手撕HashMap源码
终于通过不屑努力,把源码中的重要部分全都看完了,每一行代码都看明白了,还写了注释
import java.lang.reflect.ParameterizedType;
import java.lang.reflect.Type;
import java.util.*;
import java.util.function.Consumer;
import java.util.function.Function;public class MyHashMap<K, V> extends AbstractMap<K, V> implements Map<K, V> {// 默认初始容量,必须是2的次幂static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;// 最大容量,不能超过这个值static final int MAXIMUM_CAPACITY = 1 << 30;// 默认负载因子static final float DEFAULT_LOAD_FACTOR = 0.75f;// 链表阈值,超过这个值,需要扩容static final int TREEIFY_THRESHOLD = 8;// 红黑树转换为链表的阈值static final int UNTREEIFY_THRESHOLD = 6;// 哈希表的大小至少超过该值才将链表转换为红黑树static final int MIN_TREEIFY_CAPACITY = 64;static class Node<K, V> implements Map.Entry<K, V> {// 哈希值final int hash;// 键final K key;// 值V value;// 下一个节点Node<K, V> next;Node(int hash, K key, V value, Node<K, V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}@Overridepublic K getKey() {return key;}@Overridepublic V getValue() {return value;}@Overridepublic V setValue(V value) {V oldValue = this.value;this.value = value;return oldValue;}@Overridepublic boolean equals(Object o) {// 判断是否是同一个对象if (this == o)return true;// 判断是否是Map.Entry类if (o instanceof Map.Entry) {// 将对象转换为Map.EntryMap.Entry<?, ?> e = (Map.Entry<?, ?>) o;if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) {return true;}}return false;}}static final int hash(Object key) {if (key == null)return 0;int hash = key.hashCode();hash = hash ^ (hash >>> 16);return hash;}static Class<?> comparableClassFor(Object x) {if (x instanceof Comparable) {Class<?> c;Type[] ts, as;Type t;ParameterizedType p;if ((c = x.getClass()) == String.class) // bypass checksreturn c;if ((ts = c.getGenericInterfaces()) != null) {for (int i = 0; i < ts.length; ++i) {if (((t = ts[i]) instanceof ParameterizedType) &&((p = (ParameterizedType) t).getRawType() ==Comparable.class) &&(as = p.getActualTypeArguments()) != null &&as.length == 1 && as[0] == c) // type arg is creturn c;}}}return null;}static int compareComparables(Class<?> kc, Object k, Object x) {return (x == null || x.getClass() != kc ? 0 :((Comparable) k).compareTo(x));}static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}@Overridepublic Set<Entry<K, V>> entrySet() {return null;}// 哈希表,第一次使用的时候才会加载,必要时会重新设置大小// 长度总是2的次幂transient Node<K, V>[] table;// 键值对集合transient Set<Entry<K, V>> entrySet;// 键值对数量transient int size;// modCounttransient int modCount;// 当键值对数量达到阈值时,会进行扩容,这个阈值 = 容量 * 加载因子int threshold;// 加载因子final float loadFactor;public MyHashMap(int initialCapacity, float loadFactor) {// 初始容量不能小于0if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);// 初始容量不能大于最大容量if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;// 加载因子不能小于 0// 加载因子不能为NaNif (loadFactor <= 0 || Float.isNaN(loadFactor)) {throw new IllegalArgumentException("Illegal load factor: " + loadFactor);}this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);}public MyHashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}public MyHashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}// 将传入的map中的键值对添加到哈希表中public MyHashMap(Map<? extends K, ? extends V> m) {this.loadFactor = DEFAULT_LOAD_FACTOR;putMapEntries(m, false);}final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {int s = m.size();if (s > 0) {// hash表还没有初始化if (table == null) {// 计算哈希表的大小float ft = ((float) s / loadFactor) + 1.0F;int t = MAXIMUM_CAPACITY;if (ft < (float) MAXIMUM_CAPACITY) {t = (int) ft;}if (t > threshold)threshold = tableSizeFor(t);} else if (s > threshold)resize();for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {K key = e.getKey();V value = e.getValue();putVal(hash(key), key, value, false, evict);}}}/*** 获取键值对数量** @return*/public int size() {return size;}public boolean isEmpty() {return size == 0;}public V get(Object key) {Node<K, V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;}final Node<K, V> getNode(int hash, Object key) {Node<K, V>[] tab;Node<K, V> first, e;int n;K k;// 经典三步走:// 1.看桶是否为null// 2.判断链表头和key是否相等// 3.遍历链表(如果是红黑树去遍历红黑树)if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;if ((e = first.next) != null) {if (first instanceof TreeNode)return ((TreeNode<K, V>) first).getTreeNode(hash, key);do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;}final Node<K, V>[] resize() {Node<K, V>[] oldTable = table;// 获取旧数组长度int oldCapacity = (oldTable == null) ? 0 : oldTable.length;// 获取旧数组扩容阈值int oldThreshold = threshold;int newCapacity = 0;int newThreshold = 0;// 1.如果旧数组长度>0,那就扩容if (oldCapacity > 0) {// 2.容量大于最大容量,则直接返回if (oldCapacity >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTable;} else {// 3.旧数组容量小于最大容量,则扩容。直接翻倍if (oldCapacity >= DEFAULT_INITIAL_CAPACITY &&(oldCapacity << 1) < MAXIMUM_CAPACITY) {newCapacity = oldCapacity << 1;newThreshold = oldThreshold << 1;}// 4.旧数组容量太大,无法翻倍}// 5.