Python深度学习实战:人脸关键点(15点)检测pytorch实现
引言
人脸关键点检测即对人类面部若干个点位置进行检测,可以通过这些点的变化来实现许多功能,该技术可以应用到很多领域,例如捕捉人脸的关键点,然后驱动动画人物做相同的面部表情;识别人脸的面部表情,让机器能够察言观色等等。

如何检测人脸关键点
本文是实现15点的检测,至于N点的原理都是一样的,使用的算法模型是深度神经网络,使用CV也是可以的。
如何检测
这个问题抽象出来,就是一个使用神经网络来进行预测的功能,只不过输出是15个点的坐标,训练数据包含15个面部的特征点和面部的图像(大小为96x96),15个特征点分别是:left_eye_center, right_eye_center, left_eye_inner_corner, left_eye_outer_corner, right_eye_inner_corner, right_eye_outer_corner, left_eyebrow_inner_end, left_eyebrow_outer_end, right_eyebrow_inner_end, right_eyebrow_outer_end, nose_tip, mouth_left_corner, mouth_right_corner, mouth_center_top_lip, mouth_center_bottom_lip
因此神经网络需要学习一个从人脸图像到15个关键点坐标间的映射。
使用的网络结构
在本文中,我们使用深度神经网络来实现该功能,基本卷积块使用Google的Inception网络,也就是使用GoogLeNet网络,该结构的网络是基于卷积神经网络来改进的,是一个含有并行连接的网络。
众所周知,卷积有滤波、提取特征的作用,但到底采用多大的卷积来提取特征是最好的呢?这个问题没有确切的答案,那就集百家之长:使用多个形状不一的卷积来提取特征并进行拼接,从而学习到更为丰富的特征;特别是里面加上了1x1的卷积结构,能够实现跨通道的信息交互和整合(其本质就是在多个channel上的线性求和),同时能在feature map通道数上的降维(读者可以验证计算一下,能够极大减少卷积核的参数),也能够增加非线性映射次数使得网络能够更深。
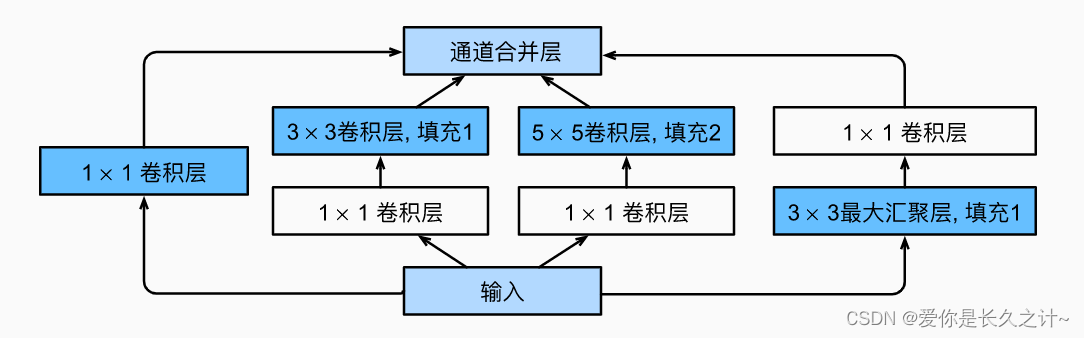
下面是Inception块的示意图:
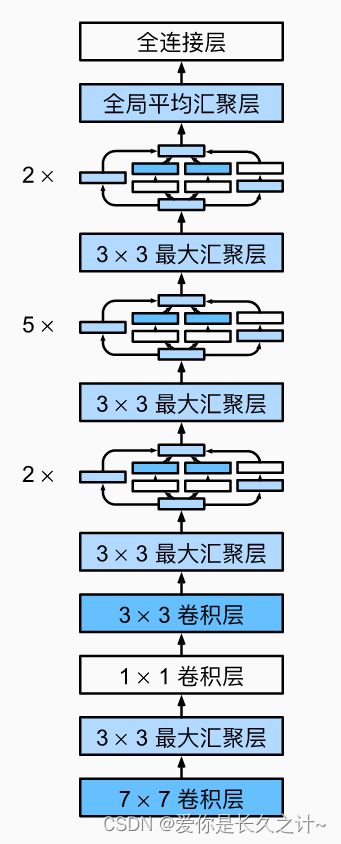
整个GoogLeNet的结构如下所示:
接下来是代码实现部分,后续作者会补充神经网络的相关原理知识,若对此感兴趣的读者也可继续关注支持~
代码实现
import torch as tc
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torch.utils.data import TensorDataset
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.utils import shuffle# 对图片像素的处理
def proFunc1(data,testFlag:bool=False) -> tuple:data['Image'] = data['Image'].apply(lambda im: np.fromstring(im, sep=' '))# 处理nadata = data.dropna() # 神经网络对数据范围较为敏感 /255 将所有像素都弄到[0,1]之间X = np.vstack(data['Image'].values) / 255X = X.astype(np.float32)# 特别注意 这里要变成 n channle w h 要跟卷积第一层相匹配X = X.reshape(-1, 1,96, 96) # 等会神经网络的输入层就是 96 96 黑白图片 通道只有一个# 只有训练集才有y 测试集返回一个None出去if not testFlag: y = data[data.columns[:-1]].values# 规范化y = (y - 48) / 48 X, y = shuffle(X, y, random_state=42) y = y.astype(np.float32)else:y = Nonereturn X,y# 工具类
