复现nnUNet2并跑通自定义数据
复现nnUNet2并跑通自定义数据
- 1. 配置环境
- 2. 处理数据集
- 2.1 创建文件夹
- 2.2 数据集格式转换
- 2.3 数据集预处理
- 3. 训练
- 4. 改进模型
- 4.1 概要
- 4.2 加注意力模块
1. 配置环境
stage1:创建python环境,这里建议python3.10
conda create --n nnunet python=3.10
conda activate nnunet
stage2:按照pytorch官方链接 (conda/pip) 上的说明安装PyTorch。
nnunetv2 2.5.1 需要 torch>=2.1.2,比如:
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=11.8
但是,使用上述指令安装pytorch,很多时候还是装的cpuonly版,这里可以进行本地安装,首先搜索whl,最后的cuda版本可以自行更改。
https://download.pytorch.org/whl/cu117
最后,直接cd到下载文件所属的盘符下:
d:
cd D:\program
pip install torch-2.1.2+cu118-cp310-cp310-win_amd64.whl
stage3:git nnUnet的源代码,并配置nnUnet
git clone https://github.com/MIC-DKFZ/nnUNet.git
cd nnUNet
pip install -e .
2. 处理数据集
可以通过运行将 nnU-Net v1 中的数据集转换为 V2 nnUNetv2_convert_old_nnUNet_dataset INPUT_FOLDER OUTPUT_DATASET_NAME。请记住,v2 调用数据集 DatasetXXX_Name(而不是 Task),其中 XXX 是一个 3 位数字。请提供旧任务的路径,而不仅仅是任务名称。nnU-Net V2 不知道 v1 任务在哪里!
2.1 创建文件夹
首先,创建nnUNet_raw、nnUNet_preprocessed、nnUNet_results三个文件夹,将下载的原始数据集放到nnUNet_raw下,这里MSD挑战赛的Task02_Heart数据集为例。
nnUNet_raw用于存放原始数据集;
nnUNet_preprocessed用于存放格式转换并预处理的数据集及配置信息;
nnUNet_results用于存放训练结果相关的信息文件。

2.2 数据集格式转换
接着,我们转换数据集格式:
nnUNetv2_convert_MSD_dataset -i D:\nnUNet\nnUNet_raw\Task02_Heart
可能会出现下列错误:
TypeError: expected str, bytes or os.PathLike object, not NoneType
解决方法:
原因是没有设置相关数据集的路径,打开D:\nnUNet\nnunetv2\paths.py文件

方法1:直接在这个py文件指定数据集路径:

方法2:
设置环境变量:
1.windows:
#这个变量只在当前命令提示符会话中有效,不会被保存到系统环境变量中
set nnUNet_raw=D:/nnUNet/nnUNet_raw
set nnUNet_preprocessed=D:/nnUNet/nnUNet_preprocessed
set nnUNet_results=D:/nnUNet/nnUNet_results
2.linux:
export nnUNet_raw="D:/nnUNet/nnUNet_raw"
export nnUNet_preprocessed="D:/nnUNet/nnUNet_preprocessed"
export nnUNet_results="D:/nnUNet/nnUNet_results"
发现,转换成功,生成了1个Dataset002_Heart文件夹:

转换前后主要区别在于:
1、文件夹由Task02_Heart变成Dataset002_Heart。
ps:文件夹命名为:Dataset+三位整数+任务名,Dataset002_Heart中数据集ID为2,任务名为Heart。此文件夹下存放需要的训练数据集imageTr、测试集imageTs、标签labelsTr。其中labelsTr是与imageTr中一一对应的标签,文件中都是nii.gz文件。imageTs是可选项,可以没有。
2、原始json中是:

转换后,字典的key为"channel_names":

3、原始json中有"training"、"test"这两个key存放数据集的相对路径:

转换后,字典的key为"file_ending",直接记录数据集的后缀名即可:

2.3 数据集预处理
nnUNetv2_plan_and_preprocess -d DATASET\_ID --verify_dataset_integrity
#这里我是用的是Dataset002_Heart,将ID改为2
nnUNetv2_plan_and_preprocess -d 2 --verify_dataset_integrity
运行成功后,会在nnUNet_preprocessed文件下生成如下文件:

此步骤主要就是对数据进行:裁剪crop,重采样resample以及标准化normalization。将提取数据集fingerprint(一组特定于数据集的属性,例如图像大小、体素间距、强度信息等)。此信息用于设计三种 U-Net 配置。每个管道都在其自己的数据集预处理版本上运行。其中的nnUNetPlans.json是网络结构相关的配置文件。
3. 训练
训练使用如下脚本指令:
nnUNetv2_train DATASET_NAME_OR_ID UNET_CONFIGURATION FOLD [additional options, see -h]
DATASET_NAME_OR_ID 指定应在哪个数据集上进行训练;UNET_CONFIGURATION 是一个字符串,用于标识所请求的 U-Net 配置(默认值:2d、3d_fullres、3d_lowres、3d_cascade_lowres);
FOLD 指定训练 5 折交叉验证中的哪一折。
根据数据集名称或者数据集的ID、UNET配置、折数FOLD,进行训练:
nnUNetv2_train 2 2d 0
成功开始训练:

4. 改进模型
4.1 概要
许多人可能不满足于只是复现跑通,而是有一些改进模型,提升指标,最后发paper的需求。
但是,会发现nnUNet2的网络模型结构很难找,但当找到nnUNet\nnunetv2\utilities\get_network_from_plans.py时,发现还是找不到网络模型的model。
但是,我们在数据集处理的时候生成的nnUNet_preprocessed文件下的nnUNetPlans.json文件中发现了网络结构的model文件。

于是,发现这个模型结构在我们配置的环境中,我就在Anaconda中我的环境下D:\Anaconda3\envs\nnunet\Lib\site-packages\dynamic_network_architectures\architectures找到了。

4.2 加注意力模块
我们以在unet的编码器中添加SE注意力模块为例,首先打开unet.py文件,找到调用编码器实例化类对象的地方。

发现,PlainConvEncoder类中卷积模块通过StackedConvBlocks类实例化出来的,

简单点,我们就直接在StackedConvBlocks类中嵌入SE模块。找到了,nn.Sequential()模块拼接模块的部分,
我们在下面堆上SE模块。

这里我也附上SE的代码,通过参考其它来的继承来写SE:
class SE(nn.Module):def __init__(self,conv_op: Type[_ConvNd],input_channels: int,output_channels: int,kernel_size: Union[int, List[int], Tuple[int, ...]],stride: Union[int, List[int], Tuple[int, ...]],conv_bias: bool = False,norm_op: Union[None, Type[nn.Module]] = None,norm_op_kwargs: dict = None,dropout_op: Union[None, Type[_DropoutNd]] = None,dropout_op_kwargs: dict = None,nonlin: Union[None, Type[torch.nn.Module]] = None,nonlin_kwargs: dict = None,nonlin_first: bool = False):super(SE, self).__init__()self.input_channels = input_channelsself.output_channels = output_channelsstride = maybe_convert_scalar_to_list(conv_op, stride)self.stride = stridekernel_size = maybe_convert_scalar_to_list(conv_op, kernel_size)if norm_op_kwargs is None:norm_op_kwargs = {}if nonlin_kwargs is None:nonlin_kwargs = {}ops = []self.conv = conv_op(input_channels,output_channels,kernel_size,stride,padding=[(i - 1) // 2 for i in kernel_size],dilation=1,bias=conv_bias,)ops.append(self.conv)if dropout_op is not None:self.dropout = dropout_op(**dropout_op_kwargs)ops.append(self.dropout)if norm_op is not None:self.norm = norm_op(output_channels, **norm_op_kwargs)ops.append(self.norm)self.all_modules = nn.Sequential(*ops)self.se = SEAttention(conv_op=conv_op, channel=output_channels)def forward(self, x):x = self.all_modules(x)x = self.se(x)return xdef compute_conv_feature_map_size(self, input_size):assert len(input_size) == len(self.stride), "just give the image size without color/feature channels or " \"batch channel. Do not give input_size=(b, c, x, y(, z)). " \"Give input_size=(x, y(, z))!"output_size = [i // j for i, j in zip(input_size, self.stride)] # we always do same paddingreturn np.prod([self.output_channels, *output_size], dtype=np.int64)class SEAttention(nn.Module):def __init__(self, conv_op, channel=512, reduction=16):super().__init__()if conv_op == torch.nn.modules.conv.Conv2d:self.pool = nn.AdaptiveAvgPool2d(1)elif conv_op == torch.nn.modules.conv.Conv3d:self.pool = nn.AdaptiveAvgPool3d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def forward(self, x):size = x.size()b, c = size[0], size[1]y = self.pool(x).view(b, c)y = self.fc(y).view(b, c, *[1 for i in range(len(size) - 2)])return x * y.expand_as(x)def init_weights(self):for m in self.modules():if isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)
相关文章:
复现nnUNet2并跑通自定义数据
复现nnUNet2并跑通自定义数据 1. 配置环境2. 处理数据集2.1 创建文件夹2.2 数据集格式转换2.3 数据集预处理 3. 训练4. 改进模型4.1 概要4.2 加注意力模块 1. 配置环境 stage1:创建python环境,这里建议python3.10 conda create --n nnunet python3.10 …...