此时 oldCapacity == 0;} else if (oldThreshold > 0) {newCapacity = oldThreshold;} else {// oldCapacity == 0;// oldThreshold == 0// newCapacity = 16,newThreshold = 12newCapacity = DEFAULT_INITIAL_CAPACITY;newThreshold = (int) (DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}// newThreshold 说明没有更新阈值,自己计算新的阈值// 可能是由于情况4,情况5if (newThreshold == 0) {float ft = (float) newCapacity * loadFactor;newThreshold = (newCapacity < MAXIMUM_CAPACITY && ft < (float) MAXIMUM_CAPACITY ?(int) ft : Integer.MAX_VALUE);}threshold = newThreshold;Node<K, V>[] newTable = (Node<K, V>[]) new Node[newCapacity];table = newTable;if (oldTable != null) {for (int j = 0; j < oldCapacity; j++) {Node<K, V> e = oldTable[j];if (e == null)continue;oldTable[j] = null;if (e.next == null) {// 该捅只有一个元素,讲该元素赋值到新的捅中newTable[e.hash & (newCapacity - 1)] = e;} else if (e instanceof TreeNode) {((TreeNode<K, V>) e).split(this, newTable, j, oldCapacity);} else {// 原来桶上的链表,讲他们分成两个链表,放在新链表的两个桶上// 举个例子,oldCapacity = 16// 此时 j = 1// 假设,现在链表上有 1、17、33、49这些元素// 那么需要讲他们重新找到新桶,放在新桶的位置上// 那么只会有两种结果,一种是放在1桶上,一种是放在17桶上// 为啥源代码中会让e.hash & oldCap 是否等于0来分开链表// 我们看下这些元素的二进制// 1: 000001// 17:010001// 33:100001// 49:110001// 而16:010000// 所以说只要二进制中倒数五位是1,那就说明是放在17桶上.否则就是放在1桶上Node<K, V> loHead = null, loTail = null;Node<K, V> hiHead = null, hiTail = null;Node<K, V> next;do {next = e.next;if ((e.hash & oldCapacity) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;} else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTable[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTable[j + oldCapacity] = hiHead;}}}}return newTable;}public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K, V>[] tab;Node<K, V> p;int len, index;// 如果table为空或者长度为0,表示还没有初始化,需要初始化if ((tab = table) == null || (len = tab.length) == 0)len = (tab = resize()).length;// 计算keyhash后对应的捅索引,看是否为空if ((p = tab[index = (len - 1) & hash]) == null)tab[index] = newNode(hash, key, value, null);else {// 如果捅不为空,则需要遍历捅// 检测key是否存在Node<K, V> e;K k;// 如果第一个点就是要找的keyif (p.hash == hash && compareKey(key, p.key))e = p;// 如果第一个点不是要找的key,判断是红黑树吗else if (p instanceof TreeNode)e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);else {// 不是红黑树,那就是链表for (int binCount = 0; ; ++binCount) {// 找到最后都没找到keyif ((e = p.next) == null) {// 在链表尾部添加一个节点p.next = newNode(hash, key, value, null);// 查看链表个数是否大于等于8if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st// 转换为红黑树treeifyBin(tab, hash);break;}// 如果找到了,直接退出查找if (e.hash == hash && compareKey(key, e.key))break;p = e;}}// 表示存在要找的keyif (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;
// afterNodeAccess(e);return oldValue;}}++modCount;// 如果元素个数大于阈值,则扩容if (++size > threshold)resize();// afterNodeInsertion(evict);return null;}final void treeifyBin(Node<K, V>[] tab, int hash) {int len, index;Node<K, V> e;// 如果链表的大小超过8,但是哈希表的大小小于64,会进行扩容,等到满足了才会转换成红黑树if (tab == null || (len = tab.length) < MIN_TREEIFY_CAPACITY)resize();else if ((e = tab[index = (len - 1) & hash]) != null) {TreeNode<K, V> head = null, tail = null;do {// 尾插法,先将链表中的所有节点转换为树节点TreeNode<K, V> p = replacementTreeNode(e, null);if (tail == null)head = p;else {p.prev = tail;tail.next = p;}tail = p;} while ((e = e.next) != null);// 转换成红黑树if ((tab[index] = head) != null)head.treeify(tab);}}public void putAll(Map<? extends K, ? extends V> m) {putMapEntries(m, true);}final boolean compareKey(K k1, K k2) {return Objects.equals(k1, k2);}@Overridepublic V remove(Object key) {Node<K, V> e;e = removeNode(hash(key), key, null, false, true);if (e == null)return null;return e.value;}@Overridepublic boolean replace(K key, V oldValue, V newValue) {Node<K, V> e;V v;if ((e = getNode(hash(key), key)) != null &&((v = e.value) == oldValue || (v != null && v.equals(oldValue)))) {e.value = newValue;return true;}return false;}@Overridepublic V replace(K key, V value) {Node<K, V> e;if ((e = getNode(hash(key), key)) != null) {V oldValue = e.value;e.value = value;return oldValue;}return null;}// matchValue : 是否需要比较valuefinal Node<K, V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {Node<K, V>[] tab;Node<K, V> p;int n, index;// 判断该key对应的桶是否有元素if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) {// 查找到的key对应的node节点Node<K, V> node = null;Node<K, V> e;K k;V v;// 头节点是不是if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) {node = p;// 头节点不是,找下一个节点} else if ((e = p.next) != null) {// 如果是红黑树的话if (p instanceof TreeNode) {node = ((TreeNode<K, V>) p).getTreeNode(hash, key);}// 不是红黑树else {do {if (e.hash == hash && compareKey(e.key, key)) {node = e;break;}p = e;} while ((e = e.next) != null);}}//if (node != null && (!matchValue || (v = node.value) == value ||(value != null && value.equals(v)))) {// 找到的节点属于红黑树节点,从红黑树中删除if (node instanceof TreeNode) {((TreeNode<K, V>) node).removeTreeNode(this, tab, movable);// node是找到的节点,p是链表头,如果node正好是链表头的话,直接删除头节点} else if (node == p) {tab[index] = node.next;} else {// 此时p是当node的上一个节点p.next = node.next;}++modCount;--size;return node;}}return null;}// 删除所有的元素public void clear() {Node<K, V>[] tab;modCount++;if ((tab = table) != null && size > 0) {size = 0;for (int i = 0; i < tab.length; ++i) {tab[i] = null;}}}public boolean