【人工智能】项目案例分析:使用自动编码器进行信用卡欺诈检测
一、项目背景
信用卡欺诈是金融行业面临的一个重要问题,快速且准确的欺诈检测对于保护消费者和金融机构的利益至关重要。本项目旨在通过利用自动编码器(Autoencoder)这一无监督学习算法,来检测信用卡交易中的欺诈行为,特别适合于异常检测任务,因为它能够学习正常数据的分布,并通过重构误差来识别异常数据。
二、项目概述
目标:构建一个自动编码器模型,用于检测信用卡交易数据中的潜在欺诈行为。
数据集:我们将使用一个公开的信用卡欺诈数据集,该数据集已经被预处理过,包括标准化的特征和一个指示是否为欺诈交易的目标变量。
技术栈:
- 编程语言:Python
- 数据分析库:Pandas
- 数据可视化库:Matplotlib
- 机器学习库:TensorFlow/Keras
三、架构设计
- 数据准备:加载数据集,进行初步的数据探索和预处理。
- 模型构建:定义自动编码器模型,包括编码器和解码器部分。
- 模型训练:使用正常交易数据训练自动编码器。
- 异常检测:通过计算重构误差来识别潜在的欺诈交易。
- 结果评估:使用常见的评估指标来评估模型的性能。
四、示例代码
首先,我们需要安装必要的库:
pip install tensorflow pandas matplotlib接下来,让我们开始编写代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, classification_report# 读取数据
def load_data(file_path):data = pd.read_csv(file_path)return data# 数据预处理
def preprocess_data(data):# 分离特征和标签X = data.drop('Class', axis=1)y = data['Class']# 标准化特征scaler = StandardScaler()X_scaled = scaler.fit_transform(X)return X_scaled, y# 构建自动编码器模型
def build_autoencoder(input_dim):input_layer = Input(shape=(input_dim,))# 编码器encoded = Dense(128, activation='relu')(input_layer)encoded = Dense(64, activation='relu')(encoded)encoded = Dense(32, activation='relu')(encoded)# 解码器decoded = Dense(64, activation='relu')(encoded)decoded = Dense(128, activation='relu')(decoded)decoded = Dense(input_dim, activation='linear')(decoded)autoencoder = Model(inputs=input_layer, outputs=decoded)autoencoder.compile(optimizer='adam', loss='mse')encoder = Model(inputs=input_layer, outputs=encoded)return autoencoder, encoder# 训练模型
def train_model(autoencoder, X_train, epochs=100, batch_size=32):autoencoder.fit(X_train, X_train,epochs=epochs,batch_size=batch_size,shuffle=True,validation_split=0.2,verbose=1)# 异常检测
def detect_anomalies(autoencoder, X_test):# 使用自动编码器进行重构reconstructions = autoencoder.predict(X_test)# 计算重构误差reconstruction_errors = np.mean(np.power(X_test - reconstructions, 2), axis=1)return reconstruction_errors# 可视化结果
def plot_results(reconstruction_errors, threshold, y_true):plt.figure(figsize=(10, 6))plt.hist(reconstruction_errors, bins=50, color='blue', alpha=0.6, label='Reconstruction Errors')plt.axvline(threshold, color='red', linestyle='--', linewidth=2, label=f'Threshold: {threshold:.2f}')plt.xlabel('Reconstruction Error')plt.ylabel('Count')plt.legend()plt.show()# 主函数
if __name__ == '__main__':file_path = 'creditcard.csv' # 假设这是信用卡欺诈数据集的路径data = load_data(file_path)# 数据预处理X_scaled, y = preprocess_data(data)# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 构建自动编码器模型input_dim = X_train.shape[1]autoencoder, encoder = build_autoencoder(input_dim)# 训练模型train_model(autoencoder, X_train)# 异常检测reconstruction_errors = detect_anomalies(autoencoder, X_test)# 设置阈值threshold = np.percentile(reconstruction_errors, 95)# 评估结果y_pred = (reconstruction_errors > threshold).astype(int)print("Confusion Matrix:")print(confusion_matrix(y_test, y_pred))print("Classification Report:")print(classification_report(y_test, y_pred))# 可视化结果plot_results(reconstruction_errors, threshold, y_test)五、注意事项
- 数据集:确保你使用的数据集已经被适当预处理过,包括标准化特征等。
- 模型架构:自动编码器的架构可以根据具体情况调整,例如层数和节点数量。
