[DL]深度学习_扩散模型
扩散模型原理
深入浅出扩散模型
一、概念简介
1、Denoising Diffusion Probalistic Models,DDPM
1.1 扩散模型运行原理

- 首先sample一个都是噪声的图片向量,这个向量的shape和要生成的图像大小相同。
- 通过Denoise过程来一步一步有规律的滤去噪声。
- Denoise的次数是事先规定的,给每一个步骤给定编号,最终步骤编号为1。
- 从噪声到图像的过程称为Reverse Process
雕像已经在大理石里边了,我只是把不要的部分凿掉。--米开朗基罗
1.2 Denoise Model

将相同的Denoise model反复进行图像去噪过程,但是每一个步骤阶段输入的噪声图像之间差别很大。则如果每个不同阶段都使用完全相同的Denoise model或许表现不会很好。
解决方案是,设计Denoise时候,去噪过程中,输入元素不仅是该阶段的噪声影像,还同时输入当前图像的噪声覆盖严重程度指标(即当前是第几步骤)。Denoise model根据输入的噪声程度采取不同的去噪操作。
1.3 Denoise model内部构造

- Noise Predictor的作用是预测输入图像中的噪声分布。
- Noise Predictor通过接收输入噪声图像和噪声覆盖程度参数,生成预测的该噪声图像中的噪声分布图。
- 输出的预测噪声图与输入的噪声图相减,得出Denoise操作后的结果。
1.4 如何训练Noise Predictor

在训练预测噪声分布的时候是需要有Ground Truth来进行监督的,则需要首先制造Ground Truth标签来提供Noise Predictor训练。

- 首先,拿出一张训练影像,随机从高斯分布Gaussian distribution中sample一个噪声加到训练影像中,产生有点噪声的影像,并记录这是第几步增加噪声。
- 重复每一步骤增加噪声的过程,最后会得到一个完全被噪声覆盖的影像。
- 将训练集中的影像都进行这样增加噪声的处理。
- 做完增加噪声处理过后,就得到训练Denoise Predictor的每一噪声覆盖程度的Ground Truth数据了。
- 这个增加噪声的过程称为Forward Process(Diffusion Process)
1.5 文字提示的生成影像Text-to-Image

- 需要训练一个由文字生成影像的模型,则需要文本和影像成对的训练数据,如LAION数据集具有58.5亿张成对影像。
- 在训练过程中,通过在每一个Denoise步骤中加入文字描述条件来进行影响去噪。
- 即在Noise Predictor模组中同时输入文字描述条件。

- 每一张训练影像都有对应的文字描述,先将图片进行Diffusion Process增加噪声之后
- 在训练时不仅要给Noise Predictor输入该步骤的影像和步骤参数还包括文字描述。
- Noise Predictor根据输入的三者数据产生适当的噪声预测。
2、Stable Diffusion
2.1 框架Framework

经典Stable Diffusion框架由三个关键部件组成:Text Encoder文本编码器、Generation生成器、Decoder解码器。文本编码器将文本描述编码为向量嵌入;生成器则利用Diffusion model,输入一个噪声矩阵与文本编码输出一个“中间产物”,即高维度的编码影像;最后经过解码器来将编码影像解码输出生成的影像。通常三个模组是单独训练的,最后将其组合在一起。
2.1.1 Text Encoder

文本编码器的大小会影响到模型生成图像的质量好坏。图中的FID值越小越好,CLIP Score值越大越好。由图中的实验结果可以看出,当文本编码器的参数量越大时,模型生成后的图像质量越高。
edges:

- FID(Fréchet Inception Distance)一种用于评估生成模型的图像质量的指标。
- 先有一个预训练好的CNN分类模型,将影像输入CNN模型中,得到CNN模型的潜在representation,之后将真实影像的representation和生成影像的representation画出来。
- 若两组representation之间的距离越接近则表示生成的图像与真实图像越相近,则生成质量越高。
- 假设两者representation的分布为高斯分布,FID通过计算两组representation之间的Fréchet距离,FID值越小越好。
- FID存在的问题是需要sample出很多的影像才能计算,如FID-10k就是sample了10k张影像来评估模型的生成性能。

