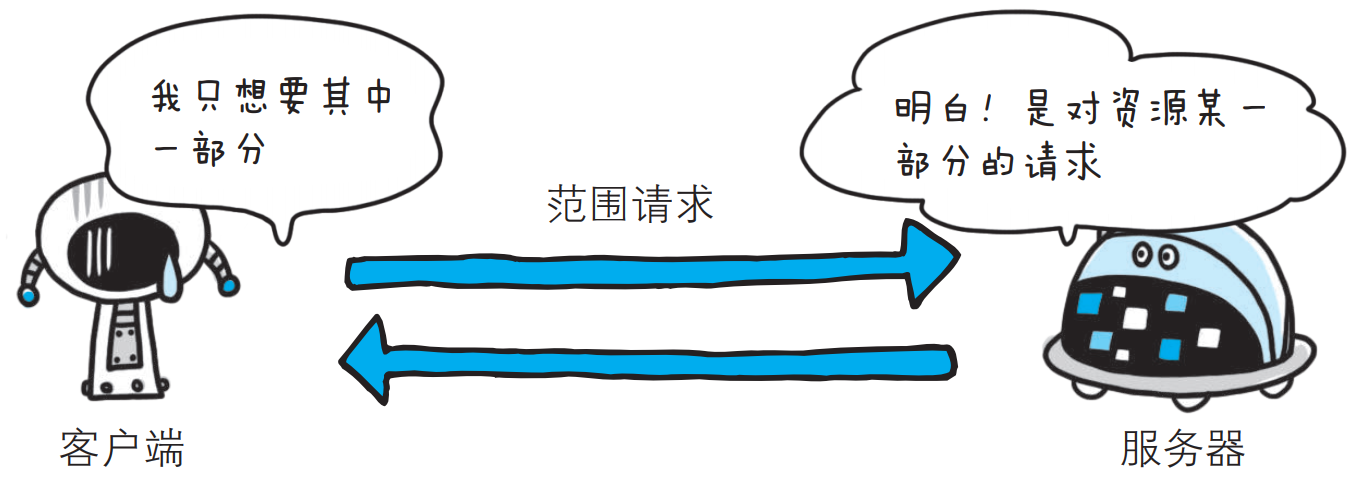
- 206 Partial Content
该状态码表示客户端进行了范围请求, 而服务器成功执行了这部分的GET请求, 响应报文中包含由Content-Range指定范围的实体内容.
🍂3XX 重定向: 3XX 响应结果表明浏览器需要执行某些特殊的处理以正确处理请求.
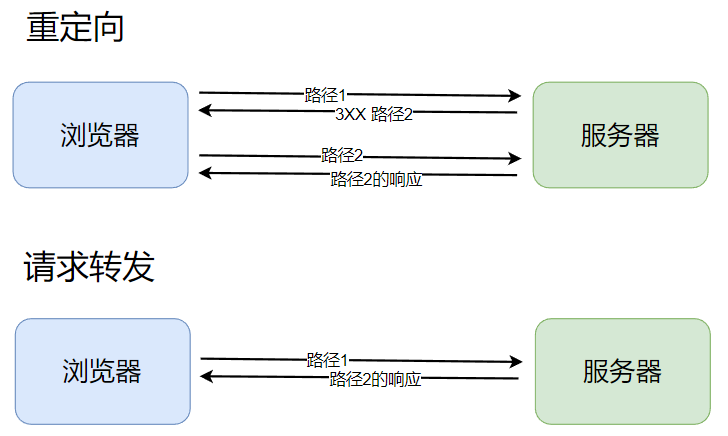
这里注意理解一下 “重定向”, 就相当于手机号码中的 “呼叫转移” 功能, 比如我本来的手机号是186-1234-5678, 后来换了个新号码135-1234-5678, 那么不需要让我的朋友知道新号码, 只要我去办理一个呼叫转移业务, 其他人拨打186-1234-5678, 就会自动转移到135-1234-5678上.
要注意区别重定向和请求转发, 重定向可定性到外部的资源(跳转到别的网站), 而请求转发只能在服务器内部的资源之间进行转发, 比重定向少了一次交互而更高效; 重定向是HTTP里提供的机制, 而请求转发是servlet/spring里面提供的机制.
- 301 Moved Permanently
永久性重定向, 该状态码表示请求的资源已被分配了新的URI, 以后应使用资源现在所指的URI; 也就是说, 如果已经把资源对应的URI保存为书签了, 这时应该按Location首部字段提示的URI重新保存.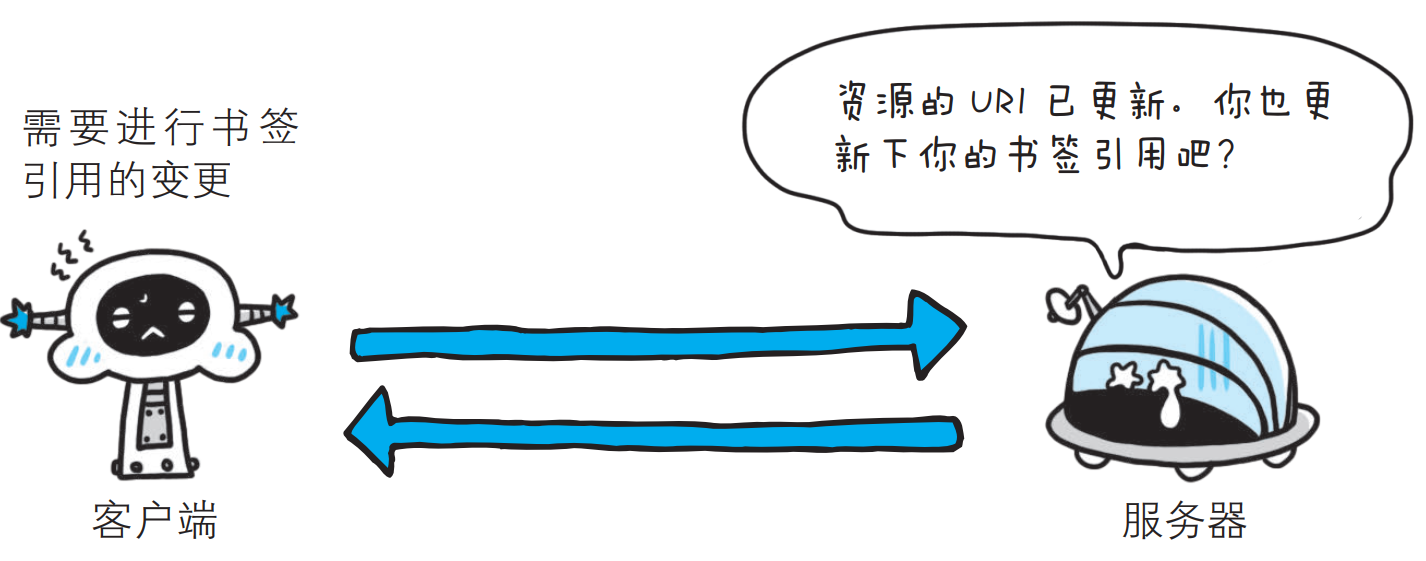
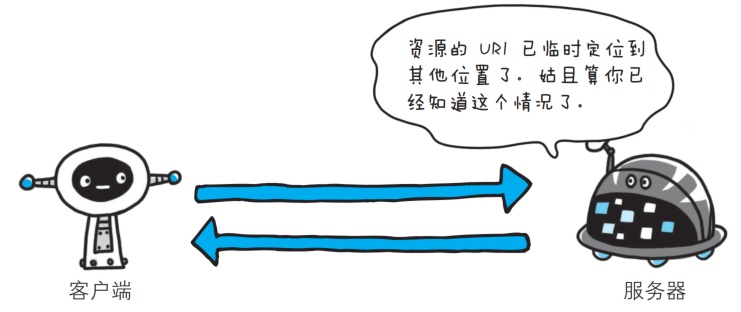
