【机器学习第11章——特征选择与稀疏学习】
机器学习第11章——特征选择与稀疏学习
- 11.特征选择与稀疏学习
- 11.1子集搜索与评价
- 子集搜索
- 子集评价
- 11.2 过滤式选择
- 11.3 包裹式选择
- 11.4 嵌入式选择
- 11.5 稀疏表示与字典学习
- 稀疏表示
- 字典学习
- 11.6 压缩感知
11.特征选择与稀疏学习
11.1子集搜索与评价
-
特征:描述物体的属性
-
特征的分类
- 相关特征:对当前学习任务有用的属性
- 无关特征:与当前学习任务无关的属性
-
特征选择
- 从给定的特征集合中选出任务相关特征子集
- 必须确保不丢失重要特征
-
原因
- 减轻维度灾难:在少量属性上构建模型
- 降低学习难度:留下关键信息
如果按一般的思想,遍历特征的所有可能子集,会在计算上遭遇组合爆炸,所以可行的方法是子集搜索和子集评价
- 产生初始候选子集
- 评价候选子集的好坏
- 基于评价结果产生下一个候选子集,对其继续进行评价
子集搜索
用贪心策略选择包含重要信息的特征子集
- 前向搜索:最优子集初始为空集,逐渐增加相关特征

- 后向搜索:从完整的特征集合开始,逐渐减少特征
- 双向搜索:每一轮逐渐增加相关特征,同时减少无关特征
但这样的子集搜索会可能会导致失去全局最优解的问题,这是贪心算法不可避免的
子集评价
-
特征子集A确定了对数据集D的一个划分(每个划分区域对应着特征子集A的某种取值)
{ D 1 , D 2 , . . . , D V } \{D^1,D^2,...,D^V\} {D1,D2,...,DV} -
样本标记Y对应着对数据集的真实划分
-
通过估算这两个划分的差异,就能对特征子集进行评价;与样本标记对应的划分的差异越小,则说明当前特征子集越好
-
信息熵是判断这种差异的一种方式(熵越大,说明数据越混乱)
E n t ( D ) = − ∑ i = 1 ∣ y ∣ p k log 2 p k Ent(D)=-\sum_{i=1}^{|y|}p_k\log_2p_k Ent(D)=−i=1∑∣y∣pklog2pk -
信息增益
G a i n ( A ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(A)=Ent(D)-\sum_{v=1}^V\frac{|D^v|}{|D|}Ent(D^v) Gain(A)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
信息增益越大,说明这次的划分使数据变得比较规整是有帮助的(具体定义和例子见https://blog.csdn.net/m0_53694086/article/details/140758015)
将特征子集搜索机制与子集评价机制相结合,即可得到特征选择方法:过滤式、包裹式、嵌入式
11.2 过滤式选择
先对数据集进行特征选择,然后再训练学习器,特征选择过程与后续学习器无关。先用特征选择过程过滤原始数据,再用过滤后的特征来训练模型。
-
Relief方法
- 是一种特征权重算法,根据各个特征和类别的相关性赋予特征不同的权重(相关统计量),权重小于某个阈值的特征将被移除。
- 特征和类别的相关性是基于特征对近距离样本的区分能力。
- 关键在于确定权重(相关统计量)
-
算法实现
-
从训练集D中随机选择一个样本 x i x_i xi,然后
-
从和 x i x_i xi同类的样本中寻找最近邻样本,称为猜中近邻
-
从和 x i x_i xi不同类的样本中寻找最近邻样本,称为猜错近邻
-
-
然后根据以下规则更新每个特征的权重
-
如果 x i x_i xi和猜中近邻在某个特征上的距离小于 x i x_i xi和猜错近邻上的距离,则说明该特征对区分同类和不同类的最近邻是有益的,则增加该特征的权重;
-
反之,如果 x i x_i xi和猜中近邻在某个特征的距离大于 x i x_i xi和猜错近邻上的距离,说明该特征对区分同类和不同类的最近邻起负面作用,则降低该特征的权重。
