目标检测 | yolov10 原理和介绍
相关系列:
目标检测 | yolov1 原理和介绍
目标检测 | yolov2/yolo9000 原理和介绍
目标检测 | yolov3 原理和介绍
目标检测 | yolov4 原理和介绍
目标检测 | yolov5 原理和介绍
目标检测 | yolov6 原理和介绍
目标检测 | yolov7 原理和介绍
目标检测 | yolov8 原理和介绍
目标检测 | yolov9 原理和介绍
目标检测 | yolov10 原理和介绍
论文:https://arxiv.org/pdf/2405.14458
代码:https://github.com/THU-MIG/yolov10
- 引言:介绍了实时目标检测的重要性以及YOLO系列在这一领域的主导地位。指出现有YOLO模型在后处理和模型架构上存在的不足,包括对非极大值抑制(NMS)的依赖以及模型设计的不彻底检查,这些问题限制了模型的性能和效率。
- 相关工作:回顾了实时目标检测器的发展,包括YOLO系列和其他基于CNN的检测器,以及端到端目标检测方法,如DETR及其变体。
- YOLOv10方法论:
- 一致的双重分配(Consistent Dual Assignments):提出了一种新的训练策略,通过双重标签分配和一致的匹配度量实现无需NMS的YOLO训练,提高了推理效率。
- 全面效率-准确性驱动的模型设计策略:对YOLO的各个组件进行了全面优化,包括轻量级分类头、空间-通道解耦下采样、基于排名引导的块设计、大核卷积和部分自注意力模块,以提高计算效率和模型性能。
- 实验:
- 实验设置:使用COCO数据集进行训练和评估,采用与YOLOv8相同的训练设置。
- 与现有方法的比较:YOLOv10在不同模型规模下实现了最先进的性能和效率,例如,YOLOv10-S在相似的AP下比RT-DETR-R18快1.8倍,参数和FLOPs分别减少了2.8倍。
- 模型分析:
- 消融研究:验证了NMS-free训练和效率驱动模型设计的有效性。
- 效率驱动模型设计分析:展示了轻量级分类头、空间-通道解耦下采样和基于排名引导的块设计对减少参数和计算量的贡献。
- 准确性驱动模型设计分析:探讨了大核卷积和部分自注意力模块对提高性能的影响。
- 结论:YOLOv10通过提出的方法在实时端到端目标检测方面取得了显著的性能和效率,为未来在这一领域的研究提供了新的方向。
- 附录:提供了实现细节、一致匹配度量的详细推导、基于排名引导的块设计的算法细节、COCO数据集上的详细性能数据、YOLOv10在复杂场景下的可视化结果,以及对YOLOv10贡献、局限性和更广泛影响的讨论。
Abstract 摘要
在过去的几年里,YOLO 已成为实时目标检测领域的主要范式,因为它们在计算成本和检测性能之间有效平衡。研究人员探索了 YOLO 的架构设计、优化目标、数据增强策略等,取得了显着进展。然而,对非最大抑制(NMS)进行后处理的依赖阻碍了YOLO的端到端部署,并对推理延迟产生不利影响。此外,YOLOs中各个组件的设计缺乏全面和彻底的检测,导致计算冗余明显,限制了模型的能力。它使次优效率,以及性能改进的巨大潜力。在这项工作中,我们的目标是从后处理和模型架构中进一步推进 YOLO 的性能效率边界。为此,我们首先给出了YOLOs无NMS训练的一致对偶分配,同时带来了具有竞争力的性能和较低的推理延迟。此外,我们介绍了 YOLO 的整体效率-精度驱动模型设计策略。我们从效率和准确性的角度全面优化了YOLOs的各个组成部分,大大降低了计算开销,提高了能力。我们工作的结果是新一代YOLO系列,用于实时端到端目标检测,称为YOLOv10。大量的实验表明,YOLOv10在各种模型尺度上达到了最先进的性能和效率。例如,在COCO上相似的AP下,我们的YOLOv10-S比RT-DETR-R18快1.8倍,同时参数数量和FLOPs减少了2.8倍。与 YOLOv9-C 相比,YOLOv10-B 在相同性能下的延迟减少了 46%,参数减少了 25%。代码:https://github.com/THU-MIG/yolov10。
1 Introduction 简介
实时目标检测一直是计算机视觉领域的一个焦点,其目的是在低延迟下准确预测图像中物体的类别和位置。它被广泛应用于自动驾驶[3]、机器人导航[11]和目标跟踪[66]等各种实际应用中。近年来,研究人员专注于设计基于cnn的目标检测器来实现实时检测[18,22,43,44,45,51,12]。其中,YOLO 因其在性能和效率之间的良好平衡而越来越受欢迎 [2, 19 , 27 , 19 , 20 , 59, 54, 64 , 7, 65, 16,27]。YOLOs的检测流水线由两部分组成:模型正向过程和NMS后处理。然而,它们都仍然存在缺陷,导致精度延迟边界次优。
具体来说,YOLO 在训练期间通常采用一对多标签分配策略,其中一个真实对象对应于多个正样本。尽管产生了卓越的性能,但这种方法需要 NMS 在推理过程中选择最佳正预测。这会减慢推理速度并使性能对 NMS 的超参数敏感,从而防止 YOLO 实现最佳端到端部署 [71]。解决这个问题的一种方法是采用最近引入的端到端DETR架构[4,74,67,28,34,40,61]。例如,RT-DETR[71]提出了一种有效的混合编码器和不确定性最小查询选择,将DETR推进到实时应用领域。然而,部署 DETR 的固有复杂性阻碍了它能够在准确性和速度之间获得最佳平衡。另一条线是探索基于 CNN 的检测器的端到端检测,它通常利用一对一的分配策略来抑制冗余预测 [5, 49, 60, 73, 16]。然而,它们通常引入额外的推理开销或实现次优性能。
此外,模型架构设计仍然是YOLOs的一个基本挑战,它对精度和速度有重要影响[45,16,65,7]。为了实现更高效和有效的模型架构,研究人员探索了不同的设计策略。主干提出了各种主要计算单元来增强特征提取能力,包括DarkNet[43,44,45]、CSPNet[2]、EfficientRep[27]和ELAN[56,58]等。对于颈部,探索了PAN[35]、BiC[27]、GD[54]和RepGFPN[65]等来增强多尺度特征融合。此外,还研究了模型缩放策略[56,55]和重新参数化[10,27]技术。虽然这些努力取得了显着的进步,但仍然缺乏从效率和准确性角度对 YOLO 中各种组件的全面检查。因此,YOLOs中仍然存在相当大的计算冗余,导致参数利用率低,效率次优。此外,由此产生的约束模型能力也会导致性能下降,从而为准确性改进留下了充足的空间。
在这项工作中,我们旨在解决这些问题并进一步推进 YOLO 的精度-速度边界。我们在整个检测管道中同时针对后处理和模型架构。为此,我们首先通过为具有双重标签分配和一致匹配度量的无 NMS YOLO 呈现一致的双重分配策略来解决后处理中冗余预测问题。它允许模型在训练期间享受丰富和谐的监督,同时在推理过程中消除对 NMS 的需求,从而提高竞争性能。其次,通过对YOLOs中的各种组件进行全面检查,提出了模型体系结构的整体效率-精度驱动模型设计策略。为了提高效率,我们提出了轻量级分类头、空间通道解耦下采样和秩引导块设计,以减少所表现出的计算冗余并实现更高效的架构。为了准确性,我们探索了大内核卷积,并提出了有效的部分自注意力模块来增强模型能力,利用低成本性能改进的潜力。
基于这些方法,我们成功地实现了一系列具有不同模型尺度的新的实时端到端检测器,即YOLOv10-N / S / M / B / L / X。在目标检测标准基准(即COCO[33])上的大量实验表明,我们的YOLOv10在各种模型尺度上的计算精度权衡方面的性能明显优于以前的最先进模型。如图1所示,在相同的性能下,我们的YOLOv10-S / X分别比RT-DETRR18 / R101快1.8×/ 1.3×。与YOLOv9-C相比,YOLOv10-B在相同的性能下实现了46%的延迟降低。此外,YOLOv10 表现出高效的参数利用率。我们的 YOLOv10-L / X 分别比 YOLOv8-L / X 高 0.3 AP 和 0.5 AP,参数数量分别减少了 1.8 倍和 2.3 倍。YOLOv10-M 与 YOLOv9-M / YOLO-MS 相比实现了 2 个相似的 AP,参数减少了 23% / 31%。我们希望我们的工作能够激发该领域的进一步研究和进步。

