基于 PyTorch + LSTM 进行时间序列预测(附完整源码)
时间序列数据,顾名思义是一种随时间变化的数据类型。
例如,24小时内的温度、一个月内各种产品的价格、某家公司一年内的股票价格等。深度学习模型如长短期记忆网络(LSTM)能够捕捉时间序列数据中的模式,因此可以用于预测未来趋势。
文章目录
- 技术提升
- 数据集和问题定义
- 数据预处理
- 创建LSTM模型
- 训练模型
- 进行预测
- 结论
在本文中,您将看到如何使用 LSTM 算法利用时间序列数据进行未来预测,使用的是 PyTorch 库,这是最常用于深度学习的Python库之一。
在继续之前,确保已安装了 PyTorch 库。同时掌握基本机器学习和深度学习概念会有所帮助。如果尚未安装PyTorch,则可以使用以下pip命令进行安装:
$ pip install pytorch
技术提升
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
完整代码、数据、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:pythoner666,备注:来自 CSDN + python
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
数据集和问题定义
我们将使用的数据集是Python Seaborn库中内置的。让我们首先导入所需的库,然后再导入数据集:
import torch
import torch.nn as nnimport seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
让我们打印出Seaborn库中内置的所有数据集列表:
sns.get_dataset_names()
输出
['anscombe','attention','brain_networks','car_crashes','diamonds','dots','exercise','flights','fmri','gammas','iris','mpg','planets','tips','titanic']
我们将使用的数据集是航班数据集。让我们将数据集加载到我们的应用程序中,看看它的样子:
flight_data = sns.load_dataset("flights")
flight_data.head()
数据集有三列:年份、月份和乘客数。乘客列包含指定月份旅行的总人数。让我们绘制数据集的形状:
flight_data.shape## (144, 3)
您可以看到数据集中有144行和3列,这意味着该数据集包含乘客12年的旅行记录。
任务是基于前132个月预测最近12个月旅行的乘客人数。请记住,我们有144个月的记录,这意味着来自前132个月的数据将用于训练我们的LSTM模型,而模型性能将使用最后12个月的值进行评估。
让我们绘制每月旅行乘客数量的频率。以下脚本增加了默认图形大小:
fig_size = plt.rcParams["figure.figsize"]
fig_size[0] = 15
fig_size[1] = 5
plt.rcParams["figure.figsize"] = fig_size
接下来的脚本绘制了乘客数量每月出现的频率:
plt.title('Month vs Passenger')
plt.ylabel('Total Passengers')
plt.xlabel('Months')
plt.grid(True)
plt.autoscale(axis='x',tight=True)
plt.plot(flight_data['passengers'])
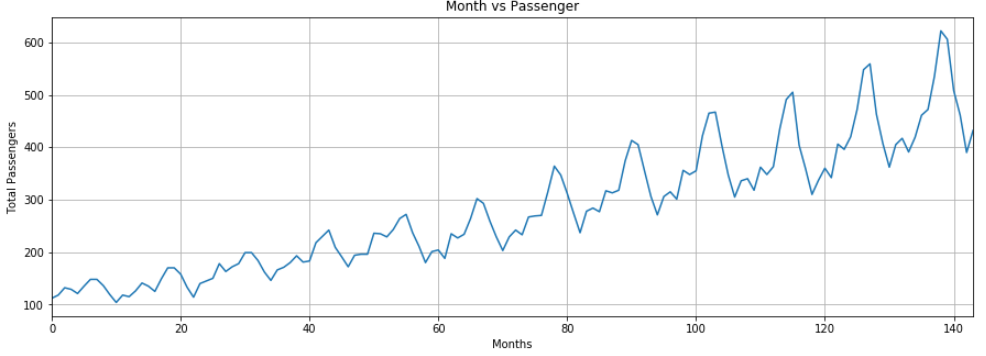
输出结果显示,多年来乘坐飞机旅行的平均乘客人数增加了。一年内旅行的乘客数量波动,这是有道理的,因为在暑假或寒假期间,与其他时间相比旅行乘客数量会增加。
数据预处理
我们数据集中的列类型是对象,如下代码所示:
flight_data.columns
## output
Index(['year', 'month', 'passengers'], dtype='object')
第一个预处理步骤是将乘客列的类型更改为浮点数。
all_data = flight_data['passengers'].values.astype(float)
现在,如果您打印 all_data numpy数组,您应该会看到以下浮点类型值:
print(all_data)
[112. 118. 132. 129. 121. 135. 148. 148. 136. 119. 104. 118. 115. 126.141. 135. 125. 149. 170. 170. 158. 133. 114. 140. 145. 150. 178. 163.172. 178. 199. 199. 184. 162. 146. 166. 171. 180. 193. 181. 183. 218.230. 242. 209. 191. 172. 194. 196. 196. 236. 235. 229. 243. 264. 272.237. 211. 180. 201. 204. 188. 235. 227. 234. 264. 302. 293. 259. 229.203. 229. 242. 233. 267. 269. 270. 315. 364. 347. 312. 274. 237. 278.284. 277. 317. 313. 318. 374. 413. 405. 355. 306. 271. 306. 315. 301.356. 348. 355. 422. 465. 467. 404. 347. 305. 336. 340. 318. 362. 348.363. 435. 491. 505. 404. 359. 310. 337. 360. 342. 406. 396. 420. 472.548. 559. 463. 407. 362. 405. 417. 391. 419. 461. 472. 535. 622. 606.508. 461. 390. 432.]
接下来,我们将把数据集分成训练集和测试集。LSTM算法将在训练集上进行训练。然后,该模型将用于在测试集上进行预测。预测结果将与测试集中的实际值进行比较,以评估已训练模型的性能。
前132条记录将用于训练模型,而最后12条记录将用作测试集。以下脚本将数据分成训练集和测试集。
test_data_size = 12train_data = all_data[:-test_data_size]
test_data = all_data[-test_data_size:]
现在让我们打印测试集和训练集的长度:
print(len(train_data))
print(len(test_data))
##
132
12
如果您现在打印测试数据,您将看到它包含了all_data numpy数组中的最后12条记录:
我们的数据集目前尚未标准化。最初几年的乘客总数远远少于后来几年的乘客总数。对于时间序列预测,将数据进行标准化非常重要。我们将在数据集上执行 min/max 缩放,该方法可以使数据在一定范围内归一化到最小值和最大值之间。
我们将使用 sklearn.preprocessing 模块中的 MinMaxScaler 类来缩放我们的数据。
以下代码使用最小值为-1,最大值为1 的 min/max 缩放器对我们的数据进行了标准化处理:
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler(feature_range=(-1, 1))
train_data_normalized = scaler.fit_transform(train_data .reshape(-1, 1))
让我们现在打印出归一化训练数据的前5条和后5条记录。
print(train_data_normalized[:5])
print(train_data_normalized[-5:])## output