-
-
以上过程重复m次,最后得到各特征的平均权重。
-
特征的权重越大,表示该特征的分类能力越强,反之,表示该特征分类能力越弱。
-
Relief方法的时间开销随采样次数以及原始特征数线性增长,运行效率很高。
-
记
猜中近邻 : x i , n h , 猜错近邻 : x i , n m 猜中近邻:x_{i,nh},猜错近邻:x_{i,nm} 猜中近邻:xi,nh,猜错近邻:xi,nm
对第j个特征(属性)的相关统计量为
δ j = ∑ i { − d i f f ( x i j , x i , n h j ) 2 + d i f f ( x i j , x i , n m j ) 2 } d i f f ( 表示两点属性值的距离的差异 ) = { 两样本属性值相同记为 0 , 否则记为 1 , 属性值为离散型 两样本属性值间的距离 , 属性值为连续型 \delta^j=\sum_i\{-diff(x^j_i,x_{i,nh}^j)^2+diff(x^j_i,x_{i,nm}^j)^2\}\\ diff(表示两点属性值的距离的差异)= \begin{cases} 两样本属性值相同记为0,否则记为1, & 属性值为离散型 \\ 两样本属性值间的距离, & 属性值为连续型 \\ \end{cases} δj=i∑{−diff(xij,xi,nhj)2+diff(xij,xi,nmj)2}diff(表示两点属性值的距离的差异)={两样本属性值相同记为0,否则记为1,两样本属性值间的距离,属性值为离散型属性值为连续型
δ j > 0 说明第 j 个特征有益,加一定的权重 δ j < 0 说明第 j 个特征无益,减一定的权重 \delta^j>0说明第j个特征有益,加一定的权重\\ \delta^j<0说明第j个特征无益,减一定的权重 δj>0说明第j个特征有益,加一定的权重δj<0说明第j个特征无益,减一定的权重
-
Relief是对二分类问题设计的,所以在后来在多分类问题中进行了调整
-
每次从训练样本集中随机取出一个样本 x i x_i xi
-
从和 x i x_i xi同类的样本集中找出 x i x_i xi的1个猜中近邻样本
-
从每个 x i x_i xi的不同类的样本集中均找出k-1个猜错近邻样本
-
然后更新每个特征的权重
δ j = ∑ i − d i f f ( x i j , x i , n h j ) 2 + ∑ l ≠ k ( p l × d i f f ( x i j , x i , n m j ) 2 ) p l 为第 l 类样本在数据集 D 中所占的比例 \delta^j=\sum_i-diff(x^j_i,x_{i,nh}^j)^2+\sum_{l\neq k}\big(p_l\times diff(x^j_i,x_{i,nm}^j)^2\big)\\ p_l为第l类样本在数据集D中所占的比例 δj=i∑−diff(xij,xi,nhj)2+l=k∑(pl×diff(xij,xi,nmj)2)pl为第l类样本在数据集D中所占的比例
-
11.3 包裹式选择
直接把最终将要使用的学习器的性能作为特征子集的评价准则
- 包裹式特征选择的目的就是为给定学习器选择最有利于其性能、“量身定做”的特征子集
- 包裹式选择方法直接针对给定学习器进行优化,因此从最终学习器性能来看,包裹式特征选择比过滤式特征选择更好
- 包裹式特征选择过程中需多次训练学习器,计算开销通常比过滤式特征选择大得多
- LVW是一个典型的包裹式特征选择方法,LVW在拉斯维加斯方法框架下使用随机策略来进行子集搜索,并以最终分类器的误差作为特征子集评价准则
- LVW基本步骤
- 在循环的每一轮随机产生一个特征子集
- 在随机产生的特征子集上通过交叉验证推断当前特征子集的误差
- 进行多次循环,在多个随机产生的特征子集中选择误差最小的特征子集作为最终解