图 1:在延迟精度(左)和大小精度(右)权衡方面与其他比较。我们使用官方预训练模型测量端到端延迟。
2 Related Work 相关工作
- Real-time object detectors 实时对象检测器。
实时目标检测旨在对低延迟下的对象进行分类和定位,这对于现实世界的应用至关重要。在过去的几年里,人们投入了大量的努力来开发高效的检测器[18,51,43,32,72,69,30,29,39]。特别是YOLO系列[43,44,45,2,19,27,56,20,59]作为主流系列。YOLOv1、YOLOv2 和 YOLOv3 识别由主干、颈部和头部三部分组成的典型检测架构 [43, 44, 45]。YOLOv4 [2] 和 YOLOv5 [19] 引入了 CSPNet [57] 设计来取代 DarkNet [42],以及数据增强策略、增强 PAN 和更多种类的模型尺度等。 YOLOv6 [27] 分别提出了颈部和主干的 BiC 和 SimCSPSPPF,具有锚辅助训练和自蒸馏策略。YOLOv7[56]为丰富的梯度流路径引入了E-ELAN,探索了几种可训练的免费赠品袋方法。YOLOv8[20]提出了C2f构建块,用于有效的特征提取和融合。Gold-YOLO[54]提供了先进的GD机制来提高多尺度特征融合能力。YOLOv9[59] 提出了 GELAN 来改进架构和 PGI 以增强训练过程。 - End-to-end object detectors.端到端对象检测器。
端到端目标检测已经成为传统管道的范式转变,提供了精简的体系结构[48]。DETR[4]引入了变压器架构,采用匈牙利损失实现一对一匹配预测,从而消除了手工制作的组件和后处理。因此,已经提出了各种DETR变体来提高其性能和效率[40,61,50,28,34]。Deformable-DETR[74]利用多尺度可变形注意模块来加速收敛速度。DINO[67]将对比去噪、混合查询选择和展望两种方案集成到DETRs中。RT-DETR[71]进一步设计了高效的混合编码器,提出了不确定性最小查询选择来提高准确性和延迟。实现端到端对象检测的另一条线是基于 CNN 检测器。可学习的NMS[23]和关系网络[25]提出了另一种网络来去除检测器的重复预测。OneNet [49] 和 DeFCN [60] 提出了一种一对一匹配策略,以实现使用全卷积网络的端到端目标检测。FCOSps[73]引入了一个正样本选择器来选择最优样本进行预测。
3 Methodology 方法
3.1 Consistent Dual Assignments for NMS-free Training 无 NMS 训练的一致对偶分配
在训练过程中,YOLO[20,59,27,64]通常利用TAL[14]为每个实例分配多个正样本。采用一对多分配会产生丰富的监督信号,促进优化并实现卓越的性能。然而,它需要 YOLO 依赖于 NMS 后处理,这导致部署的推理效率次优。虽然之前的工作 [49, 60, 73, 5] 探索了一对一的匹配来抑制冗余预测,但它们通常引入额外的推理开销或产生次优性能。在这项工作中,我们提出了一种用于具有双重标签分配和一致匹配度量的 YOLO 的无 NMS 训练策略,实现了高效率和具有竞争力的性能。
Dual label assignments 双重标签分配
与一对多分配不同,一对一匹配只为每个基本事实分配一个预测,避免了 NMS 后处理。然而,它导致了弱监督,这导致了次优的准确性和收敛速度[75]。幸运的是,这种缺陷可以通过一对多分配来补偿[5]。为此,我们为 YOLO 引入双重标签分配来组合这两种策略的优点。具体来说,如图 2(a) 所示,我们为 YOLO 合并了另一个一对一的头。它保留了相同的结构,并采用与原始一对多分支相同的优化目标,但利用一对一匹配来获得标签分配。在训练期间,两个头部与模型联合优化,允许主干和颈部享受一对多分配提供的丰富监督。在推理过程中,我们丢弃一对多的头部并利用一对一的头部进行预测。这使得 YOLO 能够用于端到端部署,而不会产生任何额外的推理成本。此外,在一对一匹配中,我们采用前一种选择,实现了与匈牙利匹配[4]相同的性能,训练时间更少。