- 阈值选择:选择合适的阈值非常重要,可以通过观察重构误差的分布来确定一个合理的阈值。
- 评估指标:由于欺诈检测是一个不平衡分类问题,因此除了混淆矩阵外,还可以使用精确率、召回率和F1分数等指标来评估模型性能。
六、扩展和完善项目
在现有代码的基础上,我们可以进一步扩展和完善项目,包括以下方面:
- 数据探索与可视化:更好地理解数据集的特征分布。
- 模型调优:通过超参数调优来提高模型性能。
- 异常检测阈值的确定:使用更系统的方法来确定异常检测的阈值。
- 模型评估:使用多种评估指标来全面评估模型性能。
- 结果可视化:更详细的可视化结果,包括混淆矩阵和ROC曲线等。
1.示例代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, classification_report, roc_auc_score, roc_curve, precision_recall_curve
from sklearn.model_selection import GridSearchCV
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier# 读取数据
def load_data(file_path):data = pd.read_csv(file_path)return data# 数据探索
def explore_data(data):# 查看数据集的基本统计信息print(data.describe())# 查看数据集中各特征的相关性correlation_matrix = data.corr()plt.figure(figsize=(10, 8))sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')plt.title('Correlation Matrix')plt.show()# 数据预处理
def preprocess_data(data):# 分离特征和标签X = data.drop('Class', axis=1)y = data['Class']# 标准化特征scaler = StandardScaler()X_scaled = scaler.fit_transform(X)return X_scaled, y# 构建自动编码器模型
def build_autoencoder(input_dim, hidden_units=[128, 64, 32]):input_layer = Input(shape=(input_dim,))# 编码器encoded = Dense(hidden_units[0], activation='relu')(input_layer)encoded = Dense(hidden_units[1], activation='relu')(encoded)encoded = Dense(hidden_units[2], activation='relu')(encoded)# 解码器decoded = Dense(hidden_units[1], activation='relu')(encoded)decoded = Dense(hidden_units[0], activation='relu')(decoded)decoded = Dense(input_dim, activation='linear')(decoded)autoencoder = Model(inputs=input_layer, outputs=decoded)autoencoder.compile(optimizer='adam', loss='mse')encoder = Model(inputs=input_layer, outputs=encoded)return autoencoder, encoder# 超参数调优
def tune_hyperparameters(X_train, y_train):def create_model(hidden_units=[128, 64, 32]):input_dim = X_train.shape[1]autoencoder, _ = build_autoencoder(input_dim, hidden_units)return autoencoderparam_grid = {'hidden_units': [[128, 64, 32], [128, 64, 16]],'batch_size': [32, 64],'epochs': [100, 150]}model = KerasClassifier(build_fn=create_model, verbose=0)grid = GridSearchCV(estimator=model, param_grid=param_grid, cv=3, scoring='neg_mean_squared_error')grid_result = grid.fit(X_train, X_train)print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))means = grid_result.cv_results_['mean_test_score']stds = grid_result.cv_results_['std_test_score']params = grid_result.cv_results_['params']for mean, stdev, param in zip(means, stds, params):print("%f (%f) with: %r" % (mean, stdev, param))return grid_result.best_params_# 训练模型
def train_model(autoencoder, X_train, epochs=100, batch_size=32):autoencoder.fit(X_train, X_train,epochs=epochs,batch_size=batch_size,shuffle=True,validation_split=0.2,verbose=1)# 异常检测
def detect_anomalies(autoencoder, X_test):# 使用自动编码器进行重构reconstructions = autoencoder.predict(X_test)# 计算重构误差reconstruction_errors = np.mean(np.power(X_test - reconstructions, 2), axis=1)return reconstruction_errors# 确定异常检测阈值