Educational Codeforces Round 169 (Rated for Div. 2)(ABCDE)
A. Closest Point 签到 #define _rep(i,a,b) for(int i(a);i<(b);i) int n,m; int q[N]; void solve() {cin>>n;_rep(i,1,n)cin>>q[i];if(n!2)cout<<"NO\n";else if(abs(q[1]-q[2])!1)cout<<"YES\n";else cout<<"…...

成为Python砖家(2): str 最常用的8大方法
str 类最常用的8个方法 str.lower()str.upper()str.split(sepNone, maxsplit-1)str.count(sub[, start[, end]])str.replace(old, new[, count])str.center(width[, fillchar])str.strip([chars])str.join(iterable) 查询方法的文档 根据 成为Python砖家(1): 在本地查询Pyth…...
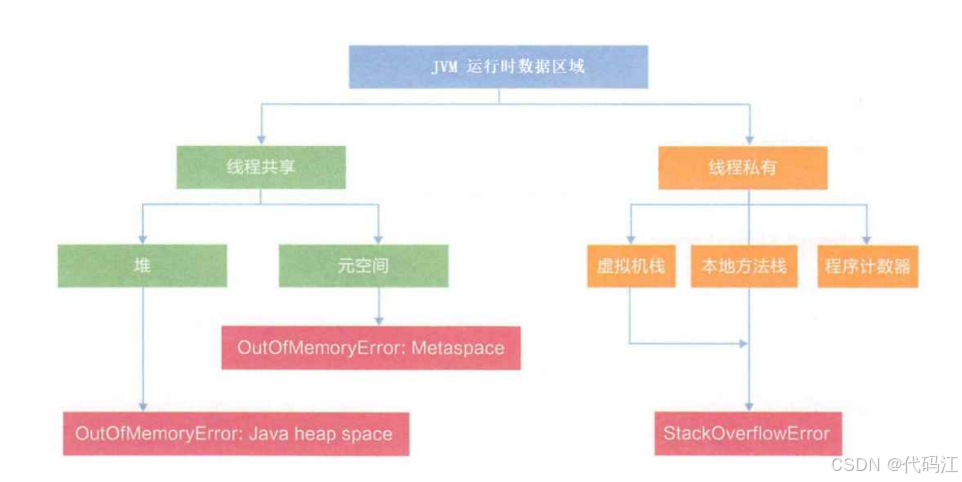
深入理解JVM运行时数据区(内存布局 )5大部分 | 异常讨论
前言: JVM运行时数据区(内存布局)是Java程序执行时用于存储各种数据的内存区域。这些区域在JVM启动时被创建,并在JVM关闭时销毁。它们的布局和管理方式对Java程序的性能和稳定性有着重要影响。 目录 一、由以下5大部分组成 1.…...