containsValue(Object value) {Node<K, V>[] tab;V v;if ((tab = table) != null && size > 0) {for (int i = 0; i < tab.length; i++) {for (Node<K, V> e = tab[i]; e != null; e = e.next) {if ((v = e.value) == value || (value != null && value.equals(v))) {return true;}}}}return false;}@Overridepublic V getOrDefault(Object key, V defaultValue) {Node<K, V> e;return (e = getNode(hash(key), key)) == null ? defaultValue : e.value;}@Overridepublic V putIfAbsent(K key, V value) {// 当不存在时才添加return putVal(hash(key), key, value, true, true);}// 当不存在时,执行mappingFunction方法,否则返回之前的值@Overridepublic V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) {if (mappingFunction == null)throw new NullPointerException();int hash = hash(key);Node<K, V>[] tab;Node<K, V> first; // 头节点int n, i; // n:tab长度,i:hash & n - 1int binCount = 0;TreeNode<K, V> t = null; // 红黑树的头节点Node<K, V> old = null; // 之前的值// 当该key对应的桶为null,重新resizeif (size > threshold || (tab = table) == null || (n = tab.length) == 0) {n = (tab = resize()).length;}if ((first = tab[i = (n - 1) & hash]) != null) {if (first instanceof TreeNode) {old = (t = (TreeNode<K, V>) first).getTreeNode(hash, key);} else {Node<K, V> e = first;K k;// 遍历链表do {if (e.hash == hash &&((k = e.key) == key) || (key != null && key.equals(k))) {old = e;break;}++binCount;} while ((e = e.next) != null);}V oldValue;if (old != null && (oldValue = old.value) != null) {return oldValue;}}// 走到这里说明该key在hash表中不存在或者对应的value不存在V v = mappingFunction.apply(key);if (v == null) {return null;// v!=null 并且 old !=null, 说明该key已经存在,但是 vlaue == null} else if (old != null) {old.value = v;return v;}// 表示该key在哈希表中不存在// 并且该key对应的桶是红黑树节点,那么就加入到红黑树中else if (t != null) {t.putTreeVal(this, tab, hash, key, v);} else {// 该桶是链表节点tab[i] = newNode(hash, key, v, first);if (binCount >= TREEIFY_THRESHOLD - 1) {treeifyBin(tab, hash);}}++modCount;++size;return v;}TreeNode<K, V> replacementTreeNode(Node<K, V> p, Node<K, V> next) {return new TreeNode<>(p.hash, p.key, p.value, next);}static final class TreeNode<K, V> extends MyLinkedHashMap.Entry<K, V> {TreeNode<K, V> parent; // red-black tree linksTreeNode<K, V> left;TreeNode<K, V> right;TreeNode<K, V> prev; // needed to unlink next upon deletionboolean red;TreeNode(int hash, K key, V val, Node<K, V> next) {super(hash, key, val, next);}final TreeNode<K, V> root() {TreeNode<K, V> p = this;while (p.parent != null) {p = p.parent;}return p;}// 将链表转换为红黑树final void treeify(Node<K, V>[] tab) {TreeNode<K, V> root = null;for (TreeNode<K, V> x = this, next; x != null; x = next) {next = (TreeNode<K, V>) x.next;x.left = x.right = null;// 如果根节点为空,则直接作为根节点if (root == null) {x.parent = null;x.red = false;root = x;} else {// 根节点不为空,则需要找到该节点在红黑树中的位置// 找到该key在红黑树中插入的位置K k = x.key;int h = x.hash;Class<?> kc = null;TreeNode<K, V> p = root;while (true) {// 向左还是向右 -1 表示向左, 1表示向右int dir;int ph = p.hash;K pk = p.key;// 如果hash值小于当前节点的hash值,则向左子树查找if (h < ph) {dir = -1;// 如果hash值大于当前节点的hash值,则向右子树查找} else if (h > ph) {dir = 1;// 如果hash值等于当前节点的hash值,则比较key} else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0)dir = tieBreakOrder(k, pk);TreeNode<K, V> xp = p;if (dir <= 0) {p = p.left;} else {p = p.right;}if (p == null) {x.parent = xp;if (dir <= 0) {xp.left = x;} else {xp.right = x;}root = balanceInsertion(root, x);break;}}}}moveRootToFront(tab, root);}// 红黑树转换为列表final Node<K, V> untreeify(MyHashMap<K, V> map) {Node<K, V> head = null, tail = null;// 这里我保证是红黑树的根节点Node<K, V> q = root();while (q != null) {Node<K, V> p = map.replacementNode(q, null);if (tail == null)head = p;elsetail.next = p;tail = p;q = q.next;}return head;}// 最终裁决方法// 1.先比较a,b的类名字符串,看返回值是不是0// 2.仍然返回0的话,调用System.identityHashCode去比较// System.identityHashCode会强制调用Object.hashCode()static int tieBreakOrder(Object a, Object b) {int d;if (a == null || b == null ||(d = a.getClass().getName().compareTo(b.getClass().getName())) == 0)d = (System.identityHashCode(a) <= System.identityHashCode(b) ?-1 : 1);return d;}final TreeNode<K, V> putTreeVal(MyHashMap<K, V> map, Node<K, V>[] tab,int h, K k, V v) {Class<?> kc = null;// 是否找到keyboolean searched = false;// 找到该红黑树的根节点TreeNode<K, V> root = root();TreeNode<K, V> p = root;while (true) {int dir;int ph = p.hash;K pk = p.key;if (h < ph) {dir = -1;} else if (h > ph) {dir = 1;} else if (pk == k || (k != null && k.equals(pk))) {return p;} else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0) {if (!searched) {TreeNode<K, V> q, ch;searched = true;ch = p.left;// 从左子树中找if (ch != null && (q = ch.find(h, k, kc)) != null) {return q;}ch = p.right;// 从右子树中找if (ch != null && (q = ch.find(h, k, kc)) != null) {return q;}}dir = tieBreakOrder(k, pk);}TreeNode<K, V> xp = p;if (dir <= 0)p = p.left;elsep = p.right;if (p == null) {Node<K, V> xpn = xp.next;TreeNode<K, V> x = map.newTreeNode(h, k, v, xpn);if (dir <= 0)xp.left = x;elsexp.right = x;xp.next = x;x.parent = xp;x.prev = xp;if (xpn != null) {((TreeNode<K, V>) xpn).prev = x;}root = balanceInsertion(root, x);moveRootToFront(tab, root);return null;}}}final TreeNode<K, V> find(int h, Object k, Class<?