def determine_threshold(reconstruction_errors, y_test):precision, recall, thresholds = precision_recall_curve(y_test, reconstruction_errors)f1_scores = 2 * (precision * recall) / (precision + recall)f1_scores = np.nan_to_num(f1_scores)best_threshold_index = np.argmax(f1_scores)best_threshold = thresholds[best_threshold_index]return best_threshold# 可视化结果
def plot_results(reconstruction_errors, threshold, y_test):plt.figure(figsize=(10, 6))plt.hist(reconstruction_errors, bins=50, color='blue', alpha=0.6, label='Reconstruction Errors')plt.axvline(threshold, color='red', linestyle='--', linewidth=2, label=f'Threshold: {threshold:.2f}')plt.xlabel('Reconstruction Error')plt.ylabel('Count')plt.legend()plt.show()# 绘制混淆矩阵y_pred = (reconstruction_errors > threshold).astype(int)cm = confusion_matrix(y_test, y_pred)plt.figure(figsize=(6, 6))sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=['Normal', 'Fraud'], yticklabels=['Normal', 'Fraud'])plt.xlabel('Predicted')plt.ylabel('True')plt.title('Confusion Matrix')plt.show()# 绘制ROC曲线fpr, tpr, _ = roc_curve(y_test, reconstruction_errors)auc = roc_auc_score(y_test, reconstruction_errors)plt.figure(figsize=(6, 6))plt.plot(fpr, tpr, label=f'ROC curve (AUC = {auc:.2f})')plt.plot([0, 1], [0, 1], 'k--')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('False Positive Rate')plt.ylabel('True Positive Rate')plt.title('Receiver Operating Characteristic')plt.legend(loc="lower right")plt.show()# 主函数
if __name__ == '__main__':file_path = 'creditcard.csv' # 假设这是信用卡欺诈数据集的路径data = load_data(file_path)# 数据探索explore_data(data)# 数据预处理X_scaled, y = preprocess_data(data)# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 超参数调优best_params = tune_hyperparameters(X_train, y_train)# 构建自动编码器模型input_dim = X_train.shape[1]autoencoder, encoder = build_autoencoder(input_dim, hidden_units=best_params['hidden_units'])# 训练模型train_model(autoencoder, X_train, epochs=best_params['epochs'], batch_size=best_params['batch_size'])# 异常检测reconstruction_errors = detect_anomalies(autoencoder, X_test)# 确定阈值threshold = determine_threshold(reconstruction_errors, y_test)# 评估结果y_pred = (reconstruction_errors > threshold).astype(int)print("Confusion Matrix:")print(confusion_matrix(y_test, y_pred))print("Classification Report:")print(classification_report(y_test, y_pred))# 可视化结果plot_results(reconstruction_errors, threshold, y_test)2.新增功能说明
- 数据探索与可视化:通过统计描述和相关性热力图来更好地理解数据集的特征分布。
- 模型调优:使用
GridSearchCV进行超参数调优,寻找最优的隐藏层单元数、批次大小和训练轮次。 - 异常检测阈值的确定:通过计算F1分数来确定最优的异常检测阈值。
- 模型评估:使用混淆矩阵、分类报告、ROC曲线和AUC值等多种评估指标来全面评估模型性能。
- 结果可视化:增加了混淆矩阵和ROC曲线的可视化。
3.注意事项
- 数据集:确保你使用的数据集已经被适当预处理过,包括标准化特征等。
- 模型架构:自动编码器的架构可以根据具体情况调整,例如层数和节点数量。
- 阈值选择:通过计算F1分数来确定最优阈值,这种方法可以平衡精度和召回率。
- 评估指标:由于欺诈检测是一个不平衡分类问题,因此除了混淆矩阵外,还可以使用精确率、召回率和F1分数等指标来评估模型性能。
七、总结
以上代码提供了一个基本的框架来使用自动编码器进行信用卡欺诈检测。通过训练自动编码器来学习正常交易数据的分布,并通过计算重构误差来识别潜在的异常交易。这个项目现在不仅能够训练自动编码器来检测信用卡欺诈,还能够通过多种方式评估模型的性能,并且能够可视化结果。这些改进使得该项目更加贴近实际应用场景,也为你提供了更多的工具来探索和优化异常检测模型。
如果文章内容对您有所触动,别忘了点赞、关注,收藏!
推荐阅读:
1.【人工智能】项目实践与案例分析:利用机器学习探测外太空中的系外行星
2.【人工智能】利用TensorFlow.js在浏览器中实现一个基本的情感分析系统
3.【人工智能】TensorFlow lite介绍、应用场景以及项目实践:使用TensorFlow Lite进行数字分类
4.【人工智能】使用NLP进行语音到文本的转换和主题的提取项目实践及案例分析一
5.【人工智能】使用NLP进行语音到文本的转换和主题的提取项目实践及案例分析二
相关文章:

