Python爬虫所需的技术及其原理(简单易懂)
导言
随着互联网的发展,大量的数据被存储在网络上,而我们需要从中获取有用的信息。Python作为一种功能强大且易于学习的编程语言,被广泛用于网络爬虫的开发。本文将详细介绍Python爬虫所需的技术及其原理,并提供相关的代码案例。
1. HTTP请求与响应
当然,我可以用Python的requests库来演示HTTP请求与响应的详细过程。requests库是Python中用于发送HTTP请求的第三方库,它简化了HTTP请求的发送和响应的接收过程。
首先,确保你已经安装了requests库。如果还没有安装,可以通过pip安装:
pip install requests
接下来,我将演示如何使用requests库发送一个GET请求到某个网站(例如https://httpbin.org/,这是一个用于HTTP请求的测试和模拟的网站),并接收并打印出响应的状态码、响应头和响应体。
Python代码示例
import requests# 目标URL
url = 'https://httpbin.org/get'# 发送GET请求
response = requests.get(url)# 打印响应的状态码
print(f'Status Code: {response.status_code}')# 打印响应头
print('Response Headers:')
for header, value in response.headers.items():print(f'{header}: {value}')# 打印响应体(以文本形式)
print('\nResponse Body:')
print(response.text)# 如果你知道响应是JSON格式的,也可以直接使用.json()方法将其解析为Python字典
# 注意:这里httpbin.org/get返回的是一个简单的HTML页面,所以这里只是演示
# 正常情况下,如果URL是返回JSON的(如httpbin.org/ip),你可以这样做:
# data = response.json()
# print(data)
代码解析
-
导入requests库:首先,你需要导入
requests库,以便使用它提供的函数来发送HTTP请求。 -
定义URL:然后,你需要定义你想要发送请求的URL。在这个例子中,我们使用
https://httpbin.org/get,这是一个会返回你发送给它的GET请求信息的网站。 -
发送GET请求:使用
requests.get(url)发送GET请求到指定的URL,并将返回的响应对象存储在response变量中。 -
打印响应的状态码:通过
response.status_code获取响应的状态码,并打印出来。状态码是一个整数,用于表示请求的结果,如200表示成功,404表示未找到资源等。 -
打印响应头:通过遍历
response.headers.items()来打印响应头。响应头是一个包含多个键值对的字典,每个键值对代表了一个响应头字段和它的值。 -
打印响应体:通过
response.text获取响应体的文本内容,并打印出来。如果响应体是JSON格式的,你可以使用response.json()方法将其解析为Python字典。但是,请注意,在这个例子中,https://httpbin.org/get返回的实际上是一个HTML页面,所以我们只是简单地打印了文本内容。
2. 网页解析技术
爬虫的网页解析技术主要涉及到从HTTP响应中提取并解析出所需数据的过程。这些技术通常依赖于一些库或框架来简化HTML、XML或JSON等格式的解析工作。在Python中,常用的网页解析库有BeautifulSoup、lxml、re(正则表达式)以及pandas(对于表格数据)等。下面,我将以BeautifulSoup为例,结合代码来详细讲解网页解析技术。
1. 安装BeautifulSoup和lxml
首先,你需要安装beautifulsoup4和lxml(作为解析器)库。你可以通过pip来安装它们:
pip install beautifulsoup4 lxml
2. 使用BeautifulSoup解析网页
假设我们有一个HTML字符串或者已经从网页中获取了HTML内容,我们将使用BeautifulSoup来解析它并提取数据。
示例HTML内容
<html>
<head><title>示例页面</title>
</head>
<body><h1>欢迎来到我的网站</h1><p class="content">这是网页的主要内容部分。</p><ul id="links"><li><a href="http://example.com/link1">链接1</a></li><li><a href="http://example.com/link2">链接2</a></li></ul>
</body>
</html>
Python代码示例
from bs4 import BeautifulSoup# 假设html_content是从网页获取的HTML内容,这里我们直接用一个字符串代替
html_content = """
<html>
<head><title>示例页面</title>
</head>
<body><h1>欢迎来到我的网站</h1><p class="content">这是网页的主要内容部分。</p><ul id="links"><li><a href="http://example.com/link1">链接1</a></li><li><a href="http://example.com/link2">链接2</a></li></ul>
</body>
</html>
"""# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(html_content, 'lxml') # 使用lxml作为解析器# 提取标题
title = soup.title.text
print(f"标题: {title}")# 提取特定类名的段落内容
paragraph = soup.find('p', class_='content').text
print(f"内容: {paragraph}")# 提取所有链接的href属性
links = [a['href'] for a in soup.find_all('a', href=True)]
print(f"链接: {links}")# 提取具有特定ID的<ul>标签中的所有<li>标签的文本
list_items = [li.text for li in soup.find('ul', id='links').find_all('li')]
print(f"列表项: {list_items}")
代码讲解
- 创建BeautifulSoup对象:首先,我们使用
BeautifulSoup类创建一个对象,将HTML内容作为第一个参数传入,并指定解析器(这里使用的是lxml)。 - 提取标题:通过
.title.text可以直接获取<title>标签内的文本。 - 提取特定类名的段落内容:使用
.find()方法,并指定标签名和类名(class_作为参数名,因为class是Python的保留字),然后获取.text属性。 - 提取链接:使用
.find_all()方法查找所有<a>标签,并通过列表推导式获取每个<a>标签的href属性。 - 提取具有特定ID的列表项:首先使用
.find()方法找到具有特定ID的<ul>标签,然后在其内部使用.find_all()方法查找所有<li>标签,并获取它们的文本内容。