> kc) {TreeNode<K, V> p = this;do {int ph, dir;K pk;TreeNode<K, V> pl = p.left, pr = p.right, q;// 比较hash值// 给定hash小于当前节点的hash值,则向左子树查找if ((ph = p.hash) > h)p = pl;// 给定hash大于当前节点的hash值,则向右子树查找else if (ph < h)p = pr;// 如果hash相等,则比较key,如果key也相等,那直接返回else if ((pk = p.key) == k || (k != null && k.equals(pk)))return p;// 如果hash相等,但是key不相等,说明还需要继续往下找// 这个节点可能在左子树也可能在右子树// 如果当前节点的左子树为空,则向右子树查找else if (pl == null)p = pr;else if (pr == null)p = pl;// 左子树和右子树都不为空// 看这个插入的类是不是可比较的// 如果不是else if ((kc != null ||(kc = comparableClassFor(k)) != null) &&(dir = compareComparables(kc, k, pk)) != 0)p = (dir < 0) ? pl : pr;// 如果k是不可比较类型,那这里有什么作用呢?// TODO: 待补充else if ((q = pr.find(h, k, kc)) != null)return q;// 如果确定不了,那就从左子树开始找elsep = pl;} while (p != null);return null;}final TreeNode<K, V> getTreeNode(int h, Object k) {TreeNode<K, V> p = root();return p.find(h, k, null);}static <K, V> void moveRootToFront(Node<K, V>[] tab, TreeNode<K, V> root) {if (root == null || tab == null || tab.length == 0)return;int len = tab.length;int index = root.hash & (len - 1);TreeNode<K, V> first = (TreeNode<K, V>) tab[index];// 如果根节点不是第一个节点,则需要将根节点放到链表第一个位置if (root != first) {tab[index] = root;TreeNode<K, V> rp = root.prev;TreeNode<K, V> rn = (TreeNode<K, V>) root.next;if (rn != null)rn.prev = rp;if (rp != null)rp.next = rn;if (first != null)first.prev = root;root.next = first;root.prev = null;}}final void split(MyHashMap<K, V> map, Node<K, V>[] tab, int index, int bit) {// bit : oldCapacityTreeNode<K, V> b = this;TreeNode<K, V> loHead = null, loTail = null;TreeNode<K, V> hiHead = null, hiTail = null;int lc = 0, hc = 0;for (TreeNode<K, V> e = b, next; e != null; e = next) {next = (TreeNode<K, V>) e.next;e.next = null;if ((e.hash & bit) == 0) {if ((e.prev = loTail) == null) {loHead = e;} else {loTail.next = e;}loTail = e;++lc;} else {if ((e.prev = hiTail) == null) {hiHead = e;} else {hiTail.next = e;}hiTail = e;++hc;}}if (loHead != null) {// 如果链表个数小于等于6,退化成链表if (lc <= UNTREEIFY_THRESHOLD) {tab[index] = loHead.untreeify(map);} else {tab[index] = loHead;// 如果hiHead != null,说明分成了两个红黑树。// 那么就需要重新构建红黑树if (hiHead != null) {loHead.treeify(tab);}}}if (hiHead != null) {if (hc <= UNTREEIFY_THRESHOLD) {tab[index + bit] = hiHead.untreeify(map);} else {tab[index + bit] = hiHead;if (loHead != null) {hiHead.treeify(tab);}}}}static <K, V> TreeNode<K, V> rotateLeft(TreeNode<K, V> root, TreeNode<K, V> p) {if (p == null || p.right == null)return root;TreeNode<K, V> pp = p.parent; // 父节点TreeNode<K, V> pr = p.right; // 右孩子TreeNode<K, V> prl = pr.left;// 右孩子的左孩子p.right = prl;if (prl != null) {prl.parent = p;}pr.parent = pp;if (pp == null) {root = pr;root.red = false;} else if (p == pp.left) {pp.left = pr;} else {pp.right = pr;}pr.left = p;p.parent = pr;return root;}static <K, V> TreeNode<K, V> rotateRight(TreeNode<K, V> root, TreeNode<K, V> p) {if (p == null || p.left == null)return root;TreeNode<K, V> pp = p.parent;TreeNode<K, V> pl = p.left;TreeNode<K, V> plr = pl.left;p.left = plr;if (plr != null) {plr.parent = p;}// 更新旋转节点的父节点pl.parent = pp;if (pp == null) {root = pl;root.red = false;} else if (p == pp.left) {pp.left = pl;} else {pp.right = pl;}pl.right = p;p.parent = pl;return root;}static <K, V> TreeNode<K, V> balanceInsertion(TreeNode<K, V> root,TreeNode<K, V> x) {// x 为插入节点,将其颜色设置为nullx.red = true;TreeNode<K, V> xp, xpp, xppl, xppr;while (true) {xp = x.parent;// 1.如果插入节点的父亲为null,则它是根节点// 并将其设置成黑色if (xp == null) {x.red = false;return x;// 如果父亲节点为黑色,那么插入一个红色节点不会影响平衡,直接返回} else if (!xp.red) {return root;} else {// TODO: 如果父亲节点是根节点的话,那不应该是黑色嘛xpp = xp.parent;if (xpp == null) {return root;}}// 此时父亲肯定是红色xppl = xpp.left;xppr = xpp.right;if (xp == xppl) {if (xppr != null && xppr.red) {xppr.red = false;xp.red = false;xpp.red = true;// 将爷爷节点设置为插入节点,因为爷爷节点变成了红色,// 可能会破坏平衡,所以需要重新走一遍平衡x = xpp;} else {// 到这里,证明它的叔叔节点为空或者为黑色// 如果插入节点是父亲节点的右孩子if (x == xp.right) {// 先将父节点左旋x = xp;root = rotateLeft(root, x);xp = x.parent;xpp = xp == null ? null : xp.parent;}// 如果有父节点if (xp != null) {// 父节点设置成黑色xp.red = false;if (xpp != null) {// 爷爷节点设置成红色xpp.red = true;// 将爷爷节点右旋root = rotateRight(root, xpp);}}}} else {if (xppl != null && xppl.red) {xppl.red = false;xp.red = false;xpp.red = true;x = xpp;} else {if (x == xp.left) {x = xp;root = rotateRight(root, x);xp = x.parent;xpp = xp == null ? null : xp.parent;}if (xp != null) {xp.red = false;if (xpp != null) {xpp.red = true;root = rotateLeft(root, xpp);}}}}}}final void removeTreeNode(MyHashMap<K, V> map, Node<K, V>[] tab,boolean movable) {/*** 链表的处理*/int n;// 如果当前哈希表为空直接返回if (tab == null || (n = tab.length) == 0)return;// 计算当前节点在hash表的索引位置int index = (n - 1) & hash;// fisrt : t头节点TreeNode<K, V> first = (TreeNode<K, V>) tab[index];// 如果索引位置的红黑树为空if (first == null) {return;}// root:根节点TreeNode<K, V> root = first;// rl : root的左节点TreeNode<K, V> rl;// succ:节点的后继节点TreeNode<K, V> succ = (TreeNode<K, V>) next;// pred:节点的前驱节点TreeNode<K, V> pred = prev;// 如果根节点为空,则当前节点就是头节点,直接删除if (pred == null) {first = succ;tab[index] = succ;// 根节点不为空,当前节点为中间某个节点,删除中间节点} else {// 前驱的后继pred.next = succ;}// 后继的前驱if (succ != null) {succ.prev = pred;}// 如果root的父节点不为空,说明该节点并不是真正的红黑树根节点,需要重新查找根节点if (root.parent != null) {root = root.parent;}// 通过root节点来判断此红黑树是否太小, 如果是太小了则调用untreeify方法转为链表节点并返回// (转链表后就无需再进行下面的红黑树处理)// 太小的判定依据:根节点为null,或者根的右节点为null,或者根的左节点为null,或者根的左节点的左节点为null// 这里并没有遍历整个红黑树去统计节点数是否小于等于阈值6,而是直接判断这几种情况,// 来决定要不要转换为链表,因为这几种情况一般就涵盖了节点数小于6的情况,这样执行效率也会变高if (root == null || root.right == null ||(rl = root.left) == null || rl.left == null) {tab[index] = first.untreeify(map); // too smallreturn;}/*** 红黑树的处理*/TreeNode<K, V> p = this;TreeNode<K, V> pl = left;TreeNode<K, V> pr = right;// replacement:替换节点TreeNode<K, V> replacement;if (pl != null && pr != null) {// 找到当前节点的后继TreeNode<K, V> s = pr;TreeNode<K, V> sl = s.left;while (sl != null) {s = sl;sl = s.left;}// 交换p和s的颜色boolean c = s.red;s.red = p.red;p.red = c;TreeNode<K, V> sr = s.right;TreeNode<K, V> pp = p.parent;// 如果p的后继节点s恰好是p的右节点,那说明pr没有左节点// 那么就可以直接将pr替换为pif (s == pr) {// 先处理pp.parent = s;p.left = null;p.right = sr;if (sr != null) {sr.parent = p;}// 处理ss.right = p;s.left = pl;pl.parent = s;s.parent = pp;if (pp == null) {root = s;} else if (p == pp.left) {pp.left = s;} else {pp.right = s;}} else {// 将p和s互换TreeNode<K, V> sp = s.parent;p.parent = sp;if (s == sp.left) {sp.left = p;} else {sp.right = p;}p.left = null;p.right = sr;if (sr != null) {sr.parent = p;}s.parent = pp;if (pp == null) {root = s;} else if (p == pp.left) {pp.left = s;} else {pp.right = s;}s.left = pl;s.right = pr;pr.parent = s;}// 如果sr不等于null,那需要p和sr替换掉if (sr != null) {replacement = sr;// 如果sr等于null,此时p无子树,直接删掉就可以} else {replacement = p;}// 走到这里说明pr为null,pl不为null} else if (pl != null) {replacement = pl;// 走到这里说明pl为null,pr不为null} else if (pr != null) {replacement = pr;}// 到这里,说明p的左右节点都为nullelse {replacement = p;}// 删掉当前节点pif (replacement != p) {TreeNode<K, V> pp = replacement.parent = p.parent;// 当p只有一个子树的时候,p的父节点可能为nullif (pp == null) {root = replacement;} else if (p == pp.left) {pp.left = replacement;} else {pp.right = replacement;}// 删掉p节点p.left = p.right = p.parent = null;}// 如果p节点是红色,那不影响树的结构TreeNode<K, V> r = p.red ? root : balanceDeletion(root, replacement);if (replacement == p) {TreeNode<K, V> pp = p.parent;p.parent = null;if (pp != null) {if (p == pp.left) {pp.left = null;} else {pp.right = null;}}}}static <K, V> TreeNode<K, V> balanceDeletion(TreeNode<K, V> root,TreeNode<K, V> x) {TreeNode<K, V> xp, xpl, xpr;while (true) {// 如果x为null或者是根节点,说明已经删除完了if (x == null || x == root) {return root;// 父节点为null,说明是根节点} else if ((xp = x.parent) == null) {x.red = false;return x;// 如果x是红色的,那么直接让它变成黑色的就行了// 因为父节点是黑色的,x节点直接代替他成为黑色的就行了// 这对应情景1.1或情景2} else if (x.red) {x.red = false;return root;// x既不是根节点,也不是红色// x是父亲的左节点} else if ((xpl = xp.left) == x) {// 此时对应于情景1.2.1,父兄换色,然后对x在进行一次平衡if ((xpr = xp.right) != null && xpr.red) {xpr.red = false;xp.red = true;root = rotateLeft(root, xp);xpr = (xp = x.parent) == null ? null : xp.right;}if (xpr == null) {// TODO: 这里应该不可能出现System.out.println("..........");x = xp;} else {TreeNode<K, V> sl = xpr.left, sr = xpr.right;// 此时xpr只能是黑色// 这里if判断成功的可能条件:// 1.sl == null,sr == null (对应情景1.2.2.3)// 2.sl == null,sr == black (不可能)// 3.sl == black,sr == null (不可能)// 4.sl == black,sr == black (不可能)if ((sr == null || !sr.red) &&(sl == null || !sl.red)) {// 对应情景1.2.2.3xpr.red = true;x = xp;} else {// 进入这里的可能条件// 1.sl == null,sr == red (对应情景1.2.2.1)// 2.sl == red,sr == null (对应情景1.2.2.2)// 3.sl == red,sr == red (对应情景1.2.2.1)// 4.sl == black,sr == red (不存在)// 4.sl == red,sr == black (不存在)// 条件2if (sr == null) {// 情景1.2.2.2sl.red = false;xpr.red = true;root = rotateRight(root, xpr);xpr = (xp = x.parent) == null ? null : xp.right;}// 此时就变成了场景1.2.2.1if (xpr != null) {// 父兄换色xpr.red = xp.red;if ((sr = xpr.right) != null) {sr.red = false;}}if (xp != null) {xp.red = false;root = rotateLeft(root, xp);}x = root;}}} else {// 如果xpl为红色,那xp和xpl的孩子肯定为黑色if (xpl != null && xpl.red) {xpl.red = false;xp.red = true;root = rotateRight(root, xp);xpl = (xp = x.parent) == null ? null : xp.left;}if (xpl == null) {x = xp;} else {TreeNode<K, V> sl = xpl.left, sr = xpl.right;if ((sl == null || !sl.red) && (sr == null || !sr.red)) {xpl.red = true;x = xp;} else {if (sl == null) {sr.red = false;xpl.red = true;root = rotateLeft(root, xpl);xpl = (xp = x.parent) == null ?null : xp.left;}if (xpl != null) {xpl.red = xp.red;if ((sl = xpl.left) != null)sl.red = false;}if (xp != null) {xp.red = false;root = rotateRight(root, xp);}x = root;}}}}}}TreeNode<K, V> newTreeNode(int hash, K key, V value, Node<K, V> next) {return new TreeNode<>(hash, key, value, next);}Node<K, V> replacementNode(Node<K, V> p, Node<K, V> next) {return new Node<>(p.hash, p.key, p.value, next);}Node<K, V> newNode(int hash, K key, V value, Node<K, V> next) {return new Node<>(hash, key, value, next);}
}相关文章:

手撕HashMap源码
终于通过不屑努力,把源码中的重要部分全都看完了,每一行代码都看明白了,还写了注释 import java.lang.reflect.ParameterizedType; import java.lang.reflect.Type; import java.util.*; import java.util.function.Consumer; import java.ut…...

OceanBase block_file与log过大 的问题
一、说明 block_file 是存放sstable的数据文件,由datafile_disk_percentage 参数与datafile_size参数决定,两个参数同时配置,以datafile_size为主。 datafile_disk_percentage 默认值是90 datafile_size 默认值是0M到正无穷 因为block_file 的…...

【Focal Loss 本质】
Focal Loss 示例 Focal Loss公式: 在后面的例子中,我们假定 y 1 的样本中,有两个预测值分别为(0.8, 0.4)。显然,0.8 很容易分类,0.4 很难分类。 可以看出,Focal Loss 降低了容易分类(prt 0…...
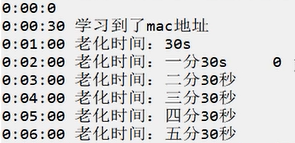
端口安全老化细节
我们都知道port-security aging-time命令用来配置端口安全动态MAC地址的老化时间,但是后面还可以加上类型: [SW1-GigabitEthernet0/0/1]port-security aging-time 5 type absolute Absolute time 绝对老化 inactivity Inactivity time相对老化 …...

