目标跟踪算法——ByteTrack算法原理解析
文章目录
- ByteTrack
- 1. ByteTrack算法步骤:
- 2. 算法解释
- 2.1 模型初始化
- 2.2 模型更新算法流程
- 2.2.1 检测结果划分,划分为高分和较低分段
- 2.2.2 高分段处理手段
- 2.2.3 最优匹配与未匹配划分
- 2.2.4 低分框再匹配
- 2.2.5 未确认轨迹处理
- 2.2.6 更新状态
- 2.3 匈牙利匹配算法(线性分配)
ByteTrack
1. ByteTrack算法步骤:
- 目标检测:ByteTrack算法首先会对视频数据进行目标检测。
- 检测结果划分:根据得分(score)对检测结果进行划分。通过设定一个阈值,将检测结果分为高分(high score)和低分(low score)两个部分。高分部分通常对应着较为准确的检测结果,而低分部分可能包含一些误检或检测不准的目标。
- 初次匹配:将高分中的检测结果与已有的跟踪轨迹进行匹配追踪。这一步通常使用如SORT等算法进行。在这个过程中,会有部分轨迹成功匹配到检测结果,但也有部分轨迹可能没有被匹配成功。
- 再次匹配:对于初次匹配中未能成功匹配的轨迹,ByteTrack算法会将其与低分中的检测结果进行再次匹配。这样做的目的是为了尽可能利用所有的检测结果,提高跟踪的准确性和鲁棒性。
- 新建和保留轨迹:对于未能匹配到任何检测结果的跟踪轨迹,ByteTrack算法会保留这些轨迹m帧(m是一个预设的帧数),等待这些轨迹再次出现时再进行匹配。对于没有匹配上跟踪轨迹但得分又足够高的检测框,ByteTrack算法会新建一个跟踪轨迹。
2. 算法解释
2.1 模型初始化
def __init__(self, args, frame_rate=30):# 初始化一个空列表,用于存储正在被跟踪的轨迹self.tracked_stracks = [] # type: list[STrack]# 初始化一个空列表,用于存储丢失的轨迹(即当前帧中未检测到的轨迹)self.lost_stracks = [] # type: list[STrack]# 初始化一个空列表,用于存储已经从跟踪列表中移除的轨迹self.removed_stracks = [] # type: list[STrack]# 当前处理的帧的ID,初始化为0self.frame_id = 0# 存储算法的参数self.args = args#self.det_thresh = args.track_thresh# 初始化检测阈值,这个值用于判断检测到的物体是否应该被追踪# 初始值设置为args中的track_thresh值加上0.1self.det_thresh = args.track_thresh + 0.1# 根据帧率和args中的track_buffer来计算buffer的大小self.buffer_size = int(frame_rate / 30.0 * args.track_buffer)# 最大时间丢失阈值,用于判断一个轨迹何时应该被视为丢失self.max_time_lost = self.buffer_size# 初始化Kalman滤波器,用于预测物体的位置self.kalman_filter = KalmanFilter()
2.2 模型更新算法流程
2.2.1 检测结果划分,划分为高分和较低分段
self.frame_id += 1
# 初始化几个列表,用于存储不同类型的轨迹
activated_starcks = []
refind_stracks = []
lost_stracks = []
removed_stracks = []# 根据output_results的形状决定如何处理检测结果
if output_results.shape[1] == 5:# 如果输出结果的列数是5,那么只包含边界框和分数scores = output_results[:, 4] # 获取分数列bboxes = output_results[:, :4] # 获取边界框列
else:# 否则,需要将output_results从tensor转换为numpy数组output_results = output_results.cpu().numpy()scores = output_results[:, 4] # 获取分数列# 这一行被注释掉了,如果取消注释,则会将分数与另一列相乘# scores = output_results[:, 4] * output_results[:, 5]bboxes = output_results[:, :4] # 获取边界框列,格式为x1y1x2y2(左上角和右下角坐标)# 以下是关于边界框缩放的代码
# scale = min(img_size[0] / float(img_h), img_size[1] / float(img_w))
# bboxes /= scale# 过滤掉分数低于跟踪阈值的检测结果
remain_inds = scores > self.args.track_thresh
# 分割出分数较高的和较低的检测结果
inds_low = scores > 0.1
inds_high = scores < self.args.track_thresh
# 找到同时满足上述两个条件的索引
inds_second = np.logical_and(inds_low, inds_high)# 获取对应的边界框和分数
dets = bboxes[remain_inds]
scores_keep = scores[remain_inds]dets_second = bboxes[inds_second]