- 302 Found
临时性重定向, 该状态码表示请求的资源已被分配了新的URI, 希望用户(本次)能使用新的URI访问; 和301 Moved Permanently状态码相似, 但302状态码代表的资源不是被永久移动, 只是临时性质的.
在登陆页面中经常会见到302, 用于实现登陆成功后自动跳转到主页, 响应报文的header部分会包含一个Location字段, 表示要跳转到哪个页面.
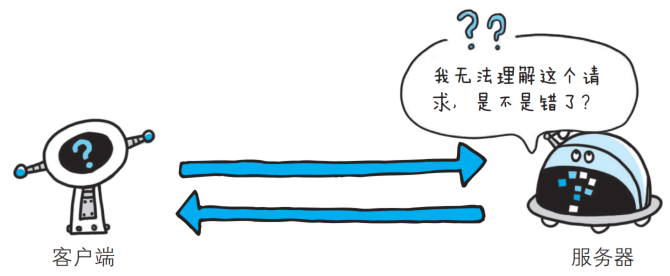
🍂4XX 客户端错误: 4XX 的响应结果表明客户端是发生错误的原因所在.
- 400 Bad Request
该状态码表示请求报文中存在语法错误, 当错误发生时, 需修改请求的内容后再次发送请求.
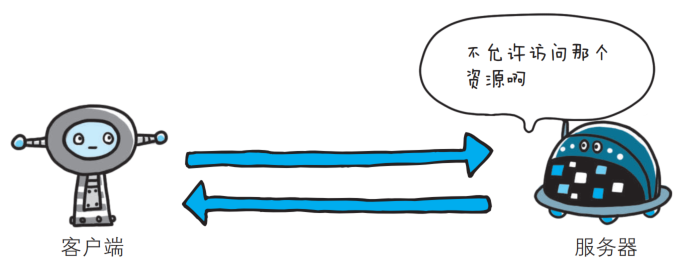
- 403 Forbidden
该状态码表明对请求资源的访问被服务器拒绝了, 有的页面通常需要用户具有一定的权限才能访问(登陆后才能访问), 如果用户没有登陆直接访问, 就容易见到403.
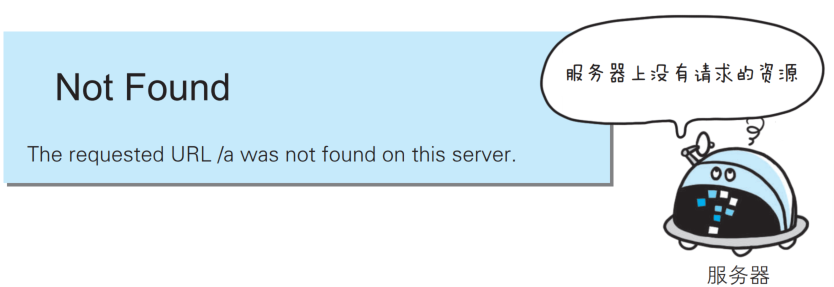
- 404 Not Found
该状态码表明服务器上无法找到请求的资源.
- 405 Method Not Allowed
表示方法不被允许, 即客户端(如浏览器)发送的请求使用了不被服务器支持的请求方法.
🍂5XX 服务器错误: 5XX 的响应结果表明服务器本身发生错误.
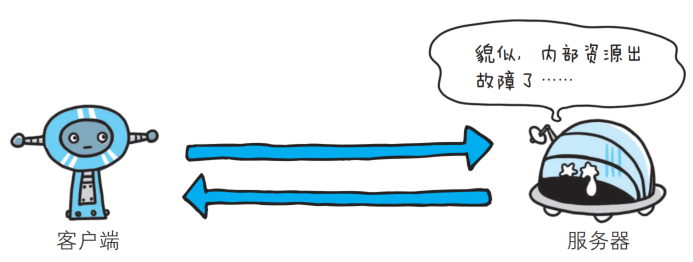
- 500 Internal Server Error
