深度学习——强化学习算法介绍
强化学习算法介绍

强化学习讨论的问题是一个智能体(agent) 怎么在一个复杂不确定的环境(environment)里面去极大化它能获得的奖励。
强化学习和监督学习
- 强化学习有这个试错探索(trial-and-error exploration),它需要通过探索环境来获取对环境的理解。强化学习 agent 会从环境里面获得延迟的奖励。
- 在强化学习的训练过程中,时间非常重要。因为你得到的数据都是有时间关联的(sequential data),而不是独立同分布的。在机器学习中,如果观测数据有非常强的关联,其实会使得这个训练非常不稳定。这也是为什么在监督学习中,我们希望数据尽量是独立同分布,这样就可以消除数据之间的相关性。
- Agent 的行为会影响它随后得到的数据,这一点是非常重要的。在我们训练 agent 的过程中,很多时候我们也是通过正在学习的这个 agent 去跟环境交互来得到数据。所以如果在训练过程中,这个 agent 的模型很快死掉了,那会使得我们采集到的数据是非常糟糕的,这样整个训练过程就失败了。所以在强化学习里面一个非常重要的问题就是怎么让这个 agent 的行为一直稳定地提升。
- 为什么我们关注强化学习,其中非常重要的一点就是强化学习得到的模型可以有超人类的表现。
监督学习获取的这些监督数据,其实是让人来标注的。比如说 ImageNet 的图片都是人类标注的。那么我们就可以确定这个算法的上限(upper bound)就是人类的表现,人类的这个标注结果决定了它永远不可能超越人类。但是对于强化学习,它在环境里面自己探索,有非常大的潜力,它可以获得超越人的能力的这个表现,比如谷歌 DeepMind 的 AlphaGo 这样一个强化学习的算法可以把人类最强的棋手都打败。
这里给大家举一些在现实生活中强化学习的例子。
在自然界中,羚羊其实也是在做一个强化学习,它刚刚出生的时候,可能都不知道怎么站立,然后它通过试错的一个尝试,三十分钟过后,它就可以跑到每小时 36 公里,很快地适应了这个环境。
你也可以把股票交易看成一个强化学习的问题,就怎么去买卖来使你的收益极大化。
玩雅达利游戏或者一些电脑游戏,也是一个强化学习的过程。