以上就是通过BeautifulSoup进行网页解析的一个基本示例和代码讲解。你可以根据实际需要调整HTML内容和解析逻辑。
3. 爬虫框架
在实际的爬虫开发中,我们通常会使用一些爬虫框架,它们提供了更高级别的抽象和更方便的功能。以下是一些常用的Python爬虫框架。
3.1 Scrapy
Scrapy是一个快速、可扩展且高级别的Web爬取框架。它提供了强大的抓取功能和数据处理能力,使爬虫开发更加高效。下面是一个使用Scrapy爬取网页的示例代码:
import scrapy class MySpider(scrapy.Spider): name = 'example.com' start\_urls = \['http://www.example.com'\] def parse(self, response): \# 处理响应 \# 提取数据 \# 发送更多请求 pass3.2 BeautifulSoup + requests
BeautifulSoup和requests的组合是另一种常用的爬虫开发方式。使用BeautifulSoup解析网页,使用requests发送HTTP请求。
下面是一个使用BeautifulSoup和requests爬取网页的示例代码:
import requests
from bs4 import BeautifulSoup url = 'http://www.example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
\# 处理页面,提取数据3.3 Selenium
Selenium是一种自动化浏览器工具,可以模拟浏览器行为。它通常与浏览器驱动一起使用,如ChromeDriver。使用Selenium可以解决一些JavaScript渲染的网页爬取问题。
下面是一个使用Selenium模拟浏览器爬取网页的示例代码(需要使用selenium库):
from selenium import webdriver driver = webdriver.Chrome('path/to/chromedriver')
driver.get('http://www.example.com')
\# 处理页面,提取数据
driver.quit()4. 其他
除了了解基本的爬虫工作原理,还需要掌握一些相关的技术,以便更好地应对各种复杂情况。下面是几个常用的技术要点:
4.1 User-Agent伪装
为了防止网站屏蔽爬虫,我们可以在发送HTTP请求时设置User-Agent头部,将其伪装成浏览器的请求。这样可以减少被服务器识别为爬虫的概率。
Python requests库可以通过设置headers参数来添加自定义的HTTP头部。
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers\=headers)4.2 反爬虫策略与解决方法
为了防止被爬虫抓取数据,网站可能会采取一些反爬虫策略,如限制请求频率、设置验证码、使用动态加载等。对于这些情况,我们可以采取以下解决方法:
-
限制请求频率:可以通过设置合适的时间间隔来控制请求的频率,避免过快访问网站。
-
验证码识别:可以使用第三方的验证码识别库(如Tesseract-OCR)来自动识别并输入验证码。
-
动态加载页面:对于使用JavaScript动态加载的页面,可以使用Selenium库模拟浏览器行为进行处理。
4.3 网页登录与Session管理
有些网站需要登录后才能获取到所需的数据。在这种情况下,我们可以通过模拟登录行为,发送POST请求并记录登录后的Session信息,以便后续的数据访问。
下面是一个使用requests库模拟登录的示例代码:
import requests login\_url = 'https://example.com/login'
data = { 'username': 'your\_username', 'password': 'your\_password'
}
response = requests.post(login\_url, data\=data)
session = response.cookies data\_url = 'https://example.com/data'
response = requests.get(data\_url, cookies\=session)
data = response.text在这个示例中,我们首先发送POST请求模拟登录,将用户名和密码作为表单数据data发送给登录页面login_url,并保存返回的Session信息。
然后我们可以使用requests.get()方法发送GET请求,同时将保存的Session信息作为cookies参数传入,以便获取登录后的数据。
5. 实例:爬取简书网站文章信息
为了更好地演示Python爬虫的技术和原理,我们选取了简书网站作为示例。我们将爬取简书网站中的热门文章列表,提取出每篇文章的标题、作者和链接。
以下是完整的实现代码:
import requests
from bs4 import BeautifulSoup \# 发送HTTP请求
url = 'https://www.jianshu.com'
response = requests.get(url)
html = response.text \# 解析HTML内容
soup = BeautifulSoup(html, 'html.parser') \# 提取数据
articles = soup.select('.note-list li') data = \[\]
for article in articles: title = article.select('a.title')\[0\].string.strip() author = article.select('.name')\[0\].string.strip() href = 'https://www.jianshu.com' + article.select('a.title')\[0\]\['href'\] data.append(\[title, author, href\]) \# 数据存储
import csv
with open('jianshu\_articles.csv', 'w', newline\='', encoding\="utf-8") as file: writer = csv.writer(file) writer.writerows(data)在这个示例中,我们首先发送GET请求获取简书网站的HTML内容,然后使用BeautifulSoup库进行解析。
接着,我们使用CSS选择器字符串.note-list li选取所有文章的外层容器,并使用CSS选择器和字典键值对的方式提取文章的标题、作者和链接。
最后,我们采用CSV格式将提取的数据保存到了名为jianshu_articles.csv的文件中。
结语
本文详细介绍了Python爬虫所需的技术及其原理,包括HTTP请求与响应、网页解析技术和爬虫框架。通过掌握这些技术,我们可以有效地开发出强大且高效的Python爬虫。希望本文能对你理解和掌握Python爬虫有所帮助。
请注意,在进行网络爬虫时,需要遵守网站的使用条款,并遵守相关法律法规。同时,合理使用爬虫技术,不对网络资源进行滥用和破坏。
相关文章:
)
Python爬虫所需的技术及其原理(简单易懂)
导言 随着互联网的发展,大量的数据被存储在网络上,而我们需要从中获取有用的信息。Python作为一种功能强大且易于学习的编程语言,被广泛用于网络爬虫的开发。本文将详细介绍Python爬虫所需的技术及其原理,并提供相关的代码案例。…...