- CLIP Score代表通过使用经由400 million个影像-文本对上预训练的CLIP模型,将生成的影像和该影像对应的文本描述同时输入预训练好的CLIP模型中。
- CLIP模型利用图像编码器和文本编码器将输入的影像和文本描述编码为特征向量。
- 给影像向量与文本向量之间计算相似性,相似性越高证明生成的影像和文本描述越贴合,则生成的影像质量很高。
2.1.2 Generation Model

经研究之后,Generation中的Diffusion Model的大小对生成图像的质量影响非常小。上图的U-Net size表示Diffusion Model中的Noise Predictor的大小。
训练过程

- Noise需要添加在中间产物(小图或潜在表征)上。
- 先利用Encoder将一幅影像进行编码,得到潜在表征。
- sample一个噪声,添加在潜在表征上,重复添加噪声的过程,直到最后得到的潜在表征变为纯粹的噪声。
- 将某一step添加噪声的潜在表征作为输入,该step的编号代表当前噪声的覆盖程度作为输入,还有对原始图像的文本描述进行编码之后得到的文本潜在向量作为输入。
- 训练Noise Predictor来预测当前的step的噪声潜在表征,当前step添加进去的噪声分布作为Ground Truth进行监督。
生成过程

- 首先纯粹从高斯分布(正态分布)中sample出的潜在表征输入Denoise。
- 对当前生成的文本描述进行编码之后作为条件输入Denoise。
- Denoise通过训练好Noise Predictor预测噪声来去除一些潜在表征在文本描述条件下的噪声。
- 重复去除噪声的步骤。
- 直到产生的潜在表征达到质量要求之后,将潜在表征输入训练好的Decoder来解码为最终的生成影像。
2.1.3 Decoder
Decoder在训练时不需要影像配对的文本描述。
Generation输出为低分辨率影像时对Decoder训练的策略

- 可以将训练影像都进行下采样操作,得到成对的下采样后影像与原始图像对。
- 利用低分辨率和原始影像对进行Decoder的训练。
Generation输出为潜在表征时对Decoder训练的策略

- 训练一个Auto-encoder,将输入的影像进行编码之后得到潜在表征。
- 将潜在表征通过Decoder还原为原始影像。
- 训练目的是将Decoder还原的影像与原始影像越接近。
- 训练好Decoder之后,Decoder就可以执行将输入的潜在表征解码为生成的最终影像。
3、Diffusion Model的数学原理
3.1 Denoising DIffusion Probabilistic Models的算法
3.1.1 Training过程

- repeat---表示一直重复步骤1到步骤5的内容,直到converged结束。
---首先sample一张干净的影像
,即所需要生成的影像。
---从1到T之间sample一个整数t,T通常会设定一个较大的数值,例如T=1000。
---从一个高斯分布(正态分布)中sample一个noise为
,该正态分布的平均值mean为0,每一个维度的方差variance为1。sample的noise
---公式中红色框中所做的事是
,通常设计是由大到小,
最大,则如果第三步sample的t值越大,代表
越小,代表原始图像占比越小,noise占比越多,则t值sample到越大,代表噪声添加的越多。进行权值相加之后得到的是一个加了噪声的影像,作为
函数的输入,这个

- 概念中的Diffusion Model运行应该是一点一点在原始影像上添加噪声,每次训练Noise Predictor的时候是把有噪声的影像作为输入,再输入step的数值来预测这个step添加进来的噪声分布,还原的时候将有噪声的影像还原为该step添加噪声之前的状态。想象中是噪声是一点一点添加进去,Denoise时候也是一点一点去除噪声。
- 实际上DDPM的运行是给原始的影像直接按照权重比例添加一个噪声,得到有噪声的影像。训练时就是将有噪声的影像和 t 作为输入,直接预测添加的噪声分布。实际上噪声并没有一步一步添加进来,并没有多次添加噪声,而是一次直接将噪声添加进去,在Denoise时候也是一次就将噪声去除。
3.1.2 Sampling过程