[[-0.96483516][-0.93846154][-0.87692308][-0.89010989][-0.92527473]]
[[1. ][0.57802198][0.33186813][0.13406593][0.32307692]]
你可以看到数据集的值现在在-1和1之间。
这里需要强调的是,数据归一化仅应用于训练数据,而不应用于测试数据。如果对测试数据进行归一化,则有可能会将某些信息从训练集泄漏到测试集中。
下一步是将我们的数据集转换为张量,因为 PyTorch 模型使用张量进行训练。要将数据集转换为张量,我们只需将其传递给FloatTensor对象的构造函数即可,如下所示:
train_data_normalized = torch.FloatTensor(train_data_normalized).view(-1)
最后的预处理步骤是将我们的训练数据转换为序列和相应的标签。
您可以使用任何序列长度,这取决于领域知识。然而,在我们的数据集中,由于我们有每月的数据且一年有12个月,因此使用序列长度为12是方便的。如果我们有每日数据,则更好的序列长度将是365,即一年中的天数。因此,我们将设置训练输入序列长度为12。
train_window = 12
接下来,我们将定义一个名为create_inout_sequences的函数。该函数将接受原始输入数据,并返回一个元组列表。在每个元组中,第一个元素将包含12个项目的列表,对应于12个月内旅行的乘客数量,第二个元素将包含一项即第13个月的乘客数量。
def create_inout_sequences(input_data, tw):inout_seq = []L = len(input_data)for i in range(L-tw):train_seq = input_data[i:i+tw]inout_seq.append((train_seq ,train_label))return inout_seq
执行以下脚本以创建用于训练的序列和相应标签:
train_inout_seq = create_inout_sequences(train_data_normalized, train_window)
如果您打印 train_inout_seq 列表的长度,您会发现它包含120个项目。这是因为尽管训练集包含132个元素,但序列长度为12,这意味着第一个序列由前12个项目组成,而第13个项目是第一个序列的标签。同样,第二个序列从第二项开始,并在第13项结束,而第14项是第二个序列的标签等等。
现在让我们打印 train_inout_seq 列表的前5项:
train_inout_seq[:5]
## output
[(tensor([-0.9648, -0.9385, -0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066,-0.8593, -0.9341, -1.0000, -0.9385]), tensor([-0.9516])),(tensor([-0.9385, -0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593,-0.9341, -1.0000, -0.9385, -0.9516]),tensor([-0.9033])),(tensor([-0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341,-1.0000, -0.9385, -0.9516, -0.9033]), tensor([-0.8374])),(tensor([-0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341, -1.0000,-0.9385, -0.9516, -0.9033, -0.8374]), tensor([-0.8637])),(tensor([-0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341, -1.0000, -0.9385,-0.9516, -0.9033, -0.8374, -0.8637]), tensor([-0.9077]))]
你可以看到每个项目都是一个元组,其中第一个元素包含序列的12个项目,第二个元组元素包含相应的标签。
创建LSTM模型
我们已经预处理了数据,现在是训练模型的时候了。我们将定义一个类LSTM,它继承自PyTorch库的nn.Module类。
class LSTM(nn.Module):def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):super().__init__()self.hidden_layer_size = hidden_layer_sizeself.lstm = nn.LSTM(input_size, hidden_layer_size)self.linear = nn.Linear(hidden_layer_size, output_size)def forward(self, input_seq):lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq) ,1, -1), self.hidden_cell)predictions = self.linear(lstm_out.view(len(input_seq), -1))return predictions[-1]
让我总结一下上面代码中发生的事情。LSTM 类的构造函数接受三个参数:
- input_size:对应于输入中特征的数量。虽然我们的序列长度为12,但每个月只有1个值,即乘客总数,因此输入大小将为1。
- hidden_layer_size:指定隐藏层的数量以及每层神经元的数量。我们将有一个100个神经元的隐藏层。
- output_size:输出中项目的数量,由于我们想要预测未来1个月内乘客人数,因此输出大小将为1。
接下来,在构造函数中创建变量 hidden_layer_size、lstm、linear 和 hidden_cell。
LSTM 算法接受三个输入:先前隐藏状态、先前单元格状态和当前输入。hidden_cell 变量包含先前隐藏和单元格状态。lstm和linear层变量用于创建LSTM和线性层。
在 forward 方法内部,input_seq 作为参数传递,并首先通过lstm层传递。 lstm 层的输出是当前时间步长处的隐藏和 单元状态 ,以及输出 。从 lstm 层得到的输出会被传递到linear层 。预测出来的乘客人数存储在 predictions 列表 中最后一个项目中,并返回给调用函数。
下一步是创建 LSTM() 类对象、定义损失函数和优化器。由于我们正在解决分类问题,所以使用交叉熵损失。对于优化器函数,我们将使用adam优化器。
model = LSTM()
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
让我们打印我们的模型:
print(model)## output
LSTM((lstm): LSTM(1, 100)(linear): Linear(in_features=100, out_features=1, bias=True)
)
训练模型
我们将训练我们的模型150个epochs。如果您愿意,可以尝试更多的epochs。每25个epochs后会打印损失值。
epochs = 150for i in range(epochs):for seq, labels in train_inout_seq:optimizer.zero_grad()model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),torch.zeros(1, 1, model.hidden_layer_size))y_pred = model(seq)single_loss = loss_function(y_pred, labels)single_loss.backward()optimizer.step()if i%25 == 1:print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')print(f'epoch: {i:3} loss: {single_loss.item():10.10f}')