scores_second = scores[inds_second]
2.2.2 高分段处理手段
if len(dets) > 0:'''Detections'''# 创建新的轨迹对象,并添加到detections列表中detections = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for(tlbr, s) in zip(dets, scores_keep)]
else:# 如果没有符合条件的检测结果,则detections列表为空detections = []
''' Add newly detected tracklets to tracked_stracks'''# 将未激活的轨迹添加到unconfirmed列表中,已激活的轨迹添加到tracked_stracks列表中
unconfirmed = []
tracked_stracks = [] # type: list[STrack]
for track in self.tracked_stracks:if not track.is_activated:unconfirmed.append(track)else:tracked_stracks.append(track)
2.2.3 最优匹配与未匹配划分
1.通过计算IoU距离来评估轨迹与检测框之间的匹配程度,并使用匈牙利算法来找到最优匹配。
2.匹配成功后,轨迹会根据新的检测框信息进行更新,或者被重新激活。
3.未匹配的轨迹和检测框则分别存储在u_track和u_detection中,
轨迹和检测框可能需要在后续步骤中进行进一步处理,例如将长时间未匹配的轨迹标记为丢失或移除。
# 第二步:首先与分数较高的检测结果进行关联将当前正在跟踪的轨迹和已丢失的轨迹合并成一个列表,准备进行匹配
strack_pool = joint_stracks(tracked_stracks, self.lost_stracks)
# Predict the current location with KF
# 使用Kalman滤波器预测strack_pool中每个轨迹在当前帧的位置
STrack.multi_predict(strack_pool)
# 计算strack_pool中每个轨迹的预测位置与当前帧检测框之间的IoU距离
dists = matching.iou_distance(strack_pool, detections)
# 如果不是使用MOT20格式的数据集,则根据检测框的分数调整IoU距离
if not self.args.mot20:dists = matching.fuse_score(dists, detections)
# 使用线性分配算法(也称为匈牙利算法)进行轨迹与检测框的匹配
# 返回匹配成功的轨迹和检测框索引对,未匹配的轨迹索引和未匹配的检测框索引
matches, u_track, u_detection = matching.linear_assignment(dists, thresh=self.args.match_thresh)
# 遍历匹配结果
for itracked, idet in matches:# 获取匹配的轨迹和检测框track = strack_pool[itracked]det = detections[idet]if track.state == TrackState.Tracked:# 将激活的轨迹添加到activated_starcks列表中track.update(detections[idet], self.frame_id)activated_starcks.append(track)else:# 如果轨迹是处于丢失状态(Lost) 重新激活轨迹,使用新的检测框信息,将重新找到的轨迹添加到refind_stracks列表中track.re_activate(det, self.frame_id, new_id=False)refind_stracks.append(track)
2.2.4 低分框再匹配
1.如果存在分数较低的检测框,将它们转换成STrack对象列表。
1.1 从未匹配的轨迹中筛选出状态为Tracked的轨迹。
1.2 计算这些轨迹与分数较低的检测框之间的IoU距离。
1.3使用线性分配算法进行二次匹配,阈值设为0.
匹配成功的轨迹根据检测框信息更新或重新激活。
对于剩余未匹配的轨迹,如果它们不是已标记为Lost的状态,则将它们标记为Lost并添加到lost_stracks列表中。
# 第三步:使用分数较低的检测框进行二次关联# 如果存在分数较低的检测框if len(dets_second) > 0:# 创建一个新的轨迹列表,用于存储分数较低的检测框'''Detections'''detections_second = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for (tlbr, s) in zip(dets_second, scores_second)]else:# 如果没有分数较低的检测框,则创建一个空列表detections_second = []# 从未匹配的轨迹中筛选出状态为Tracked的轨迹r_tracked_stracks = [strack_pool[i] for i in u_track if strack_pool[i].state == TrackState.Tracked]# 计算筛选后的轨迹与分数较低的检测框之间的IoU距离dists = matching.iou_distance(r_tracked_stracks, detections_second)# 