【C++】—— string 模拟实现
【C】—— string模拟实现 0 前言1 string的底层结构2 默认成员函数的实现2.1 构造函数2.1.1 无参构造2.1.2 带参构造2.1.2 合并 2.2 析构函数2.3 拷贝构造函数2.3.1 传统写法2.3.2 现代写法 2.3 赋值重载2.3.1 传统写法2.3.2 现代写法2.3.3 传统写法与现代写法的优劣 3 size、…...

详解TensorRT的C++高性能部署以及C++部署Yolo实践
详解TensorRT的C高性能部署 一. ONNX1. ONNX的定位2. ONNX模型格式3. ONNX代码使用实例 二、TensorRT1 引言 三、C部署Yolo模型实例 一. ONNX 1. ONNX的定位 ONNX是一种中间文件格式,用于解决部署的硬件与不同的训练框架特定的模型格式的兼容性问题。 ONNX本身其…...

手机如何切换网络IP地址:方法详解与操作指南
在当今的数字化时代,网络IP地址作为设备在网络中的唯一标识,扮演着至关重要的角色。对于手机用户而言,了解如何切换网络IP地址不仅有助于提升网络体验,还能在一定程度上保护个人隐私。本文将详细介绍手机切换网络IP地…...
南通网站建设手机版网页
随着移动互联网的迅猛发展,越来越多的人通过手机浏览网页,进行在线购物、信息查询和社交互动。因此,建立一个适合移动端访问的网站已成为企业和个人不可忽视的重要任务。在南通,网站建设手机版网页的需求逐渐增加,如何…...

macos系统内置php文件列表 系统自带php卸载方法
在macos系统中, 自带已经安装了php, 根据不同的macos版本php的版本号可能不同, 我们可以通过 which php 命令来查看mac自带的默认php安装路径, 不过注意这个只是php的执行文件路径. 系统自带php文件列表 一下就是macos默认安装的php文件列表. macos 10.15内置PHP文件列表配置…...

微信小程序认证和备案
小程序备案的流程一般包括以下步骤: 准备备案所需材料:通常需要提供营业执照、法人的身份证、两个手机号和一个邮箱等资料。 1 登录微信公众平台:作为第一次开发微信小程序的服务商,需要通过微信公众平台申请…...

C++复习day05
类和对象 1. 面向对象和面向过程的区别是什么?(开放性问题) 1. **抽象级别**:- **面向对象**:以对象(数据和方法的集合)为中心,强调的是数据和行为的封装。- **面向过程**…...

python数值误差
最近在用fenics框架跑有限元代码,其中有一个部分是把在矩阵里定义的初始值,赋值到有限元空间里,这就涉及到了初始矩阵和有限元空间坐标的转化,部分代码如下 for i in range(len(dof_coordinates)):# x, y dof_coordinates[i…...