- 采用随机策略搜索特征子集,而每次特征子集的评价都需要训练学习器,开销很大。
11.4 嵌入式选择
过滤式和包裹式的特征选择过程与学习器训练过程有明显的分别,而嵌入式将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,在学习器训练过程中自动地进行特征选择
-
算法实现
-
考虑最简单的线性回归模型,以平方误差为损失函数,并引入
L 2 范数正则化项 L_2范数正则化项 L2范数正则化项
防止过拟合,则有
min w ∑ i = 1 m ( y i − w T x i ) 2 + λ ∣ ∣ w ∣ ∣ 2 2 \min_w\sum_{i=1}^m(y_i-w^Tx_i)^2+\lambda||w||^2_2 wmini=1∑m(yi−wTxi)2+λ∣∣w∣∣22 -
将
L 2 范数替换为 L 1 范数 L_2范数替换为L_1范数 L2范数替换为L1范数
则有
min w ∑ i = 1 m ( y i − w T x i ) 2 + λ ∣ ∣ w ∣ ∣ 1 \min_w\sum_{i=1}^m(y_i-w^Tx_i)^2+\lambda||w||_1 wmini=1∑m(yi−wTxi)2+λ∣∣w∣∣1 -
L 2 L_2 L2范数和 L 1 L_1 L1范数均有助于降低过拟合风险,但是 L 1 L_1 L1范数易获得稀疏解,即w会有更少的非零分量,是一种嵌入式特征选择方法
-
L 1 L_1 L1正则化问题的求解可使用近端梯度下降算法
-
11.5 稀疏表示与字典学习
稀疏表示
- 稀疏表示
- 将数据集D考虑成一个矩阵,每行对应一个样本,每列对应一个特征。特征选择所考虑的问题是特征具有稀疏性,即矩阵中的许多列与当前学习任务无关,通过特征选择去除这些列,则学习器训练过程仅需在较小的矩阵上进行,学习任务的难度可能有所降低,设计的计算和存储开销会减少,学得模型的可解释性也会提高。
- 矩阵中有很多零元素,且非整行整列出现。
- 稀疏表达的优势:
- 数据具有稀疏性,使得大多数问题变得线性可分
- 稀疏矩阵已有很多高效的存储方法
字典学习
-
为普通稠密表达的样本找到合适的字典,将样本转化为稀疏表示,这—过程称为字典学习
-
采用变量交替优化策略求解
字典 D 和稀疏向量 α i 字典D和稀疏向量\alpha_i 字典D和稀疏向量αi-
固定字典D,为每个样本 x i x_i xi找到对应的 α i \alpha_i αi
a r g min α ∣ ∣ x − D α ∣ ∣ 2 2 + λ ∣ ∣ α ∣ ∣ 1 arg \min_{\alpha}||x-D\alpha||^2_2+\lambda||\alpha||_1 argαmin∣∣x−Dα∣∣22+λ∣∣α∣∣1 -
以 α i \alpha_i αi为初值,更新字典D
min D ∣ ∣ x − D α ∣ ∣ F 2 \min_{D}||x-D\alpha||^2_F Dmin∣∣x−Dα∣∣F2
-
-
常用的求解方法有K-SVD
- 核心思想:K-SVD最大的不同在字典更新这一步,K-SVD对误差矩阵 E i E_i Ei进行奇异值分解,取得最大奇异值对应的正交向量更新字典中的一个原子,同时并更新其对应的稀疏系数,直到所有的原子更新完毕,重复迭代几次即可得到优化的字典和稀疏系数。
∣ ∣ Y − D X ∣ ∣ F 2 = ∣ ∣ Y − ∑ j = 1 K d j X F j ∣ ∣ F 2 = ∣ ∣ ( Y − ∑ j ≠ k d j X T j ) − f k X T k ∣ ∣ F 2 = ∣ ∣ E k − d k X T k ∣ ∣ F 2 ||Y-DX||^2_F=\bigg|\bigg|Y-\sum_{j=1}^Kd_jX_F^j\bigg|\bigg|^2_F\\ =\bigg|\bigg|\bigg(Y-\sum_{j\neq k}d_jX_T^j\bigg)-f_kX^k_T\bigg|\bigg|^2_F\\ =||E_k-d_kX_T^k||^2_F ∣∣Y−DX∣∣F2= Y−j=1∑KdjXFj F2= (Y−j=k∑djXTj)−fkXTk F2=∣∣Ek−dkXTk∣∣F2