图 2:(a) 无 NMS 训练的一致双重分配。(b) YOLOv8-S 的一对多结果的 Top-1/5/10 中一对一分配的频率,默认使用 α o 2 m = 0.5 α_{o2m}=0.5 αo2m=0.5 和 β o 2 m = 6 β_{o2m}=6 βo2m=6 [20]。为了保持一致性, α o 2 o = 0.5 α_{o2o}=0.5 αo2o=0.5; β o 2 o = 6 β_{o2o}=6 βo2o=6。对于不一致, α o 2 o = 0.5 α_{o2o}=0.5 αo2o=0.5; β o 2 o = 2 β_{o2o}=2 βo2o=2。
Consistent matching metric 一致的匹配指标
在分配过程中,一对一和一对多的方法都利用度量来定量评估预测和实例之间的一致性水平。为了实现两个分支的预测感知匹配,我们采用了统一的匹配度量,即
m ( α , β ) = s ⋅ p α ⋅ I o U ( b ^ , b ) β , (1) m(α, β) = s · p^α · IoU(\hat{b}, b)^β ,\tag{1} m(α,β)=s⋅pα⋅IoU(b^,b)β,(1)
其中 p p p 是分类分数, b ^ \hat{b} b^ 和 b b b 分别表示预测和实例的边界框。 s s s表示空间先验,指示预测的锚点是否在实例内[20,59,27,64]。 α α α 和 β β β 是平衡语义预测任务和位置回归任务影响的两个重要超参数。我们将一对多和一对一指标分别表示为 m o 2 m = m ( α o 2 m , β o 2 m ) m_{o2m}=m(α_{o2m}, β_{o2m}) mo2m=m(αo2m,βo2m) 和 m o 2 o = m ( α o 2 o , β o 2 o ) m_{o2o}=m(α_{o2o}, β_{o2o}) mo2o=m(αo2o,βo2o)。这些指标会影响两个头部的标签分配和监督信息。
在双重标签分配中,一对多分支提供了比一对一分支更丰富的监督信号。直观地说,如果我们可以将一对一头部的监督与一对多头部的监督协调,我们可以将一对一头部优化到一对多头部优化的方向。因此,一对一头部在推理过程中可以提供更高质量的样本,从而获得更好的性能。为此,我们首先分析了两个头部之间的监督差距。由于训练期间的随机性,我们从使用相同值初始化的两个头开始开始检查并产生相同的预测,即一对一头和一对多头为每个预测实例对生成相同的 p p p 和 I o U IoU IoU。我们注意到两个分支的回归目标不冲突,因为匹配的预测共享相同的目标,并且忽略不匹配的预测。因此,监督差距在于不同的分类目标。给定一个实例,我们将其最大的 I o U IoU IoU 表示为 u ∗ u^∗ u∗,类似的,最大的一对多和一对一匹配分数分别表示为 m o 2 m ∗ m^∗_{o2m} mo2m∗ 和 m o 2 o ∗ m^∗_{o2o} mo2o∗。假设一对多分支产生正样本 Ω Ω Ω,一对一分支选择第 i i i个预测,度量为 m o 2 o , i = m o 2 o ∗ m_{o2o,i}=m^*_{o2o} mo2o,i=mo2o∗ ,那么我们可以为 j ∈ Ω j∈Ω j∈Ω 导出分类目标 t o 2 m , j = u ∗ ⋅ m o 2 m , j m o 2 m ∗ ≤ u ∗ t_{o2m,j}=u^*·\frac{m_{o2m},j}{m^*_{o2m}}≤u * to2m,j=u∗⋅mo2m∗mo2m,j≤u∗ ,为任务对齐损失导出分类目标 t o 2 o , i = u ∗ ⋅ m o 2 o , i m o 2 o ∗ = u ∗ t_{o2o,i}=u^*·\frac{m_{o2o},i}{m^*_{o2o}}=u * to2o,i=u∗⋅mo2o∗mo2o,i=u∗ ,如[20,59,27,64,14]。因此,两个分支之间的监督差距可以由不同分类目标的1-Wasserstein距离[41]推导出来,即:
A = t o 2 o , i − Ⅱ ( i ∈ Ω ) t o 2 m , i + ∑ k ∈ Ω ∖ { i } t o 2 m , k , (2) A = t_{o2o,i} − Ⅱ(i ∈ Ω)t_{o2m,i} + { \sum_{k∈Ω \setminus \{i\}} {t_{o2m},k} } \tag{2}, A=to2o,i−Ⅱ(i∈Ω)to2m,i+k∈Ω∖{i}∑to2m,k,(2)
我们可以观察到差距随着 t o 2 m , i t_{o2m},i to2m,i 的增加而减小,即 i i i 在 Ω Ω Ω 内排名更高。当 t o 2 m , i = u ∗ t_{o2m},i=u^* to2m,i=u∗时,它达到最小值,即 i i i是 Ω Ω Ω中最好的正样本,如图2(a)所示。为此,我们提出了一致的匹配度量,即 α o 2 o = r ⋅ α o 2 m α_{o2o}=r·α_{o2m} αo2o=r⋅αo2m和 β o 2 o = r ⋅ β o 2 m β_{o2o}=r·β_{o2m} βo2o=r⋅βo2m,这意味着 m o 2 o = m o 2 m r m_{o2o}=m^r_{ o2m} mo2o=mo2mr。因此,一对多头部的最佳正样本对于一对一头部也是最好的。因此,两个头部都可以一致地和谐地优化。为简单起见,我们默认取 r = 1 r=1 r=1,即 α o 2 o = α o 2 m α_{o2o}=α_{o2m} αo2o=αo2m 和 β o 2 o = β o 2 m β_{o2o}=β_{o2m} βo2o=βo2m。为了验证改进的监督对齐,我们计算了训练后一对多结果的前 top-1 / 5 / 10 内的一对一匹配对的数量。如图2.(B)所示,在一致的匹配度量下,对齐得到了改进。有关数学证明的更全面的理解,请参阅附录。
3.2 Holistic Efficiency-Accuracy Driven Model Design 整体效率-精度驱动模型设计
除了后处理之外,YOLO 的模型架构对效率和准确性权衡也提出了巨大挑战 [45, 7, 27]。虽然以前的工作探索了各种设计策略,仍然缺乏对 YOLO 中各个组件的全面检查。因此,模型架构表现出不可忽略的计算冗余和约束能力,这阻碍了其实现高效率和性能的潜力。在这里,我们的目标是从效率和准确性的角度为 YOLO 整体执行模型设计。
Efficiency driven model design 效率驱动模型设计
YOLO 中的组件由茎、下采样层、具有基本构建块的阶段和头部组成。词干的计算成本很少,因此我们对其他三个部分进行了效率驱动模型设计。
- Lightweight classification head 轻量级分类头。分类和回归头通常在 YOLO 中共享相同的架构。然而,它们在计算开销上表现出显着的差异。例如,YOLOv8-S中分类头(5.95G/1.51M)的FLOPs和参数计数分别为回归头(2.34G/0.64M)的2.5×和2.4×。然而,在分析分类错误和回归误差的影响后(见表。6),我们发现回归头对YOLOs的性能更有意义。因此,我们可以减少分类头的开销,而不必担心极大地损害性能。因此,我们简单地对分类头采用轻量级架构,它由两个深度可分离卷积 [24, 8] 组成,内核大小为 3×3,然后是 1×1 卷积。
- Spatial-channel decoupled downsampling 空间通道解耦下采样。YOLO 通常利用步长为 2 的常规 3×3 标准卷积,同时实现空间下采样(从 H × W H × W H×W 到 H 2 × W 2 \frac{H}{2} × \frac{W}{2} 2H×2W )和通道变换(从 C C C 到 2 C 2C 2C)。这引入了 O ( 9 2 H W C 2 ) O(\frac{9}{2} HWC^2) O(29HWC2) 的不可忽略的计算成本和 O ( 18 C 2 ) O(18C^2) O(18C2) 的参数计数。相反,我们建议将空间缩减和通道增加操作解耦,从而实现更有效的下采样。具体来说,我们首先利用逐点卷积调制通道维度,然后利用深度卷积进行空间下采样。这将计算成本降低到 O ( 2 H W C 2 + 9 2 H W C ) O(2HWC^2 + \frac{9}{2} HWC) O(2HWC2+29HWC),参数计数降低到 O ( 2 C 2 + 18 C ) O(2C^2 + 18C) O(2C2+18C)。同时,它在下采样过程中最大化信息保留,导致与延迟降低竞争性能。
- Rank-guided block design Rank-guided块设计。YOLOs通常对所有阶段使用相同的基本构建块[27,59],例如YOLOv8[20]的瓶颈块。为了彻底检查 YOLO 的这种同质设计,我们利用内在排名 [31, 15] 来分析每个阶段的冗余 2。具体来说,我们计算每个阶段最后一个基本块中最后一个卷积的数值秩,它计算大于阈值的奇异值的数量。图3.(A)给出了YOLOv8的结果,表明深层阶段和大模型容易表现出更多的冗余。这一观察表明,简单地对所有阶段应用相同的块设计对于最佳容量效率权衡是次优的。为了解决这个问题,我们提出了一种秩引导的块设计方案,该方案旨在降低使用紧凑架构设计被证明是冗余的阶段的复杂性。我们首先提出了一种紧凑的倒块(CIB)结构,该结构采用廉价的深度卷积进行空间混合,采用高性价比的点卷积进行通道混合,如图3 (b)所示。它可以作为有效的基本构建块,例如嵌入在 ELAN 结构 [58, 20] 中(图 3.(b))。然后,我们提倡秩引导的块分配策略,在保持竞争容量的同时达到最佳效率。具体来说,给定一个模型,我们根据其内在等级升序对其所有阶段进行排序。我们进一步检查了用 CIB 替换领先阶段基本块的性能变化。如果与给定模型相比没有性能下降,我们继续替换下一阶段,否则停止该过程。因此,我们可以在阶段和模型尺度上实现自适应紧凑块设计,在不影响性能的情况下实现更高的效率。由于页面限制,我们在附录中提供了算法的详细信息。

