保姆级教程,带你复现病理AI的经典模型CLAM(一)|项目复现·24-08-19
小罗碎碎念
推文概述
复现CLAM的第一期推文
通过这期推文你首先会学会如何在服务器端使用jupyter编程,比你用其他的编译器(例如PyCharm、VS)会更加的清晰,对新手也更友好。
接着我会介绍如何进行数据预处理,以及你应该如何准备自己的数据;随后我会介绍如何对WSI进行分割并切成patches;最后,我会讲解如何利用切片级的标签进行特征提取。
注意,我这篇推文的数据只用了两张切片,前面这些步骤是没有影响的,如果想要进行后面的步骤,两张切片是不够的,因为要划分训练集、验证集和测试集。
这篇推文是所有后续项目复现的基础,一定要掌握这个流程。
如果想了解文献具体讲了什么内容,可以移步我的另一篇推文
CLAM:病理AI发展里程碑,建议每一个研究病理AI的人都了解的文章|24-08-16
模型概述
CLAM(Clustering-constrained Attention Multiple Instance Learning)是一种基于深度学习的弱监督方法,用于高效和弱监督的全切片级分析。
CLAM的工作步骤:
- 自动分割:CLAM首先对全切片图像进行自动分割,识别出组织区域。这通常涉及到将图像转换到HSV颜色空间,并使用饱和度通道进行阈值处理,以提取组织区域。
- 特征提取:在分割之后,CLAM利用深度卷积神经网络(CNN)为每个分割出的补丁计算低维特征表示。这通常涉及到使用预训练的CNN模型,如ResNet50,来提取特征。
- 注意力机制:CLAM使用注意力机制来确定每个补丁对最终切片级预测的贡献程度。这涉及到计算每个补丁的不归一化注意力分数,并将其转换为百分位数分数,然后缩放到0到1.0之间。
- 实例级聚类:CLAM使用实例级聚类来约束和优化特征空间。具体来说,CLAM模型有多个并行的注意力分支,每个分支计算一个独特的切片级表示,该表示由网络视为多类诊断任务中某一类的强阳性证据的高度关注区域确定。
- 分类预测:每个类别特定的切片表示被分类层检查,以获得整个切片的最终概率分数预测。
- 模型训练:CLAM模型使用弱监督学习进行训练,只需要切片级标签,不需要像素级或补丁级注释。这使得CLAM能够高效地利用数据,并能够在训练数据有限的情况下取得良好的性能。
总的来说,CLAM通过使用注意力机制和实例级聚类,实现了高效和弱监督的全切片级分析,能够自动识别高诊断价值的子区域,并准确地对整个切片进行分类。
CLAM的最新更新
关于CLAM的最新更新,以下是关键点:
2024年4月6日
发布了UNI和CONCH,作为预训练的编码器,现在可以作为CLAM的预训练模型(后续推文中会介绍)。
请确保通过安装最新的env.yml文件,并使用相应的clam_latestconda环境,正确安装所有依赖项。
2024年3月19日
发布了UNI和CONCH,这是一对在计算病理学工作流程上表现卓越的预训练编码器,包括基于MIL的CLAM工作流程。