---首先从正态分布中sample一个全是Noise的影像
。
---Reverse process过程生成影像,需要循环T次。
---每次生成图的时候,都要先从正态分布中sample一个Noise z。
---其中
是上一轮循环中得到的,减去带有权重的Denoise中的Noise Predictor预测的噪声分布
。式子中的关键点为最后需要加上一个噪声
,这里
是一个常数。最终得到的影像为
。
3.2 影像生成模型本质上的共同目标

影像生成模型本质上的共同目标是在输入端有一个简单已知的概率分布,通常是高斯分布。从高斯分布中sample出一个向量z出来,输入到一个Network中G(z)=x,输出为一张影像x。就算输入是很简单的高斯分布sample,通过一个Network之后转换为一个非常复杂的影像x,该影像x应该与真实的影像分布越接近。

更常见的应用是给一段文本描述,根据描述来生成图形。这段文本描述称之为条件Condition,但是对应的影像是千变万化的,此时模型的目标是产生出的影像分布与真实影像的分布越接近越好。
3.3 最大似然估计Maximum Likelihood Estimation
3.3.1 概述
最大似然估计(Maximum Likelihood Estimation,简称MLE)是统计学中一种用于估计概率分布参数的方法。MLE的目标是找到最大化似然函数的参数值,其中似然函数衡量观测数据与分布之间的拟合程度。
MLE的基本思想是找到使观测数据最有可能发生的参数值。这是通过计算在不同的参数值下获得观测数据的概率来实现的。为了进行MLE,需要根据对概率分布的假设定义似然函数。然后通过对参数求导并令导数等于零来最大化似然函数。这将得到一组方程,可以通过数值求解来获得参数估计值。

如何去衡量两个分布之间的距离,常用影像生成模型的衡量方法是最大似然估计。
- 假设Network的参数用
表示,根据Network生成的分布用
表示,真实分布用
表示。
- 首先从
,这些影像是训练模型时所需要的训练数据。
- 假设能够计算Network
的几率
(实际上因为
- 要得出的模型参数

- 目标函数为上图公式,
代表需要寻找一组参数
部分的值最大。
- 最终得到的
为模型学习所需要得到的参数。
3.3.2 目标函数详解

- 因为arg max操作的目的是取最大值,则给原式取log不影响最终结果。
---左边式子中和最大,近似于每个
---等同于对x做积分。
---不会影响结果
---则此时与KL散度Kullback-Leibler Divergence等价。KL散度作用是计算两个概率分布之间的差异程度。KL散度的值越大就代表两个概率分布之间的差异越大。
- 在求取模型参数的目标中,最大似然估计等价于最小化KL散度。
3.4 VAE与DDPM的相似推导
3.4.1 VAE的推导

---要去计算x被生成的概率需要去看每一个z被生成的概率,再看每个z生成x的概率,再对所有的z求积分。其中每个z被生成的概率是已知,如从高斯分布中sample的z。
---代表每个z经过Network生成x的概率。式子中,若一个z经过Network生成的影像完全逐像素相等于x,此时概率为1,反之就是0。但是生成的影像几乎不可能和原始影像x逐像素完全相同,这样定义的坏处是每张生成的影像的概率都可能是0。
- VAE中的假设是,输入z,输出G(z),G(z)代表高斯分布的mean均值。
---式子中
的随机发生的概率Probability Density正比于G(z)与x的距离的第二范式,取负号,再取e的指数函数。假设G(z)代表高斯分布的均值mean,
3.4.2 VAE中logP(x)的下界

在VAE中无法直接最大化P(x),通常真正最大化的是P(x)的下界。
---无论是什么分布,等式都成立。logP(x)与z无关,提出积分符号外边之后,积分里边的值等于1。
---根据贝叶斯公式可以得到。
---为
的KL散度。KL散度衡大于等于0,
。
---则对其取期望值,就得到概率
的下界。
- 在VAE中
- 在做VAE时就相当于是寻找一个好的方法来最大化下界。
3.4.3 DDPM的推导

当DDPM生成影像时,可以把过程想成生成了一个高斯分布的mean,如果
与生成的
完全相同,此时概率最大。(假设为高斯分布并不完全合理,且假设每个维度都是固定的,文献中的实验都证明将方差考虑进来并不会提升性能。假设输出为高斯分布因为对中间部分推导有益)