图 3:(a) YOLOv8 中跨阶段和模型的内在排名。主干颈部和颈部的阶段按照模型前向过程的顺序编号。对于 y 轴,数值秩 r 归一化为 r / C o r/C_o r/Co,其阈值默认设置为 λ m a x / 2 λmax/2 λmax/2,其中 C o C_o Co 表示输出通道的数量, λ m a x λ_{max} λmax 是最大奇异值。可以观察到,深层阶段和大模型表现出较低的内在等级值。(b) 紧凑的倒置块 (CIB)。© 部分自注意力模块 (PSA)。
Accuracy driven model design 精度驱动模型设计
我们进一步探索了用于精度驱动设计的大内核卷积和自注意力,旨在以最小的成本提高性能。
- Large-kernel convolution 大内核卷积
采用大核深度卷积是扩大感受野和增强模型能力的有效方法[9,38,37]。然而,简单地在所有阶段利用它们可能会在用于检测小物体的浅层特征中引入污染,同时在高分辨率阶段[7]中引入显著的I/O开销和延迟。因此,我们建议在深度阶段利用 CIB 中的大内核深度卷积。具体来说,我们按照 [37] 将 CIB 中第二个 3×3 深度卷积的内核大小增加到 7×7。此外,我们采用结构重新参数化技术 [10, 9, 53] 来引入另一个 3×3 深度卷积分支来缓解优化问题,而无需推理开销。此外,随着模型大小的增加,其感受野自然扩大,这得益于使用大内核卷积递减。因此,我们只对小模型尺度采用大核卷积。 - Partial self-attention (PSA)部分自注意力 (PSA)
由于其卓越的全局建模能力[36,13,70],自我注意[52]被广泛应用于各种视觉任务中。然而,它表现出较高的计算复杂度和内存占用。为了解决这个问题,鉴于流行的注意力头冗余 [63],我们提出了一种有效的部分自注意力 (PSA) 模块设计,如图 3.© 所示。具体来说,我们在 1×1 卷积之后将跨通道的特征均匀地划分为两部分。我们只将一部分输入由多头自注意力模块 (MHSA) 和前馈网络 (FFN) 组成的 NPSA 块。然后通过 1×1 卷积连接和融合两部分。此外,我们遵循[21]将查询和键的维度分配给MHSA中值的一半,并将LayerNorm[1]替换为BatchNorm[26]进行快速推理。此外,PSA 仅放置在分辨率最低的第 4 阶段之后,避免了自注意力二次计算复杂度的过度开销。通过这种方式,全局表示学习能力可以以较低的计算成本合并到YOLOs中,这很好地增强了模型的能力,从而提高了性能。
4 Experiments 实验
4.1 Implementation Details 实施细节
我们选择 YOLOv8 [20] 作为我们的基线模型,因为它具有可搜索的延迟-精度平衡及其在各种模型大小中的可用性。我们对无 NMS 训练采用一致的双重分配,并在此基础上进行整体效率-精度驱动模型设计,带来了我们的 YOLOv10 模型。YOLOv10 与 YOLOv8 具有相同的变体,即 N / S / M / L / X。此外,我们通过简单地增加YOLOv10-M的宽度比例因子,推导出一种新的变体YOLOv10-B。我们在相同的从头开始训练设置下在COCO[33]上验证了所提出的检测器[20,59,56]。此外,所有模型的延迟在带有TensorRT FP16的T4 GPU上进行了测试,遵循[71]。
4.2 Comparison with state-of-the-arts 与最先进技术的比较
如表中所示。如图 1 所示,我们的 YOLOv10 在各种模型尺度上实现了最先进的性能和端到端延迟。我们首先将 YOLOv10 与我们的基线模型(即 YOLOv8)进行比较。在 N / S / M / L / X 5 变体上,我们的 YOLOv10 实现了 1.2% / 1.4% / 0.5% / 0.5% AP 改进,28% / 36% / 41% / 44% / 57% 的参数少,23% / 24% / 25% / 27% / 38% 的计算量少,70% / 65% / 50% / 41% / 37% 的延迟降低。与其他 YOLO 相比,YOLOv10 在准确性和计算成本之间也表现出卓越的权衡。具体来说,对于轻量级和小型模型,YOLOv10-N / S 比 YOLOv6-3.0-N / S 高 1.5 AP 和 2.0 AP,参数减少了 51% / 61%,计算量减少了 41% / 52%。对于中等模型,与 YOLOv9-C / YOLO-MS 相比,YOLOv10-B / M 在相同或更好的性能下分别享有 46% / 62% 的延迟降低。对于大型模型,与 Gold-YOLO-L 相比,我们的 YOLOv10-L 的参数减少了 68%,延迟降低了 32%,AP 显着提高了 1.4%。此外,与 RT-DETR 相比,YOLOv10 获得了显着的性能和延迟改进。值得注意的是,在相同的性能下,YOLOv10-S / X 的推理速度分别比 RT-DETR-R18 / R101 快 1.8 倍和 1.3 倍。这些结果很好地证明了YOLOv10作为实时端到端检测器的优越性。
我们还使用原始的一对多训练方法将 YOLOv10 与其他 YOLO 进行比较。在这种情况下,我们考虑模型前向过程 (Latencyf) 的性能和延迟,遵循 [56, 20, 54]。如表中所示。1、YOLOv10 还展示了不同模型尺度上最先进的性能和效率,表明了我们的架构设计的有效性。