2021年5月24日
热图可视化脚本create_heatmaps.py现在可用,配置模板位于heatmaps/configs。
2021年3月1日
由于CLAM只需要图像特征进行训练,因此不需要保存实际的图像补丁,新的流水线消除了这一开销,而是只在“补丁”过程中保存图像补丁的坐标,并在特征提取时从WSI中实时加载这些区域。
这比旧流水线快得多,通常只需1-2秒进行“补丁”,以及几分钟的时间来特征化一个WSI。
要使用新的流水线,请确保调用create_patches_fp.py和extract_features_fp.py而不是旧的create_patches.py和extract_features.py脚本。README已经更新,默认使用新的、更快的流水线。
如果您仍然希望使用旧的流水线,请参考:README_old.md。它保存组织补丁,这比使用特征嵌入要慢得多,并且会占用大量的存储空间,但如果您需要处理原始图像补丁而不是特征嵌入,它仍然很有用。
注意
最新更新默认会将图像补丁调整大小为224 x 224,然后使用预训练编码器提取特征。这一改变是为了与UNI、CONCH和其他研究中使用的评估协议保持一致。
如果您希望保留补丁生成的原始图像补丁的大小,或者使用特征提取时不同的图像尺寸,可以在extract_features_fp.py中指定--target_patch_size。
一、安装
注意:我下面的操作在服务器内完成,个人电脑的操作流程一样,只是后续运行时间有差别
1-1:服务器端
首先登录服务器(个人电脑就打开终端操作),然后创建一个新的文件夹,并进入
mkdir CLAM
cd CLAM
克隆仓库
git clone https://github.com/mahmoodlab/CLAM.git
接下来,使用环境配置文件创建一个conda环境:
cd CLAM
conda env create -f env.yml
如果此时配置环境的时候,遇到了下列问题,可以遵照下列流程处理
没遇到问题就跳过,不过建议收藏,以后可能会遇到类似的问题,例如你新建一个虚拟环境,一直在solving enviroment……
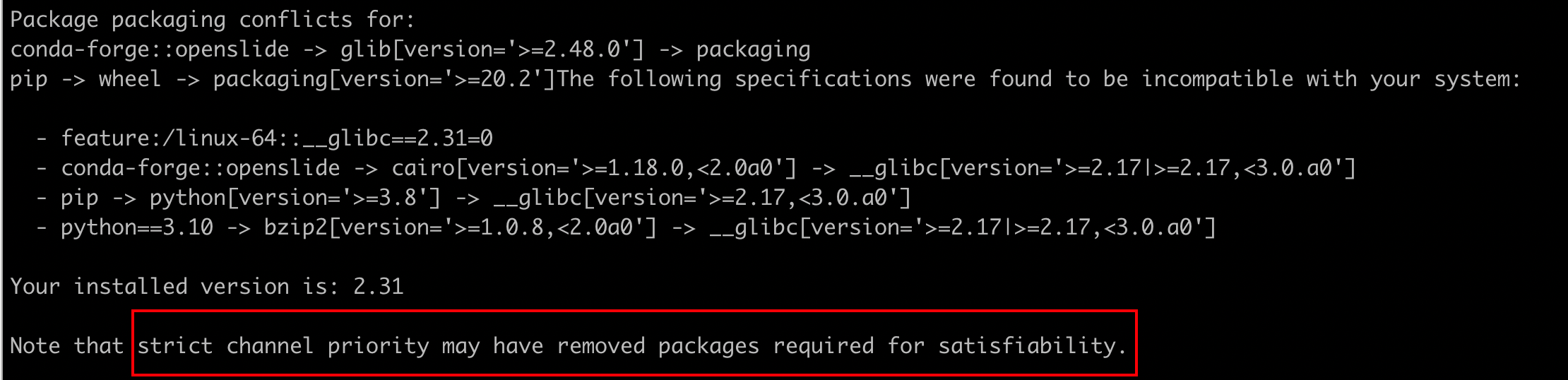
#确定通道优先级
conda config --show channel_priority
#关闭通道优先级
conda config --set channel_priority false
#查看当前通道
conda config --show channels
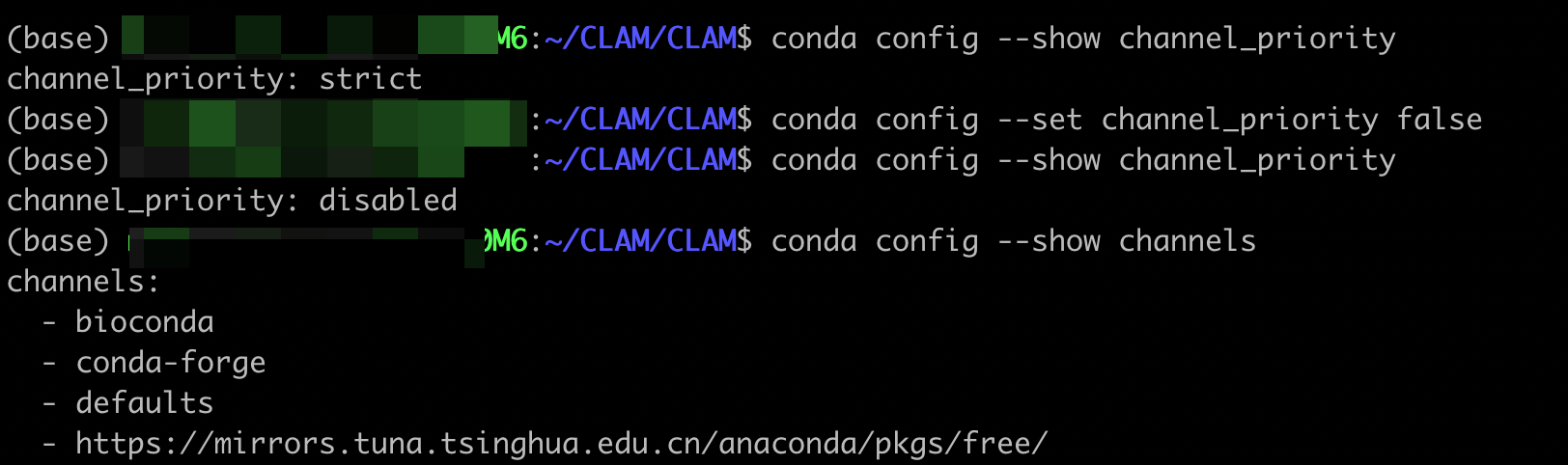
激活环境
conda activate clam_latest
如果您想使用CONCH作为预训练的编码器,可以在环境中安装该包,通过运行以下命令:
pip install git+https://github.com/Mahmoodlab/CONCH.git