FxFactory 8 for Mac 视觉特效插件包安装
Mac分享吧 文章目录 介绍页面效果一、下载软件二、开始安装1、Install安装2、显示软件页面,表示安装成功3、补丁安装 三、注意事项1、若已安装过其他版本,需要使用软件自带的卸载功能进行软件卸载,再安装此版本 安装完成!&#x…...

将语义分割的标签转换为实例分割(yolo)的标签
语义分割的标签(目标处为255,其余处为0) 实例分割的标签(yolo.txt),描述边界的多边形顶点的归一化位置 绘制在原图类似蓝色的边框所示。 废话不多说,直接贴代码; import os import cv2 imp…...

QT 遍历ini配置文件
在 Qt 中,处理 INI 配置文件是一项常见任务,通常使用 QSettings 类来读取和写入这些文件。QSettings 提供了一种方便的方式来操作 INI 文件中的配置数据。下面是如何使用 QSettings 遍历和处理 INI 配置文件的示例。 示例代码 假设有一个名为 config.i…...

ecmascript和javascript的区别详细讲解
大家好,我是程序员小羊! 前言: ECMAScript 和 JavaScript是紧密相关的术语,但它们有着各自明确的定义和用途。要理解它们的区别,首先需要从它们的起源、发展历史、技术架构以及具体应用领域来分析。以下是对它们的详…...