class UtilClass:def __init__(self,model,procFun,trainFile:str='data/training.csv',testFile:str='data/test.csv') -> None:self.trainFile = trainFileself.testFile = testFileself.trainData = Noneself.testData = Noneself.trainTarget = Noneself.model = modelself.procFun = procFun@staticmethoddef procData(data, procFunc ,testFlag:bool=False) -> tuple:return procFunc(data,testFlag)def loadResource(self):rawTrain = pd.read_csv(self.trainFile)rawTest = pd.read_csv(self.testFile)self.trainData , self.trainTarget = self.procData(rawTrain,self.procFun)self.testData , _ = self.procData(rawTest,self.procFun,testFlag=True)def getTrain(self):return tc.from_numpy(self.trainData), tc.from_numpy(self.trainTarget)def getTest(self):return tc.from_numpy(self.testData)@staticmethoddef plotData(img, keyPoints, axis):axis.imshow(np.squeeze(img), cmap='gray') # 恢复到原始像素数据 keyPoints = keyPoints * 48 + 48 # 把keypoint弄到图上面axis.scatter(keyPoints[0::2], keyPoints[1::2], marker='o', c='c', s=40)# 自定义的卷积神经网络
class MyCNN(tc.nn.Module):def __init__(self,imgShape = (96,96,1),keyPoint:int = 15):super(MyCNN, self).__init__()self.conv1 = tc.nn.Conv2d(in_channels=1, out_channels =10, kernel_size=3)self.pooling = tc.nn.MaxPool2d(kernel_size=2)self.conv2 = tc.nn.Conv2d(10, 5, kernel_size=3)# 这里的2420是通过下面的计算得出的 如果改变神经网络结构了 # 需要计算最后的Liner的in_feature数量 输出是固定的keyPoint*2self.fc = tc.nn.Linear(2420, keyPoint*2)def forward(self, x):# print("start----------------------")batch_size = x.size(0)# x = x.view((-1,1,96,96))# print('after view shape:',x.shape)x = F.relu(self.pooling(self.conv1(x)))# print('conv1 size',x.shape)x = F.relu(self.pooling(self.conv2(x)))# print('conv2 size',x.shape)# print('end--------------------------')# 改形状x = x.view(batch_size, -1)# print(x.shape)x = self.fc(x)# print(x.shape)return x# GoogleNet基本的卷积块
class MyInception(nn.Module):def __init__(self,in_channels, c1, c2, c3, c4,) -> None:super().__init__()self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)def forward(self, x):p1 = F.relu(self.p1_1(x))p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))p4 = F.relu(self.p4_2(self.p4_1(x)))# 在通道维度上连结输出return tc.cat((p1, p2, p3, p4), dim=1)# GoogLeNet的设计 此处参数结果google大量实验得出