该状态码表明服务器端在执行请求时发生了错误, 一般是服务器的代码执行过程中遇到了一些特殊情况(服务器异常崩溃)会产生这个状态码.
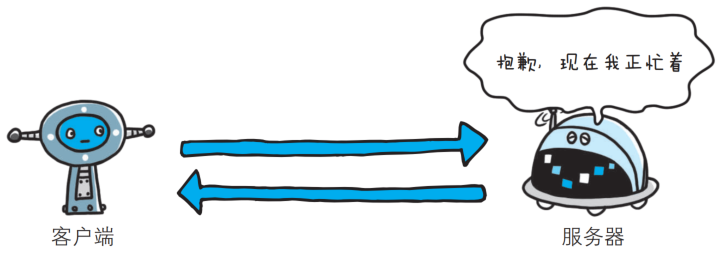
- 503 Service Unavailable
该状态码表明服务器暂时处于超负载或正在进行停机维护, 现在无法处理请求, 当服务器负载比较大的时候, 服务器处理单条请求的时候消耗的时间就会很长, 就可能会导致出现超时的情况, 比如这种情况在双十一等 “秒杀” 场景中容易出现.
- 504 Gateway Timeout
该状态码表示网关超时, 可以理解为服务器响应时间太久(长时间未响应), 客户端这边就不等服务器返回响应了, 就会出现这个状态码.
gateway是网关的意思, 也就是一个网络的入口/出口, 通常也用来代指一个机房的入口服务器.
最后, 有了上面了理解, HTTP协议中URL中的路径, URL中的query string, header中键值对, header中Cookie属性中的键值对, 还有body部分, 都是程序员可以自定义的.
相关文章:
计网之HTTP协议和Fiddler的使用
文章目录一. HTTP概述和fidder的使用1. 什么是HTTP2. 抓包工具fidder的使用2.1 注意事项2.2 fidder的使用二. HTTP协议格式1. HTTP请求格式1.1 基本格式1.2 认识URL1.3 方法2. 请求报头关键字段3. HTTP响应格式3.1 基本格式3.2 状态码一. HTTP概述和fidder的使用 1. 什么是HTT…...