完成实验后,要停用环境:
conda deactivate clam_latest
如有任何问题,可以在交流群内讨论。
1-2:jupyter端
因为我个人比较喜欢在jupyter内写代码,不喜欢服务器黑乎乎只有代码的窗口,所以我会调用jupyter的可视化界面来辅助自己编程,如果你也喜欢这种方式,或者没有尝试过,不妨跟着我一起试试。
在终端输入
#你要记住你的jupyter是在哪个环境安装的,你激活的环境里是不会安装的
jupyter notebook --no-browser
在个人电脑的终端输入
ssh -N -L localhost:8888:localhost:8888 用户名@IP地址
ssh -N -L localhost:8888:localhost:8888 mailab015@10.30.24.101
输入上述代码之后,会让你输入密码,即为服务器账户密码。正确输入密码之后,打开你的浏览器,在网址栏输入localhost:8888后,进入登录界面。
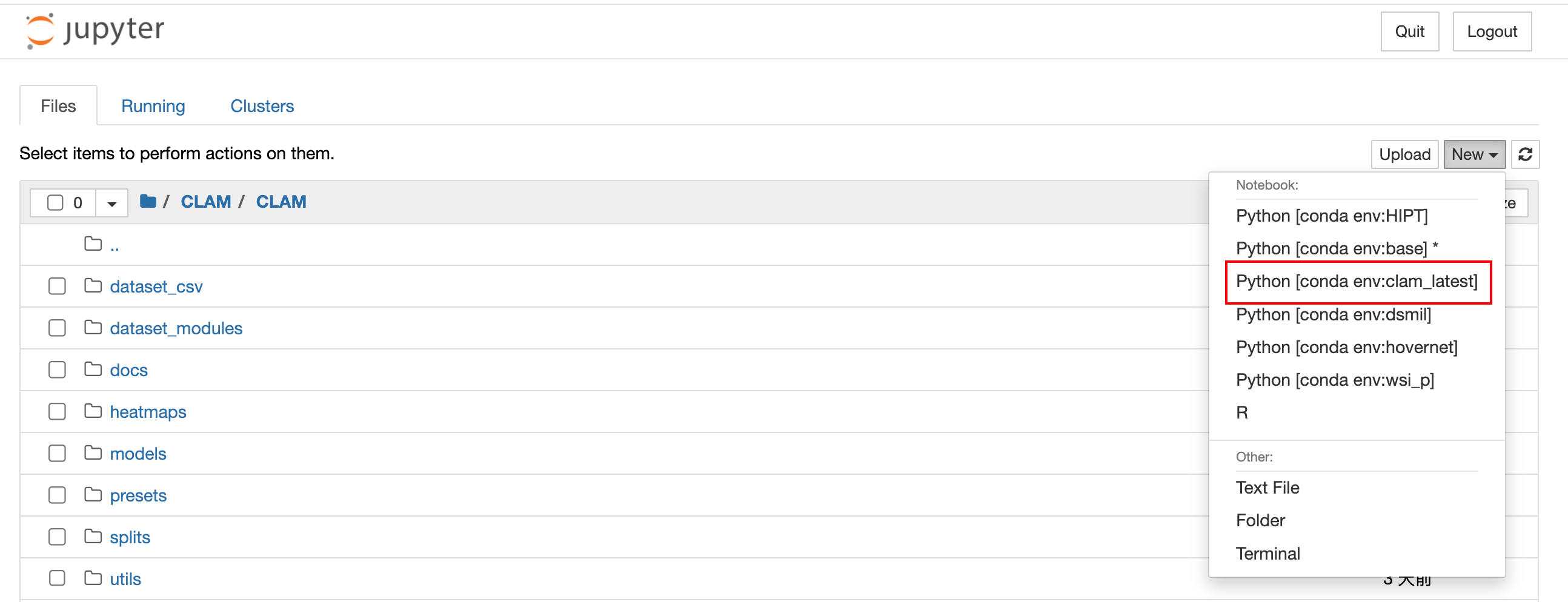
进入以后,我们会发现CLAM的虚拟环境不在内核里,所以我们需要安装一下。这里提一嘴,我这里还安装了R的内核,可以用jupyter写R语言哈,之前的推文也都介绍过。
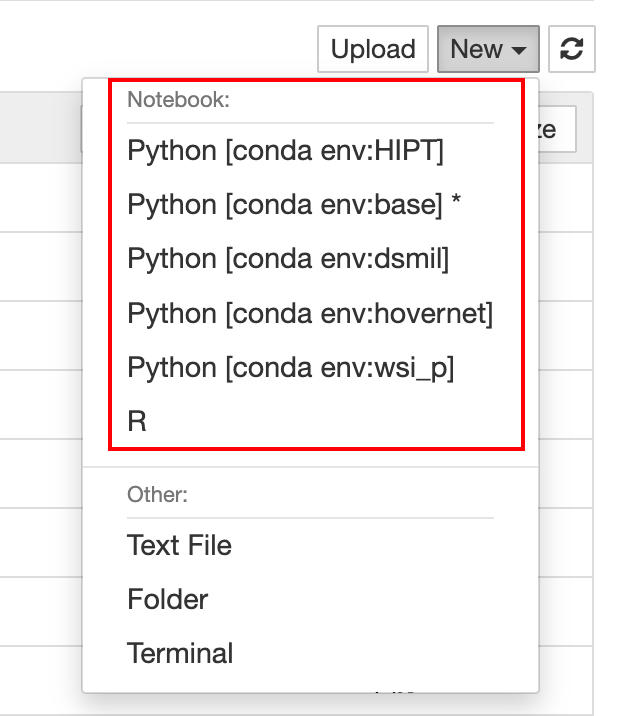
进入你克隆的仓库,新建一个终端
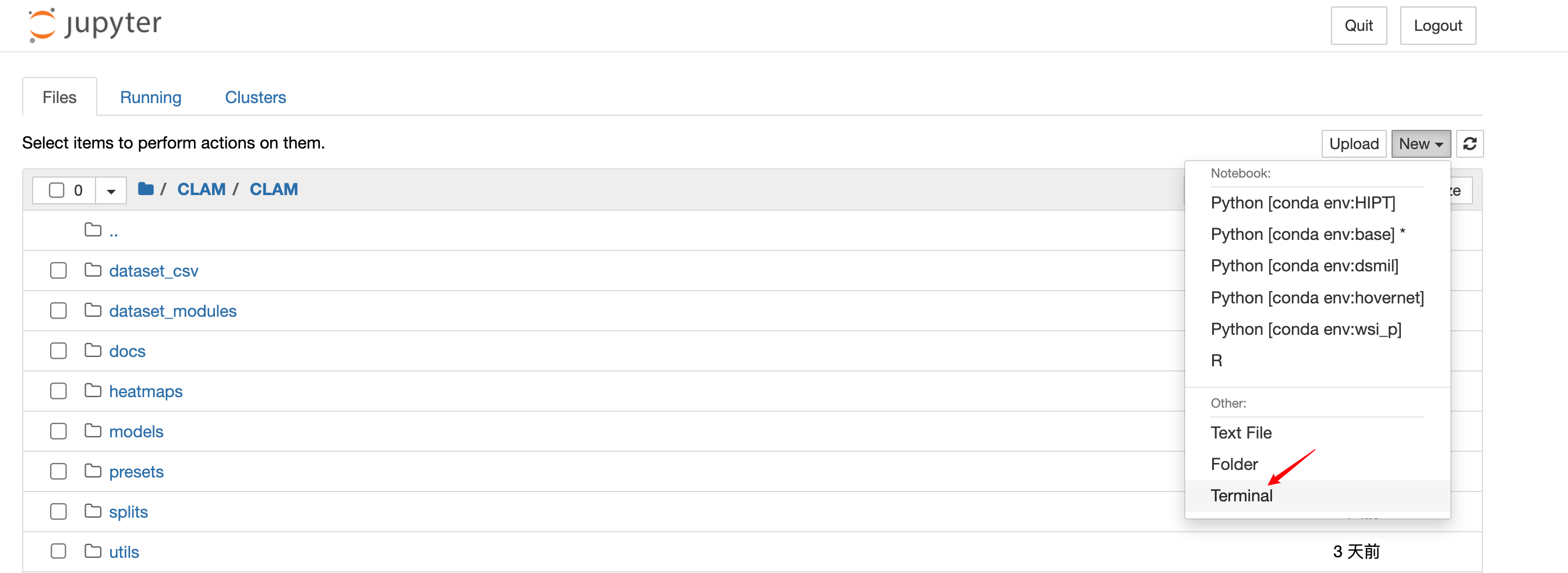
#我这里是因为自己想存放一些与CLAM相关的代码,所以套了一个CLAM,你们随意
cd CLAM/CLAM
#检查一下是否进入正确位置
ls
#激活虚拟环境
conda activate clam_latest# 在当前激活的环境中安装ipykernel,这是一个允许Jupyter Notebook使用conda环境内核的工具
conda install ipykernel# 激活名为base的conda环境,也可以激活其他环境
conda activate base# 在当前激活的环境中安装nb_conda_kernels,这是一个允许Jupyter Notebook识别并使用conda环境中安装的内核的工具
conda install nb_conda_kernels
然后刷新一下界面,就可以将刚刚创立的虚拟环境作为新的内核了。
二、准备数据集
不建议一上来就用自己的数据哦,所以你可以先跟着我处理一下公开数据集,正好也趁着这个机会了解一下如何利用公开数据集。
#我选的是camelyon16的数据,官网提供百度网盘的链接
https://camelyon17.grand-challenge.org/Data
按箭头指示操作
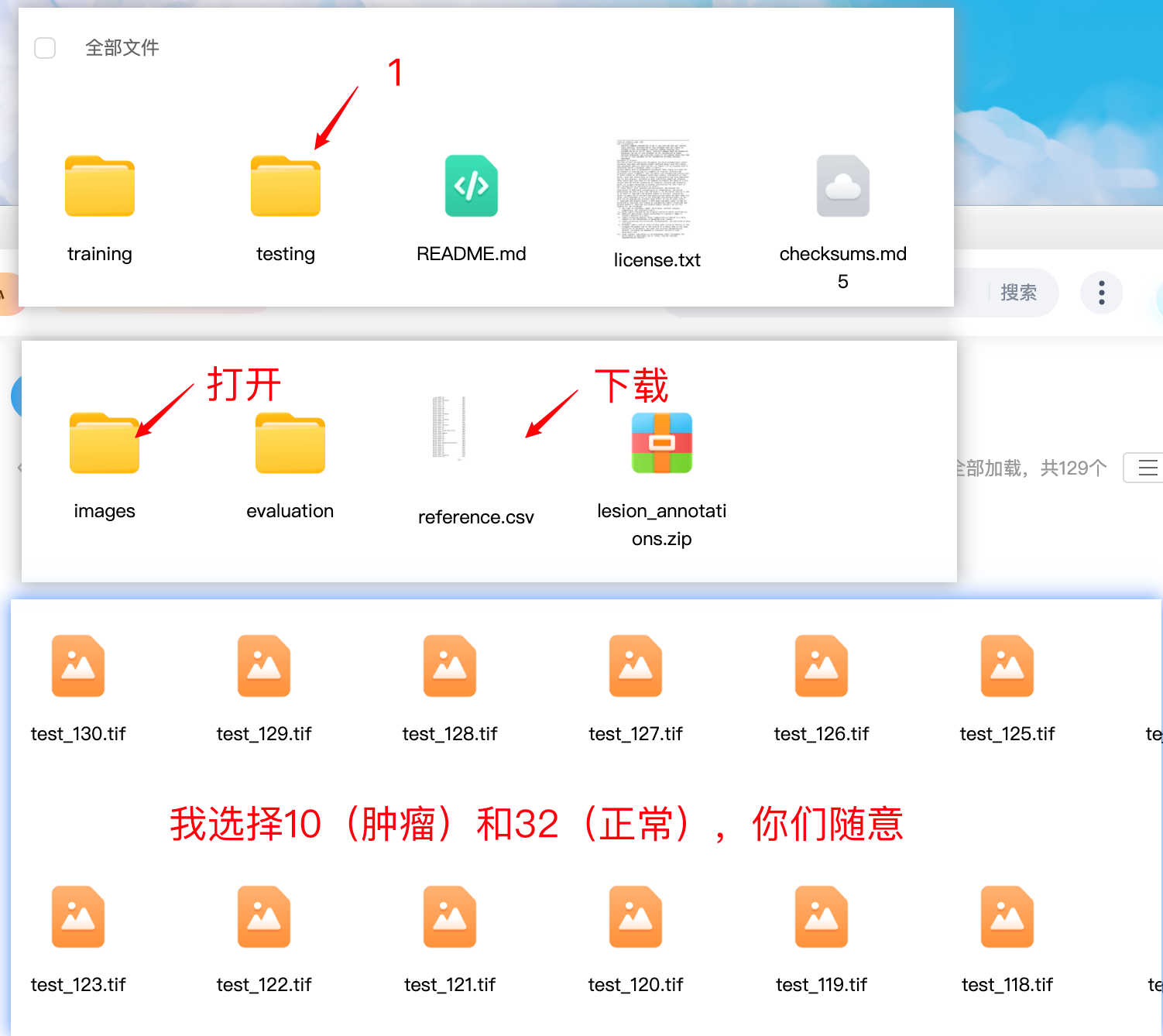
然后上传数据到你的服务器(个人电脑端不需要这一步)