输出
epoch: 1 loss: 0.00517058
epoch: 26 loss: 0.00390285
epoch: 51 loss: 0.00473305
epoch: 76 loss: 0.00187001
epoch: 101 loss: 0.00000075
epoch: 126 loss: 0.00608046
epoch: 149 loss: 0.0004329932
由于 PyTorch 神经网络默认情况下会随机初始化权重,因此您可能会得到不同的值。
进行预测
现在我们的模型已经训练好了,我们可以开始进行预测。由于测试集包含过去 12 个月的乘客数据,并且我们的模型是使用长度为 12 的序列来进行预测训练的。因此,我们将首先从训练集中筛选出最后 12 个值:
fut_pred = 12test_inputs = train_data_normalized[-train_window:].tolist()
print(test_inputs)output
[0.12527473270893097, 0.04615384712815285, 0.3274725377559662, 0.2835164964199066, 0.3890109956264496, 0.6175824403762817, 0.9516483545303345, 1.0, 0.5780220031738281, 0.33186814188957214, 0.13406594097614288, 0.32307693362236023]
您可以将上述值与train_data_normalized数据列表的最后12个值进行比较。
最初,test_inputs 项目将包含12个项目。在for循环内部,这些12个项目将用于对测试集中的第一个项目(即第133项)进行预测。然后,预测值将附加到test_inputs列表中。在第二次迭代中,再次使用最后12个项目作为输入,并进行新的预测,然后再次将其附加到test_inputs列表中。由于测试集中有12个元素,因此for循环将执行12次。在循环结束时,test_inputs列表将包含24个项目。最后12项是测试集的预测值。
以下脚本用于进行预测:
model.eval()for i in range(fut_pred):seq = torch.FloatTensor(test_inputs[-train_window:])with torch.no_grad():model.hidden = (torch.zeros(1, 1, model.hidden_layer_size),torch.zeros(1, 1, model.hidden_layer_size))test_inputs.append(model(seq).item())
如果您打印test_inputs列表的长度,您将看到它包含24个项目。最后12个预测项可以按如下方式打印:
test_inputs[fut_pred:]
[0.4574652910232544,0.9810629487037659,1.279405951499939,1.0621851682662964,1.5830546617507935,1.8899496793746948,1.323508620262146,1.8764172792434692,2.1249167919158936,1.7745600938796997,1.7952896356582642,1.977765679359436]
需要再次提到的是,根据用于训练 LSTM 的权重不同,您可能会得到不同的值。
由于我们对数据集进行了归一化处理以进行训练,因此预测值也被归一化。我们需要将归一化后的预测值转换为实际预测值。我们可以通过将归一化后的值传递给最小/最大缩放器对象的inverse_transform方法来实现这一点。
actual_predictions = scaler.inverse_transform(np.array(test_inputs[train_window:] ).reshape(-1, 1))
print(actual_predictions)## output
[[435.57335371][554.69182083][622.56485397][573.14712578][691.64493555][761.46355206][632.59821111][758.38493103][814.91857016][735.21242136][739.92839211][781.44169205]]
现在让我们将预测值与实际值绘制出来。请看以下代码:
x = np.arange(132, 144, 1)
print(x)## output
[132 133 134 135 136 137 138 139 140 141 142 143]
在上面的脚本中,我们创建了一个包含过去12个月数值的列表。第一个月的索引值为0,因此最后一个月将在索引143处。
在下面的脚本中,我们将绘制144个月的乘客总数以及最后12个月预测的乘客数量。
plt.title('Month vs Passenger')
plt.ylabel('Total Passengers')
plt.grid(True)
plt.autoscale(axis='x', tight=True)
plt.plot(flight_data['passengers'])
plt.plot(x,actual_predictions)
plt.show()
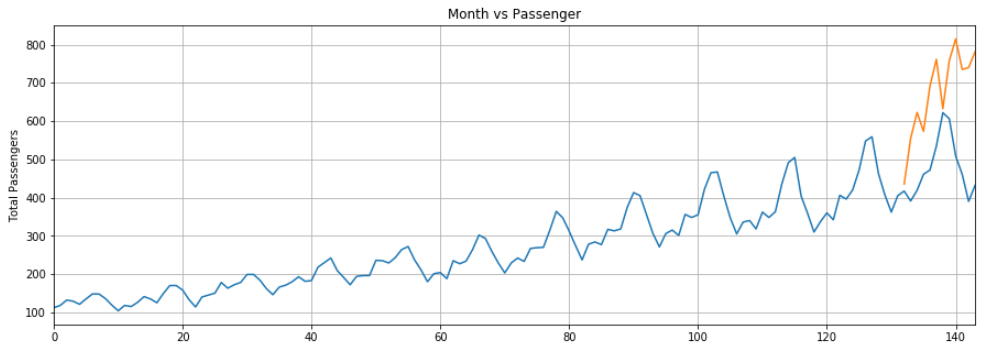
我们的LSTM所做出的预测由橙色线条表示。您可以看到,我们的算法并不是非常准确,但仍然能够捕捉到过去12个月旅客总数上升趋势以及偶发波动。您可以尝试增加训练轮数和LSTM层中神经元数量来提高性能。
为了更好地查看输出结果,我们可以按以下方式绘制过去12个月实际和预测乘客人数:
plt.title('Month vs Passenger')
plt.ylabel('Total Passengers')
plt.grid(True)
plt.autoscale(axis='x', tight=True)plt.plot(flight_data['passengers'][-train_window:])
plt.plot(x,actual_predictions)
plt.show()
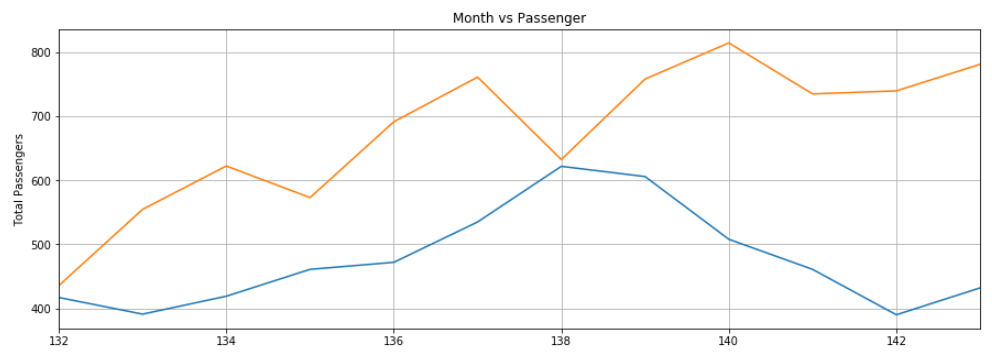
结论
LSTM 是解决序列问题最广泛使用的算法之一。在本文中,我们看到了如何使用 LSTM 对时间序列数据进行未来预测。
您还学会了如何使用 PyTorch 库实现 LSTM,并将预测结果与实际值绘制在一起以查看训练好的算法表现如何。
相关文章:
基于 PyTorch + LSTM 进行时间序列预测(附完整源码)
时间序列数据,顾名思义是一种随时间变化的数据类型。 例如,24小时内的温度、一个月内各种产品的价格、某家公司一年内的股票价格等。深度学习模型如长短期记忆网络(LSTM)能够捕捉时间序列数据中的模式,因此可以用于预…...
GEE页面介绍
目录一、背景二、用户界面三、数据类型:栅格1、请求图像集合2、学习查看栅格元数据3、矢量实例一:四、数据集五、数据属性1、空间分辨率2、时间分辨率六可视化多个波段1、真彩色(TCI)2彩色红外(CI)3、伪色 1 和 2 (FC1/FC2)七、可…...
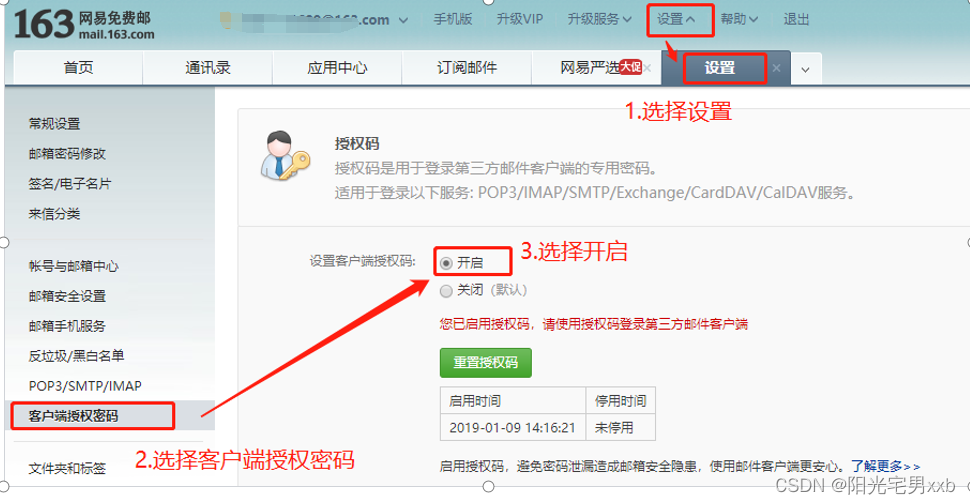
python自动发送邮件,qq邮箱、网易邮箱自动发送和回复
在python中,我们可以用程序来实现向别人的邮箱自动发送一封邮件,甚至可以定时,如每天8点钟准时给某人发送一封邮件。今天,我们就来学习一下,如何向qq邮箱,网易邮箱等发送邮件。 一、获取邮箱的SMTP授权码。…...