JAVA根据表名获取Oracle表结构信息
响应实体封装 import lombok.AllArgsConstructor; import lombok.Builder; import lombok.Data; import lombok.NoArgsConstructor;/*** author CQY* version 1.0* date 2024/8/15 16:33**/ Data NoArgsConstructor AllArgsConstructor Builder public class OracleTableInfo …...

网络性能优化
网络性能优化是确保网络稳定性、速度和可靠性的关键步骤。优化过程通常包括诊断问题、识别瓶颈以及实施具体的解决方案。以下是关于如何进行网络性能优化的详细指南: 一、问题诊断 网络性能监控 网络流量分析工具:使用Wireshark、NetFlow、Ntop等工具监…...

[C++String]接口解读,深拷贝和浅拷贝,string的模拟实现
💖💖💖欢迎来到我的博客,我是anmory💖💖💖 又和大家见面了 欢迎来到C探索系列 作为一个程序员你不能不掌握的知识 先来自我推荐一波 个人网站欢迎访问以及捐款 推荐阅读 如何低成本搭建个人网站…...
理性看待、正确理解 AI 中的 Scaling “laws”
编者按:LLMs 规模和性能的不断提升,让人们不禁产生疑问:这种趋势是否能一直持续下去?我们是否能通过不断扩大模型规模最终实现通用人工智能(AGI)?回答这些问题对于理解 AI 的未来发展轨迹至关重…...
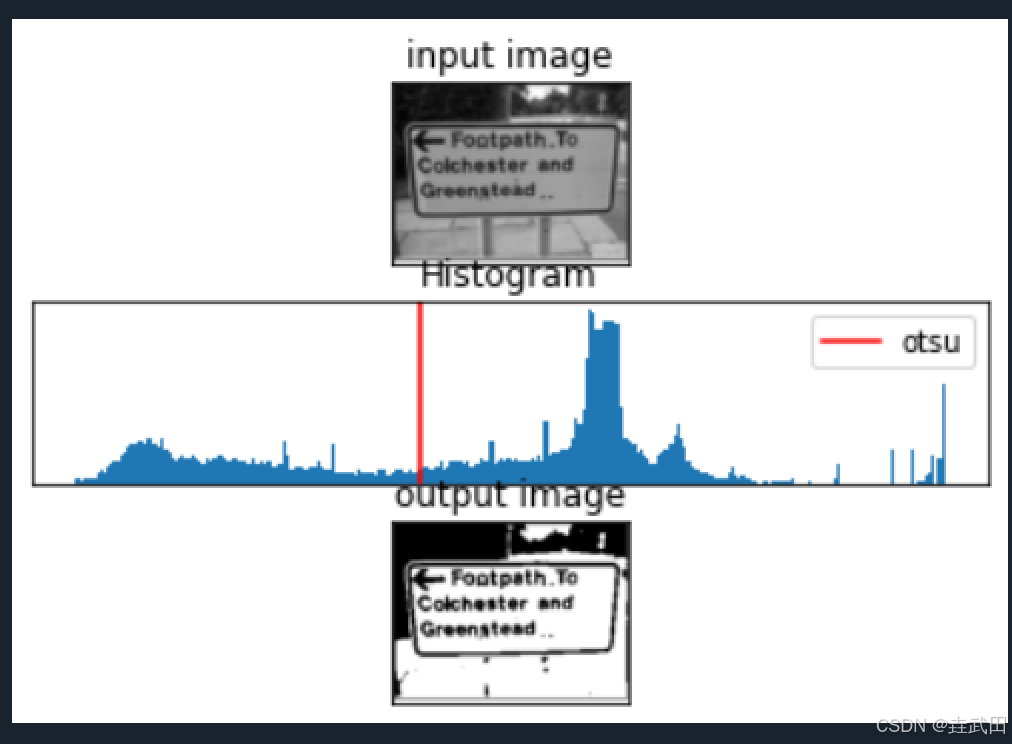
【OCR 学习笔记】二值化——全局阈值方法
二值化——全局阈值方法 固定阈值方法Otsu算法在OpenCV中的实现固定阈值Otsu算法 图像二值化(Image Binarization)是指将像素点的灰度值设为0或255,使图像呈现明显的黑白效果。二值化一方面减少了数据维度,另一方面通过排除原图中…...
Java - IDEA开发
使用IDEA开发Java程序步骤: 创建工程 Project;创建模块 Module;创建包 Package;创建类;编写代码; 如何查看JDK版本 Package介绍: package是将项目中的各种文件,比如源代码、编译生成的字节码、配置文件、…...
什么是内存优化表(In-Memory Table)?)
Oracle(62)什么是内存优化表(In-Memory Table)?
内存优化表(In-Memory Table)是指将表的数据存储在内存中,以提高数据访问和查询性能的一种技术。内存优化表通过利用内存的高速访问特性,显著减少I/O操作的延迟,提升数据处理的速度。这种技术在需要高性能数据处理的应…...
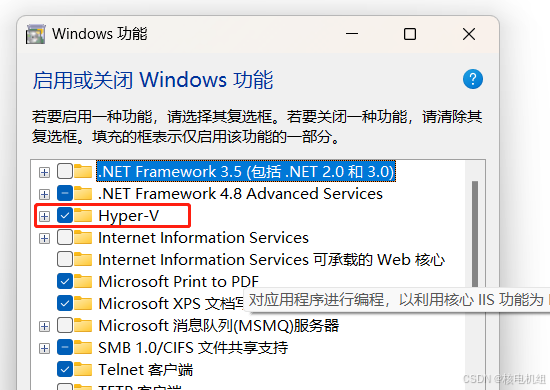
#window家庭版安装hyper-v#
由于window 11 家庭版没有hyper-v虚拟机服务,则需要安装一下,使用如下操作 1:新建一个txt文件,拷贝如下脚本到里面 pushd "%\~dp0" dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper-v.txt for /f %%i in (findst…...