11.6 压缩感知
“压缩感知”是直接感知压缩后的信息,其目的是从尽量少的数据中提取尽量多的信息。压缩理论证明了如果信号在正交空间具有稀疏性(即可压缩性),就能以远低于奈奎斯特采样频率的速率采样该信号,最后通过优化算法高概率重建出原信号。其基本思想是一种基于稀疏表示的信号压缩和重构技术,也可以称为压缩采样或稀疏采样。
压缩感知引起了信号采样及相应重构方式的本质性变化,即:数据的采样和压缩是以低速率同步进行的,这对于降低信息的采样成本和资源都具有重要意又。
由于压缩感知技术突破了传统香农采样定理的限制,其理论研究已经成为应用数学、数字信号处理、数字图像处理等领域的最热门的方向之一,同时其应用领域涉及到图像压缩、医学图像处理、生物信息处理、高光谱影像、地球物理数据分析、压缩雷达、遥感和计算机图像处理等诸多方面。
-
长度为M的离散信号x,用远小于奈奎斯特采样定理的要求的采样率采样得到长度为N的采样后信号y。一般情况下,N<<M,不能利用y还原x,但是
- 若存在某个线性变换Ψ,使得x = Ψα,即可以近乎完美地恢复x
- 压缩感知关注的问题是如何利用信号本身具有的稀疏性,从部分观测样本y中恢复原始信号x。
- 压缩感知需要解决的三个问题:感知测量(信号的稀疏表示),设计观测矩阵ϕ,信号重构技术。
-
核心问题
-
感知测量
- 信号的最佳稀疏域表示是压缩感知理论应用的基础和前提,只有选择合适的基Ψ表示信号才能保证信号的稀疏度,从而保证信号的恢复精度。
- 涉及到前面介绍的稀疏编码和字典学习。
-
设计观测矩阵ϕ
- 观测矩阵ϕ是压缩感知理论采样的实现部分。通过观测矩阵控制的采样使得目标信号x在采样过程中被压缩,同时保证目标信号所含有效信息不丢失,能够由压缩采样值还原出目标信号。
- 如何设计一个平稳的、与变换基不相关、满足有限等距(RIP,即从观测矩阵中抽取的每M个列向量构成的矩阵是非奇异的)性质的观测矩阵ϕ,同时保证稀疏向量从N维降维到M维时重要信息不遭破坏(即信号低速采样问题),是压缩感知的另一个重要研究丙容。
- 目前常用的测量矩阵主要有:高斯随机矩阵、伯努利随机矩阵(二值随机矩阵)、局部哈达玛矩阵、局部傅里叶矩阵、Chirp序列、Altop序列、托普利兹矩阵等。
-
信号重构技术
-
重构算法是从采样值求解最优化问题寻找到目标信号最优解。
-
在压缩感知理论中,由于观测值M远小于信号x的长度N,因此信号重构的核心在于如何求解欠定方程组
y = Φ Ψ x y=\Phi\Psi x y=ΦΨx
如果信号是稀疏或可压缩的,且观测矩阵ϕ具有有限等距RIP性质,那么从M个观测值中精确恢复信号x是可能的。 -
信号重构的常用方法:
-
l 0 l_0 l0 范数非凸优化问题:贪婪算法,如匹配追踪、正交匹配追踪算法等
-
l 1 l_1 l1范数凸优化问题:线性规划方法进行求解,如基追踪、梯度投影稀疏重构算法
-
l p l_p lp范数非凸优化问题:通过p范数优化问题求解来找到信号的“最优”逼近
-
Bayesian方法:基思想是首先合理假设未知的信号系数具有某种稀疏性的先验概率分布,然后根据压缩观测信号对未知系数的后验概率分布进行推理。该类方法还能够估计出重构问题的解的误差范围,这一优点是传统优化方法所不具备的
-
-
-
相关文章:
【机器学习第11章——特征选择与稀疏学习】
机器学习第11章——特征选择与稀疏学习 11.特征选择与稀疏学习11.1子集搜索与评价子集搜索子集评价 11.2 过滤式选择11.3 包裹式选择11.4 嵌入式选择11.5 稀疏表示与字典学习稀疏表示字典学习 11.6 压缩感知 11.特征选择与稀疏学习 11.1子集搜索与评价 特征:描述物…...