整个DDPM在生成某一幅影像的概率可以写成上式。对所有可能的
做积分。
3.4.4 q(x_t|x_t-1)的推导

先有一张
相乘,
为事先设定好的超参数,可以调整。
乘上从高斯分布中sample出的噪声。
- 则
,方差为
,每个维度的方差都相同。
的计算实际上是可以直接算出的,并不需要按照步骤计算。

- 每一个step中从高斯分布中sample出的噪声之间是相互独立的。
- 将上一个step的
公式带入到
中,可以得到

- 在同一个高斯分布中sample出两个噪声,并乘上两个不同的权重,加起来之后的概率分布项可以简化成只从高斯分布中sample一次噪声乘上一个权重。相互独立的高斯分布的和仍然是高斯分布。

- 以此类推,整个扩散过程可以整合为图中式子。
- 为了公式简化,设定为
,
。
- 实际上整个扩散过程是一步到位的只需要从高斯分布中sample一次噪声。
3.4.5 DDPM中logP(x)的下界

- DDPM的下界在形式上与VAE十分相似,且推导过程也是相同步骤。
- DDPM中的
为扩散过程Diffusion Process。

- 需要最大化的下界在整理之后得到可以计算的公式。

- 第一项是
的概率分布,对
取期望值。
- 第二项为
与
的KL散度。(第二项可以不用计算,
- 第三项中期望值的概率分布是

---假设已经看到
- 可以算出的是
、
。
- 同经公式变换化简之后得到
,已知化简后式子中都是高斯分布。

- 通过推导

如何去最小化KL散度
- 并不需要实际的计算出KL散度,只需要最小化KL散度。
是由Denoise Model决定的,但是均值variance也是固定的,假设输出的高斯分布的每个维度的方差都是固定值。也有文献讨论过均值variance方差但是并不影响结果。均值mean取决于Denoise Model,如果目标是让两个分布的KL散度越大,即让两个分布越接近越好。
- 其中
- 实际上的操作是,
。通过训练Denoise Model,让

- 期望
中

- Denoise Model接受输入
- 再将

- 在要真实生成的目标中,Network真正需要去预测的是加到影像中的噪声
与
- 在DDPM论文中视图训练
3.5 补充说明部分
3.5.1 Sampling算法中需要额外添加噪声猜想

- 需要考虑的是为什么在Sampling算法中还需要多添加一个噪声。
- 在Denoise model输出的是一个高斯分布的均值mean,在做sample时候需要加上一个噪声代表考虑高斯分布的方差variance。
- 若直接取均值mean,代表取高斯分布中的概率密度函数最大的输出。
猜想:

- Diffusion Model其实是一种Autoregressive Model妥协的结果。
- Autoregressive Model的一次到位的结果通常不好,将其改为N个step。
- 每次Denoise的步骤相当于Autoregressive的一个step,在做Autoregressive时每个step需要添加一点噪声,即一点随机性结果才会好,也许在Denoise时也加一点噪声,随机性会好。

- 通过验证这种说法,当
- 当
时,就无法生成正常影像。
相关文章:
[DL]深度学习_扩散模型
扩散模型原理 深入浅出扩散模型 一、概念简介 1、Denoising Diffusion Probalistic Models,DDPM 1.1 扩散模型运行原理 首先sample一个都是噪声的图片向量,这个向量的shape和要生成的图像大小相同。通过Denoise过程来一步一步有规律的滤去噪声。Den…...

AI学习记录 - 如何快速构造一个简单的token词汇表
创作不易,有用的话点个赞 先直接贴代码,我们再慢慢分析,代码来自openai的图像分类模型的一小段 def bytes_to_unicode():"""Returns list of utf-8 byte and a corresponding list of unicode strings.The reversible bpe c…...

JAVA中的数组流ByteArrayOutputStream
Java 中的 ByteArrayOutputStream 是一个字节数组输出流,它允许应用程序以字节的形式写入数据到一个字节数组缓冲区中。以下是对 ByteArrayOutputStream 的详细介绍,包括其构造方法、方法、使用示例以及运行结果。 一、ByteArrayOutputStream 概述 Byt…...