sql性能优化:MS-SQL(SQL Server)跟踪日志信息结果列字段说明,MSSQL的列字段说明(column)
sql性能优化:MS-SQL(SQL Server)跟踪日志信息结果列字段说明,MSSQL的列字段说明(column) 参考: SQL:BatchCompleted 事件类 | Microsoft Learn SQL 跟踪 | Microsoft Learn sp_trace_setevent (…...

DNS主从复制
#前提准备:关闭SElinux 关闭防火墙 时间同步 #环境说明:Centos7 #ip地址:dns-master:10.0.0.100 dns-slave:10.0.0.103 web:10.0.0.101 主DNS服务配置 1.安装软件包: yum install bind -…...

常见的js加密/js解密方法
常见的js加密/js解密方法 当今互联网世界中,数据安全是至关重要的。为了保护用户的隐私和保密信息,开发人员必须采取适当的安全措施。在前端开发中,加密和解密技术是一种常见的数据安全措施,其中 JavaScript 是最常用的语言之一。…...

6 python函数
函数 在实现某个功能对应的代码的时候,如果将实现功能对应的函数放到函数中,那么下一次再需要这个功能的时候,就可以不用再写这个功能对应的代码,直接调用这个功能对应的函数。 1.什么是函数 函数就是实现某一特点功能的代码的封装…...

7.避免不必要的渲染
目录 1 组件更新机制 2 虚拟DOM配合Diff算法 3 减轻state 4 shouldComponentUpdate() 4.1 基本使用 4.2 使用参数 5 纯组件 5.1 基本使用 5.2 纯组件的比较方法 shallow compere 1 组件更新机制 当父组件重新渲染时,父组件的所有子组件也会重新…...

国产化大趋势下学习linux的必要性
由于国际上的一些国家的制裁和威胁。最近几年国产化大趋势慢慢的兴起,我们国产化硬件的需求越来越大。对国产操作系统的需求也越来越多,那么我们一直用的Windows系统为什么不用了呢?众所周知的原因,不管是最新的Windows11还是正值…...

浅谈虚树
问题引入 你是否遇到过下面这种问题: SDOI2011 消耗战 在一场战争中,战场由 nnn 个岛屿和 n−1n-1n−1 个桥梁组成,保证每两个岛屿间有且仅有一条路径可达。现在,我军已经侦查到敌军的总部在编号为1的岛屿,而且他们已…...

裸机条件下写一个基于时间片轮转的多任务并发程序
目录前言A. 使用RTOSB.裸机多任务并发前言 在学习各种MCU的时候,都是用在main函数里写一个while(1){/* 执行代码 */},这种方式只能一个函数运行完以后再运行另一个函数。 假设需求控制多个模块,如显示屏幕信息的同时控制电机,还要…...

RK3588 系统定制开关机动画
平台:ITX-3588J, ROC-RK3588S-PC 系统:Android12.0 作者:jpchen & zzz 一. 功能描述 定制自己的开机动画和关机动画 二. 功能实现 1.开启功能 修改device/rockchip/common/BoardConfig.mk文件 BOOT_SHUTDOWN_ANIMATION_RINGINGtrue2.…...