使用线性分配算法进行二次匹配,匹配阈值设为0.5matches, u_track, u_detection_second = matching.linear_assignment(dists, thresh=0.5)# 遍历匹配结果for itracked, idet in matches:# 获取匹配的轨迹和检测框track = r_tracked_stracks[itracked]det = detections_second[idet]# 如果轨迹是处于跟踪状态(Tracked)if track.state == TrackState.Tracked:# 使用检测框的信息更新轨迹track.update(det, self.frame_id)# 将激活的轨迹添加到activated_starcks列表中activated_starcks.append(track)# 如果轨迹不是处于跟踪状态(可能是Lost)else:# 重新激活轨迹,使用新的检测框信息track.re_activate(det, self.frame_id, new_id=False)# 将重新找到的轨迹添加到refind_stracks列表中refind_stracks.append(track)# 遍历剩余未匹配的轨迹for it in u_track:# 获取轨迹track = r_tracked_stracks[it]# 如果轨迹不是已标记为Lost的状态if not track.state == TrackState.Lost:# 标记轨迹为Losttrack.mark_lost()# 将Lost状态的轨迹添加到lost_stracks列表中lost_stracks.append(track)
2.2.5 未确认轨迹处理
- 从所有检测框中筛选出与未确认轨迹相关的检测框。
- 计算未确认轨迹与这些检测框之间的IoU距离。
- 如果不是使用MOT20标准,则将轨迹的分数与IoU距离融合,以得到一个综合的匹配距离。
- 使用线性分配算法进行匹配,阈值设为0.7。
- 对于匹配成功的未确认轨迹,使用检测框的信息进行更新,并将其标记为已激活,添加到activated_starcks列表中。
- 对于剩余的未确认轨迹,即未能与任何检测框匹配的轨迹,将其标记为已移除,并添加到removed_stracks列表中。
# 处理未确认的轨迹,这些轨迹通常只有起始帧
'''Deal with unconfirmed tracks, usually tracks with only one beginning frame'''
# 从所有检测框中筛选出与未确认轨迹相关的检测框
detections = [detections[i] for i in u_detection]# 计算未确认轨迹与筛选后的检测框之间的IoU距离
dists = matching.iou_distance(unconfirmed, detections)# 如果不是使用MOT20标准,则将轨迹的分数与IoU距离融合
if not self.args.mot20:dists = matching.fuse_score(dists, detections)# 使用线性分配算法进行匹配,匹配阈值设为0.7
matches, u_unconfirmed, u_detection = matching.linear_assignment(dists, thresh=0.7)# 遍历匹配结果
for itracked, idet in matches:# 获取匹配的未确认轨迹和检测框track = unconfirmed[itracked]det = detections[idet]# 使用检测框的信息更新未确认轨迹track.update(det, self.frame_id)# 将已激活的轨迹添加到activated_starcks列表中activated_starcks.append(track)# 遍历剩余的未确认轨迹
for it in u_unconfirmed:# 获取轨迹track = unconfirmed[it]# 标记轨迹为已移除track.mark_removed()# 将已移除的轨迹添加到removed_stracks列表中removed_stracks.append(track)
2.2.6 更新状态
检查并移除那些超过最大丢失时间阈值的丢失轨迹。
更新已跟踪的轨迹列表,只保留状态为“Tracked”的轨迹。
将新激活的轨迹和重新找到的轨迹添加到已跟踪的轨迹列表中。
更新丢失的轨迹列表,移除那些已经被跟踪的轨迹,并添加新标记为丢失的轨迹。
从丢失的轨迹列表中移除那些已经被移除的轨迹。
将已移除的轨迹添加到移除的轨迹列表中。
移除已跟踪和丢失轨迹列表中的重复轨迹。
返回所有已激活的跟踪轨迹列表。
# 遍历所有标记为丢失的轨迹
for track in self.lost_stracks:# 如果轨迹丢失的时间超过了最大允许丢失时间if self.frame_id - track.end_frame > self.max_time_lost:# 标记轨迹为已移除track.mark_removed()# 将移除的轨迹添加到removed_stracks列表中removed_stracks.append(track)# 更新已跟踪的轨迹列表,只保留状态为Tracked的轨迹
self.tracked_stracks = [t for t in self.tracked_stracks if t.state == TrackState.Tracked]