【人工智能】项目案例分析:使用自动编码器进行信用卡欺诈检测
一、项目背景 信用卡欺诈是金融行业面临的一个重要问题,快速且准确的欺诈检测对于保护消费者和金融机构的利益至关重要。本项目旨在通过利用自动编码器(Autoencoder)这一无监督学习算法,来检测信用卡交易中的欺诈行为,…...

【工控】线扫相机小结
背景简介 我目前接触到的线扫相机有两种形式: 无采集卡,数据通过网线传输。 配备采集卡,使用PCIe接口。 第一种形式的数据通过网线传输,速度较慢,因此扫描和生成图像的速度都较慢,参数设置主要集中在相机本身。第二种形式的相机配备采集卡,通常速度更快,但由于相机和…...

将Web应用部署到Tomcat根目录的三种方法
将应用部署到Tomcat根目录的三种方法 将应用部署到Tomcat根目录的目的是可以通过"http://[ip]:[port]"直接访问应用,而不是使用"http://[ip]:[port]/[appName]"上下文路径进行访问。 方法一:(最简单直接的方法࿰…...

工业和信息化部教育与考试中心计算机相关专业介绍
国家工信部的认证证书在行业内享有较高声誉。 此外,还设有专门的工业和信息化技术技能人才数据库查询服务,进一步方便了个人和企业对相关职业能力证书的查询需求。 序号 专业工种 级别 备注 1 JAVA程序员 初级 职业技术 2 电子…...

第二证券:生物天然气线上交易达成 创新探索互联互通、气证合一
8月20日,上海石油天然气生意中心在国内立异推出生物天然气线上生意。当日,绿气新动力(北京)有限公司(简称“绿气新动力”)挂单的1500万立方米生物天然气被百事食物(我国)有限公司&am…...

重磅!RISC-V+OpenHarmony平板电脑发布
仟江水商业电讯(8月18日 北京 委托发布)RISC-V作为历史上全球发展速度最快、创新最为活跃的开放指令架构,正在不断拓展高性能计算领域的边界。OpenHarmony是由开放原子开源基金会孵化并运营的开源项目,已成为发展速度最快的智能终…...
[DL]深度学习_扩散模型
扩散模型原理 深入浅出扩散模型 一、概念简介 1、Denoising Diffusion Probalistic Models,DDPM 1.1 扩散模型运行原理 首先sample一个都是噪声的图片向量,这个向量的shape和要生成的图像大小相同。通过Denoise过程来一步一步有规律的滤去噪声。Den…...

AI学习记录 - 如何快速构造一个简单的token词汇表
创作不易,有用的话点个赞 先直接贴代码,我们再慢慢分析,代码来自openai的图像分类模型的一小段 def bytes_to_unicode():"""Returns list of utf-8 byte and a corresponding list of unicode strings.The reversible bpe c…...

JAVA中的数组流ByteArrayOutputStream
Java 中的 ByteArrayOutputStream 是一个字节数组输出流,它允许应用程序以字节的形式写入数据到一个字节数组缓冲区中。以下是对 ByteArrayOutputStream 的详细介绍,包括其构造方法、方法、使用示例以及运行结果。 一、ByteArrayOutputStream 概述 Byt…...