表 1:与最先进的比较。延迟是使用官方预训练模型来衡量的。Latencyf 表示没有后处理的模型前向过程中的延迟。† 表示 YOLOv10 使用 NMS 的原始一对多训练的结果。下面的所有结果都没有额外的高级训练技术,如知识蒸馏或 PGI 进行公平比较。
4.3 Model Analyses 模型分析
Ablation study消融研究
我们在 表2中展示了基于 YOLOv10-S 和 YOLOv10-M 的消融结果.可以观察到,我们的具有一致双重分配的无NMS训练显著降低了YOLOv10-S的端到端时延4.63ms,同时保持了44.3%AP的竞争性能。此外,我们的效率驱动模型设计导致减少了 11.8 M 参数和 20.8 GFLOP,YOLOv10-M 的延迟减少了 0.65ms,很好地显示了其有效性。此外,我们的精度驱动模型设计在YOLOv10-S和YOLOv10-M上实现了1.8 AP和0.7 AP的显著改进,分别只有0.18ms和0.17ms的延迟开销,很好地证明了它的优越性。

表2:COCO上YOLOv10-S和YOLOv10-M的消融研究。
Analyses for NMS-free training 无NMS训练的分析
- Dual label assignments 双重标签分配。
我们为无 NMS 的 YOLO 提出了双重标签分配,它可以在推理过程中为一对多 (o2m) 分支带来丰富的监督,为一对一 (o2o) 分支提供高效率。我们基于 YOLOv8-S 验证其好处,即 Tab 中的 #1。2. 具体来说,我们引入了仅使用 o2m 分支和仅 o2o 分支进行训练的基线。如表3中所示,我们的双重标签分配实现了最佳的AP-延迟权衡。

表 3:双重分配。
- Consistent matching metric 一致的匹配指标。
我们引入了一致的匹配度量,使一对一头部与一对多头部更加和谐。我们基于 YOLOv8-S 验证其好处,即 Tab 中的 #1。2,在不同的 αo2o 和 βo2o 下。如表4中所示,所提出的一致匹配度量,即αo2o=r·αo2m和βo2o=r·βo2m,可以达到最佳性能,其中αo2m=0.5和βo2m=6.0在一对多头部[20]。这种改进可以归因于监督差距的减少(等式(2)),它提供了两个分支之间的改进监督对齐。此外,所提出的一致匹配度量消除了对详尽超参数调整的需要,这在实际场景中很有吸引力。