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),nn.ReLU(),nn.Conv2d(64, 192, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))b3 = nn.Sequential(MyInception(192, 64, (96, 128), (16, 32), 32),MyInception(256, 128, (128, 192), (32, 96), 64),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))b4 = nn.Sequential(MyInception(480, 192, (96, 208), (16, 48), 64),MyInception(512, 160, (112, 224), (24, 64), 64),MyInception(512, 128, (128, 256), (24, 64), 64),MyInception(512, 112, (144, 288), (32, 64), 64),MyInception(528, 256, (160, 320), (32, 128), 128),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))b5 = nn.Sequential(MyInception(832, 256, (160, 320), (32, 128), 128),MyInception(832, 384, (192, 384), (48, 128), 128),nn.AdaptiveAvgPool2d((1,1)),nn.Flatten())uClass = UtilClass(model=None,procFun=proFunc1)
uClass.loadResource()
xTrain ,yTrain = uClass.getTrain()
xTest = uClass.getTest()dataset = TensorDataset(xTrain, yTrain)
trainLoader = DataLoader(dataset, 64, shuffle=True, num_workers=4)# 训练net并进行测试 由于显示篇幅问题 只能打印出极为有限的若干测试图片效果
def testCode(net):optimizer = tc.optim.Adam(params=net.parameters())criterion = tc.nn.MSELoss()for epoch in range(30):trainLoss = 0.0# 这里是用的是mini_batch 也就是说 每次只使用mini_batch个数据大小来计算# 总共有total个 因此总共训练 total/mini_batch 次# 由于不能每组数据只使用一次 所以在下面还要使用一个for循环来对整体训练多次for batchIndex, data in enumerate(trainLoader, 0):input_, y = datayPred = net(input_)loss = criterion(yPred, y)optimizer.zero_grad()loss.backward()optimizer.step()trainLoss += loss.item()# 只在每5个epoch的最后一轮打印信息if batchIndex % 30 ==29 and not epoch % 5 :print("[{},{}] loss:{}".format(epoch + 1, batchIndex + 1, trainLoss / 300))trainLoss = 0.0# 测试print("-----------test begin-------------")# print(xTest.shape)yPost = net(xTest)# print(yPost.shape)import matplotlib.pyplot as plt%matplotlib inlinefig = plt.figure(figsize=(20,20))fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)for i in range(9,18):ax = fig.add_subplot(3, 3, i - 9 + 1, xticks=[], yticks=[])uClass.plotData(xTest[i], y[i], ax)print("-----------test end-------------")if __name__ == "__main__":# 训练MyCNN网络 并可视化在9个测试数据的效果图myNet = MyCNN()testCode(myNet)inception = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 30))testCode(inception)
本文使用的数据可在此找到两个data文件,本文有你帮助的话,就给个点赞关注支持一下吧!
相关文章:
Python深度学习实战:人脸关键点(15点)检测pytorch实现
引言 人脸关键点检测即对人类面部若干个点位置进行检测,可以通过这些点的变化来实现许多功能,该技术可以应用到很多领域,例如捕捉人脸的关键点,然后驱动动画人物做相同的面部表情;识别人脸的面部表情,让机…...