三、WSI 分割&切片
第一步专注于分割组织并排除任何孔洞。特定幻灯片的分割可以通过调整个别参数来调整(例如,某些肉瘤可能需要考虑扩张的血管作为孔洞)。
以下示例假设以广为人知的标准格式(.svs、.ndpi、.tiff等)存储的数字全切片图像数据位于名为DATA_DIRECTORY的文件夹中。
DATA_DIRECTORY/├── slide_1.svs├── slide_2.svs└── ...
3-1:基础纯自动分割
# 调用create_patches_fp.py脚本,用于从源图像中创建补丁
python create_patches_fp.py \# 指定源图像文件夹的路径
--source /home/mailab015/08-18/wsi_processing_tools/test/测试图像 \# 指定保存生成的补丁图像的文件夹路径
--save_dir /home/mailab015/CLAM/test \# 设置生成的补丁图像的大小为256x256像素
--patch_size 256 \# 表示脚本会进行图像分割,即将图像分成多个部分或区域
--seg \# 表明脚本的主要功能是创建图像补丁
--patch \# 表示脚本在创建补丁之后,还会将这些补丁拼接回原始图像或者一个新的图像
--stitch
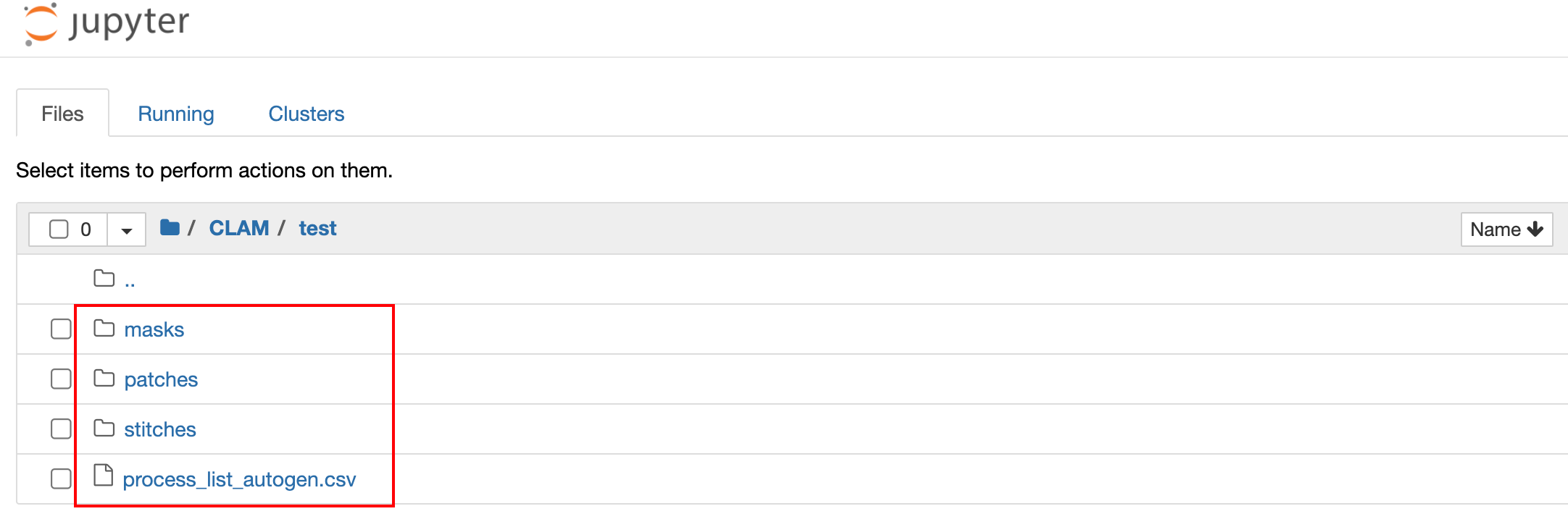
上述命令将使用默认参数分割DATA_DIRECTORY文件夹中的每个幻灯片,从分割的组织区域中提取所有补丁,为每个幻灯片使用其提取的补丁创建拼接重建(可选),并在指定的RESULTS_DIRECTORY生成以下文件结构:
RESULTS_DIRECTORY/├── masks├── slide_1.png├── slide_2.png└── ...├── patches├── slide_1.h5├── slide_2.h5└── ...├── stitches├── slide_1.png├── slide_2.png└── ...└── process_list_autogen.csv
注意
masks文件夹包含分割结果(每个幻灯片一个图像)。patches文件夹包含从每个幻灯片中提取的组织补丁数组(每个幻灯片一个.h5文件,其中每个条目对应于补丁的左上角坐标)。stitches文件夹包含从拼接的组织补丁中下采样的可视化(每个幻灯片一个图像)(可选,不用于下游任务)。- 自动生成的CSV文件
process_list_autogen.csv包含所有处理过的幻灯片的列表,以及它们使用的分割/补丁参数。
其他标志
--custom_downsample:自定义降采样的因子(不推荐,最好首先检查是否存在本地的降采样)--patch_level:从哪个下采样金字塔级别提取补丁(默认是0,最高分辨率)--no_auto_skip:默认情况下,脚本会跳过目标文件夹中已存在的补丁.h5文件,这个切换可以用来覆盖这种行为
参数模板
bwh_biopsy.csv:用于分割在BWH扫描的活检幻灯片(使用Hamamatsu S210和Aperio GT450扫描)bwh_resection.csv:用于分割在BWH扫描的切除幻灯片tcga.csv:用于分割TCGA幻灯片
只需将模板文件的名称传递给--preset参数,例如,要使用活检模板(biopsy template):
这将使用bwh_biopsy.csv中指定的参数来处理您的数据。
python create_patches_fp.py --source DATA_DIRECTORY --save_dir RESULTS_DIRECTORY --patch_size 256 --preset bwh_biopsy.csv --seg --patch --stitch
3-2:自定义默认分割参数(可选)
对于高级使用,除了使用脚本create_patches_fp.py中定义的默认、单个参数集之外,用户还可以根据数据集定义自定义的参数模板。这些模板应存储在presets文件夹下,包含分割和补丁期间使用的每个参数的值。
分割参数列表
seg_level:在哪个下采样级别上对WSI进行分割(默认:-1,使用WSI中最接近64x下采样的下采样级别)sthresh:分割阈值(正整数,默认:8,使用更高的阈值会导致前景更少,背景检测更多)mthresh:中值滤波大小(正奇数,默认:7)use_otsu:使用Otsu方法而不是简单的二值阈值(默认:False)close:在初始阈值处理后应用的额外形态学闭合(正整数或-1,默认:4)
用户可以根据自己的需求和数据集的特点,为这些参数设置不同的值,以获得最佳的分割效果。
轮廓过滤参数列表