表 4:匹配度量
Analyses for efficiency driven model design 效率驱动模型设计的分析
我们进行了实验,以逐步结合基于YOLOv10-S/M的效率驱动设计元素。我们的基线是没有效率精度驱动模型设计的 YOLOv10-S/M 模型,即 Tab 中的 #2/#6。2. 如表5中所示,每个设计组件,包括轻量级分类头、空间通道解耦下采样和秩引导块设计,有助于减少参数计数、FLOPs和延迟。重要的是,这些改进是在保持竞争性能的同时实现的。

表 5:效率。对于YOLOv10-S/M
- Lightweight classification head 轻量级分类头
我们根据表5中 #1 和 #2 的 YOLOv10-S 分析了预测的类别和定位误差对性能的影响,如[6]。具体来说,我们通过一对一分配将预测与实例进行匹配。然后,我们用实例标签替换预测的类别分数,从而得到没有分类错误的 A P w / o c v a l AP^{val}_{w/o\ c} APw/o cval。类似地,我们将预测的位置替换为实例的位置,产生没有回归错误的 A P w / o r v a l AP^{val}_{w/o\ r} APw/o rval。如表6中所示、 A P w / o r v a l AP^{val}_{ w/o\ r} APw/o rval 远高于 A P w / o c v a l AP^{val}_{ w/o\ c} APw/o cval,表明消除回归误差可以实现更大的改进。因此,性能瓶颈更多地在于回归任务。因此,采用轻量级分类头可以在不损害性能的情况下获得更高的效率。

表6:分类结果
- Spatial-channel decoupled downsampling 空间通道解耦下采样
我们解耦下采样操作以提高效率,其中通道维度首先通过逐点卷积 (PW) 增加,然后通过深度卷积 (DW) 降低分辨率以获得最大信息保留。我们将其与DW的空间缩减基线方法进行了比较,然后是PW的通道调制,基于表5中#3的YOLOv10-S。 如表7中所示,我们的下采样策略通过在下采样过程中享受更少的信息丢失,实现了0.7%的AP改进。

表7:d.s.结果
在目标检测领域,"Results of d.s."可能指的是D-S证据理论(Dempster-Shafer evidence theory)的应用结果,或者DSSD(Deconvolutional Single Shot Detector)的检测结果。以下是两种可能的解释:
D-S证据理论:D-S证据理论在目标识别中有着广泛的应用,是一种有效的数据融合方法。然而,在证据高度冲突时,可能会产生有悖常理的结果。为了解决这个问题,有研究提出了一种改进算法,引入了传感器的可信度,以提高水下目标识别的准确性和有效性。
DSSD:DSSD是一种基于SSD(Single Shot Detector)的改进模型,它通过添加反卷积层和预测模块来提高对小目标的检测精度。DSSD的核心思想是利用Top Down的网络结构,通过反卷积层实现深层特征和浅层特征的融合,并在预测阶段添加基于残差块构建的预测模块,以优化用于分类和边界框任务的特征图。
- Compact inverted block (CIB) 紧凑型倒置块(CIB)
我们将 CIB 引入紧凑的基本构建块。我们根据表5中 #4 的 YOLOv10-S 验证其有效性。具体来说,我们引入倒置残差块[46] (IRB)作为基线,实现了次优的43.7% AP,如表8所示。然后我们在它之后附加一个3×3深度卷积(DW),记为“IRB-DW”,它带来0.5%的AP改善。与“IRB-DW”相比,我们的CIB以最小的开销增加了另一个DW,从而进一步提高了0.3%的AP,表明了它的优越性。

表 8:CIB 的结果
- Rank-guided block design - Rank-guided块设计
我们引入了秩引导块设计,自适应地集成紧凑的块设计,以提高模型效率。我们根据表5中 #3 的 YOLOv10-S 验证其好处。基于内在等级按升序排序的阶段是阶段 8-4-7-3-5-1-6-2,如图 3(a) 所示。如表9中所示,当用高效的 CIB 逐步替换每个阶段的瓶颈块时,我们观察到从第 7 阶段开始的性能下降。在第 8 阶段和第 4 阶段具有较低的内在等级和更多的冗余,因此我们可以在不影响性能的情况下采用有效的块设计。这些结果表明,rank-guided 块设计可以作为更高模型效率的有效策略。

表 9:Rank-guided
Analyses for accuracy driven model design 精度驱动模型设计的分析
我们展示了基于YOLOv10-S/M逐步集成精度驱动设计元素的结果。我们的基线是在结合效率驱动设计后 YOLOv10-S/M 模型,即 表2 中的 #3/#7。如表10中所示,采用大核卷积和PSA模块,在0.03ms和0.15ms的最小延迟增加下,YOLOv10-S的AP和1.4%AP的性能分别提高了0.4%和1.4%。请注意,YOLOv10-M 不使用大内核卷积(见表 12)。

表 10:准确性。对于 S/M。
- Large-kernel convolution 大内核卷积。
我们首先研究了基于 表10 中 #2 的 YOLOv10-S 的不同内核大小的影响。 如表11中所示,随着内核大小的增加而增加,并在 7×7 的内核大小附近停滞,性能有所提高,表明感知场大的好处。此外,在训练期间去除重新参数化分支可实现 0.1% 的 AP 退化,显示了它对优化的有效性。此外,我们基于 YOLOv10-N / S / M 检查了大内核卷积在模型尺度上的好处。如表12中所示,由于其固有的广泛感受野,它对大型模型(即 YOLOv10-M)没有改进。因此,我们只对小型模型采用大内核卷积,即 YOLOv10-N / S。

表 11:L.k。结果。

表 12:L.k。使用
- Partial self-attention (PSA) 部分自注意力(PSA)。
我们引入了PSA,通过在最小成本下结合全局建模能力来提高性能。我们首先在表10中基于 #3 的 YOLOv10-S 来验证其有效性。具体来说,我们引入变压器块,即MHSA和FFN作为基线,记为“Trans”。如表13中所示, 与之相比,PSA 带来了 0.3% 的 AP 改进,延迟减少了 0.05ms。性能提升可能是由于通过减少注意力头的冗余来缓解自注意力中的优化问题 [62, 9]。此外,我们研究了不同 NPSA 的影响。如表13中所示,将 NPSA 增加到 2 可以获得 0.2% 的 AP 改进,但延迟开销为 0.1 毫秒。因此,我们默认将 NPSA 设置为 1,以提高模型能力,同时保持高效率。