S3C2440中断处理
一、中断处理机制概述 中断是CPU在执行程序过程中,遇到急需处理的事件时,暂时停止当前程序的执行,转而执行处理该事件的中断服务程序,并在处理完毕后返回原程序继续执行的过程。S3C2440提供了丰富的中断源,包括内部中…...

《数据分析与知识发现》
《数据分析与知识发现》介绍 1 期刊定位 《数据分析与知识发现》(Data Analysis and Knowledge Discovery)是由中国科学院主管、中国科学院文献情报中心主办的学术性专业期刊。期刊创刊于2017年,由《现代图书情报技术》(1985-20…...
IaaS,PaaS,aPaaS,SaaS,FaaS,如何区分?
IaaS, PaaS,SaaS,aPaaS 还有一种 FaaS ,这几个都是云服务中常见的 5 大类型: IaaS:基础架构即服务,Infrastructure as a Service PaaS:平台即服务,Platform as a Service aPaaS&…...

软件测试工具分享
要想在测试中旗开得胜,趁手的“武器”那是相当重要(说人话,要保证测试质量和效率,测试工具也很重要)。现在,小酋打算亮一亮自己的武器库,希望不要闪瞎你的眼(天上在打雷,…...
word翻译工具有哪些?5个工具助你快速翻译Word文件
无论是商业沟通还是文化交流,都需要跨越语言障碍。而文档翻译则是这一过程中的重要环节之一。 想象一下,当你需要将一份重要的Word文档从一种语言翻译成另一种语言时,如果手动逐句翻译不仅耗时耗力,还可能因为文化差异导致误解。…...

【51单片机】ds18b20驱动,11.0592MHZ,使用DS18b20
文章目录 ds18b20.h #include <reg52.h> #include <intrins.h> #include <math.h>// 管脚定义 sbit DS18B20_DATA_PIN = P1 ^ 0; // DS18B20数据口定义/******************************************************************************* * 函 数 名 …...

Vue 导航条+滑块效果
目录 前言代码效果展示导航实现代码导航实现代码导航应用代码前言 总结一个最近开发的需求。设计稿里面有一个置顶的导航条,要求在激活的项目下面展示个下划线。我最先开始尝试的是使用 after 的伪类选择器,直接效果一样,但是展示的时候就会闪现变化,感觉不够自然,参考了一…...

Android:使用Gson常见问题(包含解决将Long型转化为科学计数法的问题)
一、解决将Long型转化为科学计数法的问题 1.1 场景 将一个对象转为Map类型时,调用Gson.fromJson发现,原来对象中的long类型的personId字段,被解析成了科学计数法,导致请求接口失败,报参数错误。 解决结果图 1.2、Exa…...

【Win开发环境搭建】Redis与可视化工具详细安装与配置过程
🎯导读:本文档提供了Redis的简介、安装指南、配置教程及常见操作方法。包括了安装包的选择与配置环境变量的过程,详细说明了如何通过修改配置文件来设置密码和端口等内容。同时,文档还介绍了如何使用命令行工具连接Redisÿ…...

Compose知识分享
前言 “Jetpack Compose 是一个适用于 Android 的新式声明性界面工具包。Compose 提供声明性 API,让您可在不以命令方式改变前端视图的情况下呈现应用界面,从而使编写和维护应用界面变得更加容易。” 以上是Compose官网中对于Compose这套全新的Androi…...

python-study-day5
urllib中handler的使用 import urllib.request url "http://www.baidu.com" headers {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0 } # 请求地址的定制 reques…...

Telegram mini app 本地开发配置
前言: 为了能在telegram里本地调试mini app,参考了网上很多方案,踩了不少坑。最后整了一个适合自己的方案,记录一下。 这个方案一定不是最好的,不过是目前适合我上手开发的方案了。 本文章适合需要在 telegram 本地…...

python发票查验接口助您拒绝做糊涂账、发票ocr
发票识别发票查验接口让发票真假立现。仅需一键上传发票图片,即可实现发票真伪的秒速、批量验证,操作简单方便,避免因人工核验失误所导致“错账”现象的发生,减轻财务工作负担,提升企业工作效率,降低因假票…...