# 将新激活的轨迹(activated_starcks)添加到已跟踪的轨迹列表中
self.tracked_stracks = joint_stracks(self.tracked_stracks, activated_starcks)
# 将重新找到的轨迹(refind_stracks)也添加到已跟踪的轨迹列表中
self.tracked_stracks = joint_stracks(self.tracked_stracks, refind_stracks)
# 从丢失的轨迹列表中移除那些已经被跟踪的轨迹
self.lost_stracks = sub_stracks(self.lost_stracks, self.tracked_stracks)
# 将新标记为丢失的轨迹(lost_stracks)添加到丢失的轨迹列表中
self.lost_stracks.extend(lost_stracks)
# 从丢失的轨迹列表中移除那些已经被移除的轨迹
self.lost_stracks = sub_stracks(self.lost_stracks, self.removed_stracks)
# 将已移除的轨迹(removed_stracks)添加到移除的轨迹列表中
self.removed_stracks.extend(removed_stracks)
# 移除已跟踪和丢失轨迹列表中的重复轨迹
self.tracked_stracks, self.lost_stracks = remove_duplicate_stracks(self.tracked_stracks, self.lost_stracks)
# 获取所有已激活的跟踪轨迹
output_stracks = [track for track in self.tracked_stracks if track.is_activated]
# 返回已激活的跟踪轨迹列表
return output_stracks
2.3 匈牙利匹配算法(线性分配)
在 cost, x, y = lap.lapjv(cost_matrix, extend_cost=True, cost_limit=thresh) 这行代码中,lapjv 函数来自 SciPy 的 scipy.optimize 模块,用于解决线性分配问题(也称为匈牙利算法)。这个函数会找到一种最优的配对方式,使得两组元素之间的配对总成本最小。
函数的参数解释如下:
cost_matrix: 这是一个二维数组(或矩阵),表示不同元素配对之间的成本。cost_matrix[i][j]表示将第一组中的第i个元素与第二组中的第j个元素配对的成本。extend_cost: 这是一个布尔值,当设置为True时,lapjv函数会扩展成本矩阵,使其成为一个方阵(即行数和列数相等),并在扩展的部分填充一个足够大的值,以确保原始成本矩阵中的配对是最优的。这对于非方阵的成本矩阵是必要的,因为匈牙利算法要求成本矩阵是方阵。cost_limit: 这是一个阈值,用于限制考虑的配对成本。只有当配对的成本小于或等于此阈值时,该配对才会被考虑在内。这有助于排除那些成本过高的配对,从而加速计算过程或找到满足特定条件的解。
函数的返回值解释如下:
cost: 这是一个标量值,表示找到的最优配对方案的总成本。x: 这是一个整数数组,表示第一组元素与第二组元素的配对关系。如果x[i]的值是j(且j是非负的),那么表示第一组中的第i个元素与第二组中的第j个元素被配对。如果x[i]的值是负数,那么表示第一组中的第i个元素没有被配对。y: 这是一个整数数组,与x类似,表示第二组元素与第一组元素的配对关系。如果y[j]的值是i(且i是非负的),那么表示第二组中的第j个元素与第一组中的第i个元素被配对。如果y[j]的值是负数,那么表示第二组中的第j个元素没有被配对。
def linear_assignment(cost_matrix, thresh):'''线性分配,匈牙利算法Args:cost_matrix:thresh:Returns:'''if cost_matrix.size == 0:return np.empty((0, 2), dtype=int), tuple(range(cost_matrix.shape[0])), tuple(range(cost_matrix.shape[1]))matches, unmatched_a, unmatched_b = [], [], []cost, x, y = lap.lapjv(cost_matrix, extend_cost=True, cost_limit=thresh)for ix, mx in enumerate(x):if mx >= 0:matches.append([ix, mx])unmatched_a = np.where(x < 0)[0]unmatched_b = np.where(y < 0)[0]matches = np.asarray(matches)return matches, unmatched_a, unmatched_b
, [], []cost, x, y = lap.lapjv(cost_matrix, extend_cost=True, cost_limit=thresh)for ix, mx in enumerate(x):if mx >= 0:matches.append([ix, mx])unmatched_a = np.where(x < 0)[0]unmatched_b = np.where(y < 0)[0]matches = np.asarray(matches)return matches, unmatched_a, unmatched_b
相关文章:

目标跟踪算法——ByteTrack算法原理解析
文章目录 ByteTrack1. ByteTrack算法步骤:2. 算法解释2.1 模型初始化2.2 模型更新算法流程2.2.1 检测结果划分,划分为高分和较低分段2.2.2 高分段处理手段2.2.3 最优匹配与未匹配划分2.2.4 低分框再匹配2.2.5 未确认轨迹处理2.2.6 更新状态 2.3 匈牙利匹…...

C语言编译的过程
文章目录 1. 预处理(Preprocessing)2. 编译(Compilation)3. 汇编(Assembly)4. 链接(Linking)总结 c语言通过编译器直接编译成机器语言程序。 C语言程序的编译过程通常分为四个主要步…...

前端面试题——栈与队列、动态路由、链表
栈、队列与链表 Java数据结构栏目总结-CSDN博客 栈(Stack) 栈是一种后进先出(LIFO, Last In First Out)的数据结构。它只允许在栈顶进行添加(push)或删除(pop)元素的操作。 基本操…...
)
Java算法之计数排序(Counting Sort)
简介 计数排序是一种线性时间复杂度的排序算法,它不依赖于元素之间的比较,而是通过统计数组中每个元素出现的次数,然后根据这些统计信息对元素进行排序。这种算法特别适用于整数且整数的范围不是非常大时。 算法步骤 找出数组中的最大值。…...