【Python报错已解决】“ModuleNotFoundError: No module named ‘timm‘”
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 文章目录 引言:一、问题描述1.1 报错示例:当我们尝试导入timm库时,可能会看到以下错误信息。…...
)
「图::存储」链式邻接表|链式前向星(C++)
前置知识 上一节我们介绍了三种基本的存图结构: 「图」邻接矩阵|边集数组|邻接表(C) 概述 他们各有优劣,为了综合他们的性能, 这一节我们来介绍两种以这三种结构为基础实现的高级存储结构:链式邻接表|…...
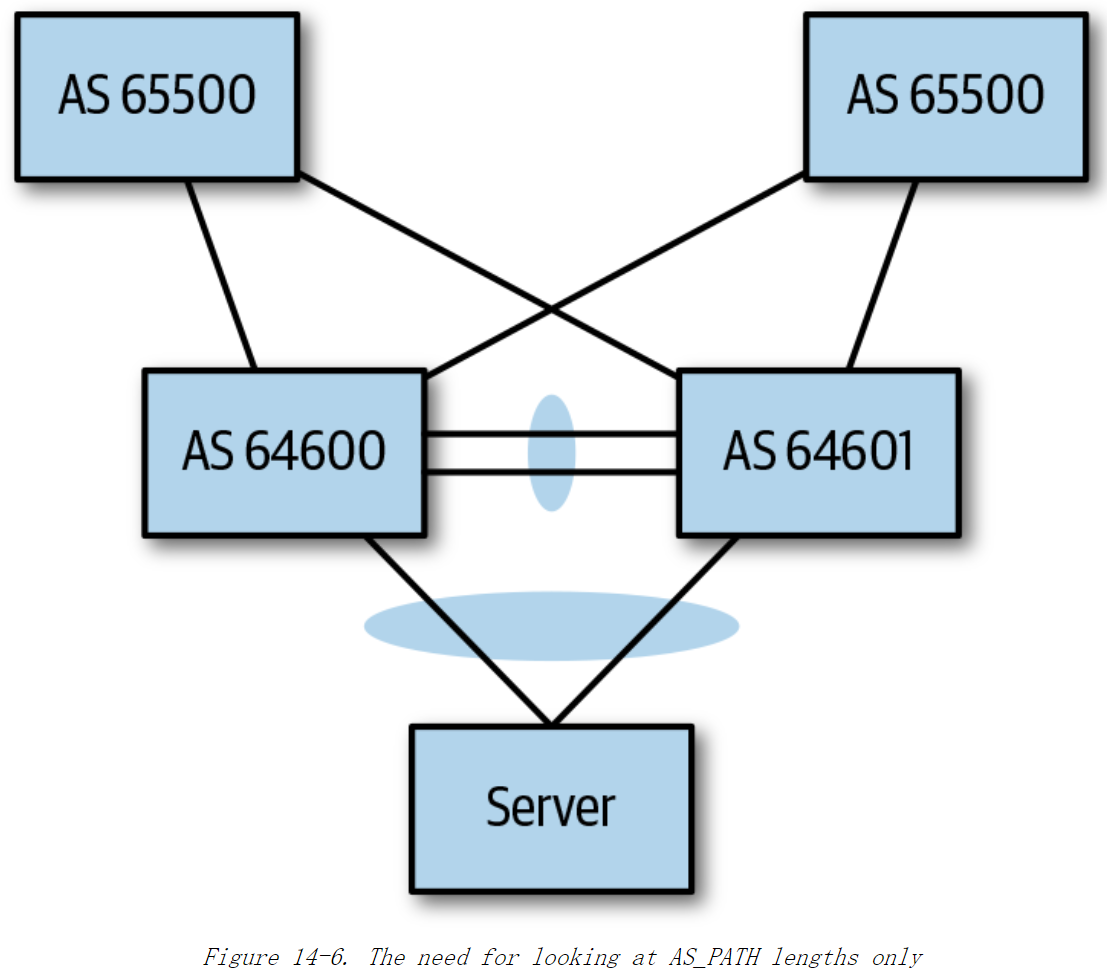
《Cloud Native Data Center Networking》(云原生数据中心网络设计)读书笔记 -- 10数据中心中的BGP
本章解答以下问题: ASN,团体(community),属性(attribute),最佳路径这些BGP术语是什么疑似?在数据中心中应该使用eBGP还是iBGP?在数据中心使用BGP时,应采用什…...

unity游戏开发——标记物体 一目了然
Unity游戏开发:标记物体,让开发变得一目了然 “好读书,不求甚解;每有会意,便欣然忘食。” 本文目录: Unity游戏开发 Unity游戏开发:标记物体,让开发变得一目了然前言1. 什么是Tag?2. Unity中如何添加和管理Tag步骤1&am…...

vue 项目打包图片没有打包进去问题解决
解决方法1.在导入图片的文件中通过 import 引入图片 这种方法只适合图片少的情况 <template> <img :srctestImg/> </template> <script> import testImg from /assets/img/testImg.png </script>2.封装公共方法,通过 new URL() 的方式…...