Reward
奖励是由环境给的一个标量的反馈信号(scalar feedback signal),这个信号显示了 agent 在某一步采取了某个策略的表现如何。
强化学习的目的就是为了最大化 agent 可以获得的奖励,agent 在这个环境里面存在的目的就是为了极大化它的期望的累积奖励(expected cumulative reward)。
不同的环境,奖励也是不同的。这里给大家举一些奖励的例子。
比如说一个下象棋的选手,他的目的其实就为了赢棋。奖励是说在最后棋局结束的时候,他知道会得到一个正奖励或者负奖励。
羚羊站立也是一个强化学习过程,它得到的奖励就是它是否可以最后跟它妈妈一块离开或者它被吃掉。
在股票管理里面,奖励定义由你的股票获取的收益跟损失决定。
在玩雅达利游戏的时候,奖励就是你有没有在增加游戏的分数,奖励本身的稀疏程度决定了这个游戏的难度。
Value Function
价值函数是末来奖励的一个预测,用来评估状态的好坏。 100 块钱,因为你可以把这 100 块钱存在银行里面,你就会有一些利息。所以我们就通过把这个折扣因子放到价值函数的定义里面,价值函数的定义其实是一个期望,如下式所示:
v π ( s ) ≐ E π [ G t ∣ S t = s ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s ] , for all s ∈ S \mathrm{v}_{\pi}(\mathrm{s}) \doteq \mathbb{E}_{\pi}\left[\mathrm{G}_{\mathrm{t}} \mid \mathrm{S}_{\mathrm{t}}=\mathrm{s}\right]=\mathbb{E}_{\pi}\left[\sum_{\mathrm{k}=0}^{\infty} \gamma^{\mathrm{k}} \mathrm{R}_{\mathrm{t}+\mathrm{k}+1} \mid \mathrm{S}_{\mathrm{t}}=\mathrm{s}\right] \text {, for all } \mathrm{s} \in \mathcal{S} vπ(s)≐Eπ[Gt∣St=s]=Eπ[k=0∑∞γkRt+k+1∣St=s], for all s∈S
这里有一个期望 E π \mathbb{E}_{\pi} Eπ ,这里有个小角标是 π \pi π 函数,这个 π \pi π 函数就是说在我们已知某一个策略函数的时候,到底可以得到多少的奖励。
我们还有一种价值函数: Q Q Q 函数。 Q Q Q 函数里面包含两个变量: 状态和动作,其定义如下式所示:
q π ( s , a ) ≐ E π [ G t ∣ S t = s , A t = a ] = E π [ ∑ k = 0 ∞ γ k k R t + k + 1 ∣ S t = s , A t = a ] \mathrm{q}_{\pi}(\mathrm{s}, \mathrm{a}) \doteq \mathbb{E}_{\pi}\left[\mathrm{G}_{\mathrm{t}} \mid \mathrm{S}_{\mathrm{t}}=\mathrm{s}, \mathrm{A}_{\mathrm{t}}=\mathrm{a}\right]=\mathbb{E}_{\pi}\left[\sum_{\mathrm{k}=0}^{\infty} \gamma^{\mathrm{k}^{\mathrm{k}}} \mathrm{R}_{\mathrm{t}+\mathrm{k}+1} \mid \mathrm{S}_{\mathrm{t}}=\mathrm{s}, \mathrm{A}_{\mathrm{t}}=\mathrm{a}\right] qπ(s,a)≐Eπ[Gt∣St=s,At=a]=Eπ[k=0∑∞γkkRt+k+1∣St=s,At=a]
末来可以获得多少的奖励,它的这个期望取决于你当前的状态和当前的行为。这个 Q Q Q 函数是强化学习算法里面要学习的一个函数。因为当我们得到这个 Q Q Q 函数后,进入某一种状态,它最优的行 为就可以通过这个 Q Q Q 函数来得到。
基于策略迭代和基于价值迭代的强化学习方法有什么区别?
-
基于策略迭代的强化学习方法,agent会制定一套动作策略(确定在给定状态下需要采取何种动作),并根据这个策略进行操作。强化学习算法直接对策略进行优化,使制定的策略能够获得最大的奖励;基于价值迭代的强化学习方法,agent不需要制定显式的策略,它维护一个价值表格或价值函数,并通过这个价值表格或价值函数来选取价值最大的动作。
-
基于价值迭代的方法只能应用在不连续的、离散的环境下(如围棋或某些游戏领域),对于行为集合规模庞大、动作连续的场景(如机器人控制领域),其很难学习到较好的结果(此时基于策略迭代的方法能够根据设定的策略来选择连续的动作);
基于价值迭代的强化学习算法有 Q-learning、 Sarsa 等,而基于策略迭代的强化学习算法有策略梯度算法等。 -
Actor-Critic 算法同时使用策略和价值评估来做出决策,其中,智能体会根据策略做出动作,而价值函数会对做出的动作给出价值,这样可以在原有的策略梯度算法的基础上加速学习过程,取得更好的效果。
有模型(model-based)学习和免模型(model-free)学习有什么区别?
-
针对是否需要对真实环境建模,强化学习可以分为有模型学习和免模型学习。
有模型学习是指根据环境中的经验,构建一个虚拟世界,同时在真实环境和虚拟世界中学习; -
免模型学习是指不对环境进行建模,直接与真实环境进行交互来学习到最优策略。总的来说,有模型学习相比于免模型学习仅仅多出一个步骤,即对真实环境进行建模。强化学习是一种机器学习范式,主要关注在一个智能体与环境的交互中,通过尝试和错误的方式来学习如何采取行动以获得最大的奖励。在强化学习中,智能体根据当前的状态选择动作,然后与环境交互,观察环境的反馈(奖励或惩罚),并调整其策略,以最大化长期累积奖励。强化学习通常涉及建立一个值函数或策略函数来指导智能体如何做出决策。
-
免模型学习通常属于数据驱动型方法,需要大量的采样来估计状态、动作及奖励函数,从而优化动作策略。免模型学习的泛化性要优于有模型学习,原因是有模型学习算需要对真实环境进行建模,并且虚拟世界与真实环境之间可能还有差异,这限制了有模型学习算法的泛化性。免模型学习是强化学习的一种方法,其特点是使用来自环境的无模型信息进行学习。在免模型学习中,智能体不需要明确地知道环境的转换动力学,即不需要了解状态转移和奖励函数。相反,智能体仅仅通过与环境的交互来学习如何在不同的状态下选择动作,以最大化奖励。免模型学习可以通过基于值函数的方法(如Q-learning)或基于策略的方法(如策略梯度方法)来实现。
因此,强化学习是一个更广泛的概念,而免模型学习是强化学习的一种具体方法。在强化学习中,可以使用模型学习或免模型学习的方法,具体选择取决于任务的特性和要求。
Q-learning
Q-learning是一种基于值函数的强化学习算法。在Q-learning中,我们考虑到环境和智能体之间的交互关系,智能体根据环境给出的奖励信号进行学习和决策。在Q-learning中,我们使用一个值函数Q(s, a),来估计在状态s下采取动作a所获得的累积回报。
Q-learning的目标是学习一个最优的策略,使得智能体在不同的状态下能够选择具有最大累积回报的动作。为了实现这个目标,Q-learning使用了贝尔曼方程来更新值函数估计值。具体来说,Q-learning的更新规则如下:
Q ( s , a ) = Q ( s , a ) + α ( r + γ m a x ( Q ( s ′ , a ′ ) ) − Q ( s , a ) ) Q(s, a) = Q(s, a) + α (r + γ max(Q(s', a')) - Q(s, a)) Q(s,a)=Q(s,a)+α(r+γmax(Q(s′,a′))−Q(s,a))
在每个时间步,智能体通过观察当前状态和采取的动作,接收到一个立即奖励 r r r,并观察到新的状态 s ′ s' s′。然后,根据贝尔曼方程,用这个奖励更新值函数的估计值。其中, α α α是学习率, γ γ γ是折扣因子,用来平衡当前奖励和未来奖励的重要性。
通过不断地与环境交互和更新值函数,Q-learning学习到每个状态下采取不同动作的最优估计值。最终,通过选择具有最大估计值的动作,智能体能够根据当前状态做出最优的决策。
因此,Q-learning是一种基于值函数的强化学习方法,通过对值函数的学习和更新来实现智能体的决策和行为优化。
相关文章:
深度学习——强化学习算法介绍
强化学习算法介绍 强化学习讨论的问题是一个智能体(agent) 怎么在一个复杂不确定的环境(environment)里面去极大化它能获得的奖励。 强化学习和监督学习 强化学习有这个试错探索(trial-and-error exploration),它需要通过探索环境来获取对环境的理解。强化学习 ag…...
轴承知识大全,详细介绍(附3D图纸免费下载)
轴承一般由内圈、外圈、滚动体和保持架组成。对于密封轴承,再加上润滑剂和密封圈(或防尘盖)。这就是轴承的全部组成。 根据轴承使用的工作状况来选用不同类型的轴承,才能更好的发挥轴承的功能,并延长轴承的使用寿命。我…...