LeetCode-day43-3137. K 周期字符串需要的最少操作次数
LeetCode-day43-3137. K 周期字符串需要的最少操作次数 题目描述示例示例1:示例2: 思路代码 题目描述 给你一个长度为 n 的字符串 word 和一个整数 k ,其中 k 是 n 的因数。 在一次操作中,你可以选择任意两个下标 i 和 j&#x…...

基于springboot的智能家居系统
TOC springboot198基于springboot的智能家居系统 研究背景与现状 时代的进步使人们的生活实现了部分自动化,由最初的全手动办公已转向手动自动相结合的方式。比如各种办公系统、智能电子电器的出现,都为人们生活的享受提供帮助。采用新型的自动化方式…...
(七))
【从问题中去学习k8s】k8s中的常见面试题(夯实理论基础)(七)
本站以分享各种运维经验和运维所需要的技能为主 《python零基础入门》:python零基础入门学习 《python运维脚本》: python运维脚本实践 《shell》:shell学习 《terraform》持续更新中:terraform_Aws学习零基础入门到最佳实战 《k8…...

C:每日一练:单身狗(2.0版本)
前言: 今天在刷题的时候突然看到一道题,疑似一位故题。仔细一看,欸!这不是就是单身狗的升级版吗?我想那必须再安排一篇,不过由于本篇文章与上一篇单身狗文章所涉及的知识点基本相同,所以还请大…...

打破接口壁垒:适配器模式让系统无缝对接
适配器模式(Adapter Pattern)是一种结构型设计模式,它允许不兼容的接口之间协同工作。主要用途是将一个类的接口转换成客户期望的另一个接口,使得原本接口不兼容的对象可以一起工作。 一、适配器模式的组成 目标接口(…...

U-Boot 命令使用
U-Boot 是一种常用的引导加载程序,用于引导嵌入式系统。它提供了一系列命令以进行系统配置、引导操作和调试。 以下是一些常见的 U-Boot 命令及其用法: bootm:从指定的内存地址启动操作系统映像。 用法:bootm [addr] bootz&…...
谷歌的高级指令有哪些
今天会分享一些组合用法,这样就能节省许多时间可以放在跟进客户上面(本文只介绍谷歌的搜索指令,并无推广) part one 谷歌常用的搜索引擎指令: 1、Inurl,在网址中 2、Intext,在网页内容中 3、…...

Redis操作--RedisTemplate(一)介绍
一、介绍 1、简介 RedisTemplate 是 Spring Data Redis 提供的一个高级抽象,由 Spring 官方提供的方便操作 Redis 数据库的一个工具类,支持模板设计模式,使得操作 Redis 更加符合 Spring 的编程模型。还支持序列化机制,可以处理…...

GitLab环境搭建
GitLab环境搭建 一、环境搭建 1、更新系统软件包: sudo yum update2、安装docker sudo yum install -y yum-utils device-mapper-persistent-data lvm2 sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo yum install do…...

Socket编程TCP 基础
一.什么是Socket(套接字) 定义:就是对网络中不同主机上的应用进程之间进行双向通信的端点的抽象。一个套接字就是网络上进程通信的一端,提供了应用层进程利用网络协议交换数据的机制。从所处的地位来讲,套接字上联应用进程&#x…...

JAVA中的Iterator与ListIterator
Java中的Iterator类是Java集合框架中的一个重要接口,它用于遍历集合中的元素。Iterator提供了三个基本操作:检查是否有下一个元素、获取下一个元素以及移除元素。下面将详细介绍Iterator类及其使用方法,并提供相应的代码例子和中文注释。 一、…...

高校疫情防控web系统pf
TOC springboot365高校疫情防控web系统pf 第1章 绪论 1.1 课题背景 互联网发展至今,无论是其理论还是技术都已经成熟,而且它广泛参与在社会中的方方面面。它让信息都可以通过网络传播,搭配信息管理工具可以很好地为人们提供服务。所以各行…...