【系统架构设计师-2012年】综合知识-答案及详解
更多内容请见: 备考系统架构设计师-核心总结索引 文章目录 【第1~2题】【第3~4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10~11题】【第12~13题】【第14~19题】【第20~21题】【第22~24题】【第25~26题】【第27~31题】【第32~33题】【第34~36题】【第37…...

webpack4手动搭建Vue项目
小满视频 很多解释使用通义灵码搜的,通义灵码的搜索结果也是有错误的全程使用pnpm包管理工具,和npm的用法基本一样 学习总结 1. 多看看webpack官网 2. webpack的作用:配置一堆东西,达到运行程序的目的 3. 无论什么东西都转成js,…...
)
Python爬虫所需的技术及其原理(简单易懂)
导言 随着互联网的发展,大量的数据被存储在网络上,而我们需要从中获取有用的信息。Python作为一种功能强大且易于学习的编程语言,被广泛用于网络爬虫的开发。本文将详细介绍Python爬虫所需的技术及其原理,并提供相关的代码案例。…...

FxFactory 8 for Mac 视觉特效插件包安装
Mac分享吧 文章目录 介绍页面效果一、下载软件二、开始安装1、Install安装2、显示软件页面,表示安装成功3、补丁安装 三、注意事项1、若已安装过其他版本,需要使用软件自带的卸载功能进行软件卸载,再安装此版本 安装完成!&#x…...

将语义分割的标签转换为实例分割(yolo)的标签
语义分割的标签(目标处为255,其余处为0) 实例分割的标签(yolo.txt),描述边界的多边形顶点的归一化位置 绘制在原图类似蓝色的边框所示。 废话不多说,直接贴代码; import os import cv2 imp…...

QT 遍历ini配置文件
在 Qt 中,处理 INI 配置文件是一项常见任务,通常使用 QSettings 类来读取和写入这些文件。QSettings 提供了一种方便的方式来操作 INI 文件中的配置数据。下面是如何使用 QSettings 遍历和处理 INI 配置文件的示例。 示例代码 假设有一个名为 config.i…...

ecmascript和javascript的区别详细讲解
大家好,我是程序员小羊! 前言: ECMAScript 和 JavaScript是紧密相关的术语,但它们有着各自明确的定义和用途。要理解它们的区别,首先需要从它们的起源、发展历史、技术架构以及具体应用领域来分析。以下是对它们的详…...

【Python报错已解决】“ModuleNotFoundError: No module named ‘timm‘”
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 文章目录 引言:一、问题描述1.1 报错示例:当我们尝试导入timm库时,可能会看到以下错误信息。…...
)
「图::存储」链式邻接表|链式前向星(C++)
前置知识 上一节我们介绍了三种基本的存图结构: 「图」邻接矩阵|边集数组|邻接表(C) 概述 他们各有优劣,为了综合他们的性能, 这一节我们来介绍两种以这三种结构为基础实现的高级存储结构:链式邻接表|…...
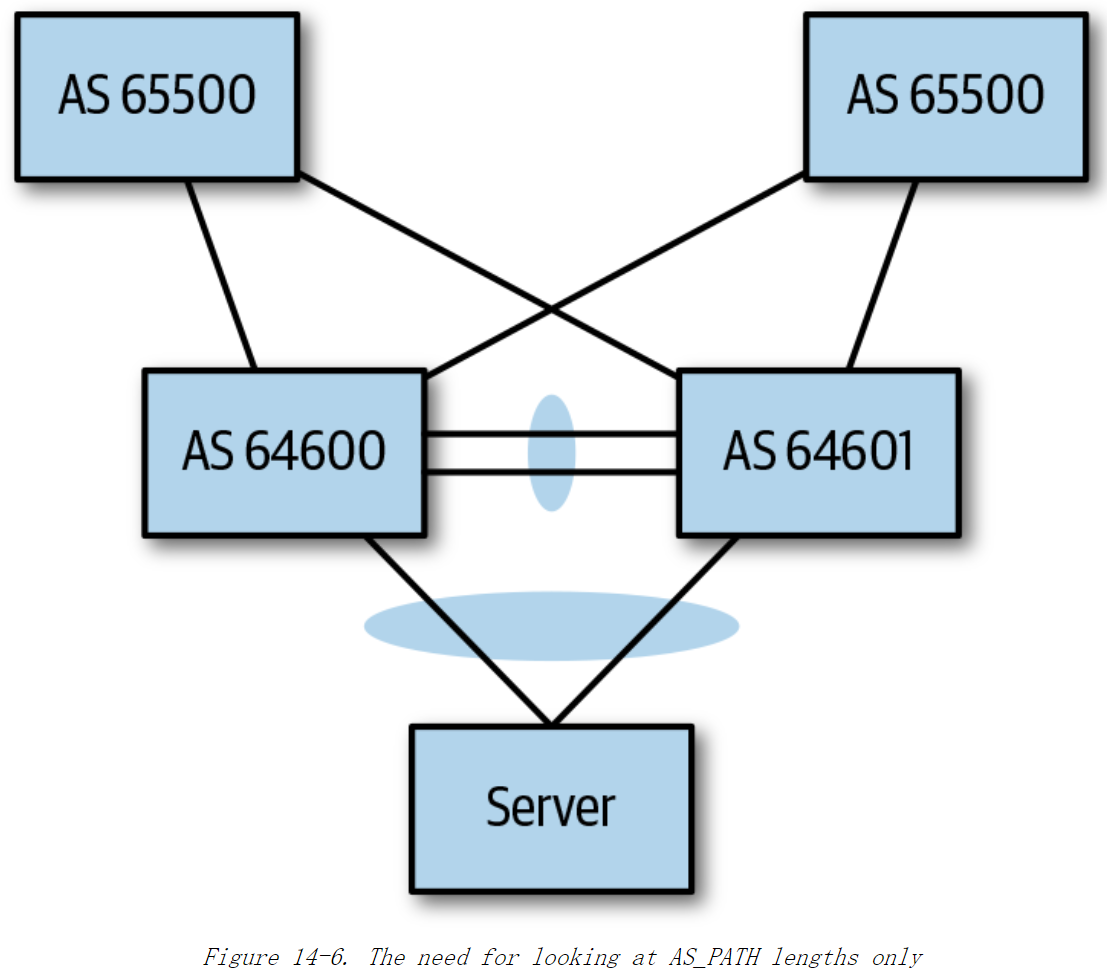
《Cloud Native Data Center Networking》(云原生数据中心网络设计)读书笔记 -- 10数据中心中的BGP
本章解答以下问题: ASN,团体(community),属性(attribute),最佳路径这些BGP术语是什么疑似?在数据中心中应该使用eBGP还是iBGP?在数据中心使用BGP时,应采用什…...