a_t:组织面积过滤阈值(正整数,用于确定检测到的前景轮廓的最小大小,相对于参考的512 x 512大小的补丁,在级别0,例如,一个值为10意味着只处理大于10个512 x 512大小补丁的前景轮廓,默认:100)a_h:孔洞面积过滤阈值(正整数,用于确定检测到的前景轮廓中的孔洞/空腔的最小大小,同样相对于512 x 512大小的补丁,在级别0,默认:16)max_n_holes:每个检测到的前景轮廓考虑的最大孔洞数量(正整数,默认:10,更高的最大值会导致更准确的补丁,但会增加计算成本)
这些参数用于在分割后的组织区域中进一步过滤和选择前景轮廓,以优化后续的补丁提取过程。用户可以根据自己的需求和数据集的特点,为这些参数设置不同的值。例如,如果您的数据集包含大量小孔洞,您可能需要调整a_h和max_n_holes的值,以避免在前景轮廓中包含这些小孔洞。
分割可视化参数列表
vis_level:用于可视化分割结果的下采样级别(默认:-1,使用WSI中最接近64x下采样的下采样级别)line_thickness:用于绘制分割结果的线条粗细(正整数,以像素为单位,表示在级别0时绘制的线条所占用的像素数,默认:250)
这些参数用于在WSI上可视化分割结果,以便用户可以直观地检查分割的质量。用户可以根据自己的需求和数据集的特点,为这些参数设置不同的值。例如,如果分割结果中的线条太细,可能难以在WSI上清晰地看到,用户可以增加line_thickness的值以提高可见性。
补丁化参数列表
use_padding:是否对幻灯片的边缘进行填充(默认:True)contour_fn:轮廓检查函数,用于决定一个补丁是否应被视为前景或背景(可选择’four_pt’ - 检查补丁中心周围的小网格中的四个点是否都在轮廓内,‘center’ - 检查补丁中心是否在轮廓内,‘basic’ - 检查补丁的左上角是否在轮廓内,默认:‘four_pt’)
这些参数用于在分割后的组织区域中提取补丁。用户可以根据自己的需求和数据集的特点,为这些参数设置不同的值。例如,如果某些补丁经常包含非组织区域(例如,由于切片制备过程中的污染),用户可能需要调整contour_fn的值,以更准确地确定哪些补丁应被视为前景。
3-3:两步运行(可选)
为了确保高质量的组织分割和提取相关的组织补丁,用户可以选择先执行分割(通常每张幻灯片大约需要1秒),检查分割结果,并根据需要调整特定幻灯片的参数,然后使用调整后的参数提取补丁。
也就是说,首先运行:
python create_patches_fp.py --source DATA_DIRECTORY --save_dir RESULTS_DIRECTORY --patch_size 256 --seg
这将只执行分割,而不提取补丁。分割完成后,用户可以手动检查每个幻灯片的分割结果,并根据需要调整分割参数。然后,用户可以再次运行CLAM脚本,这次使用调整后的参数来提取补丁。
上述命令将使用默认参数分割DATA_DIRECTORY中的每个幻灯片,并生成csv文件,但不会立即补丁(patches和stitches文件夹将为空)。
csv文件可以针对特定幻灯片进行调整,并通过–process_list CSV_FILE_NAME传递给脚本,以便脚本使用用户更新的规格。在调整分割参数之前,用户应先复制csv文件并为其指定新名称(例如,process_list_edited.csv),因为否则下次运行命令时会覆盖具有默认名称的文件。
然后,用户可以选择通过修改csv文件中相应字段的值来调整特定幻灯片的参数。process列存储了一个二进制变量(0或1),用于指示脚本是否应处理特定幻灯片。这允许用户只打开选择的几张幻灯片,以快速确认调整后的参数是否产生满意的结果。
例如,要使用用户更新的参数重新分割slide_1.svs,请根据需要修改其字段,将process单元格更改为1,保存csv文件,并将其名称传递给上述命令:
python create_patches_fp.py --source DATA_DIRECTORY --save_dir RESULTS_DIRECTORY --patch_size 256 --seg --process_list process_list_edited.csv
当对分割结果满意时,用户应将需要处理的幻灯片的process单元格更改为1,保存csv文件,并使用保存的csv文件进行补丁处理(就像在完全自动化的运行用例中一样,只需添加额外的csv文件参数):
python create_patches_fp.py --source DATA_DIRECTORY --save_dir RESULTS_DIRECTORY --patch_size 256 --seg --process_list CSV_FILE_NAME --patch --stitch
这样,脚本将根据csv文件中的参数和设置,对所有标记为需要处理的幻灯片进行补丁提取和后续处理。
这种两步运行的方法允许用户在分割阶段手动调整参数,并在确认分割结果后,使用这些调整后的参数进行最终的补丁提取,从而提高分割和补丁提取的质量。
四、使用切片级标签进行特征提取
注意,以下实验会调用GPU