hastcat
hashcat 下载地址: https://hashcat.net/hashcat/ 案例 Usage: hashcat [options]... hash|hashfile|hccapxfile [dictionary|mask|directory]...https://xz.aliyun.com/t/4008破解linux shadow /etc/shadow中密码格式: $id$salt$encrypted如:$1$2eWq10AC$NaQqalCk3 1表…...

242. 一个简单的整数问题
Powered by:NEFU AB-IN Link 文章目录242. 一个简单的整数问题题意思路代码242. 一个简单的整数问题 题意 给定长度为 N的数列 A,然后输入 M行操作指令。 第一类指令形如 C l r d,表示把数列中第 l∼r个数都加 d 第二类指令形如 Q x,表示询问…...
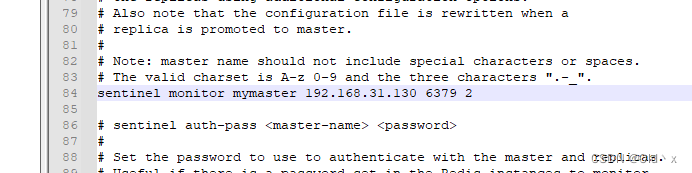
docker安装Redis高可用(一主二从三哨兵)
本次教程使用docker swarm安装 准备三台机器 hostIP用途node1192.168.31.130redis-master01,redis哨兵节点01node2192.168.31.131redis-slave01, redis哨兵节点02node3192.168.31.132redis-slave02 redis哨兵节点02 注意事项: 1:需要保证三…...
安全防御之入侵检测篇
目录 1.什么是IDS? 2.IDS和防火墙有什么不同?3.IDS的工作原理? 4.IDS的主要检测方法有哪些?请详细说明 5.IDS的部署方式有哪些? 6.IDS的签名是什么意思?签名过滤器有什么用?例外签名的配置作…...