linux简单入门
目录Linux简介Linux目录结构Linux文件命令文件处理命令文件查看命令常用文件查看命令Linux的用户和组介绍Linux权限管理Linux简介 Linux,全称GNU/Linux,是一种免费使用和自由传播的类UNIX操作系统,其内核由林纳斯本纳第克特托瓦兹࿰…...
给准备面试网络工程师岗位的应届生一些建议
你听完这个故事,应该会有所收获。最近有一个23届毕业的大学生和我聊天,他现在网络工程专业大四,因为今年6、7月份的时候毕业,所以现在面临找工作的问题。不管是现在找一份实习工作,还是毕业后找一份正式工作࿰…...
主线程与子线程之间相互通信(HandlerThread)
平时,我们一般都是在子线程中向主线程发送消息(要在主线程更新UI),从而完成请求的处理。那么如果需要主线程来向子线程发送消息,希望子线程来完成什么任务。该怎么做?这就是这篇文章将要讨论的内容。 一、…...

13基于双层优化的电动汽车日前-实时两阶段市场竞标
MATLAB代码:基于双层优化的电动汽车日前-实时两阶段市场竞标 关键词:日前-实时市场竞标 电动汽车 双层优化 编程语言:MATLAB平台 参考文献:考虑电动汽车可调度潜力的充电站两阶段市场投标策略_詹祥澎 内容简介:…...
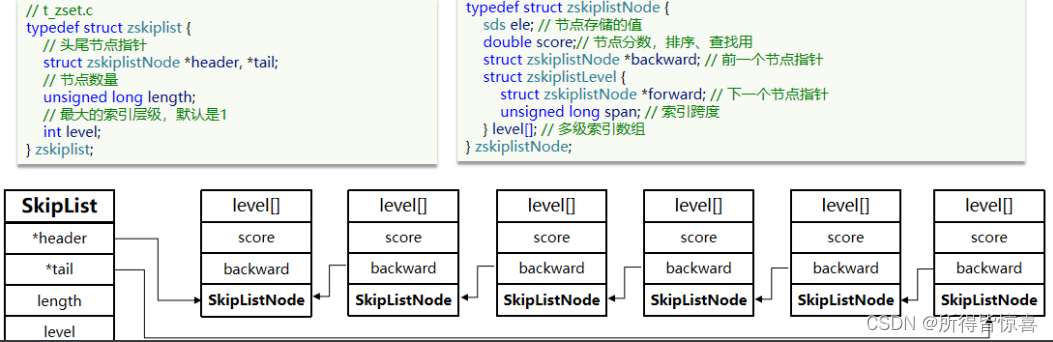
REDIS19_zipList压缩列表详解、快递列表 - QuickList、跳表 - SkipList
文章目录①. 压缩列表 - zipList②. 快递列表 - QuickList③. 跳表 - SkipList①. 压缩列表 - zipList ①. ZipList是一种特殊的"双端链表",由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作,并且该操作的时间复杂度为O(1) (oxff:11111111) type…...

JavaScript 基础 - 第3天
文章目录JavaScript 基础 - 第3天笔记数组数组的基本使用定义数组和数组单元数据单元值类型数组长度属性操作数组JavaScript 基础 - 第3天笔记 数组 数组的基本使用 定义数组和数组单元 <script>// 1. 语法,使用 [] 来定义一个空数组// 定义一个空数组let…...
23.3.26总结
康托展开 是一个全排列与自然数的映射关系,康托展开的实质是计算当前序列在所有从小到大的全排列中的顺序,跟其逆序数有关。 例如:对于 1,2,3,4,5 来说,它的康托展开值为 0*4!0*3!0*2!0*1&…...

【Java学习笔记】37.Java 网络编程
Java 网络编程 网络编程是指编写运行在多个设备(计算机)的程序,这些设备都通过网络连接起来。 java.net 包中 J2SE 的 API 包含有类和接口,它们提供低层次的通信细节。你可以直接使用这些类和接口,来专注于解决问题&…...