# 设置环境变量CUDA_VISIBLE_DEVICES,指定使用的GPU设备编号为0
CUDA_VISIBLE_DEVICES=0 # 调用extract_features_fp.py脚本,用于从指定的数据集中提取特征
python extract_features_fp.py \# 指定存储HDF5格式数据的目录路径
--data_h5_dir /home/mailab015/CLAM/test \# 指定存储切片图像的目录路径
--data_slide_dir /home/mailab015/08-18/wsi_processing_tools/test/测试图像 \# 指定CSV文件的路径,就是上一步生成的csv文件
--csv_path /home/mailab015/CLAM/test/process_list_autogen.csv \# 指定提取的特征将保存的目录路径
--feat_dir /home/mailab015/CLAM/testFEATURES_DIRECTORY \# 设置批处理大小,即每次处理的样本数量
--batch_size 512 \# 指定切片图像文件的扩展名(你的是svs,就改成.svs)
--slide_ext .tif
执行上述代码以后报错,在尝试从Hugging Face Hub下载预训练模型时出现了网络连接问题。

在执行代码前添加下列代码即可解决问题
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"

上述代码产生以下文件结构:
FEATURES_DIRECTORY/├── h5_files├── slide_1.h5├── slide_2.h5└── ...└── pt_files├── slide_1.pt├── slide_2.pt└── ...
每个.h5文件包含一组提取的特征及其补丁坐标。为了加快训练速度,每个幻灯片还创建了一个.pt文件,其中只包含补丁特征。CSV文件应包含一个幻灯片文件名列表(不带文件名扩展名)以供处理。
五、使用UNI或CONCH模型(可选)
这一部分不是本期推文的重点,后面会有推文详细介绍如何使用,感兴趣的可以自己先研究一下
如果您打算使用UNI或CONCH模型,首先需要访问它们的HF页面来请求和下载模型权重。
- UNI: https://huggingface.co/MahmoodLab/UNI
- CONCH: https://huggingface.co/MahmoodLab/CONCH
成功下载模型检查点后,您需要在运行特征提取脚本之前设置CONCH_CKPT_PATH和UNI_CKPT_PATH环境变量到预训练编码器的检查点路径。
例如,如果您已将预训练的UNI和CONCH检查点分别下载并放置在checkpoints/conch和checkpoints/uni文件夹中,您可以设置环境变量如下:
export CONCH_CKPT_PATH=checkpoints/conch/pytorch_model.bin
export UNI_CKPT_PATH=checkpoints/uni/pytorch_model.bin
运行extract_features_fp.py时,也请将--model_name设置为’uni_v1’或’conch_v1’以使用相应的编码器。
请注意,这些编码器模型(尤其是UNI,它使用ViT-L)比默认的ResNet50编码器在计算上更昂贵,需要更多的GPU内存,所以如果您用完GPU内存,预计运行时间会更长,批次大小会相应减少。UNI将产生1024维特征,而CONCH将产生512维特征。
相关文章:
保姆级教程,带你复现病理AI的经典模型CLAM(一)|项目复现·24-08-19
小罗碎碎念 推文概述 复现CLAM的第一期推文 通过这期推文你首先会学会如何在服务器端使用jupyter编程,比你用其他的编译器(例如PyCharm、VS)会更加的清晰,对新手也更友好。 接着我会介绍如何进行数据预处理,以及你应…...
数据可视化之旅,从数据洞察到图表呈现,可视化的产品设计
图表作为数据可视化的重要工具,是对原始数据进行深度加工与解读的有效手段,它助力我们洞悉数据背后的真相,使我们能更好地适应这个由数据驱动的世界。无论是工作汇报、项目实施、产品设计、后台界面还是数据大屏展示,图表都扮演着…...