学习系统编程No.10【文件描述符】
引言: 北京时间:2023/3/25,昨天摆烂一天,今天再次坐牢7小时,难受尽在不言中,并且对于笔试题,还是非常的困难,可能是我做题不够多,也可能是没有好好的总结之前做过的一些…...
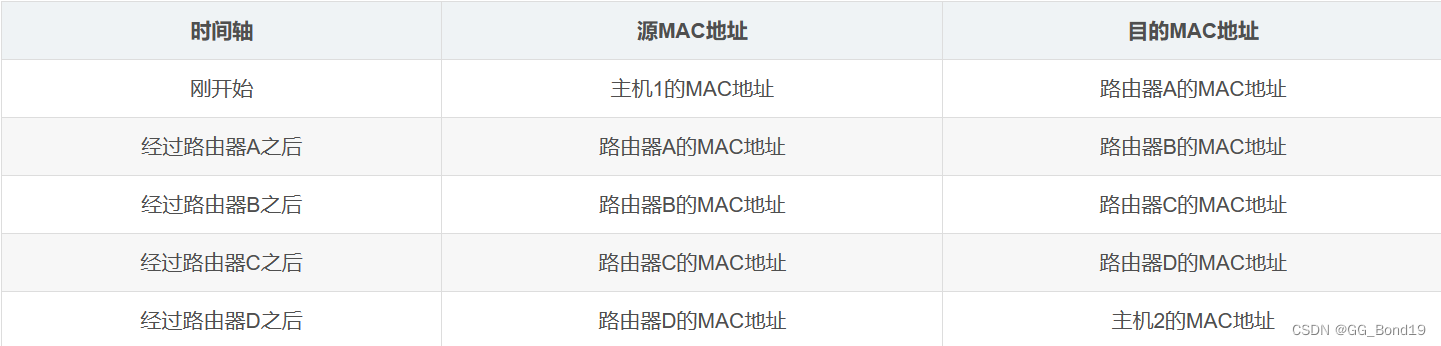
网络基础认识
目录 一、计算机网络背景 1.1 网络发展 1.2 "协议"由来 二、网络协议初识 2.1 协议分层 2.2 OSI七层模型 2.3 TCP/IP五层模型 三、网络协议栈 四、数据包封装与分用 五、网络传输基本流程 5.1 同局域网的两台主机通信 5.2 跨网络的两台主机通信 六、网络…...