unity游戏开发——标记物体 一目了然
Unity游戏开发:标记物体,让开发变得一目了然 “好读书,不求甚解;每有会意,便欣然忘食。” 本文目录: Unity游戏开发 Unity游戏开发:标记物体,让开发变得一目了然前言1. 什么是Tag?2. Unity中如何添加和管理Tag步骤1&am…...

vue 项目打包图片没有打包进去问题解决
解决方法1.在导入图片的文件中通过 import 引入图片 这种方法只适合图片少的情况 <template> <img :srctestImg/> </template> <script> import testImg from /assets/img/testImg.png </script>2.封装公共方法,通过 new URL() 的方式…...

TCP的传输速度
如何确定TCP最大传输速度? TCP 的传输速度,受限于发送窗⼝,接收窗⼝以及⽹络设备传输能⼒。 其中,窗⼝⼤⼩由内核缓冲区⼤⼩决定。如果缓冲区与⽹络传输能⼒匹配,那么缓冲区的利⽤率就达到了最⼤化。 如何计算网络传…...
直播间的“骆驼”比沙漠还多?刀郎演唱会惊现“骆驼”
“送战友,踏征程,默默无语两行泪,耳边响起驼铃声……”8月30日,刀郎知交线上演唱会在微信视频号直播。一曲《驼铃》,勾起了无数人的回忆,离别的伤感、人性的关怀与温暖,通过悠然的旋律流入千万听…...

Android Studio gradle下载太慢了!怎么办?(已解决)
Android Studio!你到底干了什么?! 不能高速下载gradle,我等如何进行app编程?! 很简单,我修改gradle地址不就是了。 找到gradle-wrapper.properties文件 修改其中distributionUrl的地址。 将 ht…...
安卓版Infuse来了 打造自己的影视墙
如何让安卓设备上的视频播放更高效?AfuseKt 或许能给出答案 AfuseKt 是一款功能强大的安卓网络视频播放器,专为满足用户对多样化媒体播放需求而设计。它不仅支持多种流行的在线存储和媒体管理平台,如阿里云盘、Alist、WebDAV 和 Emby 等&…...