表 13:PSA 结果
5 Conclusion 结论
在本文中,我们在 YOLO 的检测管道中同时针对后处理和模型架构。对于后处理,我们提出了用于无 NMS 训练的一致双重分配,实现了高效的端到端检测。对于模型架构,我们引入了整体效率-精度驱动模型设计策略,提高了性能-效率权衡。这些带来了我们的YOLOv10,一个新的实时端到端对象检测器。大量的实验表明,与其他先进的检测器相比,YOLOv10实现了最先进的性能和延迟,很好地证明了它的优越性。
相关文章:
目标检测 | yolov10 原理和介绍
相关系列: 目标检测 | yolov1 原理和介绍 目标检测 | yolov2/yolo9000 原理和介绍 目标检测 | yolov3 原理和介绍 目标检测 | yolov4 原理和介绍 目标检测 | yolov5 原理和介绍 目标检测 | yolov6 原理和介绍 目标检测 | yolov7 原理和介绍 目标检测 | yolov8 原理和…...

基于Springboot 和Vue 的高校宿舍管理系统源码
网络上很多宿舍管理系统都不完整,大多数缺少数据库文件,所在使用极其不方便,由于本人程序员,根据代码,自己花时间不全了数据库文件,并且可以完美运行!!!!&…...

3:2比例的程序员专业显示器,效率提升显著,摸鱼时间又多了
对于我们程序员来说,显示器的重要性不言而喻,作为我们与代码交流的直接工具,他影响着我们的工作效率、舒适度和整体编程体验。我在家用的是自己笔记本的屏幕,简单写写代码还行,涉及到多任务协同或者大代码量开发就有点…...

vue3 cascader省市区三级联动如何指定字段,如何根据id查到对应的名字
如果我们接口数据字段名不是value和code。要加个props :props"{ value:code,label:regionName}"根据id查name需要一个ref和一个change事件<el-cascader :options"areaData" ref"addressCodeRef" change"handleChange" :props"…...
)
算法4:前缀和(上)
文章目录 一维前缀和二维前缀和寻找数组的中心下标除自身以外数组的乘积 一维前缀和 二维前缀和 寻找数组的中心下标 class Solution { public:int pivotIndex(vector<int>& nums) {int n nums.size();vector<int> f(n), g(n);f[0] nums[0];g[n - 1] num…...

美国政府紧急应对三星Galaxy手机安全漏洞
一、美国政府紧急通知更新三星Galaxy手机系统 美国政府近日发布紧急通知,要求联邦政府雇员在8月28日前更新三星Galaxy手机系统,否则将面临禁止使用这些设备的后果。这是继7月针对Pixel手机用户的类似要求之后的又一次紧急行动。此次事件的导火索是谷歌发…...

看 逆行人生
电影和我的职业本身有相关性,而且我特别喜欢徐峥执导的电影,这次的题材也算是碰上自己的胃口。 周六,下了大半天的雨,早上驱车到公司加班,下午六点多到时候特别想去看电影,果断再驱车从公司赶回来ÿ…...

0819、0820梳理及一些面试题梳理
一、抓包分析 二、HTTP服务器 三、动态库与静态库 四、一些面试题 指针数组和数组指针的区别:指针数组本质是一个数组,只是数组中存储的是指针变量。数组指针存储的是该数组的起始地址,对该指针来说每偏移一个单位就是偏移了一整个数组的地…...
常见的HttpUtils工具类及如何自定义java的http连接池)
HttpUtils工具类(一)常见的HttpUtils工具类及如何自定义java的http连接池
目录 一、几种常见的Http调用方式 1. 使用 Apache HttpClient 2. 使用 OKhttpClient 3. 使用第三方库(Hutool)的http链接池 4. 使用 Spring RestTemplate 5. 使用 Java 原生的HttpURLConnection 二、总结 常用三种HttpUtils对比总结 一、几种常见…...

使用 Lombok 遇到一个问题
起因是换了一个电脑,重新从服务器上拉了一个项目。项目是由maven构建的,在控制台中使用mvn命令编译项目时,没有任何问题,编译成功。如下图: 可是idea里面的源码,却标红了,如下: 错误…...

Linux基础环境开发工具gcc/g++ make/Makefile
1.Linux编译器-gcc/g使用 1. 预处理(进行宏替换) 预处理功能主要包括宏定义,文件包含,条件编译,去注释等。 预处理指令是以#号开头的代码行。 实例: gcc –E hello.c –o hello.i 选项“-E”,该选项的作用是让 gcc 在预处理结束后停止编译过程。 选项“-o”是指目标…...

ES 模糊查询 wildcard 的替代方案探索
一、Wildcard 概述 Wildcard 是一种支持通配符的模糊检索方式。在 Elasticsearch 中,它使用星号 * 代表零个或多个字符,问号 ? 代表单个字符。 其使用方式多样,例如可以通过 {"wildcard": {"field_name": "value&…...