复现nnUNet2并跑通自定义数据
复现nnUNet2并跑通自定义数据 1. 配置环境2. 处理数据集2.1 创建文件夹2.2 数据集格式转换2.3 数据集预处理 3. 训练4. 改进模型4.1 概要4.2 加注意力模块 1. 配置环境 stage1:创建python环境,这里建议python3.10 conda create --n nnunet python3.10 …...

Educational Codeforces Round 169 (Rated for Div. 2)(ABCDE)
A. Closest Point 签到 #define _rep(i,a,b) for(int i(a);i<(b);i) int n,m; int q[N]; void solve() {cin>>n;_rep(i,1,n)cin>>q[i];if(n!2)cout<<"NO\n";else if(abs(q[1]-q[2])!1)cout<<"YES\n";else cout<<"…...

成为Python砖家(2): str 最常用的8大方法
str 类最常用的8个方法 str.lower()str.upper()str.split(sepNone, maxsplit-1)str.count(sub[, start[, end]])str.replace(old, new[, count])str.center(width[, fillchar])str.strip([chars])str.join(iterable) 查询方法的文档 根据 成为Python砖家(1): 在本地查询Pyth…...
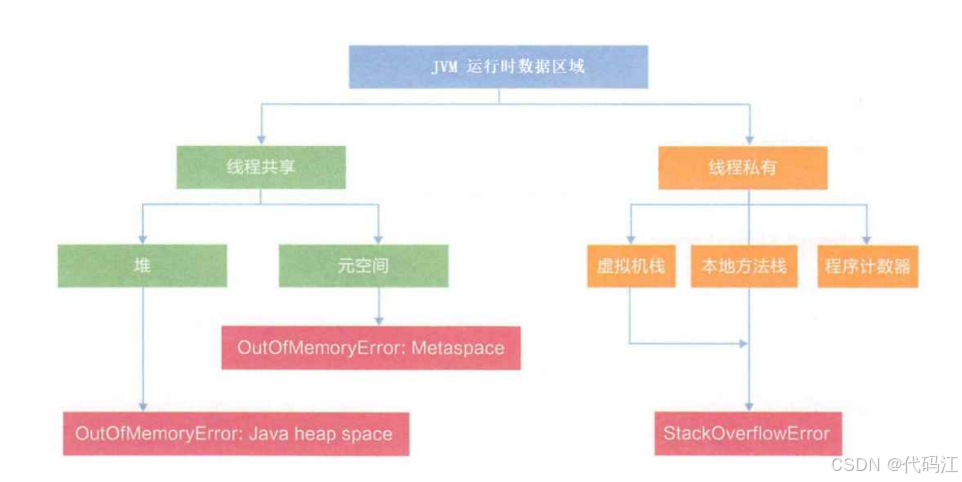
深入理解JVM运行时数据区(内存布局 )5大部分 | 异常讨论
前言: JVM运行时数据区(内存布局)是Java程序执行时用于存储各种数据的内存区域。这些区域在JVM启动时被创建,并在JVM关闭时销毁。它们的布局和管理方式对Java程序的性能和稳定性有着重要影响。 目录 一、由以下5大部分组成 1.…...

JAVA根据表名获取Oracle表结构信息
响应实体封装 import lombok.AllArgsConstructor; import lombok.Builder; import lombok.Data; import lombok.NoArgsConstructor;/*** author CQY* version 1.0* date 2024/8/15 16:33**/ Data NoArgsConstructor AllArgsConstructor Builder public class OracleTableInfo …...

网络性能优化
网络性能优化是确保网络稳定性、速度和可靠性的关键步骤。优化过程通常包括诊断问题、识别瓶颈以及实施具体的解决方案。以下是关于如何进行网络性能优化的详细指南: 一、问题诊断 网络性能监控 网络流量分析工具:使用Wireshark、NetFlow、Ntop等工具监…...