【蓝桥杯_练习】
蓝桥杯1.创建工程2.LED灯点亮led.c3.LCD液晶屏显示lcd.c4.定时器按键单机interrupt.hinterrupt.cman.c5.定时器(长按键)interrupt.hinterrupt.cmain.c6.PWMmain.c7.定时器-输入捕获(频率,占空比测量)interrupt.cmain.c…...
【C语言蓝桥杯每日一题】——跑步锻炼
【C语言蓝桥杯每日一题】—— 跑步锻炼😎前言🙌排序🙌总结撒花💞😎博客昵称:博客小梦 😊最喜欢的座右铭:全神贯注的上吧!!! 😊作者简介…...

Qt之实现类似软件安装时的新功能介绍界面
一.效果 在软件安装时,一般会轮播软件的新功能,安装后,如果还想查看这些新功能该怎么办呢,我们可以把这个介绍新新功能的小应用集成到软件的“帮助”菜单中,比起纯黑文字的无趣介绍,图文方式的呈现会生动得多。 最近在看《赘婿》,借几张图过来用用。 二.原理 1.分层结…...

echarts地图不同地区设置不同的颜色
var myChart ec.init(document.getElementById(main));let option {tooltip: {trigger: item,},dataRange: {//左下角的颜色块。start:值域开始值;end:值域结束值;label:图例名称;color:自定义…...
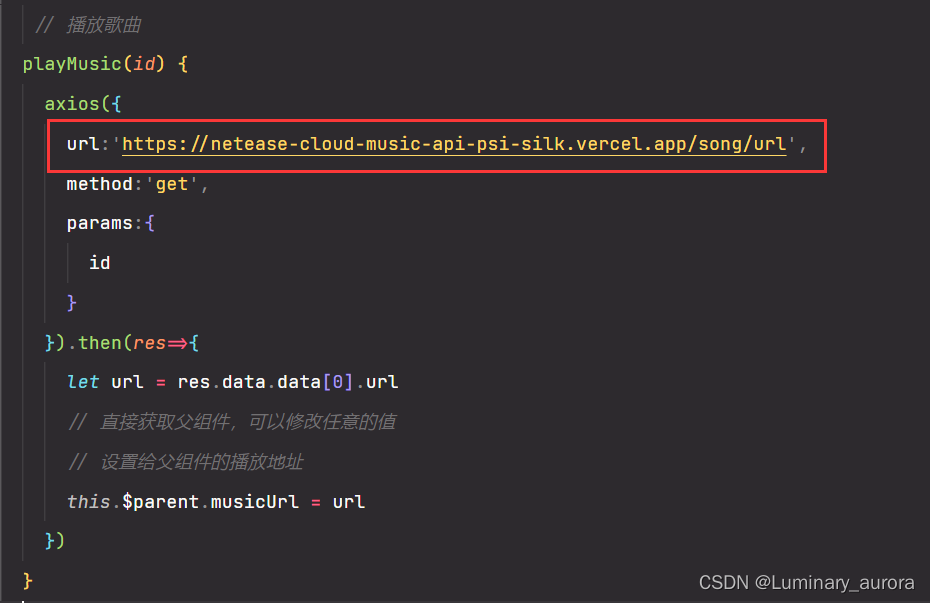
网易云音乐API部署Vercel获取接口过程
前提:部署自己的网易云接口主要用途在于在完成前端的仿网易云播放器的时候,根据自己部署的接口可以用于获取数据。大体流程是通过在github上fork别人的API接口项目,然后在Vercel部署即可获得自己的网易云后端数据接口了,不过根据我…...