【Linux】线程控制|POSIX线程库|多线程创建|线程终止|等待|线程分离|线程空间布局
目录 编辑 POSIX线程库 多线程创建 独立栈结构 获取线程ID pthread_self 线程终止 return终止线程 pthread_exit pthread_cancel 线程等待 退出码问题 线程分离 测试 线程ID及地址空间布局 编辑 POSIX线程库 pthread线程库是 POSIX线程库的一部分…...
JimuReport 积木报表 v1.8.0 版本发布,开源可视化报表
项目介绍 一款免费的数据可视化报表工具,含报表和大屏设计,像搭建积木一样在线设计报表!功能涵盖,数据报表、打印设计、图表报表、大屏设计等! Web 版报表设计器,类似于excel操作风格,通过拖拽完…...
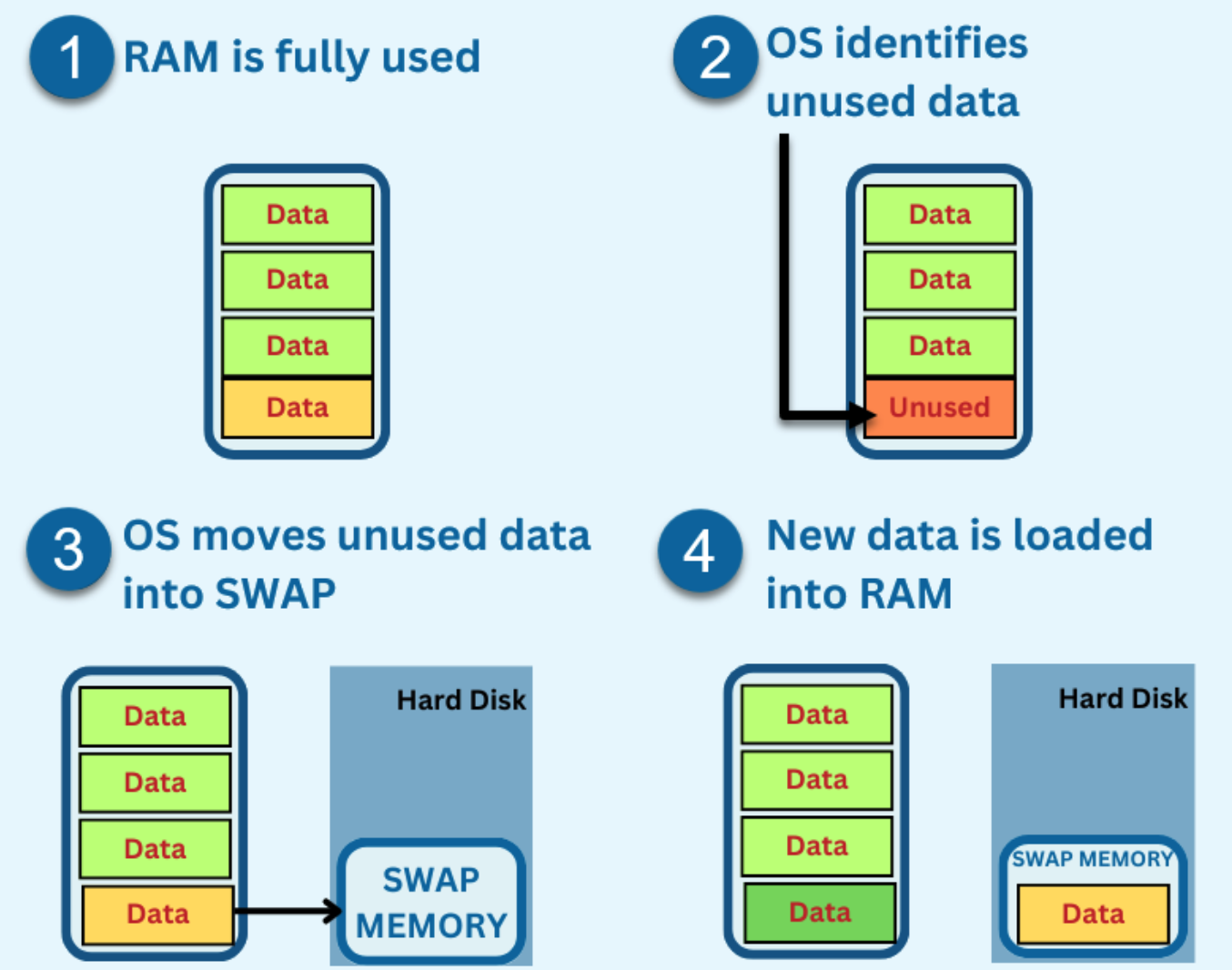
性能优化理论篇 | swap area是个什么东西
我们知道每台计算机的内存(RAM)都是有限的,而我们的应用程序需要加载到内存才能被运行,如果一台机器运行多个应用程序时,内存可能会耗尽。Linux 系统中的“交换空间(也称为交换分区)”可以帮助缓…...
下载安装win/mac版)
Photoshop (PS)下载安装win/mac版
目录 一、概述 下载 二、安装步骤 三、使用教程 四、快捷键汇总 一、概述 Adobe Photoshop,简称“PS”,是由Adobe Systems开发和发行的图像处理软件。它主要处理以像素所构成的数字图像,涵盖了诸多领域,如图像编辑、图像合成…...
)
【详细版教程】飞书聊天控制电脑 OpenClaw 配置实操教程(含安装包)
OpenClaw 飞书机器人配置教程|一键对接飞书 聊天下达 AI 指令 适配版本:OpenClaw v2.7.1(小龙虾)前置要求:已部署 OpenClaw Windows 端(Win10/Win11 均可),未部署可先下载一键部署包…...