【PyTorch】基础环境如何打开
前期安装可以基于这个视频,本文是为了给自己存档如何打开pycharm和jupyter notebookPyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili Pycharm 配置 新建项目的时候选择解释器pytorch-gpu即可。 Jupyte…...

QT教程:QTime和QTimer的使用场景
QTime类 QTime 是一个用来表示和操作时间的类,它处理一天中的具体时间(例如小时、分钟、秒、毫秒)。通常用于计算时间间隔、记录时间戳、获取当前时间等。 特点和功能 表示时间:QTime 用来表示一天中的某个具体时间(小…...

MySQL 迁移中 explicit_defaults_for_timestamp 参数影响
前言 最近在做数据迁移的时候,使用的是云平台自带的同步工具,在预检查阶段,当时报错 explicit_defaults_for_timestamp 参数在目标端为 off 建议修改 on,有什么风险呢?在此记录下。 测试对比 MySQL 默认情况下 expl…...

树状数组记录
树状数组(Fenwick Tree)是一种用于维护数组前缀和的数据结构,支持高效的单点更新和区间查询操作。它的查询和更新时间复杂度为 O ( log n ) O(\log n) O(logn),适用于需要频繁更新和查询的场景。 树状数组的基本操作 单点更…...
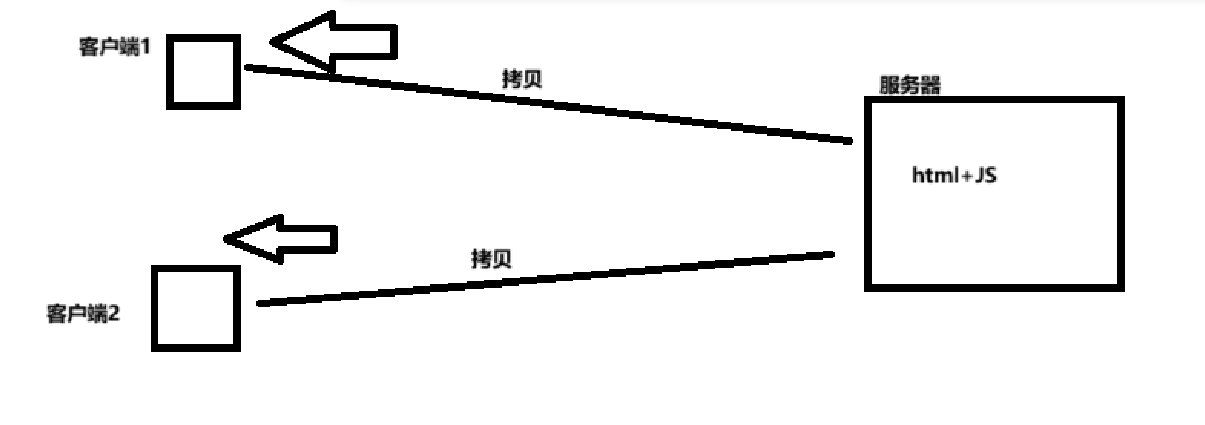
客户端时间和服务器时间的区别
客户端时间: 服务器向客户端拷贝一份前端内容,客户端通过JS获取时间,这样获取的是客户端时间 服务器时间: 服务器通过java代码获取的时间传输给客户端,这样获取的是服务器时间 当有些时候需要使用客户端时间…...