【云原生】Pass容器研发基础——汇总篇
云原生基础汇总 系列综述: 💞目的:本系列是个人整理为了云计算学习的,整理期间苛求每个知识点,平衡理解简易度与深入程度。 🥰来源:每个知识点的修正和深入主要参考各平台大佬的文章,…...
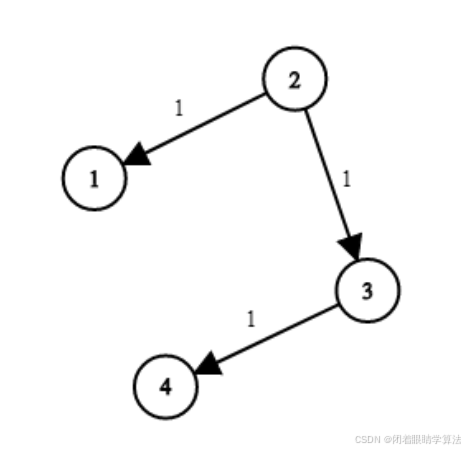
【Py/Java/C++三种语言详解】LeetCode743、网络延迟时间【单源最短路问题Djikstra算法】
可上 欧弟OJ系统 练习华子OD、大厂真题 绿色聊天软件戳 od1441了解算法冲刺训练(备注【CSDN】否则不通过) 文章目录 相关推荐阅读一、题目描述二、题目解析三、参考代码PythonJavaC 时空复杂度 华为OD算法/大厂面试高频题算法练习冲刺训练 相关推荐阅读 …...

交替输出
交替输出 题目:线程 1 输出 a 5 次,线程 2 输出 b 5 次,线程 3 输出 c 5 次。现在要求输出 abcabcabcabcabc wait notify 版 public class SyncWaitNotify {private volatile int flag;private volatile int loopNumber;public SyncWaitNo…...
——更改html内数据)
JS(三)——更改html内数据
获取 DOM 元素,然后修改其属性或内容。使用 getElementById 方法获取特定 ID 的元素: <p id"myParagraph">这是初始的文本</p> const paragraph document.getElementById(myParagraph); paragraph.innerHTML 这是修改后的文本…...