ArrayList 和 LinkedList 的区别是什么
数据结构实现:ArrayList 是动态数组的数据结构实现,而 LinkedList 是双向链表的数据结构实现。随机访问效率:ArrayList 比 LinkedList 在随机访问的时候效率要高,因为 LinkedList 是线性的数据存储方式,所以需要移动指…...

在Matlab中进行射频电路S、Z、Y、ABCD等参数的转换
在Matlab中进行射频电路S、Z、Y、ABCD等参数的转换 目录 在Matlab中进行射频电路S、Z、Y、ABCD等参数的转换1、转换案例-3dB电桥2、将转换结果应用到ADS中制造理想3dB电桥器件 在微带线的ABCD矩阵的推导、转换与级联-Matlab计算实例(S、Z、Y参数转换)中&…...
渗透实战——为喜欢的游戏“排忧解难”
本文仅用于技术研究学习,请遵守相关法律,禁止使用本文所提及的相关技术开展非法攻击行为,由于传播、利用本文所提供的信息而造成任何不良后果及损失,与本账号及作者无关。 资料查询来源- 安全社区与AI模型结合探索【文末申请免费…...

政务大数据解决方案(十)
政务大数据解决方案通过建立全面的集成数据平台,整合来自各政府部门的异构数据,运用大数据分析、人工智能和机器学习技术对数据进行深度挖掘与智能化处理,提供实时精准的决策支持,从而提升政策制定和实施的科学性与效率。该方案包…...

使用WebStorm进行高效的全栈JavaScript开发
使用WebStorm进行高效的全栈JavaScript开发,是一个涉及多方面技能与工具利用的过程。WebStorm,作为JetBrains公司推出的一款专为前端开发者和全栈工程师设计的集成开发环境(IDE),以其强大的功能、卓越的性能和友好的用…...

数据导入导出(EasyExcel)框架入门指南
写在前面 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站 文章目录 EasyExcel 框架概述依赖APIExcel 实体类注解写 Excel概念介绍写 Excel 通用参数WriteWorkbookWriteSheetWriteTable 代码…...

Ubuntu如何实现每天定时关机
要在Ubuntu中实现每天定时关机,你可以使用cron来安排定时任务。以下是具体的步骤: 步骤 1: 创建脚本 打开终端。使用文本编辑器创建一个新的文件。例如: nano ~/shutdown_script.sh 步骤 2: 编写脚本 在编辑器中输入以下内容:…...

【MySQL进阶】事务、存储引擎、索引、SQL优化、锁
一、事务 1.概念 事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向 系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。 例子:转账,要求扣钱和进账…...

BeanDefinitionOverrideException产生原因及解决方案
BeanDefinitionOverrideException 是 Spring 框架中与依赖注入(Dependency Injection)相关的异常。它通常在 Spring 应用程序启动时抛出,当 Spring 在加载应用程序上下文时,检测到有多个相同名称的 Bean 定义被加载,并…...

配置Prettier+Vscode setting提高前端开发效率
前言 大家好,上一篇一文读懂 系列的文章中我们介绍了前端的代码格式化校验工具ESLient。代码格式是进行自动校验了,但你还要一个个的微调,很麻烦不是吗? 本文介绍和ESLient配合使用的Prettier实现编译器自动将代码格式化。 同时也…...

系统架构师计算题(1)——计算机系统基础知识(上)
持续刷题,持续总结,持续更新! 目录 1. 文件系统 题型1:多级索引 2. 存储管理 题型1:页式存储 题型2:段式存储 题型3:段页式存储 3. 磁盘读取 题型1:访问耗时 4. RAID 题型1:计算容量 1. 文件系统 文件在系统中的存储结构有如下几种: (1) 连续结构。 连续结构…...