S3C2440中断处理
一、中断处理机制概述 中断是CPU在执行程序过程中,遇到急需处理的事件时,暂时停止当前程序的执行,转而执行处理该事件的中断服务程序,并在处理完毕后返回原程序继续执行的过程。S3C2440提供了丰富的中断源,包括内部中…...

《数据分析与知识发现》
《数据分析与知识发现》介绍 1 期刊定位 《数据分析与知识发现》(Data Analysis and Knowledge Discovery)是由中国科学院主管、中国科学院文献情报中心主办的学术性专业期刊。期刊创刊于2017年,由《现代图书情报技术》(1985-20…...
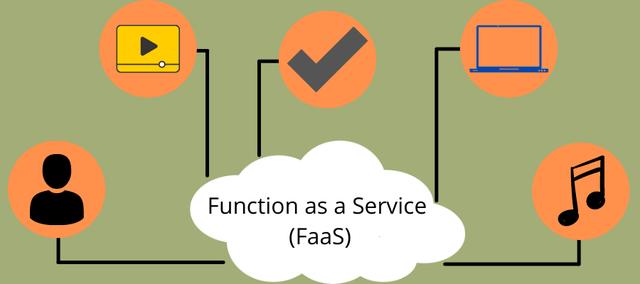
IaaS,PaaS,aPaaS,SaaS,FaaS,如何区分?
IaaS, PaaS,SaaS,aPaaS 还有一种 FaaS ,这几个都是云服务中常见的 5 大类型: IaaS:基础架构即服务,Infrastructure as a Service PaaS:平台即服务,Platform as a Service aPaaS&…...

软件测试工具分享
要想在测试中旗开得胜,趁手的“武器”那是相当重要(说人话,要保证测试质量和效率,测试工具也很重要)。现在,小酋打算亮一亮自己的武器库,希望不要闪瞎你的眼(天上在打雷,…...
word翻译工具有哪些?5个工具助你快速翻译Word文件
无论是商业沟通还是文化交流,都需要跨越语言障碍。而文档翻译则是这一过程中的重要环节之一。 想象一下,当你需要将一份重要的Word文档从一种语言翻译成另一种语言时,如果手动逐句翻译不仅耗时耗力,还可能因为文化差异导致误解。…...

【51单片机】ds18b20驱动,11.0592MHZ,使用DS18b20
文章目录 ds18b20.h #include <reg52.h> #include <intrins.h> #include <math.h>// 管脚定义 sbit DS18B20_DATA_PIN = P1 ^ 0; // DS18B20数据口定义/******************************************************************************* * 函 数 名 …...

Vue 导航条+滑块效果
目录 前言代码效果展示导航实现代码导航实现代码导航应用代码前言 总结一个最近开发的需求。设计稿里面有一个置顶的导航条,要求在激活的项目下面展示个下划线。我最先开始尝试的是使用 after 的伪类选择器,直接效果一样,但是展示的时候就会闪现变化,感觉不够自然,参考了一…...

Android:使用Gson常见问题(包含解决将Long型转化为科学计数法的问题)
一、解决将Long型转化为科学计数法的问题 1.1 场景 将一个对象转为Map类型时,调用Gson.fromJson发现,原来对象中的long类型的personId字段,被解析成了科学计数法,导致请求接口失败,报参数错误。 解决结果图 1.2、Exa…...

【Win开发环境搭建】Redis与可视化工具详细安装与配置过程
🎯导读:本文档提供了Redis的简介、安装指南、配置教程及常见操作方法。包括了安装包的选择与配置环境变量的过程,详细说明了如何通过修改配置文件来设置密码和端口等内容。同时,文档还介绍了如何使用命令行工具连接Redisÿ…...