水文-编程命令快查手册
前言 脑子里面记不住一些命令,每次遇到都得查下。我经常在三个实体电脑,windows/uos/ubuntu不同系统上编程。 所以web版本的笔记查看起来方便点。这里报错下。 二级标题 cmake windows在cmake --build的时候,使用–config,指定…...
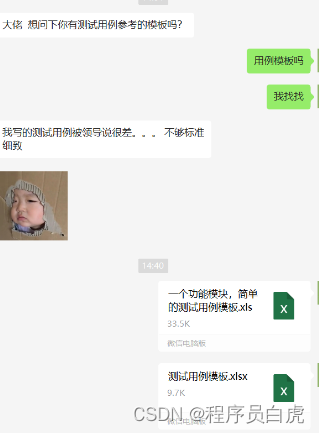
如何优雅编写测试用例
当你学会了如何设计测试用例之后,接下来便是开始用例的编写。 在设计阶段,更准确的说应该是识别测试点的过程,而编写阶段则是将测试点细化成一条条测试用例的过程,有了比较全的用例场景后,如何让别人更舒服、更方便、…...

[入门必看]数据结构2.3:线性表的链式表示
[入门必看]数据结构2.3:线性表的链式表示第二章 线性表2.3 线性表的链式表示知识总览2.3.1 单链表的定义2.3.2_1 单链表的插入删除2.3.2_2 单链表的查找2.3.2_3 单链表的建立2.3.3 双链表2.3.4 循环链表2.3.5 静态链表2.3.6 顺序表和链表的比较2.3.1 单链表的定义单…...
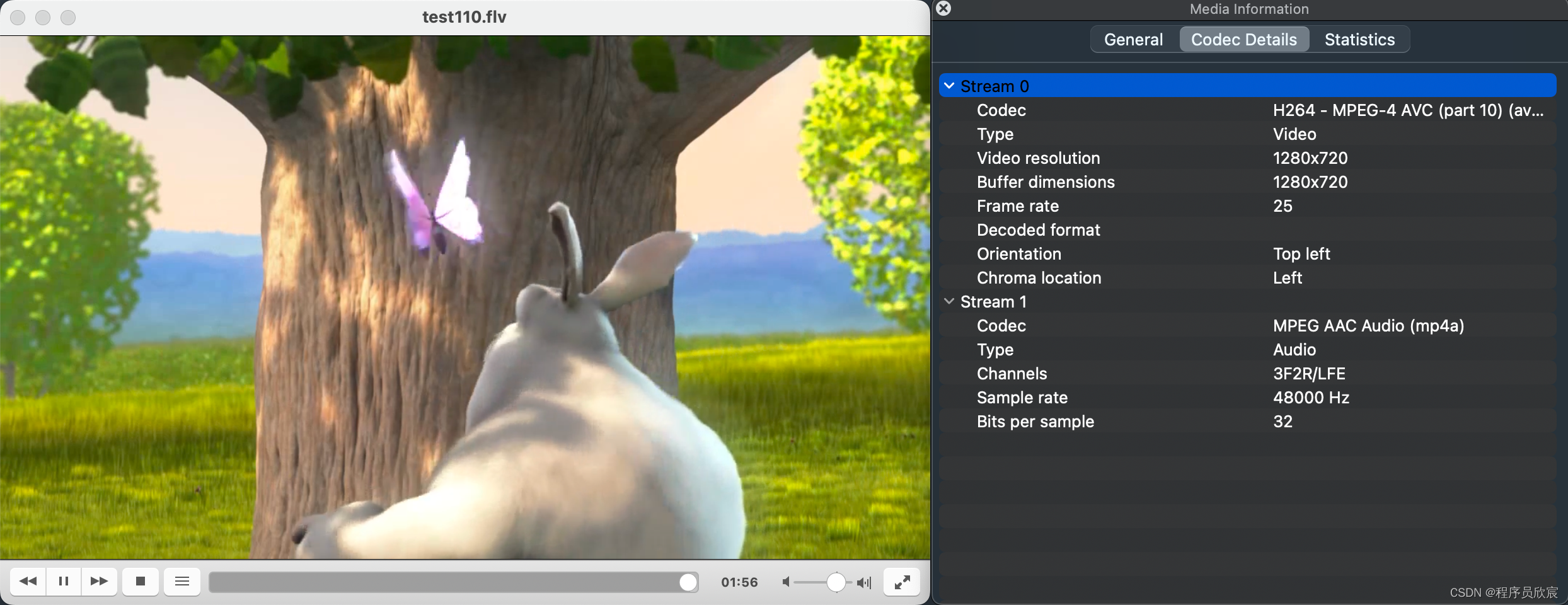
Golang流媒体实战之二:回源
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 今天的实战是流传输过程中的常见功能:回源如下图,lal(源站)和lal(拉流节点)代表两台电脑,上面都部署了lalVLC在…...

webgl——给场景添加光
文章目录前言光照理论介绍光照效果光源类型反射光颜色向场景中添加光向场景中添加环境光和点光源逐片元光照——更加逼真总结前言 在之前的学习中已经将三维物体添加到了场景中,但是并没有在场景中使用光,照可以使模型更具有立体感,本文主要…...