树莓派Pico通过DVI Sock实现HDMI视频输出:原理、配置与图形编程实战
1. 项目概述与核心价值如果你手头有一个树莓派 Pico 或者 Pico W,看着它强大的 RP2040 双核处理器和丰富的 GPIO,是不是偶尔会想:要是它能直接输出视频到我的大显示器上,那能玩的花样可就太多了。无论是做个迷你游戏机、一个酷炫的…...
)
【ElevenLabs情绪控制失效紧急修复】:4步定位pitch-contour断裂、valence-arousal偏移问题(附Python诊断脚本)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术解析 核心原理与神经声学建模 ElevenLabs 的情绪模拟并非简单调节语速或音高,而是基于多任务联合训练的扩散语音模型(Diffusion-based TTS)&…...

3步搞定Axure中文汉化:让专业原型设计工具说中文
3步搞定Axure中文汉化:让专业原型设计工具说中文 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 你是否在使用Axure …...

文档即播客时代已来,你还在手动录音?NotebookLM自动化播客流水线搭建全解析
更多请点击: https://intelliparadigm.com 第一章:文档即播客时代已来,你还在手动录音? 当 Markdown 文件能自动生成语音流、API 文档可一键转为双语播客、技术博客支持语义分段朗读与知识图谱锚点跳转时,“文档即播客…...

告别蓝屏与闪退:揪出“ntdll.dll”相关故障的五大根源及实战修复
在Windows的世界里,ntdll.dll就像一位无处不在的“幕后总调度”。无论是您点击的办公软件,还是运行的游戏,最终都需要通过它来向系统内核发出请求。正因如此,一旦它出现问题,故障现象会千奇百怪:程序突然闪…...

如何高效解锁艾尔登法环帧率限制:专业玩家的完整配置指南
如何高效解锁艾尔登法环帧率限制:专业玩家的完整配置指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/…...

上位机知识篇---提高Linux下载速度
提升 wget、pip 和 conda 的下载速度,核心方法可以归结为两类:一是使用更快的下载工具,二是连接到更近的镜像站点。下面的表格总结了几种主流的加速方案,方便你快速查阅:提速方法wgetpipconda🚀 换用更快的…...

应对高并发场景Taotoken的稳定性与路由策略实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 应对高并发场景Taotoken的稳定性与路由策略实践 1. 高并发AI服务面临的挑战 在构建依赖大模型API的应用程序时,工程团…...

全栈开发实战:基于Next.js与SQLite构建个人收入追踪系统
1. 项目概述与核心价值最近在独立开发者圈子里,一个叫“Indomi/earnings-tracker”的项目引起了我的注意。乍一看这个名字,你可能会觉得它又是一个平平无奇的收入追踪工具,但当你真正去拆解它的设计思路和代码实现时,会发现它精准…...