Compose知识分享
前言 “Jetpack Compose 是一个适用于 Android 的新式声明性界面工具包。Compose 提供声明性 API,让您可在不以命令方式改变前端视图的情况下呈现应用界面,从而使编写和维护应用界面变得更加容易。” 以上是Compose官网中对于Compose这套全新的Androi…...

python-study-day5
urllib中handler的使用 import urllib.request url "http://www.baidu.com" headers {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0 } # 请求地址的定制 reques…...

基于AgentPort框架快速构建AI智能体Web应用门户
1. 项目概述:从零到一构建你的AI智能体门户最近在GitHub上看到一个挺有意思的项目,叫agentport,作者是yakkomajuri。光看这个名字,你可能会有点摸不着头脑——“Agent Port”?智能体端口?这到底是干嘛的&am…...

构建数字情绪护盾:基于情感分析与规则引擎的个性化内容过滤系统
1. 项目概述:构建你的数字情绪护盾在数字生活的洪流中,我们每天都被海量的信息、社交互动和网络噪音所包围。你有没有过这样的感觉:刷了半小时手机,不仅没放松,反而感到莫名的焦虑和疲惫?或者,在…...

ucharts的使用
uCharts是一款基于canvas API开发的适用于所有前端应用的图表库,开发者编写一套代码,可运行到 Web、iOS、Android(基于 uni-app / taro )、以及各种小程序(微信/支付宝/百度/头条/飞书/QQ/快手/钉钉/淘宝/京东/360&…...

程序设计语言 —计算机等级考试—软件设计师考前备忘录—东方仙盟
章节:程序设计语言 → 程序语言分类就在程序语言基础那一大块,专门分 4 大类:命令式(过程式)语言函数式语言逻辑式语言面向对象语言你刷题没翻到,是因为一般教材把它放在:编译原理 / 程序设计语…...

聚合式AI对话客户端chatAllAI2:多模型统一管理与本地部署实战
1. 项目概述:一个聚合式AI对话客户端的诞生最近在折腾AI工具的朋友,可能都遇到过这样的烦恼:手头同时用着好几个AI服务,比如ChatGPT、Claude、文心一言、通义千问等等。每次想对比不同模型的回答,或者根据任务切换最合…...

有限元分析前传:不懂‘最小势能原理’和‘自然边界条件’?从变分法开始说清楚
有限元分析前传:从变分法到最小势能原理的工程实践指南 在ANSYS或Abaqus中点击"求解"按钮时,软件究竟在背后执行什么数学魔法?许多工程师能熟练操作CAE界面,却对弹窗中"势能最小化计算中"的提示感到困惑。当我…...
)
【SPIE出版】黄冈师范学院主办!第四届大数据、计算智能与应用国际会议(BDCIA 2026)
第四届大数据、计算智能与应用国际会议(BDCIA 2026)将于2026年11月6-8日在中国黄冈召开。本次大会由黄冈师范学院主办,旨在汇聚全球学术界与产业界的专家学者、研究人员及工程技术人员,共同探讨大数据、计算智能及相关应用领域的前…...

对TinyRedis中主从复制的理解
TinyRedis 中有 master 和 replica 两种角色。master 作为服务端监听端口,既可以管理普通客户端连接,也可以接收 replica 建立的复制连接。replica 本身也是一个服务端,但对于 master 来说,它会额外作为客户端主动创建 socket fd …...
)
别再用老方法了!手把手教你用Coilcraft在线工具搞定BUCK电感选型(附避坑指南)
别再用老方法了!手把手教你用Coilcraft在线工具搞定BUCK电感选型(附避坑指南) 在电源设计领域,BUCK电路因其高效、稳定的特性成为工程师们的首选方案。然而,电感选型这个看似简单的环节却让不少资深工程师栽过跟头——…...

shadcn-ui-expansions Infinite Scroll 实现原理:构建高性能无限滚动列表的完整指南
shadcn-ui-expansions Infinite Scroll 实现原理:构建高性能无限滚动列表的完整指南 【免费下载链接】shadcn-ui-expansions More components built on top of shadcn-ui. 项目地址: https://gitcode.com/gh_mirrors/sh/shadcn-ui-expansions shadcn-ui-expa…...