2024/8/18周报
文章目录 摘要Abstract蚁群算法背景基本步骤应用TSP问题蚁群算法具体实现 遗传算法基本原理主要步骤遗传算法的主要组件遗传算法的应用遗传算法的优点遗传算法的局限性示例代码 多目标优化算法多目标优化的基本概念多目标优化算法的分类NSGA-II 算法示例 总结 摘要 本周对项目…...

端点安全新纪元:EDR与XDR技术的融合应用
在数字时代,随着网络威胁的日益复杂化和多样化,端点安全成为了企业组织不可或缺的重要防线。传统的防病毒软件和防火墙等安全解决方案已难以满足当前的安全需求,而EDR(端点检测与响应)和XDR(扩展检测与响应…...

机器学习:多元线性回归模型
目录 前言 一、讲在前面 1.多元_血压.csv: 2.完整代码: 3.运行结果: 二、实现步骤 1.导入库 2.导入数据 3.绘制散点图(这步可以省略) 编辑 4.求特征和标签的相关系数 5.建立并训练线性回归模型 6.检验模…...

树莓派5环境配置笔记 新建虚拟python环境—安装第三方库—配置Thonny解释器
树莓派5虚拟环境配及第三方库的安装🚀 在完成了树莓派的系统下载和各项基础配置之后进入到了,传感器开发部分,在测试传感器开发之前我打算先安装一下自己需要的库,但是在我直接在系统的根目录下运行pip命令的时候总会报环境错误&a…...

浅谈Winform
一、Winform简介说明 C# 是一种面向对象的编程语言,由微软开发并作为.NET框架的主要编程语言。C# 设计时考虑了易用性,并且具有丰富的特性,如垃圾回收、异常处理、泛型、LINQ(Language Integrated Query)、异步编程等。…...

MySQL(二)——CRUD
文章目录 CRUD新增全列插入指定列插入插入查询结果 查询全列查询指定列查询查询字段为表达式表达式不包含字段表达式包含一个字段表达式包含多个字段 补充:别名去重查询排序条件查询 补充:运算符区间查询模糊查询NULL的查询 分页查询聚合查询聚合函数 分…...

presto高级用法(grouping、grouping sets)
目录 准备工作: 在hive中建表 在presto中计算 分解式 按照城市分组 统计人数 按照性别分组 统计人数 编辑 按照爱好分组 统计人数 编辑 按照城市和性别分组 统计人数 按照城市和爱好分组 统计人数 按照性别和爱好分组 统计人数 按照城市和性别还有…...

2026年便利店成交金额究竟要达到多少,才能摆脱亏损困境?
在便利店行业竞争日益激烈的当下,众多便利店品牌都在为实现盈利而努力。美喜福作为便利店行业的一员,在这一背景下有着独特的发展路径和潜力。那么,2026年便利店成交金额究竟要达到多少才能摆脱亏损困境呢?让我们结合美喜福的实际…...

CW32驱动S12SD紫外线传感器:I2C通信、数据解析与嵌入式实践
1. 项目概述与核心需求解析最近在做一个户外环境监测的小玩意儿,需要实时监测紫外线强度,选来选去,最终敲定了S12SD这款紫外线传感器模块。之所以选它,一方面是因为它直接输出数字信号,省去了模拟信号调理的麻烦&#…...

你的微信聊天记录,真的安全吗?揭秘永久保存数字记忆的开源方案
你的微信聊天记录,真的安全吗?揭秘永久保存数字记忆的开源方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHu…...

别再被html2canvas生成的图片糊一脸了!试试这个新版1.4.1的清晰度优化方案
深度解析html2canvas 1.4.1:告别图片模糊的现代解决方案 当我们需要将网页内容转换为图片时,html2canvas无疑是最常用的工具之一。然而,许多开发者在使用过程中都遭遇过生成的图片模糊不清的问题,尤其是在移动设备上表现更为明显。…...

3分钟高效掌握Python手机号查QQ号实用技巧
3分钟高效掌握Python手机号查QQ号实用技巧 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 手机号查QQ号是现代社交网络管理中的一项实用技能,通过Python工具可以快速实现手机号与QQ号的关联查询。这个开源项目提供了一个…...

如何快速掌握大众点评爬虫:解决动态字体加密的终极实战指南
如何快速掌握大众点评爬虫:解决动态字体加密的终极实战指南 【免费下载链接】dianping_spider 大众点评爬虫(全站可爬,解决动态字体加密,非OCR)。持续更新 项目地址: https://gitcode.com/gh_mirrors/di/dianping_sp…...

ARM1176JZF芯片架构与时钟管理深度解析
1. ARM1176JZF芯片架构概览 ARM1176JZF是ARMv6架构中的经典处理器内核,广泛应用于嵌入式系统和移动设备。这款芯片采用了先进的流水线设计和动态时钟调节技术,在性能与功耗之间实现了出色的平衡。开发芯片版本特别集成了完整的调试功能和性能监控单元&am…...

避开HAL库:STM32F103寄存器级PWM移相全桥配置避坑指南
STM32F103寄存器级PWM移相全桥实战:从原理到避坑指南 在嵌入式开发领域,许多工程师习惯使用HAL库或标准库进行STM32开发,这确实能提高开发效率。但当项目对时序精度、资源占用或性能有极致要求时,直接操作寄存器往往能带来更优的效…...

快速 AI 迭代仍然需要操作纪律
前言 配套资源:AI 辅助开发检查清单资源包,适合把本文的流程直接落成开发前检查表和复盘模板。 上一篇文章里,我把 AI 工作流拆成了几类任务模式:开发维护、探索学习、反馈确认。这个分类解决的是一个前置问题:在使用 …...

智能电视网页浏览新选择:TV Bro浏览器如何改变你的大屏体验
智能电视网页浏览新选择:TV Bro浏览器如何改变你的大屏体验 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 你是否曾在智能电视上尝试浏览网页,却…...