Azure OpenAI 官方指南03|DALL-E 的图像生成功能与安全过滤机制
2021年1月,OpenAI 推出 DALL-E。这是 GPT 模型在图像生成方面的人工智能应用。其名称来源于著名画家、艺术家萨尔瓦多 • 达利(Dal)和机器人总动员(Wall-E)。DALL-E 图像生成器,能够直接根据文本描述生成多…...
【数据结构】堆
文章目录前言堆的概念及结构堆初始化堆的判空堆的销毁插入数据删除数据堆的数据个数获取堆顶数据用数组创建堆对数组堆排序有关topk问题整体代码展示写在最后前言 🚩前面了解了树(-> 传送门 <-)的概念后,本章带大家来实现一…...
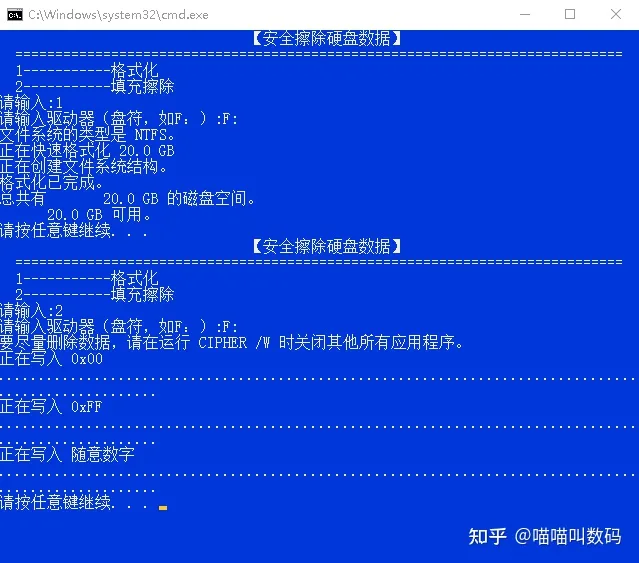
电脑硬盘文件数据误删除/格式化为什么可以恢复? 怎么恢复?谈谈文件删除与恢复背后的原理
Hello 大家好, 我是元存储~ 主页:元存储的博客_CSDN博客 1. 硬盘数据丢失场景 我们在每天办公还是记录数据的时候,文件存储大多数都是通过硬盘进行存储的,因此,使用多了,各种问题就会出现,比如…...
Gateway服务网关
Spring Cloud Gateway为微服务架构提供一种简单有效的统一的 API 路由管理方式。Gateway网关是所有微服务的统一入口。网关的核心功能特性:请求路由和负载均衡:一切请求都必须先经过gateway,但网关不处理业务,而是根据某种规则&am…...
K8S + GitLab + Jenkins自动化发布项目实践(一)
K8S GitLab Jenkins自动化发布项目实践(一)发布流程设计安装Docker服务部署Harbor作为镜像仓库部署GitLab作为代码仓库常用Git命令发布流程设计 #mermaid-svg-pe9VmFytb9GmqMvG {font-family:"trebuchet ms",verdana,arial,sans-serif;font-…...

【数据结构篇C++实现】- 堆
文章目录🚀一、堆的原理精讲⛳(一)堆的概念⛳(二)看图识最大堆⛳(三)详解堆是用数组表示的树🚀二、堆的向下调整算法🚀三、堆的向上调整算法🚀四、将任意一棵…...

C++笔试题
作用域运算符(::)的作用:1.存在具有相同名称的局部变量时,访问全局变量。2.在类之外定义类相关函数。3.访问类的静态变量。4.在多重继承的情况下,如果两个基类中存在相同的变量名,可以使用作用域运算符来进行区分。5.限定成员函数…...