基于FPGA的OV5640摄像头图像采集
1.OV5640简介 OV5640是OV(OmniVision)公司推出的一款CMOS图像传感器,实际感光阵列为:2592 x 1944(即500w像素),该传感器内部集成了图像出炉的电路,包括自动曝光控制(AEC…...

CDN ❀ Http协议标准缓存字段梳理
文章目录 1. 背景介绍2. 测试环境搭建3. 缓存字段3.1 Expires3.2 Cache-Control3.3 协商缓存 1. 背景介绍 Http协议标准有RFC定义好的请求和响应头部字段用于进行缓存设置,本文主要进行介绍缓存功能相关的头部字段及其使用方法。在使用CDN功能是,协议标…...

浅谈NODE的NPM命令和合约测试开发工具HARDHAT
$ npm install yarn -g # 将模块yarn全局安装 $ npm install moduleName # 安装模块到项目目录下 默认跟加参数 --save 一样 会在package文件的dependencies节点写入依赖。 $ npm install -g moduleName # -g 的意思是将模块安装到全局,具体安装到磁盘哪个位置&…...
)
k8s-pod 实战六 (如何在不同的部署环境中调整startupprobe的参数?)
在不同的部署环境中(如开发、测试、生产环境),你可能希望对 startupProbe 的参数进行调整,以适应不同的需求和条件。以下是几种常见的方法和实践: 方法一:使用 Kustomize 1. 目录结构 假设你的项目目录结构如下: my-app/ ├── base/ │ └── deployment.yaml …...

和服务端系统的通信
首先web网站 前端浏览器 和 后端系统 是通过HTTP协议进行通信的 同步请求&异步请求: 同步请求:可以从浏览器中直接获取的(HTML/CSS/JS这样的静态文件资源),这种获取请求的http称为同步请求 异步请求:js代码需要到服…...

python 实现perfect square完全平方数算法
python 实现perfect square完全平方数算法介绍 完全平方数(Perfect Square)是一个整数,它可以表示为某个整数的平方。例如,1,4,9,16,25,… 都是完全平方数,因为 1 1 2 , 4 2 2 , 9 3 2 11^2,42^2,93^2 112,422,93…...

【漏洞复现】某客圈子社区小程序审计(0day)
0x00 前言 █ 纸上得来终觉浅,绝知此事要躬行 █ Fofa:"/static/index/js/jweixin-1.2.0.js"该程序使用ThinkPHP 6.0.12作为框架,所以直接审计控制器即可.其Thinkphp版本较高,SQL注入不太可能,所以直接寻找其他洞. 0x01 前台任意文件读取+SSRF 在 /app/api/c…...

信息安全数学基础(1)整除的概念
前言 在信息安全数学基础中,整除是一个基础且重要的概念。它涉及整数之间的特定关系,对于理解数论、密码学等领域至关重要。以下是对整除概念的详细阐述: 一、定义 设a, b是任意两个整数,其中b ≠ 0。如果存在一个整数q࿰…...

无机布防火卷帘门报价透明,包工包料,一次说清所有费用
很多客户在选购无机布防火卷帘门时,最关心实际成交价格,也担心报价不清晰,后期产生各类额外支出。行业内产品定价参差不齐,选材做工不同,最终价位自然存在差距,挑选时不能只看表面低价。 👉 点击…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

别只拿PotPlayer看片了!挖掘它的采集录制功能,做Switch游戏存档大师
别把PotPlayer当普通播放器!解锁它的Switch游戏录制黑科技 你是否已经厌倦了在OBS、Bandicam等专业录制软件中反复调试参数的繁琐?是否想过那个每天用来看视频的PotPlayer,其实隐藏着令人惊喜的游戏录制能力?今天,我们…...

2026智慧校园规划必读:如何在预算吃紧下选到高性价比方案
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

Spring Security OAuth2 /oauth/token 401原因与Content-Type规范
1. 问题现场还原:一个看似简单却让开发停摆两小时的/oauth/token请求刚接手一个老项目做安全加固,第一件事就是验证OAuth2密码模式的token获取流程。我照着文档写了一条curl命令:curl -X POST http://localhost:8080/oauth/token回车执行&…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...

别再死记硬背了!用UE材质里的点积、叉积,5分钟搞定模型表面动态光效
用UE材质玩转动态光效:点积、叉积实战指南第一次接触UE材质编辑器时,看到那些密密麻麻的数学节点总让人头皮发麻。特别是"点积"、"叉积"这些听起来就很高深的术语,很容易让美术背景的创作者望而却步。但你知道吗…...

利用FTDI芯片MPSSE模式构建Arduino兼容开发环境
1. 项目概述:当FTDI芯片遇上Arduino生态如果你手头有一些闲置的FTDI USB转串口模块,比如常见的FT232R、FT2232H,或者像我一样,从某个旧设备上拆下来一块FT2232C的老古董,除了用来给单片机烧录程序或者做串口调试&#…...

中小企无需重型数据中台:轻量化数据体系搭建完整方案
过去几年,“数据中台”一度成为企业数字化的标配热词。大量中小企业盲目跟风搭建重型数据中台,投入高额成本、耗费数月甚至数年周期,最终落地效果极差:功能冗余、运维复杂、使用率低、投入产出比失衡。大量项目最终沦为“摆设式中…...