Linux安装MQTT 服务器(图文教程)
MQTT(Message Queuing Telemetry Transport)是一种轻量级的消息传输协议,专为低带宽和不稳定的网络环境设计,非常适合物联网(IoT)应用。 官网地址:https://www.emqx.com/ 一、版本选择 根据自己…...
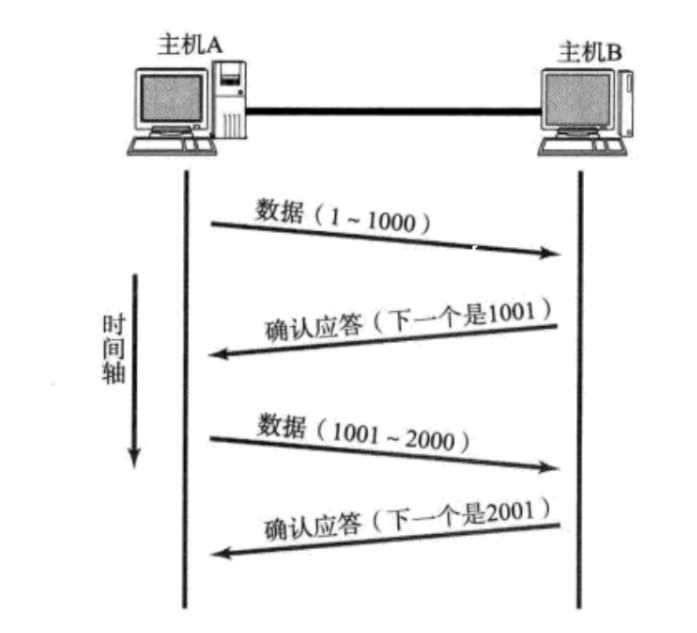
【TCP】核心机制:延时应答、捎带应答和面向字节流
文章目录 延时应答捎带应答面向字节流粘包问题方案一:指定分隔符方案二:指定数据的长度 TCP 报头首部长度保留(6 位)选项序号确认序号 延时应答 尽可能降低可靠传输带来的性能影响 提升性能>让滑动窗口变大 如果我们立即返回 …...

题解:AT_abc352_e [ABC352E] Clique Connect
[题目通道]([ABC352E] Clique Connect - 洛谷) 鄙人今日写人生第一篇题解 希望管理大大通过 首先,我们先看题: 它说一共有n个点,m回操作。。。 每次操作 都有 一个Ki 和 Ci Ki代表有Ki个点,Ci代表每条边所赋的边权 一看就知道这是个最小生成树的板子…...

【代码随想录训练营第42期 Day32打卡 - 从零开始动态规划 - LeetCode 509. 斐波那契数 70. 爬楼梯 746. 使用最小花费爬楼梯
目录 一、做题心得 二、动规五步走 三、题目与题解 题目一:509. 斐波那契数 题目链接 题解1:记忆性递归 题解2:动态规划 题目二:70. 爬楼梯 题目链接 题解:动态规划 题目三:746. 使用最小花费爬楼…...

源码构建LAMP
目录 一、安装Apache 二、安装Mysql 三、安装PHP 四、安装论坛 一、安装Apache 1.cd 到opt目录下面,将压缩包拉进Xhell 2.解压缩apr和httpd压缩包 tar xf apr-1.6.2.tar.gz tar xf apr-util-1.6.0.tar.gz tar xf httpd-2.4.29.tar.bz2 3.将apr-1.6.2 移动到ht…...

Java:封装树结构
实体类 public class DictTreeselectVO {private String value;private String label;/*** 节点*/private String parentId;private List<DictTreeselectVO> children new ArrayList<DictTreeselectVO>();public String getValue() {return value;}public void s…...

linux内核 pintrl子系统
1、什么是pinctrl子系统 在 Linux 内核中,pinctrl子系统是一个专门用于管理和控制 SoC引脚复用和配置的子系统。SoC 通常具有大量的引脚(pin),这些引脚可以被配置为不同的功能,比如 GPIO(通用输入输出&…...

网络通信要素
网络介绍 定义:将具有独立功能的多台计算机通过通信线路和通信设备连接起来,在网络管理软件及网络通信协议下,实现资源共享和信息传递的虚拟平台。 学习网络的目的: 能够编写基于网络通信的软件或程序,通常来说就是网…...

我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案 作为一名频繁使用Claude Code进行代码生成和审查的个人…...

Unity游戏接入TapTap登录,从后台配置到打包上线的完整避坑指南
Unity游戏接入TapTap登录的全流程避坑指南:从配置到上线的实战经验 在独立游戏开发领域,TapTap平台凭借其庞大的用户基础和便捷的登录系统,已成为许多开发者的首选接入方案。然而,从后台配置到最终打包上线的完整流程中࿰…...

OSINT自动化平台ClawShield:模块化架构与安全运营实战解析
1. 项目概述:一个面向安全运营的公开情报收集与分析平台最近在整理自己的开源项目收藏夹,发现一个挺有意思的仓库,叫SleuthCo/clawshield-public。乍一看这个名字,“ClawShield”,爪子与盾牌,就透着一股子攻…...

终极免费城通网盘直连解析工具:告别下载限速的完整指南
终极免费城通网盘直连解析工具:告别下载限速的完整指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘下载速度慢、等待时间长而烦恼吗?ctfileGet是一款专为城通…...

在线Graphviz图表编辑器:3步创建专业技术流程图
在线Graphviz图表编辑器:3步创建专业技术流程图 【免费下载链接】GraphvizOnline Lets Graphviz it online 项目地址: https://gitcode.com/gh_mirrors/gr/GraphvizOnline 还在为复杂的技术图表绘制而烦恼吗?GraphvizOnline作为一款革命性的在线G…...

Thorium浏览器深度解析:5个核心优势与进阶配置实战
Thorium浏览器深度解析:5个核心优势与进阶配置实战 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, links are towards the top of the RE…...

UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器
UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool 你是否曾好奇计算机启动时底层发生了什么?想要深入了解UEFI固件的…...

开源机械爪OpenClaw:从设计到力控抓取的完整实现指南
1. 项目概述:从“OpenClaw”看开源机械爪的无限可能最近在逛GitHub的时候,发现了一个挺有意思的项目,叫“MeyerZhou/openclaw”。光看名字,你大概能猜到这是个关于机械爪的开源项目。没错,这是一个旨在提供低成本、模块…...

PCL2启动器离线登录按钮消失?5分钟快速修复指南
PCL2启动器离线登录按钮消失?5分钟快速修复指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 你是否遇到过PCL2启动器离线登录按钮突然消失的困扰࿱…...

CircuitPython嵌入式游戏开发:基于TileGrid的迷宫寻蛋与JSON数据持久化实践
1. 项目概述与核心价值如果你和我一样,对嵌入式开发充满热情,同时又对游戏开发抱有好奇心,那么将两者结合——在微控制器上编写一个完整的2D游戏——绝对是一次令人兴奋的挑战。这不仅仅是让LED闪烁或读取传感器数据,而是要在资源…...