【Python】基本语法
数据类型 通过 print(type(x)) 可以输出 x 的数据类型,type() 函数可以获取数据类型 整数 a 10 print(type(a)) 浮点数 a 0.5 print(type(a)) 字符串 a hello print(type(a)) 获取字符串长度 a hello print(len(a))字符串拼接 a hello b world prin…...
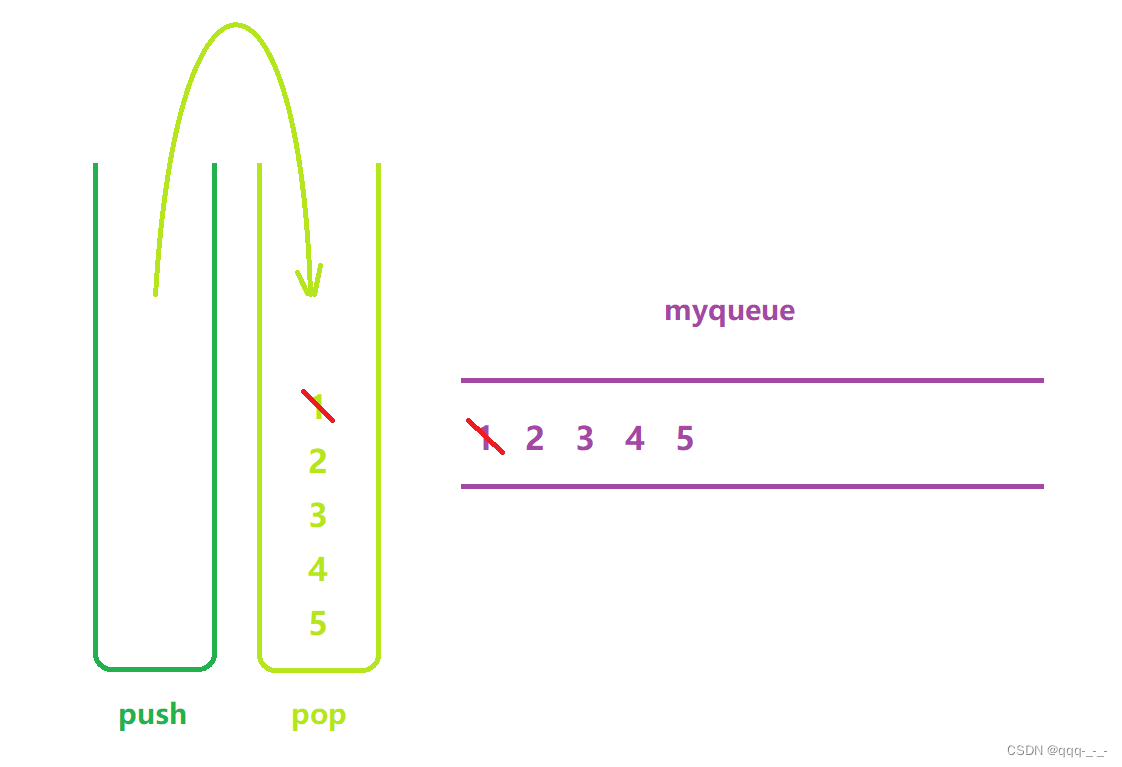
用栈实现队列(图示超详解哦)
全文目录引言用栈实现队列题目介绍思路简述实现栈的部分队列的部分创建队列判断队列是否为空在队列尾入在队列头出访问队头元素释放队列总结引言 在上一篇文章中,我们了解了用两个队列实现栈。在这篇问章中将继续介绍用两个栈实现队列的OJ练习: 用栈实现…...

Spring - Spring 注解相关面试题总结
文章目录01. Spring 配置方式有几种?02. Spring 如何实现基于xml的配置方式?03. Spring 如何实现基于注解的配置?04. Spring 如何基于注解配置bean的作用范围?05. Spring Component, Controller, Repository, Service 注解有何区别…...
【数据结构】实现二叉树的基本操作
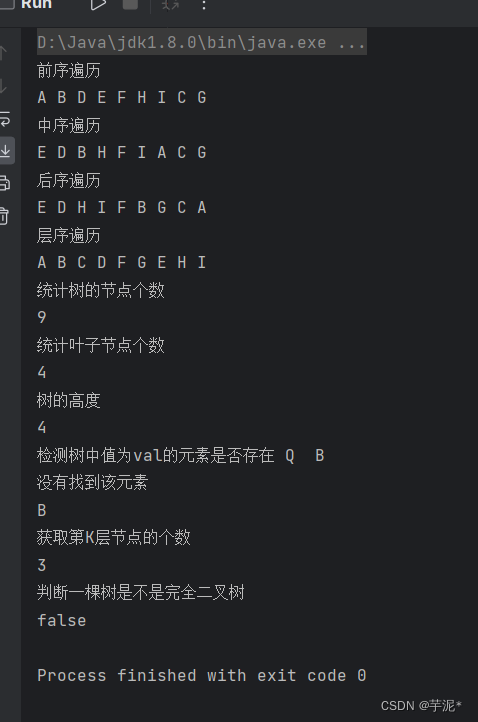
目录 1. 二叉树的基本操作 2. 具体实现 2.1 创建BinaryTree类以及简单创建一棵树 2.2 前序遍历 2.3 中序遍历 2.4 后序遍历 2.5 层序遍历 2.6 获取树中节点的个数 2.7 获取叶子节点的个数 2.8 获取第K层节点的个数 2.9 获取二叉树的高度 2.10 检测值为val的元素是否…...