CSS小玩意儿:文字适配背景
一,效果 二,代码 1,搭个框架 添加一张背景图片,在图片中显示一行文字。 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" conte…...
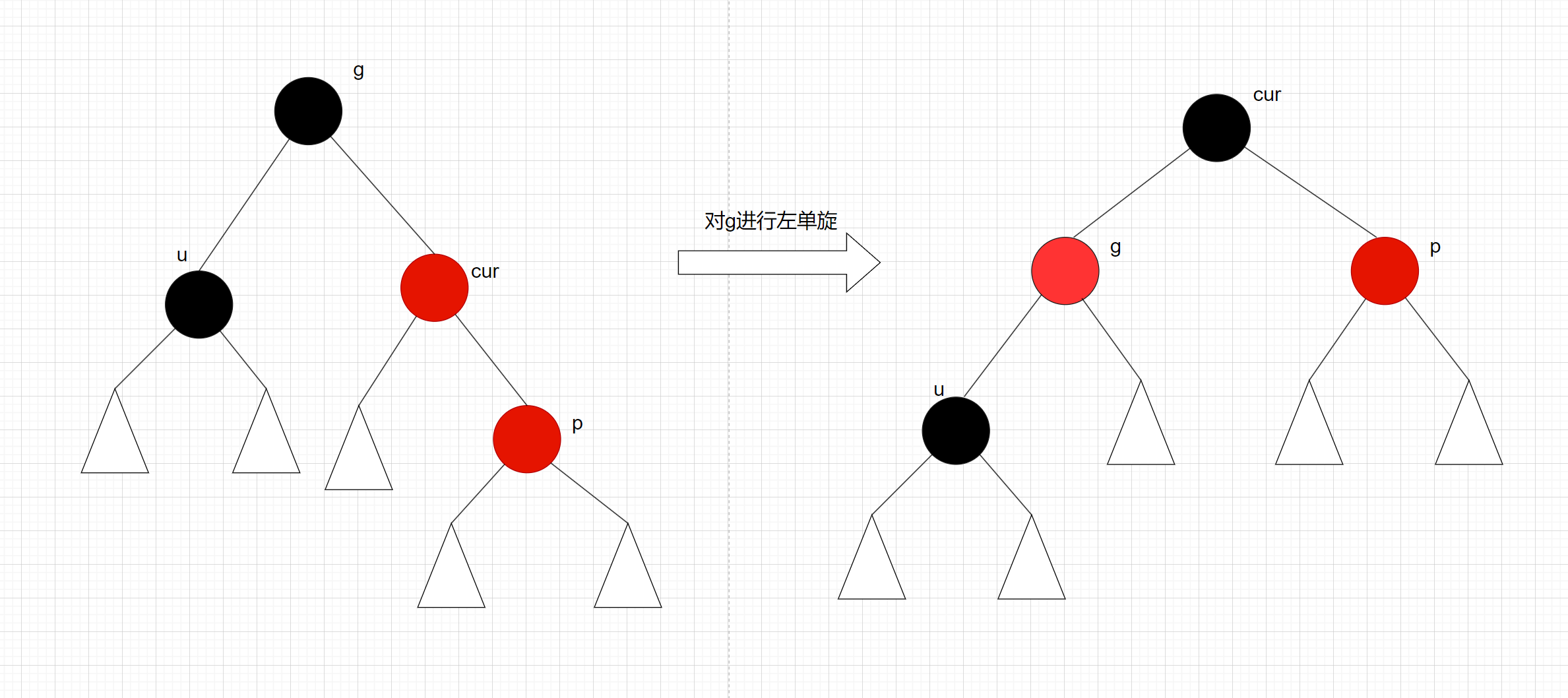
C++:平衡二叉搜索树之红黑树
一、红黑树的概念 红黑树, 和AVL都是二叉搜索树, 红黑树通过在每个节点上增加一个储存位表示节点的颜色, 可以是RED或者BLACK, 通过任何一条从根到叶子的路径上各个节点着色方式的限制,红黑树能够确保没有一条路径会比…...

CentOS 7 系统优化
CentOS 7 系统优化 1、配置YUM源 阿里云的YUM源配置: CentOS 7使用以下命令: sudo wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repoCentOS 8使用以下命令: sudo wget -O /etc/yum.repos.d/CentOS…...