Vue实战【Vue项目开发时常见的几个错误】
目录🌟前言🌟安装超时(install timeout)🌟can’t not find ‘xxModule’ - 找不到某些依赖或者模块🌟data functions should return an object🌟给组件内的原生控件添加事件,不生效了🌟我在函数内用了this.…...

【多线程】常见的锁策略
✨个人主页:bit me👇 ✨当前专栏:Java EE初阶👇 ✨每日一语:老当益壮,宁移白首之心;穷且益坚,不坠青云之志。 目 录🏳️一. 乐观锁 vs 悲观锁🏴二. 普通的互斥…...
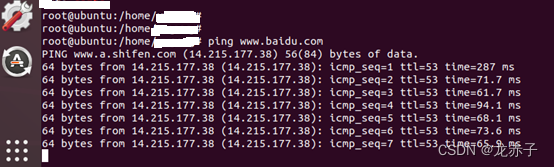
如何让虚拟机里的Ubuntu通过连接手机USB数据线上网
目录 一 前言 二 Windows联网方法 三 Ubuntu联网方法 一 前言 最近遇到了这样一个问题,有一台台式机,地插网口无法访问外网,周边也没有无线路由器,要访问外网,该如何做?进一步的,这台台式机…...
)
windows渗透(sam、system文件导出)
通过本地PC中渗透测试平台Kali对服务器场景Windows进行系统服务及版本扫描渗透测试,并将该操作显示结果中Telnet服务对应的端口号作为FLAG提交;通过本地PC中渗透测试平台Kali对服务器场景Windows进行系统服...
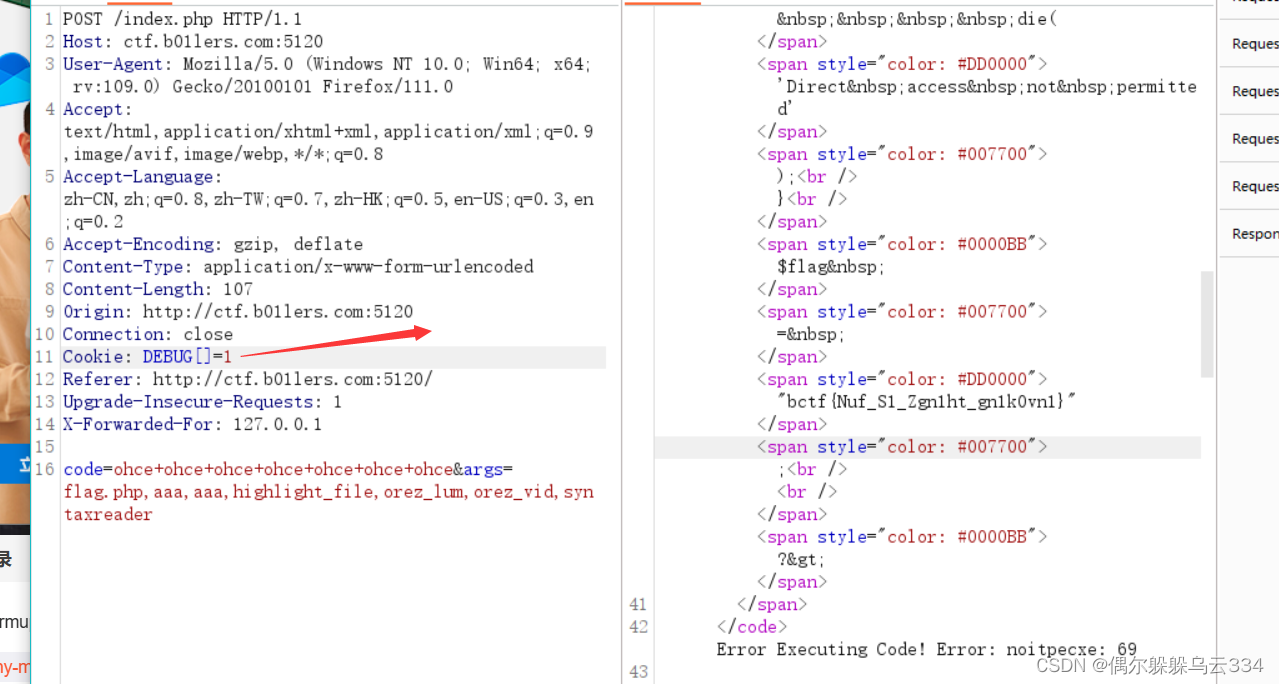
b01lers(php.galf)
目录 前文 正文 前文 <?phpclass A{public $codeNULL;public $argsNULL;public function __construct($code,$argsNULL){$this->code$code;$this->args$args;print_r("2333") ;} public function __invoke($code,$args){echo $code;print_r("执行inv…...