已入职华为!!关于我成功拿下华为大模型算法岗经验总结
方向:大模型算法工程师 整个面试持续了1小时10分钟,能够看出面试官是典型搞技术的,问的很专业又很细,全程感觉压力好大,面完后感觉丝丝凉意,不过幸好还是成功拿下了Offer 一面: 自我介绍 简历项目深度交流 1.项目的背…...

从安卓开发到AI产品经理——我的AI绘画之旅
大家好,我是一名有着多年安卓开发经验的程序员。在日复一日的编码生活中,我对AI行业产生了浓厚的兴趣。于是,我决定转行成为一名AI产品经理。在这个过程中,我通过学习AI绘画工具初步了解了AI行业,下面我将分享我的学习…...

代码随想录八股训练营第三十四天| C++
前言 一、vector和list的区别? 1.1.存储方式: 1.2.随机访问: 1.3.插入和删除操作: 1.4.内存使用: 1.5.容量和大小: 1.6.迭代器类型: 1.7.用途: 二、vector 底层原理和扩容过…...

《深入理解 Java 中的 this 关键字》
目录 一、this关键字的基本理解 二、this调用属性和方法 (一)一般情况 (二)特殊情况 三、this调用构造器 四、案例分析 (一)Account类 (二)Customer类 (三&…...

python文件自动分类(5)
完成了文件自动分类的操作后,我们一起来复习下: 首先,获取文件夹中所有文件名称,用 os.path.join() 函数拼接出要移动到的目标地址。然后,使用 os.path.exists() 函数判断目标文件夹是否存在,不存在用 os.m…...

【Unity-Lua】音乐播放器循环滚动播放音乐名
前言:Unity中UI节点 图1 如上所示,一开始本来是打算用ScrollView做的,觉得直接计算对应的文本位置就行,所以没用ScrollRect来做,可以忽略Scroll,Viewport这些名字。如下图:需要在一个背景Image…...

宏碁扩展Swift系列,推出四款全新AI笔记本电脑
Acer正在扩展其Swift笔记本产品线,推出四款新型号,每款都内置了AI功能。这些笔记本提供诸如Microsoft Copilot、Acer用户感应技术、Windows Studio效应、PurifiedVoice 2.0和PurifiedView等功能。其他功能还包括Wi-Fi 7和Bluetooth 5.4连接。 我们先来看…...

科研绘图系列:R语言差异基因四分图(Quad plot)
文章目录 介绍加载R包导入数据数据预处理画图参考介绍 四分图(Quad plot)是一种数据可视化技术,通常用于展示四个变量之间的关系。它由四个子图组成,每个子图都显示两个变量之间的关系。四分图的布局通常是2x2的网格,每个格子代表一个变量对的散点图。 在四分图中,通常…...

文字或图案点选坐标点返回
最近看到这篇文章中讲到极验图片验证码破解方案 https://blog.geetest.com/article/65aaaa944edc5ec343ba9f52efef0cdc 其中核心解决步骤如下,作者还贴心的贴出了CNN代码,真是用心良极: step 3:批量下载存储验证图片,…...

硬盘数据恢复软件TOP4榜单出炉,选对方法竟然如此重要
这年头,信息多得不得了,数据对我们来说太重要了。但是,不管是咱们自己还是公司,都可能碰上丢数据的倒霉事,特别是不小心把硬盘里的东西删了。数据一丢,不光可能亏钱,工作和生活也可能受影响。好…...