TCP的传输速度
如何确定TCP最大传输速度? TCP 的传输速度,受限于发送窗⼝,接收窗⼝以及⽹络设备传输能⼒。 其中,窗⼝⼤⼩由内核缓冲区⼤⼩决定。如果缓冲区与⽹络传输能⼒匹配,那么缓冲区的利⽤率就达到了最⼤化。 如何计算网络传…...
直播间的“骆驼”比沙漠还多?刀郎演唱会惊现“骆驼”
“送战友,踏征程,默默无语两行泪,耳边响起驼铃声……”8月30日,刀郎知交线上演唱会在微信视频号直播。一曲《驼铃》,勾起了无数人的回忆,离别的伤感、人性的关怀与温暖,通过悠然的旋律流入千万听…...

Android Studio gradle下载太慢了!怎么办?(已解决)
Android Studio!你到底干了什么?! 不能高速下载gradle,我等如何进行app编程?! 很简单,我修改gradle地址不就是了。 找到gradle-wrapper.properties文件 修改其中distributionUrl的地址。 将 ht…...
安卓版Infuse来了 打造自己的影视墙
如何让安卓设备上的视频播放更高效?AfuseKt 或许能给出答案 AfuseKt 是一款功能强大的安卓网络视频播放器,专为满足用户对多样化媒体播放需求而设计。它不仅支持多种流行的在线存储和媒体管理平台,如阿里云盘、Alist、WebDAV 和 Emby 等&…...
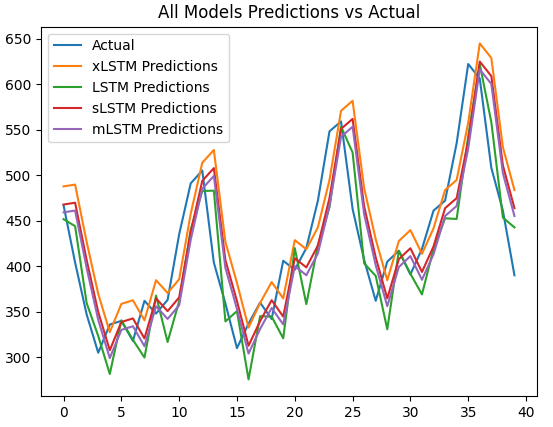
【Python时序预测系列】高创新模型:基于xlstm模型实现单变量时间序列预测(案例+源码)
这是我的第351篇原创文章。 一、引言 LSTM在1990年代被提出,用以解决循环神经网络(RNN)的梯度消失问题。LSTM在多种领域取得了成功,但随着Transformer技术的出现,其地位受到了挑战。如果将LSTM扩展到数十亿参数&#…...

Ubuntu 22.04 系统中 ROS2安装
Ubuntu 22.04 系统中 ROS2安装 ROS2安装 # 多窗口终端工具 sudo apt update sudo apt install tilix打开软件,点击右上角图标进入设置 -> General -> size120, columns:48Command -> 勾选第一个 Run command as login shellColor -> Theme Color 选择…...

Vue内置指令v-once、v-memo和v-pre提升性能?
前言 Vue的内置指令估计大家都用过不少,例如v-for、v-if之类的就是最常用的内置指令,但今天给大家介绍几个平时用的比较少的内置指令。毕竟这几个Vue内置指令可用可不用,不用的时候系统正常跑,但在对的地方用了却能提升系统性能&…...

OpenHarmony轻松玩转GIF数据渲染
OpenAtom OpenHarmony(以下简称“OpenHarmony”)提供了Image组件支持GIF动图的播放,但是缺乏扩展能力,不支持播放控制等。今天介绍一款三方库——ohos-gif-drawable三方组件,带大家一起玩转GIF的数据渲染,搞…...

torch.clip函数介绍
PyTorch 中,torch.clip函数用于对张量中的元素进行裁剪,将其值限制在指定的范围内。 一、函数语法及参数解释 torch.clip(input, min=None, max=None, out=None) input:输入张量,即要进行裁剪的张量。min(可选):裁剪的下限。如果未指定,则不进行下限裁剪。max(可选)…...