扫雷游戏——附源代码
扫雷游戏的源代码比较简单,不设计比较复杂的代码,主要是多个函数的组合,每个函数执行自己的功能,最终支持游戏的完成。 1.菜单 我们需要一个提醒信息来让用户进行选择。 void menu() {printf("***********************\n&…...

如何用Mermaid CLI彻底改变技术文档工作流
如何用Mermaid CLI彻底改变技术文档工作流 【免费下载链接】mermaid-cli Command line tool for the Mermaid library 项目地址: https://gitcode.com/gh_mirrors/me/mermaid-cli 在技术文档编写过程中,图表创建往往是效率瓶颈。传统绘图工具需要手动拖拽、反…...

基于ESP32-S3的免焊接RGB矩阵屏驱动方案:从硬件解析到项目实战
1. 项目概述:从零到一的免焊接RGB矩阵显示方案如果你曾经尝试过驱动一块RGB LED矩阵屏,大概率会经历一段“痛并快乐着”的时光。快乐在于,当代码跑通,绚丽的色彩在眼前流动时,那种成就感无与伦比;痛苦则在于…...

基于本地文档的智能问答系统:从向量检索到私有化部署
1. 项目概述:当本地文档库遇上AI大脑最近在折腾一个挺有意思的东西,一个叫“word-GPT-Plus”的项目。简单来说,它解决了一个我,相信也是很多朋友都有的痛点:我电脑里存了海量的文档——工作周报、技术方案、学习笔记、…...

电子认证合规护航跨境数字身份互认、国际数字身份互信
在数字中国建设与高水平对外开放协同推进的背景下,跨境贸易、金融合作与数字服务加速线上化,数字信任成为打通跨境交互壁垒的核心因素。电子认证作为网络空间信任体系的基石,其全流程合规不仅是自身服务运营的要求,更是护航跨境数…...

BMO:基于Node.js的无头浏览器管理工具,解决Puppeteer资源泄漏与并发难题
1. 项目概述:一个被低估的浏览器自动化利器如果你经常需要处理网页数据抓取、自动化测试,或者重复性的网页操作任务,那么你大概率听说过或者用过 Puppeteer、Playwright 或者 Selenium。这些工具功能强大,但有时候,它们…...

Android性能与功耗深度优化:从理论到实践
引言 在当今移动互联网时代,用户体验是应用成功的关键因素之一。流畅的操作、快速的响应、持久的续航,这些都与应用的性能和功耗表现息息相关。对于Android开发工程师而言,深入理解系统机制并掌握性能与功耗优化技术,已从加分项变为必备技能。特别是在金融、游戏、直播等对…...

人工神经网络知识点讲解
人工神经网络知识点讲解 知识导图 人工神经网络 ├── 基础认知 │ ├── 神经网络的核心概念 │ ├── 神经元的工作机制 │ └── 网络的层级结构 ├── 激活函数 │ ├── 激活函数的作用 │ ├── 常见激活函数:sigmoid/tanh/ReLU/Softmax │ …...
设计:超越RBAC的精细化权限管理核心)
权限组(PerGroup)设计:超越RBAC的精细化权限管理核心
1. 从“组”到“权限组”:一个被忽视的系统管理基石在系统管理和软件开发中,我们经常听到“用户组”(Group)这个概念。无论是Linux系统上的/etc/group文件,还是Windows的本地用户和组管理,亦或是各类应用后…...

面试题:评估指标详解——NLP 常用评估指标、BLEU、ROUGE、BLEU 和 ROUGE 区别全解析
1. 为什么“评估指标”是大模型面试里的高频题?1.1 面试官真正想听的,不只是定义很多人一看到“评估指标”就开始背 Accuracy、Precision、Recall、F1、BLEU、ROUGE,但如果只是把名词丢出来,回答往往会显得很散。面试官真正想听的…...

数据库内机器学习:用SQL调用AI模型,简化预测工作流
1. 项目概述:当数据库遇上机器学习最近在开源社区里,一个名为mindsdb/anton的项目引起了我的注意。乍一看,这像是一个普通的数据库项目,但深入了解后,你会发现它试图解决一个困扰了数据工程师和分析师很久的痛点&#…...