Java基础:字符串(String)及常用操作
目录 字符串的声明及创建 字符串的操作 连接字符串(或concat) 获取字符串的长度 length 查找字符串 indexOf 获取字符串某个位置的字符 charAt 查询某个字符串是否存在 contains 截取字符串 substring(一) 截取字符串 su…...
FL Studio 21中文版支持主题随心换,FL Studio 21Mac版新增对苹果M2/1家族芯片原生支持。
FL Studio 21.0.0 官方中文版重磅发布 纯正简体中文支持,更快捷的音频剪辑及素材管理器,多样主题随心换! Mac版新增对苹果M2/1家族芯片原生支持。 更新版本:21.0.0支持语言:简体中文/英语更新时间:2022.12…...
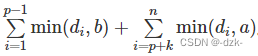
【蓝桥杯集训·周赛】AcWing 第96场周赛
文章目录第一题 AcWing 4876. 完美数一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解第二题 AcWing 4877. 最大价值一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解第三题 AcWing 4878. 维护数组一、题目1、原…...
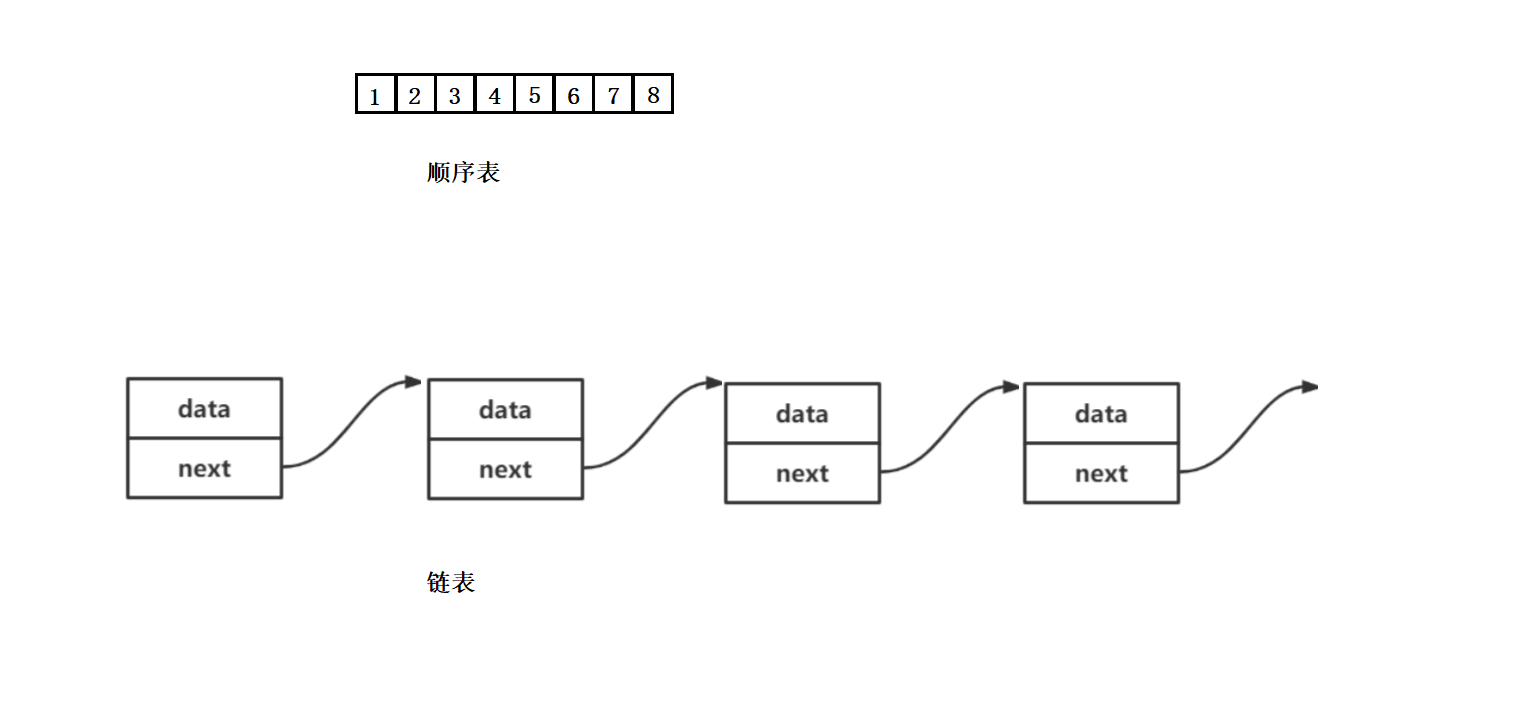
【数据结构】顺序表的深度刨剖析
前言:在上一篇文章中,我们已经对数据结构有了一定了解,我们可以通过优化空间复杂度或者时间复杂度从而提高我们程序运行或存储速率。至此我们就知道了数据结构的重要性,所以今天我们将要了解和学习一种实用的数据结构——线性表。…...