[C++String]接口解读,深拷贝和浅拷贝,string的模拟实现
💖💖💖欢迎来到我的博客,我是anmory💖💖💖 又和大家见面了 欢迎来到C探索系列 作为一个程序员你不能不掌握的知识 先来自我推荐一波 个人网站欢迎访问以及捐款 推荐阅读 如何低成本搭建个人网站…...

AMD Ryzen嵌入式处理器在COM Express模块上的高性能应用与设计实践
1. 项目概述:当COM Express遇上AMD Ryzen,一次嵌入式设计的性能跃迁 在嵌入式系统设计领域,COM Express(Computer-On-Module Express)模块因其标准化、高集成度和易于扩展的特性,一直是构建紧凑型、高性能嵌…...

MuseTalk 唇语同步配置指南:解决3大常见问题,从入门到精通
MuseTalk 唇语同步配置指南:解决3大常见问题,从入门到精通 【免费下载链接】MuseTalk MuseTalk: Real-Time High Quality Lip Synchorization with Latent Space Inpainting 项目地址: https://gitcode.com/gh_mirrors/mu/MuseTalk MuseTalk 是一…...

JoyCon-Driver:让Switch手柄在Windows上重获新生的完整方案
JoyCon-Driver:让Switch手柄在Windows上重获新生的完整方案 【免费下载链接】JoyCon-Driver A vJoy feeder for the Nintendo Switch JoyCons and Pro Controller 项目地址: https://gitcode.com/gh_mirrors/jo/JoyCon-Driver 你是否曾经想过,让闲…...

明日方舟游戏资源库:一站式高清素材解决方案
明日方舟游戏资源库:一站式高清素材解决方案 【免费下载链接】ArknightsGameResource 明日方舟客户端素材 项目地址: https://gitcode.com/gh_mirrors/ar/ArknightsGameResource 还在为创作明日方舟同人内容却找不到高质量素材而烦恼吗?想要开发明…...

ComfyUI-Inpaint-CropAndStitch:如何用局部修复技术将AI图像处理速度提升100倍
ComfyUI-Inpaint-CropAndStitch:如何用局部修复技术将AI图像处理速度提升100倍 【免费下载链接】ComfyUI-Inpaint-CropAndStitch ComfyUI nodes to crop before sampling and stitch back after sampling that speed up inpainting 项目地址: https://gitcode.com…...

戴尔笔记本风扇终极管理指南:3种模式轻松掌控散热与噪音
戴尔笔记本风扇终极管理指南:3种模式轻松掌控散热与噪音 【免费下载链接】DellFanManagement A suite of tools for managing the fans in many Dell laptops. 项目地址: https://gitcode.com/gh_mirrors/de/DellFanManagement 还在为戴尔笔记本风扇的噪音而…...

Verilog数据类型详解:从wire/reg到memory的硬件映射与工程实践
1. 从电路到代码:理解Verilog数据类型的本质刚接触Verilog的时候,很多人会把它当成一门编程语言来学,上来就琢磨reg和wire怎么赋值,结果越学越迷糊。我刚开始也踩过这个坑,后来才明白,Verilog的本质是硬件描…...

告别Ping不通!STM32H7以太网LWIP裸机移植实战:LAN8720硬件连接与软件调试全记录
STM32H7以太网LWIP裸机移植:从硬件连接到软件调试的深度实战指南 当你在深夜的实验室里盯着屏幕上那个顽固的"Request timed out"提示,第十次尝试ping通你的STM32H750开发板时,那种挫败感我深有体会。以太网移植看似简单——连接几…...

如何快速掌握Spinning Up超参数调优:提升深度强化学习性能的终极指南
如何快速掌握Spinning Up超参数调优:提升深度强化学习性能的终极指南 【免费下载链接】spinningup An educational resource to help anyone learn deep reinforcement learning. 项目地址: https://gitcode.com/gh_mirrors/sp/spinningup Spinning Up是一款…...

如何快速解锁WeMod完整功能:WandEnhancer终极使用指南
如何快速解锁WeMod完整功能:WandEnhancer终极使用指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer WandEnhancer是一款专为WeMod应用设计…...