CANN 推理引擎深度解析:从模型加载到执行结果的全流程追踪
一、ACL 推理引擎架构 1.1 整体架构 ACL(Ascend Compute Language)是昇腾的推理运行时框架,负责模型加载和执行。其核心组件包括:模型加载器(Model Loader)、内存管理器(Memory Manager…...

【习题05】求n的阶乘
题目: 分别利用递归和非递归的方法求n的阶乘 1、题目分析 规定:0的阶乘为1。 非递归: 我们先列举几个求阶乘的案例,从中找寻规律。 0! 11! 12! 1 * 23! 1 * 2 * 3 从上述几个例子可…...

Belkin向范围3排放碳中和目标迈进
该公司发布的《2025年环境影响报告》重点介绍了其在减排、循环设计和负责任包装方面取得的持续进展 发布了《2025年环境影响报告》(2025 Impact Report),重点介绍了关键成就,并重申了其对企业社会责任的承诺。在2025年实现范围1和…...

【AI绘画构图生死线】:为什么你的提示词再精准也出不了大片?——透视层级、视觉动线与负空间权重分配全拆解
更多请点击: https://kaifayun.com 第一章:AI绘画构图的底层认知革命 传统构图理论建立在人眼视觉经验与经典美学范式之上,而AI绘画的构图逻辑则根植于高维特征空间中的统计分布、注意力权重映射与跨模态对齐机制。当用户输入“晨雾中的孤松…...
)
Linux 进程从入门到实战(一)
.个人主页:晓风飞专栏:数据结构|Linux|C语言路漫漫其修远兮,吾将上下而求索文章目录进程为什么要存在内存??操作系统进程什么是进程?PCB(进程控制块)操作系统如何管理进程࿱…...

如何在脑电信号处理的星辰大海中,找到你的开源坐标?[特殊字符]
如何在脑电信号处理的星辰大海中,找到你的开源坐标?🚀 【免费下载链接】eeglab EEGLAB is an open source signal processing environment for electrophysiological signals running on Matlab and developed at the SCCN/UCSD 项目地址: …...

不止于指路,智慧导览如何重构公共空间价值
在过去很长一段时间里,公共空间的价值被简单地等同于功能性。一个公园只要有绿化和座椅,一个商场只要有商铺和电梯,一个政务大厅只要有窗口和座位,就被认为是合格的公共空间。然而,随着人们生活水平的提高和消费观念的…...

宇视出入口相机抓拍调试速成方法
宇视出入口相机抓拍调试速成方法一、背景概述智慧园区、停车场等场景已普及宇视出入口抓拍相机,用于车辆出入管控与车牌识别。现场易受光照、车速、车道环境等影响,常出现漏抓、识别率低、画面模糊等问题。传统调试无标准、耗时长、上手门槛高࿰…...

人大金仓KingbaseES分区表‘挂载’与‘摘除’功能详解:像搭积木一样管理你的数据
人大金仓KingbaseES分区表‘挂载’与‘摘除’功能实战指南:数据管理的乐高式玩法 想象一下,你的数据库表像一堆积木,可以随时拆解、重组,而无需担心数据丢失或性能下降。这正是人大金仓KingbaseES分区表"挂载(ATTACH)"和…...

为你的AI Agent项目选择并接入Taotoken多模型聚合平台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的AI Agent项目选择并接入Taotoken多模型聚合平台 当你着手构建一个智能Agent应用时,很快会面临一个现实问题&…...