大规模矩阵SVD与GSVD计算方法【附代码】
✨ 长期致力于办公建筑设计、建筑能耗、光性能、热性能、modeFRONTIER、多目标优化、性能模拟、寒冷地区研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1ÿ…...

5步实现《鸣潮》游戏体验全面升级:WuWa-Mod模组高效部署指南
5步实现《鸣潮》游戏体验全面升级:WuWa-Mod模组高效部署指南 【免费下载链接】wuwa-mod Wuthering Waves pak mods 项目地址: https://gitcode.com/GitHub_Trending/wu/wuwa-mod 还在为《鸣潮》游戏中的技能冷却、体力限制和繁琐操作而烦恼吗?WuW…...

Spring Boot Actuator生产级监控与管理工具包
Spring Boot Actuator 是 Spring Boot 提供的生产级监控与管理工具包,帮你把应用“可观测化”。它提供了一系列内置的端点(Endpoint),用来查看应用的内部状态,比如健康情况、配置信息、内存指标等。你可以把它理解成为…...

vue3+vite+springboot路径配置:维护统一的baseUrl
提交表单:try…catch 捕获异常,如果校验失败,前台页面会有错误提示。 const submitForm async () > {try {await formRef.value.validate(); // 校验失败会抛出异常const submitData { ...formData };submitData.allowedSubmitTypes su…...

快马AI生成高性能JMeter压测脚本的核心原理与实战
1. 这不是“又一个AI写脚本工具”,而是压测工程师终于能睡整觉的转折点快马AI、JMeter、一键生成高性能测试脚本——这三个词凑在一起,很多老压测人第一反应是皱眉:又来个包装成“智能”的模板填充器?我亲手调过37版登录接口的Thi…...

STM32 SysTick中断:嵌入式系统时间管理的核心原理与实战应用
1. 项目概述:为什么SysTick中断是STM32开发的基石在STM32的嵌入式开发世界里,无论你是刚入门的新手,还是已经做过几个项目的熟手,有一个功能你几乎无法绕开,那就是SysTick——系统滴答定时器。你可能在HAL库的初始化代…...

RK3562核心板在工业物联网与边缘AI中的实战应用解析
1. 项目概述:为什么RK3562核心板值得关注?最近在为一个工业网关项目选型,市面上主流的ARM核心板看了个遍,从全志到瑞芯微,从低功耗到高性能。当拿到迅为电子这款基于RK3562的核心板规格书时,我的第一反应是…...

告别频繁中断!华大HC32F4A0串口DMA接收实战:用TIMEOUT中断替代STM32的IDLE
HC32F4A0串口DMA接收优化:TIMEOUT中断替代STM32 IDLE的工程实践 对于习惯了STM32开发环境的工程师而言,华大半导体的HC32F4A0系列微控制器在串口通信处理上存在一个显著差异——缺少IDLE中断机制。这一差异在RS485通信等需要帧完整性判断的场景中尤为突出…...
)
你的方差分析做对了吗?避开SPSS中ANOVA的5个经典坑(从数据准备到结果报告)
你的方差分析做对了吗?避开SPSS中ANOVA的5个经典坑(从数据准备到结果报告) 在科研论文和市场调研中,方差分析(ANOVA)是最常用的统计方法之一。许多研究者虽然掌握了SPSS的基本操作,却在结果报告…...

终极指南:如何用Continue实现AI驱动的代码检查与PR自动化审查
终极指南:如何用Continue实现AI驱动的代码检查与PR自动化审查 【免费下载链接】continue ⏩ Source-controlled AI checks, enforceable in CI. Powered by the open-source Continue CLI 项目地址: https://gitcode.com/GitHub_Trending/co/continue Contin…...