Salt Player:Android本地音乐播放器的专业选择与深度体验
Salt Player:Android本地音乐播放器的专业选择与深度体验 【免费下载链接】SaltPlayerSource Salt Player (A local music player trusted and chosen by hundreds of thousands of users) for Android Release, Feedback. 项目地址: https://gitcode.com/GitHub_…...
)
Arduino实战:如何用旋转编码器控制你的项目(附方向判断代码)
Arduino实战:旋转编码器方向判断与项目集成指南 引言 在创客和电子爱好者的世界里,旋转编码器就像是一个神奇的"旋钮",它能把你的物理转动动作转化为数字信号。想象一下,通过简单的旋转就能精确控制音量大小、菜单选择…...

5个必装开源应用:彻底改变你的macOS工作流
5个必装开源应用:彻底改变你的macOS工作流 【免费下载链接】open-source-mac-os-apps 🚀 Awesome list of open source applications for macOS. https://t.me/s/opensourcemacosapps 项目地址: https://gitcode.com/gh_mirrors/op/open-source-mac-os…...

5分钟打造专属AI声优:RVC语音变声完整指南
5分钟打造专属AI声优:RVC语音变声完整指南 【免费下载链接】Retrieval-based-Voice-Conversion-WebUI Easily train a good VC model with voice data < 10 mins! 项目地址: https://gitcode.com/GitHub_Trending/re/Retrieval-based-Voice-Conversion-WebUI …...

Anything V5图像生成服务实测:512x512分辨率下的惊艳效果展示
Anything V5图像生成服务实测:512x512分辨率下的惊艳效果展示 1. 开篇:认识Anything V5 Anything V5是基于Stable Diffusion技术构建的专用图像生成模型,专注于提供高质量的动漫风格图像生成能力。作为"万象熔炉"系列的最新版本&…...

2026最新!3款亲测搞定音频怎么转换成文字的免费神器,实用必备不踩坑!
很多朋友找音频转文字工具,第一个坑就是只盯着“免费”两个字,要么是限额度转不全,要么是错漏百出改到秃头,算下来时间成本贵到离谱。作为蹲了大半年工具的测评博主,我亲测了3款目前能用的高性价比工具,直接…...
ClearerVoice-Studio在客服系统中的实战应用:语音质检与分析
ClearerVoice-Studio在客服系统中的实战应用:语音质检与分析 1. 引言 你有没有遇到过这样的情况:客服中心的通话录音总是夹杂着键盘敲击声、背景交谈声,甚至还有空调的嗡嗡声?想要从中提取关键信息做质量分析,却发现…...

文墨共鸣:如何用AI理解文字“意思”而不仅仅是“文字”?
文墨共鸣:如何用AI理解文字“意思”而不仅仅是“文字”? 你有没有遇到过这样的情况?两段文字,用词完全不同,但说的却是同一个意思。或者反过来,字面看起来差不多,但想表达的核心观点天差地别。…...

ncmdump终极指南:简单三步实现NCM音乐格式快速转换
ncmdump终极指南:简单三步实现NCM音乐格式快速转换 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密文件无法在其他设备播放而烦恼吗?ncmdump工具让你轻松突破格式限制ÿ…...

OpenClaw对话式开发:Qwen3-32B镜像生成Python脚本实例
OpenClaw对话式开发:Qwen3-32B镜像生成Python脚本实例 1. 为什么选择对话式开发 作为一名长期与Python打交道的开发者,我一直在寻找更高效的编码方式。传统IDE虽然功能强大,但面对重复性脚本编写时,仍然需要大量手动操作。直到尝…...