Unity 之 使用原生UGUI实现随手移动摇杆功能经典实例
Unity 之 使用原生UGUI实现随手移动摇杆功能实现效果一,实现思路1.1 原理解析1.2 思路概述二,实现代码2.1 随手落下2.2 摇杆转动三,源码分享3.1 场景搭建3.2 完整代码3.3 实现效果实现效果 本文最终实现效果: 一,实现…...
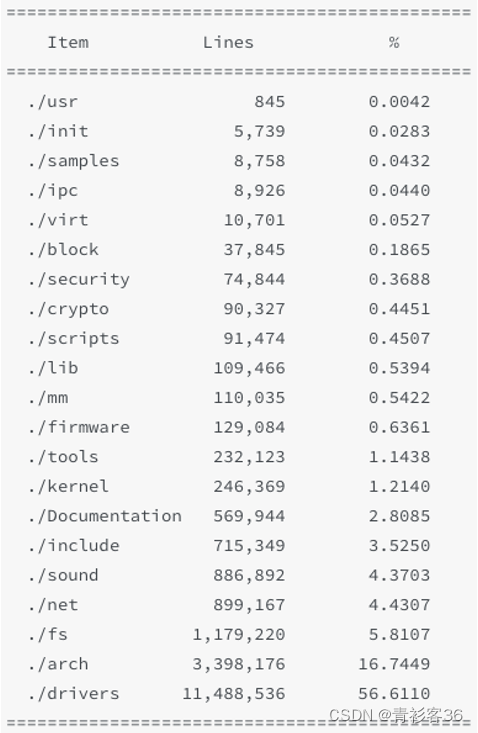
Linux内核源代码概述
Linux内核源代码非常庞大,截止到2015年据统计代码总量就已经超过1500万行(LOC,Line of Code),看代码总量非常吓人,具体看这1500万行代码的大致分布情况如下图。 显然占比最大的drivers和arch目录下的代码合…...

抖音批量下载神器:5分钟掌握高效内容采集的终极指南
抖音批量下载神器:5分钟掌握高效内容采集的终极指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...

如何在Docker容器中高效运行Android模拟器:完整实践指南
如何在Docker容器中高效运行Android模拟器:完整实践指南 【免费下载链接】docker-android Android in docker solution with noVNC supported and video recording 项目地址: https://gitcode.com/GitHub_Trending/do/docker-android 在移动应用开发和测试过…...

Diablo Edit2:10分钟掌握暗黑破坏神2存档修改终极指南
Diablo Edit2:10分钟掌握暗黑破坏神2存档修改终极指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 厌倦了在暗黑破坏神2中反复刷装备?想要快速测试新build却不想花费40小…...
)
全学科适用AI写作辅助软件排名(2026 精选)
基于功能完整性、学术适配性、用户满意度和操作便捷性,以下是当前主流AI论文写作工具的权威测评结果,按综合使用价值从高到低排序,并详细说明各工具的核心优势与适用领域。🏆 第一梯队:全流程学术解决方案(…...
)
别再复制粘贴了!手把手教你用Git命令将本地项目一键推送到GitLab仓库(含常见错误解决)
从零掌握Git命令流:本地项目高效同步GitLab全指南 在代码协作开发中,Git已成为不可或缺的版本控制工具。尽管现代IDE提供了便捷的图形化Git操作界面,但真正理解并熟练运用Git命令行,才是开发者摆脱"界面依赖症"、深入掌…...

三星固件下载全攻略:Bifrost跨平台工具的快速上手指南
三星固件下载全攻略:Bifrost跨平台工具的快速上手指南 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 还在为三星设备刷机找不到官方固件而烦恼吗&am…...
)
从单摆到机械臂:拉格朗日方程在机器人控制中的三个实战应用(附MATLAB/Simulink模型)
从单摆到机械臂:拉格朗日方程在机器人控制中的三个实战应用(附MATLAB/Simulink模型) 在机器人控制领域,动力学建模是连接理论设计与实际应用的关键桥梁。拉格朗日方程作为一种基于能量的分析方法,能够优雅地处理复杂系…...

chatgpt-mirai-qq-bot内存持久化:文件和Redis存储方案对比
chatgpt-mirai-qq-bot内存持久化:文件和Redis存储方案对比 你是否在为聊天机器人的记忆管理而烦恼?在多轮对话中,如何确保机器人能够记住上下文,同时保证数据的安全性和性能?chatgpt-mirai-qq-bot提供了两种内存持久化…...

Word怎么转图片?免费在线转换工具对比|2026实用方案
Word文档转换为图片是职场和学习中常见的需求。无论是为了方便分享、制作演示素材,还是保护文档隐私,掌握多种转换方法都能大幅提升工作效率。本文将为你盘点2026年最实用的Word转图片在线工具,以及电脑和手机端的完整解决方案。为什么要把Wo…...

5分钟上手:用VMagicMirror打造你的虚拟形象分身
5分钟上手:用VMagicMirror打造你的虚拟形象分身 【免费下载链接】VMagicMirror VRM Software for Windows to move avatar with minimal devices. 项目地址: https://gitcode.com/gh_mirrors/vm/VMagicMirror VMagicMirror是一款专为Windows设计的开源虚拟角…...