西北工业大学oj题-兔子生崽
题目描述: 兔子生崽问题。假设一对小兔的成熟期是一个月,即一个月可长成成兔,每对成兔每个月可以生一对小兔,一对新生的小兔从第二个月起就开始生兔子,试问从一对兔子开始繁殖,一年以后可有多少对兔子&…...

造相Z-Image模型v2提示词工程进阶:结构化Prompt构建方法
造相Z-Image模型v2提示词工程进阶:结构化Prompt构建方法 用对方法,让AI真正听懂你的创意 不知道你有没有这样的经历:脑子里有个特别棒的画面,但用Z-Image生成出来的结果总是差那么点意思。要么细节不对,要么风格跑偏&a…...

如何高效使用网盘直链下载工具:告别限速的全能解决方案
如何高效使用网盘直链下载工具:告别限速的全能解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

Phi-3-mini-128k-instruct代码生成效果展示:自动补全Python与JavaScript函数
Phi-3-mini-128k-instruct代码生成效果展示:自动补全Python与JavaScript函数 最近在尝试各种代码生成模型,想找一个既轻量又聪明的编程助手。试了一圈,微软开源的Phi-3-mini-128k-instruct让我有点惊喜。它模型不大,但在理解编程…...

【零基础入门】本地LLM聊天机器人保姆级教程|Windows+Mac通用
本文适合:完全不懂Python、AI零基础小白,无需显卡、无需翻墙、无需付费,跟着步骤复制粘贴即可拥有自己的本地AI助手。 🍓 前言 最近本地大模型特别火,很多同学想入门,却被环境配置、模型部署、代码逻辑劝退…...

宝塔面板网站出现MySQL连接超时丢失怎么解决_合理增大max_allowed_packet和超时等待参数
MySQL连接超时丢失主因是max_allowed_packet过小或wait_timeout/interactive_timeout设置不当,需同步调大并重启MySQL验证生效。MySQL 连接超时丢失的典型表现页面报错 Lost connection to MySQL server during query 或 MySQL server has gone away,尤其…...
Gemma-3-12b-it开源大模型教程:Transformers + PIL + Gradio全栈整合
Gemma-3-12b-it开源大模型教程:Transformers PIL Gradio全栈整合 1. 项目概述 Gemma-3-12b-it是一个基于Google最新开源大模型的多模态交互工具,专为本地化部署设计。这个工具将强大的12B参数大模型与直观的用户界面相结合,让开发者能够轻…...

SUNFLOWER MATCH LAB硬件对接:基于STM32F103C8T6最小系统板的图像采集端设计
SUNFLOWER MATCH LAB硬件对接:基于STM32F103C8T6最小系统板的图像采集端设计 最近在做一个植物生长监测的项目,需要部署一批低成本的图像采集终端。核心需求很简单:定时给植物拍照,然后把照片传到云端服务器。听起来不难…...

开箱即用的AI视觉工具:万物识别镜像部署与简单调用演示
开箱即用的AI视觉工具:万物识别镜像部署与简单调用演示 1. 引言:让AI视觉识别触手可及 想象一下,你刚拿到一个功能强大的AI视觉识别工具,它能识别5万多种日常物品,而且直接用中文输出结果。但当你准备使用时…...

2026 安全生产精选:五款巡检软件实用清单,隐患排查与闭环管理轻松上手
安全生产是企业发展的核心防线,而巡检巡查则是守护这道防线的关键动作。无论是餐饮门店的消防安全检查、工厂车间的设备点检,还是建筑工地的隐患排查,传统的纸质记录和人工巡查方式正逐渐暴露出效率低、易造假、难追溯的问题。今天为大家整理…...
 一键部署教程)
技术实测|告别命令行!OpenClaw(小龙虾AI) 一键部署教程
前言 随着本地 AI 智能体快速普及,私有化部署、数据安全、低门槛落地已成为技术选型核心。OpenClaw 作为开源轻量化 AI 智能体,v2.6.1 版本在环境适配、服务稳定性、模型集成度上全面优化,无需编译、无需手动配置依赖,真正实现 W…...