给自己复盘用的随想录笔记-栈与队列
用栈实现队列 难在出去 232. 用栈实现队列 - 力扣(LeetCode) class MyQueue {private Stack<Integer> A;private Stack<Integer> B;public MyQueue() {Anew Stack<>();Bnew Stack<>();}public void push(int x) {A.push(x);}pu…...

微信小程序跳转到另一个微信小程序
引用:http://www.xmdeal.com/mobanjiaocheng/254.html 第一种方法: wx.navigateToMiniProgram 官方文档:https://developers.weixin.qq.com/miniprogram/dev/api/navigate/wx.navigateToMiniProgram.html wx.navigateToMiniProgram({appId…...

【知识图谱】4、LLM大模型结合neo4j图数据库实现AI问答的功能
昨天写了一篇文章,使用fastapi直接操作neo4j图数据库插入数据的例子, 本文实现LLM大模型结合neo4j图数据库实现AI问答功能。 废话不多说,先上代码 import gradio as gr from fastapi import FastAPI, HTTPException, Request from pydantic…...

从‘炼丹’到‘产线’:手把手教你用AutoDockTools和Python脚本搭建可复现的批量分子对接流程
从‘炼丹’到‘产线’:手把手教你用AutoDockTools和Python脚本搭建可复现的批量分子对接流程 在药物发现和生物分子相互作用研究中,分子对接技术已成为虚拟筛选和先导化合物优化不可或缺的工具。然而,当面对数十甚至上百个小分子配体时&#…...

CANFD双ID过滤的妙用:用STM32实现车载ECU的故障诊断与正常通信分离
CANFD双ID过滤在车载ECU中的实战应用:诊断与通信的智能分离 在汽车电子系统中,ECU(电子控制单元)需要同时处理诊断请求和常规通信报文。传统做法往往需要复杂的软件过滤逻辑,不仅增加了CPU负担,还可能导致实…...

LangChain教程-、Langchain基础妨
简介 AI Agent 不仅仅是一个能聊天的机器人(如普通的 ChatGPT),而是一个能够感知环境、进行推理、自主决策并调用工具来完成特定任务的智能系统,更够完成更为复杂的AI场景需求。 AI Agent 功能 根据查阅的资料,agent的…...

ATCODER ABC C题解饺
这,是一个采用C精灵库编写的程序,它画了一幅漂亮的图形: 复制代码 #include "sprites.h" //包含C精灵库 Sprite turtle; //建立角色叫turtle void draw(int d){for(int i0;i<5;i)turtle.fd(d).left(72); } int main(){ …...

注册获取阿里云qwen大模型api key
1.进入阿里云官网,然后注册登录并完善个人信息https://cn.aliyun.com/2.搜索框搜索api key 或点击模型,最下边的api key-->创建...

ENVI/ArcGIS实操指南:五分钟搞懂高光谱分类里的端元提取与丰度反演
ENVI/ArcGIS实操指南:五分钟搞懂高光谱分类里的端元提取与丰度反演 当你第一次打开ENVI软件,面对一张包含数百个波段的高光谱影像时,是否感到无从下手?那些五彩斑斓的像素背后,隐藏着怎样的物质组成信息?本…...

STM32开发避坑指南:KEIL中__use_no_semihosting报错的终极解决方案
STM32开发避坑指南:KEIL中__use_no_semihosting报错的终极解决方案 在嵌入式开发领域,STM32凭借其出色的性能和丰富的外设资源,成为众多开发者的首选。然而,在使用KEIL MDK进行开发时,不少开发者都会遇到一个令人头疼的…...

动画测试与调试完全手册:animation-samples项目中的自动化测试实践
动画测试与调试完全手册:animation-samples项目中的自动化测试实践 【免费下载链接】animation-samples Multiple samples showing the best practices in animation on Android. 项目地址: https://gitcode.com/gh_mirrors/an/animation-samples animation-…...

BiliBiliCCSubtitle:智能解析引擎驱动的B站字幕处理效率革命
BiliBiliCCSubtitle:智能解析引擎驱动的B站字幕处理效率革命 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 在数字内容产业高速发展的今天࿰…...

避开RISC-V流水线的那些“坑”:一次搞懂Load-Use Hazard与数据前递的边界条件
RISC-V流水线设计的隐秘陷阱:深度解析Load-Use Hazard与数据前递的临界条件 当你在RISC-V处理器的仿真测试中反复检查数据前递逻辑,却发现某些lw指令序列仍然无法正确执行时,那种挫败感我深有体会。这不是简单的代码错误,而是处理…...